
En bref
L'IA Text-to-Video est une technologie d'intelligence artificielle qui génère automatiquement des vidéos à partir de descriptions textuelles. Il suffit d'entrer une description pour que l'IA produise un clip vidéo comprenant des mouvements, des effets d'éclairage et des mouvements de caméra. D'ici 2026, grâce à l'architecture Diffusion Transformer (DiT), cette technologie est passée d'un prototype expérimental flou à une qualité quasi cinématographique. Ce guide couvre les principes techniques, un tutoriel pratique en cinq étapes, dix modèles de invites reproductibles, une analyse comparative de huit outils, six scénarios d'application majeurs et les limites réelles que vous devez comprendre.Découvrez gratuitement la génération de texte en vidéo →

IA texte-vidéo : à partir d'une simple description, l'IA transforme le texte en vidéo de qualité cinématographique.
Qu'est-ce que l'IA de conversion texte-vidéo ?
L'IA texte-vidéo désigne une catégorie de technologie d'intelligence artificielle qui génère automatiquement du contenu vidéo à partir de descriptions textuelles. Vous décrivez une scène (une femme se promenant sous la pluie, un produit tournant sur un présentoir, un drone survolant des montagnes) et le modèle d'IA produit un clip vidéo très réaliste, avec des mouvements, un éclairage et des effets physiques naturels.
Le concept de base est simple : saisie de texte, sortie vidéo. Pourtant, la technologie sous-jacente est loin d'être simple. Les systèmes modernes de conversion de texte en vidéo utilisent des réseaux neuronaux entraînés sur des milliards de jeux de données appariés « vidéo-texte », apprenant les relations statistiques entre les descriptions linguistiques et le mouvement visuel. Lorsque vous écrivez « un chat saute sur une table », le modèle s'appuie sur ses connaissances accumulées sur les chats, la physique du saut, les surfaces des tables et la gravité pour générer une vidéo plausible.
2026 : de l'expérimentation à l'outil de productivité
L'IA de conversion texte-vidéo a franchi le seuil de la « maturité opérationnelle » en 2025-2026. Les premiers systèmes de 2022-2023 ne pouvaient produire que des clips courts, flous et physiquement invraisemblables. Les modèles actuels, en revanche, génèrent des vidéos en résolution 2K avec des mouvements physiquement précis, naturellement animés et de qualité cinématographique, d'une durée de 5 à 15 secondes. Ce bond en avant transforme la technologie de conversion texte-vidéo d'une curiosité scientifique en un outil pratique :
- Créateurs de contenu : obtenez des séquences B-roll, des séquences d'introduction et des ressources pour les réseaux sociaux sans caméra
- Professionnels du marketing : Produisez en masse des variantes publicitaires et des démonstrations de produits
- Enseignants : Visualisez des concepts abstraits
- Petites et moyennes entreprises : Évitez les coûts élevés de la production vidéo professionnelle
- Tout le monde : Si vous savez écrire, vous pouvez créer des vidéos
Le seuil pour créer une vidéo est passé de « posséder une caméra et savoir monter » à « rédiger une description convaincante ».
Évolution technologique : du GAN au DiT
Comprendre la technologie sous-jacente peut vous aider à créer de meilleures invites et à sélectionner des outils plus adaptés. Vous trouverez ci-dessous les trois générations d'évolution technologique de l'IA de conversion de texte en vidéo.

Trois générations d'évolution technologique : GAN (2020-2022) → Modèles de diffusion (2023-2024) → Diffusion Transformers / DiT (2025-2026).
Première génération : l'ère des GAN (2020-2022)
Les réseaux antagonistes génératifs (GAN) ont été la première architecture à démontrer la faisabilité de la conversion « texte-vidéo ». Deux réseaux neuronaux sont soumis à un entraînement antagoniste : le générateur crée des images vidéo tandis que le discriminateur juge leur authenticité. Cependant, les résultats étaient de faible résolution (256 × 256), de courte durée (2 à 4 secondes) et physiquement invraisemblables. Les objets subissent des déformations imprévisibles, les traits du visage sont déformés et la cohérence temporelle est gravement compromise. Parmi les réalisations représentatives, on peut citer CogVideo et NUWA.
Deuxième génération : l'ère des modèles de diffusion (2023-2024)
Le modèle de diffusion a fondamentalement remodelé le paysage. Il n'utilise plus l'apprentissage antagoniste, mais apprend plutôt un processus de « débruitage inversé » : il part d'un bruit pur et le débruit progressivement pour obtenir une vidéo cohérente guidée par le texte. Cette approche offre un bond qualitatif : une résolution plus élevée (jusqu'à 1080p), une durée plus longue (4 à 10 secondes) et un meilleur alignement entre le texte et l'image.
Sora d'OpenAI (sorti en février 2024) a démontré que les modèles de diffusion peuvent générer des vidéos étonnamment photoréalistes. Runway Gen-2/Gen-3, Pika et Stable Video Diffusion appartiennent tous à cette génération.
Troisième génération : DiT — Transformateur à diffusion (2025-2026)
Les architectures les plus avancées combinent actuellement des processus de diffusion avec l'architecture Transformer (la même architecture que celle utilisée par GPT et BERT). Les modèles DiT traitent la vidéo comme une séquence de patchs spatio-temporels, ce qui permet d'obtenir :
- Amélioration de la cohérence temporelle : les transformateurs excellent dans la modélisation des dépendances à long terme entre les images
- Résolution supérieure : Sortie native 2K (Seedance 2.0 atteint 2048×1080)
- Précision physique améliorée : Mouvements, gravité et dynamique des fluides plus réalistes
- Meilleure compréhension du texte : Alignement nettement amélioré entre les descriptions des invites et les sorties visuelles
- Entrée multimodale : certains modèles DiT peuvent accepter simultanément des entrées image, vidéo et audio
Seedance 2.0, Google Veo 3 et Keeling 3.0 utilisent tous l'architecture DiT. C'est pourquoi la génération de texte en vidéo en 2026 présente une différence qualitative par rapport à celle de 2024.
Texte-vidéo vs image-vidéo
Ces deux approches sont complémentaires plutôt que concurrentes :
| Dimension | Texte-vidéo (T2V) | Image-vidéo (I2V) | |------|------------------|----------------- -| | Entrée | Description textuelle uniquement | Photographie + description du mouvement | | Liberté créative | Maximale — L'IA détermine tous les éléments visuels | Limitée par l'image source | | Contrôlabilité | Moindre — Dépend de la précision de la commande | Supérieure — Ancrages visuels disponibles | | Scénarios adaptés | Exploration de concepts, contenu original | Présentation de produits, animation de photos, correspondance de styles | | Prévisibilité | Faible — Une même invite donne des résultats différents à chaque fois | Élevée — Le résultat correspond toujours à l'image source |
La plupart des flux de travail professionnels utilisent les deux approches : ils commencent par employer le T2V pour explorer des concepts créatifs, puis affinent le résultat avec l'I2V. Pour une exploration détaillée de la génération d'images à partir de vidéos, consultez notre Guide complet sur l'IA image-vidéo.
Tutoriel en 5 étapes : créer votre première vidéo IA
Voici un guide étape par étape pour générer du contenu texte-vidéo à partir de zéro, en utilisant Seedance 2.0 comme plateforme de démonstration. Les principes sous-jacents s'appliquent à n'importe quel outil.

De la création rapide au résultat final : cinq étapes pour réaliser votre première vidéo IA.
Étape 1 : Définir les objectifs de la vidéo
Avant de rédiger l'invite, déterminez d'abord :
- Type : séquences B-roll, démonstrations de produits, contenu pour les réseaux sociaux, créations artistiques ou narration ?
- Durée : 5 secondes pour les tests, 10 à 15 secondes pour le résultat final
- Format d'image : 16:9 pour YouTube / Bilibili, 9:16 pour Douyin / Kuaishou / Xiaohongshu, 1:1 pour WeChat Moments
- Style : Cinématographique, documentaire, animation, publicité commerciale ou artistique
Définir des objectifs clairs permet d'éviter de gaspiller les quotas de génération dans des expériences ambiguës.
Étape 2 : Créer des invites textuelles de haute qualité
La promptitude est l'essence même de la génération de texte en vidéo. Utilisez la formule suivante :
[Sujet] + [Action/Mouvement] + [Cadre] + [Style] + [Mouvement de caméra] + [Éclairage]
Mauvaise suggestion : « Un chien qui court »
Bonne suggestion : « Un golden retriever courant dans une prairie ensoleillée, des fleurs sauvages ondulant dans la brise. Le pelage du chien ondule à chaque foulée. La caméra suit le chien au ras du sol. Lumière chaude de l'heure dorée avec de longues ombres. Profondeur de champ cinématographique, qualité 4K.
Principes clés :
- Le mouvement doit être précis : « tourne lentement la tête » plutôt que « tourne »
- Décrivez les mouvements de caméra : « la caméra effectue un zoom avant » ou « prise de vue aérienne par drone »
- Créez l'ambiance : éclairage, étalonnage des couleurs, ambiance
- Évitez les contradictions : ne demandez pas simultanément une « action rapide » et un « ralenti »
- Ne demandez pas de texte/interface utilisateur : le modèle actuel a du mal à rendre le texte lisible dans les séquences vidéo
Remarque : il est conseillé de rédiger les invites en anglais, même lorsque vous utilisez des outils nationaux (tels que KeLing, TongYi WanXiang ou Hunyuan Video). En effet, la plupart des modèles ont été entraînés à partir de jeux de données en anglais plus complets.
Pour un système de techniques de prompt plus complet, veuillez vous référer au Guide de rédaction de prompts et aux 10 prompts vidéo IA vraiment efficaces.
Étape 3 : Sélectionnez Outils et Paramètres
Sélectionnez une plateforme (voir le tableau comparatif ci-dessous), puis configurez :
- Modèle : utilisez le dernier modèle disponible (par exemple, Seedance 2.0, et non 1.0)
- Résolution : minimum 1080p ; optez pour 2K si disponible
- Durée : Testez initialement avec 5 secondes, prolongez si le résultat est satisfaisant
- Format d'image : Adaptez-vous à votre plateforme de distribution
- Valeur de graine (si disponible) : Verrouillez la graine pour une itération cohérente
Étape 4 : Générer et réviser
Cliquez sur Générer et attendez entre 60 et 180 secondes (selon l'outil). Lorsque vous examinez le résultat, prêtez attention aux éléments suivants :
- ✅ Le mouvement correspond-il à la description ?
- ✅ Le sujet est-il cohérent tout au long de la vidéo (aucune déformation) ?
- ✅ La physique est-elle plausible (gravité, fluides, tissus) ?
- ✅ Le mouvement de la caméra est-il fluide ?
- ❌ Y a-t-il des artefacts, des scintillements ou des distorsions ?
- ❌ Y a-t-il un effet « uncanny valley » sur les visages/mains ?
Étape 5 : Optimisation itérative
La première tentative est rarement parfaite. Méthodes d'optimisation :
- Ajustez la commande : ajoutez des détails là où l'IA s'est trompée
- Ne modifiez qu'une seule variable à la fois : évitez de réécrire toute la commande
- Testez différentes graines : la même invite peut donner des résultats totalement différents
- Prolongez la durée : une fois satisfait de la version de 5 secondes, essayez 10 à 15 secondes
- Intégrez de l'audio : si l'outil le permet (Seedance, Veo 3), ajoutez des effets sonores ou une musique de fond

Exemples d'itérations de prompt : V1 (prompt de base) → V2 (ajout de descriptions du mouvement et de l'éclairage) → V3 (spécifications cinématiques complètes). Chaque cycle d'amélioration améliore considérablement la qualité de l'image.
10 modèles de prompts pour la génération de vidéos à partir de texte
Les modèles suivants peuvent être copiés et utilisés directement. Ils ont été testés sur Seedance 2.0 et sont compatibles avec la plupart des plateformes courantes.
1. Portrait cinématographique
A close-up of a young woman with flowing dark hair, her face illuminated by warm golden hour sunlight filtering through a window. She slowly turns her head toward the camera, a subtle smile forming. Soft bokeh background of a cozy interior. Camera holds steady with a slight push-in. Warm amber lighting, shallow depth of field, 4K cinematic quality.
Scénarios adaptés : réseaux sociaux, image de marque personnelle, création artistique
- Présentation des produits
A sleek wireless headphone rotating slowly on a matte black pedestal. Soft studio lighting creates clean highlights on the brushed metal surface. Camera orbits 180 degrees at eye level. Minimalist white background, no shadows. Smooth continuous motion, commercial product photography quality.
Scénarios adaptés : pages détaillées de produits e-commerce, marketing produit, vidéos d'images principales Taobao/JD.com
- Cinéma nature
An epic aerial drone shot over a misty mountain valley at sunrise. Golden light breaks through layered clouds, illuminating a winding river below. Camera pushes forward slowly, revealing the vast landscape. Volumetric fog drifts between peaks. IMAX cinematography quality, hyper-detailed.
Convient pour : vidéos d'introduction YouTube/Bilibili, contenu lié au voyage, écrans de veille, chaînes de méditation
4. Rue urbaine
A neon-lit Tokyo alley at night after rain. Wet cobblestones reflect vivid pink, teal, and amber neon signs. A lone figure walks away from camera, umbrella in hand. Steam rises from a street vent. Camera follows at a distance, tracking shot. Film noir atmosphere, anamorphic lens flare.
Scénarios adaptés : clips musicaux, séquences d'ambiance, contenu de style cyberpunk
- Style anime
An anime warrior princess with flowing silver hair stands on a cliff edge overlooking a fantasy kingdom. Her cape billows dramatically in the wind. She raises a glowing sword that emits blue energy particles. Cherry blossom petals drift past. Camera slowly orbits. Studio Ghibli meets Ufotable quality animation.
Convient pour : contenu animé, chaînes de jeux vidéo, récits fantastiques
6. Restauration
Extreme macro close-up of rich dark coffee being poured in slow motion into a pristine ceramic cup. Individual droplets and tiny splashes frozen mid-air. Wisps of steam curl elegantly upward. Warm side lighting reveals the liquid's amber transparency. Cinnamon stick and scattered beans visible in soft focus foreground.
Scénarios adaptés : marketing pour les restaurants, blogueurs culinaires, publicité pour les boissons
- Mode et éditorial
A model in a flowing white silk gown walks confidently down a dark runway. Multiple flash strobes create sharp geometric light patterns. The fabric billows with perfect physics. Camera at a low angle, slight slow motion. High fashion editorial aesthetic, Vogue magazine quality.
Scénarios adaptés : marques de mode, contenu beauté, articles rédactionnels
- Science-fiction et fantastique
A massive spaceship emerges from hyperspace above a ringed planet. Blue energy dissipates around the hull as the vessel decelerates. Tiny fighter escorts flank its sides. Camera pulls back to reveal the scale against the planet. Volumetric space dust and distant star field. Hollywood VFX quality.
Scénarios adaptés : contenus de divertissement, chaînes de science-fiction, visualisation de concepts
- Sports et action
A basketball player at the peak of a slam dunk, frozen in mid-air. Time resumes in slow motion — sweat droplets fly, the ball compresses against the rim, arena spotlights create dramatic lens flare. Camera shoots from below looking up. ESPN broadcast quality, hyper-detailed.
Convient pour : Contenu sportif, marques d'articles de sport, compilations des moments forts
- Art abstrait (abstrait et artistique)
Liquid gold and deep indigo ink collide in slow motion inside a glass sphere. The fluids intertwine in mesmerizing fractal patterns. Tiny bubbles catch light. Camera slowly rotates around the sphere. Pure black background. Macro photography meets fluid dynamics simulation. Meditative, hypnotic pace.
Scénarios adaptés : arrière-plans visuels, clips musicaux, installations artistiques, écrans de veille

Le résultat réel de quatre des dix modèles ci-dessus : chaque invite génère des visuels de qualité cinématographique au style distinctif à partir d'un texte brut.
2026 : Examen comparatif de huit outils de génération de vidéos à partir de textes
Nous avons testé huit plateformes grand public à l'aide de la même invite (« Un golden retriever courant dans une prairie ensoleillée, des fleurs sauvages ondulant au vent, qualité cinématographique 4K ») et les avons notées selon cinq critères. Tous les tests ont été réalisés en février 2026.
| Outil | Résolution maximale | Durée maximale | Version gratuite | Audio | Meilleure utilisation | Évaluation de la qualité d'image | |------|----------|---------|--------|------|-------- -|---------| | Seedance 2.0 | 2K (2048×1080) | 15 secondes | ✅ Quota quotidien gratuit | ✅ Effets sonores + musique + synchronisation labiale | Création multimodale | 9,2/10 | | Google Veo 3 | 4K (limité) | 8 secondes | ✅ Quota AI Studio | ✅ Audio natif | Fusion audiovisuelle | 9,0/10 | | Sora 2 | 1080p | 20 secondes | ❌ Nécessite ChatGPT Plus | ❌ | Vidéo basée sur un texte long | 8,8/10 | | Keling 3.0 | 1080p | 20+ secondes | ✅ Crédits d'inscription gratuits | ⚠️ Limité | Vidéos longues, bon rapport qualité-prix | 8,5/10 | | Runway Gen-4 | 1080p | 10 secondes | ✅ 125 crédits | ❌ | Flux de travail d'édition professionnel | 8,5/10 | | Pika 2.0 | 1080p | 10 secondes | ✅ Quota quotidien gratuit | ⚠️ Effets sonores uniquement | Utilisateurs débutants, effets amusants | 8,0/10 | | Luma Dream Machine | 1080p | 5 secondes | ✅ Génération gratuite | ❌ | Scènes 3D, itération rapide | 7,8/10 | | Snail AI (MiniMax) | 1080p | 6 secondes | ✅ Gratuit tous les jours | ❌ | Vitesse de génération la plus rapide | 7,5/10 |
Avis important pour les utilisateurs nationaux : Seedance 2.0, KeLing 3.0 et Haier AI sont directement accessibles en Chine. Sora 2 nécessite un abonnement ChatGPT Plus (VPN nécessaire). Google Veo 3 nécessite un accès via Google AI Studio (VPN nécessaire). Runway, Pika et Luma nécessitent tous une connexion réseau à l'étranger.
Alternatives nationales : Tongyi Wanshang (Alibaba), Hunyuan Video (Tencent) et Qingying (filiale de ByteDance) offrent également des fonctionnalités de génération de texte en vidéo, avec des quotas d'utilisation gratuits variables.
Principales conclusions :
- Meilleure qualité d'image globale : Seedance 2.0 (2K natif + entrée quadri-mode + audio)
- Meilleures capacités audio : Seedance 2.0 et Google Veo 3
- Meilleure version gratuite : Seedance 2.0 (accès gratuit à la résolution 2K, aucune carte de crédit requise)
- Durée vidéo gratuite la plus longue : Keeling 3.0 (plus de 20 secondes)
- Le plus adapté aux débutants : Pika 2.0 (interface la plus simple, effets amusants)
Pour une comparaison plus détaillée, veuillez consulter La comparaison complète des meilleurs générateurs de vidéos IA pour 2026. Pour vous concentrer uniquement sur les offres gratuites, veuillez consulter Une revue comparative des générateurs de vidéos IA gratuits.
6 scénarios d'application clés
- Contenu des réseaux sociaux
Créez des vidéos courtes accrocheuses pour TikTok, Kuaishou, Xiaohongshu, Bilibili et YouTube Shorts. L'IA élimine complètement le besoin de filmer, de monter et de faire de la post-production.
Spécifications recommandées : format 9:16, durée de 5 à 15 secondes, avec une seconde d'ouverture à fort impact visuel.
- Marketing et publicité
Produisez en masse différentes variantes de supports publicitaires. Testez plusieurs concepts visuels à l'aide de différentes invites avant de vous engager dans le budget de production officiel. Générez des versions de test A/B en quelques minutes.
Configuration recommandée : Compatibilité multiformat sur plusieurs plateformes. Associez-le aux capacités audio de Seedance pour produire des films publicitaires complets.
3. Éducation et formation
Visualiser des concepts abstraits difficiles, voire impossibles à saisir : structures moléculaires, événements historiques, concepts mathématiques, processus scientifiques. La vidéo IA rend visible l'invisible.
Configuration recommandée : pour obtenir des résultats pédagogiques optimaux, associez une invite décrivant précisément le concept à un commentaire audio.
- Divertissement et narration
Les cinéastes indépendants et les créateurs d'histoires utilisent la technologie de conversion texte-vidéo pour la visualisation de concepts, la création de storyboards et même la production finale de courts métrages. Cette technologie démocratise la réalisation cinématographique.
Configuration recommandée : incluez des spécifications détaillées concernant la direction de la caméra et l'éclairage dans la consigne afin d'obtenir un effet cinématographique.
- Vidéos de produits pour le commerce électronique
Transformez les descriptions de produits en vidéos de démonstration. Cela s'avère particulièrement utile pour les détaillants qui proposent des centaines de références et ne peuvent pas produire de vidéos individuelles pour chaque produit. Pour plus de détails sur les workflows e-commerce, veuillez consulter le Guide vidéo AI E-commerce.
Spécifications recommandées : photographie de produit avec éclairage de studio. Format 1:1 pour les pages détaillées des produits, 16:9 pour YouTube/Bilibili, 9:16 pour TikTok/Xiaohongshu.
6. Création de contenu YouTube / Bilibili
Créez des séquences B-roll, des séquences d'introduction, des commentaires visuels et des vidéos courtes complètes. Les créateurs peuvent améliorer l'efficacité de la production de contenu grâce à la technologie vidéo IA. Pour connaître l'intégralité du processus de création YouTube, veuillez consulter le Guide YouTube pour les créateurs sur la vidéo IA.
Configuration recommandée : Maintenez une cohérence visuelle entre les différents canaux au sein de chaque invite afin d'établir la reconnaissance de la marque.
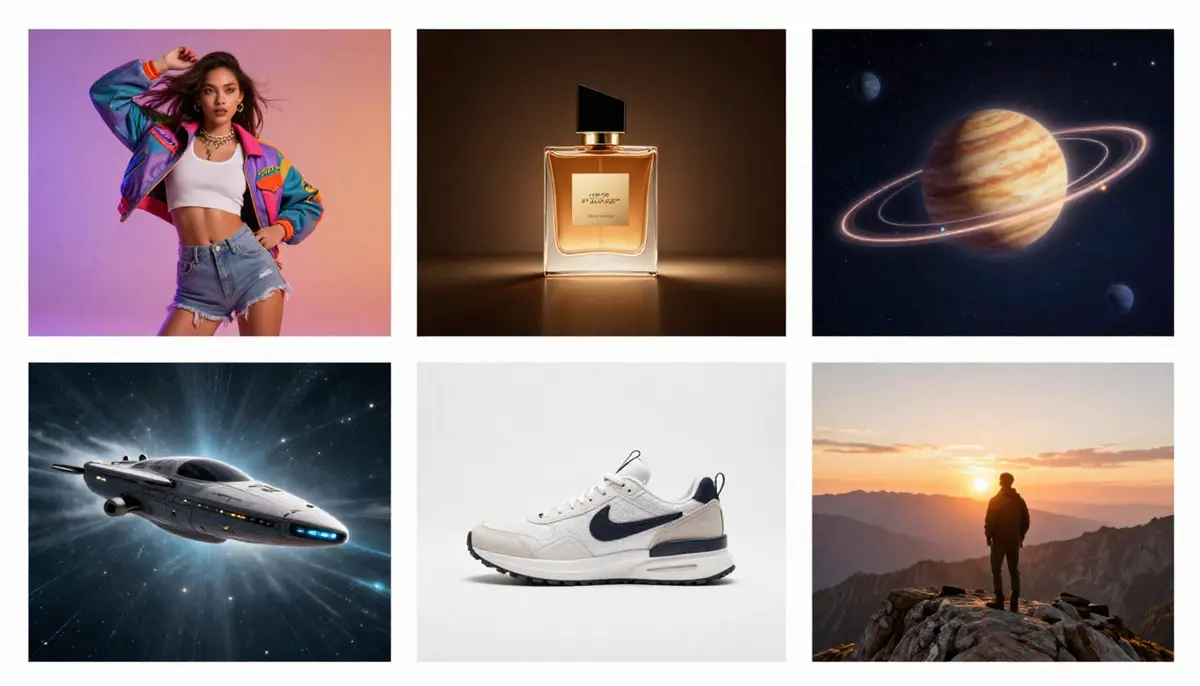
Six applications pratiques de l'IA de conversion texte-vidéo : des courts métrages sur les réseaux sociaux aux démonstrations de produits dans le commerce électronique, en passant par la visualisation de concepts éducatifs.
Texte-vidéo ou image-vidéo : quand utiliser l'un ou l'autre ?
C'est l'une des questions les plus fréquemment posées par les nouveaux utilisateurs. La réponse dépend des matériaux dont vous disposez et de vos besoins.

Deux voies vers la vidéo IA : la génération texte-vidéo part du texte, tandis que la génération image-vidéo commence à partir de photographies existantes.
Scénarios pour Text-to-Video (T2V) :
- Vous créez un contenu entièrement nouveau (sans images de référence)
- Vous souhaitez bénéficier d'une liberté créative maximale
- Vous menez une exploration conceptuelle ou un brainstorming visuel
- Vous avez besoin de scènes abstraites ou impossibles à photographier (science-fiction, fantastique, microscopique/macroscopique)
- Vous souhaitez itérer rapidement : changer une invite produit une scène complètement différente
Scénarios pour générer des vidéos à partir d'images (I2V) :
- Vous possédez une photographie spécifique nécessitant une transformation dynamique
- Vous avez besoin d'un résultat correspondant précisément aux effets visuels existants
- Vous convertissez des images de produits en vidéos de produits
- Vous avez besoin d'une cohérence des personnages (même individu dans toutes les scènes)
- Vous souhaitez des résultats plus prévisibles et contrôlables
Meilleure pratique — Combiner les deux approches :
- Utiliser la génération de texte en vidéo pour explorer des directions créatives
- Sélectionner l'image optimale comme image de référence
- Utiliser la génération d'image en vidéo pour obtenir une version finale raffinée et contrôlable
Pour un aperçu complet du processus de génération d'images en vidéos, veuillez consulter le Guide complet sur l'IA image-vidéo.
Limites actuelles — Une évaluation honnête
L'IA de conversion texte-vidéo de 2026 est impressionnante, mais loin d'être parfaite. Vous trouverez ci-dessous les domaines dans lesquels elle excelle actuellement et ceux qui restent difficiles.
Bravo !
- Vidéos courtes (5 à 15 secondes) : qualité d'image proche des normes cinématographiques
- Scènes à sujet unique : une personne, un animal, un objet — excellents résultats
- Nature et paysages : performances élevées en matière de dynamique des fluides, d'effets météorologiques et atmosphériques
- Contenu stylisé : Animation, film noir, science-fiction : conversion de style très fiable
- Démonstrations de rotation de produits : mouvement simple des produits avec une bonne cohérence
- Mouvements de caméra : panoramique, zoom, travelling, travellings : bien contrôlés
Toujours difficile
- Mains et doigts : les doigts superflus, les gestes invraisemblables et les déformations des doigts restent courants
- Rendu du texte : le texte lisible dans les vidéos s'avère peu fiable : les lettres apparaissent déformées, les caractères déformés
- Interactions complexes entre plusieurs personnes : les poignées de main entre deux personnes, les danses à deux ou les combats présentent souvent une désorganisation des membres
- Récits prolongés (>30 secondes) : le maintien de la cohérence des scènes sur de longues périodes se dégrade
- Physique précise : Rebond précis d'une balle, versement d'eau dans des récipients spécifiques : la physique est approximative, pas exacte
- Cohérence faciale à long terme : les traits du visage peuvent subir des changements subtils entre les images, en particulier sur des durées prolongées.
Tendance de progrès
Chacune de ces limitations sera nettement améliorée d'ici 2026 par rapport à 2024. Le rythme des améliorations est exponentiel. Le rendu des mains évolue de « toujours incorrect » à « généralement précis ». La cohérence faciale passe de « dérivante après 2 secondes » à « stable pendant 10 à 15 secondes ». Le rendu du texte passe de « illisible » à « parfois lisible ». Ces problèmes devraient continuer à s'améliorer rapidement entre 2026 et 2027.
Foire aux questions
Quelle est la meilleure IA de conversion texte-vidéo pour 2026 ?
Seedance 2.0 est leader en matière de qualité d'image globale avec une résolution native 2K, une entrée quadrimodale et une génération audio intégrée. Google Veo 3 excelle dans la fusion audiovisuelle et la simulation physique. Sora 2 offre la plus longue durée de génération unique (20 secondes). Le « meilleur » choix dépend de vos besoins spécifiques : résolution, audio, durée ou prix. Les utilisateurs domestiques peuvent également envisager Keeling 3.0 (bon rapport qualité-prix, vidéos longues) et Tongyi Wanxiang (intégré à l'écosystème Alibaba).
Existe-t-il une IA gratuite permettant de convertir du texte en vidéo ?
Oui. Seedance 2.0 offre un quota quotidien gratuit sans nécessiter de carte de crédit. Pika 2.0 fournit une génération quotidienne gratuite. Ke Ling 3.0 accorde un quota d'inscription. Google Veo 3 offre des quotas gratuits via AI Studio. Conch AI fournit également un quota quotidien gratuit. Pour plus de détails, consultez Comparaison des générateurs de vidéos IA gratuits.
Quelle peut être la durée des vidéos générées par l'IA à partir d'un texte ?
La plupart des outils génèrent du contenu par tranches de 5 à 15 secondes. Sora 2 étend cette durée à un maximum de 20 secondes. Keeling 3.0 prend en charge plus de 20 secondes. Pour les contenus plus longs, plusieurs segments peuvent être générés et assemblés à l'aide d'un logiciel de montage tel que Kinevision, Premiere Pro ou DaVinci Resolve.
L'IA de conversion texte-vidéo peut-elle produire des visuels de qualité professionnelle ?
Dans un délai de 5 à 15 secondes, c'est faisable. La sortie de Seedance 2.0 et Veo 3 est souvent impossible à distinguer des images professionnelles dans les clips courts. Pour les projets plus longs, la vidéo IA est mieux utilisée comme composante du matériel (b-roll, plans de transition, effets visuels) plutôt que comme l'intégralité de la production.
Comment créer des invites efficaces pour la génération de texte en vidéo ?
Suivez la formule suivante : sujet + action + décor + style + cadrage + éclairage. Les descriptions des mouvements doivent être précises, les mouvements de caméra clairement définis et l'atmosphère clairement établie. Évitez les contradictions et abstenez-vous de demander des éléments de texte/interface utilisateur. Procédez par itérations progressives, du plus simple au plus complexe. Pour plus de détails, consultez le Guide de rédaction de prompts.
Qu'est-ce qui est le plus performant : la génération de vidéos à partir de texte ou à partir d'images ?
Différentes applications. La conversion texte-vidéo offre une liberté créative maximale lorsqu'aucun matériel de référence n'est disponible. La conversion image-vidéo offre un meilleur contrôle lorsqu'il existe un point de départ visuel spécifique. La plupart des professionnels utilisent les deux approches : la conversion texte-vidéo pour le travail exploratoire et la conversion image-vidéo pour le perfectionnement.
Les vidéos générées par IA peuvent-elles être utilisées à des fins commerciales ?
La plupart des formules payantes accordent des droits commerciaux. La version payante de Seedance 2.0 inclut tous les droits commerciaux et ne comporte aucun filigrane. Les conditions d'utilisation varient selon les plateformes ; veuillez vérifier les politiques spécifiques avant utilisation. En Chine, l'utilisation commerciale de contenus générés par l'IA ne fait actuellement l'objet d'aucune restriction réglementaire explicite, mais il est conseillé de suivre les mises à jour des mesures provisoires relatives à l'administration des services d'intelligence artificielle générative.
La génération de vidéos à partir de textes alimentée par l'IA remplacera-t-elle les monteurs vidéo ?
Elle ne remplacera pas les rôles, mais les transformera. L'IA gère la génération de contenu, en créant des ressources visuelles originales à partir de descriptions. Les éditeurs humains gèrent le récit, le rythme, la résonance émotionnelle, la cohérence de la marque et les décisions créatives qui nécessitent un jugement humain. D'ici 2026, le flux de travail le plus efficace sera la génération par l'IA + l'édition humaine.
Commencez à créer des vidéos avec du texte
D'ici 2026, l'IA de conversion de texte en vidéo sera prête pour des applications professionnelles. Après avoir évolué en seulement quatre ans, passant d'expériences GAN floues à des résultats DiT quasi cinématographiques, cette technologie est désormais capable de traiter des contenus destinés aux réseaux sociaux, des démonstrations de produits, des visualisations éducatives et des explorations créatives.
La meilleure façon d'apprendre est de commencer à générer. Écrivez une invite, observez les résultats et répétez l'opération.
Transformez votre premier paragraphe en vidéo – essayez Seedance gratuitement →
Vous recherchez une plus grande précision de contrôle ? Essayez la génération d'images en vidéo →
Vous souhaitez approfondir vos connaissances sur les techniques de prompt ? Lisez notre guide de rédaction de prompts →
