
Auf einen Blick
Text-to-Video-KI ist eine Technologie der künstlichen Intelligenz, die automatisch Videos aus Textbeschreibungen generiert. Geben Sie eine Erzählung ein, und die KI erstellt einen Videoclip mit Bewegungen, Lichteffekten und Kamerabewegungen. Bis 2026 hat sich diese Technologie unter Verwendung der Diffusion Transformer (DiT)-Architektur von einem vagen experimentellen Prototyp zu einer nahezu kinoreifen Qualität entwickelt. Dieser Leitfaden behandelt die technischen Grundlagen, ein praktisches Tutorial in fünf Schritten, zehn reproduzierbare Prompt-Vorlagen, eine vergleichende Analyse von acht Tools, sechs wichtige Anwendungsszenarien und die tatsächlichen Einschränkungen, die Sie verstehen müssen.Erleben Sie die Text-zu-Video-Generierung kostenlos →

Text-zu-Video-KI: Von einer einzigen Beschreibung zu Filmmaterial in Kinoqualität – KI macht „Text-zu-Video“ zur Realität.
Was ist Text-zu-Video-KI?
Text-zu-Video-KI bezeichnet eine Kategorie der künstlichen Intelligenz, die automatisch Videoinhalte aus Textbeschreibungen generiert. Sie beschreiben eine Szene – eine Frau, die im Regen spazieren geht, ein Produkt, das sich auf einem Ausstellungsständer dreht, eine Drohne, die über Bergketten fliegt – und das KI-Modell erzeugt einen äußerst realistischen Videoclip mit natürlichen Bewegungen, Beleuchtung und physikalischen Effekten.
Das Kernkonzept ist einfach: Texteingabe, Videoausgabe. Die zugrunde liegende Technologie ist jedoch alles andere als einfach. Moderne Text-zu-Video-Systeme verwenden neuronale Netze, die mit Milliarden von gepaarten „Video-Text”-Datensätzen trainiert wurden und die statistischen Beziehungen zwischen sprachlichen Beschreibungen und visuellen Bewegungen lernen. Wenn Sie „Eine Katze springt auf einen Tisch” schreiben, greift das Modell auf sein gesammeltes Wissen über Katzen, die Physik des Springens, Tischoberflächen und die Schwerkraft zurück, um ein plausibles Video zu generieren.
2026: Vom Experiment zum Produktivitätswerkzeug
Die Text-zu-Video-KI hat 2025–2026 die Schwelle zur „produktionsreifen“ Leistungsfähigkeit überschritten. Frühe Systeme aus den Jahren 2022–2023 konnten nur kurze, unscharfe und physikalisch unrealistische Clips produzieren. Die heutigen Modelle generieren jedoch Videos mit einer Auflösung von 2K, physikalisch korrekten, natürlich animierten Bewegungen und kinoreifer Qualität, die 5–15 Sekunden lang sind. Dieser Sprung verwandelt Text-zu-Video von einer Kuriosität der Forschung in ein praktisches Werkzeug:
- Content-Ersteller: Erwerben Sie B-Roll-Material, Intro-Sequenzen und Social-Media-Assets ohne Kamera
- Vermarkter: Produzieren Sie in großem Umfang verschiedene Werbungsvarianten und Produktdemonstrationen
- Pädagogen: Visualisieren Sie abstrakte Konzepte
- Kleine und mittlere Unternehmen: Vermeiden Sie die hohen Kosten einer professionellen Videoproduktion
- Jeder: Wenn Sie schreiben können, können Sie auch Videos erstellen
Die Schwelle für die Erstellung von Videos hat sich von „eine Kamera besitzen und wissen, wie man Videos bearbeitet“ zu „eine überzeugende Beschreibung verfassen“ gesenkt.
Technologische Entwicklung: Von GAN zu DiT
Wenn Sie die zugrunde liegende Technologie verstehen, können Sie bessere Eingabeaufforderungen erstellen und geeignetere Tools auswählen. Nachfolgend finden Sie die technologische Entwicklung der Text-zu-Video-KI über drei Generationen hinweg.

Drei Generationen technologischer Entwicklung: GANs (2020–2022) → Diffusionsmodelle (2023–2024) → Diffusionstransformatoren / Diffusionsbasierte Bildgenerierung (2025–2026).
Erste Generation: Die GAN-Ära (2020–2022)
Generative Adversarial Networks (GANs) waren die erste Architektur, die die Machbarkeit der „Text-zu-Video“-Konvertierung demonstrierte. Zwei neuronale Netze durchlaufen ein adversariales Training – der Generator erstellt Videobilder, während der Diskriminator deren Authentizität beurteilt. Die Ergebnisse waren jedoch von geringer Auflösung (256×256), kurzer Dauer (2–4 Sekunden) und physikalisch unplausibel. Objekte unterliegen unvorhersehbaren Verformungen, Gesichtszüge werden verzerrt und die zeitliche Konsistenz ist stark beeinträchtigt. Zu den repräsentativen Errungenschaften gehören CogVideo und NUWA.
Zweite Generation: Die Ära der Diffusionsmodelle (2023–2024)
Das Diffusionsmodell hat die Landschaft grundlegend verändert. Es verwendet kein adversariales Training mehr, sondern lernt einen „Reverse-Denoising“-Prozess – ausgehend von reinem Rauschen wird dieses unter textueller Anleitung schrittweise zu einem kohärenten Video bereinigt. Dieser Ansatz sorgt für einen qualitativen Sprung: höhere Auflösung (bis zu 1080p), längere Dauer (4–10 Sekunden) und verbesserte textuelle und visuelle Ausrichtung.
OpenAI's Sora (veröffentlicht im Februar 2024) hat gezeigt, dass Diffusionsmodelle erstaunlich fotorealistische Videos erzeugen können. Runway Gen-2/Gen-3, Pika und Stable Video Diffusion gehören alle zu dieser Generation.
Dritte Generation: DiT – Diffusionstransformator (2025–2026)
Die derzeit fortschrittlichsten Architekturen kombinieren Diffusionsprozesse mit der Transformer-Architektur (derselben Architektur, die auch hinter GPT und BERT steht). DiT-Modelle verarbeiten Videos als eine Abfolge von räumlich-zeitlichen Patches und erreichen damit Folgendes:
- Verbesserte zeitliche Konsistenz: Transformatoren eignen sich hervorragend für die Modellierung von Langstreckenabhängigkeiten über Frames hinweg
- Höhere Auflösung: Native 2K-Ausgabe (Seedance 2.0 erreicht 2048×1080)
- Verbesserte physikalische Genauigkeit: Realistischere Bewegungen, Schwerkraft und Strömungsdynamik
- Besseres Textverständnis: Deutlich verbesserte Übereinstimmung zwischen Prompt-Beschreibungen und visuellen Ausgaben
- Multimodale Eingabe: Bestimmte DiT-Modelle können gleichzeitig Bild-, Video- und Audioeingaben akzeptieren
Seedance 2.0, Google Veo 3 und Keeling 3.0 nutzen alle die DiT-Architektur. Aus diesem Grund weist die Text-zu-Video-Generierung im Jahr 2026 einen qualitativen Unterschied zu der von 2024 auf.
Text-zu-Video vs. Bild-zu-Video
Diese beiden Ansätze ergänzen sich eher, als dass sie miteinander konkurrieren:
| Dimension | Text-zu-Video (T2V) | Bild-zu-Video (I2V) | |------|------------------|----------------- -| | Eingabe | Nur Textbeschreibung | Foto + Bewegungsbeschreibung | | Kreative Freiheit | Höchste — KI bestimmt alle visuellen Elemente | Durch Quellbild eingeschränkt | | Kontrollierbarkeit | Geringer — Abhängig von der Genauigkeit der Eingabeaufforderung | Höher — Visuelle Anker verfügbar | | Geeignete Szenarien | Konzeptfindung, originelle Inhalte | Produktpräsentation, Fotoanimation, Stilabstimmung | | Vorhersagbarkeit | Gering – Gleiche Eingabe führt zu unterschiedlichen Ergebnissen | Hoch – Ausgabe entspricht konsistent dem Ausgangsbild |
Die meisten professionellen Arbeitsabläufe nutzen beide Ansätze: Zunächst wird T2V eingesetzt, um kreative Konzepte zu erforschen, anschließend wird das Ergebnis mit I2V verfeinert. Eine detaillierte Erläuterung der Bild-zu-Video-Generierung finden Sie in unserem Image-to-Video AI Complete Guide.
5-Schritte-Anleitung: Erstellen Sie Ihr erstes KI-Video
Im Folgenden finden Sie eine Schritt-für-Schritt-Anleitung zur Erstellung von Text-zu-Video-Inhalten von Grund auf, wobei Seedance 2.0 als Demonstrationsplattform dient. Die zugrunde liegenden Prinzipien gelten für jedes Tool.

Von der schnellen Erstellung bis zur endgültigen Ausgabe: Fünf Schritte zur Fertigstellung Ihres ersten KI-Videos.
Schritt 1: Definieren Sie die Ziele des Videos.
Bevor Sie die Eingabeaufforderung schreiben, legen Sie zunächst Folgendes fest:
- Typ: B-Roll-Material, Produktvorführungen, Social-Media-Inhalte, künstlerische Kreationen oder Erzählungen?
- Dauer: 5 Sekunden für Tests, 10–15 Sekunden für die endgültige Ausgabe
- Seitenverhältnis: 16:9 für YouTube/Bilibili, 9:16 für Douyin/Kuaishou/ Xiaohongshu, 1:1 für WeChat Moments
- Stil: Filmisch, dokumentarisch, Animation, Werbung oder künstlerisch
Durch die Festlegung klarer Ziele wird verhindert, dass Generationsquoten für unklare Experimente verschwendet werden.
Schritt 2: Erstellung hochwertiger Textvorlagen
Die Eingabeaufforderung ist das Wesentliche der Text-zu-Video-Erstellung. Verwenden Sie die folgende Formel:
[Thema] + [Handlung/Bewegung] + [Kulisse] + [Stil] + [Kamerabewegung] + [Beleuchtung]
Schlechte Eingabeaufforderung: „Ein rennender Hund“
Gute Eingabeaufforderung: „Ein Golden Retriever rennt über eine sonnenbeschienene Wiese, Wildblumen wiegen sich im Wind. Das Fell des Hundes bewegt sich bei jedem Schritt. Die Kamera folgt ihm in Bodennähe. Warmes Licht der goldenen Stunde mit langen Schatten. Filmische geringe Schärfentiefe, 4K-Qualität.“
Grundprinzipien:
- Bewegungen müssen konkret beschrieben werden: „dreht langsam den Kopf“ statt „dreht sich“
- Kamerabewegungen beschreiben: „Kamera schwenkt heran“ oder „Luftaufnahme mit Drohne“
- Atmosphäre schaffen: Beleuchtung, Farbkorrektur, Ambiente
- Widersprüche vermeiden: Fordern Sie nicht gleichzeitig „schnelle Action“ und „Zeitlupe“
- Keine Texte/Benutzeroberflächen anfordern: Das aktuelle Modell hat Schwierigkeiten, lesbaren Text in Videomaterial darzustellen.
Hinweis: Es ist ratsam, Eingabeaufforderungen auf Englisch zu verfassen, auch wenn Sie inländische Tools (wie KeLing, TongYi WanXiang oder Hunyuan Video) verwenden. Der Grund dafür ist, dass die meisten Modelle mit umfangreicheren englischsprachigen Datensätzen trainiert wurden.
Ein umfassenderes System für Prompt-Techniken finden Sie unter Prompt Writing Guide und 10 Truly Effective AI Video Prompts.
Schritt 3: Werkzeuge und Parameter auswählen
Wählen Sie eine Plattform aus (siehe Vergleichstabelle unten) und konfigurieren Sie dann:
- Modell: Verwenden Sie das neueste verfügbare Modell (z. B. Seedance 2.0, nicht 1.0)
- Auflösung: Mindestens 1080p; wenn verfügbar, 2K wählen
- Dauer: Testen Sie zunächst mit 5 Sekunden und verlängern Sie die Dauer, wenn das Ergebnis zufriedenstellend ist
- Seitenverhältnis: Passen Sie es an Ihre Vertriebsplattform an
- Seed-Wert (falls verfügbar): Sperren Sie den Seed für konsistente Iterationen
Schritt 4: Generieren und Überprüfen
Klicken Sie auf „Generieren“ und warten Sie 60 bis 180 Sekunden (je nach Tool). Achten Sie bei der Überprüfung der Ausgabe auf Folgendes:
- ✅ Entspricht die Bewegung der Beschreibung?
- ✅ Ist das Motiv durchgehend konsistent (keine Verzerrung)?
- ✅ Ist die Physik plausibel (Schwerkraft, Flüssigkeiten, Stoffe)?
- ✅ Ist die Kamerabewegung flüssig?
- ❌ Gibt es Artefakte, Flackern oder Verzerrungen?
- ❌ Gibt es einen Uncanny-Valley-Effekt bei Gesichtern/Händen?
Schritt 5: Iterative Optimierung
Der erste Versuch ist selten perfekt. Optimierungsmethoden:
- Passen Sie die Eingabeaufforderung an: Fügen Sie Details hinzu, bei denen die KI einen Fehler gemacht hat
- Ändern Sie jeweils nur eine Variable: Schreiben Sie nicht die gesamte Eingabeaufforderung neu
- Experimentieren Sie mit verschiedenen Seeds: Dieselbe Eingabeaufforderung kann zu völlig unterschiedlichen Ergebnissen führen
- Verlängern Sie die Dauer: Wenn Sie mit der 5-Sekunden-Version zufrieden sind, probieren Sie 10–15 Sekunden aus
- Fügen Sie Audio hinzu: Wenn das Tool dies unterstützt (Seedance, Veo 3), integrieren Sie Soundeffekte oder Hintergrundmusik

Beispiele für Prompt-Iterationen: V1 (Basis-Prompt) → V2 (Hinzufügen von Bewegungs- und Beleuchtungsbeschreibungen) → V3 (vollständige filmische Spezifikationen). Jeder Verfeinerungszyklus verbessert die Bildqualität erheblich.
10 Vorlagen für die Erstellung von Text-zu-Video-Inhalten
Die folgenden Vorlagen können kopiert und direkt verwendet werden. Sie wurden mit Seedance 2.0 getestet und sind mit den meisten gängigen Plattformen kompatibel.
1. Filmisches Porträt
A close-up of a young woman with flowing dark hair, her face illuminated by warm golden hour sunlight filtering through a window. She slowly turns her head toward the camera, a subtle smile forming. Soft bokeh background of a cozy interior. Camera holds steady with a slight push-in. Warm amber lighting, shallow depth of field, 4K cinematic quality.
Geeignete Szenarien: Soziale Medien, persönliches Branding, künstlerisches Schaffen
- Produktpräsentation
A sleek wireless headphone rotating slowly on a matte black pedestal. Soft studio lighting creates clean highlights on the brushed metal surface. Camera orbits 180 degrees at eye level. Minimalist white background, no shadows. Smooth continuous motion, commercial product photography quality.
Geeignete Szenarien: E-Commerce-Produktdetailseiten, Produktmarketing, Taobao/JD.com-Hauptbildvideos
- Naturfilm
An epic aerial drone shot over a misty mountain valley at sunrise. Golden light breaks through layered clouds, illuminating a winding river below. Camera pushes forward slowly, revealing the vast landscape. Volumetric fog drifts between peaks. IMAX cinematography quality, hyper-detailed.
Geeignet für: YouTube-/Bilibili-Intro-Videos, Reiseinhalte, Bildschirmschoner, Meditationskanäle
4. Stadtstraße
A neon-lit Tokyo alley at night after rain. Wet cobblestones reflect vivid pink, teal, and amber neon signs. A lone figure walks away from camera, umbrella in hand. Steam rises from a street vent. Camera follows at a distance, tracking shot. Film noir atmosphere, anamorphic lens flare.
Geeignete Szenarien: Musikvideos, atmosphärisches B-Roll-Filmmaterial, Inhalte im Cyberpunk-Stil
- Anime-Stil
An anime warrior princess with flowing silver hair stands on a cliff edge overlooking a fantasy kingdom. Her cape billows dramatically in the wind. She raises a glowing sword that emits blue energy particles. Cherry blossom petals drift past. Camera slowly orbits. Studio Ghibli meets Ufotable quality animation.
Geeignet für: Animierte Inhalte, Gaming-Kanäle, Fantasy-Erzählungen
6. Speisen und Getränke
Extreme macro close-up of rich dark coffee being poured in slow motion into a pristine ceramic cup. Individual droplets and tiny splashes frozen mid-air. Wisps of steam curl elegantly upward. Warm side lighting reveals the liquid's amber transparency. Cinnamon stick and scattered beans visible in soft focus foreground.
Geeignete Szenarien: Lebensmittel- und Getränkemarketing, Food-Blogger, Getränkewerbung
- Mode & Redaktion
A model in a flowing white silk gown walks confidently down a dark runway. Multiple flash strobes create sharp geometric light patterns. The fabric billows with perfect physics. Camera at a low angle, slight slow motion. High fashion editorial aesthetic, Vogue magazine quality.
Geeignete Szenarien: Modemarken, Beauty-Inhalte, redaktionelle Beiträge
- Science Fiction & Fantasy
A massive spaceship emerges from hyperspace above a ringed planet. Blue energy dissipates around the hull as the vessel decelerates. Tiny fighter escorts flank its sides. Camera pulls back to reveal the scale against the planet. Volumetric space dust and distant star field. Hollywood VFX quality.
Anwendbare Szenarien: Unterhaltungsinhalte, Science-Fiction-Kanäle, Konzeptvisualisierung
- Sport & Action
A basketball player at the peak of a slam dunk, frozen in mid-air. Time resumes in slow motion — sweat droplets fly, the ball compresses against the rim, arena spotlights create dramatic lens flare. Camera shoots from below looking up. ESPN broadcast quality, hyper-detailed.
Geeignete Szenarien: Sportinhalte, Sportmarken, Highlight-Zusammenfassungen
- Abstrakte Kunst (abstrakt & künstlerisch)
Liquid gold and deep indigo ink collide in slow motion inside a glass sphere. The fluids intertwine in mesmerizing fractal patterns. Tiny bubbles catch light. Camera slowly rotates around the sphere. Pure black background. Macro photography meets fluid dynamics simulation. Meditative, hypnotic pace.
Geeignete Szenarien: Hintergrundbilder, Musikvideos, Kunstinstallationen, Bildschirmschoner

Die tatsächliche Ausgabe von vier der zehn oben genannten Vorlagen – jede Eingabeaufforderung generiert aus einfachem Text einzigartig gestaltete Bilder in Kinoqualität.
Zusammenfassung 2026: 8 Text-zu-Video-Tools im Vergleich
Wir haben acht gängige Plattformen mit derselben Eingabe („Ein Golden Retriever rennt durch eine sonnenbeschienene Wiese, Wildblumen wiegen sich im Wind, filmreife 4K-Qualität“) getestet und sie in fünf Kategorien bewertet. Alle Tests wurden im Februar 2026 abgeschlossen.
| Tool | Maximale Auflösung | Maximale Dauer | Kostenlose Version | Audio | Beste Verwendung | Bildqualitätsbewertung | |------|----------|---------|--------|------|-------- -|---------| | Seedance 2.0 | 2K (2048×1080) | 15 Sekunden | ✅ Tägliches kostenloses Kontingent | ✅ Soundeffekte + Musik + Lippensynchronisation | Multimodale Erstellung | 9,2/10 | | Google Veo 3 | 4K (begrenzt) | 8 Sekunden | ✅ AI Studio-Kontingent | ✅ Native Audio | Audiovisuelle Fusion | 9,0/10 | | Sora 2 | 1080p | 20 Sekunden | ❌ Erfordert ChatGPT Plus | ❌ | Langtextgesteuertes Video | 8,8/10 | | Keling 3.0 | 1080p | 20+ Sekunden | ✅ Kostenlose Anmelde-Credits | ⚠️ Begrenzt | Lange Videos, gutes Preis-Leistungs-Verhältnis | 8,5/10 | | Runway Gen-4 | 1080p | 10 Sekunden | ✅ 125 Credits | ❌ | Professioneller Bearbeitungsworkflow | 8,5/10 | | Pika 2.0 | 1080p | 10 Sekunden | ✅ Tägliches Freikontingent | ⚠️ Nur Soundeffekte | Anfänger, spielerische Effekte | 8,0/10 | | Luma Dream Machine | 1080p | 5 Sekunden | ✅ Kostenlose Generierung | ❌ | 3D-Szenen, schnelle Iteration | 7,8/10 | | Snail AI (MiniMax) | 1080p | 6 Sekunden | ✅ Täglich kostenlos | ❌ | Schnellste Generierungsgeschwindigkeit | 7,5/10 |
Wichtiger Hinweis für Nutzer innerhalb Chinas: Seedance 2.0, KeLing 3.0 und Haier AI sind innerhalb Chinas direkt zugänglich. Für Sora 2 ist ein ChatGPT Plus-Abonnement erforderlich (VPN notwendig). Google Veo 3 erfordert den Zugriff über Google AI Studio (VPN erforderlich). Runway, Pika und Luma erfordern alle eine Netzwerkverbindung ins Ausland.
Inländische Alternativen: Tongyi Wanshang (Alibaba), Hunyuan Video (Tencent) und Qingying (Tochtergesellschaft von ByteDance) bieten ebenfalls Funktionen zur Text-zu-Video-Generierung mit unterschiedlichen kostenlosen Nutzungsquoten.
Wichtigste Schlussfolgerungen:
- Beste Gesamtbildqualität: Seedance 2.0 (native 2K + Quad-Modus-Eingang + Audio)
- Stärkste Audiofunktionen: Seedance 2.0 und Google Veo 3
- Beste kostenlose Version: Seedance 2.0 (kostenloser Zugriff auf 2K-Auflösung, keine Kreditkarte erforderlich)
- Längstes kostenloses Video: Keeling 3.0 (über 20 Sekunden)
- Am besten für Anfänger geeignet: Pika 2.0 (einfachste Benutzeroberfläche, lustige Effekte)
Einen detaillierteren Vergleich finden Sie unter Der vollständige Vergleich der besten KI-Videogeneratoren für 2026. Wenn Sie sich ausschließlich für kostenlose Angebote interessieren, lesen Sie bitte Ein Vergleichstest kostenloser KI-Videogeneratoren.
6 wichtige Anwendungsszenarien
- Inhalte in sozialen Medien
Erstellen Sie auffällige Kurzvideos für Douyin, Kuaishou, Xiaohongshu, Bilibili und YouTube Shorts. Dank KI entfallen Filmaufnahmen, Bearbeitung und Nachbearbeitung vollständig.
Empfohlene Spezifikationen: Seitenverhältnis 9:16, Dauer 5–15 Sekunden, mit einer visuell auffälligen Eröffnung innerhalb der ersten Sekunde.
- Marketing und Werbung
Produzieren Sie Werbematerialvarianten in großer Stückzahl. Testen Sie mehrere visuelle Konzepte mit unterschiedlichen Aufforderungen, bevor Sie sich auf das formelle Produktionsbudget festlegen. Erstellen Sie innerhalb weniger Minuten A/B-Testversionen.
Empfohlene Konfiguration: Kompatibilität mit mehreren Formaten auf verschiedenen Plattformen. In Kombination mit den Audiofunktionen von Seedance lassen sich komplette Werbefilme produzieren.
3. Aus- und Weiterbildung
Visualisierung abstrakter Konzepte, die schwer oder gar nicht zu erfassen sind: Molekülstrukturen, historische Ereignisse, mathematische Konzepte, wissenschaftliche Prozesse. KI-Videos machen das Unsichtbare sichtbar.
Empfohlene Konfiguration: Um optimale Lernergebnisse zu erzielen, verwenden Sie neben den Audioaufnahmen auch Hinweise, die die Konzepte genau beschreiben.
- Unterhaltung und Erzählung
Unabhängige Filmemacher und Geschichtenerzähler nutzen die Text-zu-Video-Technologie für die Konzeptvisualisierung, das Storyboarding und sogar für die endgültige Produktion von Kurzfilmen. Diese Technologie demokratisiert das Filmemachen.
Empfohlene Konfiguration: Geben Sie detaillierte Angaben zur Kamerarichtung und Beleuchtung in der Eingabeaufforderung an, um eine kinoreife Qualität zu erzielen.
- E-Commerce-Produktvideos
Verwandeln Sie Produktbeschreibungen in Produktdemonstrationsvideos. Dies ist besonders wertvoll für Einzelhändler mit Hunderten von Artikelnummern, die nicht für jedes Produkt ein eigenes Video drehen können. Ausführliche Informationen zu E-Commerce-Workflows finden Sie im AI E-Commerce Video Guide.
Empfohlene Spezifikationen: Produktfotografie mit Studiobeleuchtung. Seitenverhältnis 1:1 für Produktdetailseiten, 16:9 für YouTube/Bilibili, 9:16 für TikTok/Xiaohongshu.
6. Erstellung von Inhalten für YouTube/Bilibili
Erstellen Sie B-Roll-Material, Intro-Sequenzen, visuelle Kommentare und komplette Kurzvideos. Mit KI-Videotechnologie können Creator die Effizienz ihrer Content-Produktion steigern. Den vollständigen YouTube-Creator-Workflow finden Sie im AI Video YouTube Creator Guide.
Empfohlene Konfiguration: Sorgen Sie für eine einheitliche Optik aller Eingabeaufforderungen, um die Wiedererkennbarkeit Ihrer Marke zu stärken.
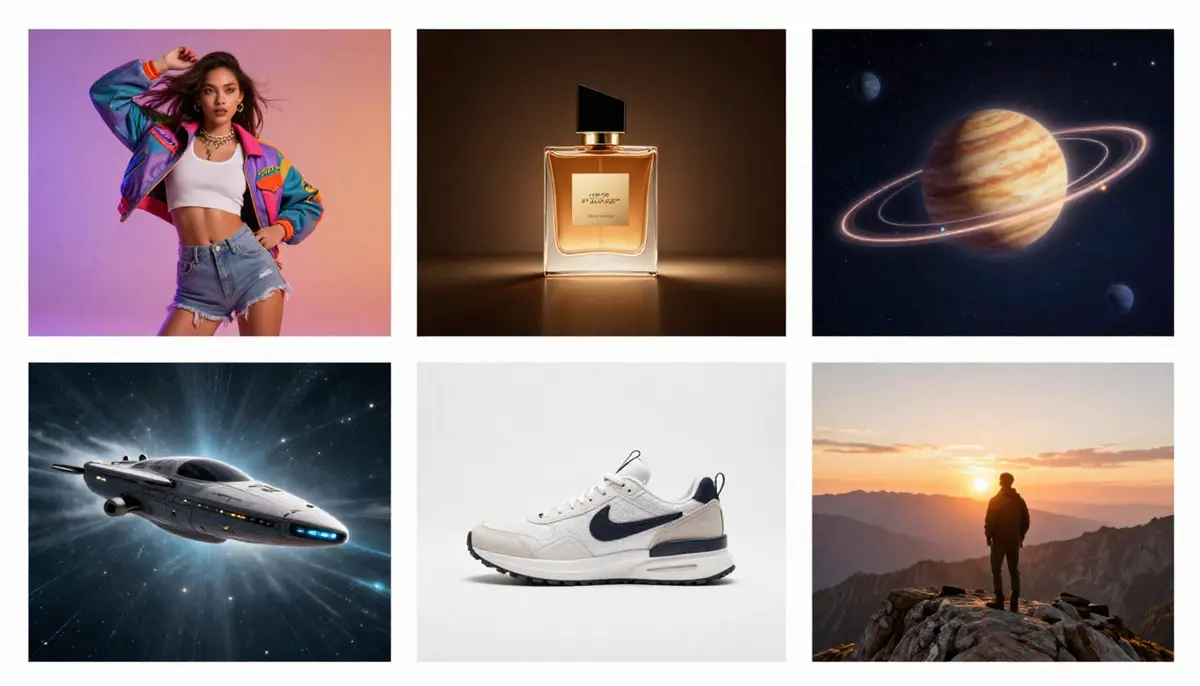
Sechs praktische Anwendungen von Text-zu-Video-KI: Von Social-Media-Kurzfilmen über Produktdemos im E-Commerce bis hin zur Visualisierung von Bildungskonzepten.
Text-zu-Video vs. Bild-zu-Video: Wann sollte man was nutzen?
Dies ist eine der häufigsten Fragen neuer Benutzer. Die Antwort hängt davon ab, welche Materialien Ihnen zur Verfügung stehen und was Sie benötigen.

Zwei Wege zur KI-Videoerstellung: Die Text-zu-Video-Erstellung beginnt mit geschriebenem Text, während die Bild-zu-Video-Erstellung mit vorhandenen Fotos beginnt.
Szenarien für Text-zu-Video (T2V): – Sie erstellen völlig neue Inhalte (keine Referenzbilder)
- Sie wünschen sich maximale kreative Freiheit
- Sie führen eine Konzeptfindung oder ein visuelles Brainstorming durch
- Sie benötigen abstrakte oder nicht fotografierbare Szenen (Science-Fiction, Fantasy, mikroskopisch/makroskopisch)
- Sie möchten schnell iterieren – eine Änderung der Eingabeaufforderung führt zu einer völlig anderen Szene
Szenarien für die Erstellung von Videos aus Bildern (I2V):
- Sie besitzen ein bestimmtes Foto, das dynamisch transformiert werden muss
- Sie benötigen eine Ausgabe, die genau zu den vorhandenen visuellen Effekten passt
- Sie konvertieren Produktbilder in Produktvideos
- Sie benötigen Charakterkonsistenz (gleiche Person in allen Szenen)
- Sie wünschen sich vorhersehbarere und besser kontrollierbare Ergebnisse
Bewährte Vorgehensweise – Kombination beider Ansätze:
- Verwenden Sie die Text-zu-Video-Generierung, um kreative Richtungen zu erkunden.
- Wählen Sie den optimalen Frame als Referenzbild aus.
- Verwenden Sie die Bild-zu-Video-Generierung für eine verfeinerte, kontrollierbare Endversion.
Einen umfassenden Workflow zur Erstellung von Videos aus Bildern finden Sie im Image-to-Video AI Complete Guide.
Aktuelle Einschränkungen – Eine ehrliche Einschätzung
Die Text-zu-Video-KI von 2026 ist beeindruckend, aber noch lange nicht fehlerfrei. Nachstehend sind die Bereiche aufgeführt, in denen sie derzeit herausragende Leistungen erbringt, und diejenigen, die weiterhin Herausforderungen darstellen.
Gut gemacht!
- Kurze Videos (5–15 Sekunden): Bildqualität, die kinoreifen Standards nahekommt
- Szenen mit einem einzigen Motiv: Eine Person, ein Tier, ein Objekt – hervorragende Ergebnisse
- Natur und Landschaften: Außergewöhnliche Wiedergabe von Strömungsdynamik, Wetter und atmosphärischen Effekten
- Stilisierte Inhalte: Animation, Film Noir, Science-Fiction – äußerst zuverlässige Stilkonvertierung
- Produktrotationsanzeigen: Einfache Produktbewegung mit guter Konsistenz
- Kamerabewegungen: Schwenken, Zoomen, Dolly, Kamerafahrten – gut kontrolliert
Immer noch schwierig
- Hände und Finger: Überzählige Finger, unplausible Gesten und Deformierungen der Fingerglieder sind nach wie vor weit verbreitet
- Textdarstellung: Lesbarer Text in Videos ist unzuverlässig – Buchstaben erscheinen verzerrt, Zeichen verzerrt
- Komplexe Interaktionen zwischen mehreren Personen: Bei Handschlägen zwischen zwei Personen, beim gemeinsamen Tanzen oder bei Kämpfen kommt es häufig zu Unstimmigkeiten bei den Gliedmaßen
- Längere Erzählsequenzen (>30 Sekunden): Die Konsistenz der Szenen über längere Zeiträume hinweg verschlechtert sich
- Präzise Physik: Präzises Springen eines Balls, Wasser, das in bestimmte Behälter fließt – die Physik ist annähernd, nicht exakt
- Langfristige Konsistenz der Gesichter: Gesichtszüge können zwischen den Einzelbildern subtile Veränderungen erfahren, insbesondere über längere Zeiträume hinweg.
Fortschrittsentwicklung
Jede dieser Einschränkungen wird bis 2026 im Vergleich zu 2024 deutlich verbessert werden. Das Tempo der Verbesserung ist exponentiell. Die Handwiedergabe wird sich von „immer falsch” zu „im Allgemeinen genau” entwickeln. Die Gesichtskonsistenz wird sich von „beginnt nach 2 Sekunden zu driften” zu „bleibt 10-15 Sekunden lang stabil” verschieben. Die Textwiedergabe wird sich von „unlesbar” zu „gelegentlich lesbar” verbessern. Es wird erwartet, dass sich diese Probleme zwischen 2026 und 2027 weiter rapide verbessern werden.
Häufig gestellte Fragen
Welche ist die beste Text-zu-Video-KI für 2026?
Seedance 2.0 ist mit nativer 2K-Auflösung, vierfacher Eingabe und integrierter Audioerzeugung führend in der Gesamtbildqualität. Google Veo 3 zeichnet sich durch audiovisuelle Fusion und physikalische Simulation aus. Sora 2 bietet die längste Dauer einer einzelnen Generation (20 Sekunden). Was „das Beste” ist, hängt von Ihren spezifischen Anforderungen ab – Auflösung, Audio, Dauer oder Preis. Privatanwender können auch KeLing 3.0 (gutes Preis-Leistungs-Verhältnis, lange Videos) und Tongyi Wanxiang (integriert in das Alibaba-Ökosystem) in Betracht ziehen.
Gibt es eine kostenlose KI für die Umwandlung von Text in Video?
Ja. Seedance 2.0 bietet ein tägliches Freikontingent, ohne dass eine Kreditkarte erforderlich ist. Pika 2.0 bietet eine tägliche kostenlose Generierung. Keiling 3.0 gewährt ein Anmelde-Kontingent. Google Veo 3 bietet kostenlose Kontingente über AI Studio. Conch AI bietet ebenfalls ein tägliches Freikontingent. Weitere Informationen finden Sie unter Vergleich kostenloser KI-Videogeneratoren.
Wie lang können aus Text generierte KI-Videos sein?
Die meisten Tools generieren Inhalte in Schritten von 5 bis 15 Sekunden. Sora 2 unterstützt bis zu 20 Sekunden. Keeling 3.0 unterstützt mehr als 20 Sekunden. Für längere Inhalte können mehrere Segmente generiert und mit einer Bearbeitungssoftware wie Kinevision, Premiere Pro oder DaVinci Resolve zusammengefügt werden.
Kann Text-zu-Video-KI professionelle Bildqualität erzielen?
Innerhalb von 5 bis 15 Sekunden ist dies machbar. Die Ergebnisse von Seedance 2.0 und Veo 3 sind in kurzen Clips oft nicht von professionellem Filmmaterial zu unterscheiden. Bei längeren Projekten eignet sich KI-Video am besten als Bestandteil des Materials (B-Roll, Übergangsszenen, visuelle Effekte) und nicht als Gesamtheit der Produktion.
Wie erstellt man effektive Eingabeaufforderungen für die Text-zu-Video-Generierung?
Befolgen Sie die Formel: Thema + Handlung + Kulisse + Stil + Kameraeinstellung + Beleuchtung. Bewegungsbeschreibungen sollten konkret sein, Kamerabewegungen klar definiert und die Atmosphäre deutlich herausgearbeitet werden. Vermeiden Sie Widersprüche und verzichten Sie auf Text-/UI-Elemente. Arbeiten Sie sich schrittweise von einfach zu komplex vor. Weitere Details finden Sie im Leitfaden zum Verfassen von Prompts.
Was ist besser: Text-zu-Video- oder Bild-zu-Video-Generierung?
Unterschiedliche Anwendungen. Text-zu-Video bietet maximale kreative Freiheit, wenn kein Referenzmaterial verfügbar ist. Bild-zu-Video bietet mehr Kontrolle, wenn ein bestimmter visueller Ausgangspunkt vorhanden ist. Die meisten Fachleute nutzen beide Ansätze – Text-zu-Video für explorative Arbeiten und Bild-zu-Video für die Verfeinerung.
Können KI-generierte Videos für kommerzielle Zwecke verwendet werden?
Die meisten kostenpflichtigen Tarife gewähren kommerzielle Rechte. Die kostenpflichtige Version von Seedance 2.0 umfasst vollständige kommerzielle Rechte und ist frei von Wasserzeichen. Die Nutzungsbedingungen variieren je nach Plattform. Bitte überprüfen Sie vor der Nutzung die spezifischen Richtlinien. In China unterliegt die kommerzielle Nutzung von KI-generierten Inhalten derzeit keinen ausdrücklichen regulatorischen Beschränkungen. Es ist jedoch ratsam, die Aktualisierungen der vorläufigen Maßnahmen zur Verwaltung generativer KI-Dienste zu verfolgen.
Wird die Text-zu-Video-KI Redakteure ersetzen?
Es wird keine Rollen ersetzen, sondern vielmehr verändern. KI übernimmt die Generierung von Inhalten – sie erstellt anhand von Beschreibungen originelle visuelle Elemente. Menschliche Redakteure kümmern sich um die Erzählung, das Tempo, die emotionale Resonanz, die Markenkonsistenz und kreative Entscheidungen, die menschliches Urteilsvermögen erfordern. Bis 2026 wird der effektivste Arbeitsablauf aus KI-Generierung und menschlicher Bearbeitung bestehen.
Beginnen Sie mit der Erstellung von Videos mit Text
Bis 2026 wird die Text-zu-Video-KI für professionelle Anwendungen bereit sein. Diese Technologie hat sich innerhalb von nur vier Jahren von unscharfen GAN-Experimenten zu fast kinoreifen DiT-Ergebnissen entwickelt und ist nun in der Lage, Social-Media-Inhalte, Produktdemonstrationen, visuelle Darstellungen für Bildungszwecke und kreative Entdeckungsreisen zu verarbeiten.
Der beste Weg zum Lernen ist, einfach anzufangen. Schreiben Sie eine Eingabeaufforderung, sehen Sie sich die Ergebnisse an und wiederholen Sie den Vorgang.
Verwandeln Sie Ihren ersten Absatz in ein Video – probieren Sie Seedance kostenlos aus →
Sie wünschen sich eine höhere Steuerungspräzision? Probieren Sie die Bild-zu-Video-Generierung aus →
Möchten Sie sich näher mit Prompt-Techniken befassen? Lesen Sie unseren Leitfaden zum Verfassen von Prompts →
