
速览
图生图 AI(Image-to-Image)是以已有图片为起点,通过 AI 进行风格迁移、局部编辑、画质增强、变体生成和画布扩展的技术。和文生图(从零创建画面)不同,图生图从你的照片或画作出发,根据文字提示词生成变换后的新版本。它是 2026 年最实用的 AI 创作工具之一——不需要任何修图技能,就能对图片做专业级的风格化处理和精修。更关键的是,图生图是 AI 视频生成的必备前置步骤:先把图片编辑到位,再把它作为首帧输入视频模型,出片质量天差地别。本指南覆盖技术原理、6 大核心能力、8 款工具对比、Seedance 实操教程、8 个提示词示例,以及图生图到视频的完整创作链路。试用 Seedance 图生图 --> | 文生图入口 -->
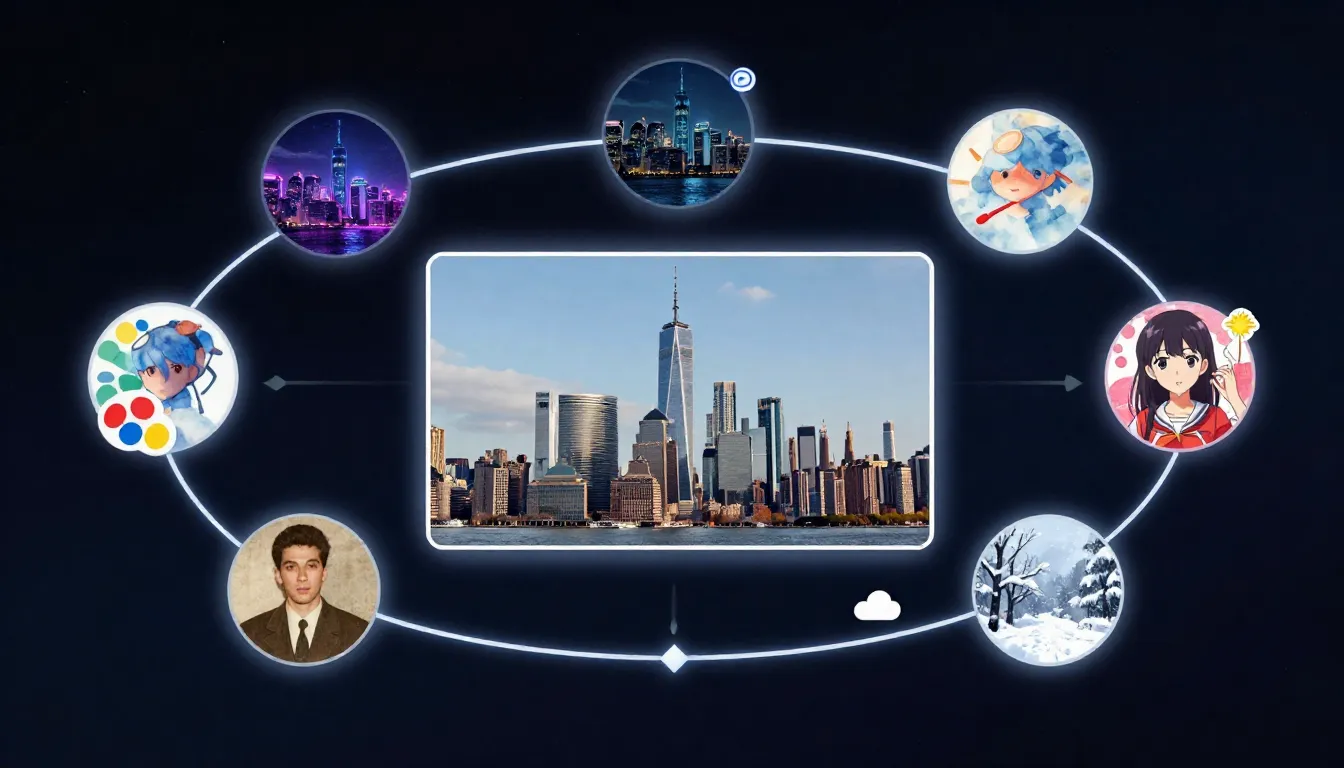
图生图AI以你的照片为起点,生成风格迁移、画质增强、局部编辑、画布扩展等多种变体——全程由文字提示词引导。
什么是图生图 AI?
图生图 AI 是一种以已有图片作为输入、生成其修改版本的人工智能技术。你提供一张照片、插画、草稿或任何视觉素材,附带一段描述目标变换的文字提示词,AI 就会输出一张既保留原图核心元素、又体现你指令的新图片。
和文生图的关键区别在于起点不同。文生图从文字描述凭空生成画面——AI 自行决定所有视觉元素。图生图从一张具体的视觉参考出发,AI 已经知道画面的构图、主体位置、色彩分布和空间结构,它的工作是按照你的提示词去修改、增强或重新风格化这个视觉基础。
核心能力
图生图不是单一功能,而是基于同一底层技术的一系列能力:
- 风格迁移:把照片变成油画、水彩、动漫、赛博朋克或任何艺术风格,同时保留原始构图
- 局部编辑(Inpainting):只改图片的特定区域(移除物体、换背景、改服装),其余部分不动
- 画布扩展(Outpainting):向任意方向扩展图片边界,AI 无缝填充新区域
- 画质增强和超分辨率:提升分辨率、锐化细节、降噪、修正曝光
- 变体生成:从同一张图生成多个版本,在姿势、表情、角度或细节上做微调
- 视频首帧准备:在将图片输入 AI 视频模型之前,先用图生图精修到最佳状态
为什么重要
在图生图 AI 出现之前,修改一张图片要么需要 Photoshop 技能,要么需要找设计师。把一张写实照片改成水彩风格?至少几个小时的专业工作。从复杂场景中移除一个不想要的物体?需要反复使用克隆图章和混合工具。把裁切过的图片扩展到更宽的画幅?基本上不可能。
图生图 AI 把这些操作压缩到了几秒钟。描述你想要什么,AI 负责技术执行。这不是取代专业设计师——而是让每个人都能用上过去需要专业培训才能掌握的能力。
在视频制作中的角色
这是图生图 AI 最被低估的价值:它是静态图片和 AI 视频生成之间的关键桥梁。视频首帧的质量直接决定了生成视频的质量上限。图生图能帮你:
- 把粗糙草稿变成精致的电影级首帧
- 调整光影、调色和风格,匹配目标视频的美学方向
- 修复 AI 生成图片中的瑕疵(多余手指、不自然的光线),再用它做视频参考帧
- 在不同宽高比之间转换(竖版转横版),适配视频需求
如果你在做图生视频创作,图生图不是可选项——它是把业余成品和专业级作品拉开差距的关键准备步骤。
图生图 AI 的 6 大核心能力
图生图涵盖广泛的创作操作。以下是 6 种最具影响力的能力及其实际应用场景。
1. 风格迁移
风格迁移改变图片的视觉美学,同时保留底层构图和结构。你可以把照片变成油画、把铅笔草稿变成精致数字插画、把写实风景变成动漫场景。
AI 分析输入图片的结构元素——边缘、形状、深度、主体位置——然后用完全不同的艺术风格重新生成视觉表面。结果保持可辨识性(明显是同一个场景),但看起来像在完全不同的媒介中创作的。
实际应用:
- 批量将品牌内容统一为一致的视觉风格
- 把产品摄影转化为插画版本用于营销物料
- 把写实参考照片转化为风格化概念艺术
- 生成具有独特美学识别度的社交媒体内容
操作示例: 上传一张城市街景照片。提示词:"Transform into a Studio Ghibli anime scene. Soft watercolor textures, warm pastel colors, hand-painted feel."(转化为吉卜力动画场景。柔和水彩质感,温暖粉彩色调,手绘感。)AI 保留街道布局、建筑位置和透视关系,但用动画艺术风格重新绘制一切。
2. 画质增强与超分辨率
增强功能将低质量图片提升到更好的状态——锐化细节、提升分辨率、降噪、修正曝光、恢复清晰度。这远超传统的插值放大算法。AI 增强实际上会生成新的视觉细节,让结果看起来像原始照片中本该存在的那样。
一张 512x512 的手机照片可以变成清晰的 2048x2048 图片,带有原图中不存在的细节。AI 根据上下文推断那些细节应该是什么样子——如果看到模糊的眼睛,它会生成带有虹膜纹理、反光和睫毛的清晰眼睛。
实际应用:
- 为高质量印刷准备低分辨率图片
- 修复老旧或受损照片
- 把手机随拍提升到专业品质
- 放大分辨率不够的 AI 生成图片
- 为AI 视频生成准备尺寸过小的参考帧
3. 局部编辑(Inpainting)
局部编辑让你只修改图片的特定区域,其余部分完全不动。你选择一个区域(通过涂抹遮罩或文字描述),告诉 AI 要改什么,只有那个部分会被重新生成,周围的像素原封不动。
这是 AI 最接近"手术级编辑"的能力。不同于全图变换可能偏离原图,局部编辑完美保留编辑区域外的一切。难点在于让编辑区域与周围环境无缝融合——现代模型在光照一致性、纹理匹配和透视准确度上的表现已经相当出色。
实际应用:
- 从照片中移除不想要的物体(路人、广告牌、杂物)
- 保留主体的同时更换背景
- 改变人物的服装、配饰或颜色
- 修复 AI 生成图片中的瑕疵(多余手指、变形细节)
- 在视频参考帧投入生成之前修正特定区域
4. 画布扩展(Outpainting)
画布扩展将图片向原始边界之外延伸。AI 向任意方向(左、右、上、下或同时四面)生成无缝衔接的新内容。生成的延伸区域在透视、光照、风格和内容上都与原图匹配。
这对宽高比转换特别有用。如果你有一张方形竖版人像但需要 16:9 横版用于视频,画布扩展可以向左右两侧延伸,用合理的上下文内容填充。AI 根据可见场景推断画框外应该存在什么——如果左侧边缘显示了一片森林的一部分,延伸区域会自然地继续这片森林。
实际应用:
- 把竖版图片转为横版用于视频制作
- 扩展裁剪过紧的图片,显示更多场景
- 从标准照片创建全景版本
- 为不同社交平台调整宽高比(1:1 转 16:9,4:3 转 9:16)
- 为首尾帧视频生成准备更宽的画布
5. 变体生成
变体生成从同一张图创建多个带有可控差异的版本。从单一源图出发,你可以生成在姿势、表情、角度、色彩或构图细节上略有不同的多个版本。每个变体都能一眼认出是同一个场景,但提供不同的视角。
这对迭代式创作极有价值。不用从零生成全新图片然后碰运气,你从一张已经接近目标的图片出发,生成十个变体——总有一个完全符合预期。
实际应用:
- 为营销活动做视觉素材的 A/B 测试
- 创建视频首尾帧(同一场景、不同状态——门关着 vs. 打开,白天 vs. 黄昏)
- 为产品目录生成略有差异的产品图
- 不重新设计就能探索品牌配色方案
- 从单一参考图生成多个社交媒体发布选项
6. 图生图用于视频首帧
这是将图生图 AI 接入完整 AI 视频制作流程的关键能力。Seedance 等视频生成模型在接收到高质量、构图优秀的参考帧时,输出效果会显著提升。图生图就是你创建这个参考帧的工具。
工作流非常直观:拿任何图片(粗糙草稿、AI 生成的初稿、手机照片),用图生图将其变换为精致的电影级画面,然后将这个画面输入图生视频来生成专业视频片段。
为什么这很重要: 首帧设定了视频模型生成每一个后续帧的视觉标准。低质量首帧 = 低质量视频。电影级首帧 = 电影级视频。图生图就是确保你的首帧达到这个标准的工具。

图生图AI的6大核心能力——从风格迁移和画质增强,到连接图片与AI视频生成的首帧准备流程。
图生图 AI 的技术原理
理解图生图 AI 的技术过程有助于你获得更好的结果。知道 AI 为什么会那样表现,你就能提供更好的输入、写更好的提示词、更有效地调整参数。
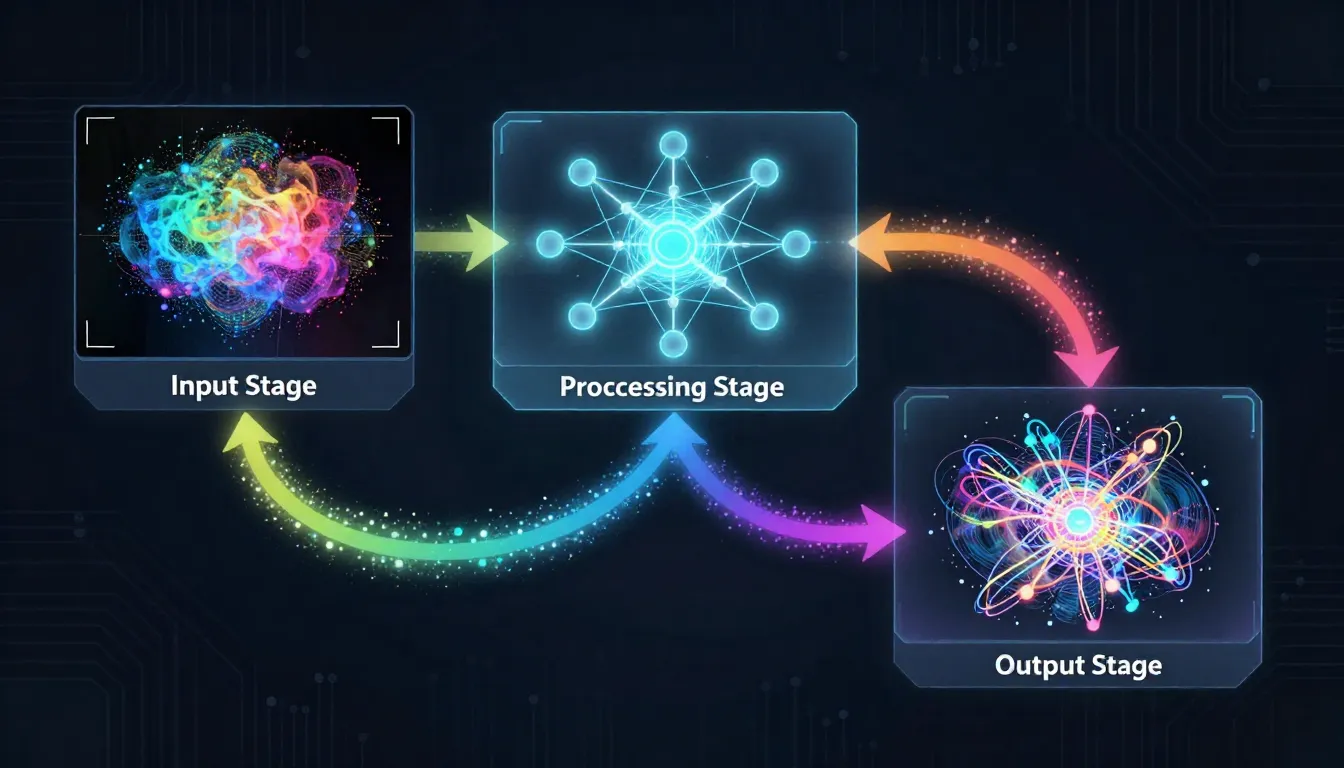
图生图AI流程:源图被部分加噪,然后在文字提示词的引导下去噪重建。强度参数决定了变化幅度。
img2img 去噪过程
图生图 AI 的核心机制是部分噪声扩散(Partial Noise Diffusion)。流程如下:
-
图片编码:源图被压缩为一个潜空间表示(latent representation)——一个密集的数学指纹,捕捉图片的结构、色彩、深度、语义和构图信息。
-
部分加噪:模型不是从纯随机噪声开始(文生图才那样),而是向编码后的图片添加可控量的噪声。这会部分破坏图片——模糊一些细节、偏移一些颜色、降解一些结构。加入噪声的量由强度/去噪参数(Strength/Denoising)决定。
-
文本引导去噪:模型反向执行噪声过程,逐步将被破坏的图片去噪恢复为干净的图片。关键在于:去噪过程受你的文字提示词引导。模型不是简单地还原原图——而是将重建方向引导向提示词描述的目标。
-
输出解码:最终的潜空间表示被解码回像素空间,产出你的变换图片。
结果是一张介于原图和提示词描述之间的图片。这个平衡点由强度参数控制。
强度/去噪参数
这是图生图 AI 中最重要的单一参数。它控制输出与输入的偏离程度:
- 低强度(0.1--0.3):微调。输出与输入非常相似,只有轻微调整——色彩微移、柔和处理、小幅风格修饰。原始构图和细节几乎完全保留。
- 中等强度(0.4--0.6):适度变换。整体构图和结构被保留,但会施加显著的视觉变化。风格迁移在这个区间效果最好——场景依然可辨识,但美学风格明显不同。
- 高强度(0.7--0.9):大幅变换。AI 有足够自由度大幅改变图片,只有大致布局和粗略形状被保留。适合戏剧性的风格重塑或需要文字提示词主导的场景。
- 最大强度(1.0):原图基本被忽略。输出几乎完全由文字提示词决定——此时本质上就是以极松散的构图指导做文生图。
经验法则: 从 0.5 开始,根据首次结果上下调整。和原图太像?提高强度。丢失了太多原图特征?降低强度。
ControlNet:结构引导
ControlNet 是一种扩展架构,它从输入图片中提取特定的结构信息,作为生成过程中的硬约束。与标准 img2img(将整张图片作为软引导)不同,ControlNet 提取一个特定的结构元素并严格保留它,同时允许其他一切改变。
常见 ControlNet 模式:
- 边缘/Canny:保留图片的轮廓和边缘。AI 在这些边缘内用新风格重绘一切。适合需要精确保留形状的风格迁移。
- 深度(Depth):保留空间深度图(远近关系)。物体在 3D 空间中保持相对位置。适合在保持空间布局的同时重新风格化场景。
- 姿态(OpenPose):保留人体姿势(关节位置、肢体角度)。AI 可以完全改变人物外观,同时保持精确姿态。适合角色重新风格化。
- 语义分割(Segmentation):保留语义区域(天空、地面、建筑、人物)。每个区域可以独立重新风格化,同时保持边界。
IP-Adapter:风格与身份迁移
IP-Adapter 是另一种方法,它将参考图的风格或身份特征迁移到你的生成中。它不是提取结构信息,而是提取视觉"性格"——色彩方案、光影风格、质感特征,甚至一个人的面部身份。
与标准 img2img 的区别: 标准 img2img 将你的输入图片同时作为结构指导和风格来源。IP-Adapter 将这两个角色分离。你可以用一张图提供结构,用另一张图提供风格——将一张的构图与另一张的美学结合。
实际示例: 用一张城市照片提供结构(建筑、街道、透视),用一幅梵高画作作为 IP-Adapter 风格参考。结果:你的城市场景以梵高的旋涡状笔触风格呈现,同时保持准确的构图。
文字提示词与图片如何协同
文字提示词和源图通过加权混合过程协同工作。模型同时接收两种输入的引导:
- 图片引导提供构图结构、色彩范围、深度信息和语义内容
- 文字引导提供风格方向、修改指令和创意意图
当两者一致时(例如图片展示日落,提示词说"golden sunset"),模型强化两个信号,产出自信的结果。当两者冲突时(例如图片展示海滩,提示词说"snowy mountain"),模型必须妥协——强度参数决定哪个输入赢。
最佳实践: 写提示词时要和图片互补,而不是与之矛盾。描述你想要的变换方向,而不是一个完全不同的场景。
8 款最佳图生图 AI 工具(2026)
我们从画质、功能、易用性和性价比四个维度评估了 8 个主流平台,包括国内外工具。测试均在 2026 年 2 月进行。
| 工具 | 最适合 | 免费额度 | 核心优势 | 局限性 |
|---|---|---|---|---|
| Seedance 图生图 | 图片-视频联动工作流 | 有(免费积分) | 图生图→图生视频无缝衔接 | 较新平台 |
| Stable Diffusion (img2img) | 极致控制与定制 | 有(开源) | 全参数控制、ControlNet、LoRA | 需要技术配置 |
| 通义万相 | 中文用户、国风内容 | 有(免费额度充足) | 中文理解力最强,国内直接访问 | 海外访问受限 |
| 文心一格 | 文创、中国风、水墨 | 有(每日额度) | 中国传统美学独特优势 | 国际风格稍弱 |
| Kolors(快手可图) | 免费高质量出图 | 有(开源) | 美学质量出色,开源免费 | 社区生态不如 SD |
| Adobe Firefly | 商业/专业用途 | 有(有限) | 企业级,Adobe CC 集成 | 输出偏保守 |
| Midjourney (--image) | 美学级风格变换 | 无(纯付费) | 美学质量顶级 | 编辑精度有限 |
| DALL-E 3 (ChatGPT) | 对话式编辑 | 有(ChatGPT免费版) | 自然语言交互 | 精细控制较弱 |

同一张照片在不同图生图平台上的处理效果。风格还原度、细节保留和变换质量的差异一目了然。
1. Seedance 图生图——图片-视频联动最强
Seedance 的独特之处在于把图生图定位为视频制作流程的第一步,而不是一个独立工具。变换完图片后,一键就能将结果直接送入图生视频。不用下载、不用重新上传、不用格式转换。这种图片变换到视频生成之间的无缝衔接在市场上独一无二。图片质量过硬,支持多种变换模式,提示词界面在功能性和简洁性之间取得了很好的平衡。免费积分足够测试从图片变换到视频生成的完整工作流。
2. Stable Diffusion (img2img)——极致控制与定制
Stable Diffusion 是开源界的性能之王。它提供对图生图生成每个方面最精细的控制:强度、CFG scale、采样方法、步数、ControlNet 集成、LoRA 模型加载、自定义模型检查点。如果你想精调每一个参数、加载社区训练的特定风格模型,没有什么能与之匹敌。代价是复杂度——你需要安装 ComfyUI 或 AUTOMATIC1111,管理 Python 环境,学习大量技术术语。不推荐新手,但对进阶用户而言无可替代。
3. 通义万相——国内首选,中文理解最强
阿里的通义万相 2.1 是国内最强的通用 AI 图片平台,对中文提示词的理解力在所有工具中遥遥领先。图生图功能支持风格迁移、画质增强和局部编辑,内置多种风格预设。无需翻墙即可使用,免费额度充足,适合频繁实验。
特别优势:
- 中文提示词效果远超其他工具,无需翻译
- 内置国风、古风、水墨等中国特色风格
- 和通义千问生态打通,多模态联动
- 免费额度对日常创作完全够用
4. 文心一格——文创与中国传统美学
百度的文心一格在中国传统美学领域有独特竞争力。水墨风、国潮风、敦煌风等中国风格出图效果出色。图生图功能支持风格转换和画质增强,内置大量风格模板可与提示词叠加使用。
适用场景:
- 需要中国传统美学(水墨、工笔、国潮)的项目
- 文创产品设计和传统元素融合
- 配合文心一言生态做内容创作
5. Kolors(快手可图)——开源免费,美学出色
快手推出的 Kolors 是国内开源图片生成模型中的佼佼者,美学质量和色彩表现力出色。在 LiblibAI 等平台上可以直接在线使用其图生图功能。开源免费,适合有一定技术基础的用户本地部署。
6. Adobe Firefly——商业制作首选
Adobe Firefly 直接集成在 Photoshop、Illustrator 和整个 Adobe Creative Cloud 生态中。Generative Fill(生成式填充)和 Generative Expand(生成式扩展)是局部编辑和画布扩展的精致实现。商业授权是业内最清晰的——Adobe 基于授权内容训练,为企业客户提供明确的知识产权保障。输出偏保守(创意风险低、质量可预期),这恰恰是商业制作需要的。如果你的工作流已经在 Adobe 生态内,Firefly 是最自然的选择。
7. Midjourney (--image)——美学变换之王
Midjourney 产出的视觉变换最为惊艳。其美学引擎持续生成构图、色彩和谐和艺术质量出色的图片。--iw(image weight)参数控制源图对输出的影响力。结果有一种标志性的精致质感,很多用户偏好用它做创意和艺术类工作。局限在于编辑精度——Midjourney 擅长大范围的美学变换,但在精确的局部编辑上较弱。
8. DALL-E 3 (ChatGPT)——对话式编辑最自然
DALL-E 3 集成在 ChatGPT 中,提供最自然的交互模式。上传图片,用日常语言描述你想要的改变——"把左边的人去掉""改成日落场景""把裙子改成蓝色"。不需要技术参数、不需要滑块、不需要专业术语。适合知道自己想要什么但不知道技术表达方式的用户。精度低于专业工具,但无障碍程度无人能及。
我们的建议: 如果你打算把变换后的图片用作 AI 视频的参考帧,Seedance 是首选,因为它的图生视频流程无缝衔接。追求极致技术控制用 Stable Diffusion。商业制作在 Adobe 生态内用 Firefly。纯美学质量用 Midjourney。中文内容创作首选 通义万相。中国传统美学用 文心一格。更完整的 AI 图片工具对比请看 2026 年最佳 AI 图片生成器。
Seedance 图生图实操教程
按照以下 5 步操作,用 Seedance 变换任何图片。流程设计得很直观,但理解每一步背后的逻辑能帮你获得显著更好的结果。
Seedance图生图完整工作流:上传源图、描述变换目标、调整参数、生成图片、可选将结果直接转入视频生成。
第一步:上传源图
打开 Seedance 图生图,上传你的源图。支持 JPG、PNG 和 WebP 格式。
什么样的源图效果好:
- 分辨率:最低 512x512 像素,推荐 1024x1024 以上。分辨率越高,AI 能获取的信息越多,变换结果越清晰。
- 清晰度:清晰对焦的图片比模糊的好。AI 无法添加源图中不存在的细节。
- 构图:主体清晰、构图良好的图片变换效果更好。杂乱的场景会让变换模型"困惑"。
- 曝光:曝光正确、光线充足的图片能给 AI 提供准确的色彩和深度信息。
什么样的源图要避免:
- 严重压缩、可见 JPEG 伪影的图片
- 带有 UI 元素或文字叠加的截图
- 小于 512x512 像素的图片
- 过暗或过曝的照片
第二步:描述你想要的变换
写一段文字提示词,描述你想要的变换方向——不是描述你上传的图片。AI 已经看到了你的图片,你的提示词应该描述"要改变什么"。
有效提示词示例:
风格迁移:
Transform into a vibrant oil painting with thick impasto brushstrokes.
Rich, saturated colors. Impressionist style with visible texture.
Warm golden lighting. Painterly quality.(转化为鲜艳的油画,厚涂笔触。浓郁的饱和色彩。印象派风格,可见纹理。温暖金色光线。绘画质感。)
画质增强:
Enhance to professional quality. Sharpen details, improve lighting,
add subtle depth of field. Clean, crisp focus on the subject.
Professional studio lighting quality.(提升至专业品质。锐化细节、改善光线、添加柔和景深。主体清晰对焦。专业影棚光照质量。)
风格重塑:
Restyle as a cyberpunk neon scene. Add neon pink and teal lighting.
Wet reflective surfaces. Futuristic holographic elements in the
background. Dark atmosphere with vibrant accent lights.(重塑为赛博朋克霓虹场景。添加霓虹粉和青色光线。湿润反光表面。背景中加入未来全息元素。暗色氛围搭配鲜艳点缀光。)
核心原则: 描述目的地,而非旅程。说清结果应该是什么样子,而不是要执行什么操作。
第三步:调整参数
配置变换参数:
| 参数 | 建议值 | 控制什么 |
|---|---|---|
| 强度/去噪 | 从 0.5 开始 | 输出与源图的偏离程度。低 = 细微,高 = 剧烈 |
| 风格预设 | 匹配你的目标 | 预配置的美学方向(写实、动漫、油画等) |
| 宽高比 | 匹配源图或目标 | 输出尺寸。除非你需要特定视频比例,否则匹配源图 |
进阶技巧: 第一次生成用中等强度(0.5)。如果结果和原图太像,提高到 0.6--0.7。如果变化过大,降到 0.3--0.4。通常两次迭代就能找到最佳点。
第四步:生成与迭代
点击生成,审视结果。按以下标准评估:
- 变换是否匹配你预期的风格?
- 原图的关键元素(主体、构图)是否被保留?
- 图片质量是否满足你的用途需求?
- 是否有伪影、变形或不想要的改变?
常见调整:
- 太细微? 强度加 0.1,重新生成
- 丢失了原始构图? 降低强度,在提示词中更具体地说明要保留什么
- 风格不对? 调整提示词措辞,更明确描述目标美学
- 面部或手部有伪影? 尝试更低的强度设置或简化提示词
经过 2--3 次迭代,你就能获得符合创意目标的精致变换结果。
第五步(可选):用作视频首帧
这是 Seedance 的独特优势。当你获得满意的变换图片后,可以一键将其直接转入图生视频。这张图片成为 AI 生成视频的第一帧。
为什么这个工作流强大:
- 从任何图片起步——手机照片、草稿、AI 生成的初稿
- 用图生图将其变换为精致的电影级参考帧
- 直接发送到视频生成,无需下载或重新上传
- 视频继承你精心打磨的参考帧的视觉质量和风格
这种连贯的流程使 Seedance 成为同时在图片和视频领域创作的创作者的最佳选择。没有其他平台提供这样无缝的衔接。
图生图在视频制作中的应用
图生图 AI 不只是图片编辑工具。对视频创作者来说,它是决定你的 AI 视频成品是业余还是专业的准备阶段。以下是三个最有价值的视频相关工作流。
准备参考帧
视频参考帧的质量设定了视频质量的天花板。图生视频模型的输出无法超越输入帧的质量。如果你的参考帧模糊、光线差、风格不统一,生成视频的每一帧都会继承这些问题。
图生图通过让你把任何素材打磨为视频级参考帧来解决这个问题:
- 从粗糙草稿出发:将铅笔概念草图变换为完整渲染的精致插画,作为干净的视频首帧
- 从手机照片出发:将随手一拍提升到专业品质,改善光线、锐度和色彩分级
- 从 AI 生成的初稿出发:修复文生图输出中的瑕疵(变形的手、不自然的光线、构图问题),再送入视频生成
- 从不同风格出发:将写实照片重塑为电影级画质,加入合适的调色、景深和氛围感
工作流: 源图 → 图生图变换 → 精致参考帧 → 图生视频 → 专业视频片段。
创建首尾帧
AI 视频生成中最强大的技巧之一是同时提供首帧和尾帧。视频模型生成两帧之间的平滑运动过渡。这让你能同时控制视频的起始状态和结束状态。
图生图是创建匹配帧对的最快方式:
- 生成或选择首帧——场景的起始状态
- 用图生图从首帧创建尾帧,施加想要的变化:一扇门打开、光线从白天变到夜晚、一个人转头、树叶从树上飘落
- 将两帧送入视频生成——AI 产出两个状态之间的平滑运动
示例: 首帧展示黎明时分的花苞。用图生图(中等强度,提示词:"The flower is now fully bloomed, warm midday sunlight, petals spread open"——花朵已经完全绽放,温暖的正午阳光,花瓣舒展)创建展示盛开花朵的尾帧。视频模型生成这两个状态之间的绽放运动。
详细教程请看 AI 视频首尾帧指南。
跨视频的风格一致性
制作系列视频(品牌宣传片、教育系列、社交媒体内容日历)时,视觉一致性非常重要。每个视频都应该有统一的视觉感——相同的色彩方案、相同的光影风格、相同的视觉处理。
图生图通过在视频生成之前对所有参考帧施加一致的风格变换来实现这一点:
- 定义你的目标视觉风格(例如"warm cinematic color grading, shallow depth of field, amber and teal palette"——温暖电影调色、浅景深、琥珀与青色色板)
- 用同样的提示词和强度设置处理每一张参考帧
- 所有帧现在共享同一个视觉处理
- 从这些风格统一的帧生成视频
结果:一组视觉统一的系列视频,即使源图来自不同相机、不同光照条件或不同的 AI 文生图生成。
图片工作流与视频生成的完整衔接指南,请看 AI 图片转视频工作流指南。

视频首帧准备流程:粗糙源图通过图生图变换为精致参考帧,再成为专业级AI视频。
8 个图生图提示词实战示例
以下 8 个提示词覆盖最常见的变换类型。每个都包含输入场景、提示词文本和预期效果说明。
1. 照片转油画(风格迁移)
输入: 一张乡村风景照——连绵的绿色丘陵、一座农舍、多云的天空。
提示词:
Transform into a rich oil painting in the style of the Dutch Golden Age.
Thick impasto brushstrokes visible in the clouds and grass. Deep,
saturated earth tones -- ochre, burnt sienna, forest green. Dramatic
chiaroscuro lighting with strong shadow contrast. Museum-quality
classical painting aesthetic. Visible canvas texture.(转化为荷兰黄金时代风格的浓郁油画。云朵和草地中可见厚涂笔触。深沉饱和的大地色——赭石、焦赭、森林绿。戏剧性明暗对照光线,强烈阴影对比。博物馆级古典绘画美学。可见画布纹理。)
预期效果: 照片的构图被保留——同样的山丘、农舍、天空排列。但每个表面都以绘画笔触呈现,色彩方案偏向温暖大地色,光线变得更具戏剧性。图片看起来像属于一座美术馆。
2. 草稿转精致插画(增强)
输入: 一张粗糙的铅笔草稿——一个持剑披斗篷的奇幻战士角色,基本比例和姿态已定义。
提示词:
Render as a polished digital illustration with full color and detail.
Professional concept art quality. Detailed armor with metallic
reflections. Flowing cape with realistic fabric physics. Dramatic
rim lighting from behind. Rich fantasy color palette -- deep
blues, golds, and crimson. Sharp, clean linework with painterly
rendering. ArtStation trending quality.(渲染为带有完整色彩和细节的精致数字插画。专业概念艺术品质。带金属反光的精致铠甲。具有真实织物物理感的飘逸斗篷。来自身后的戏剧性轮廓光。丰富的奇幻色板——深蓝、金色和深红。清晰干净的线条搭配绘画级渲染。ArtStation热门品质。)
预期效果: 粗糙草稿变成专业级的全色彩角色插画。草稿中的姿态和比例被保留,但每个表面都有了材质、光影和色彩。对概念艺术家快速可视化粗略创意非常实用。
3. 白天场景转夜景(重新布光)
输入: 一张白天城市街景——明亮阳光、行人、店面。
提示词:
Transform to a night scene. Dark blue sky with stars visible.
Street lights and shop windows glow warm amber and yellow.
Neon signs cast colorful reflections on wet pavement. Car
headlights create light trails. Deep shadows between buildings.
Atmospheric haze around light sources. Moody, cinematic night
photography quality.(转化为夜景。深蓝色天空,星星可见。街灯和橱窗发出温暖的琥珀和黄色光芒。霓虹灯牌在湿润路面投下彩色倒影。汽车头灯产生光轨。建筑之间深沉的阴影。光源周围有大气光晕。沉郁的电影级夜景摄影品质。)
预期效果: 同样的街道构图,但天空变暗,自然日光被人造光源取代,阴影深沉而富有戏剧性,整体氛围从明亮休闲变为沉郁而有氛围感。场景结构不变——同样的建筑、透视、街道布局。
4. 随拍照转专业头像(增强)
输入: 一张普通自拍或随手拍——尚可但不专业。典型手机相机光线和背景。
提示词:
Enhance to professional headshot quality. Soft, flattering studio
lighting with key light from the upper left. Subtle fill light to
reduce harsh shadows. Clean, softly blurred background. Professional
skin tone rendering -- natural but refined. Slight color grading
for warmth. Sharp focus on eyes. Shallow depth of field. Corporate
portrait photography quality.(提升至专业头像品质。来自左上方主光的柔和讨喜影棚光线。微妙补光减弱硬阴影。干净的柔和虚化背景。专业肤色渲染——自然但精致。微暖色彩分级。眼睛锐利对焦。浅景深。企业肖像摄影品质。)
预期效果: 人物的面部和姿态被保留,但光线变成影棚级,背景变得平滑虚化,肤色均匀而讨喜,整体品质如同专业摄影师的肖像作品。
5. 真实照片转动漫风格(风格迁移)
输入: 一张年轻人站在公园中的照片,背景有樱花树,休闲装扮。
提示词:
Transform into Japanese anime art style. Large expressive eyes,
clean linework, cel-shaded coloring. Soft pastel color palette
with pink cherry blossom accents. Gentle warm lighting with subtle
lens flare. Background rendered in a softer, more impressionistic
anime style. Character proportions adjusted to anime aesthetic.
Studio Ghibli meets modern anime quality. Beautiful and ethereal.(转化为日本动漫艺术风格。大而传神的眼睛,干净线条,赛璐璐上色。柔和粉彩色板搭配粉色樱花点缀。温柔的暖色光线带微妙光晕。背景以更柔和、更印象派的动漫风格渲染。角色比例调整为动漫美学。吉卜力与现代动漫品质的融合。唯美空灵。)
预期效果: 场景依然可辨识——同样的公园、同一个人(动漫化版本)、同样的樱花背景。但每个元素都以动漫风格渲染——干净线条、平涂色彩加细腻阴影、大而传神的眼睛、日本动画艺术特有的温暖感。
6. 低分辨率转高分辨率(超分辨率)
输入: 一张小尺寸、像素化的图片(如 256x256 或 512x512)——可能是网站缩略图或裁剪过度的照片。
提示词:
Enhance to ultra-high resolution. Add fine detail to all surfaces
-- skin pores, fabric texture, hair strands, environmental detail.
Sharpen edges while maintaining natural softness where appropriate.
Remove compression artifacts and noise. Professional photographic
quality with clean, crisp detail throughout. 4K quality output.(提升至超高分辨率。为所有表面添加精细细节——皮肤毛孔、织物纹理、发丝、环境细节。在保持适当自然柔和度的同时锐化边缘。去除压缩伪影和噪点。全画面清晰锐利的专业摄影品质。4K输出品质。)
预期效果: 图片分辨率四倍甚至更多提升。模糊区域变得清晰——能看到单根发丝、织物编织、皮肤纹理。压缩伪影消失。图片看起来像用高端相机拍摄,而非从低分辨率源提取。
7. 照片转视频级首帧(视频准备)
输入: 一张标准的城市环境人像照——构图不错但属于普通手机相机品质。
提示词:
Enhance to cinematic first-frame quality. Apply film-grade color
grading with warm highlights and cool shadows. Add subtle
atmospheric haze in the background. Shallow depth of field with
creamy bokeh. Professional lighting enhancement -- add a warm rim
light on the subject. Slight film grain for texture. Anamorphic
widescreen aesthetic. Ready for cinematic video production.(提升至电影级首帧品质。施加胶片级调色——暖色高光、冷色阴影。背景添加微妙大气雾气。浅景深配奶油般虚化。专业灯光增强——为主体添加温暖轮廓光。微妙胶片颗粒增加质感。变形宽银幕美学。适合电影级视频制作。)
预期效果: 照片被提升至电影品质——如同胶片画面般的调色、增强的景深、大气元素和专业光线。图片现在可以作为完美的图生视频首帧,为每一个后续生成帧设定视觉标准。
8. 首帧转尾帧变体(视频叙事)
输入: 一张黄金时段的室内场景——一位女性站在窗前,温暖阳光透过窗帘照入。
提示词:
Same scene, but now during blue hour. The warm golden sunlight
has faded to deep blue twilight. The room is lit by warm interior
lamps instead of sunlight. The woman has turned slightly to look
away from the window. Curtains are now still (no wind). Cool blue
tones dominate outside, warm amber tones inside. Contemplative,
quieter atmosphere. Same composition and perspective.(同一场景,但现在是蓝色时段。温暖的金色阳光已消退为深蓝暮色。房间由温暖的室内灯照亮而非阳光。女性微微转身不再看窗外。窗帘静止不动。室外冷蓝色调主导,室内温暖琥珀色调。沉思、安静的氛围。保持同样的构图和透视。)
预期效果: 构图和房间完全相同,但光线从黄金时段变成蓝色时段。窗户透入的温暖阳光被室外冷蓝暮色和室内温暖灯光取代。这成为视频的尾帧——视频模型生成从黄金时段到蓝色时段的平滑时间流逝。
5 个常见错误及避免方法
基于对多个图生图平台的大量测试,以下是用户最常犯的 5 个错误——以及直接有效的修正方法。
1. 变换强度设得太高
错误: 第一次尝试就把去噪强度设到 0.8 或更高,期望获得戏剧性变换。
为什么失败: 在高强度下,AI 有太多偏离源图的自由度,本质上是在创建一张受原图松散启发的新图。你会丢失构图、主体细节、面部特征和结构元素——而这些正是你选择这张源图的原因。
修正: 从 0.5 开始,每次迭代增加 0.05--0.1。找到变换足够有趣但又不丢失原图身份的那个点。风格迁移通常 0.4--0.6 最佳。细微增强 0.2--0.35 效果最好。
2. 提示词和源图矛盾
错误: 上传一张海滩照片,提示词写"snowy mountain landscape with pine forests"(雪山松林景观)。或者上传一张人像,提示词写"vast empty desert with no people"(空旷无人的沙漠)。
为什么失败: 文字提示词和源图把模型拉向相反方向。模型试图在矛盾信号之间妥协,产出混乱的、伪影严重的结果——面部可能出现在风景中,建筑可能扭曲成不可能的形状,整体效果既不像源图也不像提示词描述的。
修正: 写修改或重塑现有图片的提示词,而不是试图替换整个场景。"海滩场景" + "transform to sunset lighting with dramatic clouds"(变换为日落光线配戏剧性云层)可以。"海滩场景" + "make this a snowy mountain"(把这变成雪山)不行。如果你需要一个完全不同的场景,用文生图。
3. 期望像素级精确编辑
错误: 期望图生图做出像素级的精确编辑——比如移除衬衫上某个特定纽扣,或改变某个小物体的精确色调。
为什么失败: 图生图 AI 是生成式的,不是手术式的。它在提示词引导下重新生成图片区域。精细编辑可能影响周围区域,在邻近元素上引入微妙变化,或无法精确命中目标。它是创意工具,不是像素编辑器。
修正: 对特定区域的精确编辑,使用带有明确遮罩选择的专用局部编辑工具,而非全图变换。对广泛的风格变化,全图 img2img 是合适的。根据你需要的精度级别选择合适的工具。如果需要像素级精确编辑,将 AI 与 Photoshop 等传统编辑工具结合使用。
4. 使用过低分辨率的源图
错误: 上传一张 200x200 的缩略图、重度裁剪的图片或视频截图,期望获得高质量输出。
为什么失败: 编码器从源图中提取信息。如果可用信息极少(像素少、压缩伪影重、没有精细细节),模型能利用的就很有限。AI 超分辨率预处理有帮助,但它添加的是插值像素,不是真实的视觉信息。结果会继承源图的局限性。
修正: 始终使用你能获取到的最高分辨率版本。最低 512x512 像素,推荐 1024x1024 以上。如果只有小图,先用专门的 AI 超分辨率工具(Real-ESRGAN、Topaz Gigapixel)做预处理,再进行图生图变换。
5. 忽视文字提示词的重要性
错误: 上传了一张很好的源图,但提示词写得模糊或极简——"make it better"(把它变好)或"improve this image"(改善这张图)。
为什么失败: 文字提示词为变换提供方向性引导。模糊的提示词给不了模型明确方向,于是它做出随机改变——轻微偏移色彩、添加随机纹理、或产出与输入几乎一样的结果。模型不知道没有具体指导的"更好"是什么意思。
修正: 明确说明你想改变什么。不要写"make it better",而要写"enhance sharpness, improve contrast, add warm color grading with golden highlights and cool shadow tones, increase depth of field blur in the background"(增强锐度,提升对比度,添加温暖调色——金色高光和冷色阴影,增加背景景深虚化)。具体的提示词产出具体、可预期的结果。提示词编写指南请参考 AI 图片提示词生成器指南。
常见问题
什么是图生图 AI?
图生图 AI 是一种以已有图片为输入、根据你的指令生成修改版本的技术。你上传照片、草稿或插画,提供一段描述目标变化(风格迁移、增强、编辑、重塑)的文字提示词,AI 产出变换后的图片。与文生图(从零创建图片)不同,图生图以你的视觉参考为起点,保留你想保留的部分,改变你想改变的部分。
图生图和文生图有什么区别?
文生图从文字描述创建全新图片,AI 自行决定构图、色彩、主体外观和所有视觉细节。图生图从已有图片出发进行修改,源图提供构图和视觉基础,文字提示词提供变换方向。需要从无到有创建东西时用文生图,已有视觉起点并想精修、重塑或增强时用图生图。文生图完整指南请看 文生图 AI 完全指南。
可以只编辑图片的一部分吗?
可以,通过局部编辑(Inpainting)。局部编辑让你选择(涂抹遮罩)图片的特定区域,只修改那个区域,其余部分不动。你可以移除不想要的物体、更换背景、改变服装颜色、修正面部特征、或添加新元素——全部在目标区域内完成。大多数图生图平台将局部编辑作为独立模式提供。编辑质量取决于工具和改变的复杂度。简单的物体移除效果可靠,复杂的结构性改变(如站姿改坐姿)不太可预测。
哪个图生图 AI 工具最好?
取决于你的工作流。Seedance 最适合打算把变换图片用作 AI 视频参考帧的用户——图生视频流程无缝衔接。Stable Diffusion 最适合想对每个参数做极致控制的技术用户。通义万相最适合中文内容创作和国风项目。文心一格在中国传统美学领域有独特优势。Adobe Firefly 最适合 Adobe 生态内的商业制作。Midjourney 产出最惊艳的美学变换。DALL-E 3 最适合用日常语言描述编辑的普通用户。完整工具对比请看 2026 年最佳 AI 图片生成器。
图生图 AI 免费吗?
多个平台提供免费使用(有限制)。Seedance 为新用户提供免费积分,足够测试图生图和视频工作流。通义万相免费额度充足,适合日常创作。文心一格提供每日免费额度。DALL-E 3 可通过 ChatGPT 免费版使用。Stable Diffusion 如果在本地硬件上运行则完全免费开源(需要 GPU)。Kolors(快手可图) 也是开源免费的。对于日常高频使用,任何平台的付费方案都提供更多生成次数、更高质量和更多功能。免费版最适合测试和轻度使用。
可以用图生图准备视频参考帧吗?
完全可以。这是图生图 AI 最有价值的应用之一。你可以把任何图片——粗糙草稿、手机照片、AI 生成的初稿——变换为适合视频生成的精致电影级参考帧。调整光影、调色和风格以匹配你的目标视频美学,然后把变换后的图片直接送入图生视频。Seedance 通过集成的图生视频转移功能让这个流程特别顺滑。
源图对输出的影响有多大?
由强度/去噪参数控制。低强度(0.1--0.3)时源图主导——输出与输入非常相似,只有微调。中等强度(0.4--0.6)时获得平衡——构图保留但视觉风格明显改变。高强度(0.7--0.9)时文字提示词主导,源图仅作为松散指导。最大强度(1.0)时源图基本被忽略。从 0.5 开始,根据效果调整。
图生图 AI 能放大低分辨率图片吗?
能。AI 超分辨率是图生图的核心能力之一。与传统放大(简单插值像素、结果模糊)不同,AI 超分辨率会生成新的视觉细节。模型根据图片上下文推断应该存在什么精细细节——添加逼真的纹理、锐度和微观细节,这些在原始低分辨率源图中并不存在。从中等分辨率(512x512)放大到高分辨率(2048x2048)时效果最令人惊叹。从极低分辨率(256x256 以下)放大效果不太可靠,因为可供 AI 参考的信息太少。
开始变换你的图片
图生图 AI 是 2026 年最实用的 AI 创作工具。它不要求你从零精通提示词工程——你从一张现有图片出发,描述你想要的改变。学习曲线比文生图更平缓,结果更可预期,因为 AI 有一个具体的视觉参考可以依据。
无论你需要为品牌一致性重塑照片风格、将低分辨率图片增强到专业级、为视频生成准备参考帧,还是想用现有的视觉素材库探索创意可能性——图生图 AI 都能胜任。
清晰的行动路径:
- 先用图生图变换和精修你的图片
- 需要从零创建时用文生图
- 把两者都接入图生视频,构建完整创作链路
试用 Seedance 图生图 --> —— 上传任意图片,几秒内看到变换结果。免费积分,无需绑定信用卡。
文字生成图片 --> —— 需要从文字描述生成全新图片时使用。
图片转视频 --> —— 把变换后的图片生成电影级视频片段。
生成完美提示词 --> —— 用 AI 为任何图片生成任务编写优化提示词。
延伸阅读:文生图 AI 完全指南 | 2026 年最佳 AI 图片生成器 | AI 图片提示词生成器指南 | 图生视频 AI 指南 | AI 视频首尾帧指南 | AI 图片转视频工作流指南
