
速览
首帧和尾帧是你在 AI 视频生成中拥有的最强大的控制手段。一张精心设计的参考图能显著提升视频质量、角色一致性和叙事能力——把 AI 视频从一场不可预测的实验变成一个可以精准导演的创作工具。
首帧告诉 AI 你的场景长什么样:主体、光影、构图、氛围。尾帧告诉 AI 场景该走向哪里,定义运动轨迹和叙事弧线。两者配合,把一个黑盒式的生成过程变成你可以可靠掌控的创作流程。
Seedance 的图生视频支持首帧上传,且有一个独特优势:你可以用内置的 AI 图片生成器或文生图工具直接生成参考帧——从想法到成片,全程无需离开平台。
生成你的首帧 → | 用图片创建视频 → | 设计完美参考帧的提示词 →
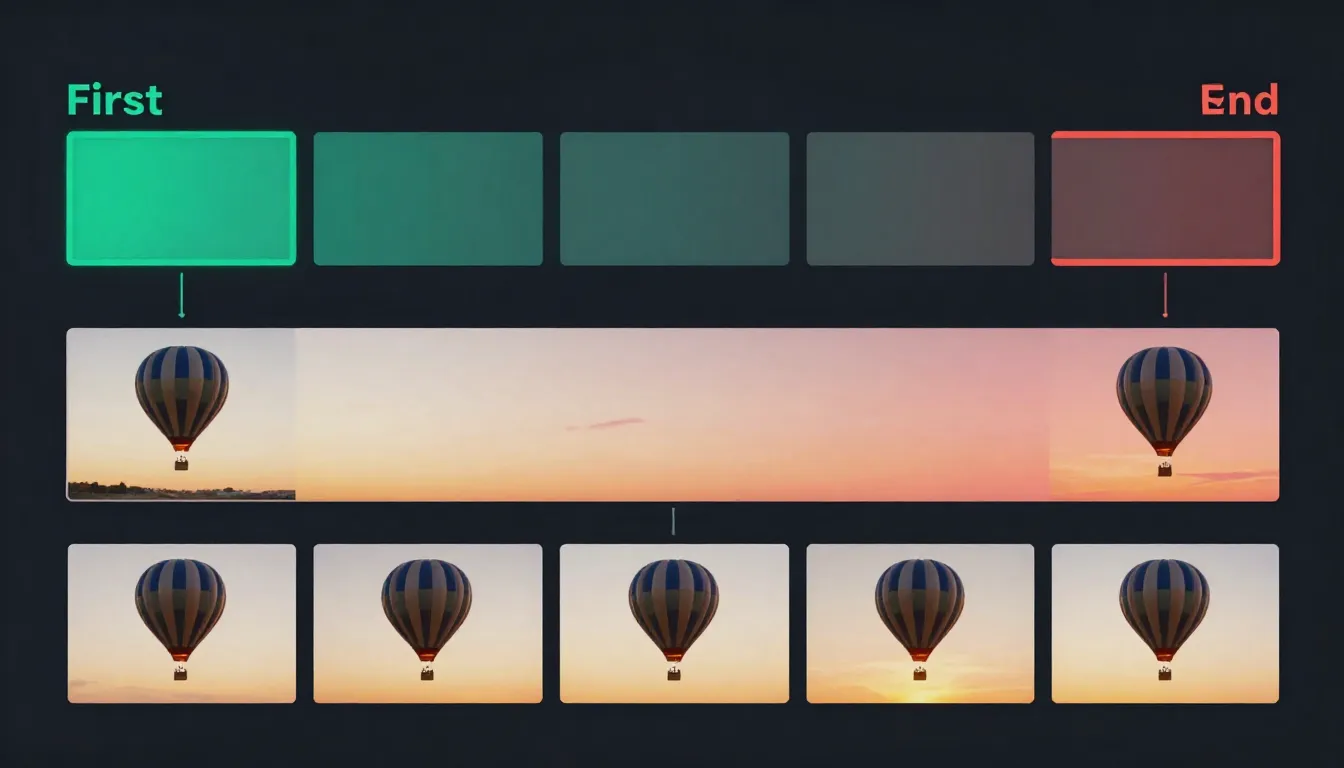
首帧和尾帧是AI视频生成的两个视觉锚点。首帧定义视频从哪里开始,尾帧定义视频到哪里结束,AI负责生成两者之间的所有运动。
什么是 AI 视频中的首帧和尾帧?
在 AI 视频生成中,首帧和尾帧指的是定义生成视频片段起点和终点的参考图。与其只给 AI 一段文字描述、然后祈祷出好结果,不如提供一到两张具体的视觉锚点来约束和引导整个生成过程。
如果你用过可灵(Kling)、即梦 AI 或通义万相视频,对这个概念应该不陌生——"图生视频"本质上就是首帧技术的应用。
首帧:你的视觉起点
首帧是一张告诉 AI 视频开场画面该长什么样的图片。上传首帧时,你在定义:
- 主体身份:角色或物体的外观——面部特征、服装、体型、姿势
- 场景构图:画面中各元素的位置关系
- 环境:场景、背景和空间语境
- 光影方向和质量:光从哪来,是硬光还是柔光,色温多少
- 色彩基调:整体调色和情绪
- 机位:初始相机角度和距主体的距离
这些元素中的每一个都会在生成的视频中延续下去。首帧不是一个建议——它是一份规格说明。
尾帧:你的视觉终点
尾帧告诉 AI 视频该走向哪里。同时提供首帧和尾帧时,AI 确知两件事:A 点和 B 点。它的任务是在两个已知状态之间生成最自然、最连贯的运动路径。
尾帧定义:
- 运动轨迹:主体从起始位置到终止位置的移动路径
- 叙事弧线:两个状态之间讲述的故事(开门、转身、花朵绽放)
- 环境变化:起止之间的光影变化、时间推移或氛围转换
- 机位路径:相机从初始位置到终止位置的运动方式
为什么参考帧能彻底改变 AI 视频质量
没有参考图时,文生视频本质上是一个黑盒。你输入描述,AI 按训练数据来理解。结果可能惊艳也可能完全走偏。你对主体外观、场景布光、机位起始都没有视觉上的控制。
有了首帧,大部分不确定性被消除。AI 已经知道场景长什么样——它唯一的任务就是生成合理的运动。这对模型来说是一个根本上更简单的任务,这也是为什么图生视频的质量和可预测性始终高于纯文生视频。
同时提供首帧和尾帧,控制力更进一步。AI 不再需要猜测事物该往哪走——它有两个确认的状态,只需在两者之间做插值。这能生成更平滑、更有意图的运动,大幅减少伪影和意外偏差。
打个比方:文生视频就像跟司机说"去个好地方"。给首帧就像说"从这个路口出发"。首帧加尾帧就像给了精确的起点地址、精确的终点地址,让司机选最佳路线。
关于图生视频的完整基础知识,请看 图生视频 AI 指南。
为什么首帧质量决定视频质量
这是参考帧视频生成中最重要的原则:首帧质量直接决定整个视频的质量。不是部分决定,不是近似决定——是直接且完全地决定。

同一条提示词,不同的首帧。左图:低分辨率、构图差的首帧导致面部不一致和环境破碎。右图:清晰、精心设计的首帧产生连贯运动和专业级视频。
首帧决定一切
AI 视频模型接收到首帧后,会将其编码为丰富的潜在表示——一个捕捉每个视觉细节的数学指纹。这个编码成为后续每一帧生成的基础。
角色身份在首帧就被锁定。清晰、光照均匀的肖像加上明显的面部特征,模型能在整个视频中保持该身份。如果首帧面部模糊、特征不清或被硬阴影遮挡关键细节,模型没有足够信息维持一致性——结果就是面部在视频中途变形、漂移或丢失。
场景构图从首帧传播。有清晰前景、中景和背景的首帧给模型提供了深度信息,可用于视差效果和自然的相机运动。扁平、构图差的首帧让模型猜不透空间关系,导致不自然的深度感。
色彩调性和氛围被直接继承。首帧的精确色板、对比度和大气质感贯穿每一帧。首帧有温暖的黄金时段光泽,视频就保持那份温暖。首帧光线平淡无趣,那种平淡也会延续下去。
光影质量决定整个片段的阴影行为。首帧中连贯、清晰的布光意味着模型能预测主体运动时阴影该如何变化。首帧中矛盾或混乱的光影会导致阴影伪影随帧数累积。
误差累积问题
AI 视频模型不会独立生成每一帧。它们按顺序外推运动——每一新帧基于之前的帧生成,首帧是原始锚点。这意味着误差会叠加。第 2 帧的小不一致在第 10 帧变成更大的不一致,到第 30 帧就是明显的伪影。
高质量首帧最小化初始误差。模型有清晰、无歧义的信息可供外推,因此后续每一帧都更贴近预期输出。差的首帧从一开始就引入模糊性,而这种模糊性随着每一帧都在增长。
这就是为什么在首帧上投入时间会带来指数级回报。多花五分钟打磨参考图,能省下几个小时反复重新生成的时间。
什么才是"好的"视频首帧
并非每张技术上合格的照片都是好的视频首帧。一张精美的静态照片可能具有对视频生成不利的特征。以下是好照片和好首帧的区别:
- 运动空间:好首帧给主体留出移动余地。把头填满整个画面的大头照不留任何转头、点头或移动的空间。
- 隐含物理:最好的首帧包含运动线索。被风吹起的头发、受重力下垂的布料、即将溅起的水花——这些线索引导运动模型。
- 稳定元素:应该保持不动的区域需要清晰界定。杂乱的背景和模糊的深度让模型难以判断什么该动、什么该不动。
- 适当的复杂度:场景应该匹配视频模型的处理能力。一到两个主要主体配上连贯背景的效果远好于有几十个运动元素的群体场景。
首帧与尾帧的技术原理
理解技术机制有助于你做出更好的创意决策。你不需要成为机器学习工程师,但了解模型如何使用参考图能解释为什么某些方法有效而其他的无效。

首帧和尾帧如何调节视频扩散模型:参考图被编码到潜在空间,运动在两个状态之间被预测,扩散过程生成时间上一致的中间帧。
视频扩散模型中的图像调节
现代 AI 视频生成器基于视频扩散模型——通过逐步将随机噪声去噪为连贯帧序列来学习生成视频的神经网络。当你提供首帧时,它充当条件信号,约束去噪过程。
技术层面讲,首帧通过图像编码器(通常是 VAE——变分自编码器)被编码为潜在向量。这个潜在向量在扩散模型的多个阶段被注入,确保每一帧与原始参考保持视觉一致性。
简单理解:没有首帧时,扩散模型从纯噪声开始,需要同时搞清楚场景长什么样以及物体该怎么动。有了首帧,"场景长什么样"的问题已经被回答。模型可以全力以赴生成自然运动。
首帧注入机制
只提供首帧(无尾帧)时,模型在前向外推模式下运行。它获取编码后的首帧,通过预测从该初始状态最可能出现的运动来生成后续帧。
模型通过几种机制维持一致性:
- 交叉注意力层:让每个生成的帧能"回看"编码后的首帧,检查主体是否保持身份、场景是否连贯
- 时间注意力:生成的帧之间也相互关注,确保相邻帧之间的平滑过渡和一致运动
- 无分类器引导:文本提示词引导运动方向,首帧约束视觉内容
实际意义是:生成帧距首帧越远(在时间上),漂移越大。这就是为什么短片段(5-10 秒)的一致性远高于长片段(30 秒以上)。首帧的影响力随着更多帧的生成而逐渐减弱。
尾帧定向机制
同时提供首帧和尾帧时,模型切换到插值模式。不再从单一锚点向前外推,而是生成在两个已知状态之间形成合理路径的帧。
这在技术上是一个约束更多的问题,意味着:
- 更好的运动连贯性:模型知道事物需要到达哪里,可以规划运动轨迹
- 更少的漂移:没有参考信号的逐渐丢失——两端都有锚点
- 更可预测的结果:两个约束而非一个,可能的输出空间大大缩小
插值过程通过将两帧编码到潜在空间、计算差异、在帧序列上分配变化来实现。模型再用扩散填充每个中间帧的视觉细节,确保平滑过渡。
一致性保障机制
除了基础调节,现代视频模型还采用了几种专门维持帧间一致性的技术:
参考注意力(IP-Adapter 风格):部分模型维持从首帧提取的持久特征图,每个生成帧都对其进行交叉注意。这对维持人脸身份和精细细节尤其有效。
光流估计:模型在内部估计像素在帧间应如何移动,使用这个流场将首帧的特征变形到后续帧中,再应用扩散精修。这确保了主体运动时的结构一致性。
时间卷积:3D 卷积层同时处理多帧,强制局部时间连贯性,使相邻帧看起来平滑且连贯。
模型能做什么和不能做什么
能可靠控制的:
- 运动方向和大致轨迹(主体向左走、向右转)
- 相机运动类型(平移、变焦、环绕、推拉)
- 运动速度和节奏(缓慢、稳定、动感)
- 环境运动(风、水、云)
无法保证的:
- 尾帧的像素级精确还原(终点会接近但不完全一致)
- 复杂的多步动作(一个人接球然后扔出去)
- 新场景中的物理准确性(模型从训练数据中学习,不是物理模拟)
- 运动中保持小文字或精细图案
诚实说说局限性
没有完美的参考帧系统。以下是你需要了解的真实限制:
时间漂移:即使有优秀的首帧,视频模型在较长时长上也会逐渐漂移。5 秒片段保持高度一致;30 秒片段可能出现明显的面部结构或场景细节变化。这是活跃的研究领域,每一代新模型都在改进,但仍是根本性挑战。
运动复杂度上限:当前模型能很好地处理 1-2 个同时动作(一个人走路同时相机平移)。增加更多同时运动会增加伪影概率。如果需要复杂编排,生成较短片段然后剪辑在一起。
尾帧精度:提供尾帧时,生成的视频会向尾帧运动,但最终生成帧可能不会精确匹配参考。把尾帧视为强方向引导,而非像素级精确约束。
风格偏移:如果首帧和尾帧的光影或调色略有不同,模型会尝试在两者之间过渡。这可能产生非预期的视频中段色彩偏移。为获得最平滑的结果,尽量让首帧和尾帧的视觉风格保持一致。
设计完美的首帧
创建能最大化视频质量的首帧本身就是一门手艺。它结合了传统摄影和电影摄影原则,以及对 AI 视频模型需要什么才能产出最佳作品的理解。

首帧设计四大支柱:带运动空间的构图、适合一致性的主体设计、光影与色彩的氛围控制、分辨率匹配实现最优输出。
视频化构图原则
静态图像构图和视频构图的目标不同。照片是一个自足的瞬间。首帧是一个故事的开头——它需要为接下来发生的事留出空间。
三分法加运动空间。 应用标准三分法,但将主体放在与预期运动方向相反的一侧。主体将向右走,就放在画面左三分之一。相机将向左平移,就在左侧留出额外空间。这个"引导空间"给 AI 余地创建自然运动,不会撞到画面边界。
深度层次比静态摄影更重要。 包含清晰的前景、中景和背景元素。这些深度层给 AI 提供视差信息——相机移动时,近处物体的偏移应大于远处物体。没有深度变化的扁平图像会产生扁平、不可信的相机运动。
避免主体填满整个画面。 如果主体占满整帧没有留白,AI 就没有空间添加相机运动、微妙的主体位移或边缘环境运动。在主体周围留出至少 10-15% 的边距。如果你打算在提示词中指定任何相机运动,这一点尤其重要。
构图时考虑预期的相机运动。 如果计划推镜头,确保画面中心是最精细和有趣的区域。如果计划平移,确保画面两侧都有足够的视觉信息支撑平滑运动。如果计划推拉镜头,确保深度层次清晰分明。
不对称创造视觉趣味。 完全居中、对称的构图容易产出看起来静态的视频。轻微的不对称给 AI 一个更自然的起点,让生成的运动感觉更有机。
主体设计与一致性
首帧中主体的设计(或选择)方式直接影响 AI 在整个视频中维持该主体身份的能力。
角色视频需要清晰、光照均匀的面部。 如果视频聚焦于人物,面部需要清晰可见且光照均匀。面部有硬阴影、特征不清或极端角度,都会让模型更难维持面部身份。正面光或四分之三光照的肖像(双眼可见)产出最好的一致性。
独特的服装和配饰。 AI 模型用服装颜色、图案和配饰等视觉线索跨帧追踪身份。穿灰色衬衫站在灰色背景前的角色几乎没给模型什么参考。穿红色夹克、有特定发型和标志性配饰的角色更容易被追踪和维持。
避免可能混淆模型的复杂图案。 人字纹、容易产生摩尔纹的图案、非常细的条纹或精细的几何图案在视频输出中会产生闪烁。纯色、微妙质感和大面积图案对首帧效果好得多。
复杂度匹配用途。 角色为主的视频用简洁背景——让主体主导注意力,背景保持稳定。风光或建筑视频用详细环境——环境本身就是主体,AI 应该动画化整个场景。
光影与色彩的氛围控制
首帧的光影可能是最有影响力的特征。首帧中的每个阴影、高光和色偏都会在每一个生成帧中持续和传播。要像布置电影场景一样有意识地选择光影。
黄金时段光线产出温暖、电影感的视频,有长阴影和丰富肤色。方向性的黄金时段光给 AI 提供强运动阴影行为线索。
阴天或漫射光产出均匀的商业风格视频。最少的阴影意味着 AI 需要维持的阴影一致性更少——这实际上可以提高复杂场景的输出质量。
影棚布光(控制主光、补光和轮廓光)产出干净、专业的视频,适合产品拍摄、头像和商业内容。影棚光的可控性能很好地转化为一致的视频输出。
霓虹和戏剧性光影产出风格化、有情绪的视频,有强烈色彩对比。适合创意和娱乐内容,但增加了生成帧中色彩不一致的风险,因为模型必须维持复杂的光影交互。
色板被直接继承。 如果首帧采用青橙调色,整个视频都会带这个色板。如果首帧去饱和、情绪化,视频也会如此。为首帧选择色板时,就当你在为整个最终视频选择调色。
分辨率与宽高比
技术规格和创意决策同样重要。
首帧分辨率匹配目标视频分辨率。 如果想要 1080p 输出,至少提供 1920x1080 的首帧。更高分辨率更好——编码器从 2048x2048 的图中提取的细节比 1024x1024 多得多,即使输出分辨率相同。
常用宽高比及最佳用途:
| 宽高比 | 尺寸 | 最适合 |
|---|---|---|
| 16:9 | 1920x1080 | YouTube、网站、演示、电影级内容 |
| 9:16 | 1080x1920 | 抖音、快手、小红书、YouTube Shorts、移动端优先内容 |
| 1:1 | 1080x1080 | 小红书信息流、社交广告、产品展示 |
| 4:5 | 1080x1350 | 小红书帖子、微信公众号 |
| 21:9 | 2560x1080 | 超宽电影级、横幅视频 |
关键:首帧宽高比必须匹配输出视频宽高比。 上传横版首帧却请求竖版视频输出,会迫使 AI 大幅裁切或凭空生成缺失内容。两种情况效果都很差。如果需要与源图不同的宽高比,先自己裁切源图——不要让 AI 处理这种不匹配。
更高分辨率的首帧产出更清晰的视频。 这在一定程度上成立。大多数当前模型有内部处理分辨率(通常长边 1024px 或 1280px)。提供高于此分辨率的图不会有害,但收益递减。低于此分辨率,质量下降会很明显。
用尾帧讲故事
尾帧将 AI 视频从"给图片加运动"变成"用视觉讲一个短故事"。通过定义视频从哪开始和到哪结束,你在编写一个视觉叙事,AI 用自然运动来填充。

首帧和尾帧定义叙事弧线。左:离别。中:生长。右:聚会。AI生成两个状态之间的所有运动,仅凭两张图就创造出一个视觉故事。
定义叙事弧线
每个视频,不管多短,都讲述一个微型故事。首帧和尾帧定义故事的开头和结尾。AI 生成中间部分——运动、过渡、两个已知状态之间事件的展开。
示例:离别叙事
- 首帧:一个人站在门口,面对镜头
- 尾帧:同一个人沿小路走远,只看到背影
- AI 生成的内容:人转身、开门、走出、继续远去
- 情感基调:告别、旅程、向前
示例:生长叙事
- 首帧:一朵紧闭的花苞在茎上,清晨的光线
- 尾帧:同一朵花完全绽放,温暖的午后光线
- AI 生成的内容:花瓣展开,光线转移,花朵向阳开放
- 情感基调:蜕变、美丽、自然过程
示例:聚会叙事
- 首帧:一张摆好餐具但空无一人的餐桌
- 尾帧:同一张桌子坐满了人,正在交谈
- AI 生成的内容:人们进入画面,拉出椅子,落座,房间变得生动
- 情感基调:团聚、温暖、欢庆
示例:揭示叙事
- 首帧:一个包装好的礼盒,关闭状态
- 尾帧:礼盒打开,产品清晰可见
- AI 生成的内容:手伸向盒子,掀开盖子,展示内容物
- 情感基调:期待、惊喜、满足
核心洞察:两张图之间的空间就是一个故事,AI 是你的叙述者。你越用心选择这两个锚点,故事就越引人入胜。
尾帧最佳实践
创建有效的尾帧需要和首帧不同的思维方式。尾帧必须足够不同以创造叙事,又足够相似以让 AI 生成平滑、可信的过渡。
保持同一场景和环境。 首帧和尾帧之间不要换场景。首帧在厨房,尾帧也应该在同一个厨房。换场景需要切镜,这不是模型能生成的——它会尝试将一个场景变形为另一个,产出超现实且通常不理想的结果。
保持角色身份。 尾帧中的人应该是首帧中的同一个人,穿同样的衣服,同样的发型。模型无论如何都会试图维持身份,但参考图之间的不一致会创建冲突信号,降低输出质量。
只改变应该改变的。 对首帧和尾帧之间的差异要有选择性。AI 能很好处理的变化元素:
- 位置和姿势:主体从坐变站、转头看另一个方向
- 表情:从平静变微笑、从沉思变兴奋
- 时间推移:光线从早晨变傍晚(微妙更好)
- 物体状态:门从关到开、盒子从包装到拆开、蜡烛从点燃到燃尽
微妙变化产出更平滑的结果。 小幅转头、温柔的表情变化、轻微的姿势调整——这些产出美妙平滑、自然的视频。AI 不需要创造太多运动,因此能专注于让生成的内容看起来完美。
剧烈变化需要更长时长。 如果首帧和尾帧之间的变化显著(人从房间一侧到另一侧、花从花苞到绽放),给 AI 更多时间。剧烈变化压缩到 3 秒看起来仓促且经常产生伪影。同样的变化展开到 10-15 秒看起来自然且有电影感。
帧间视觉风格保持一致。 使用相同的机位角度(或非常相似)、相同的调色、相同的光影质量。如果首帧是温暖柔光、尾帧是冷硬光,视频会包含不自然的光影过渡。
什么时候不需要尾帧
尾帧很强大但并非总是必要的。有些场景只提供首帧反而效果更好。
想让 AI 给你惊喜时。 有时最具创意的结果来自给 AI 一个强起点然后让它自由发挥。对抽象、艺术或实验性内容尤其如此,这些场景中可预测性是敌人。
视频纯粹是氛围型的。 生成循环背景视频——海浪、飘云、壁炉跳动——没有叙事弧线需要定义。运动是循环的、氛围性的。首帧就够了;尾帧不必要,甚至可能不恰当地约束 AI。
首帧本身已提供充分引导。 如果首帧强烈暗示了应有的运动——跑步中的运动员、弧顶的球、跳水中的人——AI 能准确外推预期运动。加尾帧会多余且限制 AI 生成最自然的基于物理的运动。
没有合适的尾帧时。 差的尾帧比没有尾帧更糟。如果你不确定结束状态该是什么样,让 AI 决定。你随时可以生成多个变体然后选最好的。
5 个首帧/尾帧实战工作流
理论有用,但实践才出结果。以下五个完整工作流覆盖首帧尾帧视频生成最常见的使用场景。每个工作流包含帧设计、提示词和工具链的具体指导。

五个实战工作流,演示首帧尾帧视频生成在不同内容类型中的应用:角色动画、产品揭示、风光延时、动作序列和情感叙事。
工作流 1:角色动画
使用场景:社交媒体内容、虚拟形象动画、角色叙事
首帧设计:一个人直视镜头的肖像。中近景(头肩可见)。柔和均匀的光照配干净背景。面部完全可见、光照良好、中性或略带愉悦的表情。头发和服装清晰。
尾帧设计:同一个人,同样的构图,同样的背景——但现在转头看向右侧窗户。身体旋转约 45 度。表情从中性变为沉思。
提示词参考:
The person slowly turns their head to the right, gazing out the
window. Gentle, natural movement. Soft light from the window
illuminates their face from the side. Hair moves slightly with
the turn. Smooth, steady camera. Cinematic film quality.(人物缓慢向右转头,凝视窗外。温柔自然的动作。窗户柔光从侧面照亮面部。头发随转动微微飘动。平稳镜头。电影级画质。)
为什么有效:角色动画要求模型在运动过程中维持面部身份。清晰、光照良好的首帧给模型提供强面部特征数据。首帧和尾帧之间的微妙旋转容易实现——模型不需要生成极端运动,只要平滑的转头。
工具链:Seedance 图片生成器或文生图创建肖像,然后图生视频制作动画。国产工具中,可灵和即梦 AI 同样支持这种图生视频的角色动画工作流。
工作流 2:产品揭示
使用场景:电商产品视频、开箱内容、产品发布
首帧设计:一个高端产品盒或包装,在干净表面上居中。影棚灯光搭配微妙渐变背景。包装完好且关闭。干净的商业美学。
尾帧设计:同样的场景、灯光、表面——但盒子已打开,产品可见,以主角镜头呈现。包装被推到一侧展示内容物。
提示词参考:
Smooth product reveal. The box lid lifts open gracefully,
revealing the product inside. Dramatic studio lighting with soft
shadows. Camera slowly pushes in as the product is revealed.
Premium commercial quality. Clean, precise movements.(平滑产品揭示。盒盖优雅掀开,展露内部产品。戏剧性影棚灯光配柔和阴影。产品显现时相机缓缓推进。高端商业品质。干净、精准的运动。)
为什么有效:产品视频需要精准和专业。受控的影棚环境足够简单,AI 能完美处理。运动直截了当(开盒、展示产品),首帧和尾帧之间清晰的视觉差异给模型明确的轨迹。
工具链:拍摄实物产品照,或用文生图生成产品模型图。导入图生视频生成最终动画。
更多 AI 产品视频内容请看 电商产品视频 AI 指南。
工作流 3:风光延时
使用场景:电影级建立镜头、旅行内容、氛围背景视频
首帧设计:日出时分的宽幅风光照。天空在地平线低处呈现温暖的粉橙色调。山脉、水面或建筑提供清晰的前景和背景深度层。16:9 宽高比。高分辨率,全画面细节丰富。
尾帧设计:完全相同的风光和机位——但几小时后。天空变为深蓝和橙色,太阳位置大幅改变。阴影明显偏移。整体色温变暖。
提示词参考:
Gradual time passage across the landscape. Clouds drift slowly
across the sky. Sunlight shifts from sunrise to golden hour.
Shadows lengthen across the foreground. Water reflects the
changing sky colors. Static camera, no movement. Smooth,
hypnotic time-lapse quality.(风景中的渐进时间流逝。云缓缓飘过天际。阳光从日出过渡到黄金时段。前景阴影逐渐拉长。水面映射变化的天空色彩。静态相机,无运动。平滑、催眠感的延时品质。)
为什么有效:延时是首帧/尾帧生成的理想场景,因为空间内容保持不变——只有光影和氛围在变。模型擅长插值光照变化,因为光照在潜在空间中被编码为连续参数。静态相机指令去除了相机运动的复杂性,让模型全力以赴处理时间过渡。
工具链:使用不同时间拍摄的同一风光照,或用文生图生成一对(指定同一场景的不同时段)。日出版作为首帧上传到图生视频。
工作流 4:动作序列
使用场景:创意内容、娱乐、体育营销、动感社交媒体
首帧设计:角色处于准备姿态——蓄势待跳的舞者、坡道顶端的滑板手、起跑器上的运动员。动感构图配清晰的运动方向暗示。略低的机位增加戏剧感。主体清晰对焦,背景有景深虚化。
尾帧设计:同一角色处于动作中段——完全舒展的跳跃、空中的技巧、全速冲刺。姿势捕捉动作的峰值瞬间。四肢略带运动模糊增强动感。
提示词参考:
Dynamic burst of movement. The figure launches into action
with explosive energy. Cinematic slow motion capturing every
detail of the movement. Subtle motion blur on fast-moving limbs.
Camera tracks the action smoothly. Dramatic lighting emphasizes
the form. High-end sports commercial quality.(动感爆发。人物以爆炸性能量冲入动作。电影级慢镜头捕捉运动的每个细节。快速移动的肢体带微妙运动模糊。相机平滑跟踪动作。戏剧性灯光强调体态。高端体育商业品质。)
为什么有效:动作序列从尾帧中受益巨大,因为模型知道动作该在哪达到高潮。没有尾帧,AI 可能生成胆怯、不自然的运动。尾帧给了它生成大幅度、全身运动的许可和方向。两帧中隐含的物理(起跑蹲姿、空中峰值)提供强运动线索。
工具链:用文生图生成起始姿势和动作峰值。导入图生视频生成最终动态片段。
工作流 5:情感叙事
使用场景:品牌叙事、社交媒体叙事内容、短片
首帧设计:一个人独坐在餐桌旁。桌上摆了多人的餐具,但椅子空着。温暖、略暗的灯光。安静独处的氛围。主体表情中性或略带沉思。
尾帧设计:同一张桌子,同一个人——但其他椅子现在坐满了朋友或家人。灯光略微更暖更亮。主体正在微笑。盘中有食物。氛围从独处变为团聚。
提示词参考:
People gradually enter the frame and take their seats at the
table. The atmosphere warms as the room fills with conversation.
The main subject's expression shifts from pensive to joyful.
Lighting brightens subtly. Natural, warm movement. Handheld
camera with gentle, organic motion. Emotionally resonant,
cinematic storytelling quality.(人们逐渐进入画面在桌旁落座。随着房间充满交谈声氛围变暖。主角的表情从沉思变为欣喜。灯光微妙变亮。自然、温暖的运动。手持镜头配温柔、有机的运动。情感共鸣的电影叙事品质。)
为什么有效:情感叙事是首帧/尾帧生成最精妙的用法。叙事弧线(孤独到归属)通过两帧清晰定义。模型不仅能插值物理变化(人到来、表情变化),还能插值氛围变化(灯光变暖、能量积聚)。这产出的视频能真正唤起情感——纯文本提示词很少能做到。
工具链:用文生图生成两个场景,仔细保持两张图中相同的环境和角色设计。用图生视频生成最终叙事片段。
用 AI 图片生成工具创建首帧
Seedance 最强大的优势之一是你不需要依赖现有照片做首帧。你可以用平台的 AI 图片工具从零生成自定义参考图——然后直接送入视频生成器。这创造了一个完整的"想法到视频"流水线。
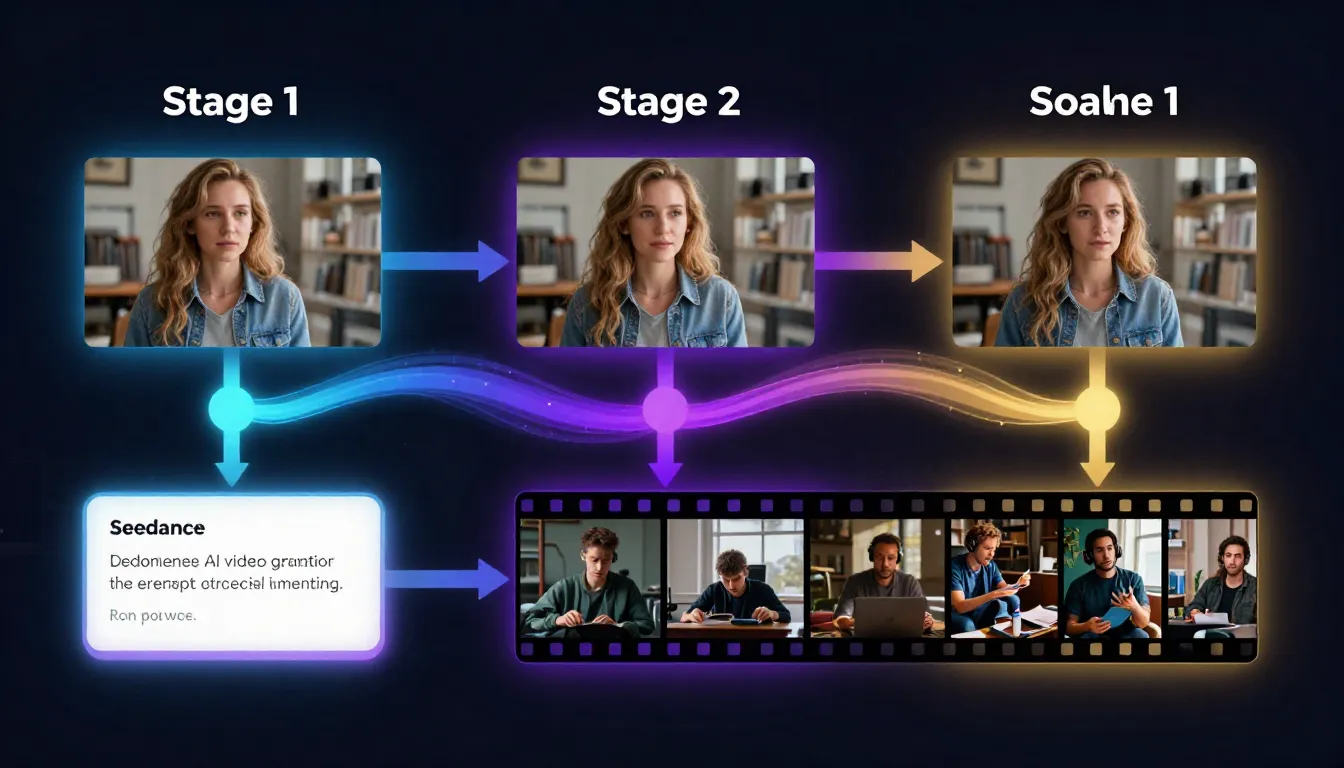
Seedance流水线:描述想法、生成提示词、创建参考图、制作视频——全程在一个平台内完成。每一步自然衔接下一步。
使用 Seedance 图片提示词生成器
流水线从你的想法开始。也许它很模糊:"一个未来城市的夜景"。也许很具体:"一片露珠在叶子上的微距照片,日出时分"。不管哪种,图片提示词生成器都能将其转化为覆盖 7 大维度的详细专业提示词,效果远好于随意描述。
图片提示词生成器做的事:
- 扩展描述覆盖 7 大维度:主体、环境、光影、色彩、构图、风格/媒介和画质修饰
- 让你选择视觉风格匹配预期的视频美学——写实、电影、插画、动漫等
- 为下游使用优化:生成的提示词产出天然适合做视频首帧的图片,构图和深度恰当
完整的图片提示词工程指南请看 AI 图片提示词生成器指南。
关键优势:为视频用途设计的图片提示词和为独立图片设计的提示词根本不同。 提示词生成器理解这种区别,能产出优先考虑好首帧特征的提示词——运动空间、深度层次、清晰主体和电影级构图。
使用 Seedance 文生图
有了优化的提示词,文生图生成实际的参考图。你的首帧在这一步诞生。
工作流是迭代的:
- 从提示词生成一批图片
- 逐一评估是否满足前面讨论的首帧设计原则:有运动空间吗?深度层清晰吗?主体清晰吗?光影一致且有意图吗?
- 微调并重新生成直到获得满足你标准的参考图
- 选出最佳候选作为首帧
用 AI 生成首帧而非使用现有照片的优势在于完全的创意控制。你不受已拍摄过什么的限制。可以创建任何场景、任何角色、任何环境,精确的构图、光影和氛围——一切按视频需求来。
文生图完整指南请看 文生图 AI 完整指南。
使用 Seedance 图生图
如果你已有一张图——照片、草图、其他项目的截图——但还不够适合做首帧怎么办?图生图将现有图片转化为精致的、适合做视频首帧的参考图。
常见的图生图首帧创建工作流:
- 风格转换:将手机随手拍转化为电影级、专业布光的场景
- 增强和精修:提升分辨率、锐化细节、校正光影问题、增加视频生成所需的视觉精修
- 构图调整:修改现有图片以增加运动空间、改善深度层次或重新平衡主体位置
- 美学转换:对现有图片应用特定视觉风格(黑色电影、黄金时段、科幻、田园)以建立视频氛围
完整指南请看 图生图 AI 指南。
Seedance 完整流水线
从想法到成品 AI 视频的完整端到端工作流:
第一步:构思 用大白话描述你的视频概念。"一个机器人走在霓虹灯照亮的东京夜晚街头。"
第二步:提示词生成 用图片提示词生成器将描述扩展为详细、多维度的图片提示词,优化为生成适合做视频首帧的参考图。
第三步:首帧生成 将提示词送入文生图生成首帧。反复迭代直到构图、光影、主体和氛围完全满意。
第四步:可选精修 如果生成的图接近但不完美,用图生图精修——调整风格、增强细节或修改构图。
第五步:视频生成 将最终首帧上传到图生视频。写一条聚焦运动的提示词描述场景如何活起来。生成视频。
这条流水线是 Seedance 独有的。其他平台支持图生视频,但要求你自带参考图。Seedance 在一个平台内提供完整创作链——减少工具切换摩擦、跨工具保持视觉一致性、加速从概念到成品视频的迭代。
更深入的工具组合指南请看 图生视频工作流指南。
平台对比:首帧支持情况
了解不同平台如何处理首帧和尾帧输入,有助于选择合适的工具。以下是基于实际测试的对比。
| 平台 | 首帧 | 尾帧 | AI 图片生成 | 最适合 |
|---|---|---|---|---|
| Seedance 2.0 | 支持 | 文本引导 | 内置(完整流水线) | 端到端工作流、一站式流水线 |
| 可灵 3.0(Kling) | 支持 | 支持 | 不支持(需外部图片) | 长时长视频、高一致性 |
| Runway Gen-4 | 支持 | 支持(通过风格参考) | 不支持 | 精准运动控制、专业剪辑 |
| Pika 2.0 | 支持 | 不支持 | 不支持 | 快速简单的图生视频 |
| Sora | 支持 | 有限 | 不支持 | 创意、艺术视频生成 |
| Veo 3 | 支持 | 图像调节 | 不支持 | 高视觉质量、Google 生态 |
| Luma Dream Machine | 支持 | 支持 | 不支持 | 平滑运动、自然物理 |
| 通义万相视频 | 支持 | 有限 | 内置(通义万相图片) | 中文生态、国内访问 |
| 即梦 AI | 支持 | 有限 | 内置 | 字节生态、抖音适配 |
| Pixverse | 支持 | 不支持 | 不支持 | 免费额度充足、入门友好 |
客观评价
Seedance 的独特优势在于集成流水线。没有其他平台让你在同一工具内生成参考图然后立即用于视频生成。这消除了切换应用的摩擦并跨工作流保持视觉一致性。AI 图片生成器和文生图工具专门调优以产出适合做视频首帧的输出。
国产工具的优势:可灵 3.0 支持长达 2 分钟的单首帧视频生成,这在行业内无人匹敌。通义万相视频对中文提示词的理解最为精准,与阿里的图片生成工具生态协同良好。即梦 AI 与抖音深度集成,适合社交媒体创作者的快速出片需求。Pixverse 对新手最友好,免费额度慷慨。
海外工具的优势:Runway Gen-4 的 Motion Brush 和 Director Mode 提供更精细的运动控制。Pika 2.0 界面最简单,适合上传即用。Luma Dream Machine 处理物理运动(水、布料、头发)的真实感最佳。
总结:如果你的工作流涉及从零创建参考图再生成视频,Seedance 提供最流畅的体验。如果你已有高质量参考图且需要特定功能(如长时长或像素级运动控制),其他平台可能在特定需求上更合适。国内用户如果需要无障碍访问和中文理解力,可灵、通义万相和即梦 AI 是首选。
完整平台对比请看 2026 年最佳 AI 视频生成器对比。
首帧和尾帧的常见错误
在大量首帧/尾帧视频生成实践中,以下是最常见的错误。避免它们能省下大量时间和积分。
1. 使用低分辨率图片
错误做法:上传从网站抓的 400x300 缩略图或聊天软件里被重度压缩的 JPEG。
为什么失败:图像编码器从低分辨率图中提取的细节少得多。潜在表示稀疏且有噪声,给视频模型的信息不足以维持清晰度、一致性和跨帧细节。首帧中的像素化在每个生成帧中被放大。
正确做法:始终使用最高分辨率版本的图片。最低 1024x1024 像素可获得可靠结果。如果唯一来源是小图,先用 AI 超分辨率工具放大——但要知道放大增加的是分辨率不是信息。最好直接用文生图生成高分辨率首帧。
2. 场景过于复杂
错误做法:使用有几十个主体、精细图案、杂乱背景和多个焦点的首帧。
为什么失败:视频模型需要判断什么该动、什么该静、一切该如何交互。有 20 个人、多个重叠物体和繁忙背景的场景比 1-2 个主体配干净背景的场景难度呈指数增长。模型无法处理这种复杂度,产出伪影、不一致或通用的"一切都微微动一下"输出。
正确做法:简化。一到两个主要主体。支撑场景但不抢夺注意力的背景。如果需要复杂场景,考虑分层生成——单独动画化各元素然后后期合成。
3. 首帧尾帧光影不一致
错误做法:首帧从左侧打暖色影棚灯,尾帧从上方打冷色自然光。
为什么失败:模型尝试在两个根本不同的布光方案之间插值。这创造出不自然的视频中段光影突变,看起来像失败的过渡而非自然的时间推移。阴影朝矛盾方向移动,肤色异常偏移,整体视觉一致性崩塌。
正确做法:两帧使用完全相同的布光,或只有非常微小的有意变化(例如场景推进时略微变暖)。如果做时间推移效果,让光影变化渐进且方向一致。
4. 首帧尾帧构图差异过大
错误做法:首帧是远景全景,尾帧是极端特写。或者:首帧主体在左侧,尾帧换了完全不同的主体在右侧。
为什么失败:模型将帧间过渡当作连续运动路径。剧烈的构图变化要求模型凭空创造复杂的相机运动或主体变形,这超出了它的可靠能力。结果通常是糊成一团的变形效果。
正确做法:保持构图相似。想做推镜头,从中景到中近景——不要从远景到极端特写。想要主体移动,保持同样的构图让主体在画面内移动。小幅构图变化,不是大幅跳跃。
5. 忽略宽高比不匹配
错误做法:上传 16:9 横版首帧但设置视频输出为 9:16 竖版。
为什么失败:模型要么裁切你精心设计的首帧(丢失构图和内容),要么凭空生成大量缺失的视觉内容(引入不一致)。两种结果都严重降低输出质量。
正确做法:匹配宽高比。首帧是横版,就生成横版视频。如果需要竖版视频,上传前先把首帧裁成竖版。或者更好的做法——一开始就生成竖版首帧。
6. 用有明显瑕疵的 AI 生成图做首帧
错误做法:用 AI 工具生成首帧,注意到有轻微变形的手、多余的手指或扭曲的面部——但还是用了。
为什么失败:AI 视频模型会忠实复现并经常放大首帧中的任何瑕疵。静态图中那只稍微不对的手在运动中变成怪异变形的手。那张微妙不对称的面部在 30 帧的运动中变成变形噩梦。
正确做法:对首帧质量毫不妥协。如果 AI 生成的图有任何可见瑕疵——手、手指、面部对称性、文字渲染、几何变形——重新生成。花几分钟获得干净的首帧能避免几小时失败的视频生成。用图生图修复特定问题同时保留整体构图。
常见问题
什么是 AI 视频中的首帧?
首帧是你提供给 AI 视频生成器的一张参考图,定义视频的起始画面。它替代了纯文本提示词对场景的描述,给 AI 一个具体的视觉参考。模型随后生成与这张起始图一致的运动和后续帧。首帧控制主体外观、场景构图、光影、色板和初始机位。它是图生视频(image-to-video)中影响力最大的单一输入。如果你用过可灵的图生视频功能,上传的那张图就是首帧。
必须同时提供首帧和尾帧吗?
不需要。只提供首帧对大多数使用场景已经足够,也是各 AI 视频平台更普遍支持的输入方式。首帧定义场景,AI 根据首帧加文本提示词生成运动。尾帧是额外约束,定义视频该到达的终点——适合叙事和精确运动控制,但非必需。很多优秀的 AI 视频只用了首帧。当你有明确的叙事弧线(从 A 点到 B 点)并希望 AI 生成精确的运动路径时,再加尾帧。
首帧分辨率应该多少?
最低建议 1024x1024 像素在大多数平台上可获得可靠结果。最优输出质量推荐 1920x1080(16:9)、1080x1920(9:16)或 2048x2048(1:1)。更高分辨率给图像编码器提供更多视觉信息,产出更清晰、更细腻的视频。避免低于 512x512,质量下降非常明显。如果手头只有低分辨率图片,考虑用 AI 超分辨率工具放大,或用文生图直接生成高分辨率首帧。
可以用照片做首帧吗?
完全可以。照片做首帧效果很好,很多时候甚至优于 AI 生成图,因为照片包含真实细节、自然光影和真实质感。最适合做首帧的照片特征:高分辨率、构图良好、曝光正确、主体清晰。避免重度滤镜、极度压缩或低光照片。专业照片、产品图、肖像和风光照都适合。图片应干净、无明显噪点或压缩伪影。
如何保持视频中的角色一致性?
角色一致性从首帧开始。提供清晰、光照良好的图片,让角色的面部、服装和标志性特征完全可见。AI 获得的角色外观信息越多,跨帧维持的效果越好。具体建议:使用正面光或四分之三光的肖像(避免面部硬阴影)、选择独特的服装和配饰让模型可追踪、保持视频时长较短(5-10 秒的一致性远好于 30 秒)、避免提示词中要求极端运动(需要从不寻常角度重建面部)。如果一致性至关重要,生成较短片段然后在视频编辑器中组合。
哪些 AI 视频生成器支持首帧上传?
2026 年所有主流 AI 视频生成器都支持首帧上传:Seedance 2.0、可灵 3.0(Kling)、Runway Gen-4、Pika 2.0、Sora、Veo 3、Luma Dream Machine、通义万相视频、即梦 AI、Pixverse。这个功能现在是标配。平台之间的差异在于尾帧支持、图像调节质量和围绕首帧工作流提供的额外工具。Seedance 独特之处在于提供内置图片生成流水线(提示词生成器、文生图、图生图),直接衔接视频生成器。详见上方平台对比。
可以用 AI 生成首帧而不用照片吗?
可以,而且这是最有效的方法之一。AI 生成的首帧提供完全的创意控制——你可以创建任何描述得出的场景、角色、环境或构图。Seedance 为此提供完整流水线:用图片提示词生成器创建优化提示词,然后文生图生成图片,可选用图生图精修,最后图生视频制作动画。关键注意事项:在用于视频生成前仔细检查 AI 生成的首帧是否有瑕疵(变形的手、面部不对称、图案扭曲),因为任何缺陷都会在视频中被放大。
首帧和风格参考有什么区别?
首帧作为视频的实际起始画面。AI 从这张精确的图片向前生成运动,维持其内容、构图和视觉细节。风格参考(部分平台如 Runway 提供)用于引导视频的美学风格,不要求输出从那张精确图片开始。风格参考影响调色、光影质量、质感和整体氛围,但视频内容仍主要由文本提示词决定。简单理解:首帧说"从这里开始往前走"。风格参考说"让它看起来像这样"。部分工作流两者兼用——首帧控制内容,风格参考控制美学。
开始创建可控的 AI 视频
随机生成的 AI 视频和有意图导演的 AI 视频之间的差距,归结为一件事:参考帧。一张精心设计的首帧将 AI 视频生成从老虎机变成创作工具。首帧加尾帧的组合更进一步——把它变成一种叙事媒介。
以下是将本指南所有内容付诸实践的步骤:
第一步:设计参考图。 用图片提示词生成器创建优化提示词,针对视频用途的构图、光影和主体设计。
第二步:生成首帧。 用文生图创建高质量参考图,体现你希望视频呈现的一切。反复迭代直到构图、主体和氛围都对了。
第三步:创建视频。 将首帧上传到图生视频,写一条聚焦运动的提示词,生成。你的参考图确保输出匹配你的创意愿景——而不是 AI 的猜测。
第四步:迭代优化。 生成变体、调整提示词、尝试不同的首帧构图。每次迭代都让你更了解模型的响应方式。
工具已就绪。技术已讲透。唯一的变量是你的创意愿景。
生成你的首帧 → — 为下一个 AI 视频创建完美的参考图。
用图片创建视频 → — 将参考帧转化为动态视频内容。
设计完美参考帧的提示词 → — 让 AI 帮你写理想的首帧提示词。
掌握完整流水线 → — 精通从概念到成品视频的全流程。
