
En bref
La manière la plus efficace de créer des vidéos IA n'est pas simplement d'entrer une description dans des outils de conversion texte-vidéo. Il faut plutôt commencer par une image soigneusement préparée.
Le pipeline en trois étapes — invite → image → vidéo — donne des résultats bien supérieurs à ceux obtenus avec la seule génération de texte en vidéo. Commencez par rédiger une invite de qualité professionnelle. Utilisez cette invite pour générer une image avec une composition précise. Ensuite, introduisez cette image comme première image dans un générateur de vidéo. Résultat : vous obtenez un contrôle précis sur le contenu visuel, l'ambiance lumineuse, les détails de composition et le point de départ du mouvement.
Seedance est le seul outil qui intègre les trois étapes au sein d'une seule plateforme : le générateur d'images vous aide à créer des invites professionnelles, Text-to-Image génère des images de référence de haute qualité et Image-to-Video transforme les images en clips vidéo cinématographiques. Pas besoin de changer d'outil, pas besoin de télécharger et de recharger : de l'inspiration à la pièce finie, tout se fait en un seul flux continu.
Étape 1 : Générer une invite → | Étape 2 : Générer une image → | Étape 3 : Générer une vidéo →

À gauche : génération pure de texte en vidéo — composition aléatoire, visuels incontrôlables. À droite : pipeline axé sur l'image — affiner d'abord les visuels, puis ajouter du mouvement ; composition précise, qualité constante.
Pourquoi « l'image d'abord, la vidéo ensuite » surpasse largement la conversion texte-vidéo
Ceux qui ont déjà utilisé Wensheng Video connaissent bien cette expérience : vous rédigez une description détaillée (sujet, éclairage, angle de caméra et composition), mais les images générées par l'IA ne correspondent en rien à votre vision. Les personnages sont tournés dans la mauvaise direction, l'éclairage est plat, les compositions semblent générées au hasard et les rôles ne correspondent pas à la description.
Il ne s'agit pas d'un défaut propre à un outil particulier, mais plutôt d'une limitation structurelle inhérente à l'approche texte-vidéo.
Les limites inhérentes à la création de contenu vidéo
Wensheng Video exige que l'IA accomplisse simultanément deux tâches extrêmement difficiles : générer des images et générer des mouvements. Le modèle doit interpréter votre texte, déterminer l'apparence de chaque pixel, composer la scène, régler l'éclairage et les ombres, établir la position de la caméra, puis générer un mouvement cohérent à partir de tout cela, le tout à partir d'un seul texte.
Il en résulte que chaque dimension échappe à tout contrôle :
- Composition aléatoire. Vous écrivez « une femme debout au milieu de la rue », mais elle se retrouve dans le tiers gauche, avec la moitié du cadre dominé par des bâtiments inutiles.
- **Personnages incohérents. ** La structure du visage, les vêtements, la coiffure et les proportions du corps varient d'une génération à l'autre. L'IA fournit des « interprétations créatives », et non vos spécifications.
- **Éclairage incontrôlé. ** Même en spécifiant « heure dorée, éclairage latéral chaud depuis la gauche », les résultats sont extrêmement incohérents. L'interprétation des descriptions d'éclairage par l'IA reste fondamentalement vague.
- Cadrage peu fiable. Gros plans, plans moyens, plans d'ensemble : les outils de conversion texte-vidéo interprètent ces termes avec une extrême instabilité. Demandez un gros plan extrême, et vous obtiendrez un plan d'ensemble.
Pour les expériences créatives exploratoires, cette incertitude peut faire partie du plaisir. Mais si vous avez besoin d'un résultat professionnel contrôlé et fiable, cela devient un défaut fatal.
L'avantage principal de la priorité à l'image
TuSheng Video a complètement inversé cette équation. Vous n'avez plus besoin que l'IA génère simultanément les visuels et le mouvement ; au lieu de cela, vous séparer les deux tâches :
- Commencez par l'image. Sujet, composition, éclairage, couleur, cadrage : vous avez le contrôle total et pouvez répéter l'opération jusqu'à obtenir la perfection.
- Ajoutez ensuite du mouvement. La seule tâche de l'IA est d'animer votre cadre parfait. Elle n'a pas besoin de déchiffrer des descriptions vagues ni de prendre des décisions en matière de composition ; elle génère plutôt du mouvement à partir de vos repères visuels concrets.
Cette séparation des objectifs donne des résultats supérieurs dans tous les domaines :
- Composition verrouillée. Le sujet reste exactement là où vous l'avez placé.
- Cohérence des personnages. Les traits du visage, les vêtements et les proportions restent identiques à ceux de l'image source.
- **Éclairage et ombres préservés. ** La direction de la lumière, la texture et la température de couleur sont entièrement héritées de l'image.
- Cadrage fixe. La position de la caméra et le point de vue restent cohérents avec la configuration d'origine de l'image.
Pour illustrer cela : la conversion texte-vidéo s'apparente à la description d'une scène de film au téléphone et à la demande faite à quelqu'un de la filmer. La conversion image-vidéo, en revanche, revient à montrer une photographie à quelqu'un et à lui dire : « Donnez vie à cette image ». Cette dernière approche donne des résultats plus contrôlables et de meilleure qualité, car l'IA reçoit des références visuelles concrètes plutôt que des descriptions textuelles abstraites.
L'effet multiplicateur de la qualité
Les avantages sont cumulatifs. Un cadre d'ouverture soigneusement conçu améliore tous les aspects de la vidéo :
- Cohérence temporelle améliorée — Le modèle dispose d'ancrages visuels de haute qualité pour maintenir la cohérence tout au long de la séquence.
- Qualité de mouvement améliorée — Le modèle extrait avec précision les informations de profondeur, d'éclairage et d'espace à partir d'images sources claires.
- Cohérence stylistique améliorée — Les systèmes de couleurs, les ambiances et l'esthétique sont directement intégrés dans les images, ne laissant aucune place à l'interprétation textuelle.
- Taux d'imperfection réduit — Le modèle commence avec des données visuelles propres et haute résolution plutôt que de tout synthétiser à partir du bruit.
Les vidéos générées à partir d'une première image de haute qualité démontrent une supériorité significative par rapport aux vidéos générées uniquement à partir de texte avec des invites identiques en termes de qualité visuelle, de continuité temporelle et d'attrait esthétique. Il ne s'agit pas d'une distinction subtile, mais d'un fossé entre les « démonstrations divertissantes de l'IA » et le « contenu utilisable par des professionnels ».
Pour en savoir plus sur la conception d'images spécialement destinées à la génération de vidéos, consultez le Guide de conception des premières et dernières images.
Pipeline créatif IA en trois étapes
Le processus complet est divisé en trois étapes, chacune s'appuyant sur la précédente. Toute étape traitée avec négligence compromettra au final le résultat final. Il est essentiel de comprendre l'importance de chaque étape et où investir son temps pour produire de manière constante des vidéos IA de haute qualité.
Phase 1 : Génération rapide
Tout commence par la consigne. Consignes médiocres → images médiocres → vidéos médiocres. Consignes exceptionnelles → images époustouflantes → vidéos époustouflantes. La qualité de la consigne est la variable la plus importante dans la qualité du résultat final, et c'est aussi l'étape dans laquelle on investit le moins dans la plupart des flux de travail.
Le problème avec la rédaction manuelle des invites. La plupart des gens abordent la rédaction d'invites comme s'il s'agissait de créer des mots-clés de recherche : brèves, vagues et axées uniquement sur le sujet. « Une montre de luxe, fond sombre. » Cela indique à l'IA ce qu'elle doit dessiner, mais ne lui dit pas comment le dessiner. Le modèle remplit les blancs avec des valeurs par défaut : éclairage plat, composition centrée, aucun détail atmosphérique, aucune direction stylistique.
Solution : génération de prompts assistée par l'IA. Le générateur de prompts développe vos idées générales en prompts professionnels couvrant le sujet, l'environnement, l'éclairage, la couleur, la composition, le style et les améliorations de la qualité de l'image. La différence de qualité entre un prompt manuel de 10 mots et un prompt généré de 100 mots représente un bond qualitatif.
C'est exactement ce que fait le [générateur d'images par prompt] (/image-prompt-generator) de Seedance. Entrez une brève description telle que « publicité pour une montre de luxe, sombre et dramatique », sélectionnez un style (photoréaliste, cinématographique, illustratif, etc.), et l'IA génère instantanément un prompt professionnel complet. L'ensemble du processus ne prend que quelques secondes et coûte 2 crédits par prompt. Pour un guide complet sur la génération de suggestions, consultez le Guide du générateur de suggestions d'images IA.
Pourquoi cette étape est-elle si cruciale ? La consigne est l'ADN de l'ensemble de votre pipeline. Elle dicte le style, l'ambiance, la composition et le niveau de qualité de tout ce qui suit. Passer cinq minutes à peaufiner votre consigne avant de générer des images peut vous faire gagner trente minutes de retouches itératives sur des résultats médiocres par la suite.
Deuxième étape : génération d'images
Une fois que tu as reçu les instructions professionnelles, l'étape suivante consiste à créer l'image qui servira de cadre d'ouverture à la vidéo. C'est là que tu passes du texte aux visuels, ce qui marque l'étape où tu devrais consacrer le plus de temps à l'itération.
De l'invite à l'image. Collez l'invite générée dans l'outil de conversion texte-image et cliquez sur « Générer ». Évaluez le résultat : la composition est-elle adaptée à la vidéo ? L'éclairage est-il suffisamment nuancé ? Le sujet semble-t-il correct ? La scène donne-t-elle une impression de profondeur ?
Si vous disposez déjà d'une image de référence ou souhaitez affiner les résultats de génération existants, image-to-image est l'outil qu'il vous faut. Téléchargez votre image existante et décrivez les modifications souhaitées. Cet outil s'avère particulièrement puissant pour les itérations de composition : ajustez l'éclairage, ajoutez des effets atmosphériques ou modifiez le contenu de la scène sans repartir de zéro. Pour obtenir un guide complet sur le flux de travail Image-to-Image, consultez le Guide AI Image-to-Image.
Concevez des images destinées à être utilisées dans des vidéos. Toutes les images visuellement attrayantes ne constituent pas nécessairement un cadre d'ouverture adapté à une vidéo. Lorsque vous générez des images destinées à être utilisées dans un pipeline, gardez à l'esprit les principes de composition suivants :
- Laissez un espace négatif dans le sens du mouvement. Si un personnage se déplace de gauche à droite, placez-le légèrement vers la droite du cadre.
- Incluez des niveaux de profondeur. Les images avec des éléments distincts au premier plan, au milieu et à l'arrière-plan créent de meilleurs effets de parallaxe et des mouvements de caméra plus naturels dans la vidéo.
- **Tenez compte de la direction du mouvement de la caméra. ** Si vous prévoyez d'utiliser un mouvement « push », assurez-vous que la composition est bonne à la fois dans le cadrage actuel et dans un cadrage plus serré centré sur le sujet.
- Évitez les grands blocs de texte ou les motifs symétriques. Ces éléments sont difficiles à animer naturellement et peuvent facilement produire des artefacts.
- **Utilisez un éclairage directionnel. ** Un éclairage directionnel puissant avec des ombres visibles produit un effet vidéo plus cinématographique qu'un éclairage plat.
Principe fondamental : consacrez du temps à peaufiner vos images. Chaque minute passée à perfectionner vos visuels vous en fera gagner plusieurs lors de la phase de génération de la vidéo. Une première image parfaite signifie que votre vidéo est utilisable dès le premier essai. Une première image imparfaite peut nécessiter plusieurs régénérations (chacune consommant des crédits et du temps) sans garantir un résultat satisfaisant.
Avant de commencer la génération de la vidéo, parcourez les images 3 à 5 fois. Il ne s'agit pas de perfectionnisme, mais d'efficacité.
Pour un guide complet sur la génération de texte en image (y compris les techniques de prompt et les comparaisons d'outils), consultez Le guide complet sur l'IA de texte en image. Pour un aperçu des meilleurs outils de génération d'images, consultez Les meilleurs générateurs d'images IA pour 2026.
Générer votre image → | Affiner l'image →
Troisième étape : génération de vidéos
C'est à ce stade que vous récoltez les fruits de votre travail. Les images peaufinées que vous avez affinées constituent le point de départ de vos clips vidéo animés.
Téléchargez une image comme première image. Téléchargez votre image générée dans l'outil [Image-to-Video] de Seedance. L'outil récupère les images directement depuis votre historique de génération, sans qu'il soit nécessaire de les télécharger et de les re-télécharger.
Accompagnez le mouvement avec des mots. Écrivez une description du mouvement que vous souhaitez obtenir, sans décrire les éléments visuels (l'image a déjà été traitée). Concentrez-vous sur :
- Mouvement de caméra : « lent travelling avant » 、panoramique doux vers la gauche、orbite fluide autour du sujet
- Action du sujet : « la femme tourne lentement la tête »、les pétales tombent vers le bas、de la vapeur s'élève de la tasse
- Mouvement de l'environnement : « les nuages se déplacent lentement », « l'eau ondule vers l'extérieur », « les feuilles se balancent doucement dans la brise »
- ** Ambiance** : « atmosphère dramatique », « qualité onirique et éthérée », « rythme cinématographique »
Générez et révisez. L'IA reçoit vos instructions relatives à l'image et au mouvement, puis produit des segments vidéo qui commencent précisément à partir de votre première image et se déroulent selon vos instructions de mouvement. Comme vous contrôlez le point de départ visuel, le résultat est prévisible et cohérent. La qualité vidéo hérite de la qualité de l'image : une première image claire, bien éclairée et composée avec précision se traduit directement par une vidéo claire, bien éclairée et composée avec précision.
Pour les techniques avancées de contrôle du mouvement et l'appariement de la première et de la dernière image, veuillez vous reporter au Guide de conception de la première et de la dernière image. Pour une introduction complète à l'IA Image-to-Video, consultez le Guide de l'IA Image-to-Video.
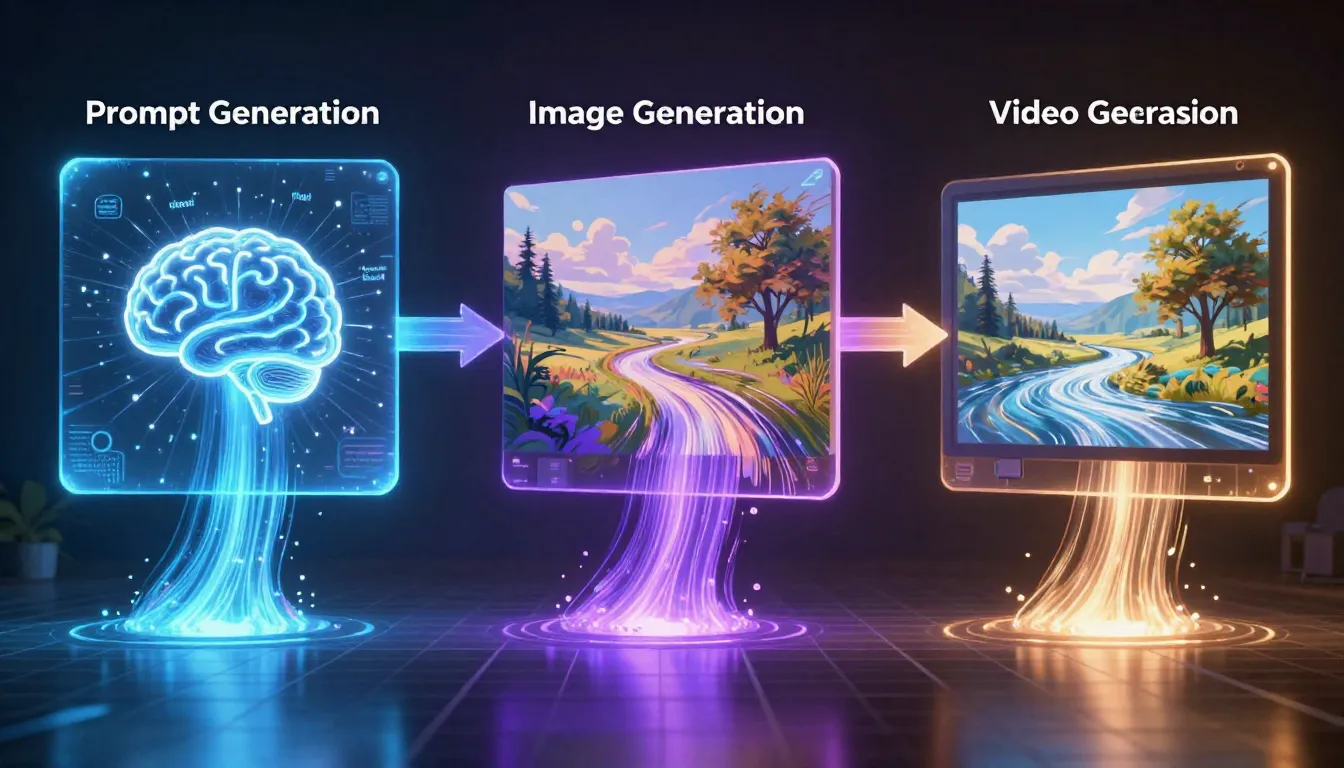
Pipeline en trois étapes en action : transformer de brèves descriptions en invites professionnelles, transformer les invites en images de haute qualité, et convertir les images en vidéos dynamiques. Chaque étape amplifie la qualité de la précédente.
Avantage Seedance : réalisation en trois étapes, en un seul endroit
Aujourd'hui, la plupart des créateurs qui mettent en place ce pipeline assemblent trois ou quatre outils. Ils utilisent ChatGPT ou Claude pour rédiger des invites d'images, passent à Midjourney ou Tongyi Wansheng pour la génération d'images, téléchargent l'image, ouvrent Ke Ling ou Runway, puis la téléchargent pour générer une vidéo. Chaque changement implique une interface différente, des comptes différents, des systèmes de facturation différents et des contraintes différentes.
Ce flux de travail fragmenté n'est pas seulement gênant, il compromet activement la qualité.
Comment le changement d'outils compromet la qualité
Chaque fois qu'une image est transférée entre différents outils, elle subit une dégradation. Le cycle de téléchargement-chargement introduit des artefacts de compression. Les conversions de format (PNG vers JPG, WebP vers PNG) modifient les valeurs chromatiques. La résolution peut être rééchantillonnée. Les métadonnées relatives à la manière dont l'image a été générée, informations qui auraient pu aider le modèle vidéo à produire des résultats supérieurs, sont entièrement supprimées.
Au-delà de la qualité des données, il y a aussi la charge cognitive. Chaque outil a sa propre syntaxe de commande, des paramètres de sortie distincts et des options de rapport d'aspect variables. Vous perdez du temps à vous familiariser à nouveau avec les interfaces au lieu de le consacrer à des itérations créatives.
Tuyauterie intégrée
Seedance élimine toutes ces frictions en proposant les trois étapes au sein d'une seule et même plateforme :
1. Générateur de suggestions d'images (/image-prompt-generator). Saisissez votre concept créatif, sélectionnez l'un des 12 styles proposés et obtenez une suggestion professionnelle complète. Les suggestions générées sont optimisées pour le modèle de génération d'images Seedance, mais conviennent également à tout outil de peinture IA.
2. Texte-image et image-image (/text-to-image | /image-to-image). Générez des images à partir de suggestions ou apportez des modifications ciblées à des images existantes. Produisez rapidement plusieurs variantes. Une fois que vous avez trouvé la bonne composition, vous pouvez passer directement à l'étape suivante.
- Image vers vidéo Sélectionnez n'importe quelle image pré-générée dans votre bibliothèque et envoyez-la directement au générateur de vidéo. Aucun téléchargement, aucun transfert, aucune conversion de format n'est nécessaire. Les images en pleine résolution sont transférées sans perte.
Pourquoi l'intégration donne-t-elle des résultats supérieurs ?
Il ne s'agit pas seulement d'une fonctionnalité pratique ; l'intégration produit véritablement des résultats supérieurs :
- Aucune perte de transmission. Les images sont transférées en pleine résolution entre les étapes, sans compression ni rééchantillonnage.
- Écosystème de modèles cohérent. Les modèles de génération d'images et de vidéos sont calibrés pour une compatibilité inhérente. Les images produites par le modèle texte-image de Seedance sont intrinsèquement adaptées au modèle vidéo de Seedance.
- **Système de crédits unifié. ** Pas besoin de souscrire trois abonnements distincts. Vos crédits sont universels pour les trois outils, ce qui rend l'allocation budgétaire simple et transparente.
- Cycles d'itération plus rapides. Le temps entre « Je veux modifier cette image » et « Je regarde la nouvelle vidéo » passe de plusieurs minutes passées à changer d'outil à quelques secondes grâce à une intégration transparente.
- **Maintenez votre flux créatif. ** Restez dans une seule interface pour préserver le contexte de votre réflexion. Concentrez-vous sur le concept créatif lui-même, et non sur la gestion des fichiers ou la navigation entre les outils.
Pour être franc, vous pouvez très bien utiliser ChatGPT pour rédiger des invites, Midjourney ou Tongyi Wansheng pour générer des images, et Keling ou Runway pour créer des vidéos afin de mettre en place un pipeline de haute qualité. C'est précisément ce que font de nombreux professionnels. L'avantage de Seedance ne réside pas dans le fait qu'une étape particulière surpasse largement ses concurrents, mais dans son intégration qui élimine les frictions qui poussent la plupart des créateurs à abandonner le processus en cours de route. Le meilleur flux de travail est celui que vous menez à bien du début à la fin.
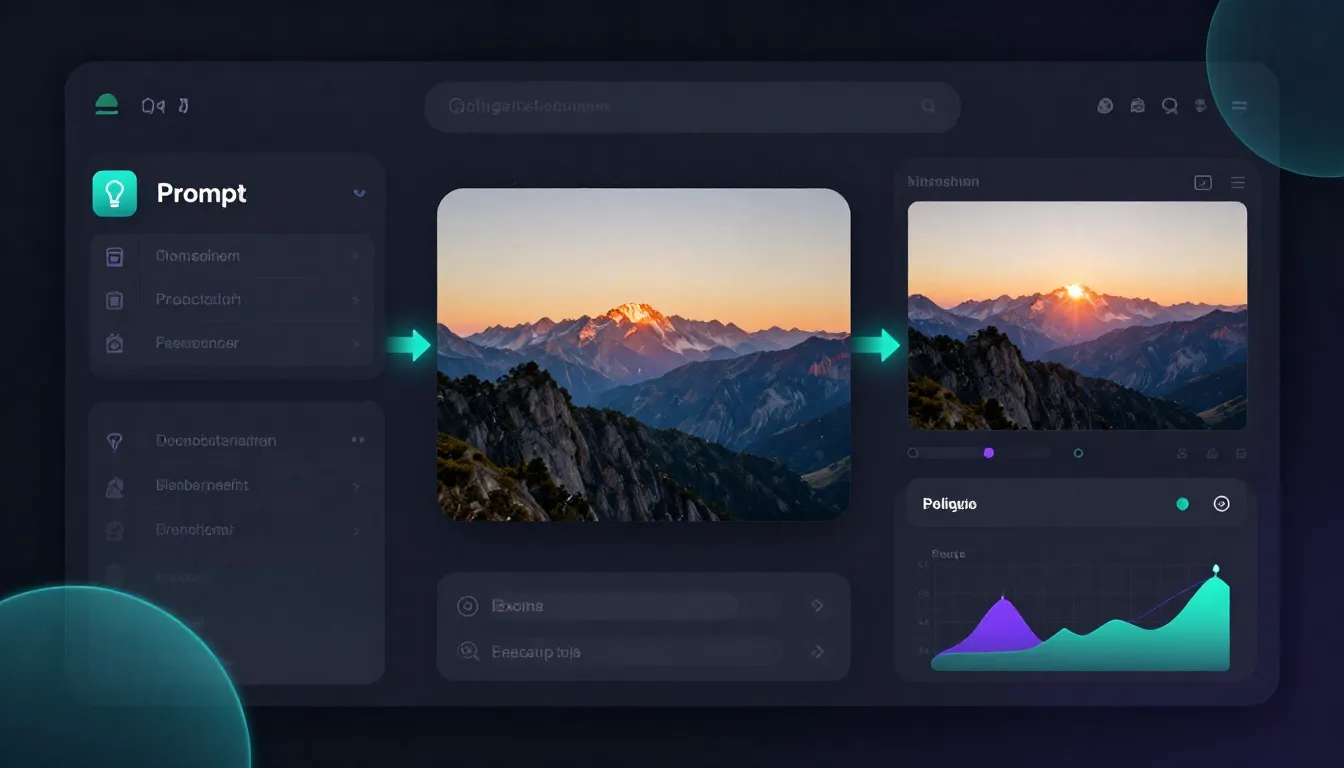
Seedance intègre la génération de prompts, la génération d'images et la génération de vidéos dans une seule et même plateforme. De la conception à la vidéo finale, il n'est pas nécessaire de changer d'outil, de télécharger des fichiers ou de gérer plusieurs comptes.
Guide pratique complet : 3 études de cas concrets
La théorie est utile, mais c'est la pratique qui donne des résultats. Vous trouverez ci-dessous trois exercices complets, chacun correspondant à des objectifs créatifs différents, des styles distincts et des formats variés. Suivez-les pour créer votre premier pipeline complet.
Cas n° 1 : publicité cinématographique pour un produit
Objectif : Produire une publicité de cinq secondes pour une montre de luxe destinée à la page de présentation du produit.
Phase 1 — Génération rapide
Ouvrez le générateur d'invites d'image et saisissez votre concept.
Entrée : « publicité pour une montre de luxe, sombre et dramatique »
Sélectionnez le style : Photoréaliste
Invite générée :
A luxury men's wristwatch resting on a slab of dark emperador marble,
shot from a low three-quarter angle. Dramatic studio lighting: a single
hard key light from the upper left creates sharp reflections on the
polished steel case and sapphire crystal. The watch face shows 10:10
with luminous indices glowing faintly. Deep shadows pool around the
base, enhancing the sense of weight and prestige. Background is pure
black, fading to subtle charcoal gradient. Microscopic dust particles
float in the key light beam. Color palette: silver, deep charcoal,
amber highlights from the lume. Photorealistic product photography,
8K resolution, razor-sharp detail on every dial marking and link.La création manuelle de cette invite prendrait au moins 10 à 15 minutes. Un générateur d'invites le fait en quelques secondes, en couvrant les sept dimensions des invites professionnelles : sujet, environnement, éclairage, couleur, composition, style et qualité d'image.
Deuxième étape — Génération d'images
Collez l'invite générée dans text-to-image. Générez avec un format d'image 16:9 pour s'adapter aux cadres vidéo paysage.
Premier rendu : la composition générale est bonne, mais la surface en marbre réfléchit un peu trop, détournant l'attention de la montre.
Itération : Affinez le résultat à l'aide de Image-to-Image. Téléchargez l'image générée initialement avec l'instruction suivante : « Réduisez l'intensité du reflet de la surface du marbre. Augmentez la netteté des détails du cadran de la montre. Rendez le dégradé de l'arrière-plan légèrement plus profond. »
Deuxième prise : la montre occupe le devant de la scène, baignée d'une lumière et d'ombres spectaculaires, avec une composition en couches. Prêt à passer à la phase vidéo.
Troisième étape — Génération vidéo
Envoyez les images retouchées à Image-to-Video.
Consignes d'exercice :
The camera executes a slow, smooth orbiting movement around the watch,
revealing different angles of the case and bracelet. The key light
shifts subtly as the camera moves, creating dynamic reflections across
the polished surfaces. Dust particles drift slowly through the light
beam. Cinematic, premium commercial pacing. Steady, professional
camera movement.(La caméra effectue un panoramique lent et régulier autour de la montre, révélant différents angles du boîtier et du bracelet. Au fur et à mesure que la prise de vue se déplace, la source lumineuse principale change subtilement, créant des reflets dynamiques sur les surfaces polies. Des particules de poussière flottent doucement dans le faisceau lumineux. Rythme cinématographique, publicité haut de gamme. Mouvement de caméra régulier et professionnel.)
Livrables : une présentation soignée du produit de 5 secondes, commençant par votre image méticuleusement composée, tournant en douceur autour de la montre. Un éclairage spectaculaire, des détails nets et des textures haut de gamme sont reproduits de manière homogène depuis l'image source jusqu'à chaque image de la vidéo.

Cas n° 1 : publicité pour une montre de luxe. D'un brief conceptuel en cinq mots à une vidéo produit raffinée de cinq secondes : un processus en trois étapes pour un résultat de qualité commerciale.
Cas n° 2 : Contenu lié aux voyages sur les réseaux sociaux
Objectif : Produire une vidéo verticale capturant le lever du soleil dans un sanctuaire japonais pour TikTok/Instagram Reels.
Phase 1 — Génération rapide
Ouvrez le générateur d'invites d'image.
Entrée : « Lever du soleil dans un temple japonais, matin paisible »
Sélectionnez le style : Photoréaliste
Invite générée :
A traditional Japanese wooden temple (Kiyomizu-dera style) nestled
among ancient cedar trees, photographed at dawn. Golden sunrise light
filters through morning mist, casting long warm shadows across the
temple's wooden veranda. Cherry blossom branches frame the upper
portion of the composition, with delicate pink petals catching the
first light. A stone lantern stands in the foreground left, moss-
covered and weathered. The temple roof's curved eaves are silhouetted
against a sky transitioning from deep indigo to warm peach and gold.
Subtle mist hovers at ground level among the trees. Photorealistic
landscape photography, golden hour lighting, serene and contemplative
atmosphere, high dynamic range, rich natural color palette.Deuxième étape — Génération d'images
Collez dans Text-to-Image. Paramètres clés : Générer dans un format portrait 9:16, adapté à TikTok et Instagram Reels.
Première ébauche : L'atmosphère est magnifique, mais les branches de cerisier en fleurs sont placées trop haut dans le cadre, laissant un espace vide excessif dans le tiers inférieur.
Itération : Après avoir légèrement modifié l'invite et ajouté la description « branches de cerisiers en fleurs s'étendant depuis les coins supérieurs droit et gauche, remplissant le tiers supérieur du cadre vertical », la deuxième génération a parfaitement positionné les fleurs de cerisier pour former un cadre naturel à la composition.
La composition se prête parfaitement à la vidéo verticale : le sanctuaire attire le regard vers le centre du cadre, tandis que les fleurs de cerisier en haut créent un intérêt visuel. Les lanternes en pierre et la brume au premier plan apportent de la profondeur. Ce plan offre un potentiel de mouvement sur plusieurs niveaux.
Troisième étape — Génération vidéo
Envoyer vers Image-to-Video.
Consignes d'exercice :
Gentle cherry blossom petals drift slowly downward through the frame.
Morning mist shifts and swirls at ground level among the trees. Two
birds fly across the sky in the background. The sunrise light gradually
intensifies, warming the scene. A subtle breeze moves the cherry
blossom branches slightly. Peaceful, meditative atmosphere. Slow,
contemplative pacing.Des pétales de fleurs de cerisier flottent doucement dans le cadre. La brume matinale s'étend doucement sur le sol entre les arbres. Deux oiseaux glissent dans le ciel en arrière-plan. La lumière du lever du soleil s'intensifie progressivement, réchauffant toute la scène. Une brise légère agite les branches de cerisier en fleurs. Une atmosphère tranquille et méditative. Un rythme lent et contemplatif.
Résultats attendus : une vidéo verticale atmosphérique de 4 secondes, parfaitement adaptée à TikTok et Instagram Reels. Les fleurs de cerisier flottent naturellement, tandis que la brume matinale ajoute de la profondeur et du mouvement. Les oiseaux en arrière-plan créent des points focaux subtils. Les tons chauds et dorés de l'image source imprègnent chaque image de la vidéo.
Étude de cas n° 3 : Récit de marque – Associer la première et la dernière image
Objectif : Produire un récit de marque de six secondes illustrant la transformation du café, passant du calme du petit matin à l'effervescence d'une salle comble.
Dans ce cas, le pipeline est utilisé deux fois, générant une paire d'images comprenant la première et la dernière image afin de fournir au modèle vidéo deux repères visuels pour définir l'arc narratif. Pour une analyse approfondie de cette technique, veuillez vous reporter au Guide de conception de la première et de la dernière image.
Phase 1 — Deux invites
Générez deux séries de suggestions à partir du générateur de suggestions d'images.
Première image : « Un café vide, baigné par la lumière du petit matin, avec des tons ambrés chaleureux. »
Invite générée pour la première image :
Interior of an artisanal coffee shop in the early morning, before
opening. Warm amber sunlight streams through large front windows,
casting long golden rectangles across worn hardwood floors. Exposed
brick walls, a polished wooden counter with a brass espresso machine,
and empty mismatched chairs around small tables. A chalkboard menu
hangs behind the counter. Dust motes float in the sunbeams. The space
feels warm, inviting, and full of potential. Shot at eye level from
just inside the entrance. Photorealistic interior photography, warm
color palette, golden hour tones, cozy atmosphere.Image finale : « Un café animé par une matinée chaude, où les clients dégustent leur café. »
Invite de la dernière image générée :
The same artisanal coffee shop, now alive with morning activity.
Diverse customers sit at tables -- some reading, some talking, some
working on laptops. A barista behind the counter steams milk, creating
a plume of white steam. Coffee cups and pastries fill the tables. Warm
morning light still streams through the windows but is supplemented by
the warm glow of pendant lights. The atmosphere is bustling but cozy,
full of quiet energy and the warmth of community. Shot from the same
eye-level position just inside the entrance. Photorealistic interior
photography, warm tones, lively atmosphere.Deuxième étape — Deux images
Générez la première image dans text-to-image avec un format 16:9. Répétez l'opération jusqu'à ce que le café vide semble chaleureux et accueillant, baigné par la lumière dorée du matin.
La dernière image utilise la génération [image-à-image]. Téléchargez l'image initiale comme image de référence et utilisez l'invite de la dernière image. Cette étape est cruciale : l'utilisation de l'image initiale comme référence garantit la cohérence visuelle. L'architecture, l'ameublement, la direction de l'éclairage et les combinaisons de couleurs restent cohérents d'une image à l'autre, la seule addition étant l'inclusion de personnages et d'activités.
Répétez l'opération sur l'image finale pour vous assurer que le client semble naturel et que le barista est bien placé derrière le comptoir. Point crucial : les deux images doivent donner l'impression d'avoir été prises au même endroit à des moments différents, et non à deux endroits distincts.
Troisième étape — Génération vidéo
Téléchargez la première image sur Image-to-Video. Sur les plateformes prenant en charge la référence à la dernière image, téléchargez simultanément la dernière image.
Consignes d'exercice :
Time-lapse style transition. The empty coffee shop gradually fills
with people arriving -- customers entering, sitting down, a barista
beginning to work. Morning light shifts slowly. The scene transitions
from quiet solitude to warm, bustling community. Smooth, cinematic
pacing. The camera position remains fixed.(Transition de type time-lapse. Un café vide se remplit progressivement de clients qui arrivent : ils entrent, s'assoient et le barista commence à travailler. La lumière du matin change subtilement. La scène évolue d'une solitude tranquille à une atmosphère chaleureuse et animée. Rythme fluide, cinématographique. La caméra reste fixe.)
Résultat : Une histoire de marque de six secondes dévoile un arc narratif complet : le réveil d'un café. Le premier plan établit un espace tranquille et accueillant. Le dernier plan présente l'état souhaité. Des transitions générées par l'IA font le lien entre les deux : les portes s'ouvrent, les clients prennent place, les baristas activent les machines à expresso et les tasses à café apparaissent sur les tables. Le message de la marque est discret mais puissant : c'est un endroit où l'on se sent chez soi.

Cas n° 3 : récit de marque associant les images d'ouverture et de clôture. L'IA génère une transition en accéléré entre deux repères visuels : du calme de l'aube à la chaleur de la communauté.
Techniques d'optimisation des pipelines
Après avoir produit des centaines de vidéos grâce à ce processus, les cinq principes suivants ont eu le plus grand impact sur la qualité du résultat.
Astuce n° 1 : consacrez 80 % de votre temps aux images
Il s'agit là de l'optimisation la plus cruciale. La qualité de l'image est le goulot d'étranglement tout au long du processus. Une image parfaite donnera une vidéo utilisable dès la première génération. Une image médiocre, même si les mouvements sont parfaitement réalisés, ne produira qu'une vidéo médiocre.
La répartition du temps devrait être approximativement la suivante :
- Génération rapide : 5 % (le générateur prend quelques secondes, l'écriture manuscrite prend plusieurs minutes)
- Génération et itération d'images : 80 % (générer, évaluer, affiner, régénérer jusqu'à ce que la scène soit parfaite)
- Génération de vidéos : 15 % (télécharger, écrire des invites de mouvement, générer)
La plupart des novices inversent l'ordre des opérations : ils passent dix secondes sur une image, puis génèrent des vidéos les unes après les autres, dans l'espoir d'en trouver une qui leur convienne. Les utilisateurs expérimentés passent dix minutes sur une image et obtiennent une bonne vidéo dès les premières tentatives. Cette dernière approche donne de meilleurs résultats avec moins de crédits et moins de temps.
Avant de commencer la génération de la vidéo, parcourez les images trois à cinq fois. Il ne s'agit pas de perfectionnisme, mais d'efficacité.
Conseil n° 2 : Conçu pour le mouvement
Une photo agréable et une bonne image vidéo ne sont pas la même chose. Lorsque vous générez des images pour des pipelines, imaginez comment la scène apparaîtra lorsqu'elle prendra vie.
Laissez un espace négatif dans le sens du mouvement principal. Si un personnage se déplace de gauche à droite, évitez de le centrer : placez-le légèrement à droite afin de laisser de l'espace pour le mouvement. Si la caméra se déplace vers la gauche, veillez à ce que le côté gauche du cadre contienne un contenu visuellement attrayant.
Composez vos plans en fonction de la direction de la caméra. Les plans en poussée sont plus efficaces lorsque le détail le plus captivant occupe le centre du cadre. Les plans panoramiques nécessitent un intérêt visuel sur toute la largeur du cadre. Les travellings circulaires exigent des sujets tridimensionnels avec de la profondeur, plutôt que des sujets plats.
Évitez les compositions symétriques complexes. Si la symétrie parfaite peut être saisissante dans les photographies, elle pose des difficultés pour la génération de vidéos. L'IA a du mal à maintenir une symétrie précise entre les images, ce qui entraîne des tremblements gênants. Les compositions asymétriques avec un flux visuel naturel produisent des vidéos plus fluides.
Intégrez des indices de profondeur. Les images comportant des éléments superposés à différentes distances (objets au premier plan, sujets au second plan et environnements en arrière-plan) fournissent à l'IA des informations sur la profondeur, ce qui se traduit par des effets de parallaxe améliorés et des mouvements de caméra plus naturels.
Pour obtenir un guide complet sur la conception d'images spécialement destinées à la vidéo, consultez le Guide de conception des premières et dernières images.
Technique 3 : Maintenir des rapports d'aspect cohérents tout au long du processus
Les rapports d'aspect incompatibles entre les images et les trames vidéo constituent l'une des erreurs les plus courantes dans le pipeline, ce qui diminue inévitablement la qualité du résultat final.
- 16:9 pour les vidéos au format paysage (YouTube, présentations, pages d'accueil de sites web)
- 9:16 pour les vidéos au format portrait (TikTok, Instagram Reels, YouTube Shorts)
- 1:1 pour les vidéos carrées (Instagram Stories, certaines publicités sur les réseaux sociaux)
Définissez le format d'image lors de la génération de l'image plutôt que d'attendre la phase vidéo. Si vous générez une image carrée au format 1:1, puis essayez de créer une vidéo au format 16:9, le modèle vidéo devra remplir les côtés à partir de zéro, et la qualité de ce contenu généré sera inférieure à celle du reste de l'image. Générez dès le départ des images au format de la vidéo finale.
Conseil n° 4 : conservez un style cohérent tout au long des différentes étapes
Les mots-clés stylistiques dans les invites d'image et les repères de mouvement dans les invites vidéo doivent parler le même langage visuel. Toute incohérence entre les deux entraînera des problèmes de qualité subtils dans le résultat final.
Si votre suggestion d'image comprend « cinématographique, éclairage dramatique, atmosphère sombre », la suggestion de mouvement vidéo doit utiliser un langage compatible : « mouvement de caméra cinématographique, atmosphère dramatique, rythme sombre ». Évitez d'associer des images dramatiques et cinématographiques à des suggestions de mouvement telles que « ludique, rebondissant, énergique » : les conflits de ton confondront le modèle et réduiront la cohérence.
Référence rapide — Tableau de correspondance des styles :
| Style d'image | Langage de commande de mouvement adapté |
|---|---|
| Cinématographique, dramatique | « Mouvement de caméra cinématographique, rythme dramatique, lent et délibéré » |
| Lumineux, commercial, épuré | « Mouvement fluide et professionnel, rythme régulier, transitions épurées » |
| Rêveur, éthéré, doux | « Mouvement doux et flottant, atmosphère rêveuse, dérive lente » |
| Énergique, dynamique | « Mouvement de caméra dynamique, rythme énergique, montages rapides » |
| Documentaire, naturel | « Sensation de caméra à main, mouvement naturel, rythme d'observation » |
Astuce n° 5 : enregistrez vos meilleurs modèles de pipeline
Lorsqu'un pipeline prompt → image → vidéo donne des résultats satisfaisants, enregistrez l'intégralité du pipeline :
- Invite d'image (texte original)
- Paramètres de style sélectionnés
- Paramètres de génération d'image (format d'image, modèle, nombre de graines, etc.)
- Invite de mouvement vidéo
- Paramètres de génération vidéo (durée, résolution)
Ce pipeline sert de modèle. Vous avez besoin de créer des vidéos similaires pour différents produits ? Remplacez le sujet dans l'invite d'image et régénérez. Vous avez besoin de scènes différentes dans le même style ? Conservez les mots-clés de style et remplacez la description du sujet.
Au fil du temps, vous constituerez une bibliothèque complète de pipelines adaptés à différents objectifs créatifs : publicités pour des produits, contenu pour les réseaux sociaux, récits de marque, B-roll pour films, animation de personnages. Chaque nouveau projet part d'une base éprouvée plutôt que d'être créé à partir de zéro.
Comparaison des différents outils à chaque étape
Seedance fournit un pipeline intégré, mais vous pouvez également créer ce flux de travail à l'aide d'outils distincts. Vous trouverez ci-dessous une comparaison objective de chaque étape.
Phase 1 : Génération rapide
| Outil | Idéal pour | Description |
|---|---|---|
| Générateur d'images Seedance | Pipeline intégré, 12 préréglages de style | 2 crédits par requête. Sortie directe vers l'outil d'image Seedance. |
| ChatGPT / GPT-4 | Ingénierie de prompt personnalisée | Nécessite un copier-coller manuel. Pas de préréglages de style. Plus flexible pour les instructions complexes. |
| Claude | Prompts raffinés et détaillés | Excelle dans l'exécution de briefs créatifs complexes. Pas d'intégration de génération d'images. |
| Tongyi Qianwen | Optimisé pour les contextes chinois | Compréhension plus naturelle des descriptions chinoises. Convient aux utilisateurs nationaux. Nécessite une intégration manuelle avec les outils en aval. |
Deuxième étape : génération d'images
| Outil | Idéal pour | Remarques |
|---|---|---|
| Seedance Text-to-Image / Image-to-Image | Intégration dans le pipeline, flux de travail axé sur la vidéo | Images transférées directement vers la phase vidéo sans perte de qualité. |
| Midjourney | Qualité artistique, expressivité esthétique | Produit des résultats exceptionnels. Nécessite une utilisation via Discord ou une interface web. Téléchargeable manuellement dans les pipelines. |
| Tongyi Wanshang | Compatible avec les invites en chinois, accès national stable | Développé par Alibaba, excelle dans la compréhension des descriptions en chinois. Convient aux utilisateurs nationaux sans VPN. |
| DALL-E 3 | Fidélité aux invites, rendu textuel | Excelle dans l'exécution littérale d'invites complexes. Contrôle stylistique limité. |
| Stable Diffusion | Contrôle total, génération locale | Flexibilité maximale. Nécessite une configuration technique de l'environnement. Convient aux travaux à volume élevé. |
Troisième étape : génération de vidéos
| Outil | Idéal pour | Description |
|---|---|---|
| Seedance Image-to-Video | Pipeline intégré, qualité constante | Transfert d'images fluide, prise en charge directe de l'entrée de la première image. |
| Kling 3.0 | Longue durée, haute qualité | Génère jusqu'à 2 minutes par exécution. Qualité de mouvement élevée. Par Kuaishou, accessible en Chine. |
| Jimeng AI | Écosystème chinois, convivial | Par ByteDance, profondément intégré à l'écosystème TikTok. Idéal pour la création de vidéos courtes. |
| Runway Gen-4 | Contrôle de précision, pinceaux de mouvement | Le mode Director prend en charge les trajectoires de caméra personnalisées. Interface professionnelle. Prix plus élevé. |
| Pika 2.0 | Prise en main simple, expérimentation rapide | Interface la plus minimaliste. Convient aux débutants. Contrôle limité des détails du mouvement. |
Franchement parlant : vous pourriez certainement créer un pipeline de haute qualité en utilisant ChatGPT pour la rédaction rapide, Midjourney pour la génération d'images et Keeling pour la production vidéo. C'est précisément ce que font de nombreux professionnels. L'avantage de Seedance ne réside pas dans le fait de surpasser ses concurrents à un stade particulier, mais plutôt dans l'élimination des frictions grâce à l'intégration, au maintien de la qualité à toutes les étapes et à la fusion de trois flux de travail distincts en un seul. Pour les créateurs qui produisent fréquemment des vidéos IA, le temps gagné en restant sur une seule plateforme représente plusieurs heures par semaine.
Pour une comparaison détaillée des outils de génération vidéo, veuillez consulter Comparaison des meilleurs générateurs vidéo IA 2026.
Erreurs courantes dans les pipelines
Vous trouverez ci-dessous les cinq erreurs les plus courantes rencontrées lors de la configuration d'un pipeline prompt → image → vidéo. Chacune d'entre elles a une solution simple.
Erreur 1 : Ignorer complètement l'étape de l'image
Manifestation spécifique : Conversion directe du texte en vidéo, sans passer par la génération d'images.
Pourquoi cela pose problème : vous perdez tout contrôle sur la composition. Le modèle vidéo dicte tout : le contenu visuel, le cadrage des scènes et les points de départ de la caméra. Les résultats sont imprévisibles, avec peu de chances que votre intention créative soit respectée dès la première tentative.
Comment y remédier : générez toujours une première image, même si vous pensez que votre invite textuelle est suffisamment détaillée. Les 30 secondes passées à générer une image peuvent vous éviter plusieurs générations de vidéos ratées.
Erreur n° 2 : Utilisation d'images d'archives sans évaluation
Manifestation spécifique : Télécharger au hasard une image sur Internet ou en sélectionner une dans une bibliothèque d'images, puis l'insérer directement dans le processus de génération de la vidéo sans évaluer sa pertinence en tant qu'image d'ouverture.
Pourquoi cela pose problème : De nombreuses photographies sont conçues pour être visionnées de manière statique, et non en mouvement. Le cadrage est trop serré, ne laissant aucune place au mouvement de la caméra. Les sujets sont centrés, ce qui limite les options de cadrage. L'éclairage est plat, ce qui donne des effets vidéo ternes. Les fichiers JPEG fortement compressés introduisent des artefacts.
Comment y remédier : avant d'utiliser une image, évaluez-la d'abord selon le principe « conçu pour le mouvement ». Une meilleure approche consiste à utiliser des pipelines spécifiquement conçus pour générer une image clé.
Erreur 3 : Format d'image incompatible
Manifestations spécifiques : Génération d'images carrées puis création de vidéos au format 16:9, ou utilisation d'images au format paysage pour produire des vidéos au format portrait.
Pourquoi cela cause-t-il des dommages importants ? Les modèles vidéo recadrent vos images (ce qui entraîne la perte de votre contenu soigneusement conçu) ou remplissent le nouveau format d'image avec du contenu généré à partir de zéro (les bords ajoutés étant de moindre qualité).
Comment résoudre le problème : Déterminez le format d'image final avant de générer les images. Générez les images en fonction de ce format.
Erreur 4 : invites vidéo trop descriptives
Manifestation spécifique : La vidéo décrit simultanément la scène et son mouvement : « Une montre de luxe posée sur du marbre sombre sous un éclairage spectaculaire, la caméra tourne lentement et les reflets de lumière dansent à la surface. »
Pourquoi cela pose problème : la description visuelle peut entrer en conflit avec le contenu de l'image. Si la montre est représentée sur du marbre blanc, mais que l'invite spécifie du marbre foncé, le modèle reçoit des signaux contradictoires. Au mieux, la description visuelle devient redondante ; au pire, elle pousse le modèle à tenter de modifier votre première image soigneusement conçue.
Comment créer : Les indications vidéo doivent uniquement décrire les mouvements, les angles de caméra et l'atmosphère. Les éléments visuels ont déjà été rendus sous forme d'images. Gardez à l'esprit ce principe : les images transmettent « ce qui est vu », tandis que les indications vidéo dictent « comment cela bouge ».
Erreur 5 : se précipiter pour générer des vidéos sans passer par toutes les images
Manifestation spécifique : Générer une image et l'intégrer directement dans la génération vidéo, même lorsqu'elle présente des défauts évidents, tels qu'une composition légèrement asymétrique, des imperfections mineures ou un éclairage sous-optimal.
Pourquoi l'impact est plus important : la vidéo amplifie chaque défaut de l'image source. Une imperfection mineure dans une photographie fixe devient un défaut persistant et mobile sur 120 images animées. Une composition légèrement décentrée devient manifestement incorrecte lorsque le mouvement de la caméra attire l'attention sur le cadrage. Chaque défaut d'une photographie devient plus apparent, et non moins, dans une vidéo.
Comment y remédier : Considérez l'étape de l'image comme un point de contrôle qualité. Ne passez pas à l'étape de la vidéo tant que l'image n'est pas vraiment satisfaisante. Répétez l'opération 3 à 5 fois. Utilisez la génération d'image à image pour des réparations ciblées. La qualité de la vidéo ne peut pas dépasser celle de l'image source.
Foire aux questions
Pourquoi utiliser l'intermédiation d'images plutôt que de convertir directement le texte en vidéo ?
La génération de texte en vidéo nécessite que l'IA crée simultanément des visuels et des mouvements à partir du texte, ce qui signifie que vous avez un contrôle minimal sur la composition, l'apparence des personnages, l'éclairage et le cadrage. L'approche axée sur l'image sépare ces deux tâches : vous affinez les visuels pendant la phase d'image, puis vous demandez à l'IA d'ajouter uniquement du mouvement. Cela donne des résultats plus prévisibles et de meilleure qualité, car l'IA reçoit des références visuelles concrètes plutôt que d'interpréter un texte ambigu. La différence est particulièrement prononcée dans les scénarios professionnels qui nécessitent des compositions spécifiques, des palettes de couleurs de marque ou une conception cohérente des personnages.
Quel est le processus complet pour créer des vidéos IA à partir de zéro ?
Le processus complet comprend trois étapes. Première étape : utilisez un générateur de prompts IA (tel que Image Prompt Generator de Seedance) pour développer votre concept en un prompt image détaillé. Deuxième étape : utilisez ce prompt dans un outil de conversion texte-image (tel que Text-to-Image de Seedance) pour générer des images de référence de haute qualité, en répétant l'opération jusqu'à obtenir un résultat satisfaisant. Troisième étape : téléchargez l'image dans un générateur d'images en vidéo (tel que image-to-video de Seedance), rédigez une invite décrivant uniquement le mouvement (mouvement de la caméra et actions du sujet) et générez la vidéo. L'ensemble du processus prend entre 5 et 15 minutes, selon le nombre d'itérations nécessaires pendant la phase d'image.
Combien de crédits coûte le pipeline complet sur Seedance ?
Les coûts varient en fonction de la configuration, mais un pipeline type implique généralement : la génération rapide à 2 crédits, la génération d'images à 4-8 crédits par itération (en prévoyant 3-5 itérations, soit 12-40 crédits) et la génération de vidéos à 10-30 crédits (en fonction de la durée et de la résolution). De la conception à la vidéo finale, le coût total varie généralement entre 25 et 70 crédits. Cela représente une économie significative par rapport à l'utilisation de trois outils distincts avec trois abonnements distincts.
Les images générées par d'autres outils peuvent-elles être utilisées pour créer des vidéos dans Seedance ?
Bien sûr. L'outil [Image-to-Video] de Seedance accepte toutes les images téléchargées, qu'elles aient été générées ou non par Seedance. Vous pouvez créer des images à l'aide de Midjourney, DALL-E, Tongyi Wanshang, Stable Diffusion ou tout autre outil, puis les télécharger en tant que première image. L'avantage du pipeline intégré réside dans l'élimination de l'étape de téléchargement/chargement, bien que celle-ci ne soit pas obligatoire. Lorsque vous utilisez des images externes, nous vous recommandons le format PNG avec une résolution de 1024x1024 ou supérieure afin d'éviter que les artefacts de compression n'affectent la sortie vidéo.
Quel format d'image faut-il utiliser pour les images ?
Assurez-vous toujours que le format de votre image correspond au format final de votre vidéo. 16:9 pour les vidéos au format paysage (YouTube, présentations, intégrations sur sites web), 9:16 pour les vidéos au format portrait (TikTok, Instagram Reels, YouTube Shorts), 1:1 pour les vidéos carrées (fil Instagram, certaines publicités sur les réseaux sociaux). Générez des images au format correct dès le départ. Ne générez pas d'images carrées en espérant que les outils vidéo les convertissent au format 16:9, car cela entraînerait soit un recadrage de votre composition, soit l'ajout de contenu généré par l'IA sur les bords, ce qui compromettrait la qualité.
Comment créer des paires d'images clés ?
Générez deux images à l'aide de pipelines distincts. La première image suit le flux de travail standard : générez des invites, créez des images et répétez l'opération jusqu'à obtenir un résultat satisfaisant. La dernière image utilise image-to-image, en téléchargeant la première image comme image de référence et en décrivant les changements dans l'état final. Cela garantit une cohérence visuelle (même emplacement, même direction d'éclairage, même palette de couleurs) tout en permettant d'obtenir le changement narratif souhaité (différents moments, activités ou ambiances). Téléchargez les deux images dans un générateur de vidéo et laissez l'IA créer la transition. Pour un guide complet sur cette technique, consultez le Guide de conception de la première et de la dernière image.
Ce flux de travail est-il adapté au contenu commercial ?
Convient. Le pipeline en trois étapes a été adopté par les marques de commerce électronique pour les vidéos de produits, les équipes marketing pour les supports publicitaires, les agences immobilières pour les présentations immobilières et les agences de contenu pour la production de médias sociaux. Les vidéos générées par l'IA, d'une durée de 5 à 15 secondes et dotées d'images d'ouverture de haute qualité, répondent désormais aux normes professionnelles en matière de contenu numérique. La clé du succès commercial réside dans le temps consacré à la phase d'image : une image d'ouverture raffinée se traduit directement par une vidéo raffinée. Pour les contenus commerciaux plus longs ou de qualité professionnelle, la vidéo IA est de plus en plus utilisée pour la conception créative et la visualisation préalable, la production finale étant toujours réalisée selon des méthodes traditionnelles afin de garantir un contrôle maximal.
Que faire si l'image générée présente des imperfections ?
Ne procédez pas à la génération de la vidéo. Les imperfections de l'image source seront amplifiées dans la vidéo : une main légèrement déformée dans une image statique deviendra une main nettement déformée dans une séquence animée de 120 images. Pré-traitez l'image. Utilisez [image-to-image] pour régénérer les zones problématiques tout en préservant le reste de la composition. Pour les défauts graves (figures humaines déformées, géométries invraisemblables), régénérez complètement l'image avec une invite modifiée afin de contourner le problème. Les éléments susceptibles de présenter des défauts sont notamment les mains (précisez « mains reposant sur les côtés » ou « mains dans les poches » pour éviter les poses complexes des doigts), le texte (évitez d'inclure du texte dans les images générées) et les reflets (simplifiez les surfaces réfléchissantes dans les invites). Ne passez à la production vidéo que lorsque l'image est parfaite.
Commencez à développer votre pipeline créatif
Le processus en trois étapes (invite → image → vidéo) reste la méthode la plus fiable pour produire des vidéos IA de haute qualité en 2026. Il sépare le contrôle créatif dont vous avez besoin (comment la scène doit apparaître) de la capacité de génération que vous souhaitez (comment elle doit bouger), ce qui permet d'obtenir des vidéos qui correspondent à votre vision plutôt qu'à des suppositions aléatoires de l'IA.
Toute bonne vidéo commence par une bonne image. Toute bonne image commence par une bonne suggestion. Préparez bien le terrain, et tout le reste suivra naturellement.
Première étape : générer des invites → — Transformez vos concepts en invites d'images de qualité professionnelle à l'aide du générateur d'invites IA de Seedance.
Deuxième étape : générer une image → — Générez et affinez de manière itérative le cadre d'ouverture idéal pour votre vidéo.
Troisième étape : générer une vidéo → — Transformez des images en vidéos dynamiques mettant en scène des mouvements, des angles de caméra et une atmosphère.
Maîtriser la technique du premier cadre → — Prenez le contrôle de votre création vidéo IA en apprenant à concevoir des cadres de référence.
Pour en savoir plus : Guide sur l'IA image-vidéo | Guide de conception des premières et dernières images | Guide complet sur l'IA texte-image | Guide sur l'IA image-image | Guide sur le générateur de suggestions d'images IA | Meilleurs générateurs d'images IA 2026 | Meilleurs générateurs de vidéos IA pour 2026*
