
Sekilas
Cara paling efektif untuk membuat video AI bukanlah dengan hanya memasukkan deskripsi ke dalam alat teks-ke-video. Sebaliknya, mulailah dengan gambar yang telah disiapkan dengan cermat.
Pipa tiga tahap — prompt → gambar → video — menghasilkan hasil yang jauh melampaui generasi teks-ke-video saja. Pertama, buat prompt berkualitas profesional. Gunakan prompt ini untuk menghasilkan gambar dengan komposisi yang presisi. Kemudian masukkan gambar ini sebagai frame pertama ke dalam generator video. Hasilnya: Anda mendapatkan kendali presisi atas konten visual, atmosfer pencahayaan, detail komposisi, dan titik awal gerakan.
Seedance adalah satu-satunya alat yang mengintegrasikan ketiga tahap dalam satu platform: Image Prompt Generator membantu Anda membuat prompt profesional, Text-to-Image menghasilkan gambar referensi berkualitas tinggi, dan Image-to-Video mengubah gambar menjadi klip video sinematik. Tidak perlu berganti alat, tidak perlu mengunduh dan mengunggah ulang – dari inspirasi hingga hasil akhir, semuanya dilakukan dalam alur yang mulus.
Langkah 1: Buat Prompt → | Langkah 2: Buat Gambar → | Langkah 3: Buat Video →

Kiri: Pembangkitan teks-ke-video murni — komposisi acak, visual yang tidak terkendali. Kanan: Alur kerja berbasis gambar — sempurnakan visual terlebih dahulu, lalu tambahkan gerakan; komposisi yang presisi, kualitas yang konsisten.
Mengapa "Gambar Dahulu, Video Kemudian" Jauh Lebih Unggul daripada Konversi Teks ke Video
Mereka yang pernah menggunakan Wensheng Video tahu pengalaman ini: Anda menulis deskripsi detail—mencakup subjek, pencahayaan, sudut kamera, dan komposisi—namun rekaman yang dihasilkan oleh AI sama sekali tidak mirip dengan visi Anda. Karakter menghadap ke arah yang salah, pencahayaan datar, komposisi tampak dihasilkan secara acak, dan peran tidak sesuai dengan deskripsi.
Ini bukanlah kelemahan pada alat tertentu, melainkan batasan struktural yang melekat pada pendekatan teks-ke-video.
Batasan Alami dalam Pembuatan Konten Berbasis Video
Wensheng Video menuntut agar AI menyelesaikan dua tugas yang sangat menantang secara bersamaan: menghasilkan gambar dan menghasilkan gerakan. Model harus menginterpretasikan teks Anda, menentukan penampilan setiap piksel, menyusun adegan, mengatur pencahayaan dan bayangan, menetapkan posisi kamera, dan kemudian menghasilkan gerakan yang kohesif berdasarkan semua ini—semua dari satu potong teks.
Akibatnya, setiap aspek berada di luar kendali:
- Komposisi acak. Anda menulis "seorang wanita berdiri di tengah jalan", namun dia berakhir di sepertiga kiri, dengan setengah bingkai didominasi oleh bangunan yang tidak perlu.
- **Karakter yang tidak konsisten. ** Struktur wajah, pakaian, gaya rambut, dan proporsi tubuh berubah-ubah di setiap generasi. AI menghasilkan "interpretasi kreatif," bukan spesifikasi Anda.
- **Pencahayaan yang tidak terkendali. ** Bahkan dengan spesifikasi "golden hour, pencahayaan hangat dari kiri," hasilnya tetap tidak konsisten. Interpretasi AI terhadap deskripsi pencahayaan tetap sangat samar.
- Komposisi yang tidak dapat diandalkan. Close-up, medium shot, full shot—alat teks-ke-video menginterpretasikan istilah-istilah ini dengan ketidakstabilan yang ekstrem. Minta close-up ekstrem, dan ia memberikan full-body shot.
Untuk eksperimen kreatif eksploratif, ketidakpastian ini bisa menjadi bagian dari keseruannya. Namun, jika Anda membutuhkan hasil profesional yang terkendali dan dapat diandalkan, hal ini menjadi kelemahan fatal.
Keunggulan Utama Prioritas Gambar
TuSheng Video telah sepenuhnya membalikkan persamaan ini. Anda tidak lagi memerlukan AI untuk menghasilkan visual dan gerakan secara bersamaan; sebaliknya, Anda memisahkan kedua tugas tersebut:
- Mulailah dengan gambar. Subjek, komposisi, pencahayaan, warna, bingkai—Anda sepenuhnya mengendalikan semuanya, mengulang hingga sempurna.
- Kemudian tambahkan gerakan. Tugas tunggal AI adalah menganimasi bingkai sempurna Anda. Ia tidak perlu menafsirkan deskripsi yang samar atau membuat keputusan komposisi; sebaliknya, ia menghasilkan gerakan dari titik acuan visual konkret Anda.
Pemisahan fokus ini menghasilkan hasil yang lebih baik di setiap aspek:
- Komposisi terkunci. Objek tetap berada persis di tempat Anda menempatkannya.
- Konsistensi karakter. Ciri wajah, pakaian, dan proporsi tetap identik dengan gambar asli sepanjang proses.
- **Pencahayaan dan bayangan terjaga. ** Arah cahaya, tekstur, dan suhu warna sepenuhnya diwarisi dari gambar.
- Bingkai tetap. Posisi kamera dan sudut pandang tetap konsisten dengan pengaturan asli gambar.
Sebagai ilustrasi: text-to-video mirip dengan mendeskripsikan adegan film melalui telepon dan memerintahkan seseorang untuk merekamnya. Image-to-video, di sisi lain, seperti menunjukkan foto kepada seseorang dan berkata, "Jadikan gambar ini hidup." Pendekatan terakhir ini menghasilkan hasil yang lebih terkontrol dan berkualitas tinggi, karena AI menerima referensi visual konkret daripada deskripsi teks abstrak.
Efek Multiplier Kualitas
Manfaatnya bersifat kumulatif. Bingkai pembuka yang dirancang dengan cermat meningkatkan setiap aspek video:
- Konsistensi temporal yang ditingkatkan — Model ini dilengkapi dengan penanda visual berkualitas tinggi untuk menjaga kohesi sepanjang urutan.
- Kualitas gerak yang ditingkatkan — Model ini secara akurat mengekstrak informasi kedalaman, pencahayaan, dan spasial dari gambar sumber yang jelas.
- Konsistensi Gaya yang Ditingkatkan — Sistem warna, suasana, dan estetika langsung tertanam dalam gambar, sehingga tidak ada ruang untuk interpretasi teks.
- Penurunan Tingkat Ketidaksempurnaan — Model ini dimulai dengan data visual bersih dan beresolusi tinggi, bukan mensintesis semuanya dari noise.
Video yang dihasilkan dari frame pertama berkualitas tinggi menunjukkan keunggulan yang signifikan dibandingkan dengan video yang dihasilkan hanya dari teks dengan prompt yang sama dalam hal kualitas visual, kontinuitas temporal, dan daya tarik estetika. Ini bukanlah perbedaan yang halus—ini mewakili jurang antara "demonstrasi AI yang menghibur" dan "konten yang dapat digunakan secara profesional".
Untuk panduan mendalam tentang cara mendesain gambar khusus untuk pembangkitan video, lihat Panduan Desain Frame Pertama dan Terakhir.
Pipa Kreatif AI Tiga Tahap
Alur kerja lengkap dibagi menjadi tiga tahap, masing-masing dibangun di atas tahap sebelumnya. Setiap tahap yang ditangani dengan sembarangan pada akhirnya akan mengganggu hasil akhir. Memahami kontribusi masing-masing tahap—dan di mana harus menginvestasikan waktu—adalah kunci untuk secara konsisten menghasilkan video AI berkualitas tinggi.
Fase Pertama: Pembangkitan Prompt
Semua dimulai dari prompt. Prompt yang biasa-biasa saja → gambar yang biasa-biasa saja → video yang biasa-biasa saja. Prompt yang luar biasa → gambar yang menakjubkan → video yang menakjubkan. Kualitas prompt adalah faktor terpenting dalam kualitas hasil akhir, dan ini juga merupakan tahap yang paling sedikit diperhatikan dalam sebagian besar alur kerja.
Masalah dengan menulis prompt secara manual. Kebanyakan orang mendekati penulisan prompt seperti membuat kata kunci pencarian: singkat, samar, dan hanya berfokus pada subjek. "Jam tangan mewah, latar belakang gelap." Ini memberi tahu AI apa yang harus digambar, tetapi gagal memberi instruksi bagaimana menggambarnya. Model mengisi celah dengan nilai default—pencahayaan datar, komposisi terpusat, tanpa detail atmosferik, tanpa arahan gaya.
Solusi: Pembuatan prompt dengan bantuan AI. Generator prompt ini mengembangkan ide-ide kasar Anda menjadi prompt profesional yang mencakup topik, lingkungan, pencahayaan, warna, komposisi, gaya, dan peningkatan kualitas gambar. Perbedaan kualitas output antara prompt manual berisikan 10 kata dan prompt yang dihasilkan berisikan 100 kata mewakili lompatan kualitas yang signifikan.
Seedance's Image Prompt Generator melakukan hal tersebut secara tepat. Masukkan deskripsi singkat seperti "iklan jam tangan mewah, gelap dan dramatis", pilih gaya (fotorealistik, sinematik, ilustratif, dll.), dan AI secara instan menghasilkan prompt profesional lengkap. Seluruh proses hanya memakan waktu beberapa detik, dengan biaya 2 kredit per prompt. Untuk panduan lengkap tentang pembuatan prompt, lihat Panduan Generator Prompt Gambar AI.
Mengapa langkah ini begitu penting. Prompt adalah inti dari seluruh alur kerja Anda. Ia menentukan gaya, suasana, komposisi, dan batas kualitas untuk semua yang mengikuti. Menghabiskan lima menit untuk menyempurnakan prompt Anda sebelum menghasilkan gambar dapat menghemat tiga puluh menit pengulangan penyesuaian pada hasil yang biasa-biasa saja di kemudian hari.
Tahap Dua: Pembangkitan Gambar
Setelah menerima petunjuk profesional, langkah selanjutnya adalah menghasilkan gambar yang akan digunakan sebagai bingkai pembuka video. Di sini, Anda beralih dari teks ke visual, menandai tahap di mana waktu iterasi paling banyak harus diinvestasikan.
Dari prompt ke gambar. Salin prompt yang dihasilkan ke alat teks-ke-gambar dan klik "Generate". Evaluasi hasilnya: Apakah komposisinya cocok untuk video? Apakah pencahayaannya cukup berlapis? Apakah subjeknya terlihat benar? Apakah adegannya menyampaikan kesan kedalaman?
Jika Anda sudah memiliki gambar referensi atau ingin menyempurnakan hasil generasi yang sudah ada, image-to-image adalah alat yang tepat untuk Anda. Unggah gambar yang sudah ada dan deskripsikan perubahan yang diinginkan—ini sangat berguna untuk iterasi komposisi: sesuaikan pencahayaan, tambahkan efek atmosfer, atau ubah konten adegan tanpa harus memulai dari awal. Untuk panduan lengkap tentang alur kerja Image-to-Image, lihat Panduan AI Image-to-Image.
Desain gambar untuk penggunaan video. Tidak semua gambar yang menarik secara visual cocok sebagai bingkai pembuka video. Saat membuat gambar untuk penggunaan dalam pipeline, perhatikan prinsip-prinsip komposisi berikut:
- Biarkan ruang kosong sesuai arah gerakan. Jika karakter bergerak dari kiri ke kanan, posisikan dia sedikit ke kanan dari bingkai.
- Sertakan tingkat kedalaman. Gambar dengan elemen latar depan, tengah, dan belakang yang jelas menciptakan efek parallax yang lebih baik dan gerakan kamera yang lebih alami dalam video.
- **Pertimbangkan arah gerakan kamera. ** Jika berencana menggunakan gerakan "push", pastikan komposisi terlihat baik baik dalam potongan saat ini maupun dalam potongan yang lebih ketat yang berpusat pada subjek.
- Hindari blok teks besar atau pola simetris. Elemen-elemen ini sulit dianimasikan secara alami dan dapat dengan mudah menghasilkan artefak.
- **Gunakan pencahayaan arah. ** Pencahayaan arah yang kuat dengan bayangan yang terlihat menghasilkan efek video yang lebih sinematik daripada pencahayaan datar.
Prinsip utama: Luangkan waktu untuk memastikan gambar Anda sempurna. Setiap menit yang dihabiskan untuk menyempurnakan visual Anda akan menghemat waktu berlipat ganda pada tahap pembuatan video. Frame pertama yang sempurna berarti video Anda dapat digunakan sejak percobaan pertama. Frame pertama yang bermasalah mungkin memerlukan beberapa kali regenerasi (masing-masing menghabiskan kredit dan waktu) tanpa menjamin hasil yang memuaskan.
Sebelum memulai proses pembuatan video, ulangi proses pengolahan gambar sebanyak 3–5 kali. Ini bukan tentang perfeksionisme—ini tentang efisiensi.
Untuk panduan lengkap tentang generasi teks ke gambar (termasuk teknik prompting dan perbandingan alat), lihat Panduan Lengkap tentang AI Generasi Teks ke Gambar. Untuk gambaran umum tentang alat generasi gambar terbaik, lihat Alat Generasi Gambar AI Terbaik untuk 2026.
Buat gambar Anda → | Sesuaikan gambar ke gambar →
Tahap Tiga: Pembuatan Video
Ini adalah tahap di mana Anda menuai hasilnya. Gambar-gambar yang telah Anda sempurnakan menjadi titik awal untuk klip video animasi Anda.
Unggah gambar sebagai frame pertama. Unggah gambar yang telah Anda buat ke alat [Image-to-Video] Seedance. Alat ini mengambil gambar langsung dari riwayat pembuatan Anda—tidak perlu mengunduh dan mengunggah ulang.
Panduan gerakan dengan kata-kata. Tuliskan petunjuk yang menggambarkan gerakan yang Anda inginkan—jangan menggambarkan visualnya (gambar sudah diproses). Fokus pada:
- Gerakan kamera: "pergerakan dolly lambat ke dalam" 、pergerakan pan ke kiri yang lembut、pergerakan orbit yang halus di sekitar subjek
- Aksi Subjek: "wanita itu memutar kepalanya perlahan"、kelopak bunga melayang ke bawah、uap naik dari cangkir
- Gerakan lingkungan: "awan bergerak perlahan", "air bergelombang ke luar", "daun bergoyang perlahan di angin"
- ** Atmosfer**: "atmosfer dramatis", "kualitas mimpi, ethereal", "kecepatan sinematik"
Generate dan tinjau. AI menerima prompt gambar dan gerakan Anda, menghasilkan segmen video yang dimulai tepat dari frame pertama Anda dan berkembang sesuai dengan instruksi gerakan Anda. Karena Anda mengontrol titik awal visual, outputnya dapat diprediksi dan konsisten. Kualitas video mewarisi kualitas gambar—frame pertama yang jelas, terang, dan komposisi yang presisi akan langsung menghasilkan video yang jelas, terang, dan komposisi yang presisi.
Untuk teknik kontrol gerak lanjutan dan pemasangan bingkai pertama/terakhir, silakan merujuk ke Panduan Desain Bingkai Pertama dan Terakhir. Untuk pengenalan komprehensif tentang AI Image-to-Video, konsultasikan Panduan AI Image-to-Video.
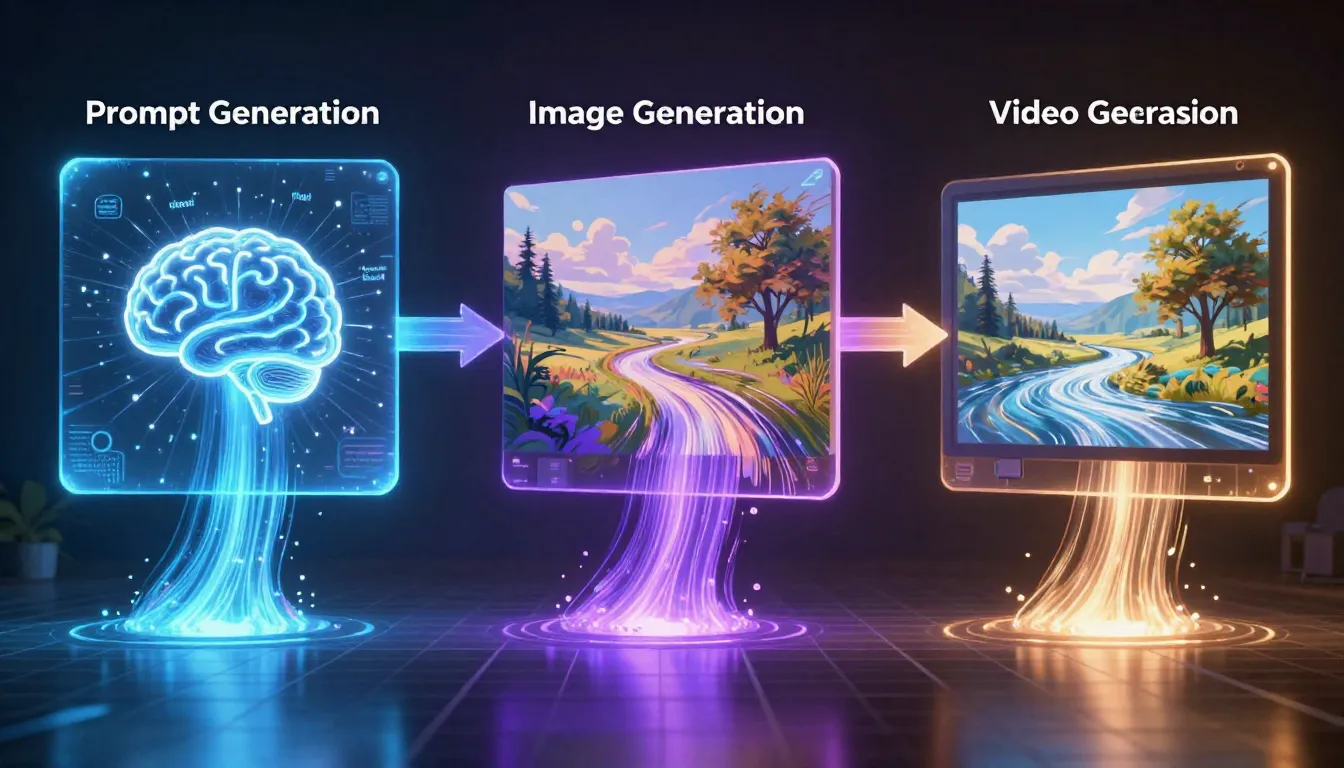
Proses tiga tahap dalam aksi: Ubah deskripsi singkat menjadi prompt profesional, Ubah prompt menjadi gambar berkualitas tinggi, Dan ubah gambar menjadi video dinamis. Setiap tahap meningkatkan kualitas tahap sebelumnya.
Keunggulan Seedance: Penyelesaian tiga tahap dalam satu langkah
Saat ini, sebagian besar kreator yang merangkai alur kerja ini menggunakan tiga atau empat alat yang berbeda. Mereka menggunakan ChatGPT atau Claude untuk menulis prompt gambar, beralih ke Midjourney atau Tongyi Wansheng untuk menghasilkan gambar, mengunduh gambar tersebut, membuka Ke Ling atau Runway, lalu mengunggahnya untuk menghasilkan video. Setiap kali beralih berarti menggunakan antarmuka yang berbeda, akun yang berbeda, sistem penagihan yang berbeda, dan batasan yang berbeda.
Alur kerja yang terfragmentasi ini bukan hanya merepotkan; ia secara aktif mengorbankan kualitas.
Bagaimana Pergantian Alat Mempengaruhi Kualitas
Setiap kali gambar ditransfer antara alat, terjadi degradasi. Siklus unduh-unggah menyebabkan artefak kompresi. Konversi format (PNG ke JPG, WebP ke PNG) mengubah nilai warna. Resolusi mungkin diubah. Metadata yang berkaitan dengan cara gambar dihasilkan—informasi yang dapat membantu model video menghasilkan hasil yang lebih baik—sepenuhnya dihapus.
Selain kualitas data, ada juga beban kognitif. Setiap alat memiliki sintaks perintah yang berbeda, pengaturan output yang unik, dan opsi rasio aspek yang bervariasi. Anda membuang-buang waktu untuk mempelajari kembali antarmuka alih-alih menggunakannya untuk iterasi kreatif.
Pipa Terintegrasi
Seedance menghilangkan semua gesekan tersebut dengan menawarkan ketiga tahap dalam satu platform:
1. Generator Prompt Gambar (/image-prompt-generator). Masukkan konsep kreatif Anda, pilih dari 12 gaya, dan dapatkan prompt profesional yang lengkap. Prompt yang dihasilkan dioptimalkan untuk model generasi gambar Seedance tetapi juga cocok untuk alat lukis AI apa pun.
2. Text-to-Image dan Image-to-Image (/text-to-image | /image-to-image). Buat gambar dari prompt atau lakukan modifikasi yang ditargetkan pada gambar yang sudah ada. Hasilkan berbagai varian dengan cepat. Setelah menemukan komposisi yang tepat, Anda dapat langsung melanjutkan ke tahap berikutnya.
- Gambar ke Video Pilih gambar yang telah dihasilkan sebelumnya dari perpustakaan Anda dan kirimkan langsung ke generator video. Tidak perlu mengunduh, mengunggah, atau mengubah format. Gambar beresolusi penuh ditransfer tanpa kehilangan kualitas.
Mengapa integrasi menghasilkan hasil yang lebih baik?
Ini bukan sekadar fitur kenyamanan; integrasi benar-benar menghasilkan hasil yang lebih baik:
- Tanpa kehilangan transmisi. Gambar ditransfer dengan resolusi penuh antar tahap, tanpa kompresi atau resampling.
- Ekosistem model yang konsisten. Model generasi gambar dan video dikalibrasi untuk kompatibilitas bawaan. Gambar yang dihasilkan oleh model teks-ke-gambar Seedance secara alami cocok untuk model video Seedance.
- **Sistem kredit terpadu. ** Tidak perlu mempertahankan tiga langganan terpisah. Kredit Anda berlaku secara universal di semua tiga alat, sehingga alokasi anggaran menjadi sederhana dan transparan.
- siklus iterasi yang lebih cepat. Waktu dari "Saya ingin mengedit gambar ini" hingga "Saya menonton video baru" berkurang dari menit yang dihabiskan untuk beralih alat menjadi hanya beberapa detik integrasi yang mulus.
- **Pertahankan aliran kreatif. ** Tetap berada dalam satu antarmuka untuk mempertahankan konteks pemikiran Anda. Fokus pada konsep kreatif itu sendiri, bukan manajemen file atau navigasi alat.
Jujur saja: Anda bisa dengan mudah menggunakan ChatGPT untuk menulis prompt, Midjourney atau Tongyi Wansheng untuk generasi gambar, dan Keling atau Runway untuk pembuatan video guna membangun alur kerja berkualitas tinggi. Banyak profesional melakukan hal yang sama. Keunggulan Seedance tidak terletak pada satu tahap yang jauh lebih unggul dari pesaing—melainkan pada cara integrasinya menghilangkan hambatan yang membuat kebanyakan kreator menghentikan proses di tengah jalan. Alur kerja terbaik adalah yang benar-benar Anda selesaikan dari awal hingga akhir.
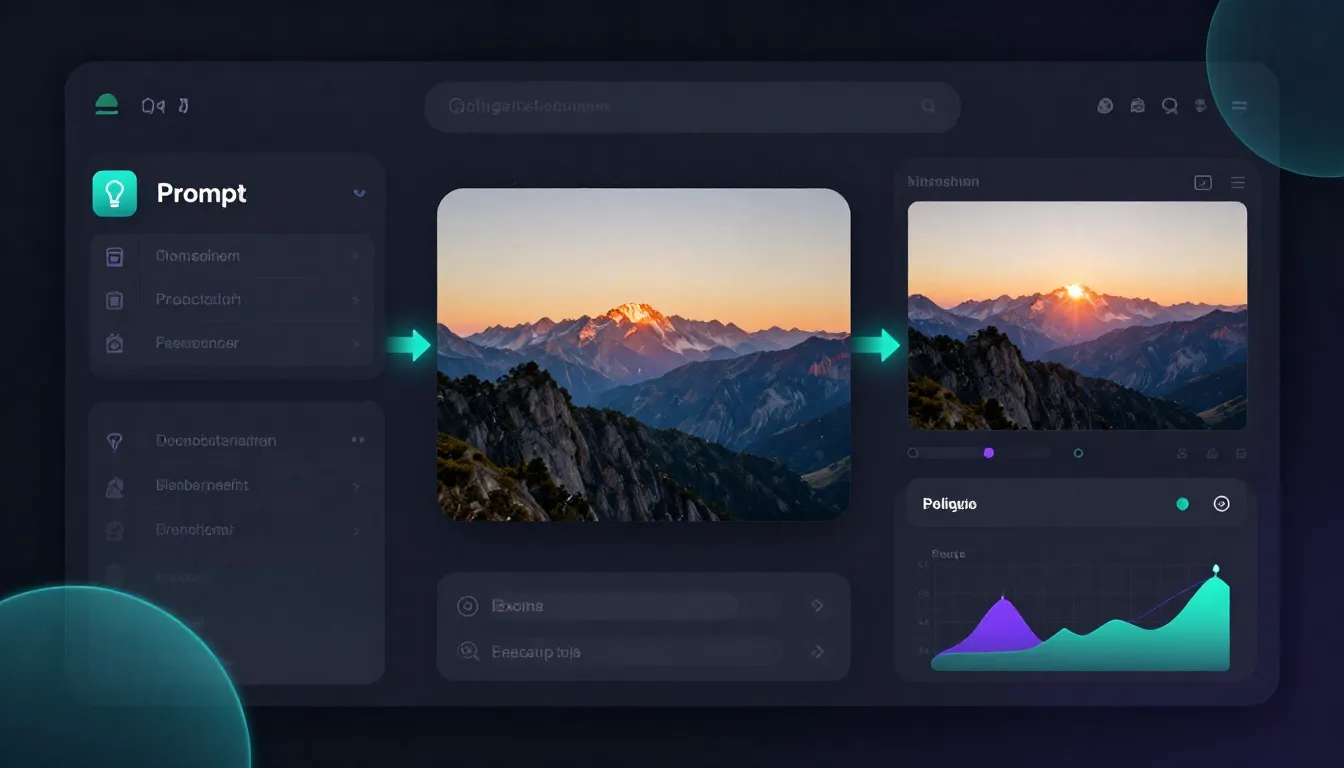
Seedance mengintegrasikan pembangkitan teks, pembangkitan gambar, dan pembangkitan video ke dalam satu platform tunggal. Dari konsep hingga video selesai, Anda tidak perlu beralih alat, mengunduh file, atau mengelola beberapa akun.
Panduan Praktis Lengkap: 3 Studi Kasus Nyata
Teori memang berguna, tetapi praktiklah yang menghasilkan hasil. Di bawah ini terdapat tiga latihan pipeline lengkap—masing-masing sesuai dengan tujuan kreatif yang berbeda, gaya yang unik, dan rasio aspek yang bervariasi. Ikuti langkah-langkahnya untuk membangun pipeline lengkap pertama Anda.
Kasus 1: Iklan Produk Berkonsep Sinematik
Tujuan: Membuat iklan jam tangan mewah berdurasi lima detik untuk halaman tampilan produk.
Fase Satu — Pembangkitan Prompt
Buka Image Prompt Generator dan masukkan konsep Anda.
Input: "iklan jam tangan mewah, gelap dan dramatis"
Pilih Gaya: Fotorealistik
Prompt yang dihasilkan:
A luxury men's wristwatch resting on a slab of dark emperador marble,
shot from a low three-quarter angle. Dramatic studio lighting: a single
hard key light from the upper left creates sharp reflections on the
polished steel case and sapphire crystal. The watch face shows 10:10
with luminous indices glowing faintly. Deep shadows pool around the
base, enhancing the sense of weight and prestige. Background is pure
black, fading to subtle charcoal gradient. Microscopic dust particles
float in the key light beam. Color palette: silver, deep charcoal,
amber highlights from the lume. Photorealistic product photography,
8K resolution, razor-sharp detail on every dial marking and link.Membuat prompt ini secara manual akan memakan waktu setidaknya 10–15 menit. Generator prompt dapat melakukannya dalam hitungan detik, mencakup semua tujuh dimensi prompt profesional: subjek, lingkungan, pencahayaan, warna, komposisi, gaya, dan kualitas gambar.
Tahap Dua — Pembangkitan Gambar
Salin prompt yang dihasilkan ke text-to-image. Buat dengan rasio aspek 16:9 agar sesuai dengan bingkai video lanskap.
Render pertama: Komposisi keseluruhan cukup baik, meskipun permukaan marmernya memantulkan cahaya sedikit terlalu kuat, sehingga mengalihkan perhatian dari jam tangan.
Iterasi: Lakukan penyempurnaan menggunakan Image-to-Image. Unggah gambar yang dihasilkan awal dengan prompt: "Kurangi intensitas pantulan permukaan marmer. Tingkatkan ketajaman detail wajah jam. Buat gradien latar belakang sedikit lebih dalam."
Pengambilan kedua: Jam tangan menjadi pusat perhatian, diterangi oleh cahaya dan bayangan yang dramatis, dengan komposisi berlapis. Siap untuk beralih ke fase video.
Tahap Tiga — Pembuatan Video
Kirimkan gambar yang telah diolah ke Image-to-Video.
Petunjuk latihan:
The camera executes a slow, smooth orbiting movement around the watch,
revealing different angles of the case and bracelet. The key light
shifts subtly as the camera moves, creating dynamic reflections across
the polished surfaces. Dust particles drift slowly through the light
beam. Cinematic, premium commercial pacing. Steady, professional
camera movement.(Kamera bergerak perlahan dan stabil mengelilingi jam tangan, memperlihatkan sudut-sudut berbeda dari casing dan tali jam. Saat bidikan bergerak, sumber cahaya utama bergeser secara halus, menciptakan pantulan dinamis pada permukaan yang dipoles. Partikel debu melayang perlahan dalam sinar cahaya. Tempo iklan sinematik dan mewah. Gerakan kamera yang stabil dan profesional.)
Hasil Akhir: Sebuah presentasi produk yang rapi berdurasi 5 detik—dimulai dengan bingkai yang dirancang dengan teliti, berputar secara halus mengelilingi jam tangan. Pencahayaan dramatis, detail tajam, dan tekstur premium mengalir secara mulus dari gambar asli hingga setiap bingkai video.

Kasus 1: Iklan Jam Tangan Mewah. Dari konsep singkat lima kata hingga video produk berdurasi lima detik yang rapi—proses tiga tahap yang menghasilkan output berkualitas komersial.
Kasus 2: Konten Perjalanan di Media Sosial
Tujuan: Membuat video vertikal yang merekam matahari terbit di sebuah kuil Jepang untuk TikTok/Instagram Reels.
Fase Satu — Pembangkitan Prompt
Buka Image Prompt Generator.
Input: "Matahari terbit di kuil Jepang, pagi yang tenang"
Pilih Gaya: Fotorealistik
Prompt yang dihasilkan:
A traditional Japanese wooden temple (Kiyomizu-dera style) nestled
among ancient cedar trees, photographed at dawn. Golden sunrise light
filters through morning mist, casting long warm shadows across the
temple's wooden veranda. Cherry blossom branches frame the upper
portion of the composition, with delicate pink petals catching the
first light. A stone lantern stands in the foreground left, moss-
covered and weathered. The temple roof's curved eaves are silhouetted
against a sky transitioning from deep indigo to warm peach and gold.
Subtle mist hovers at ground level among the trees. Photorealistic
landscape photography, golden hour lighting, serene and contemplative
atmosphere, high dynamic range, rich natural color palette.Tahap Dua — Pembangkitan Gambar
Salin ke Text-to-Image. Pengaturan utama: Buat dalam rasio aspek potret 9:16, cocok untuk TikTok dan Instagram Reels.
Draf pertama: Suasana sangat menakjubkan, tetapi cabang-cabang bunga sakura ditempatkan terlalu tinggi dalam bingkai, meninggalkan ruang kosong yang berlebihan di sepertiga bagian bawah.
Iterasi: Setelah sedikit memodifikasi prompt dan menambahkan deskripsi "cabang-cabang bunga sakura yang menjulur dari sudut kanan atas dan kiri atas, mengisi sepertiga bagian atas bingkai vertikal", generasi kedua berhasil menempatkan bunga sakura secara sempurna sebagai bingkai alami untuk komposisi.
Komposisi ini sangat cocok untuk video vertikal: kuil menarik perhatian ke tengah frame, sementara bunga sakura di bagian atas menciptakan daya tarik visual. Lentera batu dan kabut di latar depan memberikan kedalaman. Adegan ini menawarkan potensi gerakan melintasi beberapa lapisan.
Tahap Tiga — Pembuatan Video
Kirim ke Image-to-Video.
Petunjuk latihan:
Gentle cherry blossom petals drift slowly downward through the frame.
Morning mist shifts and swirls at ground level among the trees. Two
birds fly across the sky in the background. The sunrise light gradually
intensifies, warming the scene. A subtle breeze moves the cherry
blossom branches slightly. Peaceful, meditative atmosphere. Slow,
contemplative pacing.Kelopak bunga sakura berterbangan dengan lembut melintasi bingkai. Kabut pagi mengalir perlahan di atas tanah di antara pohon-pohon. Dua burung melayang di langit di latar belakang. Cahaya matahari terbit perlahan-lahan semakin terang, menghangatkan seluruh pemandangan. Angin lembut menggerakkan dahan-dahan bunga sakura. Suasana tenang dan meditatif. Irama yang lambat dan kontemplatif.
Hasil Akhir: Video vertikal berdurasi 4 detik dengan suasana atmosferik, sangat cocok untuk TikTok dan Instagram Reels. Bunga sakura berterbangan secara alami, sementara kabut pagi menambah kedalaman dan gerakan. Burung-burung di latar belakang menciptakan titik fokus yang halus. Nada hangat keemasan dari gambar asli meresap ke setiap frame video.
Studi Kasus 3: Narasi Merek – Menggabungkan Frame Pertama dan Terakhir
Tujuan: Membuat narasi merek berdurasi enam detik yang menggambarkan transformasi kafe dari ketenangan pagi hari hingga keadaan ramai dan penuh pengunjung.
Kasus ini menggunakan pipeline dua kali, menghasilkan sepasang gambar yang terdiri dari frame pertama dan terakhir untuk memberikan model video dua titik acuan visual dalam mendefinisikan alur naratif. Untuk analisis mendalam tentang teknik ini, silakan merujuk ke Panduan Desain Frame Pertama dan Terakhir.
Fase Satu — Dua Petunjuk
Buat dua set prompt dari generator prompt gambar.
Input bingkai pertama: "Sebuah kafe kosong, diterangi cahaya pagi yang lembut, dengan nuansa amber yang hangat."
Prompt yang dihasilkan untuk frame pertama:
Interior of an artisanal coffee shop in the early morning, before
opening. Warm amber sunlight streams through large front windows,
casting long golden rectangles across worn hardwood floors. Exposed
brick walls, a polished wooden counter with a brass espresso machine,
and empty mismatched chairs around small tables. A chalkboard menu
hangs behind the counter. Dust motes float in the sunbeams. The space
feels warm, inviting, and full of potential. Shot at eye level from
just inside the entrance. Photorealistic interior photography, warm
color palette, golden hour tones, cozy atmosphere.Input bingkai akhir: "Sebuah kafe yang ramai pada pagi yang hangat, dengan pelanggan menikmati kopi mereka."
Prompt bingkai akhir yang dihasilkan:
The same artisanal coffee shop, now alive with morning activity.
Diverse customers sit at tables -- some reading, some talking, some
working on laptops. A barista behind the counter steams milk, creating
a plume of white steam. Coffee cups and pastries fill the tables. Warm
morning light still streams through the windows but is supplemented by
the warm glow of pendant lights. The atmosphere is bustling but cozy,
full of quiet energy and the warmth of community. Shot from the same
eye-level position just inside the entrance. Photorealistic interior
photography, warm tones, lively atmosphere.Tahap Dua — Dua Gambar
Buat bingkai pertama dalam text-to-image dengan rasio aspek 16:9. Ulangi hingga kafe yang kosong terlihat hangat dan mengundang, diterangi oleh cahaya pagi yang emas dan melimpah.
Frame terakhir menggunakan teknik [image-to-image] generation. Unggah frame awal sebagai gambar referensi dan gunakan prompt frame akhir. Langkah ini sangat penting—menggunakan frame awal sebagai referensi memastikan konsistensi visual. Arsitektur, perabotan, arah pencahayaan, dan skema warna tetap konsisten antar frame, dengan penambahan tunggal berupa penambahan figur dan aktivitas.
Periksa ulang bingkai terakhir untuk memastikan tamu terlihat alami dan barista berada di belakang counter. Penting: kedua gambar harus terlihat sebagai lokasi yang sama yang diambil pada waktu yang berbeda, bukan dua lokasi terpisah.
Tahap Tiga — Pembuatan Video
Unggah frame pertama ke Image-to-Video. Pada platform yang mendukung referensi frame akhir, unggah frame akhir secara bersamaan.
Petunjuk latihan:
Time-lapse style transition. The empty coffee shop gradually fills
with people arriving -- customers entering, sitting down, a barista
beginning to work. Morning light shifts slowly. The scene transitions
from quiet solitude to warm, bustling community. Smooth, cinematic
pacing. The camera position remains fixed.(Transisi bergaya time-lapse. Sebuah kafe yang kosong perlahan-lahan dipenuhi oleh pelanggan yang datang—pelanggan masuk, mengambil tempat duduk mereka, dan barista mulai bekerja. Cahaya pagi berubah secara halus. Suasana berubah dari ketenangan yang sunyi menjadi atmosfer komunitas yang hangat dan ramai. Pacing yang halus dan sinematik. Kamera tetap statis.)
Hasil: Sebuah cerita merek berdurasi enam detik menggambarkan alur cerita yang lengkap—kelahiran sebuah kafe. Adegan pembuka menampilkan ruang yang tenang dan ramah. Adegan penutup memperlihatkan keadaan yang diinginkan. Transisi yang dihasilkan oleh AI menghubungkan keduanya: pintu terbuka, pelanggan duduk di tempatnya, barista mengoperasikan mesin espresso, dan cangkir kopi muncul di atas meja. Pesan mereknya sederhana namun kuat—ini adalah tempat di mana seseorang merasa seperti di rumah sendiri.

Kasus 3: Narasi merek yang menghubungkan adegan pembuka dan penutup. AI menghasilkan transisi time-lapse antara dua titik acuan visual—dari keheningan fajar hingga kehangatan komunitas.
Teknik Optimasi Jaringan Pipa
Setelah memproduksi ratusan video melalui alur kerja ini, lima prinsip berikut ini memiliki dampak terbesar terhadap kualitas hasil.
Tips 1: Habiskan 80% waktu Anda untuk gambar
Ini adalah optimasi yang paling krusial. Kualitas gambar merupakan bottleneck sepanjang seluruh proses. Gambar yang sempurna akan menghasilkan video yang dapat digunakan pada generasi pertamanya. Gambar yang biasa-biasa saja, meskipun prompt gerak yang dibuat dengan baik, hanya akan menghasilkan video yang biasa-biasa saja.
Pembagian waktu sebaiknya kira-kira sebagai berikut:
- Pembangkitan prompt: 5% (Generator membutuhkan detik, penulisan tangan membutuhkan menit)
- Pembangkitan dan iterasi gambar: 80% (Generate, evaluasi, penyempurnaan, regenerasi hingga adegan sempurna)
- Pembangkitan video: 15% (Unggah, tulis prompt gerakan, generate)
Sebagian besar pemula melakukan urutan yang salah—menghabiskan sepuluh detik pada sebuah gambar, lalu membuat video satu demi satu, berharap menemukan yang bagus. Pengguna berpengalaman menghabiskan sepuluh menit pada sebuah gambar dan mendapatkan video yang bagus dalam beberapa upaya pertama. Pendekatan terakhir ini menghasilkan hasil yang lebih baik dengan lebih sedikit kredit dan waktu yang lebih sedikit.
Sebelum memulai proses pembuatan video, ulangi proses pengolahan gambar sebanyak tiga hingga lima kali. Ini bukan tentang perfeksionisme; ini tentang efisiensi.
Tip 2: Dirancang untuk Gerakan
Sebuah foto yang menarik dan sebuah frame video yang baik bukanlah hal yang sama. Saat menghasilkan gambar untuk pipeline, seseorang harus membayangkan bagaimana adegan tersebut akan terlihat saat dianimasikan.
Biarkan ruang kosong sesuai arah gerakan utama. Jika sebuah objek bergerak dari kiri ke kanan, hindari menempatkannya di tengah—posisikan sedikit ke kanan untuk memberi ruang bagi gerakan. Jika kamera bergerak ke kiri, pastikan sisi kiri bingkai berisi konten yang menarik secara visual.
Susun bidikan sesuai arah kamera. Bidikan dorong paling efektif ketika detail paling menarik berada di tengah bingkai. Bidikan geser memerlukan minat visual di seluruh lebar bingkai. Bidikan pelacakan melingkar membutuhkan subjek tiga dimensi dengan kedalaman, bukan subjek datar.
Hindari komposisi simetris yang rumit. Meskipun simetri sempurna dapat terlihat menakjubkan dalam foto, hal ini menimbulkan kesulitan dalam pembangkitan video. AI kesulitan mempertahankan simetri yang presisi antar frame, yang mengakibatkan getaran yang mengganggu. Komposisi asimetris dengan aliran visual yang alami menghasilkan video yang lebih halus.
Gunakan petunjuk kedalaman. Gambar yang menampilkan elemen-elemen yang tumpang tindih pada jarak yang berbeda-beda—objek latar depan, subjek latar tengah, dan lingkungan latar belakang—memberikan informasi kedalaman kepada AI, yang menghasilkan efek paralaks yang lebih baik dan gerakan kamera yang lebih alami.
Untuk panduan lengkap tentang desain gambar khusus untuk video, lihat Panduan Desain Frame Pertama dan Terakhir.
Teknik 3: Pertahankan Rasio Aspek yang Konsisten Selama Seluruh Proses
Perbedaan rasio aspek antara gambar dan bingkai video merupakan salah satu kesalahan paling umum dalam proses pengolahan, yang secara tidak terhindarkan akan mengurangi kualitas output.
- 16:9 untuk video landscape (YouTube, presentasi, halaman arahan situs web)
- 9:16 untuk video portrait (TikTok, Instagram Reels, YouTube Shorts)
- 1:1 untuk video persegi (Instagram Stories, iklan media sosial tertentu)
Tentukan rasio aspek saat menghasilkan gambar daripada menundanya hingga tahap video. Jika Anda menghasilkan gambar persegi dengan rasio 1:1 dan kemudian mencoba membuat video dengan rasio 16:9, model video akan perlu mengisi sisi-sisinya dari awal – dan kualitas konten yang dihasilkan akan lebih rendah dibandingkan dengan bagian lain dari frame. Hasilkan gambar dengan rasio aspek video akhir sejak awal.
Tip 4: Pertahankan Gaya Prompt yang Konsisten di Seluruh Tahapan
Kata kunci gaya dalam prompt gambar dan petunjuk gerakan dalam prompt video harus menggunakan bahasa visual yang sama. Ketidaksesuaian antara keduanya akan menyebabkan masalah kualitas yang halus pada output akhir.
Jika prompt gambar Anda mencakup "cinematic, pencahayaan dramatis, suasana yang mendalam", prompt gerakan video harus menggunakan bahasa yang sesuai: "gerakan kamera sinematik, suasana dramatis, ritme yang mendalam". Hindari menggabungkan gambar sinematik dan dramatis dengan prompt gerakan seperti "ceria, lincah, energik" – konflik nada akan membingungkan model dan mengurangi kohesi.
Panduan Singkat — Tabel Pencocokan Gaya:
| Gaya Gambar | Bahasa Prompt Gerakan yang Sesuai |
|---|---|
| Sinematik, Dramatis | "Gerakan kamera sinematik, tempo dramatis, lambat dan terukur" |
| Cerah, Komersial, Bersih | "Gerakan halus dan profesional, tempo stabil, transisi bersih" |
| Mimpi, ethereal, lembut | "Gerakan lembut dan melayang, suasana mimpi, pergerakan lambat" |
| Energi tinggi, dinamis | "Gerakan kamera dinamis, tempo energik, potongan cepat" |
| Dokumenter, alami | "Perasaan kamera tangan, gerakan alami, tempo observasional" |
Tip 5: Simpan templat pipeline terbaik Anda
Ketika alur kerja prompt → gambar → video menghasilkan hasil yang memuaskan, simpan seluruh alur kerja:
- Prompt gambar (teks asli)
- Pengaturan gaya yang dipilih
- Pengaturan pembangkitan gambar (rasio aspek, model, nomor benih, dll.)
- Prompt gerakan video
- Pengaturan pembangkitan video (durasi, resolusi)
Pipeline ini berfungsi sebagai templat. Perlu membuat video serupa untuk produk yang berbeda? Ganti subjek dalam prompt gambar dan regenerasi. Perlu adegan yang berbeda dalam gaya yang sama? Pertahankan kata kunci gaya dan ganti deskripsi subjek.
Seiring waktu, Anda akan membangun perpustakaan pipeline yang matang dan disesuaikan dengan berbagai tujuan kreatif: iklan produk, konten media sosial, narasi merek, B-roll film, dan animasi karakter. Setiap proyek baru dimulai dari fondasi yang telah teruji daripada harus memulai dari nol.
Perbandingan Alat Alternatif di Berbagai Tahap
Seedance menyediakan alur kerja terintegrasi, meskipun Anda juga dapat membangun alur kerja ini menggunakan alat-alat terpisah. Berikut adalah perbandingan jujur dari setiap tahap.
Fase Pertama: Pembangkitan Prompt
| Alat | Paling Cocok Untuk | Deskripsi |
|---|---|---|
| Seedance Image Prompt Generator | Alur kerja terintegrasi, 12 preset gaya | 2 kredit per prompt. Output langsung ke alat gambar Seedance. |
| ChatGPT / GPT-4 | Rekayasa prompt kustom | Membutuhkan salin-tempel manual. Tidak ada preset gaya. Lebih fleksibel untuk instruksi kompleks. |
| Claude | Prompt yang halus dan detail | Unggul dalam mengeksekusi brief kreatif kompleks. Tidak terintegrasi dengan pembangkitan gambar. |
| Tongyi Qianwen | Dioptimalkan untuk konteks Tionghoa | Pemahaman yang lebih alami terhadap deskripsi Tionghoa. Cocok untuk pengguna domestik. Membutuhkan integrasi manual dengan alat hilir. |
Tahap Dua: Pembangkitan Gambar
| Alat | Paling Cocok Untuk | Catatan |
|---|---|---|
| Seedance Text-to-Image / Image-to-Image | Integrasi pipeline, alur kerja berbasis video | Gambar ditransfer langsung ke tahap video tanpa kehilangan kualitas. |
| Midjourney | Kualitas artistik, ekspresivitas estetika | Menghasilkan output yang luar biasa. Dioperasikan melalui Discord atau antarmuka web. Dapat diunduh secara manual dalam pipeline. |
| Tongyi Wanshang | Ramah prompt Mandarin, akses domestik stabil | Dikembangkan oleh Alibaba, unggul dalam memahami deskripsi Mandarin. Cocok untuk pengguna domestik tanpa VPN. |
| DALL-E 3 | Ketepatan prompt, rendering teks | Unggul dalam eksekusi literal prompt kompleks. Kontrol gaya terbatas. |
| Stable Diffusion | Kontrol penuh, generasi lokal | Fleksibilitas maksimal. Membutuhkan pengaturan teknis. Cocok untuk pekerjaan volume tinggi. |
Tahap Tiga: Pembuatan Video
| Alat | Paling Cocok Untuk | Deskripsi |
|---|---|---|
| Seedance Image-to-Video | Alur kerja terintegrasi, kualitas konsisten | Transfer gambar yang mulus, dukungan langsung untuk input frame pertama. |
| Kling 3.0 | Durasi panjang, kualitas tinggi | Menghasilkan hingga 2 menit per eksekusi. Kualitas gerakan yang kuat. Dikembangkan oleh Kuaishou, dapat diakses di dalam China. |
| Jimeng AI | Ekosistem Tiongkok, ramah pengguna | Oleh ByteDance, terintegrasi secara mendalam dengan ekosistem TikTok. Ideal untuk pembuatan video pendek. |
| Runway Gen-4 | Kontrol presisi, kuas gerakan | Mode Sutradara mendukung jalur kamera kustom. Antarmuka profesional. Harga lebih tinggi. |
| Pika 2.0 | Pendaftaran sederhana, eksperimen cepat | Antarmuka paling minimalis. Cocok untuk pemula. Kontrol detail gerakan terbatas. |
Jujur saja: Anda tentu bisa membangun alur kerja berkualitas tinggi dengan menggunakan ChatGPT untuk penulisan prompt, Midjourney untuk pembangkitan gambar, dan Keeling untuk produksi video. Banyak profesional melakukan hal yang sama. Keunggulan Seedance tidak terletak pada keunggulan di tahap tertentu—melainkan pada pengurangan gesekan melalui integrasi, pemeliharaan kualitas di seluruh tahap, dan penggabungan tiga alur kerja terpisah menjadi satu. Bagi kreator yang sering memproduksi video AI, waktu yang dihemat dengan tetap berada dalam satu platform dapat mencapai beberapa jam setiap minggu.
Untuk perbandingan mendetail tentang alat pembuat video, silakan lihat Perbandingan Alat Pembuat Video AI Terbaik 2026.
Kesalahan Umum pada Pipeline
Berikut adalah lima kesalahan paling umum yang sering ditemui saat mengatur alur kerja prompt → gambar → video. Setiap kesalahan memiliki solusi yang sederhana.
Kesalahan 1: Melewatkan tahap gambar sepenuhnya
Manifestasi spesifik: Mengonversi teks langsung menjadi video, sepenuhnya melewati proses pembangkitan gambar.
Mengapa hal ini menjadi masalah: Anda kehilangan kendali penuh atas komposisi. Model video menentukan segalanya—konten visual, bingkai adegan, dan titik awal kamera. Hasilnya tidak dapat diprediksi, dengan kemungkinan kecil untuk sesuai dengan niat kreatif Anda pada percobaan pertama.
Cara memperbaikinya: Selalu buat gambar frame pertama, bahkan jika Anda yakin prompt teks Anda sudah cukup rinci. Waktu 30 detik yang dihabiskan untuk membuat gambar dapat menghemat Anda dari beberapa kali kegagalan dalam pembuatan video.
Kesalahan 2: Menggunakan gambar stok tanpa evaluasi
Manifestasi spesifik: Mengunduh gambar secara acak dari internet atau memilih salah satu dari perpustakaan stok, lalu menyisipkannya langsung ke dalam proses pembangkitan video tanpa mengevaluasi kesesuaiannya sebagai bingkai pembuka.
Mengapa hal ini menjadi masalah: Banyak foto dirancang untuk tampilan statis, bukan untuk gerakan. Pemotongan gambar terlalu ketat, sehingga tidak ada ruang untuk pergerakan kamera. Subjek ditempatkan di tengah, membatasi opsi komposisi. Pencahayaan datar, menghasilkan efek video yang kusam. JPEG yang sangat terkompresi menimbulkan artefak.
Cara memperbaikinya: Sebelum menggunakan gambar apa pun, pertama-tama nilai gambar tersebut berdasarkan prinsip "dirancang untuk gerakan". Pendekatan yang lebih baik adalah menggunakan pipeline khusus untuk menghasilkan keyframe.
Kesalahan 3: Perbandingan aspek tidak sesuai
Manifestasi spesifik: Membuat gambar persegi dan kemudian menghasilkan video dengan rasio aspek 16:9, atau menggunakan gambar lanskap untuk menghasilkan video potret.
Mengapa hal ini menyebabkan kerusakan yang signifikan: Model video akan memotong gambar Anda (mengakibatkan hilangnya konten yang telah Anda rancang dengan teliti) atau mengisi rasio aspek baru dengan konten yang dihasilkan dari awal (dengan bagian tepi tambahan yang memiliki kualitas lebih rendah).
Cara memperbaikinya: Tentukan rasio aspek video akhir sebelum menghasilkan gambar. Hasilkan gambar sesuai dengan rasio aspek tersebut.
Kesalahan 4: Petunjuk video yang terlalu deskriptif
Manifestasi spesifik: Video prompt secara bersamaan menggambarkan adegan dan pergerakannya: "Jam tangan mewah di atas marmer gelap dengan pencahayaan dramatis, kamera berputar perlahan dan pantulan cahaya menari-nari di permukaan."
Mengapa hal ini menjadi masalah: Deskripsi visual mungkin bertentangan dengan konten gambar. Jika jam tangan digambarkan di atas marmer putih tetapi prompt menentukan marmer gelap, model menerima sinyal yang bertentangan. Dalam skenario terbaik, deskripsi visual menjadi berlebihan; dalam skenario terburuk, hal ini menyebabkan model mencoba memodifikasi bingkai pertama yang telah Anda rancang dengan cermat.
Cara membuat: Petunjuk video hanya boleh menggambarkan gerakan, sudut kamera, dan suasana. Visualnya sudah diubah menjadi gambar. Ingat prinsip ini: gambar menyampaikan "apa yang terlihat", sementara petunjuk video menentukan "bagaimana gerakannya".
Kesalahan 5: Terburu-buru menghasilkan video tanpa mengulang melalui gambar
Manifestasi spesifik: Membuat gambar dan langsung memasukkannya ke dalam proses pembangkitan video, bahkan jika gambar tersebut memiliki kelemahan yang jelas—seperti komposisi yang sedikit miring, cacat kecil, atau pencahayaan yang kurang optimal.
Mengapa dampaknya lebih besar: Video memperbesar setiap cacat pada gambar asli. Sebuah cacat kecil pada foto statis menjadi cacat yang terus-menerus dan bergerak melintasi 120 frame gerakan. Komposisi yang sedikit tidak sentral menjadi terlihat salah ketika gerakan kamera menarik perhatian pada bingkai. Setiap cacat pada foto menjadi lebih jelas, bukan lebih samar, dalam video.
Cara memperbaikinya: Anggap tahap gambar sebagai titik pemeriksaan kualitas. Jangan lanjutkan ke tahap video hingga gambar benar-benar memuaskan. Ulangi proses ini 3–5 kali. Gunakan generasi gambar ke gambar untuk perbaikan yang ditargetkan. Kualitas output video tidak boleh melebihi kualitas gambar sumber.
Pertanyaan yang Sering Diajukan
Mengapa menggunakan intermediasi gambar daripada langsung mengonversi teks menjadi video?
Pembuatan video dari teks memerlukan AI untuk secara bersamaan menciptakan visual dan gerakan dari teks, artinya Anda memiliki kontrol minimal atas komposisi, penampilan karakter, pencahayaan, dan bingkai. Pendekatan berbasis gambar memisahkan kedua tugas ini: Anda menyempurnakan visual selama fase gambar, lalu menginstruksikan AI secara eksklusif untuk menambahkan gerakan. Hal ini menghasilkan hasil yang lebih dapat diprediksi dan berkualitas tinggi, karena AI menerima referensi visual yang konkret daripada menafsirkan teks yang ambigu. Perbedaan ini terutama terlihat dalam skenario profesional yang memerlukan komposisi spesifik, palet warna merek, atau desain karakter yang konsisten.
Apa saja langkah-langkah lengkap untuk membuat video AI dari awal?
Proses lengkap terdiri dari tiga langkah. Langkah Pertama: Gunakan generator prompt AI (seperti Seedance's Image Prompt Generator) untuk mengembangkan konsep Anda menjadi prompt gambar yang detail. Langkah Kedua: Gunakan prompt ini dalam alat text-to-image (seperti Seedance's Text-to-Image) untuk menghasilkan gambar referensi berkualitas tinggi, ulangi proses hingga puas. Langkah Ketiga: Unggah gambar ke generator gambar-ke-video (seperti Seedance's image-to-video), tulis prompt yang hanya menggambarkan gerakan (pergerakan kamera dan aksi subjek), dan hasilkan video. Seluruh proses memakan waktu 5–15 menit, tergantung pada jumlah iterasi yang diperlukan selama fase gambar.
Berapa banyak poin yang diperlukan untuk menyelesaikan seluruh proses di Seedance?
Biaya bervariasi tergantung pada konfigurasi, tetapi proses pipa kerja tipikal umumnya mencakup: pembangkitan prompt seharga 2 kredit, pembangkitan gambar seharga 4–8 kredit per iterasi (dengan perkiraan 3–5 iterasi, setara dengan 12–40 kredit), dan pembangkitan video seharga 10–30 kredit (tergantung pada durasi dan resolusi). Dari konsep hingga video selesai, total biaya umumnya berkisar antara 25 hingga 70 kredit. Ini mewakili penghematan yang signifikan dibandingkan dengan menggunakan tiga alat terpisah dengan tiga langganan terpisah.
Apakah gambar yang dihasilkan oleh alat lain dapat digunakan untuk membuat video di Seedance?
Tentu saja. Alat [Image-to-Video] Seedance dapat menerima gambar apa pun yang diunggah—tidak harus dihasilkan oleh Seedance. Anda dapat membuat gambar menggunakan Midjourney, DALL-E, Tongyi Wanshang, Stable Diffusion, atau alat lain, lalu mengunggahnya sebagai frame pertama. Keunggulan pipeline terintegrasi terletak pada penghilangan langkah unduh-unggah, meskipun hal ini tidak wajib. Saat menggunakan gambar eksternal, kami merekomendasikan format PNG dengan resolusi 1024x1024 atau lebih tinggi untuk mencegah artefak kompresi memengaruhi output video.
Rasio aspek apa yang sebaiknya digunakan untuk gambar?
Pastikan rasio aspek gambar Anda sesuai dengan output video akhir. 16:9 untuk video lanskap (YouTube, presentasi, embed situs web), 9:16 untuk video potret (TikTok, Instagram Reels, YouTube Shorts), 1:1 untuk video persegi (Instagram Stories, iklan sosial tertentu). Buat gambar dengan rasio aspek yang benar sejak awal. Jangan menghasilkan gambar persegi lalu mengharapkan alat video untuk mengonversinya menjadi 16:9 – hal ini akan memotong komposisi Anda atau menambahkan konten yang dihasilkan AI di tepi gambar, keduanya akan mengurangi kualitas.
Bagaimana cara membuat pasangan keyframe?
Generate dua frame menggunakan pipeline terpisah. Frame pertama mengikuti alur kerja standar: generate prompt, buat gambar, dan ulangi hingga hasil memuaskan. Frame akhir menggunakan image-to-image, mengunggah frame pertama sebagai gambar referensi dan mendeskripsikan perubahan pada keadaan akhir. Ini memastikan konsistensi visual—lokasi yang sama, arah pencahayaan yang sama, skema warna yang sama—sambil mencapai pergeseran naratif yang diinginkan (waktu yang berbeda, aktivitas, atau suasana hati). Unggah kedua frame ke generator video dan biarkan AI membuat transisi. Untuk panduan lengkap tentang teknik ini, lihat First and Last Frame Design Guide.
Apakah alur kerja ini cocok untuk konten komersial?
Sesuai. Sistem tiga tahap ini telah diadopsi oleh merek e-commerce untuk video produk, tim pemasaran untuk aset iklan, perusahaan properti untuk presentasi properti, dan agensi konten untuk produksi media sosial. Video yang dihasilkan oleh AI dengan durasi 5–15 detik dan bingkai pembuka berkualitas tinggi kini memenuhi standar profesional untuk konten digital. Kunci kesuksesan komersial terletak pada investasi waktu pada fase gambar—bingkai pembuka yang dipoles secara langsung tercermin pada video yang dipoles. Untuk durasi yang lebih panjang atau konten komersial berkualitas siaran, video AI semakin banyak digunakan untuk ideasi kreatif dan visualisasi pratinjau, dengan produksi akhir masih diselesaikan melalui metode tradisional untuk memastikan kontrol maksimal.
Apa yang harus dilakukan jika gambar yang dihasilkan memiliki cacat?
Jangan melanjutkan proses pembangkitan video. Ketidaksempurnaan pada gambar sumber akan diperbesar dalam video—tangan yang sedikit terdistorsi dalam gambar statis akan menjadi tangan yang jelas terdistorsi dalam urutan gerak 120 frame. Proses pra-pemrosesan gambar. Gunakan [image-to-image] untuk meregenerasi area yang bermasalah sambil mempertahankan bagian lain dari komposisi. Untuk cacat yang parah (figur manusia yang terdistorsi, geometri yang tidak masuk akal), regenerasi ulang gambar secara keseluruhan dengan prompt yang dimodifikasi untuk menghindari masalah tersebut. Elemen yang rentan terhadap cacat meliputi tangan (spesifikasikan "tangan di sisi tubuh" atau "tangan di saku" untuk menghindari pose jari yang kompleks), teks (hindari menyertakan teks dalam gambar yang dihasilkan), dan pantulan (sederhanakan permukaan reflektif dalam prompt). Hanya lanjutkan ke produksi video setelah gambar sempurna.
Mulailah membangun alur kerja kreatif Anda
Pipeline tiga tahap—prompt → gambar → video—tetap menjadi metode paling andal untuk menghasilkan video AI berkualitas tinggi pada tahun 2026. Metode ini memisahkan kendali kreatif yang Anda butuhkan (bagaimana adegan seharusnya terlihat) dari kemampuan generatif yang Anda inginkan (bagaimana adegan tersebut seharusnya bergerak), sehingga menghasilkan video yang sesuai dengan visi Anda daripada tebakan acak dari AI.
Setiap video yang bagus dimulai dengan gambar yang bagus. Setiap gambar yang bagus dimulai dengan prompt yang bagus. Bangun fondasi yang kokoh, dan segala hal lainnya akan mengikuti secara alami.
Langkah Pertama: Buat Prompt → — Ubah konsep menjadi prompt gambar berkualitas profesional menggunakan generator prompt AI Seedance.
Langkah Dua: Buat Gambar → — Buat dan sempurnakan secara berulang-ulang bingkai pembuka yang sempurna untuk video Anda.
Langkah Tiga: Buat Video → — Ubah gambar menjadi video dinamis yang menampilkan gerakan, sudut kamera, dan suasana.
Menguasai Teknik Frame Pertama → — Ambil kendali atas pembuatan video AI Anda dengan mempelajari cara mendesain frame referensi.
Bacaan tambahan: Panduan AI Gambar ke Video | Panduan Desain Frame Pertama dan Terakhir AI Video | Panduan Lengkap AI Teks ke Gambar | Panduan AI Gambar ke Gambar | Panduan Pembuat Prompt Gambar AI | Pembuat Gambar AI Terbaik 2026 | Generator Video AI Terbaik untuk 2026*
