
Auf einen Blick
Der effektivste Weg, KI-Videos zu erstellen, besteht nicht darin, einfach eine Beschreibung in Text-zu-Video-Tools einzugeben. Beginnen Sie stattdessen mit einem sorgfältig vorbereiteten Bild.
Dreistufige Pipeline – Eingabeaufforderung → Bild → Video – liefert Ergebnisse, die weit über die reine Text-zu-Video-Generierung hinausgehen. Erstellen Sie zunächst eine professionelle Eingabeaufforderung. Verwenden Sie diese Eingabeaufforderung, um ein Bild mit präziser Komposition zu generieren. Speisen Sie dieses Bild dann als erstes Bild in einen Videogenerator ein. Das Ergebnis: Sie erhalten präzise Kontrolle über visuelle Inhalte, Lichtstimmung, Kompositionsdetails und den Startpunkt der Bewegung.
Seedance ist das einzige Tool, das alle drei Phasen in einer einzigen Plattform vereint: Der Image Prompt Generator hilft Ihnen bei der Erstellung professioneller Eingabeaufforderungen, Text-to-Image generiert hochwertige Referenzbilder und Image-to-Video verwandelt Bilder in filmische Videoclips. Sie müssen nicht zwischen verschiedenen Tools wechseln, nichts herunterladen und erneut hochladen – von der Inspiration bis zum fertigen Werk erfolgt alles in einem nahtlosen Arbeitsablauf.
Schritt 1: Eingabeaufforderung generieren → | Schritt 2: Bild generieren → | Schritt 3: Video generieren →

Links: Reine Text-zu-Video-Erzeugung – zufällige Komposition, unkontrollierbare Bilddarstellung. Rechts: Bildorientierte Pipeline – zuerst die Bilddarstellung verfeinern, dann Bewegung hinzufügen; präzise Komposition, gleichbleibende Qualität.
Warum „Bild zuerst, Video später“ die Konvertierung von Text zu Video bei weitem übertrifft
Diejenigen, die Wensheng Video bereits verwendet haben, kennen diese Erfahrung: Man schreibt eine detaillierte Beschreibung – mit Angaben zu Thema, Beleuchtung, Kamerawinkel und Bildkomposition –, doch das von der KI generierte Filmmaterial entspricht in keiner Weise der eigenen Vorstellung. Die Figuren schauen in die falsche Richtung, die Beleuchtung ist flach, die Bildkompositionen wirken zufällig generiert und die Rollen entsprechen nicht der Beschreibung.
Dies ist kein Fehler eines bestimmten Tools, sondern vielmehr eine strukturelle Einschränkung, die dem Text-zu-Video-Ansatz innewohnt.
Die inhärenten Einschränkungen der Erstellung videobasierter Inhalte
Wensheng Video verlangt von der KI, dass sie zwei außergewöhnlich anspruchsvolle Aufgaben gleichzeitig erfüllt: die Erzeugung von Bildern und die Erzeugung von Bewegungen. Das Modell muss Ihren Text interpretieren, das Aussehen jedes Pixels bestimmen, die Szene komponieren, Beleuchtung und Schatten festlegen, die Kameraposition festlegen und dann auf der Grundlage all dieser Informationen eine kohärente Bewegung erzeugen – und das alles aus einem einzigen Text.
Das Ergebnis ist, dass jede Dimension außer Kontrolle gerät:
- Zufällige Komposition. Sie schreiben „eine Frau, die mitten auf der Straße steht“, doch sie landet im linken Drittel, wobei die Hälfte des Bildes von unnötigen Gebäuden dominiert wird.
- **Inkonsistente Charaktere. ** Gesichtsstruktur, Kleidung, Frisur und Körperproportionen schwanken mit jeder Generation. Die KI liefert „kreative Interpretationen“ und nicht Ihre Vorgaben.
- **Unkontrollierte Beleuchtung. ** Selbst wenn Sie „goldene Stunde, warmes Seitenlicht von links” angeben, führt dies zu äußerst inkonsistenten Ergebnissen. Die Interpretation von Beleuchtungsbeschreibungen durch die KI bleibt grundsätzlich vage.
- Unzuverlässige Bildkomposition. Nahaufnahmen, Halbnahaufnahmen, Totalen – Text-zu-Video-Tools interpretieren diese Begriffe mit extremer Instabilität. Wenn Sie eine extreme Nahaufnahme verlangen, liefert es eine Ganzkörperaufnahme.
Bei kreativen Experimenten kann diese Unsicherheit Teil des Spaßes sein. Wenn Sie jedoch kontrollierte, zuverlässige professionelle Ergebnisse benötigen, wird sie zu einem fatalen Fehler.
Der entscheidende Vorteil der Bildpriorität
TuSheng Video hat diese Gleichung komplett umgekehrt. Sie benötigen die KI nicht mehr, um sowohl Bilder als auch Bewegungen gleichzeitig zu generieren, sondern trennen die beiden Aufgaben:
- Beginnen Sie mit dem Bild. Motiv, Komposition, Beleuchtung, Farbe, Bildausschnitt – Sie haben die volle Kontrolle und können so lange iterieren, bis das Ergebnis perfekt ist.
- Fügen Sie dann Bewegung hinzu. Die einzige Aufgabe der KI besteht darin, Ihren perfekten Bildausschnitt zu animieren. Sie muss keine vagen Beschreibungen entschlüsseln oder kompositorische Entscheidungen treffen, sondern generiert Bewegung anhand Ihrer konkreten visuellen Ankerpunkte.
Diese Fokussierung führt in jeder Hinsicht zu überlegenen Ergebnissen:
- Komposition fixiert. Das Motiv bleibt genau dort, wo Sie es platziert haben.
- Konsistenz der Charaktere. Gesichtszüge, Kleidung und Proportionen bleiben durchgehend identisch mit dem Ausgangsbild.
- **Beleuchtung und Schatten bleiben erhalten. ** Lichtrichtung, Textur und Farbtemperatur werden vollständig aus dem Bild übernommen.
- Feste Bildausrichtung. Kameraposition und Blickwinkel bleiben mit der ursprünglichen Einstellung des Bildes konsistent.
Zur Veranschaulichung: Text-zu-Video ist vergleichbar damit, eine Filmszene am Telefon zu beschreiben und jemanden zu beauftragen, sie zu filmen. Bild-zu-Video hingegen ist so, als würde man jemandem ein Foto zeigen und sagen: „Erwecke dieses Bild zum Leben.“ Der letztere Ansatz führt zu besser kontrollierbaren und qualitativ hochwertigeren Ergebnissen, da die KI konkrete visuelle Referenzen erhält und keine abstrakten Textbeschreibungen.
Der Multiplikatoreffekt der Qualität
Die Vorteile sind kumulativ. Ein sorgfältig gestalteter Eröffnungsframe verbessert jeden Aspekt des Videos:
- Verbesserte zeitliche Konsistenz – Das Modell verfügt über hochwertige visuelle Ankerpunkte, um die Kohärenz während der gesamten Sequenz aufrechtzuerhalten.
- Verbesserte Bewegungsqualität – Das Modell extrahiert präzise Tiefen-, Beleuchtungs- und Rauminformationen aus klaren Quellbildern.
- Verbesserte stilistische Konsistenz – Farbsysteme, Stimmungen und Ästhetik sind direkt in die Bilder eingebettet, sodass kein Raum für textuelle Interpretationen bleibt.
- Reduzierte Fehlerquote – Das Modell beginnt mit sauberen, hochauflösenden visuellen Daten, anstatt alles aus Rauschen zu synthetisieren.
Hochwertige, aus dem ersten Bild generierte Videos weisen gegenüber rein textgenerierten Videos mit identischen Eingabeaufforderungen eine deutliche Überlegenheit in Bezug auf visuelle Qualität, zeitliche Kontinuität und ästhetische Anziehungskraft auf. Dies ist kein subtiler Unterschied – es handelt sich um einen Graben zwischen „unterhaltsamen KI-Demonstrationen” und „professionell nutzbaren Inhalten”.
Eine ausführliche Beschreibung, wie Bilder speziell für die Videogenerierung gestaltet werden, finden Sie im Leitfaden zur Gestaltung des ersten und letzten Bildes.
Dreistufige KI-Kreativ-Pipeline
Der gesamte Arbeitsablauf ist in drei Phasen unterteilt, die jeweils auf der vorherigen aufbauen. Jede Phase, die nachlässig behandelt wird, beeinträchtigt letztendlich das Endergebnis. Das Verständnis des Beitrags jeder Phase – und wo Zeit investiert werden muss – ist der Schlüssel zur konsistenten Produktion hochwertiger KI-Videos.
Phase Eins: Prompt-Generierung
Alles beginnt mit der Eingabeaufforderung. Mittelmäßige Eingabeaufforderungen → mittelmäßige Bilder → mittelmäßige Videos. Hervorragende Eingabeaufforderungen → atemberaubende Bilder → atemberaubende Videos. Die Qualität der Eingabeaufforderung ist der größte Einflussfaktor für die Qualität des Endergebnisses und gleichzeitig der Schritt, in den in den meisten Arbeitsabläufen am wenigsten investiert wird.
Das Problem beim manuellen Schreiben von Eingabeaufforderungen. Die meisten Menschen gehen an das Schreiben von Eingabeaufforderungen wie an das Erstellen von Suchbegriffen heran: kurz, vage und ausschließlich auf das Thema fokussiert. „Eine Luxusuhr, dunkler Hintergrund.“ Damit wird der KI zwar mitgeteilt, was sie zeichnen soll, aber nicht, wie sie es zeichnen soll. Das Modell füllt die Lücken mit Standardwerten – flache Beleuchtung, zentrierte Komposition, keine atmosphärischen Details, keine stilistische Ausrichtung.
Lösung: KI-gestützte Prompt-Generierung. Der Prompt-Generator erweitert Ihre groben Ideen zu professionellen Prompts, die Themen, Umgebung, Beleuchtung, Farbe, Komposition, Stil und Bildqualitätsverbesserungen abdecken. Der Unterschied in der Ausgabequalität zwischen einem manuellen Prompt mit 10 Wörtern und einem generierten Prompt mit 100 Wörtern stellt einen qualitativen Sprung dar.
Der Image Prompt Generator von Seedance macht genau das. Geben Sie eine kurze Beschreibung ein, z. B. „Luxusuhrenwerbung, düster und dramatisch“, wählen Sie einen Stil (fotorealistisch, filmisch, illustrativ usw.) und die KI generiert sofort einen vollständigen professionellen Prompt. Der gesamte Vorgang dauert nur wenige Sekunden und kostet 2 Credits pro Prompt. Eine umfassende Anleitung zur Prompt-Generierung finden Sie im AI Image Prompt Generator Guide.
Warum dieser Schritt so wichtig ist. Die Eingabeaufforderung ist die DNA Ihrer gesamten Pipeline. Sie bestimmt den Stil, die Stimmung, die Komposition und die Qualitätsgrenze für alles, was folgt. Wenn Sie fünf Minuten damit verbringen, Ihre Eingabeaufforderung zu verfeinern, bevor Sie Bilder generieren, können Sie sich später dreißig Minuten iterativer Optimierung mittelmäßiger Ergebnisse sparen.
Generieren Sie Ihre Eingabeaufforderung →
Phase Zwei: Bilderzeugung
Nach Erhalt der professionellen Eingabeaufforderung besteht der nächste Schritt darin, das Bild zu generieren, das als Eröffnungsbild des Videos dienen soll. Hier erfolgt der Übergang vom Text zum Bildmaterial, was den Zeitpunkt markiert, an dem die meiste Zeit für Iterationen investiert werden sollte.
Von der Eingabeaufforderung zum Bild. Fügen Sie die generierte Eingabeaufforderung in das Text-zu-Bild-Tool ein und klicken Sie auf „Generieren“. Bewerten Sie das Ergebnis: Ist die Komposition für ein Video geeignet? Ist die Beleuchtung ausreichend vielschichtig? Wird das Motiv korrekt dargestellt? Vermittelt die Szene ein Gefühl von Tiefe?
Wenn Sie bereits über ein Referenzbild verfügen oder vorhandene Generierungsergebnisse optimieren möchten, ist image-to-image das richtige Tool für Sie. Laden Sie Ihr vorhandenes Bild hoch und beschreiben Sie die gewünschten Änderungen – dies erweist sich als besonders leistungsstark für Kompositionsiterationen: Passen Sie die Beleuchtung an, fügen Sie atmosphärische Effekte hinzu oder ändern Sie den Inhalt der Szene, ohne von vorne beginnen zu müssen. Eine umfassende Anleitung zum Image-to-Image-Workflow finden Sie im Image-to-Image AI Guide.
Entwerfen Sie Bilder für die Verwendung in Videos. Nicht jedes optisch ansprechende Bild eignet sich als Eröffnungsbild für ein Video. Beachten Sie bei der Erstellung von Bildern für die Verwendung in Pipelines die folgenden Gestaltungsprinzipien:
- Lassen Sie negativen Raum in Bewegungsrichtung. Wenn sich eine Figur von links nach rechts bewegt, positionieren Sie sie leicht rechts vom Bildausschnitt.
- Berücksichtigen Sie Tiefenstufen. Bilder mit deutlichen Elementen im Vordergrund, Mittelgrund und Hintergrund erzeugen bessere Parallaxeneffekte und natürlichere Kamerabewegungen im Video.
- **Berücksichtigen Sie die Richtung der Kamerabewegung. ** Wenn Sie eine „Push”-Bewegung verwenden möchten, stellen Sie sicher, dass die Komposition sowohl im aktuellen Bildausschnitt als auch in einem engeren Bildausschnitt, der auf das Motiv zentriert ist, gut aussieht.
- Vermeiden Sie große Textblöcke oder symmetrische Muster. Solche Elemente lassen sich nur schwer natürlich animieren und können leicht zu Artefakten führen.
- **Verwenden Sie gerichtete Beleuchtung. ** Eine starke gerichtete Beleuchtung mit sichtbaren Schatten erzeugt einen cineastischeren Videoeffekt als eine flache Beleuchtung.
Grundprinzip: Investieren Sie Zeit in die Optimierung Ihrer Bilder. Jede Minute, die Sie für die Perfektionierung Ihrer Bilder aufwenden, spart Ihnen ein Vielfaches davon in der Videoproduktionsphase. Ein makelloses erstes Bild bedeutet, dass Ihr Video vom ersten Versuch an einsetzbar ist. Ein fehlerhaftes erstes Bild kann mehrere Neuproduktionen erfordern (die jeweils Credits und Zeit kosten), ohne dass ein zufriedenstellendes Ergebnis garantiert ist.
Bevor Sie mit der Videogenerierung beginnen, wiederholen Sie den Vorgang 3–5 Mal. Das ist kein Perfektionismus, sondern Effizienz.
Eine umfassende Anleitung zur Text-zu-Bild-Generierung (einschließlich Prompting-Techniken und Tool-Vergleichen) finden Sie unter The Complete Guide to Text-to-Image AI. Eine Übersicht über die besten Tools zur Bildgenerierung finden Sie unter Best AI Image Generators for 2026.
Bild generieren → | Bild-zu-Bild-Feinabstimmung →
Stufe 3: Videogenerierung
Dies ist die Phase, in der Sie die Früchte Ihrer Arbeit ernten. Die von Ihnen verfeinerten Bilder bilden den Ausgangspunkt für Ihre animierten Videoclips.
Laden Sie ein Bild als ersten Frame hoch. Laden Sie Ihr generiertes Bild in das [Image-to-Video]-Tool von Seedance hoch. Das Tool ruft Bilder direkt aus Ihrem Generierungsverlauf ab – Sie müssen sie also nicht herunterladen und erneut hochladen.
Leiten Sie die Bewegung mit Worten. Schreiben Sie eine Eingabeaufforderung, die die gewünschte Bewegung beschreibt – beschreiben Sie nicht die visuellen Elemente (das Bild wurde bereits verarbeitet). Konzentrieren Sie sich auf:
- Kamerabewegung: „langsame Kamerafahrt nach innen“ 、sanfte Schwenkbewegung nach links、gleichmäßige Umkreisen des Motivs
- Handlung des Motivs: „Die Frau dreht langsam den Kopf“、Blütenblätter fallen herab、Dampf steigt aus der Tasse auf
- Bewegung der Umgebung: „Wolken ziehen langsam vorbei“, „Wasser kräuselt sich“, „Blätter wiegen sich sanft im Wind“
- ** Atmosphäre**: „dramatische Atmosphäre“, „verträumte, ätherische Qualität“, „filmisches Tempo“
Generieren und überprüfen. Die KI erhält Ihre Bild- und Bewegungsvorgaben und erzeugt Videosegmente, die genau mit Ihrem ersten Bild beginnen und sich gemäß Ihren Bewegungsanweisungen entfalten. Da Sie den visuellen Ausgangspunkt steuern, ist das Ergebnis vorhersehbar und konsistent. Die Videoqualität entspricht der Bildqualität – ein klares, gut ausgeleuchtetes und präzise komponiertes erstes Bild führt direkt zu einem klaren, gut ausgeleuchteten und präzise komponierten Video.
Informationen zu fortgeschrittenen Bewegungssteuerungstechniken und zur Paarung von erstem und letztem Bild finden Sie im Leitfaden zum Design des ersten und letzten Bildes. Eine umfassende Einführung in die Image-to-Video-KI finden Sie im Leitfaden zur Image-to-Video-KI.
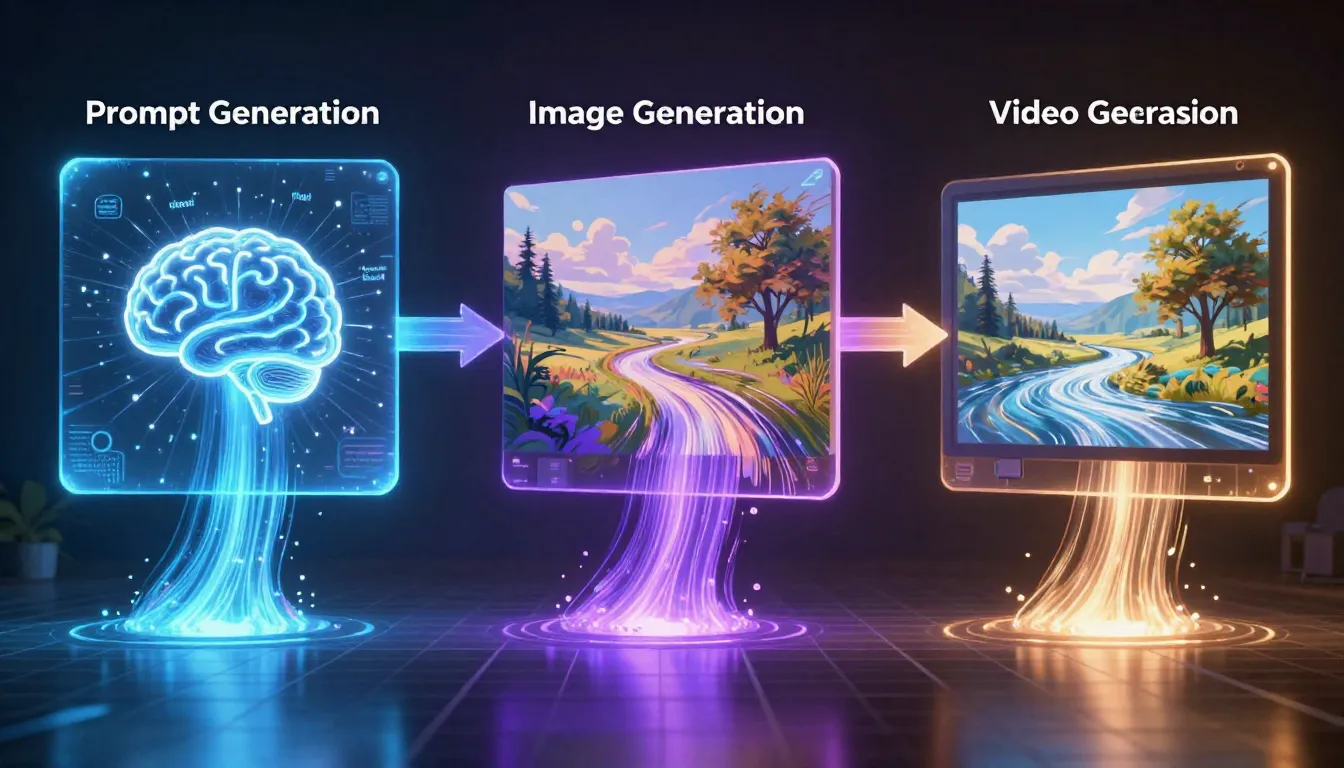
Dreistufiger Prozess in Aktion: Verwandeln Sie kurze Beschreibungen in professionelle Eingabeaufforderungen, verwandeln Sie Eingabeaufforderungen in hochwertige Bilder und wandeln Sie Bilder in dynamische Videos um. Jede Stufe verbessert die Qualität der vorherigen.
Seedance-Vorteil: Dreistufige Abwicklung aus einer Hand
Heute kombinieren die meisten Kreativen, die diese Pipeline zusammenstellen, drei oder vier Tools miteinander. Sie verwenden ChatGPT oder Claude, um Bildprompts zu schreiben, wechseln dann zu Midjourney oder Tongyi Wansheng für die Bilderzeugung, laden das Bild herunter, öffnen Ke Ling oder Runway und laden es dann hoch, um ein Video zu generieren. Jeder Wechsel bedeutet eine andere Benutzeroberfläche, andere Konten, andere Abrechnungssysteme und andere Einschränkungen.
Dieser fragmentierte Arbeitsablauf ist nicht nur lästig, sondern beeinträchtigt auch aktiv die Qualität.
Wie der Wechsel von Werkzeugen die Qualität beeinträchtigt
Jedes Mal, wenn ein Bild zwischen Tools übertragen wird, kommt es zu Qualitätsverlusten. Der Download-Upload-Zyklus führt zu Kompressionsartefakten. Formatkonvertierungen (PNG zu JPG, WebP zu PNG) verändern die Farbwerte. Die Auflösung kann neu berechnet werden. Metadaten darüber, wie das Bild erzeugt wurde – Informationen, die dem Videomodell zu besseren Ergebnissen hätten verhelfen können – werden vollständig entfernt.
Neben der Datenqualität gibt es auch kognitiven Aufwand. Jedes Tool hat seine eigene Befehlssyntax, unterschiedliche Ausgabeeinstellungen und verschiedene Optionen für das Seitenverhältnis. Sie verschwenden Zeit damit, sich wieder mit den Benutzeroberflächen vertraut zu machen, anstatt sie für kreative Iterationen zu nutzen.
Integrierte Rohrleitungen
Seedance beseitigt alle diese Reibungsverluste, indem es alle drei Phasen innerhalb einer einzigen Plattform anbietet:
1. Bild-Prompt-Generator (/image-prompt-generator). Geben Sie Ihr kreatives Konzept ein, wählen Sie aus 12 Stilen aus und erhalten Sie einen vollständigen professionellen Prompt. Die generierten Prompts sind für das Seedance-Bildgenerierungsmodell optimiert, eignen sich aber gleichermaßen für jedes KI-Malwerkzeug.
2. Text-zu-Bild und Bild-zu-Bild (/text-to-image | /image-to-image). Erstellen Sie Bilder anhand von Eingabeaufforderungen oder nehmen Sie gezielte Änderungen an vorhandenen Bildern vor. Produzieren Sie schnell mehrere Varianten. Sobald Sie die richtige Komposition gefunden haben, können Sie direkt zur nächsten Stufe übergehen.
- Bild zu Video Wählen Sie ein beliebiges vorgefertigtes Bild aus Ihrer Bibliothek aus und senden Sie es direkt an den Videogenerator. Keine Downloads, keine Uploads, keine Formatkonvertierungen erforderlich. Bilder in voller Auflösung werden verlustfrei übertragen.
Warum führt Integration zu besseren Ergebnissen?
Dies ist nicht nur eine praktische Funktion, sondern die Integration führt tatsächlich zu überlegenen Ergebnissen:
- Keine Übertragungsverluste. Bilder werden in voller Auflösung zwischen den Stufen übertragen, ohne Komprimierung oder Neuberechnung.
- Konsistentes Modell-Ökosystem. Bild- und Videogenerierungsmodelle sind auf inhärente Kompatibilität kalibriert. Bilder, die mit dem Text-zu-Bild-Modell von Seedance erzeugt werden, sind von Natur aus für das Videomodell von Seedance geeignet.
- **Einheitliches Kreditsystem. ** Sie müssen nicht drei separate Abonnements verwalten. Ihre Credits sind für alle drei Tools universell einsetzbar, was die Budgetverteilung einfach und transparent macht.
- Schnellere Iterationszyklen. Die Zeit zwischen „Ich möchte dieses Bild bearbeiten” und „Ich schaue mir das neue Video an” verkürzt sich von Minuten, die für den Wechsel zwischen den Tools benötigt werden, auf wenige Sekunden dank nahtloser Integration.
- **Kreativen Fluss aufrechterhalten. ** Bleiben Sie in einer einzigen Oberfläche, um Ihren Gedankengang nicht zu unterbrechen. Konzentrieren Sie sich auf das kreative Konzept selbst, nicht auf die Dateiverwaltung oder die Navigation zwischen den Tools.
Um ehrlich zu sein: Sie können ChatGPT zum Schreiben von Prompts, Midjourney oder Tongyi Wansheng zur Bilderzeugung und Keling oder Runway zur Videoerstellung verwenden, um eine hochwertige Pipeline aufzubauen. Viele Fachleute tun genau das. Der Vorteil von Seedance liegt nicht darin, dass es in einer einzelnen Phase die Konkurrenz weit übertrifft, sondern darin, dass seine Integration die Reibungsverluste beseitigt, die die meisten Kreativen dazu veranlassen, den Prozess vorzeitig abzubrechen. Der beste Workflow ist der, den Sie tatsächlich von Anfang bis Ende durchziehen.
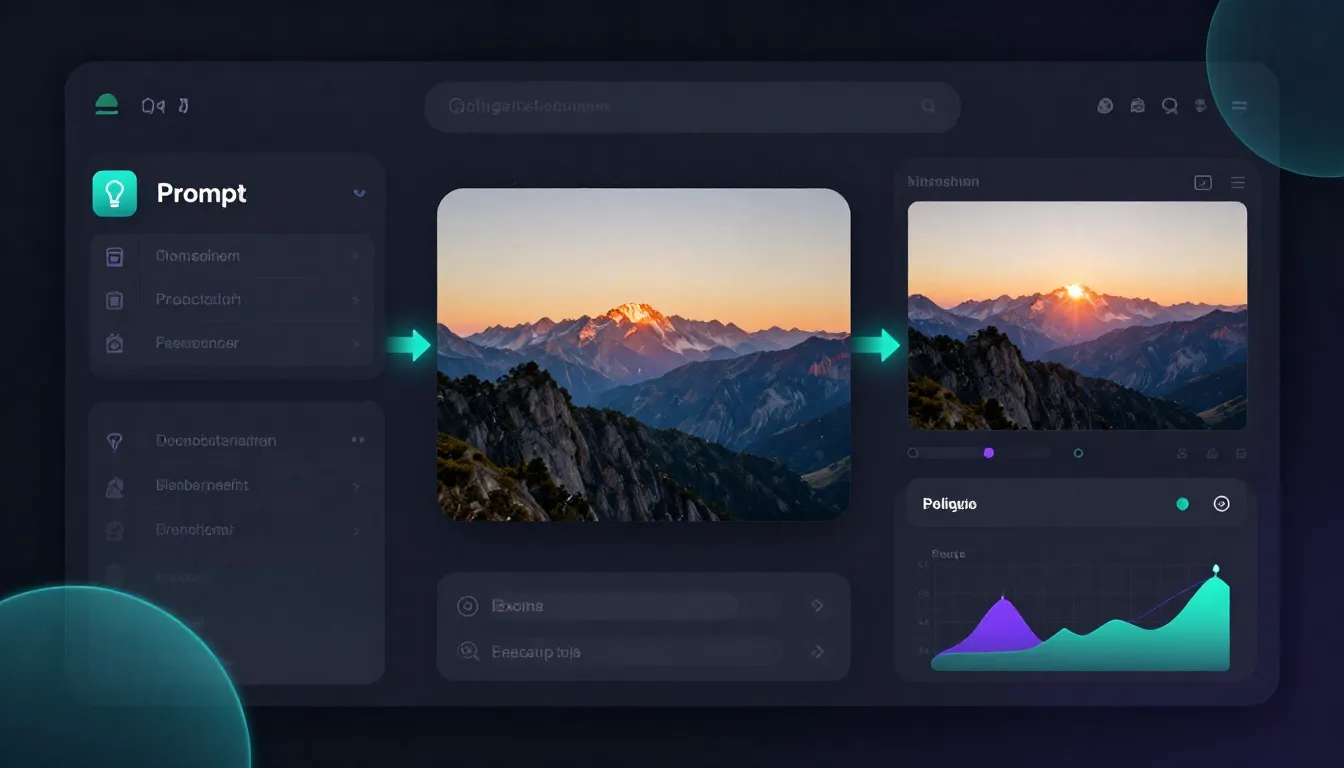
Seedance integriert die Erstellung von Prompts, Bildern und Videos in einer einzigen Plattform. Vom Konzept bis zum fertigen Video müssen Sie weder zwischen verschiedenen Tools wechseln noch Dateien herunterladen oder mehrere Konten verwalten.
Vollständiger praktischer Leitfaden: 3 Fallstudien aus der Praxis
Theorie ist nützlich, aber Praxis bringt Ergebnisse. Im Folgenden finden Sie drei vollständige Pipeline-Übungen, die jeweils unterschiedlichen kreativen Zielen, unterschiedlichen Stilen und unterschiedlichen Seitenverhältnissen entsprechen. Folgen Sie den Anweisungen, um Ihre erste vollständige Pipeline zu erstellen.
Fall 1: Filmische Produktwerbung
Ziel: Produktion einer fünfsekündigen Luxusuhrenwerbung für die Produktpräsentationsseite.
Phase Eins – Prompt-Generierung
Öffnen Sie den Image Prompt Generator und geben Sie Ihr Konzept ein.
Eingabe: „Werbung für Luxusuhren, düster und dramatisch“
Stil auswählen: Fotorealistisch
Generierte Eingabeaufforderung:
A luxury men's wristwatch resting on a slab of dark emperador marble,
shot from a low three-quarter angle. Dramatic studio lighting: a single
hard key light from the upper left creates sharp reflections on the
polished steel case and sapphire crystal. The watch face shows 10:10
with luminous indices glowing faintly. Deep shadows pool around the
base, enhancing the sense of weight and prestige. Background is pure
black, fading to subtle charcoal gradient. Microscopic dust particles
float in the key light beam. Color palette: silver, deep charcoal,
amber highlights from the lume. Photorealistic product photography,
8K resolution, razor-sharp detail on every dial marking and link.Das manuelle Erstellen dieser Eingabeaufforderung würde mindestens 10 bis 15 Minuten dauern. Ein Eingabeaufforderungsgenerator erledigt dies in Sekundenschnelle und deckt dabei alle sieben Dimensionen professioneller Eingabeaufforderungen ab: Thema, Umgebung, Beleuchtung, Farbe, Komposition, Stil und Bildqualität.
Phase Zwei – Bilderzeugung
Fügen Sie die generierte Eingabeaufforderung in Text-zu-Bild ein. Generieren Sie ein Seitenverhältnis von 16:9, das für Video-Frames im Querformat geeignet ist.
Erste Darstellung: Die Gesamtkomposition ist gelungen, allerdings reflektiert die Marmoroberfläche etwas zu stark, wodurch die Aufmerksamkeit von der Uhr abgelenkt wird.
Iteration: Feinabstimmung mit Image-to-Image. Laden Sie das ursprünglich generierte Bild mit der Eingabeaufforderung hoch: „Verringern Sie die Intensität der Reflexion auf der Marmoroberfläche. Erhöhen Sie die Schärfe der Details auf dem Zifferblatt. Machen Sie den Hintergrundverlauf etwas tiefer.“
Zweite Aufnahme: Die Uhr steht im Mittelpunkt, getaucht in dramatisches Licht und Schatten, mit einer vielschichtigen Komposition. Bereit für die Videoproduktion.
Stufe 3 – Videogenerierung
Senden Sie die bearbeiteten Bilder an Image-to-Video.
Übungsanweisungen:
The camera executes a slow, smooth orbiting movement around the watch,
revealing different angles of the case and bracelet. The key light
shifts subtly as the camera moves, creating dynamic reflections across
the polished surfaces. Dust particles drift slowly through the light
beam. Cinematic, premium commercial pacing. Steady, professional
camera movement.(Die Kamera schwenkt langsam und gleichmäßig um die Uhr herum und zeigt verschiedene Blickwinkel auf das Gehäuse und das Armband. Während sich die Kamera bewegt, verschiebt sich die Hauptlichtquelle subtil und erzeugt dynamische Reflexionen auf den polierten Oberflächen. Staubpartikel schweben sanft im Lichtstrahl. Filmisches, hochwertiges Werbetempo. Gleichmäßige, professionelle Kamerabewegung.)
Ergebnisse: Eine ausgefeilte 5-sekündige Produktpräsentation – beginnend mit Ihrem sorgfältig komponierten Bildausschnitt, der sanft um die Uhr kreist. Dramatische Beleuchtung, scharfe Details und hochwertige Texturen werden nahtlos von den Ausgangsbildern auf jeden Frame des Videos übertragen.

Fall 1: Werbung für Luxusuhren. Von einem fünf Wörter umfassenden Konzeptbriefing bis hin zu einem ausgefeilten fünfsekündigen Produktvideo – eine dreistufige Pipeline, die Ergebnisse in kommerzieller Qualität liefert.
Fall 2: Social-Media-Reiseinhalte
Ziel: Ein vertikales Video drehen, das den Sonnenaufgang an einem japanischen Schrein für TikTok/Instagram Reels einfängt.
Phase Eins – Prompt-Generierung
Öffnen Sie den Bild-Prompt-Generator.
Eingabe: „Sonnenaufgang über einem japanischen Tempel, friedlicher Morgen“
Stil auswählen: Fotorealistisch
Generierte Eingabeaufforderung:
A traditional Japanese wooden temple (Kiyomizu-dera style) nestled
among ancient cedar trees, photographed at dawn. Golden sunrise light
filters through morning mist, casting long warm shadows across the
temple's wooden veranda. Cherry blossom branches frame the upper
portion of the composition, with delicate pink petals catching the
first light. A stone lantern stands in the foreground left, moss-
covered and weathered. The temple roof's curved eaves are silhouetted
against a sky transitioning from deep indigo to warm peach and gold.
Subtle mist hovers at ground level among the trees. Photorealistic
landscape photography, golden hour lighting, serene and contemplative
atmosphere, high dynamic range, rich natural color palette.Phase Zwei – Bilderzeugung
In Text-to-Image einfügen. Wichtige Einstellungen: Im Hochformat 9:16 generieren, geeignet für TikTok und Instagram Reels.
Erster Entwurf: Die Atmosphäre ist atemberaubend, aber die Kirschblütenzweige sind zu hoch im Bild positioniert, sodass im unteren Drittel zu viel Leerraum entsteht.
Iteration: Nach einer geringfügigen Änderung der Eingabeaufforderung und Hinzufügen der Beschreibung „Kirschblütenzweige, die sich von der oberen rechten und linken Ecke aus erstrecken und das obere Drittel des vertikalen Rahmens ausfüllen” positionierte die zweite Generation die Kirschblüten perfekt als natürlichen Rahmen für die Komposition.
Die Komposition eignet sich perfekt für vertikale Videos: Der Schrein lenkt den Blick auf die Mitte des Bildes, während die Kirschblüten im oberen Bereich für visuelle Spannung sorgen. Steinlaternen und Nebel im Vordergrund verleihen dem Bild Tiefe. Diese Aufnahme bietet Potenzial für Bewegungen über mehrere Ebenen hinweg.
Stufe 3 – Videogenerierung
An Bild-zu-Video senden.
Übungsanweisungen:
Gentle cherry blossom petals drift slowly downward through the frame.
Morning mist shifts and swirls at ground level among the trees. Two
birds fly across the sky in the background. The sunrise light gradually
intensifies, warming the scene. A subtle breeze moves the cherry
blossom branches slightly. Peaceful, meditative atmosphere. Slow,
contemplative pacing.Kirschblütenblätter treiben sanft durch das Bild. Morgennebel fließt sanft über den Boden zwischen den Bäumen. Im Hintergrund gleiten zwei Vögel über den Himmel. Das Licht der aufgehenden Sonne wird allmählich intensiver und erwärmt die gesamte Szene. Eine sanfte Brise bewegt die Kirschblütenzweige. Eine ruhige, meditative Atmosphäre. Ein langsamer, kontemplativer Rhythmus.
Ergebnisse: Ein 4 Sekunden langes, atmosphärisches Vertikalvideo, das sich perfekt für TikTok und Instagram Reels eignet. Kirschblüten treiben natürlich dahin, während Morgennebel für Tiefe und Bewegung sorgt. Vögel im Hintergrund schaffen subtile Blickpunkte. Die goldenen, warmen Farbtöne des Ausgangsbildes durchziehen jeden Frame des Videos.
Fallstudie 3: Markengeschichte – Die erste und letzte Bildsequenz miteinander verbinden
Ziel: Erstellen Sie eine sechssekündige Markengeschichte, die die Verwandlung des Cafés von der Stille des frühen Morgens zu seinem geschäftigen, vollbesetzten Zustand darstellt.
In diesem Fall wird die Pipeline zweimal verwendet, wodurch ein Bildpaar aus dem ersten und letzten Frame erzeugt wird, um dem Videomodell zwei visuelle Ankerpunkte für die Definition des Erzählbogens zu liefern. Eine ausführliche Analyse dieser Technik finden Sie im Leitfaden zum Design des ersten und letzten Frames.
Phase Eins – Zwei Aufforderungen
Generieren Sie zwei Sätze von Eingabeaufforderungen aus dem Bild-Eingabeaufforderungsgenerator.
Erste Bildaufnahme: „Ein leerer Coffee-Shop, getaucht in das Licht des frühen Morgens, mit warmen Bernsteintönen.“
Generierte Eingabeaufforderung für den ersten Frame:
Interior of an artisanal coffee shop in the early morning, before
opening. Warm amber sunlight streams through large front windows,
casting long golden rectangles across worn hardwood floors. Exposed
brick walls, a polished wooden counter with a brass espresso machine,
and empty mismatched chairs around small tables. A chalkboard menu
hangs behind the counter. Dust motes float in the sunbeams. The space
feels warm, inviting, and full of potential. Shot at eye level from
just inside the entrance. Photorealistic interior photography, warm
color palette, golden hour tones, cozy atmosphere.Letzter Bildausschnitt: „Ein belebtes Café an einem warmen Morgen, in dem die Gäste ihren Kaffee genießen.“
Generierte Endbild-Eingabeaufforderung:
The same artisanal coffee shop, now alive with morning activity.
Diverse customers sit at tables -- some reading, some talking, some
working on laptops. A barista behind the counter steams milk, creating
a plume of white steam. Coffee cups and pastries fill the tables. Warm
morning light still streams through the windows but is supplemented by
the warm glow of pendant lights. The atmosphere is bustling but cozy,
full of quiet energy and the warmth of community. Shot from the same
eye-level position just inside the entrance. Photorealistic interior
photography, warm tones, lively atmosphere.Phase Zwei – Zwei Bilder
Erstellen Sie den ersten Frame in Text-zu-Bild mit einem Seitenverhältnis von 16:9. Wiederholen Sie den Vorgang, bis das leere Café warm und einladend wirkt und in reichlich goldenes Morgenlicht getaucht ist.
Der letzte Frame nutzt die [Bild-zu-Bild]-Generierung. Laden Sie den ersten Frame als Referenzbild hoch und verwenden Sie die Eingabeaufforderung für den letzten Frame. Dieser Schritt ist entscheidend – die Verwendung des ersten Frames als Referenz gewährleistet visuelle Konsistenz. Architektur, Einrichtung, Lichtrichtung und Farbschema bleiben zwischen den Frames konsistent, lediglich Figuren und Aktivitäten werden hinzugefügt.
Überprüfen Sie das endgültige Bild, um sicherzustellen, dass der Gast natürlich wirkt und der Barista hinter der Theke positioniert ist. Entscheidend ist, dass beide Bilder denselben Ort zu unterschiedlichen Zeitpunkten zeigen und nicht zwei verschiedene Orte.
Stufe 3 – Videogenerierung
Laden Sie das erste Bild auf Image-to-Video hoch. Auf Plattformen, die Endbildreferenzen unterstützen, laden Sie gleichzeitig das letzte Bild hoch.
Übungsanweisungen:
Time-lapse style transition. The empty coffee shop gradually fills
with people arriving -- customers entering, sitting down, a barista
beginning to work. Morning light shifts slowly. The scene transitions
from quiet solitude to warm, bustling community. Smooth, cinematic
pacing. The camera position remains fixed.(Zeitraffer-ähnlicher Übergang. Ein leeres Café füllt sich allmählich mit Gästen – Kunden kommen herein, nehmen Platz und der Barista beginnt mit seiner Arbeit. Das Morgenlicht verändert sich subtil. Die Szene wandelt sich von ruhiger Einsamkeit zu einer warmen, geschäftigen Gemeinschaftsatmosphäre. Sanftes, filmisches Tempo. Die Kamera bleibt stationär.)
Ergebnis: Eine sechssekündige Markengeschichte entfaltet einen vollständigen Erzählbogen – das Erwachen eines Kaffeehauses. Der erste Bildausschnitt schafft eine ruhige, einladende Atmosphäre. Der letzte Bildausschnitt präsentiert den gewünschten Zustand. KI-generierte Übergänge verbinden beide Bilder miteinander: Türen schwingen auf, Gäste nehmen Platz, Baristas schalten Espressomaschinen ein und Kaffeetassen erscheinen auf den Tischen. Die Markenbotschaft ist zurückhaltend, aber wirkungsvoll – dies ist ein Ort, an dem man sich wie zu Hause fühlt.

Fall 3: Markenerzählung, die den ersten und letzten Bildausschnitt miteinander verbindet. KI generiert einen Zeitraffer-Übergang zwischen zwei visuellen Ankerpunkten – von der Stille der Morgendämmerung zur Wärme der Gemeinschaft.
Techniken zur Pipeline-Optimierung
Nachdem wir Hunderte von Videos über diese Pipeline produziert haben, haben sich die folgenden fünf Prinzipien als besonders wichtig für die Qualität der Ergebnisse erwiesen.
Tipp 1: Verbringen Sie 80 % Ihrer Zeit mit Bildern
Dies ist die wichtigste Optimierung. Die Bildqualität ist der Engpass in der gesamten Pipeline. Ein perfektes Bild liefert bereits in der ersten Generation ein brauchbares Video. Ein mittelmäßiges Bild hingegen führt, egal wie gut die Bewegungsvorgaben auch sein mögen, nur zu einem mittelmäßigen Video.
Die Zeitaufteilung sollte in etwa wie folgt aussehen:
- Prompt-Generierung: 5 % (Generator benötigt Sekunden, Handschrift Minuten)
- Bildgenerierung und Iteration: 80 % (Generieren, bewerten, feinabstimmen, neu generieren, bis die Szene perfekt ist)
- Videogenerierung: 15 % (Hochladen, Bewegungs-Prompts schreiben, generieren)
Die meisten Anfänger gehen in der Reihenfolge umgekehrt vor – sie verbringen zehn Sekunden mit einem Bild und erstellen dann nacheinander Videos, in der Hoffnung, auf ein gutes zu stoßen. Erfahrene Benutzer verbringen zehn Minuten mit einem Bild und erhalten innerhalb der ersten paar Versuche ein gutes Video. Der letztere Ansatz liefert mit weniger Credits und weniger Zeitaufwand bessere Ergebnisse.
Bevor Sie mit der Videogenerierung beginnen, wiederholen Sie den Vorgang drei- bis fünfmal. Das ist kein Perfektionismus, sondern Effizienz.
Tipp 2: Für Bewegung konzipiert
Ein ansprechendes Foto und ein guter Videoframe sind nicht dasselbe. Wenn Sie Bilder für Pipelines erstellen, stellen Sie sich vor, wie die Szene aussehen wird, wenn sie zum Leben erwacht.
Lassen Sie negativen Raum in Richtung der Hauptbewegung. Wenn sich eine Figur von links nach rechts bewegt, vermeiden Sie es, sie in der Mitte zu positionieren – platzieren Sie sie leicht nach rechts, um Raum für die Bewegung zu lassen. Wenn die Kamera nach links fährt, stellen Sie sicher, dass die linke Seite des Bildausschnitts visuell ansprechende Inhalte enthält.
Komponieren Sie Ihre Aufnahmen entsprechend der Kamerarichtung. Push-Aufnahmen sind am effektivsten, wenn das interessanteste Detail die Bildmitte einnimmt. Bei Schwenkaufnahmen muss das gesamte Bild visuell interessant sein. Für kreisförmige Kamerafahrten eignen sich eher dreidimensionale Motive mit Tiefe als flache Motive.
Vermeiden Sie komplexe symmetrische Kompositionen. Perfekte Symmetrie kann zwar in Fotos beeindruckend wirken, stellt jedoch eine Herausforderung für die Videogenerierung dar. KI hat Schwierigkeiten, eine präzise Symmetrie zwischen den Einzelbildern aufrechtzuerhalten, was zu störenden Bildverwacklungen führt. Asymmetrische Kompositionen mit einem natürlichen visuellen Fluss sorgen für flüssigere Videos.
Tiefenhinweise einbeziehen. Bilder mit sich überlappenden Elementen in unterschiedlichen Entfernungen – Objekte im Vordergrund, Motive im Mittelgrund und Umgebungen im Hintergrund – liefern der KI Tiefeninformationen, was zu verbesserten Parallaxeneffekten und natürlicheren Kamerabewegungen führt.
Eine umfassende Anleitung zum Entwerfen von Bildern speziell für Videos finden Sie im Leitfaden zum Entwerfen des ersten und letzten Bildes.
Technik 3: Behalten Sie während des gesamten Prozesses einheitliche Seitenverhältnisse bei.
Nicht übereinstimmende Seitenverhältnisse zwischen Bildern und Videobildern stellen einen der häufigsten Pipeline-Fehler dar, der unweigerlich zu einer Verschlechterung der Ausgabequalität führt.
- 16:9 für Videos im Querformat (YouTube, Präsentationen, Landingpages von Websites)
- 9:16 für Videos im Hochformat (TikTok, Instagram Reels, YouTube Shorts)
- 1:1 für quadratische Videos (Instagram Stories, bestimmte Social-Media-Anzeigen)
Legen Sie das Seitenverhältnis während der Bilderzeugung fest, anstatt dies erst in der Videophase zu tun. Wenn Sie ein quadratisches Bild im Verhältnis 1:1 erzeugen und dann versuchen, ein Video im Verhältnis 16:9 zu erstellen, muss das Videomodell die Seiten von Grund auf neu ausfüllen – und die Qualität dieses erzeugten Inhalts ist schlechter als die des restlichen Bildes. Erzeugen Sie Bilder von Anfang an entsprechend dem Seitenverhältnis des endgültigen Videos.
Tipp 4: Behalten Sie einen einheitlichen Stil für Eingabeaufforderungen über alle Phasen hinweg bei.
Die stilistischen Schlüsselwörter in Bild-Prompts und die Bewegungshinweise in Video-Prompts sollten dieselbe visuelle Sprache sprechen. Jede Unstimmigkeit zwischen beiden führt zu subtilen Qualitätsproblemen im Endergebnis.
Wenn Ihre Bildvorgabe „filmische, dramatische Beleuchtung, stimmungsvolle Atmosphäre“ enthält, sollte die Videobewegungsvorgabe eine kompatible Sprache verwenden: „filmische Kamerabewegung, dramatische Atmosphäre, stimmungsvolles Tempo“. Vermeiden Sie es, dramatische, filmische Bilder mit Bewegungsvorgaben wie „verspielt, lebhaft, energiegeladen“ zu kombinieren – tonale Konflikte verwirren das Modell und verringern die Kohärenz.
Schnellreferenz – Stilabgleichstabelle:
| Bildstil | Passende Bewegungsanweisung Sprache |
|---|---|
| Filmisch, dramatisch | „Filmische Kamerabewegung, dramatisches Tempo, langsam und bedächtig“ |
| Hell, kommerziell, klar | „Flüssige, professionelle Bewegung, gleichmäßiges Tempo, klare Übergänge“ |
| Verträumt, ätherisch, sanft | „Sanfte, schwebende Bewegungen, verträumte Atmosphäre, langsames Dahingleiten“ |
| Energiegeladen, dynamisch | „Dynamische Kamerabewegungen, energiegeladenes Tempo, schnelle Schnitte“ |
| Dokumentarisch, natürlich | „Handkamera-Feeling, natürliche Bewegungen, beobachtendes Tempo“ |
Tipp 5: Speichern Sie Ihre besten Pipeline-Vorlagen
Wenn eine Pipeline aus Eingabeaufforderung → Bild → Video zu zufriedenstellenden Ergebnissen führt, speichern Sie die gesamte Pipeline:
- Bildaufforderung (Originaltext)
- Ausgewählte Stileinstellungen
- Einstellungen für die Bilderzeugung (Seitenverhältnis, Modell, Startwert usw.)
- Videoaufforderung
- Einstellungen für die Videoerzeugung (Dauer, Auflösung)
Diese Pipeline dient als Vorlage. Möchten Sie ähnliche Videos für verschiedene Produkte erstellen? Ersetzen Sie das Motiv in der Bildvorlage und generieren Sie das Video neu. Benötigen Sie verschiedene Szenen im gleichen Stil? Behalten Sie die Stil-Schlüsselwörter bei und tauschen Sie die Motivbeschreibung aus.
Im Laufe der Zeit werden Sie eine ausgereifte Bibliothek mit Pipelines aufbauen, die auf verschiedene kreative Ziele zugeschnitten sind: Produktwerbung, Social-Media-Inhalte, Markengeschichten, Film-B-Roll, Charakteranimation. Jedes neue Projekt beginnt auf einer bewährten Grundlage und nicht bei Null.
Vergleich alternativer Tools über verschiedene Phasen hinweg
Seedance bietet eine integrierte Pipeline, Sie können diesen Workflow jedoch auch mit separaten Tools erstellen. Nachfolgend finden Sie einen objektiven Vergleich der einzelnen Phasen.
Phase Eins: Prompt-Generierung
| Tool | Am besten geeignet für | Beschreibung |
|---|---|---|
| Seedance Image Prompt Generator | Integrierte Pipeline, 12 Stilvorlagen | 2 Credits pro Prompt. Direkte Ausgabe an das Seedance-Bildtool. |
| ChatGPT / GPT-4 | Individuelle Prompt-Erstellung | Erfordert manuelles Kopieren und Einfügen. Keine Stilvorlagen. Flexibler für komplexe Anweisungen. |
| Claude | Ausgefeilte, detaillierte Prompts | Hervorragend geeignet für die Ausführung komplexer kreativer Briefings. Keine Integration der Bildgenerierung. |
| Tongyi Qianwen | Optimiert für chinesische Kontexte | Natürlicheres Verständnis chinesischer Beschreibungen. Geeignet für inländische Nutzer. Erfordert manuelle Integration mit nachgelagerten Tools. |
Phase Zwei: Bilderzeugung
| Tool | Am besten geeignet für | Anmerkungen |
|---|---|---|
| Seedance Text-to-Image / Image-to-Image | Pipeline-Integration, Video-First-Workflow | Bilder werden ohne Qualitätsverlust direkt in die Videoplattform übertragen. |
| Midjourney | Künstlerische Qualität, ästhetische Ausdruckskraft | Liefert hervorragende Ergebnisse. Erfordert die Bedienung über Discord oder eine Webschnittstelle. Kann manuell innerhalb von Pipelines heruntergeladen werden. |
| Tongyi Wanshang | Chinesisch-freundliche Eingabeaufforderungen, stabiler Zugriff innerhalb Chinas | Entwickelt von Alibaba, zeichnet sich durch ein hervorragendes Verständnis chinesischer Beschreibungen aus. Geeignet für Nutzer innerhalb Chinas ohne VPN. |
| DALL-E 3 | Prompt-Genauigkeit, textuelle Darstellung | Hervorragend geeignet für die wörtliche Ausführung komplexer Prompts. Begrenzte stilistische Kontrolle. |
| Stable Diffusion | Vollständige Kontrolle, lokale Generierung | Maximale Flexibilität. Erfordert die Einrichtung einer technischen Umgebung. Geeignet für Arbeiten mit hohem Volumen. |
Stufe 3: Videogenerierung
| Tool | Am besten geeignet für | Beschreibung |
|---|---|---|
| Seedance Image-to-Video | Integrierte Pipeline, gleichbleibende Qualität | Nahtlose Bildübertragung, direkte Unterstützung für First-Frame-Eingabe. |
| Kling 3.0 | Lange Dauer, hohe Qualität | Erzeugt bis zu 2 Minuten pro Durchlauf. Starke Bewegungsqualität. Von Kuaishou, innerhalb Chinas zugänglich. |
| Jimeng AI | Chinesisches Ökosystem, benutzerfreundlich | Von ByteDance, tief in das TikTok-Ökosystem integriert. Ideal für die Erstellung von Kurzvideos. |
| Runway Gen-4 | Präzise Steuerung, Bewegungsbürsten | Der Director-Modus unterstützt benutzerdefinierte Kamerawege. Professionelle Benutzeroberfläche. Höherer Preis. |
| Pika 2.0 | Einfache Einarbeitung, schnelles Experimentieren | Minimalistischste Benutzeroberfläche. Geeignet für Anfänger. Begrenzte Steuerung der Bewegungsdetails. |
Offen gesagt: Man könnte durchaus eine hochwertige Pipeline aufbauen, indem man ChatGPT für das Verfassen von Prompts, Midjourney für die Bilderzeugung und Keeling für die Videoproduktion nutzt. Viele Fachleute tun genau das. Der Vorteil von Seedance liegt nicht darin, dass es die Konkurrenz in einer einzelnen Phase übertrifft, sondern darin, dass es durch Integration Reibungsverluste beseitigt, die Qualität über alle Phasen hinweg aufrechterhält und drei separate Arbeitsabläufe zu einem einzigen zusammenführt. Für Kreative, die häufig KI-Videos produzieren, summiert sich die Zeitersparnis durch die Nutzung einer einzigen Plattform auf mehrere Stunden pro Woche.
Einen detaillierten Vergleich von Tools zur Videoerstellung finden Sie unter Best AI Video Generators 2026 Comparison.
Häufige Pipeline-Fehler
Im Folgenden sind die fünf häufigsten Fehler aufgeführt, die beim Einrichten einer Pipeline für Eingabeaufforderungen → Bilder → Videos auftreten können. Für jeden dieser Fehler gibt es eine einfache Lösung.
Fehler 1: Die Bildphase wird komplett übersprungen.
Spezifische Manifestation: Direkte Umwandlung von Text in Video unter vollständiger Umgehung der Bilderzeugung.
Warum das problematisch ist: Sie verlieren jegliche Kontrolle über die Komposition. Das Videomodell bestimmt alles – visuelle Inhalte, Bildausschnitt und Kamerastandorte. Die Ergebnisse sind unvorhersehbar, und die Wahrscheinlichkeit, dass sie beim ersten Versuch Ihren kreativen Vorstellungen entsprechen, ist gering.
So beheben Sie das Problem: Erstellen Sie immer ein Erstbild, auch wenn Sie glauben, dass Ihre Textvorlage ausreichend detailliert ist. Die 30 Sekunden, die Sie für die Erstellung eines Bildes benötigen, können Ihnen mehrere fehlgeschlagene Videogenerierungen ersparen.
Fehler 2: Verwendung von Stockbildern ohne Bewertung
Konkrete Ausprägung: Zufälliges Herunterladen eines Bildes aus dem Internet oder Auswahl eines Bildes aus einer Bilddatenbank, das dann direkt in den Videogenerierungsprozess eingefügt wird, ohne dessen Eignung als Eröffnungsbild zu prüfen.
Warum das problematisch ist: Viele Fotos sind für die statische Betrachtung konzipiert, nicht für Bewegungen. Der Bildausschnitt ist zu eng, sodass kein Spielraum für Kamerabewegungen bleibt. Die Motive sind zentriert, was die Gestaltungsmöglichkeiten einschränkt. Die Beleuchtung ist flach, was zu langweiligen Videoeffekten führt. Stark komprimierte JPEGs verursachen Artefakte.
So beheben Sie das Problem: Bevor Sie ein Bild verwenden, bewerten Sie es zunächst nach dem Prinzip „für Bewegung konzipiert”. Ein besserer Ansatz ist die Verwendung von Pipelines speziell zur Erzeugung eines Keyframes.
Fehler 3: Nicht übereinstimmendes Seitenverhältnis
Spezifische Erscheinungsformen: Erstellen von quadratischen Bildern und anschließendes Erstellen von Videos im Format 16:9 oder Verwenden von Querformatbildern zum Erstellen von Hochformatvideos.
Warum dies erhebliche Schäden verursacht: Videomodelle schneiden entweder Ihre Bilder zu (was zum Verlust Ihrer sorgfältig gestalteten Inhalte führt) oder füllen das neue Seitenverhältnis mit von Grund auf neu generierten Inhalten (wobei die hinzugefügten Ränder von geringerer Qualität sind).
So beheben Sie das Problem: Legen Sie vor der Erstellung der Bilder das endgültige Seitenverhältnis des Videos fest. Erstellen Sie die Bilder entsprechend diesem Seitenverhältnis.
Fehler 4: Zu ausführliche Videoanweisungen
Konkrete Darstellung: Die Videoanweisung beschreibt gleichzeitig sowohl die Szene als auch ihre Bewegung: „Eine Luxusuhr auf dunklem Marmor mit dramatischer Beleuchtung, die Kamera dreht sich langsam und Lichtreflexe tanzen über die Oberfläche.“
Warum das problematisch ist: Die visuelle Beschreibung kann im Widerspruch zum Bildinhalt stehen. Wenn die Uhr auf weißem Marmor abgebildet ist, die Eingabeaufforderung jedoch dunklen Marmor vorgibt, erhält das Modell widersprüchliche Signale. Im besten Fall wird die visuelle Beschreibung überflüssig, im schlimmsten Fall versucht das Modell, Ihren sorgfältig gestalteten ersten Frame zu verändern.
Erstellung: Video-Anweisungen sollten nur Bewegungen, Kamerawinkel und Atmosphäre beschreiben. Die visuellen Elemente wurden bereits als Bilder gerendert. Beachten Sie diesen Grundsatz: Bilder vermitteln „das, was man sieht“, während Video-Anweisungen „die Bewegung“ vorgeben.
Fehler 5: Überstürztes Erstellen von Videos, ohne die Bilder durchzugehen
Konkrete Ausprägung: Erzeugung eines Bildes und dessen direkte Einbindung in die Videogenerierung, selbst wenn es offensichtliche Mängel aufweist – wie beispielsweise eine leicht verzerrte Komposition, kleinere Unvollkommenheiten oder suboptimale Beleuchtung.
Warum die Auswirkungen größer sind: Videos vergrößern jeden Fehler im Ausgangsbild. Eine kleine Unvollkommenheit in einem Standbild wird zu einem dauerhaften, sich bewegenden Fehler über 120 Bilder hinweg. Eine leicht außermittige Komposition fällt deutlich ins Auge, wenn die Kamerabewegung die Aufmerksamkeit auf den Bildausschnitt lenkt. Jeder Fehler in einem Foto wird in einem Video deutlicher sichtbar, nicht weniger.
So beheben Sie das Problem: Behandeln Sie die Bildphase als Kontrollpunkt für die Qualitätskontrolle. Fahren Sie erst dann mit der Videophase fort, wenn das Bild wirklich zufriedenstellend ist. Wiederholen Sie diesen Vorgang 3–5 Mal. Verwenden Sie die Bild-zu-Bild-Generierung für gezielte Reparaturen. Die Videoausgabe darf die Qualität des Quellbildes nicht überschreiten.
Häufig gestellte Fragen
Warum Bildvermittlung verwenden, anstatt Text direkt in Video umzuwandeln?
Die Text-zu-Video-Erstellung erfordert, dass die KI gleichzeitig sowohl Bilder als auch Bewegungen aus Text generiert, was bedeutet, dass Sie nur minimale Kontrolle über Komposition, Aussehen der Figuren, Beleuchtung und Bildausschnitt haben. Der bildorientierte Ansatz trennt diese beiden Aufgaben: Sie verfeinern die Bildelemente während der Bildphase und weisen die KI dann ausschließlich an, Bewegungen hinzuzufügen. Dies führt zu vorhersehbareren Ergebnissen von höherer Qualität, da die KI konkrete visuelle Referenzen erhält, anstatt mehrdeutigen Text zu interpretieren. Der Unterschied ist besonders ausgeprägt in professionellen Szenarien, die bestimmte Kompositionen, Markenfarbenpaletten oder ein einheitliches Charakterdesign erfordern.
Wie sieht der gesamte Prozess zur Erstellung von KI-Videos von Grund auf aus?
Der gesamte Prozess umfasst drei Schritte. Schritt eins: Verwenden Sie einen KI-Prompt-Generator (z. B. den Image Prompt Generator von Seedance), um Ihr Konzept zu einem detaillierten Bild-Prompt zu erweitern. Schritt zwei: Verwenden Sie diesen Prompt in einem Text-zu-Bild-Tool (z. B. Text-to-Image von Seedance), um hochwertige Referenzbilder zu generieren, und wiederholen Sie den Vorgang, bis Sie zufrieden sind. Schritt 3: Laden Sie das Bild in einen Bild-zu-Video-Generator (z. B. Seedance's image-to-video) hoch, schreiben Sie eine Eingabeaufforderung, die nur die Bewegung (Kamerabewegung und Aktionen des Motivs) beschreibt, und generieren Sie das Video. Der gesamte Prozess dauert 5 bis 15 Minuten, je nachdem, wie viele Iterationen während der Bildphase erforderlich sind.
Wie viele Credits kostet die vollständige Pipeline auf Seedance?
Die Kosten variieren je nach Konfiguration, aber ein typischer Pipeline-Lauf umfasst in der Regel: Prompt-Generierung mit 2 Credits, Bildgenerierung mit 4–8 Credits pro Iteration (bei 3–5 Iterationen entspricht dies 12–40 Credits) und Videogenerierung mit 10–30 Credits (abhängig von Dauer und Auflösung). Vom Konzept bis zum fertigen Video liegen die Gesamtkosten in der Regel zwischen 25 und 70 Credits. Dies bedeutet eine erhebliche Einsparung im Vergleich zur Verwendung von drei separaten Tools mit drei separaten Abonnements.
Können mit anderen Tools erstellte Bilder verwendet werden, um Videos in Seedance zu erstellen?
Selbstverständlich. Das [Image-to-Video]-Tool von Seedance akzeptiert jedes hochgeladene Bild – es muss nicht von Seedance generiert worden sein. Sie können Bilder mit Midjourney, DALL-E, Tongyi Wanshang, Stable Diffusion oder einem anderen Tool erstellen und als ersten Frame hochladen. Der Vorteil der integrierten Pipeline besteht darin, dass der Schritt des Herunterladens und Hochladens entfällt, obwohl dies nicht zwingend erforderlich ist. Bei der Verwendung externer Bilder empfehlen wir das PNG-Format mit einer Auflösung von 1024x1024 oder höher, um zu verhindern, dass Kompressionsartefakte die Videoausgabe beeinträchtigen.
Welches Seitenverhältnis sollte für Bilder verwendet werden?
Stellen Sie immer sicher, dass das Seitenverhältnis Ihres Bildes mit der endgültigen Videoausgabe übereinstimmt. 16:9 für Querformatvideos (YouTube, Präsentationen, Website-Einbettungen), 9:16 für Hochformatvideos (TikTok, Instagram Reels, YouTube Shorts), 1:1 für quadratische Videos (Instagram-Feed, bestimmte Social-Media-Anzeigen). Erstellen Sie Bilder von Anfang an im richtigen Seitenverhältnis. Erstellen Sie keine quadratischen Bilder und erwarten Sie dann, dass Videotools diese in 16:9 konvertieren – dadurch wird entweder Ihre Komposition beschnitten oder es werden KI-generierte Inhalte an den Rändern hinzugefügt, was in beiden Fällen die Qualität beeinträchtigt.
Wie erstellt man Keyframe-Paare?
Erstellen Sie zwei Frames mit separaten Pipelines. Der erste Frame folgt dem Standard-Workflow: Prompts generieren, Bilder erstellen und so lange iterieren, bis das Ergebnis zufriedenstellend ist. Der letzte Frame verwendet Image-to-Image, wobei der erste Frame als Referenzbild hochgeladen und die Änderungen im Endzustand beschrieben werden. Dies gewährleistet visuelle Konsistenz – gleicher Ort, gleiche Lichtrichtung, gleiche Farbgebung – und erzielt gleichzeitig die gewünschte narrative Veränderung (unterschiedliche Zeiten, Aktivitäten oder Stimmungen). Laden Sie beide Frames in einen Videogenerator hoch und lassen Sie die KI den Übergang erstellen. Eine umfassende Anleitung zu dieser Technik finden Sie im First and Last Frame Design Guide.
Ist dieser Workflow für kommerzielle Inhalte geeignet?
Geeignet. Die dreistufige Pipeline wird von E-Commerce-Marken für Produktvideos, Marketingteams für Werbematerialien, Immobilienfirmen für Immobilienpräsentationen und Content-Agenturen für die Produktion von Social-Media-Inhalten genutzt. KI-generierte Videos von 5 bis 15 Sekunden Länge mit hochwertigen Eröffnungsbildern entsprechen nun den professionellen Standards für digitale Inhalte. Der Schlüssel zum kommerziellen Erfolg liegt in der Investition von Zeit in die Bildphase – ein ausgefeiltes Eröffnungsbild führt direkt zu einem ausgefeilten Video. Bei längeren Laufzeiten oder kommerziellen Inhalten in Broadcast-Qualität wird KI-Video zunehmend für kreative Ideen und die Visualisierung von Vorschauen eingesetzt, wobei die endgültige Produktion weiterhin mit traditionellen Methoden erfolgt, um maximale Kontrolle zu gewährleisten.
Was sollte man tun, wenn das erzeugte Bild Mängel aufweist?
Fahren Sie nicht mit der Videogenerierung fort. Unvollkommenheiten im Ausgangsbild werden im Video verstärkt – eine leicht verzerrte Hand in einem statischen Bild wird zu einer deutlich deformierten Hand in einer Bewegungssequenz mit 120 Bildern. Bearbeiten Sie das Bild vorab. Verwenden Sie [image-to-image], um problematische Bereiche neu zu generieren und dabei den Rest der Komposition beizubehalten. Bei schwerwiegenden Mängeln (verformte menschliche Figuren, unplausible Geometrien) generieren Sie das Bild mit einer geänderten Eingabeaufforderung vollständig neu, um das Problem zu umgehen. Zu den Elementen, die anfällig für Fehler sind, gehören Hände (geben Sie „Hände an den Seiten“ oder „Hände in den Taschen“ an, um komplexe Fingerhaltungen zu vermeiden), Text (vermeiden Sie Text in generierten Bildern) und Reflexionen (vereinfachen Sie reflektierende Oberflächen in Eingabeaufforderungen). Fahren Sie erst mit der Videoproduktion fort, wenn das Bild fehlerfrei ist.
Beginnen Sie mit dem Aufbau Ihrer kreativen Pipeline
Die dreistufige Pipeline – Eingabe → Bild → Video – ist auch im Jahr 2026 noch die zuverlässigste Methode zur Erstellung hochwertiger KI-Videos. Sie trennt die erforderliche kreative Kontrolle (wie die Szene aussehen soll) von der gewünschten Generierungsfähigkeit (wie sie sich bewegen soll), sodass Videos entstehen, die Ihrer Vision entsprechen und nicht zufälligen Vermutungen der KI.
Jedes gute Video beginnt mit einem guten Bild. Jedes gute Bild beginnt mit einer guten Vorgabe. Lege eine gute Grundlage, dann ergibt sich alles andere von selbst.
Schritt 1: Prompts generieren → – Verwandeln Sie Konzepte mit dem KI-Prompt-Generator von Seedance in professionelle Bild-Prompts.
Schritt 2: Bild generieren → – Generieren Sie den perfekten Eröffnungsframe für Ihr Video und verfeinern Sie ihn schrittweise.
Schritt 3: Video erstellen → – Verwandeln Sie Bilder in dynamische Videos mit Bewegung, Kamerawinkeln und Atmosphäre.
Die Technik des ersten Bildes meistern → – Übernehmen Sie die Kontrolle über Ihre KI-Videoproduktion, indem Sie lernen, wie Sie Referenzbilder gestalten.
Weiterführende Literatur: Image-to-Video AI Guide | First and Last Frame Design Guide | Text-to-Image AI Complete Guide | Leitfaden zu Bild-zu-Bild-KI | Leitfaden zum KI-Bildpromptgenerator | Die besten KI-Bildgeneratoren 2026 | Die besten KI-Videogeneratoren für 2026*
