
W skrócie
Najskuteczniejszym sposobem tworzenia filmów AI nie jest po prostu wprowadzenie opisu do narzędzi zamieniających tekst na wideo. Zamiast tego zacznij od starannie przygotowanego obrazu.
Trójstopniowy proces — polecenie → obraz → wideo — daje wyniki znacznie przewyższające możliwości samego generowania tekstu do wideo. Najpierw należy stworzyć profesjonalne polecenie. Następnie należy użyć tego polecenia do wygenerowania obrazu o precyzyjnej kompozycji. Obraz ten należy następnie wprowadzić jako pierwszą klatkę do generatora wideo. W rezultacie uzyskuje się precyzyjną kontrolę nad treścią wizualną, atmosferą oświetlenia, szczegółami kompozycji i punktem początkowym ruchu.
Seedance to jedyne narzędzie integrujące wszystkie trzy etapy w ramach jednej platformy: Image Prompt Generator pomaga tworzyć profesjonalne podpowiedzi, Text-to-Image generuje wysokiej jakości obrazy referencyjne, a Image-to-Video przekształca zdjęcia w kinowe klipy wideo. Nie ma potrzeby przełączania się między narzędziami, pobierania i ponownego przesyłania plików – od inspiracji do gotowego dzieła wszystko odbywa się w jednym płynnym procesie.
Krok 1: Wygeneruj podpowiedź → | Krok 2: Wygeneruj obraz → | Krok 3: Wygeneruj wideo →

Po lewej: Generowanie czystego tekstu do wideo — losowa kompozycja, niekontrolowane efekty wizualne. Po prawej: Proces oparty na obrazie — najpierw dopracowuje się efekty wizualne, a następnie dodaje ruch; precyzyjna kompozycja, stała jakość.
Dlaczego „najpierw obraz, potem wideo” znacznie przewyższa konwersję tekstu na wideo
Ci, którzy korzystali z Wensheng Video, znają to doświadczenie: piszesz szczegółowy opis — obejmujący temat, oświetlenie, kąt kamery i kompozycję — ale materiał filmowy wygenerowany przez sztuczną inteligencję nie ma nic wspólnego z Twoją wizją. Postacie są zwrócone w złym kierunku, oświetlenie jest płaskie, kompozycje wydają się generowane losowo, a role nie pasują do opisu.
Nie jest to wada konkretnego narzędzia, ale raczej ograniczenie strukturalne związane z podejściem polegającym na przekształcaniu tekstu w wideo.
Nieodłączne ograniczenia tworzenia treści wideo
Wensheng Video wymaga od sztucznej inteligencji wykonania dwóch wyjątkowo trudnych zadań jednocześnie: generowania obrazów i generowania ruchu. Model musi zinterpretować tekst, określić wygląd każdego piksela, skomponować scenę, ustawić oświetlenie i cienie, ustalić pozycję kamery, a następnie wygenerować spójny ruch na podstawie wszystkich tych elementów — wszystko to na podstawie jednego fragmentu tekstu.
W rezultacie każdy wymiar wymyka się spod kontroli:
- Losowa kompozycja. Piszesz „kobieta stojąca na środku ulicy”, a ona pojawia się w lewej jednej trzeciej kadru, którego połowę zajmują niepotrzebne budynki.
- **Niespójne postacie. ** Struktura twarzy, ubiór, fryzura i proporcje ciała zmieniają się z każdą generacją. Sztuczna inteligencja dostarcza „kreatywne interpretacje”, a nie Twoje specyfikacje.
- **Niekontrolowane oświetlenie. ** Nawet określenie „złota godzina, ciepłe oświetlenie boczne z lewej strony” daje bardzo niespójne wyniki. Interpretacja opisów oświetlenia przez sztuczną inteligencję pozostaje zasadniczo niejasna.
- Niewiarygodne kadrowanie. Zbliżenia, ujęcia średnie, ujęcia pełne — narzędzia zamiany tekstu na wideo interpretują te terminy w sposób bardzo niestabilny. Poproś o ekstremalne zbliżenie, a otrzymasz ujęcie całej sylwetki.
W przypadku eksperymentów twórczych niepewność ta może stanowić część zabawy. Jednak jeśli potrzebujesz kontrolowanych, niezawodnych i profesjonalnych wyników, staje się ona fatalną wadą.
Główna zaleta priorytetu obrazu
TuSheng Video całkowicie odwróciło tę zależność. Nie jest już konieczne, aby sztuczna inteligencja generowała jednocześnie zarówno obraz, jak i ruch; zamiast tego rozdziela się te dwa zadania:
- Zacznij od obrazu. Temat, kompozycja, oświetlenie, kolor, kadrowanie — masz pełną kontrolę i możesz powtarzać proces aż do osiągnięcia perfekcji.
- Następnie dodaj ruch. Jedynym zadaniem sztucznej inteligencji jest animowanie idealnego kadru. Nie musi ona rozszyfrowywać niejasnych opisów ani podejmować decyzji dotyczących kompozycji — zamiast tego generuje ruch na podstawie konkretnych punktów odniesienia wizualnych.
Takie rozdzielenie obszarów zainteresowania przynosi doskonałe wyniki we wszystkich wymiarach:
- Kompozycja zablokowana. Obiekt pozostaje dokładnie w miejscu, w którym go umieściłeś.
- Spójność postaci. Cechy twarzy, ubiór i proporcje pozostają identyczne jak na zdjęciu źródłowym.
- **Oświetlenie i cienie zachowane. ** Kierunek światła, tekstura i temperatura barwowa są w pełni zachowane z obrazu.
- Stałe kadrowanie. Położenie kamery i punkt widzenia pozostają zgodne z oryginalną konfiguracją obrazu.
Aby to zilustrować: przekształcanie tekstu na wideo przypomina opisywanie sceny filmowej przez telefon i instruowanie kogoś, aby ją sfilmował. Przekształcanie obrazu na wideo jest natomiast jak pokazanie komuś zdjęcia i powiedzenie: „Ożyw ten obraz”. To drugie podejście daje bardziej kontrolowane i lepszej jakości wyniki, ponieważ sztuczna inteligencja otrzymuje konkretne odniesienia wizualne, a nie abstrakcyjne opisy tekstowe.
Efekt mnożnikowy jakości
Korzyści są kumulatywne. Starannie przygotowana ramka początkowa poprawia każdy aspekt filmu:
- Zwiększona spójność czasowa — model posiada wysokiej jakości kotwice wizualne, które zapewniają spójność całej sekwencji.
- Poprawiona jakość ruchu — model dokładnie wyodrębnia informacje dotyczące głębi, oświetlenia i przestrzeni z wyraźnych obrazów źródłowych.
- Zwiększona spójność stylistyczna — systemy kolorów, nastroje i estetyka są bezpośrednio osadzone w obrazach, nie pozostawiając miejsca na interpretację tekstową.
- Zmniejszony wskaźnik niedoskonałości — model rozpoczyna pracę od czystych danych wizualnych o wysokiej rozdzielczości, zamiast syntetyzować wszystko na podstawie szumu.
Wysokiej jakości filmy generowane na podstawie pierwszej klatki wykazują znaczną przewagę nad filmami generowanymi wyłącznie na podstawie tekstu z identycznymi podpowiedziami pod względem jakości wizualnej, ciągłości czasowej i walorów estetycznych. Nie jest to subtelna różnica — stanowi ona przepaść między „rozrywkowymi prezentacjami sztucznej inteligencji” a „profesjonalnymi treściami, które można wykorzystać w praktyce”.
Aby uzyskać szczegółowe informacje na temat projektowania obrazów przeznaczonych specjalnie do generowania filmów, zapoznaj się z Przewodnikiem po projektowaniu pierwszej i ostatniej klatki.
Trójstopniowy proces twórczy oparty na sztucznej inteligencji
Cały proces podzielony jest na trzy etapy, z których każdy opiera się na poprzednim. Każdy etap potraktowany niedbale ostatecznie wpłynie negatywnie na końcowy efekt. Zrozumienie znaczenia każdego etapu — oraz tego, gdzie należy poświęcić najwięcej czasu — jest kluczem do konsekwentnego tworzenia wysokiej jakości filmów opartych na sztucznej inteligencji.
Faza pierwsza: generowanie podpowiedzi
Wszystko zaczyna się od podpowiedzi. Przeciętne podpowiedzi → przeciętne obrazy → przeciętne filmy. Wyjątkowe podpowiedzi → oszałamiające obrazy → oszałamiające filmy. Jakość podpowiedzi jest największą zmienną wpływającą na jakość końcowego wyniku, a jednocześnie jest to etap, w który inwestuje się najmniej w większości procesów pracy.
Problem z ręcznym pisaniem podpowiedzi. Większość ludzi podchodzi do pisania podpowiedzi jak do tworzenia słów kluczowych do wyszukiwania: krótko, niejasno i skupiając się wyłącznie na temacie. „Luksusowy zegarek, ciemne tło”. To mówi sztucznej inteligencji, co ma narysować, ale nie instruuje jej, jak to narysować. Model wypełnia luki wartościami domyślnymi — płaskie oświetlenie, kompozycja wyśrodkowana, brak szczegółów atmosferycznych, brak kierunków stylistycznych.
Rozwiązanie: generowanie podpowiedzi wspomagane sztuczną inteligencją. Generator podpowiedzi rozwija Twoje wstępne pomysły w profesjonalne podpowiedzi obejmujące temat, otoczenie, oświetlenie, kolorystykę, kompozycję, styl i poprawę jakości obrazu. Różnica w jakości wyników między 10-wyrazową podpowiedzią ręczną a 100-wyrazową podpowiedzią wygenerowaną stanowi jakościowy skok.
Generator obrazów Seedance Image Prompt Generator robi właśnie to. Wystarczy wprowadzić krótki opis, np. „reklama luksusowego zegarka, mroczna i dramatyczna”, wybrać styl (fotorealistyczny, filmowy, ilustracyjny itp.), a sztuczna inteligencja natychmiast wygeneruje kompletny, profesjonalny prompt. Cały proces zajmuje zaledwie kilka sekund i kosztuje 2 kredyty za każdy prompt. Kompleksowy przewodnik po generowaniu podpowiedzi można znaleźć w Przewodniku po generatorze podpowiedzi obrazów AI.
Dlaczego ten krok jest tak ważny. Prompt to DNA całego procesu. Decyduje o stylu, nastroju, kompozycji i jakości wszystkiego, co nastąpi później. Poświęcenie pięciu minut na dopracowanie promptu przed generowaniem obrazów może zaoszczędzić trzydzieści minut powtarzalnego poprawiania przeciętnych wyników w późniejszym etapie.
Etap drugi: Generowanie obrazu
Po otrzymaniu profesjonalnej podpowiedzi następnym krokiem jest wygenerowanie obrazu, który posłuży jako pierwsza klatka filmu. W tym momencie następuje przejście od tekstu do elementów wizualnych, co oznacza etap, w który należy zainwestować najwięcej czasu na iteracje.
Od podpowiedzi do obrazu. Wklej wygenerowaną podpowiedź do narzędzia zamiany tekstu na obraz i kliknij przycisk generowania. Oceń wynik: czy kompozycja nadaje się do filmu? Czy oświetlenie jest wystarczająco warstwowe? Czy obiekt wygląda prawidłowo? Czy scena oddaje wrażenie głębi?
Jeśli masz już obraz referencyjny lub chcesz dopracować istniejące wyniki generowania, narzędzie image-to-image jest właśnie dla Ciebie. Prześlij istniejący obraz i opisz pożądane modyfikacje — jest to szczególnie przydatne w przypadku iteracji kompozycji: dostosuj oświetlenie, dodaj efekty atmosferyczne lub zmień zawartość sceny bez konieczności zaczynania od nowa. Kompleksowy przewodnik po przepływie pracy Image-to-Image można znaleźć w przewodniku Image-to-Image AI.
Projektowanie obrazów do wykorzystania w filmach. Nie każdy atrakcyjny wizualnie obraz nadaje się na początkową klatkę filmu. Tworząc obrazy do wykorzystania w filmach, należy pamiętać o następujących zasadach kompozycji:
- Zostaw negatywną przestrzeń w kierunku ruchu. Jeśli postać porusza się od lewej do prawej, umieść ją nieco po prawej stronie kadru.
- Dodaj poziomy głębi. Obrazy z wyraźnymi elementami pierwszego planu, środkowego planu i tła tworzą lepsze efekty paralaksy i bardziej naturalne ruchy kamery w filmie.
- **Weź pod uwagę kierunek ruchu kamery. ** Jeśli planujesz użyć ruchu „push”, upewnij się, że kompozycja wygląda dobrze zarówno w obecnym kadrze, jak i w węższym kadrze skupionym na obiekcie.
- Unikaj dużych bloków tekstu lub symetrycznych wzorów. Takie elementy są trudne do naturalnej animacji i mogą łatwo powodować powstawanie artefaktów.
- **Używaj oświetlenia kierunkowego. ** Silne oświetlenie kierunkowe z widocznymi cieniami daje bardziej kinowy efekt wideo niż płaskie oświetlenie.
Podstawowa zasada: poświęć czas na dopracowanie obrazów. Każda minuta spędzona na doskonaleniu grafiki pozwala zaoszczędzić kilka razy więcej czasu na etapie tworzenia filmu. Idealna pierwsza klatka oznacza, że film będzie gotowy do użycia już po pierwszym podejściu. Wadliwa pierwsza klatka może wymagać wielokrotnego ponownego generowania (co za każdym razem pochłania kredyty i czas) bez gwarancji satysfakcjonującego rezultatu.
Przed rozpoczęciem generowania wideo należy powtórzyć proces przetwarzania obrazów 3–5 razy. Nie jest to perfekcjonizm, lecz dążenie do wydajności.
Kompleksowy przewodnik po generowaniu obrazów na podstawie tekstu (w tym techniki podpowiadania i porównania narzędzi) można znaleźć w artykule Kompletny przewodnik po sztucznej inteligencji generującej obrazy na podstawie tekstu. Przegląd najlepszych narzędzi do generowania obrazów można znaleźć w artykule Najlepsze generatory obrazów oparte na sztucznej inteligencji na rok 2026.
Wygeneruj obraz → | Dostosuj obraz do obrazu →
Etap trzeci: Tworzenie filmu
To etap, na którym zbierasz owoce swojej pracy. Dopracowane obrazy stanowią punkt wyjścia dla animowanych klipów wideo.
Prześlij obraz jako pierwszą klatkę. Prześlij wygenerowany obraz do narzędzia [Image-to-Video] Seedance. Narzędzie pobiera obrazy bezpośrednio z historii generowania — nie ma potrzeby pobierania i ponownego przesyłania.
Opisz ruch słowami. Napisz opis ruchu, który chcesz uzyskać — nie opisuj elementów wizualnych (obraz został już przetworzony). Skoncentruj się na:
- Ruch kamery: „powolne zbliżenie z wózka” 、delikatny ruch w lewo、płynny ruch wokół obiektu
- Działanie obiektu: „kobieta powoli odwraca głowę”、płatki opadają、para unosi się z filiżanki
- Ruch otoczenia: „chmury powoli się przemieszczają”, „woda faluje”, „liście delikatnie kołyszą się na wietrze”
- ** Atmosfera**: „dramatyczna atmosfera”, „marzycielski, eteryczny charakter”, „kinowe tempo”
Generuj i przeglądaj. Sztuczna inteligencja otrzymuje Twoje wskazówki dotyczące obrazu i ruchu, tworząc segmenty wideo, które rozpoczynają się dokładnie od pierwszej klatki i rozwijają się zgodnie z instrukcjami dotyczącymi ruchu. Ponieważ kontrolujesz punkt początkowy obrazu, wynik jest przewidywalny i spójny. Jakość wideo dziedziczy jakość obrazu — wyraźna, dobrze oświetlona i precyzyjnie skomponowana pierwsza klatka przekłada się bezpośrednio na wyraźny, dobrze oświetlony i precyzyjnie skomponowany film.
Aby uzyskać informacje na temat zaawansowanych technik sterowania ruchem i parowania pierwszej/ostatniej klatki, zapoznaj się z Przewodnikiem projektowania pierwszej i ostatniej klatki. Kompleksowe wprowadzenie do technologii Image-to-Video AI znajdziesz w Przewodniku Image-to-Video AI.
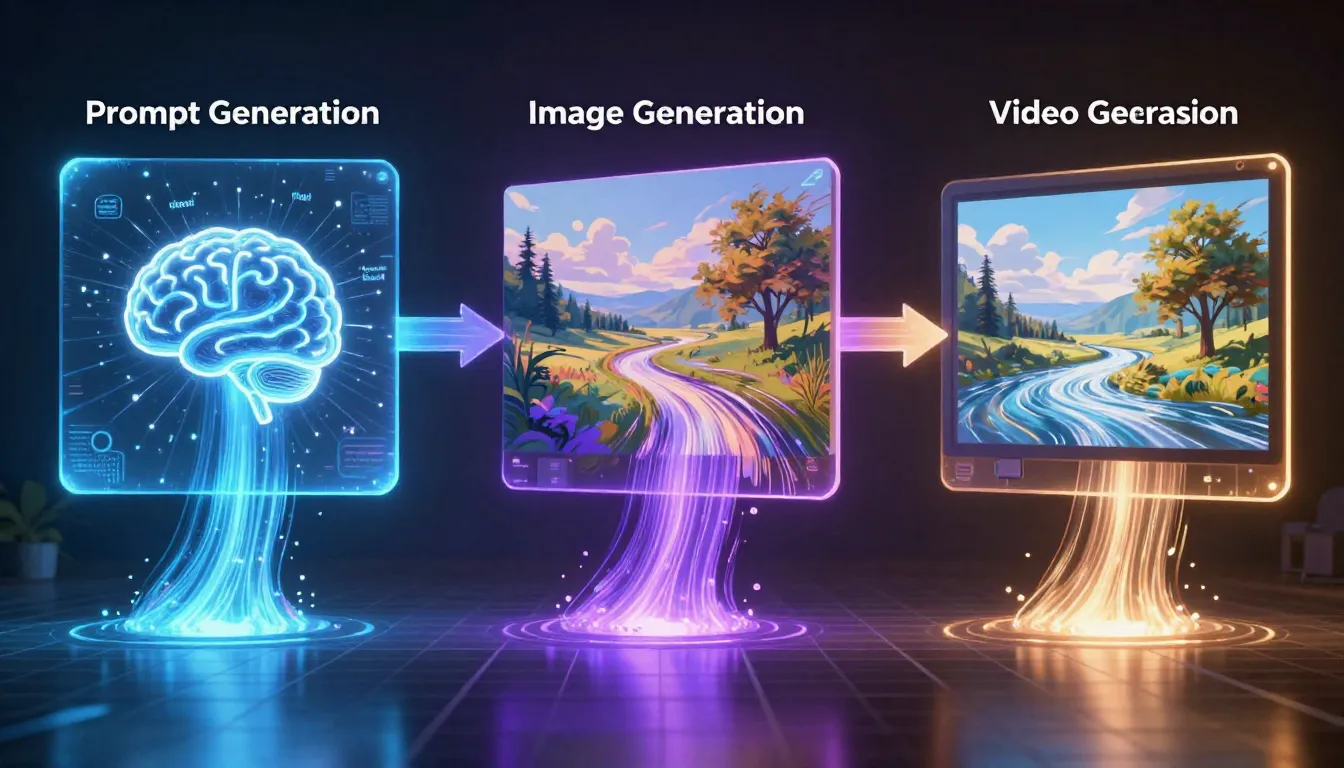
Trzyetapowy proces w praktyce: przekształcanie krótkich opisów w profesjonalne podpowiedzi, przekształcanie podpowiedzi w wysokiej jakości obrazy oraz przekształcanie obrazów w dynamiczne filmy. Każdy etap poprawia jakość poprzedniego.
Zalety Seedance: Trzystopniowa, kompleksowa realizacja
Obecnie większość twórców korzystających z tego rozwiązania łączy trzy lub cztery narzędzia. Używają ChatGPT lub Claude do pisania podpowiedzi obrazkowych, przechodzą do Midjourney lub Tongyi Wansheng w celu wygenerowania obrazu, pobierają obraz, otwierają Ke Ling lub Runway, a następnie przesyłają go w celu wygenerowania filmu. Każda zmiana oznacza inny interfejs, inne konta, inne systemy rozliczeniowe i inne ograniczenia.
Ten fragmentaryczny przebieg pracy jest nie tylko kłopotliwy, ale także aktywnie wpływa negatywnie na jakość.
Jak zmiana narzędzi wpływa na jakość
Za każdym razem, gdy obraz jest przesyłany między narzędziami, dochodzi do jego pogorszenia jakości. Cykl pobierania i wysyłania powoduje pojawienie się artefaktów kompresji. Konwersje formatów (PNG do JPG, WebP do PNG) zmieniają wartości kolorów. Rozdzielczość może zostać ponownie próbkowana. Metadane dotyczące sposobu wygenerowania obrazu — informacje, które mogłyby pomóc modelowi wideo w uzyskaniu lepszych wyników — są całkowicie usuwane.
Oprócz jakości danych istnieje również obciążenie poznawcze. Każde narzędzie ma własną składnię poleceń, odrębne ustawienia wyjściowe i różne opcje proporcji obrazu. Marnujesz czas na ponowne zapoznawanie się z interfejsami zamiast poświęcać go na kreatywne iteracje.
Zintegrowane rurociągi
Seedance eliminuje wszelkie tego typu utrudnienia, oferując wszystkie trzy etapy w ramach jednej platformy:
1. Generator podpowiedzi obrazowych (/image-prompt-generator). Wprowadź swoją koncepcję twórczą, wybierz jeden z 12 stylów i otrzymaj kompletną, profesjonalną podpowiedź. Wygenerowane podpowiedzi są zoptymalizowane pod kątem modelu generowania obrazów Seedance, ale nadają się również do każdego narzędzia do malowania opartego na sztucznej inteligencji.
2. Tekst na obraz i obraz na obraz (/text-to-image | /image-to-image). Generuj obrazy na podstawie podpowiedzi lub wprowadzaj ukierunkowane modyfikacje do istniejących zdjęć. Szybko twórz wiele wariantów. Po znalezieniu odpowiedniej kompozycji możesz przejść bezpośrednio do następnego etapu.
- Obraz do wideo Wybierz dowolny wcześniej wygenerowany obraz z biblioteki i wyślij go bezpośrednio do generatora wideo. Nie wymaga pobierania, przesyłania ani konwersji formatów. Obrazy w pełnej rozdzielczości są przesyłane bez strat.
Dlaczego integracja przynosi lepsze wyniki?
Nie jest to jedynie funkcja zwiększająca wygodę użytkowania; integracja naprawdę zapewnia doskonałe wyniki:
- Brak strat transmisji. Obrazy są przesyłane między etapami w pełnej rozdzielczości, bez kompresji i ponownego próbkowania.
- Spójny ekosystem modeli. Modele generowania obrazów i filmów są skalibrowane pod kątem naturalnej kompatybilności. Obrazy tworzone przez model tekst-obraz firmy Seedance są z natury dostosowane do modelu wideo tej samej firmy.
- **Ujednolicony system kredytowy. ** Nie ma potrzeby utrzymywania trzech oddzielnych subskrypcji. Twoje kredyty są uniwersalne dla wszystkich trzech narzędzi, co sprawia, że alokacja budżetu jest prosta i przejrzysta.
- Szybsze cykle iteracji. Czas od „Chcę edytować ten obraz” do „Oglądam nowy film” skraca się z minut spędzonych na przełączaniu narzędzi do zaledwie kilku sekund dzięki płynnej integracji.
- **Utrzymaj kreatywny przepływ. ** Pozostań w jednym interfejsie, aby zachować kontekst swoich myśli. Skoncentruj się na samej koncepcji twórczej, a nie na zarządzaniu plikami lub nawigacji po narzędziach.
Szczerze mówiąc: można doskonale wykorzystać ChatGPT do pisania podpowiedzi, Midjourney lub Tongyi Wansheng do generowania obrazów, a Keling lub Runway do tworzenia filmów, aby zbudować wysokiej jakości proces. Wielu profesjonalistów właśnie tak postępuje. Przewaga Seedance nie polega na tym, że którykolwiek z etapów znacznie przewyższa konkurencję — polega ona na integracji, która eliminuje tarcia powodujące, że większość twórców porzuca proces w połowie. Najlepszy przepływ pracy to taki, który faktycznie realizujesz od początku do końca.
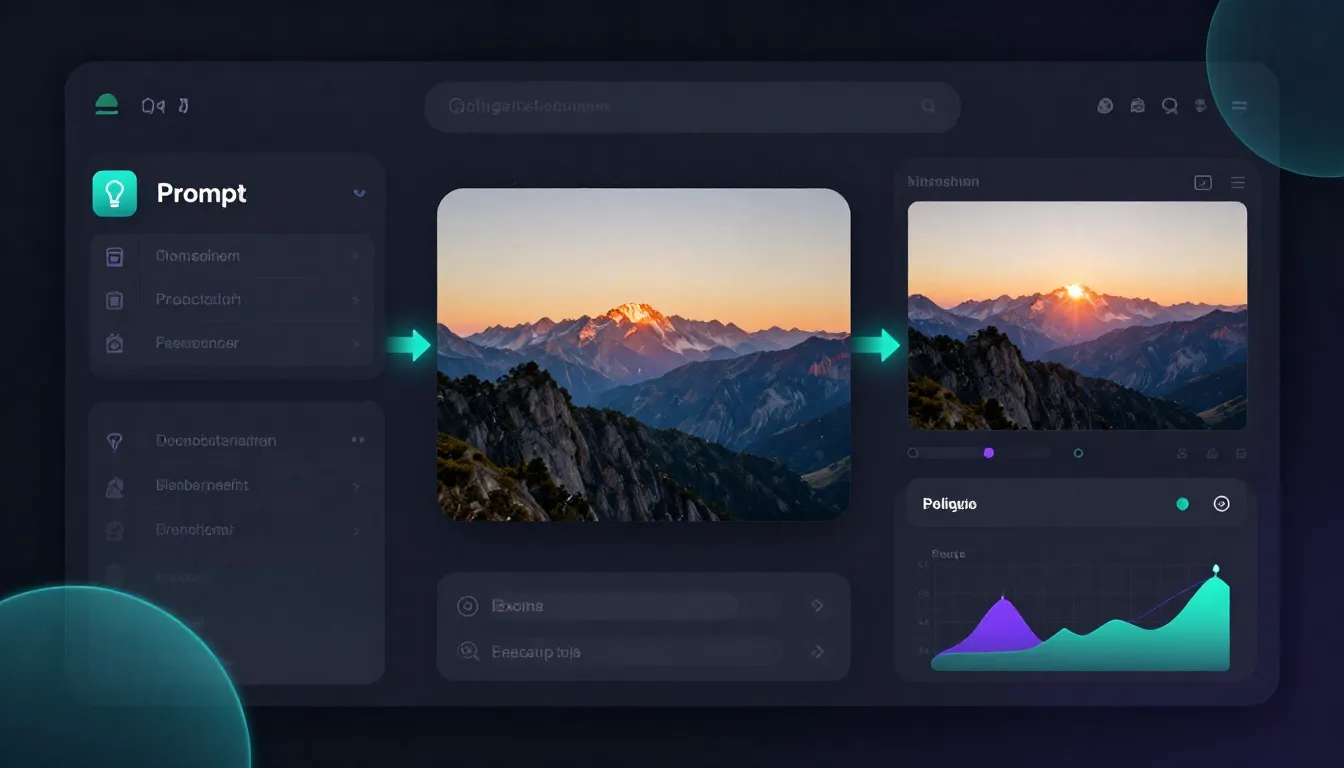
Seedance łączy generowanie podpowiedzi, obrazów i filmów w jednej platformie. Od pomysłu do gotowego filmu nie ma potrzeby przełączania się między narzędziami, pobierania plików ani zarządzania wieloma kontami.
Kompletny praktyczny przewodnik: 3 studia przypadków z życia wzięte
Teoria jest przydatna, ale to praktyka przynosi rezultaty. Poniżej przedstawiono trzy kompletne ćwiczenia dotyczące procesu tworzenia — każde z nich odpowiada innym celom twórczym, odrębnym stylom i różnym proporcjom obrazu. Postępuj zgodnie z instrukcjami, aby stworzyć swój pierwszy kompletny proces tworzenia.
Przypadek 1: Reklama produktu w formie filmowej
Cel: Stworzenie pięciosekundowej reklamy luksusowego zegarka na stronę prezentującą produkt.
Faza pierwsza — generowanie podpowiedzi
Otwórz Generator podpowiedzi obrazkowych i wprowadź swoją koncepcję.
Wprowadź: „reklama luksusowego zegarka, mroczna dramatyczna”
Wybierz styl: Fotorealistyczny
Wygenerowany komunikat:
A luxury men's wristwatch resting on a slab of dark emperador marble,
shot from a low three-quarter angle. Dramatic studio lighting: a single
hard key light from the upper left creates sharp reflections on the
polished steel case and sapphire crystal. The watch face shows 10:10
with luminous indices glowing faintly. Deep shadows pool around the
base, enhancing the sense of weight and prestige. Background is pure
black, fading to subtle charcoal gradient. Microscopic dust particles
float in the key light beam. Color palette: silver, deep charcoal,
amber highlights from the lume. Photorealistic product photography,
8K resolution, razor-sharp detail on every dial marking and link.Ręczne utworzenie tego podpowiedzi zajęłoby co najmniej 10–15 minut. Generator podpowiedzi wykonuje to w ciągu kilku sekund, uwzględniając wszystkie siedem wymiarów profesjonalnych podpowiedzi: temat, otoczenie, oświetlenie, kolor, kompozycję, styl i jakość obrazu.
Etap drugi — generowanie obrazu
Wklej wygenerowany komunikat do text-to-image. Wygeneruj obraz w proporcjach 16:9, aby pasował do ramki filmu w formacie poziomym.
Pierwsze wrażenie: Ogólna kompozycja jest udana, choć marmurowa powierzchnia odbija nieco zbyt mocno światło, odwracając uwagę od zegarka.
Iteracja: Dopracuj obraz za pomocą funkcji Image-to-Image. Prześlij początkowo wygenerowany obraz z poleceniem: „Zmniejsz intensywność odbicia powierzchni marmuru. Zwiększ ostrość szczegółów tarczy zegarka. Nieco pogłęb gradient tła”.
Drugie ujęcie: zegarek zajmuje centralne miejsce, skąpany w dramatycznym świetle i cieniu, z warstwową kompozycją. Gotowy do przejścia do fazy wideo.
Etap trzeci — generowanie wideo
Wyślij dopracowane obrazy do Image-to-Video.
Wskazówki dotyczące ćwiczeń:
The camera executes a slow, smooth orbiting movement around the watch,
revealing different angles of the case and bracelet. The key light
shifts subtly as the camera moves, creating dynamic reflections across
the polished surfaces. Dust particles drift slowly through the light
beam. Cinematic, premium commercial pacing. Steady, professional
camera movement.(Kamera powoli i płynnie obraca się wokół zegarka, ukazując różne kąty koperty i paska. Wraz z ruchem kamery główne źródło światła subtelnie się przesuwa, tworząc dynamiczne odbicia na wypolerowanych powierzchniach. Cząsteczki kurzu delikatnie unoszą się w promieniu światła. Kinowe tempo wysokiej klasy reklamy. Płynny, profesjonalny ruch kamery).
Efekty końcowe: Dopracowana, 5-sekundowa prezentacja produktu — rozpoczynająca się od starannie skomponowanej klatki, płynnie obracającej się wokół zegarka. Efektowne oświetlenie, ostre szczegóły i wysokiej jakości tekstury płynnie przechodzą z obrazu źródłowego do każdej klatki filmu.

Przypadek 1: Reklama luksusowego zegarka. Od pięciowyrazowego briefu koncepcyjnego do dopracowanego pięciosekundowego filmu produktowego — trzyetapowy proces zapewniający efekt na poziomie komercyjnym.
Przypadek 2: Treści dotyczące podróży w mediach społecznościowych
Cel: Nakręcenie pionowego filmu przedstawiającego wschód słońca w japońskiej świątyni na potrzeby serwisów TikTok/Instagram Reels.
Faza pierwsza — generowanie podpowiedzi
Otwórz Generator podpowiedzi obrazkowych.
Wpis: „Wschód słońca nad japońską świątynią, spokojny poranek”
Wybierz styl: Fotorealistyczny
Wygenerowany komunikat:
A traditional Japanese wooden temple (Kiyomizu-dera style) nestled
among ancient cedar trees, photographed at dawn. Golden sunrise light
filters through morning mist, casting long warm shadows across the
temple's wooden veranda. Cherry blossom branches frame the upper
portion of the composition, with delicate pink petals catching the
first light. A stone lantern stands in the foreground left, moss-
covered and weathered. The temple roof's curved eaves are silhouetted
against a sky transitioning from deep indigo to warm peach and gold.
Subtle mist hovers at ground level among the trees. Photorealistic
landscape photography, golden hour lighting, serene and contemplative
atmosphere, high dynamic range, rich natural color palette.Etap drugi — generowanie obrazu
Wklej do Text-to-Image. Kluczowe ustawienia: Generuj w proporcjach 9:16, odpowiednich dla TikTok i Instagram Reels.
Pierwszy szkic: Atmosfera jest oszałamiająca, ale gałęzie kwitnącej wiśni są umieszczone zbyt wysoko w kadrze, pozostawiając zbyt dużo pustej przestrzeni w dolnej jednej trzeciej części.
Iteracja: Po niewielkiej modyfikacji podpowiedzi i dodaniu opisu „gałęzie kwitnącej wiśni rozciągające się od prawego i lewego górnego rogu, wypełniające górną jedną trzecią pionowej ramki”, druga generacja idealnie umieściła kwiaty wiśni jako naturalną ramę kompozycji.
Kompozycja idealnie nadaje się do filmu pionowego: świątynia przyciąga wzrok do środka kadru, a kwiaty wiśni u góry tworzą interesujący efekt wizualny. Kamienne latarnie i mgła na pierwszym planie nadają głębię. Ujęcie to oferuje potencjał ruchu na wielu poziomach.
Etap trzeci — generowanie wideo
Wyślij do Image-to-Video.
Wskazówki dotyczące ćwiczeń:
Gentle cherry blossom petals drift slowly downward through the frame.
Morning mist shifts and swirls at ground level among the trees. Two
birds fly across the sky in the background. The sunrise light gradually
intensifies, warming the scene. A subtle breeze moves the cherry
blossom branches slightly. Peaceful, meditative atmosphere. Slow,
contemplative pacing.Płatki kwiatów wiśni delikatnie unoszą się w kadrze. Poranna mgła płynnie rozlewa się po ziemi między drzewami. W tle dwa ptaki szybują po niebie. Światło wschodzącego słońca stopniowo nabiera intensywności, ogrzewając całą scenę. Delikatny wiatr porusza gałęziami wiśni. Panuje spokojna, medytacyjna atmosfera. Powolny, kontemplacyjny rytm.
Efekty końcowe: 4-sekundowy, klimatyczny filmik w formacie pionowym, idealnie pasujący do serwisów TikTok i Instagram Reels. Kwiaty wiśni unoszą się naturalnie, a poranna mgła dodaje głębi i ruchu. Ptaki w tle tworzą subtelne punkty centralne. Złote, ciepłe odcienie obrazu źródłowego przenikają każdą klatkę filmu.
Studium przypadku 3: Narracja marki – połączenie pierwszej i ostatniej klatki
Cel: Stworzenie sześciosekundowej narracji marki przedstawiającej przemianę kawiarni od ciszy wczesnego poranka do tętniącego życiem, pełnego lokalu.
W tym przypadku wykorzystano dwukrotnie potok, generując parę obrazów składającą się z pierwszej i ostatniej klatki, aby zapewnić modelowi wideo dwa punkty odniesienia wizualnego do zdefiniowania łuku narracyjnego. Szczegółowa analiza tej techniki znajduje się w Przewodniku projektowania pierwszej i ostatniej klatki.
Faza pierwsza — dwa podpowiedzi
Wygeneruj dwa zestawy podpowiedzi za pomocą generatora podpowiedzi obrazkowych.
Pierwsza klatka: „Pusta kawiarnia skąpana w świetle wczesnego poranka, utrzymana w ciepłych bursztynowych barwach”.
Wygenerowany komunikat dla pierwszej klatki:
Interior of an artisanal coffee shop in the early morning, before
opening. Warm amber sunlight streams through large front windows,
casting long golden rectangles across worn hardwood floors. Exposed
brick walls, a polished wooden counter with a brass espresso machine,
and empty mismatched chairs around small tables. A chalkboard menu
hangs behind the counter. Dust motes float in the sunbeams. The space
feels warm, inviting, and full of potential. Shot at eye level from
just inside the entrance. Photorealistic interior photography, warm
color palette, golden hour tones, cozy atmosphere.Ostateczny obraz: „Tętniąca życiem kawiarnia w ciepły poranek, gdzie klienci delektują się kawą”.
Wygenerowany komunikat dotyczący ostatniej klatki:
The same artisanal coffee shop, now alive with morning activity.
Diverse customers sit at tables -- some reading, some talking, some
working on laptops. A barista behind the counter steams milk, creating
a plume of white steam. Coffee cups and pastries fill the tables. Warm
morning light still streams through the windows but is supplemented by
the warm glow of pendant lights. The atmosphere is bustling but cozy,
full of quiet energy and the warmth of community. Shot from the same
eye-level position just inside the entrance. Photorealistic interior
photography, warm tones, lively atmosphere.Etap drugi — dwa obrazy
Wygeneruj pierwszą klatkę w text-to-image o proporcjach 16:9. Powtarzaj tę czynność, aż pusta kawiarnia będzie wyglądać na ciepłą i zachęcającą, skąpaną w obfitym, złotym świetle poranka.
Ostatnia klatka wykorzystuje generowanie [obraz-do-obrazu]. Prześlij początkową klatkę jako obraz referencyjny i użyj podpowiedzi ostatniej klatki. Ten krok jest kluczowy — użycie początkowej klatki jako odniesienia zapewnia spójność wizualną. Architektura, wyposażenie, kierunek oświetlenia i kolorystyka pozostają spójne między klatkami, a jedynym dodatkiem jest włączenie postaci i aktywności.
Powtórz ostatnią klatkę, aby upewnić się, że gość wygląda naturalnie, a barista znajduje się za ladą. Co najważniejsze: oba obrazy powinny wyglądać jak to samo miejsce uchwycone w różnych momentach, a nie dwa oddzielne miejsca.
Etap trzeci — generowanie wideo
Prześlij pierwszą klatkę do Image-to-Video. Na platformach obsługujących odniesienia do klatek końcowych prześlij jednocześnie ostatnią klatkę.
Wskazówki dotyczące ćwiczeń:
Time-lapse style transition. The empty coffee shop gradually fills
with people arriving -- customers entering, sitting down, a barista
beginning to work. Morning light shifts slowly. The scene transitions
from quiet solitude to warm, bustling community. Smooth, cinematic
pacing. The camera position remains fixed.(Przejście w stylu poklatkowym. Pusta kawiarnia stopniowo zapełnia się przybywającymi klientami — wchodzą, zajmują miejsca, a barista zaczyna pracę. Poranne światło subtelnie się zmienia. Scena ewoluuje od spokojnej samotności do ciepłej, tętniącej życiem atmosfery społeczności. Płynne, filmowe tempo. Kamera pozostaje nieruchoma).
Rezultat: Sześciosekundowa historia marki przedstawia kompletną narrację – przebudzenie kawiarni. Pierwsza klatka przedstawia spokojną, przyjazną przestrzeń. Ostatnia klatka przedstawia stan pożądany. Przejścia generowane przez sztuczną inteligencję łączą te dwa elementy: drzwi się otwierają, klienci zajmują miejsca, bariści uruchamiają ekspresy do kawy, a na stołach pojawiają się filiżanki kawy. Przesłanie marki jest subtelne, ale mocne – to miejsce, w którym czujesz się jak w domu.

Przypadek 3: Narracja marki łącząca kadry otwierające i zamykające. Sztuczna inteligencja generuje przejście typu time-lapse między dwoma punktami odniesienia wizualnego — od ciszy świtu do ciepła społeczności.
Techniki optymalizacji rurociągów
Po wyprodukowaniu setek filmów przy użyciu tej metody, stwierdziliśmy, że pięć poniższych zasad miało największy wpływ na jakość końcowego produktu.
Wskazówka 1: Poświęć 80% czasu na obrazy
Jest to najważniejsza optymalizacja. Jakość obrazu stanowi wąskie gardło w całym procesie. Idealny obraz pozwoli uzyskać użyteczny film już w pierwszej generacji. Przeciętny obraz, niezależnie od tego, jak dobrze opracowane są sygnały ruchu, pozwoli uzyskać jedynie przeciętny film.
Podział czasu powinien wyglądać mniej więcej następująco:
- Generowanie podpowiedzi: 5% (generator zajmuje kilka sekund, ręczne pisanie zajmuje kilka minut)
- Generowanie obrazów i iteracja: 80% (generowanie, ocena, dostosowywanie, ponowne generowanie, aż scena będzie idealna)
- Generowanie wideo: 15% (przesyłanie, pisanie podpowiedzi ruchu, generowanie)
Większość początkujących użytkowników postępuje odwrotnie — poświęcają dziesięć sekund na obraz, a następnie generują kolejne filmy, mając nadzieję, że trafią na dobry. Doświadczeni użytkownicy poświęcają dziesięć minut na obraz i uzyskują dobry film już po kilku pierwszych próbach. To drugie podejście daje lepsze wyniki przy mniejszym nakładzie środków i czasu.
Przed rozpoczęciem generowania wideo należy powtórzyć proces przetwarzania obrazów od trzech do pięciu razy. Nie jest to perfekcjonizm, lecz dążenie do wydajności.
Wskazówka 2: Zaprojektowane z myślą o ruchu
Ładna fotografia i dobra klatka wideo to nie to samo. Tworząc obrazy dla potoków, wyobraź sobie, jak scena będzie wyglądać, gdy ożyje.
Zostaw trochę wolnego miejsca w kierunku głównego ruchu. Jeśli postać porusza się z lewej strony na prawą, nie umieszczaj jej na środku – przesuń ją trochę w prawo, żeby było miejsce na ruch. Jeśli kamera przesuwa się w lewo, upewnij się, że lewa strona kadru zawiera coś ciekawego.
Komponuj ujęcia zgodnie z kierunkiem kamery. Ujęcia z przesunięciem są najskuteczniejsze, gdy najbardziej interesujący element znajduje się w centrum kadru. Ujęcia panoramiczne wymagają, aby cała szerokość kadru była interesująca wizualnie. Okrężne ujęcia z przesunięciem wymagają trójwymiarowych obiektów z głębią, a nie płaskich obiektów.
Unikaj złożonych kompozycji symetrycznych. Chociaż idealna symetria może wyglądać efektownie na zdjęciach, to sprawia kłopoty przy tworzeniu filmów. Sztuczna inteligencja ma trudności z utrzymaniem dokładnej symetrii między klatkami, co powoduje rozpraszające drgania. Asymetryczne kompozycje z naturalnym przepływem wizualnym dają płynniejsze filmy.
Wykorzystaj wskazówki dotyczące głębi. Obrazy zawierające nakładające się elementy w różnych odległościach — obiekty na pierwszym planie, obiekty w środkowej części i tło — dostarczają sztucznej inteligencji informacji o głębi, co przekłada się na lepsze efekty paralaksy i bardziej naturalne ruchy kamery.
Aby uzyskać kompleksowy przewodnik dotyczący projektowania obrazów specjalnie do filmów, zapoznaj się z Przewodnikiem projektowania pierwszej i ostatniej klatki.
Technika 3: Zachowaj spójne proporcje obrazu podczas całego procesu
Niedopasowane proporcje obrazów i klatek wideo stanowią jeden z najczęstszych błędów w procesie przetwarzania, nieuchronnie obniżając jakość wyjściową.
- 16:9 dla filmów w formacie poziomym (YouTube, prezentacje, strony docelowe witryn internetowych)
- 9:16 dla filmów w formacie pionowym (TikTok, Instagram Reels, YouTube Shorts)
- 1:1 dla filmów kwadratowych (Instagram Stories, niektóre reklamy w mediach społecznościowych)
Ustaw proporcje obrazu podczas generowania obrazu, zamiast pozostawiać to do etapu tworzenia wideo. Jeśli wygenerujesz obraz kwadratowy o proporcjach 1:1, a następnie spróbujesz utworzyć wideo o proporcjach 16:9, model wideo będzie musiał wypełnić boki od podstaw — a jakość wygenerowanej treści będzie gorsza niż reszta klatki. Generuj obrazy od samego początku w proporcjach ostatecznego wideo.
Wskazówka 4: Zachowaj spójny styl komunikatów na wszystkich etapach
Słowa kluczowe dotyczące stylu w podpowiedziach obrazkowych i wskazówki dotyczące ruchu w podpowiedziach wideo powinny posługiwać się tym samym językiem wizualnym. Wszelkie niespójności między nimi spowodują subtelne problemy z jakością końcowego wyniku.
Jeśli Twój opis obrazu zawiera słowa „kinowy, dramatyczne oświetlenie, nastrojowa atmosfera”, opis ruchu wideo powinien używać podobnego języka: „kinowy ruch kamery, dramatyczna atmosfera, nastrojowe tempo”. Unikaj łączenia dramatycznych, kinowych obrazów z opisami ruchu typu „zabawny, skoczny, energiczny” – konflikty tonalne mogą zdezorientować model i zmniejszyć spójność.
Szybki przewodnik — tabela dopasowania stylów:
| Styl obrazu | Dopasowany ruch Język podpowiedzi |
|---|---|
| Kinowy, dramatyczny | „Kinowy ruch kamery, dramatyczne tempo, powolny i przemyślany” |
| Jasny, komercyjny, czysty | „Płynny, profesjonalny ruch, stałe tempo, czyste przejścia” |
| Marzycielski, eteryczny, delikatny | „Delikatny, płynny ruch, marzycielska atmosfera, powolny dryf” |
| Energetyczny, dynamiczny | „Dynamiczny ruch kamery, energiczne tempo, szybkie cięcia” |
| Dokumentalny, naturalny | „Ręczne ujęcia, naturalny ruch, tempo obserwacyjne” |
Wskazówka 5: Zapisz swoje najlepsze szablony potoku
Gdy potok polecenie → obraz → wideo daje korzystne wyniki, zapisz cały potok:
- Podpowiedź obrazu (oryginalny tekst)
- Wybrane ustawienia stylu
- Ustawienia generowania obrazu (proporcje, model, liczba początkowa itp.)
- Podpowiedź ruchu wideo
- Ustawienia generowania wideo (czas trwania, rozdzielczość)
Ten proces służy jako szablon. Chcesz stworzyć podobne filmy dla różnych produktów? Wymień temat w podpowiedzi obrazkowej i wygeneruj ponownie. Potrzebujesz różnych scen w tym samym stylu? Zachowaj słowa kluczowe stylu i zamień opis tematu.
Z czasem zbudujesz bogatą bibliotekę procesów dostosowanych do różnych celów kreatywnych: reklam produktów, treści w mediach społecznościowych, narracji dotyczących marki, materiałów filmowych B-roll, animacji postaci. Każdy nowy projekt rozpoczyna się od sprawdzonych podstaw, a nie od zera.
Porównanie alternatywnych narzędzi na poszczególnych etapach
Seedance zapewnia zintegrowany proces, ale można również skonstruować ten przepływ pracy przy użyciu oddzielnych narzędzi. Poniżej znajduje się szczere porównanie każdego etapu.
Faza pierwsza: generowanie podpowiedzi
| Narzędzie | Najbardziej odpowiednie dla | Opis |
|---|---|---|
| Seedance Image Prompt Generator | Zintegrowany potok, 12 gotowych stylów | 2 punkty za każde polecenie. Bezpośrednie wysyłanie wyników do narzędzia Seedance image. |
| ChatGPT / GPT-4 | Niestandardowe tworzenie poleceń | Wymaga ręcznego kopiowania i wklejania. Brak gotowych stylów. Bardziej elastyczne w przypadku złożonych instrukcji. |
| Claude | Wyrafinowane, szczegółowe podpowiedzi | Doskonałe do wykonywania złożonych briefów kreatywnych. Brak integracji z generowaniem obrazów. |
| Tongyi Qianwen | Zoptymalizowane pod kątem kontekstów chińskich | Bardziej naturalne rozumienie chińskich opisów. Odpowiednie dla użytkowników krajowych. Wymaga ręcznej integracji z narzędziami niższego szczebla. |
Etap drugi: Generowanie obrazu
| Narzędzie | Najbardziej odpowiednie dla | Uwagi |
|---|---|---|
| Seedance Text-to-Image / Image-to-Image | Integracja z potokiem, przepływ pracy z priorytetem dla wideo | Obrazy przenoszone bezpośrednio do etapu wideo bez utraty jakości. |
| Midjourney | Jakość artystyczna, estetyczna ekspresja | Zapewnia doskonałe wyniki. Wymaga obsługi za pośrednictwem Discord lub interfejsu internetowego. Możliwość ręcznego pobrania w ramach procesów. |
| Tongyi Wanshang | Przyjazny dla chińskich poleceń, stabilny dostęp krajowy | Opracowany przez Alibaba, doskonale rozumie chińskie opisy. Odpowiedni dla użytkowników krajowych bez VPN. |
| DALL-E 3 | Wierność poleceń, renderowanie tekstowe | Doskonale radzi sobie z dosłownym wykonywaniem złożonych poleceń. Ograniczona kontrola stylistyczna. |
| Stable Diffusion | Pełna kontrola, generowanie lokalne | Maksymalna elastyczność. Wymaga konfiguracji środowiska technicznego. Odpowiedni do pracy z dużymi ilościami danych. |
Etap trzeci: Tworzenie filmu
| Narzędzie | Najbardziej odpowiednie dla | Opis |
|---|---|---|
| Seedance Image-to-Video | Zintegrowany proces, stała jakość | Płynne przesyłanie obrazów, bezpośrednia obsługa wprowadzania pierwszej klatki. |
| Kling 3.0 | Długi czas trwania, wysoka jakość | Generuje do 2 minut na uruchomienie. Wysoka jakość ruchu. Autor: Kuaishou, dostępne w Chinach. |
| Jimeng AI | Chiński ekosystem, przyjazny dla użytkownika | Autor: ByteDance, głęboko zintegrowany z ekosystemem TikTok. Idealny do tworzenia krótkich filmów. |
| Runway Gen-4 | Precyzyjna kontrola, pędzle ruchu | Tryb reżyserski obsługuje niestandardowe ścieżki kamery. Profesjonalny interfejs. Wyższa cena. |
| Pika 2.0 | Prosta obsługa, szybkie eksperymentowanie | Najbardziej minimalistyczny interfejs. Odpowiedni dla początkujących. Ograniczona kontrola szczegółów ruchu. |
Szczerze mówiąc: Z pewnością można stworzyć wysokiej jakości proces pracy, wykorzystując ChatGPT do szybkiego pisania, Midjourney do generowania obrazów i Keeling do produkcji wideo. Wielu profesjonalistów właśnie tak postępuje. Przewaga Seedance nie polega na przewyższaniu konkurencji na żadnym z etapów — polega ona na eliminowaniu tarć poprzez integrację, utrzymywaniu jakości na wszystkich etapach oraz łączeniu trzech oddzielnych procesów w jeden. Twórcy, którzy często produkują filmy AI, dzięki korzystaniu z jednej platformy oszczędzają kilka godzin tygodniowo.
Szczegółowe porównanie narzędzi do generowania filmów można znaleźć w artykule Najlepsze generatory filmów AI 2026 – porównanie.
Typowe błędy związane z potokiem danych
Poniżej przedstawiono pięć najczęstszych błędów występujących podczas konfigurowania potoku polecenie → obraz → wideo. Każdy z nich ma proste rozwiązanie.
Błąd 1: Całkowite pominięcie etapu obrazu
Konkretny przejaw: Bezpośrednia konwersja tekstu na wideo, całkowicie pomijając generowanie obrazu.
Dlaczego jest to problematyczne: Tracisz całkowicie kontrolę nad kompozycją. Model wideo dyktuje wszystko — treść wizualną, kadrowanie sceny i punkty początkowe kamery. Wyniki są nieprzewidywalne, a prawdopodobieństwo, że za pierwszym razem uda się osiągnąć zamierzony efekt twórczy, jest niewielkie.
Jak to naprawić: Zawsze generuj obraz pierwszej klatki, nawet jeśli uważasz, że Twój tekstowy komunikat jest wystarczająco szczegółowy. 30 sekund poświęcone na wygenerowanie obrazu może zaoszczędzić Ci wielu nieudanych prób wygenerowania wideo.
Błąd 2: Korzystanie z obrazów stockowych bez oceny
Konkretny przejaw: Losowe pobieranie obrazu z internetu lub wybieranie go z biblioteki zdjęć, a następnie wstawianie go bezpośrednio do procesu generowania wideo bez oceny jego przydatności jako klatki otwierającej.
Dlaczego jest to problem: Wiele zdjęć jest przeznaczonych do oglądania w stanie statycznym, a nie w ruchu. Kadrowanie jest zbyt ciasne, nie pozostawiając miejsca na ruch kamery. Obiekty są wyśrodkowane, co ogranicza możliwości kadrowania. Oświetlenie jest płaskie, co powoduje nudne efekty wideo. Wysoce skompresowane pliki JPEG powodują powstawanie artefaktów.
Jak to naprawić: Przed użyciem jakiegokolwiek obrazu należy najpierw ocenić go zgodnie z zasadą „zaprojektowany z myślą o ruchu”. Lepszym podejściem jest użycie potoków specjalnie do generowania klatek kluczowych.
Błąd 3: Niezgodność proporcji obrazu
Konkretne przejawy: Generowanie obrazów kwadratowych, a następnie tworzenie filmów w formacie 16:9 lub wykorzystywanie obrazów poziomych do tworzenia filmów pionowych.
Dlaczego powoduje to znaczne szkody: Modele wideo albo przycinają obrazy (co powoduje utratę starannie zaprojektowanych treści), albo wypełniają nowy współczynnik proporcji treścią generowaną od podstaw (przy czym dodane krawędzie są gorszej jakości).
Jak to naprawić: Przed wygenerowaniem obrazów określ ostateczny współczynnik proporcji wideo. Wygeneruj obrazy zgodnie z tym współczynnikiem proporcji.
Błąd 4: Zbyt opisowe podpowiedzi wideo
Konkretny przykład: Wideo opisuje jednocześnie scenę i ruch: „Luksusowy zegarek na ciemnym marmurze w dramatycznym oświetleniu, kamera powoli krąży, a odbicia światła tańczą po powierzchni”.
Dlaczego jest to problematyczne: Opis wizualny może być sprzeczny z treścią obrazu. Jeśli zegarek jest przedstawiony na białym marmurze, ale polecenie określa ciemny marmur, model otrzymuje sprzeczne sygnały. W najlepszym przypadku opis wizualny staje się zbędny, w najgorszym – powoduje, że model próbuje zmodyfikować starannie zaprojektowaną pierwszą klatkę.
Jak tworzyć: Wskazówki wideo powinny opisywać wyłącznie ruch, kąty kamery i atmosferę. Elementy wizualne zostały już przetworzone na obrazy. Należy pamiętać o następującej zasadzie: obrazy przekazują „to, co widać”, natomiast wskazówki wideo określają „jak się porusza”.
Błąd 5: Pośpieszne generowanie filmów bez iteracji obrazów
Konkretny przejaw: Generowanie obrazu i bezpośrednie wprowadzanie go do procesu generowania wideo, nawet jeśli wykazuje on oczywiste wady — takie jak nieznacznie przekrzywiona kompozycja, drobne niedoskonałości lub nieoptymalne oświetlenie.
Dlaczego wpływ jest większy: Wideo powiększa każdą wadę obrazu źródłowego. Niewielka niedoskonałość na zdjęciu staje się trwałą, ruchomą wadą w 120 klatkach filmu. Nieco przesunięta kompozycja staje się wyraźnie nieprawidłowa, gdy ruch kamery zwraca uwagę na kadrowanie. Każda wada zdjęcia staje się bardziej widoczna, a nie mniej, w filmie.
Jak to naprawić: Potraktuj etap obrazu jako punkt kontroli jakości. Nie przechodź do etapu wideo, dopóki obraz nie będzie naprawdę zadowalający. Powtórz tę czynność 3–5 razy. Użyj generowania obrazu do obrazu w celu przeprowadzenia ukierunkowanych napraw. Jakość wyjściowego wideo nie może przekraczać jakości obrazu źródłowego.
Często zadawane pytania
Dlaczego warto korzystać z pośrednictwa obrazów zamiast bezpośredniej konwersji tekstu na wideo?
Generowanie tekstu do wideo wymaga od sztucznej inteligencji jednoczesnego tworzenia zarówno obrazów, jak i ruchu na podstawie tekstu, co oznacza, że masz minimalną kontrolę nad kompozycją, wyglądem postaci, oświetleniem i kadrowaniem. Podejście oparte na obrazie rozdziela te dwa zadania: podczas fazy tworzenia obrazu dopracowujesz elementy wizualne, a następnie instruujesz sztuczną inteligencję, aby dodała wyłącznie ruch. Dzięki temu uzyskujesz bardziej przewidywalne wyniki o wyższej jakości, ponieważ sztuczna inteligencja otrzymuje konkretne odniesienia wizualne zamiast interpretować niejednoznaczny tekst. Różnica jest szczególnie widoczna w profesjonalnych scenariuszach wymagających określonych kompozycji, palet kolorów marki lub spójnego projektu postaci.
Jak wygląda cały proces tworzenia filmów AI od podstaw?
Cały proces składa się z trzech kroków. Krok pierwszy: Użyj generatora podpowiedzi AI (takiego jak Image Prompt Generator firmy Seedance), aby rozwinąć swoją koncepcję w szczegółową podpowiedź obrazową. Krok drugi: Wykorzystaj tę podpowiedź w narzędziu do przekształcania tekstu w obraz (takim jak Text-to-Image firmy Seedance), aby wygenerować wysokiej jakości obrazy referencyjne, powtarzając proces aż do uzyskania satysfakcjonującego rezultatu. Krok trzeci: Prześlij obraz do generatora obrazu do wideo (takiego jak image-to-video firmy Seedance), napisz podpowiedź opisującą tylko ruch (ruch kamery i działania obiektu) i wygeneruj wideo. Cały proces trwa od 5 do 15 minut, w zależności od liczby iteracji potrzebnych na etapie obrazu.
Ile kredytów kosztuje pełny proces na Seedance?
Koszty różnią się w zależności od konfiguracji, ale typowy przebieg procesu obejmuje zazwyczaj: generowanie podpowiedzi za 2 kredyty, generowanie obrazu za 4–8 kredytów za iterację (przy założeniu 3–5 iteracji, co odpowiada 12–40 kredytom) oraz generowanie wideo za 10–30 kredytów (w zależności od czasu trwania i rozdzielczości). Od pomysłu do gotowego filmu całkowity koszt wynosi zazwyczaj od 25 do 70 kredytów. Stanowi to znaczną oszczędność w porównaniu z użyciem trzech oddzielnych narzędzi z trzema oddzielnymi subskrypcjami.
Czy obrazy wygenerowane przez inne narzędzia mogą być wykorzystane do tworzenia filmów w Seedance?
Oczywiście. Narzędzie Seedance [Image-to-Video] akceptuje każdy przesłany obraz — nie musi on być wygenerowany przez Seedance. Możesz tworzyć obrazy za pomocą Midjourney, DALL-E, Tongyi Wanshang, Stable Diffusion lub dowolnego innego narzędzia i przesyłać je jako pierwszą klatkę. Zaletą zintegrowanego potoku jest wyeliminowanie etapu pobierania i przesyłania, choć nie jest to obowiązkowe. W przypadku korzystania z obrazów zewnętrznych zalecamy format PNG o rozdzielczości 1024x1024 lub wyższej, aby zapobiec wpływowi artefaktów kompresji na wyjście wideo.
Jakie proporcje obrazu należy stosować w przypadku zdjęć?
Zawsze upewnij się, że proporcje obrazu są zgodne z ostatecznym formatem wideo. 16:9 dla filmów poziomych (YouTube, prezentacje, osadzanie na stronach internetowych), 9:16 dla filmów pionowych (TikTok, Instagram Reels, YouTube Shorts), 1:1 dla filmów kwadratowych (Instagram feed, niektóre reklamy społecznościowe). Generuj obrazy o prawidłowych proporcjach od samego początku. Nie twórz obrazów kwadratowych, a potem nie oczekuj, że narzędzia wideo przekonwertują je do formatu 16:9 – spowoduje to albo przycięcie kompozycji, albo dodanie treści wygenerowanych przez sztuczną inteligencję na krawędziach, co w obu przypadkach pogorszy jakość.
Jak tworzyć pary klatek kluczowych?
Wygeneruj dwie klatki przy użyciu oddzielnych potoków. Pierwsza klatka jest zgodna ze standardowym przepływem pracy: generowanie podpowiedzi, tworzenie obrazów i powtarzanie aż do uzyskania zadowalającego rezultatu. Ostatnia klatka wykorzystuje image-to-image, przesyłając pierwszą klatkę jako obraz referencyjny i opisując zmiany w stanie końcowym. Zapewnia to spójność wizualną — ta sama lokalizacja, ten sam kierunek oświetlenia, ta sama kolorystyka — przy jednoczesnym osiągnięciu pożądanego zmiany narracji (różne czasy, czynności lub nastroje). Prześlij obie klatki do generatora wideo i pozwól sztucznej inteligencji stworzyć przejście. Kompleksowy przewodnik po tej technice można znaleźć w Przewodniku projektowania pierwszej i ostatniej klatki.
Czy ten proces jest odpowiedni dla treści komercyjnych?
Odpowiednie. Trzystopniowy proces został przyjęty przez marki e-commerce do tworzenia filmów o produktach, zespoły marketingowe do tworzenia materiałów reklamowych, firmy nieruchomościowe do prezentacji nieruchomości oraz agencje treści do produkcji mediów społecznościowych. Filmy generowane przez sztuczną inteligencję, trwające od 5 do 15 sekund, z wysokiej jakości ramkami początkowymi, spełniają obecnie profesjonalne standardy dotyczące treści cyfrowych. Kluczem do sukcesu komercyjnego jest poświęcenie czasu na fazę obrazu — dopracowana ramka początkowa przekłada się bezpośrednio na dopracowany film. W przypadku dłuższych filmów lub treści komercyjnych o jakości telewizyjnej, filmy generowane przez sztuczną inteligencję są coraz częściej wykorzystywane do tworzenia kreatywnych pomysłów i wizualizacji podglądu, a ostateczna produkcja nadal odbywa się przy użyciu tradycyjnych metod, aby zapewnić maksymalną kontrolę.
Co należy zrobić, jeśli wygenerowany obraz ma niedoskonałości?
Nie kontynuuj generowania wideo. Niedoskonałości obrazu źródłowego zostaną wzmocnione w wideo — lekko zniekształcona ręka na statycznym obrazie stanie się wyraźnie zdeformowaną ręką w sekwencji ruchowej składającej się ze 120 klatek. Przeprowadź wstępną obróbkę obrazu. Użyj funkcji [image-to-image], aby ponownie wygenerować problematyczne obszary, zachowując pozostałą część kompozycji. W przypadku poważnych wad (zniekształcone postacie ludzkie, nieprawdopodobne geometrie) całkowicie wygeneruj obraz ponownie, używając zmodyfikowanego polecenia, aby obejść problem. Elementy podatne na wady to dłonie (określ „dłonie spoczywające po bokach” lub „dłonie w kieszeniach”, aby uniknąć skomplikowanych pozycji palców), tekst (unikaj umieszczania tekstu w generowanych obrazach) i odbicia (uprość powierzchnie odbijające w poleceniach). Przejdź do produkcji wideo dopiero po uzyskaniu obrazu bez wad.
Zacznij budować swój kreatywny proces twórczy
Trzyetapowy proces — polecenie → obraz → wideo — pozostaje najbardziej niezawodną metodą tworzenia wysokiej jakości filmów AI w 2026 roku. Oddziela on kontrolę twórczą (jak powinna wyglądać scena) od pożądanej zdolności generacyjnej (jak powinna się poruszać), co pozwala uzyskać filmy zgodne z wizją twórcy, a nie przypadkowe domysły AI.
Każdy dobry film zaczyna się od dobrego obrazu. Każdy dobry obraz zaczyna się od dobrego pomysłu. Dobrze przygotuj grunt, a wszystko inne przyjdzie samo.
Krok pierwszy: Generowanie podpowiedzi → — Przekształć koncepcje w profesjonalne podpowiedzi obrazkowe za pomocą generatora podpowiedzi AI firmy Seedance.
Krok drugi: Generowanie obrazu → — Wygeneruj i wielokrotnie udoskonalaj idealną ramkę początkową swojego filmu.
Krok trzeci: Generowanie wideo → — Przekształcaj obrazy w dynamiczne filmy z ruchem, ujęciami kamery i atmosferą.
Opanowanie techniki pierwszej klatki → — Przejmij kontrolę nad tworzeniem filmów AI, ucząc się projektowania klatek referencyjnych.
Więcej informacji: Przewodnik po sztucznej inteligencji Image-to-Video | Przewodnik po projektowaniu pierwszej i ostatniej klatki | Kompletny przewodnik po sztucznej inteligencji Text-to-Image | Przewodnik po sztucznej inteligencji w zakresie przekształcania obrazów | Przewodnik po generatorze podpowiedzi obrazów AI | Najlepsze generatory obrazów AI 2026 | Najlepsze generatory wideo AI na rok 2026*
