
Sekilas
Teknologi AI Text-to-Video adalah teknologi kecerdasan buatan yang secara otomatis menghasilkan video dari deskripsi teks. Masukkan narasi, dan AI akan menghasilkan klip video lengkap dengan gerakan, efek pencahayaan, dan pergerakan kamera. Pada tahun 2026, dengan memanfaatkan arsitektur Diffusion Transformer (DiT), teknologi ini telah berkembang dari prototipe eksperimental yang kabur menjadi kualitas hampir sinematik. Panduan ini mencakup prinsip teknis, tutorial praktis lima langkah, sepuluh templat prompt yang dapat direplikasi, analisis perbandingan delapan alat, enam skenario aplikasi utama, dan batasan nyata yang harus Anda pahami.Coba pembangkitan teks ke video secara gratis →

Teknologi AI Text-to-Video: Dari sebuah deskripsi sederhana hingga video berkualitas sinematik, AI menjadikan "text-to-video" menjadi kenyataan.
Apa itu AI teks-ke-video?
Teknologi AI teks-ke-video merujuk pada kategori teknologi kecerdasan buatan yang secara otomatis menghasilkan konten video dari deskripsi teks. Anda menggambarkan sebuah adegan—seorang wanita berjalan-jalan di bawah hujan, produk yang berputar di atas rak display, drone yang terbang di atas pegunungan—dan model AI akan menghasilkan klip video yang sangat realistis dengan gerakan alami, pencahayaan, dan efek fisik yang akurat.
Konsep dasarnya sederhana: masukan teks, keluaran video. Namun, teknologi di baliknya jauh dari sederhana. Sistem teks-ke-video modern menggunakan jaringan saraf yang dilatih pada miliaran dataset pasangan 'video-teks', mempelajari hubungan statistik antara deskripsi linguistik dan gerakan visual. Ketika Anda menulis "seekor kucing melompat ke atas meja", model tersebut memanfaatkan pengetahuan yang telah dikumpulkannya tentang kucing, fisika melompat, permukaan meja, dan gravitasi untuk menghasilkan video yang masuk akal.
2026: Dari Eksperimen Menjadi Alat Produktivitas
Teknologi AI teks-ke-video telah mencapai ambang batas kemampuan 'siap produksi' pada tahun 2025-2026. Sistem awal pada tahun 2022-2023 hanya mampu menghasilkan klip singkat, buram, dan tidak realistis secara fisik. Namun, model saat ini mampu menghasilkan video beresolusi 2K dengan gerakan yang akurat secara fisik, animasi yang alami, dan kualitas sinematik, berdurasi 5-15 detik. Lompatan ini mengubah teks-ke-video dari sekadar keunikan penelitian menjadi alat praktis:
- Pembuat konten: Dapatkan B-roll, urutan pembuka, dan aset media sosial tanpa kamera
- Pemasar: Produksi massal variasi iklan dan demonstrasi produk
- Pendidik: Visualisasikan konsep abstrak
- Usaha Kecil dan Menengah: Hindari biaya tinggi produksi video profesional
- Siapa pun: Jika Anda bisa menulis, Anda bisa membuat video
Ambang batas untuk membuat video telah menurun dari "memiliki kamera dan tahu cara mengedit" menjadi "menyusun deskripsi yang menarik".
Evolusi Teknologi: Dari GAN ke DiT
Memahami teknologi yang mendasari dapat membantu Anda membuat prompt yang lebih baik dan memilih alat yang lebih sesuai. Berikut adalah evolusi teknologi tiga generasi dari AI teks-ke-video.

Tiga generasi evolusi teknologi: GANs (2020–2022) → Model Difusi (2023–2024) → Transformator Difusi / DiT (2025–2026).
Generasi Pertama: Era GAN (2020–2022)
Jaringan Adversarial Generatif (GAN) adalah arsitektur pertama yang menunjukkan kelayakan konversi "teks ke video". Dua jaringan saraf menjalani pelatihan adversarial—generator menciptakan bingkai video sementara diskriminator menilai keasliannya. Namun, hasilnya beresolusi rendah (256×256), berdurasi pendek (2–4 detik), dan secara fisik tidak masuk akal. Objek mengalami deformasi yang tidak terduga, fitur wajah menjadi terdistorsi, dan konsistensi temporal sangat terganggu. Prestasi representatif termasuk CogVideo dan NUWA.
Generasi Kedua: Era Model Difusi (2023–2024)
Model difusi telah merevolusi lanskap. Model ini tidak lagi menggunakan pelatihan adversarial, melainkan mempelajari proses "reverse denoising"—mulai dari noise murni dan secara bertahap menghilangkan noise tersebut menjadi video yang koheren yang dipandu oleh teks. Pendekatan ini memberikan lompatan kualitas: resolusi yang lebih tinggi (hingga 1080p), durasi yang lebih lama (4–10 detik), dan keselarasan teks-visual yang lebih baik.
OpenAI's Sora (diluncurkan pada Februari 2024) menunjukkan bahwa model difusi dapat menghasilkan video yang sangat fotorealistik. Runway Gen-2/Gen-3, Pika, dan Stable Video Diffusion semuanya termasuk dalam generasi ini.
Generasi Ketiga: DiT — Diffusion Transformer (2025–2026)
Arsitektur paling canggih saat ini menggabungkan proses difusi dengan arsitektur Transformer (arsitektur yang sama di balik GPT dan BERT). Model DiT memproses video sebagai urutan patch spasial-waktu, mencapai:
- Konsistensi temporal yang ditingkatkan: Transformers unggul dalam memodelkan ketergantungan jangka panjang antar frame
- Resolusi yang lebih tinggi: Output asli 2K (Seedance 2.0 mencapai 2048×1080)
- Ketepatan fisik yang ditingkatkan: Gerakan, gravitasi, dan dinamika fluida yang lebih realistis
- Pemahaman teks yang lebih kuat: Peningkatan signifikan dalam keselarasan antara deskripsi prompt dan output visual
- Masukan multimodal: Beberapa model DiT dapat menerima masukan gambar, video, dan audio secara bersamaan
Seedance 2.0, Google Veo 3, dan Keeling 3.0 semuanya menggunakan arsitektur DiT. Inilah mengapa generasi teks-ke-video pada tahun 2026 menunjukkan perbedaan kualitas yang signifikan dibandingkan dengan tahun 2024.
Tekst ke Video vs Gambar ke Video
Kedua pendekatan ini saling melengkapi, bukan saling bersaing:
| Dimensi | Teks ke Video (T2V) | Gambar ke Video (I2V) | |------|------------------|----------------- -| | Masukan | Deskripsi teks saja | Foto + deskripsi gerakan | | Kebebasan Kreatif | Tertinggi — AI menentukan semua elemen visual | Terbatas oleh gambar sumber | | Kontrolabilitas | Lebih rendah — Bergantung pada akurasi prompt | Lebih tinggi — Ancaman visual tersedia | | Skenario yang Cocok | Eksplorasi konsep, konten asli | Tampilan produk, animasi foto, pencocokan gaya | | Prediktabilitas | Rendah — Prompt yang sama menghasilkan hasil berbeda setiap kali | Tinggi — Output secara konsisten sesuai dengan gambar sumber |
Sebagian besar alur kerja profesional menggunakan kedua pendekatan ini: pertama menggunakan T2V untuk mengeksplorasi konsep kreatif, kemudian menyempurnakan hasilnya dengan I2V. Untuk penjelasan mendalam tentang pembangkitan gambar ke video, silakan merujuk ke panduan lengkap kami Image-to-Video AI Complete Guide.
Panduan 5 Langkah: Membuat Video AI Pertama Anda
Berikut ini adalah panduan langkah demi langkah untuk membuat konten teks-ke-video dari awal, menggunakan Seedance 2.0 sebagai platform demonstrasi. Prinsip-prinsip dasar yang digunakan berlaku untuk alat apa pun.

Dari pembuatan prompt hingga output akhir: Lima langkah untuk menyelesaikan video AI pertama Anda.
Langkah 1: Tentukan tujuan video
Sebelum menulis prompt, tentukan terlebih dahulu:
- Jenis: B-roll, demonstrasi produk, konten media sosial, karya seni, atau narasi?
- Durasi: 5 detik untuk pengujian, 10-15 detik untuk output akhir
- Aspect ratio: 16:9 untuk YouTube / Bilibili, 9:16 untuk Douyin / Kuaishou / Xiaohongshu, 1:1 untuk WeChat Moments
- Gaya: Sinematik, dokumenter, animasi, iklan komersial, atau seni
Menetapkan tujuan yang jelas mencegah pemborosan kuota generasi pada eksperimen yang tidak jelas.
Langkah 2: Membuat Prompt Teks Berkualitas Tinggi
Prompt adalah inti dari proses generasi teks ke video. Gunakan rumus berikut:
[Subjek] + [Aksi/Gerakan] + [Latar Belakang] + [Gaya] + [Gerakan Kamera] + [Pencahayaan]
Prompt yang buruk: "Seekor anjing yang berlari"
Prompt yang bagus: "Seekor anjing golden retriever berlari melintasi padang rumput yang diterangi matahari, bunga-bunga liar bergoyang-goyang diterpa angin. Bulu anjing itu bergelombang dengan setiap langkahnya. Kamera mengikuti dari tingkat tanah. Pencahayaan hangat pada jam emas dengan bayangan panjang. Kedalaman bidang yang dangkal secara sinematik, kualitas 4K."
Prinsip Utama:
- Gerakan harus spesifik: "memutar kepala perlahan" daripada "memutar"
- Jelaskan gerakan kamera: "kamera mendekat" atau "pembuatan gambar udara dengan drone"
- Menciptakan suasana: Pencahayaan, penyesuaian warna, suasana
- Hindari kontradiksi: Jangan meminta "aksi cepat" dan "gerakan lambat" secara bersamaan
- Jangan meminta teks/antarmuka pengguna: Model saat ini kesulitan menampilkan teks yang terbaca dalam rekaman video
Catatan: Disarankan untuk menyusun prompt dalam bahasa Inggris, bahkan saat menggunakan alat domestik (seperti KeLing, TongYi WanXiang, atau Hunyuan Video). Hal ini karena sebagian besar model telah dilatih menggunakan dataset bahasa Inggris yang lebih luas.
Untuk sistem teknik prompt yang lebih komprehensif, silakan merujuk ke Panduan Penulisan Prompt dan 10 Prompt Video AI yang Sungguh Efektif.
Langkah 3: Pilih Alat dan Parameter
Pilih platform (lihat tabel perbandingan di bawah), lalu konfigurasikan:
- Model: Gunakan model terbaru yang tersedia (misalnya, Seedance 2.0, bukan 1.0)
- Resolusi: Minimal 1080p; pilih 2K jika tersedia
- Durasi: Uji coba dengan 5 detik awalnya, perpanjang jika memuaskan
- Aspect Ratio: Sesuaikan dengan platform distribusi Anda
- Nilai Benih (jika tersedia): Kunci nilai benih untuk iterasi yang konsisten
Langkah 4: Buat dan Periksa
Klik Generate dan tunggu selama 60–180 detik (tergantung pada alat yang digunakan). Saat memeriksa hasilnya, perhatikan:
- ✅ Apakah gerakan sesuai dengan deskripsi?
- ✅ Apakah subjek konsisten sepanjang video (tanpa distorsi)?
- ✅ Apakah fisika dalam adegan masuk akal (gravitasi, cairan, kain)?
- ✅ Apakah gerakan kamera lancar?
- ❌ Apakah ada artefak, kedipan, atau distorsi?
- ❌ Apakah ada efek uncanny valley pada wajah/tangan?
Langkah 5: Optimasi Iteratif
Upaya pertama jarang sempurna. Metode optimasi:
- Sesuaikan prompt: Tambahkan detail di bagian yang salah oleh AI
- Ubah hanya satu variabel sekaligus: Hindari menulis ulang seluruh prompt
- Coba berbagai benih (seeds): Prompt yang sama dapat menghasilkan hasil yang benar-benar berbeda
- Perpanjang durasi: Setelah puas dengan versi 5 detik, coba 10–15 detik
- Tambahkan audio: Jika didukung oleh alat (Seedance, Veo 3), sertakan efek suara atau musik latar

Contoh iterasi prompt: V1 (prompt dasar) → V2 (menambahkan deskripsi gerakan dan pencahayaan) → V3 (spesifikasi sinematik lengkap). Setiap siklus penyempurnaan secara signifikan meningkatkan kualitas gambar.
10 Template Prompt untuk Pembuatan Video dari Teks
Template-template berikut dapat disalin dan digunakan langsung. Template-template ini telah diuji pada Seedance 2.0 dan kompatibel dengan sebagian besar platform utama.
1. Potret Sinematik
A close-up of a young woman with flowing dark hair, her face illuminated by warm golden hour sunlight filtering through a window. She slowly turns her head toward the camera, a subtle smile forming. Soft bokeh background of a cozy interior. Camera holds steady with a slight push-in. Warm amber lighting, shallow depth of field, 4K cinematic quality.
Skenario yang Sesuai: Media sosial, branding pribadi, penciptaan seni
- Tampilan Produk
A sleek wireless headphone rotating slowly on a matte black pedestal. Soft studio lighting creates clean highlights on the brushed metal surface. Camera orbits 180 degrees at eye level. Minimalist white background, no shadows. Smooth continuous motion, commercial product photography quality.
Skenario yang Cocok: Halaman detail produk e-commerce, pemasaran produk, video gambar utama Taobao/JD.com
- Alam Sinematik
An epic aerial drone shot over a misty mountain valley at sunrise. Golden light breaks through layered clouds, illuminating a winding river below. Camera pushes forward slowly, revealing the vast landscape. Volumetric fog drifts between peaks. IMAX cinematography quality, hyper-detailed.
Cocok untuk: Video pembuka YouTube/Bilibili, konten perjalanan, layar pengaman, saluran meditasi
4. Jalan Kota
A neon-lit Tokyo alley at night after rain. Wet cobblestones reflect vivid pink, teal, and amber neon signs. A lone figure walks away from camera, umbrella in hand. Steam rises from a street vent. Camera follows at a distance, tracking shot. Film noir atmosphere, anamorphic lens flare.
Skenario yang Cocok: Video musik, footage B-roll yang atmosferik, konten bergaya cyberpunk
- Gaya Anime
An anime warrior princess with flowing silver hair stands on a cliff edge overlooking a fantasy kingdom. Her cape billows dramatically in the wind. She raises a glowing sword that emits blue energy particles. Cherry blossom petals drift past. Camera slowly orbits. Studio Ghibli meets Ufotable quality animation.
Cocok untuk: Konten animasi, saluran game, narasi fantasi
6. Makanan & Minuman
Extreme macro close-up of rich dark coffee being poured in slow motion into a pristine ceramic cup. Individual droplets and tiny splashes frozen mid-air. Wisps of steam curl elegantly upward. Warm side lighting reveals the liquid's amber transparency. Cinnamon stick and scattered beans visible in soft focus foreground.
Skenario yang Cocok: Pemasaran makanan dan minuman, blogger makanan, iklan minuman
- Mode & Editorial
A model in a flowing white silk gown walks confidently down a dark runway. Multiple flash strobes create sharp geometric light patterns. The fabric billows with perfect physics. Camera at a low angle, slight slow motion. High fashion editorial aesthetic, Vogue magazine quality.
Skenario yang Cocok: Merek fashion, konten kecantikan, fitur editorial
- Fiksi Ilmiah & Fantasi
A massive spaceship emerges from hyperspace above a ringed planet. Blue energy dissipates around the hull as the vessel decelerates. Tiny fighter escorts flank its sides. Camera pulls back to reveal the scale against the planet. Volumetric space dust and distant star field. Hollywood VFX quality.
Skenario yang Berlaku: Konten hiburan, saluran fiksi ilmiah, visualisasi konsep
- Olahraga & Aksi
A basketball player at the peak of a slam dunk, frozen in mid-air. Time resumes in slow motion — sweat droplets fly, the ball compresses against the rim, arena spotlights create dramatic lens flare. Camera shoots from below looking up. ESPN broadcast quality, hyper-detailed.
Cocok untuk: Konten olahraga, merek olahraga, kumpulan sorotan
- Seni Abstrak (Abstrak & Seni)
Liquid gold and deep indigo ink collide in slow motion inside a glass sphere. The fluids intertwine in mesmerizing fractal patterns. Tiny bubbles catch light. Camera slowly rotates around the sphere. Pure black background. Macro photography meets fluid dynamics simulation. Meditative, hypnotic pace.
Skenario yang Cocok: Visual latar belakang, video musik, instalasi seni, layar pengaman.

Hasil aktual dari empat dari sepuluh templat di atas—setiap prompt menghasilkan visual yang bergaya khas dan berkualitas sinematik dari teks biasa.
2026: Ulasan Perbandingan Delapan Alat Generasi Teks ke Video
Kami menguji delapan platform utama menggunakan prompt yang sama ("Seekor anjing golden retriever berlari melintasi padang rumput yang diterangi matahari, bunga liar bergoyang, kualitas sinematik 4K"), dan mengevaluasi mereka berdasarkan lima dimensi. Semua pengujian selesai pada Februari 2026.
| Alat | Resolusi Maksimum | Durasi Maksimum | Versi Gratis | Audio | Penggunaan Terbaik | Peringkat Kualitas Gambar | |------|----------|---------|--------|------|-------- -|---------| | Seedance 2.0 | 2K (2048×1080) | 15 detik | ✅ Kuota gratis harian | ✅ Efek suara + musik + sinkronisasi bibir | Pembuatan multimodal | 9.2/10 | | Google Veo 3 | 4K (terbatas) | 8 detik | ✅ Kuota AI Studio | ✅ Audio asli | Integrasi audio-visual | 9.0/10 | | Sora 2 | 1080p | 20 detik | ❌ Membutuhkan ChatGPT Plus | ❌ | Video didorong teks panjang | 8.8/10 | | Keling 3.0 | 1080p | 20+ detik | ✅ Kredit pendaftaran gratis | ⚠️ Terbatas | Video panjang, nilai untuk uang | 8.5/10 | | Runway Gen-4 | 1080p | 10 detik | ✅ 125 kredit | ❌ | Alur kerja pengeditan profesional | 8.5/10 | | Pika 2.0 | 1080p | 10 detik | ✅ Kuota gratis harian | ⚠️ Hanya efek suara | Pengguna pemula, efek yang menyenangkan | 8.0/10 | | Luma Dream Machine | 1080p | 5 detik | ✅ Pembuatan gratis | ❌ | Adegan 3D, iterasi cepat | 7.8/10 | | Snail AI (MiniMax) | 1080p | 6 detik | ✅ Kuota gratis harian | ❌ | Kecepatan generasi tercepat | 7.5/10 |
Pemberitahuan Penting untuk Pengguna Dalam Negeri: Seedance 2.0, KeLing 3.0, dan Haier AI dapat diakses langsung di dalam wilayah Tiongkok Daratan. Sora 2 memerlukan langganan ChatGPT Plus (VPN diperlukan). Google Veo 3 memerlukan akses melalui Google AI Studio (VPN diperlukan). Runway, Pika, dan Luma semuanya memerlukan koneksi jaringan luar negeri.
Alternatif Dalam Negeri: Tongyi Wanxiang (Alibaba), Hunyuan Video (Tencent), dan Qingying (anak perusahaan ByteDance) juga menawarkan kemampuan generasi teks ke video, dengan kuota penggunaan gratis yang bervariasi.
Kesimpulan Utama:
- Kualitas gambar terbaik secara keseluruhan: Seedance 2.0 (resolusi asli 2K + mode input quad + audio)
- Kemampuan audio terbaik: Seedance 2.0 dan Google Veo 3
- Versi gratis terbaik: Seedance 2.0 (Akses gratis ke resolusi 2K, tidak memerlukan kartu kredit)
- Durasi video gratis terpanjang: Keeling 3.0 (20+ detik)
- Palingsesuai untuk pemula: Pika 2.0 (Antarmuka paling sederhana, efek yang menyenangkan)
Untuk perbandingan yang lebih rinci, silakan merujuk ke Perbandingan Lengkap Generator Video AI Terbaik untuk 2026. Untuk fokus hanya pada paket gratis, silakan lihat Ulasan Perbandingan Generator Video AI Gratis.
6 Skenario Aplikasi Utama
- Konten media sosial
Buat video pendek yang menarik perhatian untuk TikTok, Kuaishou, Xiaohongshu, Bilibili, dan YouTube Shorts. AI menghilangkan kebutuhan untuk pengambilan gambar, pengeditan, dan pasca-produksi sepenuhnya.
Spesifikasi yang Direkomendasikan: Rasio aspek 9:16, durasi 5–15 detik, dengan detik pertama memberikan dampak visual yang kuat.
- Pemasaran dan Periklanan
Produksi massal variasi materi iklan. Uji beberapa konsep visual menggunakan prompt yang berbeda sebelum memutuskan anggaran produksi resmi. Buat versi uji A/B dalam hitungan menit.
Konfigurasi yang Direkomendasikan: Kompatibilitas multi-format di berbagai platform. Padukan dengan kemampuan audio Seedance untuk menghasilkan film iklan yang lengkap.
3. Pendidikan dan Pelatihan
Menampilkan konsep abstrak yang sulit atau tidak mungkin difilmkan: struktur molekul, peristiwa sejarah, konsep matematika, proses ilmiah. Video AI membuat yang tidak terlihat menjadi terlihat.
Konfigurasi yang direkomendasikan: Untuk hasil pembelajaran yang optimal, padukan prompt yang secara tepat menjelaskan konsep dengan audio yang diiringi narasi.
- Hiburan dan Narasi
Pembuat film independen dan pencipta cerita memanfaatkan teknologi teks-ke-video untuk visualisasi konsep, pembuatan storyboard, dan bahkan produksi akhir film pendek. Teknologi ini mendemokratisasi pembuatan film.
Konfigurasi yang direkomendasikan: Sertakan spesifikasi detail arah kamera dan pencahayaan dalam prompt untuk mencapai efek sinematik.
- Video Produk E-commerce
Ubah deskripsi produk menjadi video demonstrasi. Hal ini sangat berguna bagi pedagang yang memiliki ratusan SKU dan tidak dapat membuat video terpisah untuk setiap produk. Untuk alur kerja e-commerce yang lebih rinci, silakan merujuk ke Panduan Video E-commerce AI.
Spesifikasi yang Direkomendasikan: Fotografi produk dengan pengaturan pencahayaan studio. Rasio aspek 1:1 untuk halaman detail produk, 16:9 untuk YouTube/Bilibili, dan 9:16 untuk TikTok/Xiaohongshu.
6. Pembuatan Konten YouTube / Bilibili
Buat klip B-roll, urutan pembuka, komentar visual, dan video pendek lengkap. Para kreator dapat meningkatkan efisiensi produksi konten dengan teknologi video AI. Untuk alur kerja kreator YouTube yang komprehensif, silakan merujuk ke Panduan Kreator YouTube AI Video.
Konfigurasi yang direkomendasikan: Pertahankan konsistensi visual di semua prompt untuk membangun pengenalan merek.
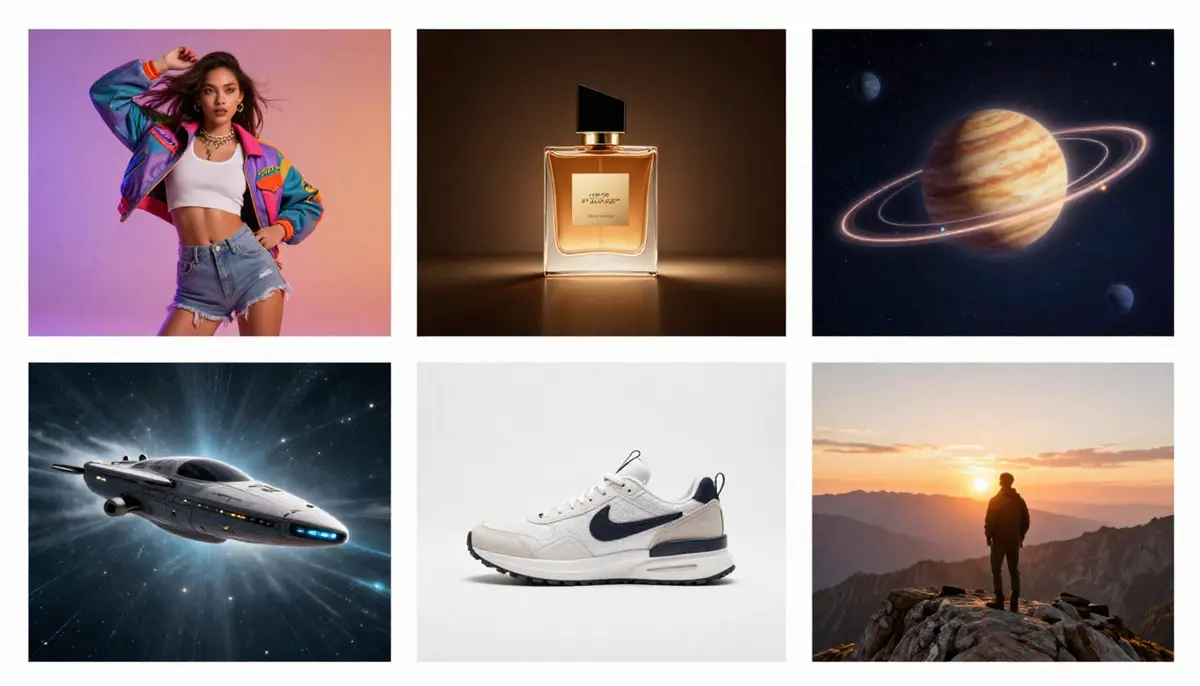
Enam Aplikasi Praktis Kecerdasan Buatan (AI) Text-to-Video: Dari Video Pendek di Media Sosial hingga Demonstrasi Produk E-commerce, dan Visualisasi Konsep Pendidikan.
Text-to-Video vs Image-to-Video: Kapan Menggunakan Mana?
Ini adalah salah satu pertanyaan yang paling sering diajukan oleh pengguna baru. Jawabannya tergantung pada bahan-bahan yang Anda miliki dan apa yang Anda butuhkan.

Dua Pendekatan dalam Pembuatan Video AI: Pembuatan video dari teks dimulai dari teks, sementara pembuatan video dari gambar dimulai dari foto yang sudah ada.
Skenario untuk Text-to-Video (T2V):
- Anda sedang membuat konten baru sepenuhnya (tanpa gambar referensi)
- Anda menginginkan kebebasan kreatif maksimal
- Anda sedang melakukan eksplorasi konsep atau brainstorming visual
- Anda memerlukan adegan abstrak atau yang tidak dapat difoto (fiksi ilmiah, fantasi, mikroskopis/makroskopis)
- Anda ingin melakukan iterasi dengan cepat—mengubah prompt menghasilkan adegan yang benar-benar berbeda
Skenario untuk menghasilkan video dari gambar (I2V):
- Anda memiliki foto tertentu yang memerlukan animasi
- Anda memerlukan output yang persis sesuai dengan efek visual yang sudah ada
- Anda sedang mengubah gambar produk menjadi video produk
- Anda memerlukan konsistensi karakter (orang yang sama di seluruh adegan)
- Anda menginginkan hasil yang lebih dapat diprediksi dan terkendali
Praktik Terbaik — Menggabungkan Kedua Pendekatan:
- Gunakan generasi teks-ke-video untuk menjelajahi arah kreatif
- Pilih bingkai optimal sebagai gambar referensi
- Gunakan generasi gambar-ke-video untuk versi akhir yang lebih halus dan terkontrol
Untuk alur kerja generasi gambar ke video yang komprehensif, silakan merujuk ke Panduan Lengkap AI Gambar ke Video.
Batasan Saat Ini — Penilaian Jujur
Teknologi AI teks-ke-video pada tahun 2026 memang mengesankan, namun masih jauh dari sempurna. Berikut adalah area di mana teknologi ini saat ini unggul dan area yang masih menantang.
Bagus sekali
- Video pendek (5-15 detik): Kualitas gambar mendekati standar sinematik
- Adegan dengan satu subjek: Satu orang, satu hewan, satu objek—hasil yang sangat baik
- ** Alam dan lanskap**: Reproduksi luar biasa dari dinamika fluida, cuaca, dan efek atmosfer
- Konten bergaya: Animasi, film noir, fiksi ilmiah – konversi gaya yang sangat andal
- Tampilan rotasi produk: Gerakan produk sederhana dengan konsistensi yang baik
- Gerakan kamera: Pan, zoom, dolly, tracking shots – terkendali dengan baik
Masih sulit
- Tangan dan jari: Jari tambahan, gerakan yang tidak wajar, dan kelainan bentuk falang tetap umum terjadi
- Penampilan teks: Teks yang dapat dibaca dalam video tidak dapat diandalkan—huruf tampak terdistorsi, karakter melengkung
- Interaksi kompleks antar orang: Jabat tangan dua orang, menari bersama, atau berkelahi sering menyebabkan ketidakaturan anggota tubuh
- Narasi yang panjang (>30 detik): Konsistensi adegan menurun selama periode yang panjang
- Fisika yang presisi: Lompatan bola yang presisi, air yang mengalir ke wadah tertentu — fisika bersifat perkiraan, bukan tepat*⦁NLBR⦁* Konsistensi wajah jangka panjang: Fitur wajah mungkin mengalami perubahan halus antar frame, terutama selama durasi yang panjang.
Tren Kemajuan
Setiap keterbatasan ini akan mengalami perbaikan yang signifikan pada tahun 2026 dibandingkan dengan tahun 2024. Kecepatan perbaikan bersifat eksponensial. Render tangan berkembang dari "selalu salah" menjadi "umumnya akurat". Konsistensi wajah berubah dari "berubah setelah 2 detik" menjadi "stabil selama 10-15 detik". Render teks meningkat dari "tidak terbaca" menjadi "kadang-kadang terbaca". Masalah-masalah ini diperkirakan akan terus membaik dengan cepat antara tahun 2026 dan 2027.
Pertanyaan yang Sering Diajukan
Apa AI teks-ke-video terbaik untuk tahun 2026?
Seedance 2.0 unggul dalam kualitas gambar secara keseluruhan dengan resolusi asli 2K, input quad-modal, dan pembangkitan audio terintegrasi. Google Veo 3 unggul dalam fusi audio-visual dan simulasi fisik. Sora 2 menawarkan durasi generasi tunggal terpanjang (20 detik). "Yang terbaik" tergantung pada kebutuhan spesifik Anda—resolusi, audio, durasi, atau harga. Pengguna domestik juga dapat mempertimbangkan Keeling 3.0 (nilai terbaik untuk uang, video panjang) dan Tongyi Wanxiang (terintegrasi dengan ekosistem Alibaba).
Apakah ada AI teks-ke-video gratis?
Ya. Seedance 2.0 menawarkan kuota gratis harian tanpa memerlukan kartu kredit. Pika 2.0 menyediakan pembangkitan gratis harian. Keiling 3.0 memberikan kuota pendaftaran. Google Veo 3 menawarkan kuota gratis melalui AI Studio. Conch AI juga memiliki kuota gratis harian. Untuk detailnya, lihat Perbandingan Generator Video AI Gratis.
Seberapa lama video yang dihasilkan oleh kecerdasan buatan (AI) berdasarkan teks dapat dibuat?
Sebagian besar alat menghasilkan konten dalam increment 5-15 detik. Sora 2 dapat menghasilkan hingga 20 detik. Keeling 3.0 mendukung lebih dari 20 detik. Untuk kebutuhan konten yang lebih panjang, beberapa segmen dapat dihasilkan dan disatukan menggunakan perangkat lunak pengeditan seperti Kinevision, Premiere Pro, atau DaVinci Resolve.
Apakah AI teks-ke-video dapat menghasilkan visual berkualitas profesional?
Dalam rentang waktu 5-15 detik, hal ini memungkinkan. Output dari Seedance 2.0 dan Veo 3 seringkali tidak dapat dibedakan dari rekaman profesional dalam klip pendek. Untuk proyek yang lebih panjang, video AI sebaiknya digunakan sebagai bagian dari materi (B-roll, adegan transisi, efek visual), bukan sebagai keseluruhan produksi.
Bagaimana cara membuat prompt yang efektif untuk generasi teks ke video?
Ikuti rumus berikut: Subjek + Aksi + Latar Belakang + Gaya + Sudut Pandang + Pencahayaan. Deskripsi gerakan harus spesifik, pergerakan kamera harus jelas didefinisikan, dan suasana harus ditetapkan dengan jelas. Hindari kontradiksi dan jangan meminta elemen teks/antarmuka pengguna. Lakukan iterasi secara bertahap dari yang sederhana ke yang kompleks. Untuk detail lebih lanjut, lihat Panduan Penulisan Prompt.
Manakah yang lebih unggul: pembangkitan teks ke video atau pembangkitan gambar ke video?
Berbagai aplikasi. Text-to-video memberikan kebebasan kreatif maksimal saat tidak ada bahan referensi yang tersedia. Image-to-video memberikan kontrol yang lebih besar saat ada titik awal visual yang spesifik. Sebagian besar profesional menggunakan kedua pendekatan ini—menggunakan text-to-video untuk pekerjaan eksplorasi dan image-to-video untuk penyempurnaan.
Apakah video yang dihasilkan oleh teks AI dapat digunakan untuk tujuan komersial?
Sebagian besar paket berbayar memberikan hak komersial. Versi berbayar Seedance 2.0 mencakup hak komersial penuh dan bebas watermark. Ketentuan layanan bervariasi antar platform; harap periksa kebijakan spesifik sebelum penggunaan. Di China, penggunaan komersial konten yang dihasilkan oleh kecerdasan buatan (AI) saat ini tidak menghadapi batasan regulasi eksplisit, meskipun disarankan untuk memantau pembaruan terhadap Peraturan Sementara tentang Pengelolaan Layanan Kecerdasan Buatan Generatif.
Apakah kecerdasan buatan (AI) yang mengubah teks menjadi video akan menggantikan editor?
Hal ini tidak akan menggantikan, melainkan mengubah peran. AI menangani pembangkitan konten—membuat aset visual asli dari deskripsi. Editor manusia mengelola narasi, tempo, resonansi emosional, konsistensi merek, dan keputusan kreatif yang memerlukan penilaian manusia. Pada tahun 2026, alur kerja paling efektif akan menjadi pembangkitan AI + pengeditan manusia.
Mulai membuat video dengan teks
Pada tahun 2026, teknologi AI text-to-video akan siap untuk aplikasi profesional. Berawal dari eksperimen GAN yang kabur hingga menghasilkan output DiT yang hampir setara dengan film dalam waktu empat tahun, teknologi ini kini mampu menangani konten media sosial, demonstrasi produk, visualisasi pendidikan, dan eksplorasi kreatif.
Cara terbaik untuk belajar adalah dengan mulai membuat. Tulis prompt, lihat hasilnya, dan ulangi.
Ubah paragraf pertama Anda menjadi video – coba Seedance secara gratis →
Mencari presisi kontrol yang lebih tinggi? Coba pembangkitan gambar ke video →
Ingin mempelajari teknik prompt secara lebih mendalam? Baca Panduan Penulisan Prompt Kami →
