
W skrócie
Technologia generowania wideo przez sztuczną inteligencję przekracza najważniejszy próg od momentu jej powstania: synchronizację audiowizualną. Do 2026 r. najlepsze generatory wideo oparte na sztucznej inteligencji nie będą już tworzyć niemych klipów wymagających ręcznego dubbingowania. Będą one generować efekty dźwiękowe dopasowane do akcji na ekranie, muzykę w tle zsynchronizowaną z nastrojem obrazu oraz synchronizację ruchu warg z mową w wielu językach – wszystko to w ramach jednego procesu generowania. Niniejszy przewodnik obejmuje: trzy podstawowe rodzaje generowania audiowizualnego przez sztuczną inteligencję (efekty dźwiękowe, podkłady muzyczne, synchronizacja ruchu warg); kompletny sześcioetapowy proces tworzenia teledysków AI od podstaw; osiem rzeczywistych scenariuszy zastosowań, od teledysków niezależnych artystów po wizualizację podcastów; pięć gotowych do użycia szablonów poleceń; kompleksowe porównanie wszystkich narzędzi obsługujących dźwięk; a także zaawansowane techniki, takie jak dopasowanie BPM i synchronizacja emocjonalna. Jeśli Twoje treści wideo wymagają dźwięku – co dotyczy praktycznie wszystkich produkcji wideo – stanowi to najbardziej znaczący postęp w dziedzinie wideo opartego na sztucznej inteligencji od czasu generowania tekstu do wideo. Zacznij tworzyć teledyski oparte na sztucznej inteligencji już teraz -->
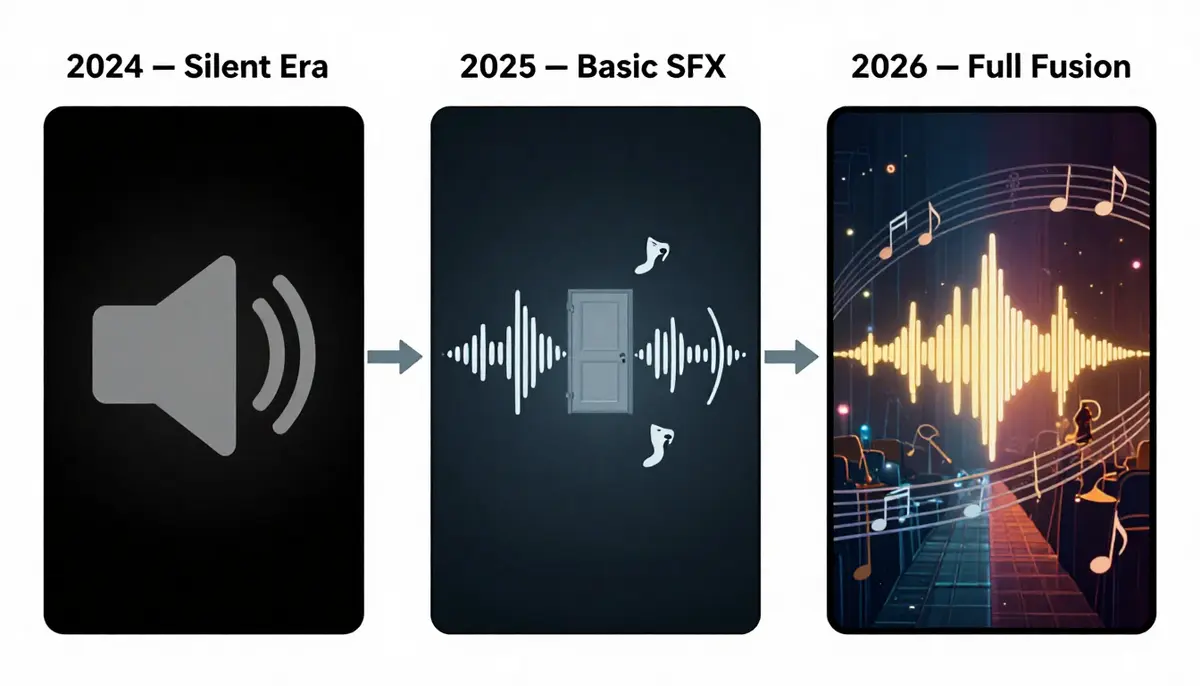
Przejście od niemych filmów AI do idealnej synchronizacji ruchu warg stanowi największy skok jakościowy w historii treści generowanych przez sztuczną inteligencję. To, co kiedyś wymagało tygodni pracy hollywoodzkich zespołów postprodukcyjnych, można teraz osiągnąć w ramach jednego procesu generowania.
Rewolucja audio w filmach AI
Przez długi czas filmy generowane przez sztuczną inteligencję pozostawały medium zasadniczo niekompletnym. Jakość obrazu poprawiała się w niezwykłym tempie – od rozmytych, kilkusekundowych klipów na początku 2024 r. do minutowych sekwencji o fotograficznej realności pod koniec 2025 r. Jednak wszystkie te filmy miały jedną wspólną wadę: były nieme.
Era ciszy: od 2024 r. do początku 2025 r.
Pierwsza generacja narzędzi wideo opartych na sztucznej inteligencji — Runway Gen-2, Pika 1.0 i wczesne wersje Keeling — mogła generować wyłącznie materiały wideo. Nie zawierały one ścieżek audio, efektów dźwiękowych ani muzyki. Wynikiem była wyłącznie wizualna plik MP4, wymagający ręcznego dubbingowania, miksowania i synchronizacji w ramach oddzielnego procesu edycji. Nie była to drobna niedogodność, ale fundamentalna rozbieżność między możliwościami produkcyjnymi sztucznej inteligencji a oczekiwaniami odbiorców.
Ludzkie postrzeganie obrazu wideo ma charakter głęboko multimodalny. Badania neurologiczne konsekwentnie wykazują, że dźwięk ma 50% lub większy wpływ na emocje wywoływane przez każdy rodzaj obrazu wideo. Krajobraz filmowy, nawet jeśli jest fotorealistyczny, bez szumu wiatru, śpiewu ptaków lub poruszającej ścieżki dźwiękowej wydaje się płaski i sztuczny. Postać mówiąca bez dźwięku — z poruszającymi się w milczeniu ustami — wpada bezpośrednio w niesamowitą dolinę. „Era ciszy” wideo AI oznacza, że każdy wygenerowany klip wymaga intensywnej postprodukcji, aby wyglądał na kompletny.
Dla profesjonalnych twórców oznacza to konieczność utrzymywania dwóch oddzielnych procesów pracy dla generowania obrazu i produkcji dźwięku, co skutecznie podwaja zarówno wymagania czasowe, jak i umiejętnościowe. Dla zwykłych twórców oznacza to, że filmy generowane przez sztuczną inteligencję wydają się nieustanie niedokończone – imponujące jako demonstracje techniczne, ale nie nadające się do wykorzystania jako ostateczna treść.
2025–2026: Konwergencja dźwięku i obrazu
Przełomowe rozwiązania pojawiają się etapami. Firma Google Veo 3 ogłosiła wprowadzenie natywnych funkcji generowania dźwięku, pokazując, jak jeden model może jednocześnie tworzyć zsynchronizowane obrazy i dźwięki. Nie jest to dźwięk nakładany na obraz podczas postprodukcji – dźwięk jest generowany jako integralna część wyjściowego obrazu, a dźwięki otoczenia są precyzyjnie dopasowane do akcji na ekranie.
W tym samym okresie Seedance 2.0 (opracowany przez zespół Seed firmy ByteDance) wypuścił na rynek kompleksowy pakiet audio obejmujący trzy odrębne funkcje: generowanie efektów dźwiękowych (SFX) przez sztuczną inteligencję zsynchronizowane z treścią wideo, generowanie ścieżki dźwiękowej przez sztuczną inteligencję dostosowane do nastroju obrazu oraz technologia synchronizacji ruchu warg przez sztuczną inteligencję, która dopasowuje dźwięk mowy do ruchów ust postaci (obsługująca osiem języków, w tym chiński). Pika wprowadziła funkcję efektów dźwiękowych dla podstawowych dźwięków otoczenia. Otworzyły się szeroko możliwości audio.
Ta zmiana jest znacząca, ponieważ przekształca wideo AI z „materiału wizualnego wymagającego ręcznej postprodukcji” w „kompletny, gotowy do publikacji format multimedialny”. Różnica między „klipami generowanymi przez AI” a „gotowymi treściami wideo” zmniejszyła się z wielu godzin edycji do zaledwie kilku minut generowania.
Szczególne znaczenie dla chińskich twórców: Ta transformacja stwarza większe możliwości dla krajowych twórców. Platformy takie jak Douyin, Kuaishou i Bilibili stworzyły rozległy ekosystem twórczy dla krótkich teledysków muzycznych. Chociaż niezależni muzycy zdobyli publiczność na NetEase Cloud Music i QQ Music, często brakuje im treści wizualnych odpowiadających jakości ich muzyki. Teledyski generowane przez sztuczną inteligencję bezpośrednio wypełniają tę lukę — producenci tworzący profesjonalną muzykę na laptopach mogą teraz tworzyć równie dopracowane teledyski przy użyciu sztucznej inteligencji.
Dlaczego dźwięk jest ostatnim elementem układanki
Weźmy na przykład proces tworzenia treści przez twórcę Bilibili, twórcę Xiaohongshu lub niezależnego muzyka:
- Koncepcja — O czym jest film?
- Obraz — Jak wygląda film?
- Dźwięk — Jak brzmi film?
- Synchronizacja — Czy obraz i dźwięk są zsynchronizowane?
- Wykończenie — Czy film jest gotowy do publikacji?
Do 2025 r. narzędzia wideo oparte na sztucznej inteligencji skutecznie rozwiązały problemy związane z etapami 1 i 2. Etapy 3 i 4 pozostały całkowicie ręczne. Dzięki generatorom posiadającym funkcje audio etapy od 1 do 4 można było teraz wykonać za pomocą jednego narzędzia. Krok 5 – ostateczne dopracowanie – pozostaje jedynym etapem wykonywanym ręcznie, choć jego konieczność maleje wraz z poprawą jakości wyników.
W przypadku produkcji teledysków oznacza to rewolucyjną zmianę. Niezależny muzyk, który nigdy nie byłby w stanie pokryć kosztów tradycyjnej produkcji teledysku, może teraz go stworzyć. Twórca Bilibili produkujący muzykę lo-fi może stworzyć wizualne dodatki do każdego utworu. Zespół marketingowy może produkować reklamy produktów z idealnie dopasowaną ścieżką dźwiękową bez konieczności zatrudniania kompozytorów lub zakupu muzyki chronionej prawami autorskimi.
Obecny stan narzędzi z funkcjami audio
Od lutego 2026 r. trzy platformy przodują w dziedzinie filmów generowanych przez sztuczną inteligencję z wbudowanym dźwiękiem:
- Seedance 2.0: Najbardziej kompleksowe rozwiązanie audiowizualne. Obsługuje generowanie efektów dźwiękowych, tworzenie ścieżek dźwiękowych/muzyki oparte na sztucznej inteligencji oraz wielojęzyczną synchronizację ruchu warg (8 języków, w tym chiński). Nadaje się zarówno do procesów przekształcania tekstu w wideo, jak i obrazu w wideo. Jako produkt ByteDance, dostępny bezpośrednio w Chinach bez VPN, obsługujący Alipay/WeChat Pay. W niniejszym przewodniku będziemy odnosić się głównie do tej platformy.
- Google Veo 3: Potężne natywne możliwości generowania dźwięku, w tym dźwięków otoczenia i efektów atmosferycznych. Wyniki są imponujące, choć brakuje mu precyzyjnej kontroli nad typami i stylami dźwięku, jaką oferuje Seedance. **Wymaga VPN do korzystania w Chinach. ** Szczegółowe porównanie można znaleźć w artykule Seedance vs Veo 3 In-Depth Comparison.
- Pika 2.0: Podstawowe generowanie efektów dźwiękowych. Ograniczone do efektów dźwiękowych otoczenia — brak generowania muzyki i obsługi synchronizacji ruchu warg. Krok we właściwym kierunku, ale nie jest to kompletne rozwiązanie audio. Wymaga VPN.
Inne narzędzia w ekosystemie — Keeling, Runway i Conch AI — w chwili pisania tego artykułu nadal koncentrują się głównie na czystej produkcji wizualnej, ale oczekuje się, że wkrótce pójdą w ich ślady. Aby uzyskać szersze porównanie wszystkich generatorów, zapoznaj się z artykułem Kompletne porównanie generatorów wideo AI 2026.
Dodatkowe opcje dla użytkowników krajowych — narzędzia do generowania muzyki oparte na sztucznej inteligencji: Oprócz możliwości audio w filmach opartych na sztucznej inteligencji, w Chinach istnieją dedykowane platformy do generowania muzyki oparte na sztucznej inteligencji, które warto poznać: SkyMusic (wyprodukowana przez Kunlun Wanwei, wyróżniająca się generowaniem chińskich tekstów piosenek) oraz NetEase Tianyin (wyprodukowana przez NetEase, zintegrowana z ekosystemem NetEase Cloud Music). Narzędzia te mogą służyć jako samodzielne procesy tworzenia muzyki, a wygenerowana muzyka może być następnie importowana do Seedance jako materiał referencyjny audio do produkcji wideo.
Trzy główne typy generowania audiowizualnego przez sztuczną inteligencję
Nie wszystkie rozwiązania audio oparte na sztucznej inteligencji są takie same. Technologia ta obejmuje trzy zasadniczo różne funkcje, z których każda służy innym celom twórczym i działa w oparciu o inne mechanizmy techniczne. Zrozumienie tych różnic ma kluczowe znaczenie dla wyboru odpowiedniego podejścia do danego projektu.

Generowanie efektów dźwiękowych przez sztuczną inteligencję polega na analizie treści wideo klatka po klatce, identyfikowaniu działań i środowisk, które wytwarzają dźwięk, a następnie syntezie pasujących fal dźwiękowych. Efektem końcowym jest dźwięk otoczenia organicznie powiązany z treścią wizualną.
Typ pierwszy: Efekty dźwiękowe AI (SFX)
Generowanie dźwięku przez sztuczną inteligencję automatycznie tworzy dźwięki otoczenia i akcji, które pasują do tego, co widzisz na ekranie. Kiedy postacie idą po żwirowej ścieżce, słyszysz odgłos kroków na kamieniach. Kiedy fale rozbijają się o skały, słyszysz szum morza. Kiedy silniki samochodów ryczą na ulicy, słyszysz odgłos silników.
Jak działa generowanie dźwięku Seedance: Model AI analizuje zawartość wizualną generowanego wideo — identyfikując obiekty, działania, otoczenie i interakcje fizyczne — i tworzy towarzyszącą ścieżkę dźwiękową z odpowiednimi efektami dźwiękowymi. Nie jest to prosta kwestia dopasowania „oceanu” do gotowego klipu z falami. Model generuje unikalny dźwięk reagujący na konkretne cechy wizualne: intensywność fal, ich odległość od kamery, obecność wiatru i właściwości akustyczne otoczenia.
Sound Generation specjalizuje się w przetwarzaniu następujących rodzajów dźwięków: – dźwięki otoczenia (wiatr, deszcz, grzmoty, odgłosy lasu, ruch uliczny) – dźwięki interakcji fizycznej (odgłosy kroków na różnych powierzchniach, otwieranie/zamykanie drzwi, ustawianie przedmiotów) – dźwięki natury (szum wody, śpiew ptaków, brzęczenie owadów, szelest liści)
- Dźwięki mechaniczne (silniki, praca maszyn, naciskanie przycisków, buczenie urządzeń elektronicznych)
- Dźwięki uderzeń (kolizje, pluski, rozbicia, zawalenia)
Techniki sugerowania dźwięków za pomocą podpowiedzi: Nawet podczas korzystania z technologii AI zamiany tekstu na wideo można wpływać na wyjście audio, opisując elementy wytwarzające dźwięk w podpowiedziach wizualnych. „Deszcz uderzający o blaszany dach” daje bardziej intensywny dźwięk opadu niż „delikatna mżawka w ogrodzie”. Dźwięk kroków „ciężkich butów tupiących po metalowej kratce” różni się całkowicie od „bosych stóp na ciepłym piasku”. Opisy wizualne wpływają na generowanie dźwięku, więc przedstawianie scen bogatych akustycznie pozwala uzyskać bardziej złożone pejzaże dźwiękowe.
Obecne ograniczenia: Generowanie dźwięków sprawdza się doskonale w przypadku dźwięków otoczenia i dźwięków naturalnych, ale może sprawiać trudności w przypadku złożonych, wielowarstwowych pejzaży dźwiękowych (takich jak ruchliwa restauracja, w której nakładają się na siebie rozmowy, brzęk sztućców, odgłosy kuchni i muzyka w tle). Lepiej radzi sobie również z dźwiękami organicznymi niż z bardzo specyficznymi, rozpoznawalnymi charakterystykami audio (odgłos silnika konkretnego modelu samochodu, śpiew konkretnego gatunku ptaka).
Typ drugi: muzyka i ścieżki dźwiękowe generowane przez sztuczną inteligencję
Generowanie muzyki przez sztuczną inteligencję pozwala tworzyć podkłady muzyczne, ścieżki dźwiękowe i oryginalne kompozycje do filmów, które idealnie pasują do treści wizualnej, nastroju i rytmu. Nie jest to po prostu dodawanie ogólnej muzyki wolnej od opłat licencyjnych – sztuczna inteligencja generuje oryginalne kompozycje dostosowane do materiału filmowego.
Kontrola stylu: Możesz kierować stylem muzycznym za pomocą podpowiedzi i ustawień generowania. Obsługiwanych jest wiele różnych stylów:
- Filmowa orkiestra: Potężne smyczki, instrumenty dęte blaszane i perkusja, idealne do epickich krajobrazów lub dramatycznych scen
- Dynamiczna muzyka elektroniczna: Żywe syntezatory i rytmy, idealne do szybkich treści, prezentacji produktów lub mediów społecznościowych
- Muzyka ambientowa/atmosferyczna: Miękkie tekstury, warstwowe tony i długie basy, idealne do treści medytacyjnych, prezentacji nieruchomości lub filmów przyrodniczych w zwolnionym tempie
- Lo-fi Hip-hop: Kultowe, ciepłe, lekko fałszywe rytmy w połączeniu z trzaskami winylu, idealne do treści związanych z nauką/koncentracją
- Napięcie/suspens: Dysonansowe struny, głębokie perkusje i warstwowa, narastająca intensywność, idealne do zwiastunów i filmów promocyjnych
- Folk/ akustyczny: gitara, fortepian i instrumenty organiczne, odpowiedni do spersonalizowanych, intymnych treści
- Tradycyjny chiński/starożytny styl: guzheng, dizi, pipa i inne tradycyjne chińskie instrumenty, odpowiednie do tradycyjnych chińskich treści wideo i teledysków w stylu starożytnym — stanowi to najbardziej charakterystyczny kierunek stylistyczny w chińskiej twórczości muzycznej opartej na sztucznej inteligencji.

Różne style muzyczne charakteryzują się wyraźnie odmiennymi właściwościami fal dźwiękowych. Generowanie ścieżki dźwiękowej przez sztuczną inteligencję nie tylko dopasowuje się do gatunku muzycznego, ale także dostosowuje krzywą energii, synchronizując intensywność muzyki z akcją wizualną w całym filmie.
Dopasowanie czasu trwania: Muzyka generowana przez sztuczną inteligencję będzie dopasowana do czasu trwania Twojego filmu. 5-sekundowy klip otrzyma spójną 5-sekundową frazę muzyczną. 30-sekundowy film otrzyma utwór o ustalonej strukturze, zawierający wprowadzenie, rozwinięcie i zakończenie. Eliminuje to powszechny problem ręcznego wyciszania/wzmacniania muzyki stockowej, która nie została zaprojektowana z myślą o konkretnej długości filmu.
Różnice w stosunku do samodzielnych narzędzi muzycznych opartych na sztucznej inteligencji: Być może znasz już dedykowane generatory muzyczne oparte na sztucznej inteligencji, takie jak Suno lub Udio, które tworzą samodzielne utwory muzyczne na podstawie tekstowych wskazówek. Chociaż narzędzia te tworzą doskonałą muzykę, brakuje im świadomości wizualnej – nie mają one wiedzy na temat tego, jak wygląda Twój film, kiedy pojawiają się kluczowe momenty wizualne ani jak zmienia się nastrój w materiale filmowym. Generowanie ścieżki dźwiękowej AI w narzędziach wideo, takich jak Seedance, działa zasadniczo inaczej, ponieważ muzyka jest generowana w odpowiedzi na treści wizualne. Muzyka staje się intensywniejsza, gdy sceny stają się bardziej dramatyczne, jej rytm dostosowuje się do ruchu na ekranie, a atmosfera pasuje do nastroju każdej sceny.
Innymi słowy, samodzielne narzędzia muzyczne AI i generatory wideo AI uzupełniają się wzajemnie. Solidny proces pracy polega najpierw na wygenerowaniu utworu w Suno lub Udio (lub krajowych alternatywach, takich jak SkyMusic lub NetEase Tianyin), a następnie wykorzystaniu tego pliku audio jako danych wejściowych do wygenerowania wideo w Seedance. Generator wideo AI stworzy wizualizacje dostosowane do struktury muzyki. Szczegółowo opiszemy ten proces pracy w poniższym samouczku krok po kroku.
Typ trzeci: synchronizacja ruchu warg i mowy za pomocą sztucznej inteligencji
Generowanie synchronizacji ruchu warg za pomocą sztucznej inteligencji stanowi największe wyzwanie techniczne spośród trzech rodzajów audio. Polega ono na dopasowaniu dźwięku mowy – zarówno przesłanego, jak i wygenerowanego – do ruchu warg postaci, tworząc wrażenie, że postać na ekranie mówi lub śpiewa.
Obsługa wielu języków: Seedance 2.0 obsługuje synchronizację ruchu warg w ośmiu językach, w tym chińskim, angielskim, japońskim, koreańskim, hiszpańskim, francuskim, niemieckim i portugalskim. Wykracza to poza zwykłe dubbingowanie dźwięku – model dostosowuje kształt ust postaci, ruchy szczęki i mikroekspresje twarzy, aby dopasować je do charakterystyki głosowej każdego języka. Kształt ust dla chińskiej samogłoski „o” różni się od angielskiej „O”, a japońska samogłoska „u” również różni się od angielskiej „u”. Dokładna synchronizacja ruchu warg musi uwzględniać te różnice językowe.
Praktyczne znaczenie chińskiego synchronizowania ruchu warg: Dla krajowych twórców chińskie synchronizowanie ruchu warg umożliwia postaciom generowanym przez sztuczną inteligencję wykonywanie utworów w standardowym mandaryńskim lub precyzyjne dopasowanie szybkich chińskich tekstów w teledyskach rapowych. Ma to ogromny potencjał twórczy w społecznościach coverów piosenek i anime na TikTok i Bilibili – wirtualni piosenkarze AI stają się nowym formatem treści.

Synchronizacja ruchu warg za pomocą sztucznej inteligencji przekształca realistyczną wizualnie, ale niemą postać w postać mówiącą. Technologia ta nie tylko dostosowuje kształt ust, ale także moduluje pozycję szczęki, napięcie policzków i subtelne mikroekspresje twarzy, aby dopasować je do fonemów mowy.
Jak to działa: Proces rozpoczyna się od referencji audio — nagrania głosu przesłanego przez użytkownika lub mowy wygenerowanej przez sztuczną inteligencję. Model analizuje treść fonetyczną audio (jakie dźwięki są generowane w poszczególnych momentach) i generuje odpowiednie ruchy warg i mimikę twarzy klatka po klatce. Aby uzyskać optymalne wyniki, audio powinno zawierać wyraźną mowę w umiarkowanym tempie, z minimalnym poziomem szumu w tle.
Scenariusze zastosowań:
- Cyfrowi ludzie i wirtualne awatary: Tworzenie gadających hostów AI dla kanałów Bilibili/YouTube, szkoleń korporacyjnych lub obsługi klienta
- Postacie animowane: Głosowe postacie animowane generowane przez AI bez synchronizacji ruchu warg klatka po klatce
- Wielojęzyczne dubbingowanie: Generuj wersje istniejących treści audiowizualnych z synchronizacją ruchu warg w innych językach, dopasowując nowy dźwięk do ruchów ust postaci.
- Występy w teledyskach: Zsynchronizuj występy wizualne piosenkarzy z ścieżkami wokalnymi, aby stworzyć autentyczne efekty występów w teledyskach.
- Wizualizacja podcastów i audiobooków: Przekształć czystą treść audio w media wizualne z mówiącymi postaciami.
Obecne ograniczenia — szczera ocena: Synchronizacja ruchu warg jest najmłodszą i najmniej dojrzałą z trzech technologii audiowizualnych. Pomimo znacznego postępu nadal istnieją pewne wyzwania. Szybka mowa czasami przekracza możliwości modelu w zakresie generowania odpowiednich ruchów warg, co powoduje niewielką desynchronizację. Ekstremalne kąty twarzy (profil z boku, ekstremalne kąty w górę) zmniejszają dokładność synchronizacji ruchu warg ze względu na mniejszą liczbę widocznych punktów orientacyjnych ust. Mowa z wyraźnym akcentem lub nietypowymi cechami głosowymi może dawać mniej precyzyjne wyniki niż standardowe wzorce mowy. W przypadku chińskich piosenek o bardzo szybkim tempie, takich jak rap, dokładność synchronizacji może być niższa niż w przypadku śpiewu w standardowym tempie. Chociaż technologia szybko się rozwija, ważne jest, aby mieć rozsądne oczekiwania — synchronizacja ruchu warg w 2026 r. będzie doskonała w standardowych scenariuszach mowy, ale w skrajnych przypadkach nadal będzie wymagała udoskonalenia.
Przewodnik krok po kroku: Tworzenie teledysków AI od podstaw
Postępując zgodnie z tym sześcioetapowym procesem, można stworzyć kompletny teledysk oparty na sztucznej inteligencji, z zsynchronizowanym dźwiękiem i obrazem, od pomysłu do realizacji. Proces ten ma zastosowanie zarówno dla niezależnych muzyków tworzących swój pierwszy teledysk, twórców treści Bilibili budujących kanał muzyczny, jak i marketerów produkujących filmy promujące markę.
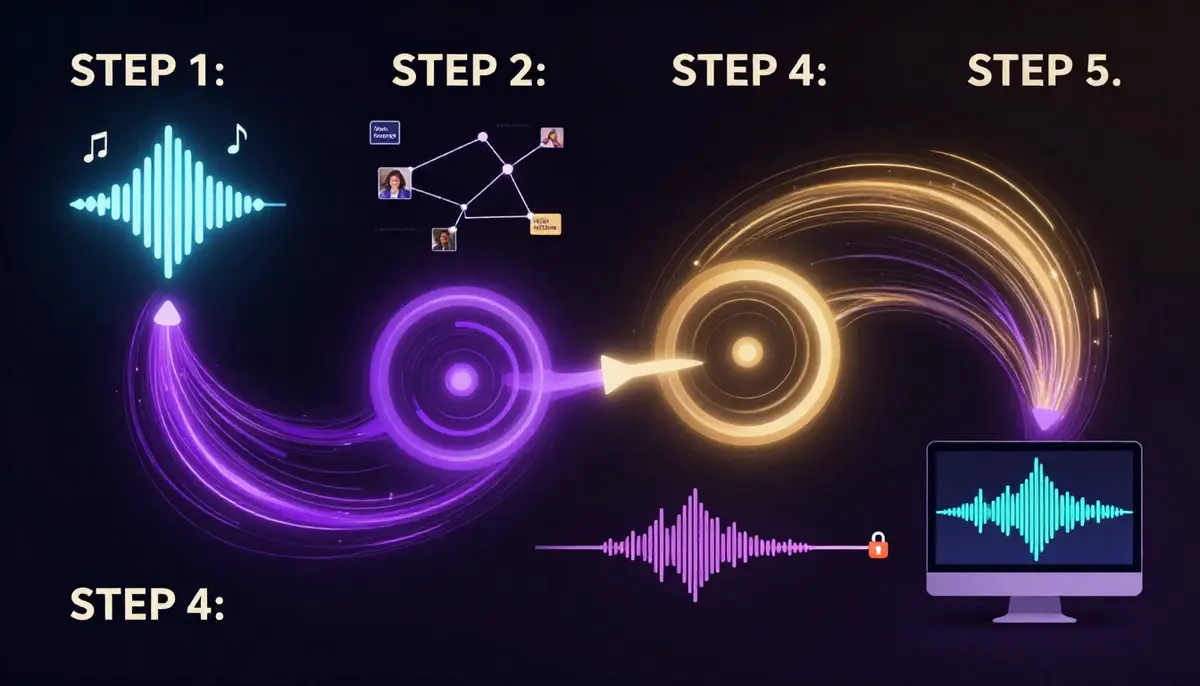
Kompletny proces tworzenia teledysku z wykorzystaniem sztucznej inteligencji, od źródła audio do gotowego produktu. Każdy etap opiera się na poprzednim, a synchronizacja audio-wizualna jest automatycznie osiągana podczas generowania.
Krok pierwszy: Przygotuj muzykę lub źródło dźwięku
Każdy teledysk zaczyna się od muzyki. Masz trzy możliwości:
Opcja A — Korzystanie z własnej muzyki: Jeśli jesteś muzykiem lub posiadasz licencjonowane utwory, przygotuj swoje pliki audio. Obsługiwane formaty to zazwyczaj MP3, WAV i AAC. Aby uzyskać optymalne wyniki, używaj wysokiej jakości wersji master lub mix (nie skompresowanych plików streamingowych). Czysty, dobrze rozdzielony dźwięk zapewnia lepszą synchronizację ruchu warg w porównaniu z mocno skompresowanymi plikami.
Opcja B — Najpierw wygeneruj muzykę za pomocą sztucznej inteligencji: Użyj samodzielnych generatorów muzycznych opartych na sztucznej inteligencji, aby stworzyć oryginalne utwory. Zagraniczne narzędzia to między innymi Suno i Udio; w kraju warto rozważyć SkyMusic (doskonałe do generowania chińskich tekstów, obsługuje wiele chińskich stylów muzycznych) lub NetEase Tianyin (zintegrowane z ekosystemem NetEase Cloud Music). Opisz pożądany styl, nastrój, tempo i aranżację, aby wygenerować wiele wersji, a następnie wybierz tę, która najlepiej pasuje do Twojej koncepcji wizualnej. Zapisz lokalnie.
Opcja C — Pełna kontrola AI: Jeśli nie masz konkretnego źródła dźwięku i chcesz, aby AI generowała jednocześnie obraz i dźwięk, pomiń przygotowanie dźwięku i skorzystaj bezpośrednio z wbudowanej funkcji generowania ścieżki dźwiękowej Seedance. W tym scenariuszu Twój bodziec wizualny będzie miał wpływ na efekt muzyczny. Jest to najszybsze podejście, ale daje mniejszą kontrolę nad precyzyjnym efektem muzycznym.
Porada dla muzyków: Jeśli chcesz, aby efekty wizualne reagowały na konkretne momenty w utworze – spadek tempa, zmianę tonacji, wejście wokalu – zanotuj te momenty. Informacje te wykorzystasz w swoich wskazówkach i możesz wygenerować segmenty dostosowane do struktury utworu.
Krok drugi: Tworzenie wizualnych wskazówek uzupełniających muzykę
Twoje wizualne wskazówki powinny przedstawiać obrazy, które w naturalny sposób uzupełniają dźwięk. Nie chodzi tu o dosłowne ilustrowanie tekstu piosenki, ale raczej o stworzenie wizualnej atmosfery, która wzmacnia emocjonalną treść muzyki.
Dopasowanie stylu muzycznego do stylu wizualnego:
| Styl muzyczny | Kierunek wizualny | Słowa kluczowe |
|---|---|---|
| Kinowa orkiestra | Rozległe krajobrazy, dramatyczne niebo, epicka skala | „rozległy”, „majestatyczny”, „powolny ruch kamery”, „jakość IMAX” |
| Lo-fi / Relaks | Delikatne dźwięki, przytulne wnętrza, mżawka, ciepłe oświetlenie | „pastelowy”, „miękkie ogniskowanie”, „ciepły”, „delikatny ruch” |
| Dynamiczna muzyka elektroniczna | Szybkie cięcia, neony, miejskie, dynamiczne ujęcia | „żywiołowa”, „dynamiczna”, „neonowa”, „szybka” |
| Liryczna ballada | Intymne zbliżenia, światło świec, zwolnione tempo | „intymna”, „mała głębia ostrości”, „ciepłe tony” |
| Mroczne/dramatyczne | Cienie, wysoki kontrast, napięcie, minimalistyczna paleta kolorów | „dramatyczne oświetlenie”, „sylwetka”, „wysoki kontrast” |
| Chiński/starożytny styl | Krajobrazy, pawilony i wieże, elementy tuszu, opadające płatki | „chiński krajobraz”, „styl malarstwa tuszem”, „tradycyjna architektura”, „eteryczny” |
| Rap/hip-hop | Sceny uliczne, graffiti, nocne pejzaże, aureole świateł samochodowych | „miejski”, „kultura uliczna”, „neony”, „dynamiczne ujęcia z ręki” |
Aby zapoznać się z kompleksowymi technikami tworzenia podpowiedzi, zapoznaj się z Przewodnikiem po podpowiedziach Seedance. Podstawowe zasady tworzenia podpowiedzi do teledysków: opisuj ruchy, które wydają się naturalne w rytmie utworu. Szybkie utwory wymagają dynamicznych efektów wizualnych, natomiast wolniejsze utwory wymagają spokojnych, pełnych gracji ruchów.
Krok trzeci: Wybierz tryb audio
Podczas generowania w Seedance wybierz odpowiedni tryb audio w zależności od projektu:
Tryb efektów dźwiękowych (SFX): Idealny, gdy film zawiera wyraźne elementy otoczenia lub akcji wymagające autentycznych dźwięków otoczenia. Samochód jadący w deszczu powinien brzmieć jak samochód w deszczu. Sceny oceaniczne powinny zawierać odgłosy fal. Tryb SFX automatycznie generuje te dźwięki na podstawie materiału filmowego.
Tryb muzyki/ścieżki dźwiękowej: Idealny, gdy chcesz, aby sztuczna inteligencja generowała muzykę w tle, która uzupełnia treści wizualne. Użyj tego trybu, gdy nie masz gotowych utworów i chcesz, aby narzędzie stworzyło oryginalną ścieżkę dźwiękową. Możesz wpływać na styl za pomocą wizualnych podpowiedzi — neonowy cyberpunkowy pejzaż miejski wygeneruje zupełnie inną muzykę niż spokojny wschód słońca w górach.
Tryb synchronizacji głosu/ruchów ust: Idealny, gdy w filmie występują postacie mówiące lub śpiewające i potrzebujesz synchronizacji dźwięku z ruchami ust. Prześlij ścieżkę głosową lub nagranie głosowe, a sztuczna inteligencja wygeneruje pasujące ruchy ust dla postaci.
Podejście łączone: Aby uzyskać najbardziej kompleksowe wrażenia podczas oglądania teledysku, warto rozważyć wieloetapowy proces pracy. Najpierw należy wygenerować podstawowy film z obrazem i muzyką, korzystając z trybu ścieżki dźwiękowej. Jeśli konieczne jest nałożenie efektów dźwiękowych otoczenia na muzykę, należy użyć trybu SFX w drugim etapie lub dodać je podczas postprodukcji. Jeśli postacie muszą śpiewać, należy to przetworzyć za pomocą trybu synchronizacji ruchu warg na ścieżce wokalnej.
Krok czwarty: Prześlij materiały referencyjne (opcjonalne, ale zdecydowanie zalecane)
Dane referencyjne mogą znacznie poprawić jakość i dokładność wyników. W przypadku produkcji teledysków szczególnie przydatne są następujące rodzaje danych referencyjnych:
Plik referencyjny audio: Prześlij swój utwór muzyczny. Sztuczna inteligencja wykorzysta go jako szkielet audio dla filmu, generując wizualizacje odpowiadające treści muzycznej. Jest to najważniejszy element referencyjny w produkcji teledysków.
Obraz referencyjny: Prześlij statyczny obraz, który określa pożądany styl wizualny. Może to być okładka albumu, zrzut ekranu z tablicy inspiracji, klatka z istniejącego teledysku, który podziwiasz, lub obraz wygenerowany przez sztuczną inteligencję, oddający pożądaną estetykę. Funkcja text-to-video Seedance wykorzystuje tę referencję do zachowania spójności wizualnej.
Film referencyjny: Jeśli posiadasz istniejący teledysk, którego ruchy kamery, rytm montażu lub styl wizualny chcesz naśladować, prześlij go jako referencję. Sztuczna inteligencja nauczy się wzorców ruchu, synchronizacji przejść i kompozycji wizualnej na podstawie Twojej referencji podczas generowania oryginalnej treści.
Krok piąty: Generowanie i dostosowywanie synchronizacji audio-wizualnej
Kliknij „Generuj”, aby sztuczna inteligencja wygenerowała wstępny wynik. Podczas przeglądu zwróć szczególną uwagę na dokładność synchronizacji ruchu warg:
Kluczowe punkty kontrolne:
- Czy energia muzyczna odpowiada energii wizualnej? Dramatyczne crescendo orkiestry powinno zbiegać się z dramatycznym momentem wizualnym, a nie statyczną sceną.
- Czy synchronizacja efektów dźwiękowych jest dokładna? Kroki powinny być słyszalne w momencie, gdy stopa dotyka podłoża. Odgłosy uderzeń powinny odpowiadać wizualnym zderzeniom.
- Czy synchronizacja ruchu warg jest przekonująca? Obserwuj usta postaci przy normalnej prędkości odtwarzania. Niewielkie rozbieżności na poziomie klatek są niewidoczne przy normalnej prędkości, ale widoczne w zwolnionym tempie – a widzowie oglądają film w normalnym tempie.
- Czy ogólna atmosfera jest spójna? Paleta kolorów wizualnych, tonacja i aranżacja muzyczna oraz rytm powinny wspólnie przekazywać tę samą emocjonalną narrację.
Jeśli pojawią się problemy z synchronizacją: Po zmodyfikowaniu podpowiedzi należy ją ponownie wygenerować. Jeśli muzyka okaże się zbyt intensywna w stosunku do obrazów, należy włączyć do podpowiedzi wizualnej bardziej dynamiczne elementy. Jeśli obrazy okażą się zbyt szybkie w stosunku do wolnej piosenki, należy w podpowiedzi umieścić terminy sugerujące tempo, takie jak „wolno”, „delikatnie” lub „celowo”. Sztuczna inteligencja zareaguje na te wskazówki rytmiczne.
Krok szósty: Wyeksportuj kompletne pliki audio i wideo
Po uzyskaniu satysfakcjonującego efektu wyeksportuj gotowy teledysk. Wynikiem jest pojedynczy plik zawierający zsynchronizowane ścieżki wideo i audio, co eliminuje konieczność ręcznego dopasowywania dźwięku w edytorze.
Uwagi dotyczące eksportu:
- Format: MP4 (wideo H.264 + audio AAC) jest uniwersalnym standardem akceptowanym na wszystkich platformach
- Rozdzielczość: Eksportuj w najwyższej dostępnej rozdzielczości. W przypadku teledysków minimalnym wymaganiem jest rozdzielczość 1080p; preferowana jest rozdzielczość 2K lub 4K.
- Proporcje obrazu: 16:9 dla Bilibili/YouTube i standardowej dystrybucji teledysków; 9:16 dla Douyin, Kuaishou, Xiaohongshu i Instagram Reels; 1:1 dla WeChat Moments i Instagram feed
- Jakość dźwięku: Upewnij się, że ustawienia eksportu zachowują wierność dźwięku. Jeśli przesłane są pliki źródłowe wysokiej jakości, eksport musi zachować ten poziom wierności.
Opcjonalne kroki po eksporcie: Chociaż teledyski wygenerowane przez sztuczną inteligencję można publikować bezpośrednio, warto dodać ostatnie poprawki w edytorze wideo: karty tytułowe, napisy z tekstami piosenek, logo artystów/wytwórni, przejścia między sekcjami lub korekcję kolorów. Do tego ostatniego etapu dobrze nadają się popularne krajowe narzędzia, takie jak CapCut, DaVinci Resolve lub Premiere. Przed opublikowaniem na Bilibili pamiętaj o dodaniu napisów i obrazu okładki — są one kluczowe dla algorytmu rekomendacji Bilibili.
Stwórz swój pierwszy teledysk z wykorzystaniem sztucznej inteligencji już teraz -->
8 głównych scenariuszy zastosowania sztucznej inteligencji w teledyskach
Generowanie teledysków przez sztuczną inteligencję nie jest technologią jednofunkcyjną. Połączenie kreacji wizualnej z zsynchronizowanym dźwiękiem otwiera kreatywne możliwości w różnych rodzajach treści i branżach. Poniżej przedstawiono osiem konkretnych scenariuszy zastosowań, z których każdy zawiera szczegółowe wytyczne operacyjne.

Osiem różnych scenariuszy zastosowania sztucznej inteligencji do generowania teledysków, każdy z unikalnym stylem wizualnym, wymaganiami audio i grupą docelową. Ta sama podstawowa technologia dostosowuje się do zupełnie różnych kierunków twórczych.
- Teledysk niezależnego muzyka
Możliwości: Niezależni muzycy od dawna borykają się z bolesną dysproporcją – różnicą między jakością muzyczną a jakością treści wizualnych. Producent muzyczny pracujący w swoim pokoju może stworzyć dopracowane, gotowe do wydania utwory na laptopie, ale wyprodukowanie pasującego teledysku kosztuje zazwyczaj od 2000 do 15 000 funtów. Nawet najbardziej podstawowe nagranie wiąże się z wysokimi kosztami. Generowanie teledysków za pomocą sztucznej inteligencji całkowicie wyeliminowało tę barierę kosztową.
Wyjątkowa wartość w Chinach: W ostatnich latach krajowa scena muzyczna niezależnych wykonawców (hip-hop, muzyka elektroniczna, tradycyjna chińska, folk) przeżywa rozkwit. Liczba niezależnych artystów na platformach NetEase Cloud Music i QQ Music stale rośnie, jednak zdecydowana większość ich utworów istnieje wyłącznie w formie ścieżek audio bez towarzyszących im teledysków. Na platformie muzycznej Bilibili utwory zawierające wysokiej jakości materiały wizualne otrzymują znacznie wyższą wagę rekomendacji niż te, które oferują tylko audio i statyczne okładki. Teledyski AI umożliwiają każdemu niezależnemu muzykowi tworzenie dzieł wizualnych.
Procedura: Prześlij gotowy utwór do Seedance jako referencję audio. Stwórz wizualne wskazówki, które oddają emocjonalny przebieg utworu – nie ilustrują scenę po scenie tekstu piosenki, ale wywołują te same uczucia. Psychodeliczny pop nadaje się do miękkich, eterycznych i płynnych wizualizacji. Kompozycje lo-fi dobrze komponują się z ciepłymi, nostalgicznymi scenami miejskimi. Eksperymentalna muzyka elektroniczna pasuje do abstrakcyjnych, surrealistycznych obrazów. Muzyka w stylu chińskim uzupełnia pejzaże malowane tuszem, starożytną architekturę i sceny opadających płatków kwiatów.
Najlepsze praktyki dotyczące samodzielnych teledysków: Jeśli utwór składa się z wyraźnych części, warto rozważyć produkcję segmentową. Stwórz jeden styl wizualny dla zwrotki, drugi dla refrenu i trzeci dla mostka. Następnie połącz je za pomocą przejść w oprogramowaniu do edycji, takim jak ShineVideo lub DaVinci Resolve. Każda część ma swoją własną tożsamość wizualną, a muzyka zapewnia ciągłość.
Rozsądne oczekiwania: Do 2026 r. teledyski generowane przez sztuczną inteligencję będą się wyróżniać stylizowaną, klimatyczną i abstrakcyjną oprawą wizualną. Będą mniej skuteczne w przypadku teledysków narracyjnych lub opartych na występach, wymagających od konkretnych aktorów wykonywania choreografii lub kręcenia w określonych lokalizacjach w świecie rzeczywistym. Wykorzystaj mocne strony sztucznej inteligencji: klimat, surrealizm i poezję wizualną.
- Teledyski z tekstami piosenek
Możliwości: Teledyski z tekstami piosenek stały się standardowym formatem wydawniczym – często pojawiają się przed oficjalnymi teledyskami lub wraz z nimi. Zwiększają one liczbę odtworzeń w serwisach streamingowych, są dostosowane do potrzeb słuchaczy zainteresowanych tekstami piosenek i stanowią pierwszy punkt kontaktu wizualnego z nowymi utworami. Tradycyjna produkcja teledysków z tekstami piosenek wymaga projektowania grafiki ruchowej, animacji tekstu i wizualizacji tła. Sztuczna inteligencja upraszcza ten proces do podpowiedzi i nakładania tekstu.
Procedura: Wygeneruj atmosferyczne pętle wizualne, które pasują do nastroju utworu. Po wyeksportowaniu dodaj nakładki z tekstem piosenki w aplikacjach takich jak Kinevision, After Effects lub Canva Video. Sztuczna inteligencja zajmie się tłem wizualnym, a Ty typografią.
Najlepsza praktyka: Stosuj powolne, płynne ruchy kamery, które nie konkurują o uwagę z tekstem. Unikaj scen, w których panuje wizualny bałagan – teksty piosenek muszą pozostać wyraźnie czytelne na tle. Twórz wizualizacje przy użyciu schematu kolorów, który zapewnia dobry kontrast z wybranym kolorem tekstu. Publikując teledyski z tekstami piosenek na Bilibili i NetEase Cloud Music, pamiętaj o synchronizacji przesyłania plików na odpowiednie platformy muzyczne, aby uzyskać podwójną ekspozycję.
- Filmy z muzyką w tle na Bilibili/YouTube
Możliwości: „Muzyka lo-fi do nauki”, „dźwięki deszczu sprzyjające zasypianiu”, „muzyka do medytacji” — kanały na Bilibili i YouTube generujące ogromną liczbę wyświetleń dzięki prostej formule: wysokiej jakości dźwięk w połączeniu z pętlą wizualną. Niektóre z największych kanałów muzycznych na YouTube są oparte wyłącznie na tym modelu. Równie popularne są sekcje „transmisje na żywo do nauki” i „biały szum” na Bilibili. Sztuczna inteligencja sprawia, że tworzenie zarówno dźwięku, jak i obrazu jest niezwykle proste.
Metoda: Stwórz zapętloną scenę wizualną — przytulny pokój, za oknem którego pada deszcz, nocną panoramę miasta i animowaną postać siedzącą przy biurku. Dodaj do tego rozbudowaną muzykę lo-fi lub ambientową wygenerowaną przez sztuczną inteligencję. Aby zoptymalizować film pod kątem YouTube, wyeksportuj go w formacie 16:9 i rozdzielczości co najmniej 1080p, dodając odpowiednie słowa kluczowe w tytule, opisie i tagach. W przypadku serwisu Bilibili dodaj tagi, takie jak „nauka”, „biały szum” lub „pomoc w zasypianiu”, i wybierz odpowiednią kategorię do przesłania.
Model przychodów: Najpopularniejsze kanały YouTube mogą zarabiać od 5000 do 50 000 dolarów miesięcznie (około 3600 do 36 000 funtów) wyłącznie z reklam. Chociaż zachęty dla twórców Bilibili są stosunkowo skromne, monetyzacja jest możliwa dzięki opłatom za członkostwo premium, udziałom w przychodach z konferencji i reklamom. Kluczem do sukcesu są regularne aktualizacje: regularne publikowanie treści i budowanie biblioteki treści pozwala algorytmowi działać skutecznie. Treści generowane przez sztuczną inteligencję sprawiają, że pojedynczy twórca może utrzymać rytm codziennego publikowania postów.
4. TikTok/Kuaishou/Xiaohongshu – krótkie teledyski muzyczne
Możliwości: TikTok, Kuaishou, Xiaohongshu, Instagram Reels, TikTok i YouTube Shorts przywiązują dużą wagę do treści wideo zawierających muzykę. Posty z dźwiękiem konsekwentnie generują znacznie większe zaangażowanie niż posty bez dźwięku lub zawierające wyłącznie tekst. Dla marek i twórców konsekwentne tworzenie krótkich treści wideo z podkładem muzycznym jest nieustannym maratonem. Sztuczna inteligencja skraca cykle produkcyjne z kilku godzin do zaledwie kilku minut.
Sposób działania: Stwórz 5–15-sekundowy film w formacie pionowym (9:16) i włącz tryb ścieżki dźwiękowej. Sztuczna inteligencja jednocześnie wygeneruje obraz i dopasowaną muzykę. Jeśli chcesz użyć popularnej muzyki z platformy, najpierw stwórz obraz, a następnie dodaj modną muzykę w tle w natywnym edytorze TikTok/Kuaishou. Jeśli chcesz mieć oryginalny dźwięk, pozwól sztucznej inteligencji stworzyć cały pakiet.
Zalecenia dotyczące krajowych platform krótkich filmów wideo:
- Douyin: Pierwsze 1-2 sekundy muszą zawierać element przyciągający uwagę. Należy używać słów, które wywołują natychmiastowy efekt wizualny – dramatyczne ujawnienia, odważne kolory lub nieoczekiwane ruchy. Douyin domyślnie ma włączony dźwięk, więc jakość audio ma znaczenie od pierwszej klatki.
- Kuaishou: Ke Ling (narzędzie AI Kuaishou) naturalnie współgra z ekosystemem Kuaishou. Jeśli Kuaishou jest Twoją główną platformą, rozważ połączony proces pracy: generowanie obrazów w Ke Ling i dodawanie dźwięku w Seedance.
- Xiaohongshu: Pionowe filmy w formacie 9:16 w połączeniu z nastrojową muzyką sprawdzają się wyjątkowo dobrze na Xiaohongshu. Artystyczne, terapeutyczne i zorientowane na ASMR treści muzyczne AI wyjątkowo dobrze pasują do bazy użytkowników Xiaohongshu.
- Wizualizacja podcastu
** Szansa: Twórcy podcastów stoją przed wyzwaniem związanym z dystrybucją. Ich treści mają charakter wyłącznie audio, ale główne platformy (Bilibili, YouTube, TikTok, Xiaohongshu) priorytetowo traktują materiały wideo. „Wizualizacja podcastów” — dynamiczna reprezentacja wizualna treści audio — rozwiązuje ten problem, nadając materiałom audio formę wizualną dostosowaną do platform wideo. Tradycyjna wizualizacja podcastów wymaga oprogramowania do tworzenia animacji i umiejętności projektowych. Sztuczna inteligencja generuje je automatycznie.
Sposób działania: Prześlij plik audio swojego podcastu do Seedance. Sztuczna inteligencja generuje dynamiczne efekty wizualne w odpowiedzi na dźwięk – intensywność, rytm i zmiany tonacji głosu powodują odpowiednie zmiany wizualne. Możesz też stworzyć wizualną wskazówkę odzwierciedlającą temat podcastu, a sztuczna inteligencja wygeneruje klimatyczną pętlę wizualną, która będzie towarzyszyć dźwiękowi.
Strategia Bilibili: Bilibili stało się jedną z największych chińskich platform z długimi filmami, gdzie wielu znanych podcasterów publikuje teraz swoje treści w wersji wideo. Generowane przez sztuczną inteligencję elementy wizualne pozwalają bez większego wysiłku zamienić zwykłe podcasty audio na filmy pasujące do Bilibili. Nawet proste pętle wizualne działają znacznie lepiej dla algorytmu rekomendacji Bilibili niż statyczne miniatury.
- Ścieżka dźwiękowa reklamy produktu
Możliwości: Filmy produktowe z dopasowaną muzyką osiągają znacznie wyższe współczynniki konwersji niż filmy produktowe bez dźwięku. Jednak licencjonowanie muzyki do użytku komercyjnego kosztuje od 500 do 5000 RMB za utwór, a zlecenie kompozytorom stworzenia ścieżki dźwiękowej na zamówienie okazuje się jeszcze droższe. Ścieżki dźwiękowe generowane przez sztuczną inteligencję eliminują zarówno koszty, jak i komplikacje związane z prawami autorskimi — generowana muzyka jest oryginalna i nadaje się do użytku komercyjnego.
Procedura: Wygeneruj treści wizualne zgodnie z procesem tworzenia filmów o produktach, a następnie włącz tryb ścieżki dźwiękowej, aby dodać pasującą muzykę. W przypadku prezentacji produktów premium wygeneruj kinową muzykę orkiestrową lub ambientową. W przypadku dynamicznych premier produktów wygeneruj energiczną muzykę elektroniczną. Sztuczna inteligencja automatycznie dopasowuje energię muzyczną do treści wizualnych.
Zalety związane z prawami autorskimi: Kluczową zaletą muzyki generowanej przez sztuczną inteligencję Seedance jest to, że jest ona oryginalna – nie jest próbką istniejących utworów chronionych prawami autorskimi. Eliminuje to ryzyko skarg dotyczących praw autorskich związanych z wykorzystaniem rozpoznawalnej muzyki w reklamach. W ramach płatnego planu zachowujesz prawa do komercyjnego wykorzystania wygenerowanego materiału, co umożliwia jego wykorzystanie w reklamach bez dodatkowych opłat związanych z prawami autorskimi. Umieszczając filmy produktowe na platformach e-commerce, takich jak Taobao, JD.com i Douyin Shop, nie musisz martwić się, że treści zostaną usunięte z powodu naruszenia praw autorskich do muzyki.
- Zwiastuny gier i aplikacji
Możliwości: Zwiastuny gier i filmy prezentujące aplikacje w dużym stopniu opierają się na synchronizacji audiowizualnej. Dramatyczne pauzy przed pojawieniem się bossa, wielopoziomowy przebieg odliczania, odgłosy potężnych umiejętności – te momenty istnieją na styku dźwięku i obrazu. Zwiastuny generowane przez sztuczną inteligencję umożliwiają niezależnym twórcom gier i aplikacji osiągnięcie jakości produkcji porównywalnej z tą oferowaną przez studia AAA.
Sposób działania: Ustaw tryb ścieżki dźwiękowej na „Cinematic” lub „Drama”, aby wygenerować dramatyczne, pełne energii sekwencje wizualne. Skomponuj podpowiedzi opisujące akcję, wpływ i spektakularne efekty wizualne. Prześlij zrzuty ekranu z gry lub grafiki koncepcyjne jako obrazy referencyjne, aby zachować spójność wizualną z rzeczywistym produktem. Nakładaj elementy interfejsu użytkownika, materiały z rozgrywki i adnotacje tekstowe podczas postprodukcji.
Nacisk na dźwięk: Zwiastuny gier to jedno z najważniejszych zastosowań jakości dźwięku. Ścieżka dźwiękowa musi budować napięcie warstwa po warstwie, osiągać punkt kulminacyjny w odpowiednim momencie i kończyć się satysfakcjonującym rozwiązaniem. Jeśli początkowa kompozycja AI nie pasuje do rytmu zwiastuna, wygeneruj ją ponownie lub użyj samodzielnych narzędzi muzycznych AI, aby stworzyć utwór na zamówienie, a następnie zaimportuj go jako odniesienie audio. Podczas publikowania zwiastunów gier na platformach takich jak TapTap, sekcja gier Bilibili lub WeGame, wysokiej jakości synchronizacja audio-wizualna ma kluczowe znaczenie dla przyciągnięcia uwagi użytkowników.
8. Najważniejsze wydarzenia ślubne i eventowe
Możliwości: Osobiste filmy z wydarzeń – śluby, ukończenie szkoły, rocznice, urodziny – to najbardziej emocjonalne treści wideo, jakie tworzą ludzie. Profesjonalne nagrania z wydarzeń kosztują zazwyczaj od 500 do 3000 funtów w kraju. Wiele osób ma setki zdjęć z takich okazji, ale nie ma nagrań wideo. Sztuczna inteligencja może przekształcić te zdjęcia w kinowe filmy z podkładem muzycznym, tworząc profesjonalne efekty z migawek zrobionych telefonem komórkowym.
Metoda: Wybierz 10–20 najlepszych zdjęć z imprezy. Wykorzystaj funkcje Seedance do przekształcania obrazów w filmy, aby nadać każdemu zdjęciu subtelny ruch: delikatne powiększenia, łagodne przesunięcia obiektywu i zmieniające się efekty świetlne. Włącz tryb ścieżki dźwiękowej i opisz pożądany nastrój: „ciepły, emocjonalny, gitara akustyczna i fortepian, klimat pierwszego tańca weselnego”. Sztuczna inteligencja wygeneruje film dla każdego klipu z dopasowaną muzyką. Połącz je w kompletną kompilację za pomocą aplikacji do edycji.
Dlaczego to działa tak dobrze: Zdjęcia z wydarzeń mają z natury głębokie znaczenie emocjonalne dla osób, które się na nich znalazły. Dodanie subtelnego ruchu ożywia je. Połączenie ich z muzyką pasującą do nastroju sprawia, że wyglądają jak film. Ta kombinacja zmienia pokaz slajdów ze zdjęć w coś, co wygląda jak prawdziwy film, praktycznie bez żadnych kosztów w porównaniu z zatrudnieniem kamerzysty po wydarzeniu. Udostępnianie takich kompilacji na WeChat Moments lub TikTok daje znacznie lepsze rezultaty niż zwykła siatka dziewięciu zdjęć.
Szablon podpowiedzi do teledysku AI
Poniższe pięć szablonów podpowiedzi zostało zaprojektowanych dla konkretnych stylów teledysków. Każdy zestaw zawiera podpowiedzi wizualne, zalecane style audio i parametry generowania. Można je skopiować i używać bezpośrednio, dostosowując je w razie potrzeby do konkretnych projektów.
Uwaga: Wszystkie słowa podpowiedzi pozostają w oryginalnej angielskiej wersji językowej, ponieważ Seedance najlepiej rozumie podpowiedzi w języku angielskim. Do każdego szablonu dołączone są objaśnienia w języku chińskim.
Szablon pierwszy: Filmowy teledysk
Wskazówka wizualna:
A silhouette walking through neon rain on a deserted downtown street
at midnight. Puddles on the asphalt reflect towering LED billboards
in magenta, cyan, and gold. Steam rises from a subway grate, curling
through the neon light. The camera tracks slowly behind the figure,
maintaining a medium-wide shot. Rain streaks catch the colored light
like falling sparks. The figure pauses at a crosswalk, head tilted
upward toward the glowing signs. Cinematic anamorphic lens with
horizontal flares. Blade Runner atmosphere. Moody, contemplative,
visually rich. 4K ultra-realistic.Północ. Sylwetka przemierza opustoszałe ulice centrum miasta pod neonowym deszczem. Kałuże na asfalcie odbijają gigantyczne billboardy LED w kolorach magenta, cyjan i złoto. Para unosi się z otworów wentylacyjnych metra, wirując w neonowym blasku. Kamera powoli podąża za postacią. Anamorficzny obiektyw, atmosfera rodem z filmu Blade Runner.
Zalecany styl audio: kinowa muzyka synthwave lub ambientowa muzyka elektroniczna. Mroczne, pulsujące linie basu połączone z eterycznymi padami syntezatora. Wolne tempo (70–85 BPM). Przywołuje klimat połączenia Vangelisa i M83.
Parametry: proporcje obrazu 16:9. Czas trwania 10 sekund. Włączony tryb ścieżki dźwiękowej. Maksymalna dostępna rozdzielczość.
Odpowiednie scenariusze: Klimatyczne teledyski do muzyki elektronicznej, synth-popowej lub indie. Nadaje się również do filmowych krótkich filmów nastrojowych i filmów wizerunkowych marek. Szczególnie dobrze pasuje do sekcji muzycznej Bilibili i treści związanych z muzyką elektroniczną.
Szablon drugi: Marzycielski Lo-fi
Wskazówka wizualna:
Soft pastel clouds drifting over a quiet city at twilight, seen
through the rain-speckled window of a cozy apartment. A desk lamp
casts warm amber light over a cluttered workspace with vinyl records,
a steaming mug, and scattered handwritten notes. Raindrops trace
slow paths down the window glass. The city lights beyond are soft,
blurred circles of warm white and gentle orange. Camera holds a
static medium shot with extremely shallow depth of field focused on
the raindrops. The background city breathes with gentle, slow
ambient motion. Warm, nostalgic, intimate. Film grain. 24fps
cinematic quality.O zmierzchu, przez okno przytulnego mieszkania pokryte smugami deszczu, widać delikatne pastelowe chmury płynące nad spokojnym miastem. Lampa biurkowa rzuca ciepły, bursztynowy blask, oświetlając stół warsztatowy, na którym piętrzą się płyty winylowe, parujące filiżanki i porozrzucane odręczne notatki. Krople deszczu powoli spływają po szybie okna. Odległe światła miasta pojawiają się jako miękkie, rozmyte aureole ciepłej bieli i bladego pomarańczu. Ciepłe, nostalgiczne, intymne.*
Zalecany styl audio: Lo-fi hip-hop. Trzaski winylu, lekko rozstrojone akordy fortepianu, łagodne rytmy kick-snare, ciepły bas. Tempo: 70-80 BPM. Estetyka Chillhop Records.
Parametry: proporcje obrazu 16:9 lub 1:1. Czas trwania 10 sekund (przeznaczone do odtwarzania w pętli). Tryb ścieżki dźwiękowej: lo-fi/ambient. Idealne do transmisji na żywo w jakości lo-fi na Bilibili i YouTube przy odtwarzaniu w pętli.
Odpowiednie scenariusze: kanały muzyczne Lo-fi, treści pomagające w nauce/koncentracji/zasypianiu, relaksujące wizualizacje playlist oraz klimatyczne posty na Xiaohongshu. Takie treści cieszą się dużą popularnością w kategoriach „Study Live” i „White Noise” serwisu Bilibili.
Szablon trzeci: Wysoka energia
Wskazówka wizualna:
Fast-paced montage of urban sports and street culture. A skateboarder
launches off a concrete ledge in slow motion, wheels spinning, body
twisted mid-air. Quick cut to a BMX rider grinding a rail with
sparks flying. Cut to a basketball spinning on a fingertip against
a graffiti-covered wall. Each scene is lit by harsh, directional
afternoon sun creating sharp shadows. Colors are high-contrast and
saturated: electric blue sky, warm concrete orange, vivid graffiti
greens and pinks. Dynamic handheld camera with intentional shake.
Rapid scene transitions. 120fps slow-motion bursts within fast
editing. GoPro meets professional sports broadcast. 4K ultra-sharp.Chińska interpretacja: Szybka montażowa sekwencja przedstawiająca sporty miejskie i kulturę uliczną. Ujęcia w zwolnionym tempie pokazujące skateboardzistów wyskakujących z betonowych schodów, wirujące kółka i ciała skręcające się w powietrzu. Szybkie przejście do rowerzystów BMX ślizgających się po poręczach, z iskrami lecącymi w powietrzu. Przejście do piłki do koszykówki obracającej się na opuszkach palców przed ścianą z graffiti. Kontrastowe, nasycone kolory. Dynamiczna praca kamery z ręki, szybkie przejścia między scenami.
Zalecany styl audio: energetyczny hip-hop lub muzyka elektroniczna. Ciężki bas 808, hi-haty trapowe, agresywne uderzenia syntezatora. Tempo: 130-150 BPM. Styl produkcji Travisa Scotta. Bardzo dobrze pasują również krajowe style rapowe.
Parametry: 9:16 (TikTok/Kuaishou/Reels) lub 16:9 (Bilibili/YouTube). Czas trwania: 5–10 sekund. Włącz tryb SFX dla dźwięków uderzeń. Dodaj energiczną ścieżkę dźwiękową.
Odpowiednie scenariusze: treści związane z markami sportowymi, reklamy napojów energetycznych, kanały poświęcone sportom ekstremalnym oraz krzykliwe/teaserowe treści w mediach społecznościowych. Wyjątkowo dobrze sprawdza się w przypadku tagów sportowych i trendów w serwisie TikTok.
Szablon czwarty: Piosenka z tekstem
Wskazówka wizualna:
A single candle flickering in darkness on a weathered wooden table.
The flame casts warm, dancing golden light across the surface,
illuminating the grain and scratches in the old wood. A person's
hand slowly enters frame from the right, fingers gently hovering
near the flame without touching it. The hand trembles slightly. The
background is pure darkness with the faintest suggestion of a
window. The camera executes an imperceptibly slow push-in toward
the flame. Extreme shallow depth of field. The flame is razor-sharp
while even the fingertips soften into bokeh. Warm amber and deep
shadow color palette. Intimate, vulnerable, deeply human. 4K
photorealistic. 24fps film cadence.Opis w języku angielskim: Pojedyncza świeca migocze w ciemności na zniszczonym drewnianym stole. Płomień rzuca ciepły, tańczący złoty blask na blat stołu, oświetlając słoje i rysy starego drewna. Ręka powoli wkracza w kadr z prawej strony, palce unoszą się delikatnie obok płomienia, nie dotykając go. Ręka drży nieznacznie. Bardzo mała głębia ostrości. Płomień jest ostro zarysowany, podczas gdy opuszki palców są zamazane. Paleta kolorów składa się z ciepłych odcieni bursztynu i głębokich cieni. Intymność, kruchość, głębokie człowieczeństwo.
Zalecany styl audio: ballady fortepianowe lub gitara akustyczna w połączeniu z subtelnym akompaniamentem smyczków. Tonacje molowe. Bardzo wolne tempo (55-65 BPM). Produkcja przypominająca Adele lub Bon Iver. Oszczędne aranżacje, w których przestrzeń i cisza same w sobie stają się elementami muzycznymi. Idealnie pasowałyby również chińskie style ludowe.
Parametry: proporcje obrazu 16:9. Czas trwania 10 sekund. Tryb ścieżki dźwiękowej: emocjonalny/oryginalny. Maksymalna dostępna rozdzielczość. Ten szablon został zaprojektowany z myślą o wywołaniu emocji, a nie spektakularnych wrażeń wizualnych.
Odpowiednie scenariusze: teledyski balladowe, filmy upamiętniające/hołdowe, dramatyczne sceny filmowe, emocjonalne narracje marek i wizualizacje serii unplugged. W kategoriach folk/piosenki miłosne w serwisach NetEase Cloud Music i QQ Music ten styl wizualny wyjątkowo dobrze odpowiada oczekiwaniom odbiorców.
Szablon piąty: Vintage/Nostalgiczny
Wskazówka wizualna:
VHS-style footage of a summer road trip along a coastal highway.
A vintage convertible with sun-faded red paint cruises along a
winding cliffside road above a sparkling ocean. The driver's arm
hangs out the window, hand surfing the wind. Palm trees line the
inland side of the road. The footage has authentic VHS artifacts:
horizontal tracking lines, slight color bleeding at edges, warm
oversaturated hues shifted toward orange and teal, subtle scan-line
texture, and occasional tracking glitches. Shot from a following car
at the same speed, steady tracking shot. Late afternoon golden light.
The ocean glitters intensely in the background. Nostalgic, carefree,
endless summer. 480p upscaled aesthetic, 4:3 aspect ratio within a
16:9 frame with black side bars.Nagranie w stylu VHS z letniej wycieczki samochodowej wzdłuż wybrzeża. Zabytkowy kabriolet z wyblakłą czerwoną farbą jedzie wzdłuż drogi na szczycie klifu, a poniżej rozciąga się lśniący ocean. Ręka kierowcy wystaje przez okno, a dłoń surfuje na wietrze. Nagranie zawiera autentyczne artefakty VHS: poziome linie śledzenia, subtelne rozmycie kolorów na krawędziach oraz przesycone ciepłe odcienie przechodzące w pomarańczowy i cyjan. Nostalgiczne, beztroskie, wieczne lato.
Zalecany styl muzyczny: indie surf rock lub dream pop. Gitary z efektem pogłosu, skoczne linie basu, jasne brzmienie tamburynu. Tempo: 110–120 BPM. Wyobraź sobie połączenie The Beach Boys i Tame Impala. Alternatywnie, bardziej elektroniczny kierunek z syntezatorami vaporwave/retro. Idealnie pasowałby również chiński pop retro (np. City Pop).
Parametry: proporcje obrazu 16:9 (z uwzględnieniem estetyki VHS 4:3). Czas trwania 10 sekund. Tryb ścieżki dźwiękowej: retro/indie. Ten szablon celowo wykorzystuje estetykę lo-fi — nie generuj go w maksymalnej rozdzielczości, a następnie nie stosuj efektów VHS; zamiast tego pozwól sztucznej inteligencji stworzyć styl vintage.
Odpowiednie scenariusze: nostalgiczne/retro teledyski, wizualizacje letnich playlist, treści inspirowane stylem vintage, sekwencje filmowe o dorastaniu oraz treści w stylu retro na Xiaohongshu. Estetyka vintage cieszy się niezmienną popularnością wśród młodych twórców w Chinach, a na Xiaohongshu i Bilibili pojawia się znaczna ilość treści oznaczonych tagami „filmowy” i „retro”.
Porównanie najlepszych narzędzi do tworzenia teledysków z wykorzystaniem sztucznej inteligencji
Nie wszystkie generatory wideo oparte na sztucznej inteligencji posiadają funkcje audio, a wśród tych, które je posiadają, zestawy funkcji różnią się znacznie. Poniżej znajduje się bezpośrednie porównanie wszystkich narzędzi związanych z produkcją teledysków według stanu na luty 2026 r.

Krajobraz funkcji audiowizualnych w 2026 r. Seedance 2.0 przoduje pod względem kompletności funkcjonalnej, podczas gdy każdy z konkurentów ma swoje specyficzne mocne strony. Właściwy wybór zależy od podstawowego scenariusza użytkowania.
Tabela porównawcza
| Narzędzie | Generowanie dźwięku | Ścieżka dźwiękowa | Synchronizacja ruchu warg | Najwyższa jakość wideo | Najlepsze dla | Cena początkowa | Dostępne w Chinach | |------|:---:|:---:|:---:|---|-- -|---|:---:| | Seedance 2.0 | Obsługiwane | Obsługiwane | Obsługiwane (8 języków) | 2K, maks. 2 minuty | Pełna produkcja teledysku | Dostępna wersja bezpłatna | Możliwość bezpośredniego użycia | | Google Veo 3 | Obsługiwane | Częściowo | Nieobsługiwane | 1080p | Sceny z dźwiękiem otoczenia | Za pośrednictwem narzędzi AI Google | Wymagane VPN | | Pika 2.0 | Podstawowe | Nieobsługiwane | Nieobsługiwane | 1080p | Proste dodawanie efektów dźwiękowych | Dostępna wersja bezpłatna | Wymagane VPN | | Kaiber | Nieobsługiwane | Nieobsługiwane (przy użyciu przesłanego audio) | Nieobsługiwane | 1080p | Wizualizacja muzyki dla przesłanych utworów | Około 10 USD/miesiąc (ok. 72 GBP) | Wymagane VPN | | Suno + Seedance | Przez Seedance | Przez Suno | Przez Seedance | 2K (Seedance) | Najlepsza kombinacja muzyki AI + najlepszego wideo AI | Suno bezpłatne + Seedance bezpłatne | Seedance dostępne bezpośrednio | | SkyMusic + Seedance | Przez Seedance | Przez SkyMusic | Przez Seedance | 2K (Seedance) | Najlepsze w Chinach połączenie muzyki AI + wideo AI w całości w języku chińskim | SkyMusic bezpłatne + Seedance bezpłatne | W pełni dostępne w Chinach |
Seedance 2.0: najbardziej kompleksowe rozwiązanie audiowizualne
Seedance to jedyna platforma obsługująca wszystkie trzy rodzaje generowania materiałów audiowizualnych – efekty dźwiękowe, podkłady muzyczne i synchronizację ruchu warg – w ramach jednego narzędzia. Dla twórców teledysków oznacza to możliwość generowania nastrojowych obrazów z ambientowymi pejzażami dźwiękowymi, dodawania dopasowanych podkładów muzycznych i synchronizowania śpiewu z ruchem warg postaci, a wszystko to bez opuszczania platformy.
Najważniejsze cechy produkcji MV:
- Trzy tryby audio (efekty dźwiękowe, muzyka, głos) wybierane podczas generowania
- 8 języków z synchronizacją ruchu warg (w tym chiński), obsługujące wielojęzyczną dystrybucję MV
- Wejście referencyjne audio: prześlij swój utwór, aby wygenerować wizualizacje zsynchronizowane z muzyką
- Wiele proporcji obrazu, w tym 9:16 dla krótkich treści MV
- Maksymalny czas generowania wynosi 2 minuty i obejmuje całe segmenty utworu
- Konwersja obrazu na wideo: animuj okładki albumów lub statyczne koncepcje
Ekskluzywne korzyści dla użytkowników krajowych: – opracowany przez ByteDance, dostępny bezpośrednio w Chinach bez VPN – obsługuje Alipay/WeChat Pay, brak barier dla płatnych aktualizacji – synchronizacja ruchu warg w języku chińskim ma kluczowe znaczenie dla tworzenia krajowych teledysków – wszystkie funkcje dostępne w wersji bezpłatnej
Pozycjonowanie: Seedance to najlepsze zintegrowane rozwiązanie dla twórców, którzy chcą zrealizować cały proces produkcji teledysku za pomocą jednego narzędzia. Połączenie wysokiej jakości obrazu i wszechstronnych funkcji audio pozostaje bezkonkurencyjne.
Stwórz swój teledysk za pomocą Seedance 2.0 już teraz -->
Google Veo 3: Potężny natywny dźwięk
Veo 3 generuje filmy z natywnym dźwiękiem, uwzględniając odgłosy otoczenia, szumy atmosferyczne i pewien stopień akompaniamentu muzycznego. Jakość dźwięku jest imponująca – dane szkoleniowe Google i skala modelu zapewniają bogate, wielowarstwowe pejzaże dźwiękowe. Sceny plażowe brzmią naprawdę jak plaże, z falami w odpowiedniej odległości, wiatrem o odpowiedniej intensywności i odgłosami ptaków morskich w wiarygodnych odstępach czasu.
Zaleta: Realistyczny dźwięk otoczenia. Veo 3 zapewnia najbardziej autentyczne brzmienie w swojej klasie.
Ograniczenia w produkcji teledysków: Veo 3 nie oferuje tak szczegółowej kontroli dźwięku jak Seedance. Nie można wybierać między trybami efektów dźwiękowych/muzyki/głosu, nie ma funkcji synchronizacji ruchu warg, nie można też przesyłać własnych ścieżek dźwiękowych jako odniesienia. W przypadku produkcji teledysków ten brak elastyczności ogranicza Veo 3 do filmów atmosferycznych/środowiskowych z towarzyszącym dźwiękiem, a nie do tworzenia ustrukturyzowanych teledysków. Ponadto dostęp z terytorium kraju wymaga VPN, co stanowi dodatkową barierę wejścia. Szczegółowe porównanie funkcji można znaleźć w artykule Seedance vs Veo 3 – szczegółowe porównanie.
Pika 2.0: Podstawowe efekty dźwiękowe
Funkcja efektów dźwiękowych Pika dodaje dźwięki otoczenia do generowanych filmów. Jest to przydatne uzupełnienie narzędzia, które wcześniej było wyłącznie wizualne, choć jego możliwości pozostają ograniczone w porównaniu z Seedance i Veo 3. Generowanie efektów dźwiękowych obejmuje podstawowe dźwięki otoczenia — kroki, odgłosy wody, odgłosy wiatru, proste uderzenia — ale nie obejmuje generowania muzyki i synchronizacji ruchu warg.
Zalety: Dodaje proste efekty dźwiękowe do krótkich klipów. Jeśli potrzebujesz pięciosekundowej sceny deszczu z dopasowanymi odgłosami opadów, Pika sobie z tym poradzi.
Ograniczenia: Brak możliwości generowania muzyki, synchronizacji ruchu warg oraz przesyłania plików audio. Do produkcji teledysków samo oprogramowanie Pika nie wystarczy — aby uzyskać pełny efekt, należy je połączyć z zewnętrznymi narzędziami audio. Wymaga VPN.
Kaiber: Specjalista ds. wizualizacji muzyki
Kaiber stosuje inne podejście niż pozostałe narzędzia z tej listy. Zamiast generować dźwięk z wideo, tworzy wideo z dźwięku. Wystarczy przesłać utwór muzyczny, a Kaiber generuje abstrakcyjne, stylizowane animacje wizualne reagujące na treść muzyczną – klatki pulsujące w rytm muzyki, kolory zmieniające się wraz ze zmianami harmonicznymi oraz intensywność odwzorowana na głośność.
Zalety: Abstrakcyjna wizualizacja muzyki. Jeśli Twoim celem jest stworzenie psychodelicznych, abstrakcyjnych wizualizacji reagujących na rytm utworu muzyki elektronicznej, Kaiber jest stworzony właśnie do tego celu.
Ograniczenia: Kaiber nie generuje dźwięku — wymaga przesłania plików audio. Wyjście wideo jest wysoce stylizowane (abstrakcyjne/artystyczne), a nie fotorealistyczne. Nie może tworzyć scen narracyjnych, postaci ani realistycznych środowisk. W przypadku pełnej produkcji teledysku wymagającej autentycznego materiału filmowego Kaiber jest raczej narzędziem niszowym niż kompletnym rozwiązaniem. Wymaga VPN.
Współpraca Suno / SkyMusic + Seedance: Esencja dwóch światów
Dla twórców, którzy chcą mieć maksymalną kontrolę nad muzyką i obrazem w swoich pracach, najlepszym rozwiązaniem jest połączenie profesjonalnego generatora muzyki AI z profesjonalnym generatorem wideo AI.
Skład edycji międzynarodowej — Suno + Seedance:
- Stwórz swój utwór w Suno: Opisz gatunek, nastrój, tempo i aranżację. Suno tworzy kompletne, wysokiej jakości utwory muzyczne, w razie potrzeby z wokalem.
- Prześlij utwór do Seedance jako referencję audio: Generator wideo AI tworzy wizualizacje dostosowane do struktury muzyki — sceny nasilają się podczas crescendo, a wyciszają podczas spokojniejszych fragmentów.
- W razie potrzeby skorzystaj z funkcji synchronizacji ruchu warg: Jeśli utwór Suno zawiera wokal i chcesz, aby postacie śpiewały, użyj trybu synchronizacji ruchu warg Seedance, aby dopasować ruchy ust do ścieżki wokalnej.
Pakiet edycji krajowej — SkyMusic + Seedance:
Ta kombinacja zapewnia chińskim twórcom najbardziej płynny proces tworzenia teledysków z wykorzystaniem sztucznej inteligencji — obie platformy są bezpośrednio dostępne w Chinach i nie wymagają korzystania z VPN.
- Stwórz swój utwór w SkyMusic: SkyMusic wyróżnia się szczególnie w generowaniu chińskich tekstów piosenek, obsługując różnorodne chińskie gatunki muzyczne, w tym rap, pop i style inspirowane muzyką klasyczną.
- Prześlij swój utwór do Seedance jako referencję audio: Seedance generuje pasujące wizualizacje na podstawie treści muzycznej.
- Synchronizacja ruchu warg w języku chińskim: Wykorzystaj możliwości Seedance w zakresie synchronizacji ruchu warg w języku chińskim, aby postacie precyzyjnie wykonywały Twoje chińskie teksty piosenek.
Zaletą tego sposobu pracy jest to, że zyskujesz jakość muzyczną profesjonalnej sztucznej inteligencji muzycznej w połączeniu z możliwościami wizualnymi i synchronizacyjnymi profesjonalnej sztucznej inteligencji wideo. Kompromisem jest konieczność korzystania z dwóch narzędzi zamiast jednego. Dla twórców dążących do uzyskania profesjonalnych rezultatów ten dodatkowy krok jest całkowicie opłacalny.
Zaawansowane: Techniki osiągania synchronizacji ruchu warg
Po opanowaniu podstawowych zasad pracy, poniższe zaawansowane techniki pomogą Ci osiągnąć poziom koordynacji audiowizualnej w teledyskach, który stanowi granicę między profesjonalnymi a amatorskimi produkcjami.
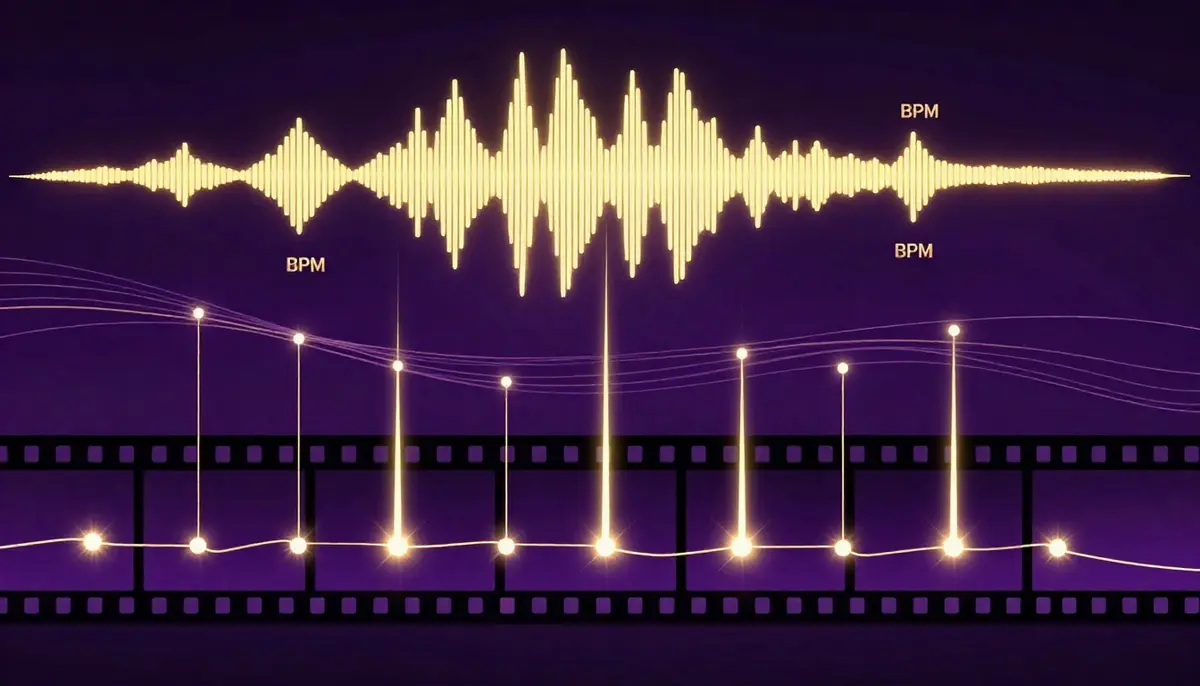
Zaawansowana synchronizacja to nie tylko generowanie dźwięku i obrazu razem. Oznacza ona świadome dopasowanie rytmu wizualnego, nastroju i struktury do kompozycji muzycznej w celu uzyskania spójnego wrażenia audiowizualnego.
Dopasowanie BPM: Dostosowanie rytmu wizualnego do tempa muzycznego
BPM (uderzenia na minutę) to rytm każdego utworu muzycznego. Gdy treść wizualna porusza się w synchronizacji z rytmem muzyki, efekt jest zamierzony i profesjonalny. Gdy te dwa elementy nie są dopasowane, sprawia to wrażenie, jakby dwie niepowiązane ze sobą rzeczy odtwarzały się jednocześnie.
Jak osiągnąć dopasowanie BPM:
- Określ tempo utworu (BPM): Większość programów DAW (Ableton, Logic, FL Studio) automatycznie wyświetla tempo (BPM). Równie skuteczne są internetowe narzędzia do wykrywania tempa. Typowe zakresy: lo-fi (70–85 BPM), pop (100–130 BPM), EDM (120–150 BPM), drum and bass (160–180 BPM).
- Przekształć BPM na wizualną prędkość ruchu: Przy 120 BPM występują dokładnie dwa uderzenia na sekundę. Ruchy kamery, przejścia scen i cięcia wizualne występujące co pół sekundy będą wydawały się zsynchronizowane z rytmem.
- Zastosowanie języka sugerującego rytm: W przypadku utworów o tempie 130 BPM należy używać terminów takich jak „szybki”, „energiczny”, „dynamiczne przejścia”. W przypadku utworów o tempie 70 BPM należy wybrać terminy „powolny”, „płynny”, „delikatny”. Sztuczna inteligencja interpretuje te wskazówki rytmiczne i odpowiednio dostosowuje tempo wizualne.
- Dostosowanie w postprodukcji: Jeśli rytm wizualny AI jest zbliżony, ale nie idealnie dopasowany do rytmu, wprowadź poprawki w edytorze wideo. Przyspiesz lub spowolnij segmenty o 5–10%, aby dopasować wydarzenia wizualne do znaczników rytmu. Takie dostosowanie daje widoczną różnicę. Zarówno ShineVideo, jak i DaVinci Resolve obsługują tak precyzyjne regulacje prędkości.
Synchronizacja emocjonalna: fragmenty muzyczne dopasowane do atmosfery wizualnej
Profesjonalne teledyski nie zachowują spójnego tonu wizualnego przez cały czas. Zmieniają atmosferę, aby dopasować się do emocjonalnego przebiegu utworu. Generowanie AI umożliwia tworzenie tych przejść poprzez generowanie odrębnych segmentów przy użyciu zróżnicowanych podpowiedzi wizualnych.
Odpowiedniość struktury muzycznej do atmosfery wizualnej:
| Sekcja utworu | Charakterystyka muzyczna | Kierunek wizualny | |-------- -|---------|---------| | Intro | Oszczędne, stopniowe | Minimalistyczna oprawa wizualna, stonowane kolory, zwolnione tempo. Budowanie atmosfery. | | Zwrotka | Narracyjna, średnia energia | Sceny oparte na fabule, umiarkowane tempo, ciepła lub neutralna paleta kolorów | | Przed refrenem | Warstwowa progresja | Intensyfikacja ruchu kamery, zwiększona nasycenie kolorów, większa złożoność wizualna | | Refren | Szczyt energii/emocji | Najbardziej dramatyczna oprawa wizualna, najodważniejsze kolory, dynamiczne ujęcia, spektakularne efekty wizualne | | Przejście | Przejście/refleksja | Całkowicie odmienny styl wizualny. Nowa paleta kolorów. Wolniejsze tempo. | | Coda | Zbieżność, wyciszenie | Powrót do stylu wizualnego intro z poczuciem rozwiązania. Zmiękczenie. Wyciszenie. |
Generuj osobne podpowiedzi dla każdego akapitu, a następnie edytuj je i połącz ze sobą. Takie segmentowe podejście daje bardziej dynamiczny efekt, który lepiej uzupełnia muzykę w porównaniu z generowaniem jednego długiego fragmentu.
Segmentowane generowanie: Twórz odrębne elementy wizualne dla refrenu, zwrotki i mostu.
W oparciu o koncepcję synchronizacji emocjonalnej, praktyczna technika generowania segmentów polega na tworzeniu niezależnych segmentów wideo AI dla każdego fragmentu muzycznego, a następnie łączeniu ich w edytorze osi czasu.
Przebieg pracy:
- Przeanalizuj strukturę utworu. Oznacz znaczniki czasu dla każdej sekcji (zwrotka 1: 0:00-0:30, refren 1: 0:30-0:55, zwrotka 2: 0:55-1:25 itd.)
- Napisz unikalne podpowiedzi wizualne dla każdej sekcji. Zachowaj wizualną ciągłość poprzez spójne opisy stylistyczne (identyczne schematy kolorów, wspólne słowa kluczowe dotyczące jakości wizualnej), jednocześnie zmieniając sceny, ujęcia i poziomy energii
- Utwórz oddzielne klipy dla każdej sekcji w Seedance. Dopasuj czas trwania klipu do długości sekcji
- Zaimportuj wszystkie klipy do oprogramowania do edycji wideo (ShineVideo, DaVinci Resolve, Premiere). Dopasuj każdy klip do odpowiadającej mu sekcji muzycznej.
- Dodaj przejścia między sekcjami: crossfade dla płynnych przejść, twarde cięcia dla dramatycznych zmian i szybkie panoramowanie dla przejść o wysokiej energii.
- Wyeksportuj zmontowaną oś czasu jako ostateczną wersję teledysku.
Ta metoda zapewnia największą kontrolę nad relacją między dźwiękiem a obrazem. Chociaż wymaga większego nakładu pracy niż praca z jednym pokoleniem, wyniki są znacznie bardziej dynamiczne i lepiej dopasowane do muzyki.
Film referencyjny: Wykorzystanie istniejących stylów teledysków jako danych wejściowych
Jeśli istnieje teledysk, którego styl wizualny, ruchy kamery lub rytm montażu podziwiasz, możesz wykorzystać go jako punkt odniesienia dla generowania przez sztuczną inteligencję.
Jak korzystać z referencyjnego MV:
- Wybierz teledysk lub klip wideo, który odzwierciedla pożądany styl wizualny.
- Prześlij go jako film referencyjny w Seedance.
- Sztuczna inteligencja analizuje ruch kamery, kompozycję, kolorystykę, rytm montażu i dynamikę ruchu w filmie referencyjnym.
- Wygenerowany wynik dziedziczy te elementy stylistyczne, tworząc jednocześnie całkowicie oryginalną treść.
Technika ta okazuje się szczególnie przydatna, gdy klienci lub współpracownicy mówią: „Chcę uzyskać efekt podobny do tego filmu” – można bezpośrednio wykorzystać ich odniesienie jako punkt wyjścia, zamiast próbować przełożyć ich wizję na język podpowiedzi.
Ważna uwaga: Sztuczna inteligencja generuje oryginalne treści wizualne inspirowane stylem referencyjnym. Nie powiela ani nie reprodukuje referencyjnego materiału wideo. Wynikiem jest unikalna treść, która ma wspólne elementy stylistyczne z materiałem referencyjnym.
Często zadawane pytania
Czy sztuczna inteligencja naprawdę może stworzyć kompletny teledysk?
Oczywiście, ale należy zrozumieć znaczenie słowa „kompletny” w kontekście roku 2026. Sztuczna inteligencja może generować klipy wideo z zsynchronizowanym dźwiękiem – w tym efektami dźwiękowymi, muzyką w tle i zsynchronizowanym z ruchem warg wokalem – które wyglądają i brzmią profesjonalnie. W przypadku klimatycznych, stylizowanych lub abstrakcyjnych teledysków trwających od 30 sekund do 2 minut, materiały wygenerowane przez sztuczną inteligencję mogą być rzeczywiście publikowane bezpośrednio. W przypadku dłuższych, narracyjnych teledysków wymagających konkretnych aktorów i złożonej choreografii, sztuczna inteligencja doskonale sprawdza się w produkcji wysokiej jakości surowego materiału filmowego, choć znacznie korzysta z ludzkiej edycji, sekwencjonowania i postprodukcji. Technologię tę najlepiej rozumieć jako narzędzie produkcyjne obsługujące 80–90% nakładu pracy, a nie jako zamiennik całego zespołu produkcyjnego za jednym kliknięciem.
Który generator teledysków oparty na sztucznej inteligencji będzie najlepszy w 2026 roku?
Seedance 2.0 to najbardziej wszechstronny generator teledysków oparty na sztucznej inteligencji z 2026 roku. W unikalny sposób łączy on w jednym narzędziu wszystkie trzy podstawowe funkcje audiowizualne: generowanie efektów dźwiękowych, tworzenie ścieżek dźwiękowych opartych na sztucznej inteligencji oraz wielojęzyczną synchronizację ruchu warg (w ośmiu językach, w tym chińskim). — w połączeniu z wysokiej jakości generowaniem obrazu (rozdzielczość do 2K, czas trwania 2 minuty). Chińscy użytkownicy odnoszą dodatkowe korzyści: jako produkt ByteDance, Seedance jest bezpośrednio dostępny w Chinach i obsługuje Alipay oraz WeChat Pay. Google Veo 3 wyróżnia się dźwiękiem otoczenia, ale nie ma synchronizacji ruchu warg i wymaga VPN. Pika zapewnia tylko podstawowe efekty dźwiękowe. Kaiber specjalizuje się w abstrakcyjnej wizualizacji muzyki.
Czy trzeba mieć własną muzykę, aby tworzyć teledyski AI?
Nie jest to konieczne. Masz trzy opcje. Po pierwsze, skorzystaj z wbudowanej funkcji generowania ścieżki dźwiękowej w Seedance, aby sztuczna inteligencja tworzyła jednocześnie efekty wizualne i muzykę. Po drugie, skorzystaj z bezpłatnych generatorów muzyki opartych na sztucznej inteligencji (takich jak międzynarodowy Suno lub krajowe alternatywy, takie jak SkyMusic i NetEase Tianyin), aby stworzyć oryginalne utwory, a następnie zaimportuj je do Seedance jako referencje audio. Po trzecie, prześlij własną oryginalną lub licencjonowaną muzykę. Wszystkie trzy podejścia zapewniają kompletne efekty audiowizualne. Wybór zależy od tego, jak dużą kontrolę chcesz mieć nad efektem muzycznym.
Jak wykorzystuje się synchronizację ruchu warg za pomocą sztucznej inteligencji w teledyskach?
Analiza synchronizacji ruchu warg przez sztuczną inteligencję bada zawartość audio ścieżek wokalnych — identyfikując, które fonemy występują w określonych momentach — i generuje odpowiednie kształty ust, pozycje szczęki i mikroekspresje twarzy postaci wideo. W przypadku śpiewania oznacza to, że usta postaci otwierają się szerzej przy wysokich tonach i samogłoskach, zwężają się przy spółgłoskach i zachowują zgodność czasową z rytmem wokalnym. Seedance obsługuje synchronizację ruchu warg w ośmiu językach (w tym chińskim), dostosowując słownictwo ust do systemu fonetycznego każdego języka. Chińska synchronizacja ruchu warg umożliwia postaciom AI precyzyjne wykonywanie chińskich tekstów piosenek, uwalniając ogromny potencjał twórczy społeczności coverów piosenek i anime Bilibili. Optymalne wyniki osiąga się dzięki wyraźnym ścieżkom wokalnym o umiarkowanym tempie i minimalnych zakłóceniach instrumentalnych.
Czy muzyka generowana przez sztuczną inteligencję może być wykorzystywana komercyjnie?
Na platformie Seedance – tak. Muzyka generowana w Seedance stanowi oryginalną treść stworzoną przez sztuczną inteligencję – nie jest to sample ani utwory pochodzące z utworów chronionych prawem autorskim. W ramach płatnego abonamentu zachowujesz prawa do komercyjnego wykorzystania wygenerowanych treści, w tym komponentów audio. Oznacza to, że możesz zarabiać na filmach muzycznych wygenerowanych przez sztuczną inteligencję na Bilibili/YouTube, wykorzystywać je w reklamach komercyjnych i rozpowszechniać na różnych platformach bez obaw o naruszenie praw autorskich.
Ważne uwagi dotyczące chińskiego kontekstu prawnego: Zgodnie z chińskimi tymczasowymi środkami dotyczącymi zarządzania usługami generatywnej sztucznej inteligencji, podczas wykorzystywania treści generowanych przez sztuczną inteligencję do celów komercyjnych należy bezwzględnie upewnić się, że treści te nie naruszają praw własności intelektualnej innych podmiotów. Ponadto w określonych sytuacjach może być konieczne oznaczenie treści jako generowanych przez sztuczną inteligencję. Przed wdrożeniem na dużą skalę w celach komercyjnych zaleca się zapoznanie się z najnowszymi wymogami polityki. Należy zawsze sprawdzać szczegółowe warunki korzystania z narzędzi, z których się korzysta, ponieważ postanowienia dotyczące licencji różnią się w zależności od platformy.
Jak długie mogą być teledyski tworzone przez sztuczną inteligencję?
Seedance obsługuje generowanie klipów o długości do 2 minut. W przypadku dłuższych teledysków zalecamy stosowanie podejścia segmentowego: utwórz oddzielne klipy dla różnych fragmentów utworu (zwrotki, refreny, mostki), a następnie połącz je w edytorze wideo. Piosenka trwająca 3-4 minuty wymaga zazwyczaj 3-6 niezależnie wygenerowanych segmentów. Takie podejście segmentowe daje lepsze wyniki w porównaniu z pojedynczym, rozbudowanym generowaniem, ponieważ każdy segment otrzymuje własny, zoptymalizowany bodziec wizualny.
Jaka jest jakość dźwięku w teledyskach generowanych przez sztuczną inteligencję?
Jakość dźwięku generowanego przez sztuczną inteligencję osiągnęła obecnie standard odpowiedni do dystrybucji online na wszystkich głównych platformach. Wynik jest dostarczany w jakości stereo CD (44,1 kHz, odpowiednik 16 bitów). Efektem jest czysty, dobrze zmiksowany dźwięk, wolny od wyraźnych artefaktów, które często towarzyszyły wcześniejszym systemom audio opartym na sztucznej inteligencji. Jeśli jednak Twoje treści są przeznaczone do profesjonalnych platform dystrybucji muzyki (NetEase Cloud Music, QQ Music, KuGou Music, Spotify, Apple Music), zaleca się przetworzenie części audio za pomocą specjalistycznych narzędzi muzycznych AI (takich jak Suno lub SkyMusic) przed zaimportowaniem jej do Seedance w celu generowania obrazu. Profesjonalne narzędzia muzyczne AI oferują obecnie nieco lepszą jakość dźwięku w porównaniu ze zintegrowanymi generatorami wideo-audio.
Jak zapobiegać desynchronizacji audio-wizualnej?
Istnieją trzy techniki, które pozwalają zminimalizować problemy z synchronizacją. Po pierwsze, poszczególne klipy powinny trwać mniej niż 30 sekund – krótsze segmenty zapewniają lepszą synchronizację. Po drugie, należy stosować wyraźne wskazówki rytmiczne w podpowiedziach wizualnych (np. „powolny, celowy ruch” dla wolnych utworów; „szybki, energiczny ruch” dla szybkich utworów), aby dostosować tempo wizualne do tempa audio. Po trzecie, jeśli w wynikach pojawią się niewielkie rozbieżności czasowe, należy dostosować synchronizację za pomocą oprogramowania do edycji wideo – przesunięcie ścieżki audio o 50–100 milisekund może skorygować zauważalną desynchronizację. Aby zapewnić dokładność synchronizacji ruchu warg, należy upewnić się, że źródłowy dźwięk jest czysty i wyraźny rytmicznie, ponieważ niejasna lub nakładająca się mowa stanowi większe wyzwanie dla precyzyjnej synchronizacji AI.
Jaką radę dałbyś osobom, które chcą publikować teledyski z wykorzystaniem sztucznej inteligencji na platformie Bilibili?
Bilibili to jedna z największych chińskich platform z długimi filmami i teledyskami. Przy publikowaniu teledysków stworzonych przez sztuczną inteligencję warto pamiętać o kilku ważnych rzeczach. Po pierwsze, wybierz odpowiednią kategorię – strefę muzyczną (kompilacje muzyczne/covery/muzyka oryginalna/muzyka elektroniczna) lub strefę parodii (jeśli treść ma charakter humorystyczny). Po drugie, należy stworzyć wysokiej jakości okładkę i tytuły, ponieważ algorytm rekomendacji Bilibili przywiązuje dużą wagę do współczynnika klikalności okładek. Po trzecie, należy dołączyć chińskie napisy/tekst piosenki, które nie tylko ułatwiają zrozumienie, ale są również domyślnym oczekiwaniem użytkowników Bilibili. Po czwarte, należy wyraźnie podać w opisie narzędzie do generowania AI, ponieważ społeczność Bilibili ceni sobie przejrzystość. Po piąte, należy wykorzystać funkcję kolumny Bilibili do publikowania towarzyszących tekstowych tutoriali dotyczących produkcji teledysków, które mogą generować dodatkowy ruch.
Zacznij tworzyć teledyski z wykorzystaniem sztucznej inteligencji już teraz
Zbieżność technologii AI wideo i AI audio nie jest przyszłościową możliwością, lecz rzeczywistością. Narzędzia już istnieją, a ich jakość osiąga standardy pozwalające na publikację w większości zastosowań, przy kosztach stanowiących jedynie ułamek kosztów tradycyjnej produkcji teledysków.
Niezależnie od tego, czy jesteś niezależnym muzykiem marzącym o profesjonalnym teledysku do swojej twórczości, twórcą treści budującym kanał muzyczny lo-fi na Bilibili, zespołem marketingowym potrzebującym podkładu muzycznego do filmów produktowych, czy też kimkolwiek, kto produkuje treści wideo wymagające akompaniamentu audio, ta technologia jest teraz gotowa dla Ciebie.
Kolejne kroki:
- Przejdź do Seedance Video Generation
- Prześlij swój utwór muzyczny (lub poproś AI o wygenerowanie go)
- Napisz podpowiedzi wizualne, które pasują do nastroju utworu
- Wybierz tryb audio (efekty dźwiękowe, ścieżka dźwiękowa lub synchronizacja ruchu warg)
- Wygeneruj swój pierwszy teledysk AI
- Opublikuj na Bilibili, TikTok, Xiaohongshu, NetEase Cloud Music
Stwórz swój pierwszy teledysk AI za darmo -->
Zarejestruj się teraz, aby otrzymać bezpłatne kredyty. Nie jest wymagana karta kredytowa. Płatne plany obejmują treści bez znaków wodnych. Pełne prawa do wykorzystania komercyjnego. Możliwość bezpośredniego wykorzystania w Chinach, obsługa Alipay/WeChat Pay.
Era niemych filmów AI dobiegła końca. Każdy film, który od teraz stworzysz, może mieć dźwięk, ścieżkę dźwiękową i duszę.
Więcej informacji: Czym jest generator wideo Seedance AI | Porównanie Seedance i Veo 3 | Kompletny przewodnik po sztucznej inteligencji tekst-wideo | Przewodnik po filmach AI dla twórców YouTube | Filmy AI dla filmów produktowych e-commerce | Przewodnik po poleceniach Seedance i przykłady | Porównanie najlepszych generatorów wideo AI na rok 2026*
