
Em resumo
A IA Text-to-Video é uma tecnologia de inteligência artificial que gera automaticamente vídeos a partir de descrições textuais. Basta inserir uma descrição e a IA produz um videoclipe com movimento, efeitos de iluminação e movimentos de câmara. Até 2026, aproveitando a arquitetura Diffusion Transformer (DiT), esta tecnologia evoluiu de um protótipo experimental impreciso para uma qualidade quase cinematográfica. Este guia abrange os princípios técnicos, um tutorial prático de 5 etapas, 10 modelos de prompts replicáveis, uma análise comparativa de 8 ferramentas, 6 cenários de aplicação principais e as limitações reais que deve compreender. Experimente a geração de texto para vídeo gratuitamente →

IA de texto para vídeo: a partir de uma única descrição, a IA transforma o texto em imagens com qualidade cinematográfica, tornando o conceito de «texto para vídeo» uma realidade.
O que é IA de texto para vídeo?
A IA de texto para vídeo refere-se a uma categoria de tecnologia de inteligência artificial que gera automaticamente conteúdo de vídeo a partir de descrições textuais. Descreve uma cena — uma mulher a passear na chuva, um produto a girar num expositor, um drone a sobrevoar cadeias montanhosas — e o modelo de IA produz um videoclipe altamente realista com movimentos naturais, iluminação e efeitos físicos.
O conceito central é simples: entrada de texto, saída de vídeo. No entanto, a tecnologia subjacente está longe de ser simples. Os sistemas modernos de conversão de texto em vídeo empregam redes neurais treinadas em bilhões de conjuntos de dados emparelhados de «vídeo-texto», aprendendo as relações estatísticas entre descrições linguísticas e movimento visual. Quando escreve «um gato salta para cima de uma mesa», o modelo recorre ao seu conhecimento acumulado sobre gatos, a física do salto, superfícies de mesa e gravidade para gerar um vídeo plausível.
2026: Da experiência à ferramenta de produtividade
A IA de texto para vídeo ultrapassou o limiar da capacidade de «prontidão para produção» em 2025-2026. Os primeiros sistemas de 2022-2023 só conseguiam produzir fragmentos fugazes, desfocados e fisicamente implausíveis. Os modelos atuais, no entanto, geram vídeos com resolução 2K com visuais fisicamente precisos, animados naturalmente e com qualidade cinematográfica, com duração de 5 a 15 segundos. Este salto transforma a tecnologia de conversão de texto em vídeo de uma curiosidade de investigação numa ferramenta prática:
- Criadores de conteúdo: Obtenha B-roll, sequências introdutórias e recursos para redes sociais sem uma câmara
- Profissionais de marketing: Produza em massa variantes de publicidade e demonstrações de produtos
- Educadores: Visualize conceitos abstratos
- Pequenas e médias empresas: Evite os altos custos da produção profissional de vídeo
- Qualquer pessoa: Se você sabe escrever, você sabe fazer vídeos
O limiar para a criação de vídeos baixou de «ter uma câmara e saber editar» para «criar uma descrição atraente».
Evolução tecnológica: de GAN para DiT
Compreender a tecnologia subjacente pode ajudá-lo a criar prompts melhores e selecionar ferramentas mais adequadas. Abaixo está a evolução tecnológica de três gerações da IA de texto para vídeo.

Três gerações de evolução tecnológica: GANs (2020–2022) → Modelos de difusão (2023–2024) → Transformadores de difusão / DiT (2025–2026).
Primeira geração: a era GAN (2020–2022)
As Redes Adversárias Generativas (GANs) foram a primeira arquitetura a demonstrar a viabilidade da geração de «texto para vídeo». Duas redes neurais passam por um treinamento adversário — o gerador cria quadros de vídeo enquanto o discriminador julga a sua autenticidade. No entanto, os resultados eram de baixa resolução (256×256), curta duração (2–4 segundos) e fisicamente implausíveis. Os objetos sofrem deformações imprevisíveis, as características faciais ficam distorcidas e a consistência temporal é severamente comprometida. Realizações representativas incluem CogVideo e NUWA.
Segunda geração: a era dos modelos de difusão (2023–2024)
O modelo de difusão revolucionou o panorama. Ele não emprega mais o treinamento adversário, mas aprende um processo de «reversão de ruído» — começando com ruído puro e, progressivamente, removendo o ruído para criar um vídeo coerente sob orientação textual. Essa abordagem proporciona um salto qualitativo: maior resolução (até 1080p), maior duração (4 a 10 segundos) e melhor alinhamento visual-textual.
O Sora da OpenAI (lançado em fevereiro de 2024) demonstra que os modelos de difusão podem gerar vídeos surpreendentemente fotorrealistas. Runway Gen-2/Gen-3, Pika e Stable Video Diffusion pertencem todos a esta geração.
Terceira geração: DiT — Transformador de difusão (2025–2026)
As arquiteturas mais avançadas atualmente combinam processos de difusão com a arquitetura Transformer (a mesma arquitetura por trás do GPT e do BERT). Os modelos DiT processam o vídeo como uma sequência de patches espaço-temporais, alcançando:
- Consistência temporal melhorada: os transformadores são excelentes na modelação de dependências de longo alcance entre fotogramas
- Maior resolução: Saída nativa 2K (Seedance 2.0 atinge 2048×1080)
- Maior precisão física: Movimento, gravidade e dinâmica de fluidos mais realistas
- Compreensão de texto mais forte: Alinhamento significativamente melhorado entre descrições de prompt e saídas visuais
- Entrada multimodal: Certos modelos DiT podem aceitar simultaneamente entradas de imagem, vídeo e áudio
O Seedance 2.0, o Google Veo 3 e o Keeling 3.0 utilizam a arquitetura DiT. É por isso que a geração de texto para vídeo em 2026 apresenta uma diferença qualitativa em comparação com a de 2024.
Texto para vídeo vs. imagem para vídeo
Estas duas abordagens são complementares, e não concorrentes:
| Dimensão | Texto para vídeo (T2V) | Imagem para vídeo (I2V) | |------|------------------|----------------- -| | Entrada | Apenas descrição textual | Fotografia + descrição de movimento | | Liberdade criativa | Máxima — a IA determina todos os elementos visuais | Limitada pela imagem de origem | | Controlabilidade | Menor — depende da precisão do prompt | Maior — âncoras visuais disponíveis | | Cenários adequados | Exploração de conceitos, conteúdo original | Exibição de produtos, animação de fotos, correspondência de estilos | | Previsibilidade | Baixa — O mesmo prompt produz resultados diferentes a cada vez | Alta — A saída corresponde consistentemente à imagem original |
A maioria dos fluxos de trabalho profissionais utiliza ambas as abordagens: primeiro empregando T2V para explorar conceitos criativos e, em seguida, refinando o resultado com I2V para um controlo preciso. Para uma exploração detalhada da geração de imagem para vídeo, consulte o nosso Guia Completo de IA de Imagem para Vídeo.
Tutorial em 5 passos: criando o seu primeiro vídeo com IA
A seguir, apresentamos um guia passo a passo para gerar conteúdo de texto para vídeo a partir do zero, usando o Seedance 2.0 como plataforma de demonstração. Os princípios básicos aplicam-se a qualquer ferramenta.

Da criação imediata à produção final: cinco etapas para concluir o seu primeiro vídeo com IA.
Passo 1: Defina os objetivos do vídeo
Antes de escrever o prompt, determine primeiro:
- Tipo: Filmagens B-roll, demonstrações de produtos, conteúdo de redes sociais, criações artísticas ou narração?
- Duração: 5 segundos para testes, 10-15 segundos para o resultado final
- Proporção da imagem: 16:9 para YouTube / Bilibili, 9:16 para Douyin / Kuaishou / Xiaohongshu, 1:1 para WeChat Moments
- Estilo: Cinematográfico, documentário, animação, anúncio comercial ou artístico
Definir objetivos claros evita o desperdício de quotas de geração em experiências ambíguas.
Passo 2: Criar prompts de texto de alta qualidade
O prompt é a essência da geração de texto para vídeo. Utilize a seguinte fórmula:
[Assunto] + [Ação/Movimento] + [Cenário] + [Estilo] + [Movimento da câmara] + [Iluminação]
Prompt inadequado: «Um cão a correr»
Boa sugestão: «Um golden retriever a correr por um prado ensolarado, flores silvestres a balançar com a brisa. O pêlo do cão ondula a cada passo. A câmara acompanha ao nível do solo. Iluminação quente da hora dourada com sombras longas. Profundidade de campo cinematográfica, qualidade 4K."
Princípios fundamentais:
- O movimento deve ser específico: «vira lentamente a cabeça» em vez de «vira»
- Descreva os movimentos da câmara: «a câmara aproxima-se» ou «imagem aérea com drone»
- Defina a atmosfera: Iluminação, gradação de cores, ambiente
- Evite contradições: Não solicite simultaneamente «ação rápida» e «câmera lenta»
- Não solicite texto/IU: O modelo atual tem dificuldade em renderizar texto legível dentro de imagens de vídeo
Observação: É aconselhável formular prompts em inglês, mesmo ao utilizar ferramentas nacionais (como KeLing, TongYi WanXiang ou Hunyuan Video). Isso porque a maioria dos modelos foi treinada com conjuntos de dados mais extensos em inglês.
Para um sistema de técnicas de prompt mais abrangente, consulte o Guia de Redação de Prompts e 10 Prompts de Vídeo de IA Realmente Eficazes.
Passo 3: Selecione Ferramentas e Parâmetros
Selecione uma plataforma (consulte a tabela comparativa abaixo) e, em seguida, configure:
- Modelo: Utilize o modelo mais recente disponível (por exemplo, Seedance 2.0, não 1.0)
- Resolução: Mínimo 1080p; opte por 2K, quando disponível
- Duração: Teste inicialmente com 5 segundos, prolongue se for satisfatório
- Proporção da imagem: Corresponde à sua plataforma de distribuição
- Valor inicial (se disponível): Bloqueie o valor inicial para uma iteração consistente
Passo 4: Gerar e rever
Clique em Gerar e aguarde entre 60 e 180 segundos (dependendo da ferramenta). Ao analisar o resultado, preste atenção ao seguinte:
- ✅ O movimento corresponde à descrição?
- ✅ O assunto é consistente ao longo do vídeo (sem distorção)?
- ✅ A física é plausível (gravidade, fluidos, tecidos)?
- ✅ O movimento da câmara é fluido?
- ❌ Existem artefactos, cintilação ou distorção?
- ❌ Existe um efeito de vale misterioso nos rostos/mãos?
Passo 5: Otimização iterativa
A primeira tentativa raramente é perfeita. Métodos de otimização:
- Ajuste o prompt: Adicione detalhes onde a IA errou
- Altere apenas uma variável de cada vez: Não reescreva o prompt inteiro
- Experimente com diferentes sementes: O mesmo prompt pode produzir resultados totalmente diferentes
- Aumente a duração: Quando estiver satisfeito com a versão de 5 segundos, tente 10 a 15 segundos
- Incorpore áudio: Se for compatível com a ferramenta (Seedance, Veo 3), adicione efeitos sonoros ou música de fundo

Exemplos de iteração rápida: V1 (prompt base) → V2 (adicionando descrições de movimento e iluminação) → V3 (especificações cinematográficas completas). Cada ciclo de refinamento melhora significativamente a qualidade da imagem.
10 modelos de prompts para geração de texto para vídeo
Os modelos a seguir podem ser copiados e usados diretamente. Eles foram testados no Seedance 2.0 e são compatíveis com a maioria das plataformas convencionais.
1. Retrato cinematográfico
A close-up of a young woman with flowing dark hair, her face illuminated by warm golden hour sunlight filtering through a window. She slowly turns her head toward the camera, a subtle smile forming. Soft bokeh background of a cozy interior. Camera holds steady with a slight push-in. Warm amber lighting, shallow depth of field, 4K cinematic quality.
Cenários adequados: Redes sociais, marca pessoal, criação artística
- Vitrine de produtos
A sleek wireless headphone rotating slowly on a matte black pedestal. Soft studio lighting creates clean highlights on the brushed metal surface. Camera orbits 180 degrees at eye level. Minimalist white background, no shadows. Smooth continuous motion, commercial product photography quality.
Cenários adequados: Páginas de detalhes de produtos de comércio eletrónico, marketing de produtos, vídeos de imagens principais do Taobao/JD.com
- Natureza Cinematográfica
An epic aerial drone shot over a misty mountain valley at sunrise. Golden light breaks through layered clouds, illuminating a winding river below. Camera pushes forward slowly, revealing the vast landscape. Volumetric fog drifts between peaks. IMAX cinematography quality, hyper-detailed.
Adequado para: vídeos de introdução do YouTube/Bilibili, conteúdo de viagens, protetores de ecrã, canais de meditação
4. Rua urbana
A neon-lit Tokyo alley at night after rain. Wet cobblestones reflect vivid pink, teal, and amber neon signs. A lone figure walks away from camera, umbrella in hand. Steam rises from a street vent. Camera follows at a distance, tracking shot. Film noir atmosphere, anamorphic lens flare.
Cenários adequados: Vídeos musicais, filmagens atmosféricas de B-roll, conteúdo no estilo cyberpunk
- Estilo Anime
An anime warrior princess with flowing silver hair stands on a cliff edge overlooking a fantasy kingdom. Her cape billows dramatically in the wind. She raises a glowing sword that emits blue energy particles. Cherry blossom petals drift past. Camera slowly orbits. Studio Ghibli meets Ufotable quality animation.
Adequado para: Conteúdo animado, canais de jogos, narrativas de fantasia
6. Alimentos e bebidas
Extreme macro close-up of rich dark coffee being poured in slow motion into a pristine ceramic cup. Individual droplets and tiny splashes frozen mid-air. Wisps of steam curl elegantly upward. Warm side lighting reveals the liquid's amber transparency. Cinnamon stick and scattered beans visible in soft focus foreground.
Cenários adequados: Marketing de alimentos e bebidas, blogueiros de culinária, publicidade de bebidas
- Moda e Editorial
A model in a flowing white silk gown walks confidently down a dark runway. Multiple flash strobes create sharp geometric light patterns. The fabric billows with perfect physics. Camera at a low angle, slight slow motion. High fashion editorial aesthetic, Vogue magazine quality.
Cenários adequados: Marcas de moda, conteúdo de beleza, artigos editoriais
- Ficção científica e fantasia
A massive spaceship emerges from hyperspace above a ringed planet. Blue energy dissipates around the hull as the vessel decelerates. Tiny fighter escorts flank its sides. Camera pulls back to reveal the scale against the planet. Volumetric space dust and distant star field. Hollywood VFX quality.
Cenários adequados: Conteúdo de entretenimento, canais de ficção científica, visualização de conceitos
- Desporto e ação
A basketball player at the peak of a slam dunk, frozen in mid-air. Time resumes in slow motion — sweat droplets fly, the ball compresses against the rim, arena spotlights create dramatic lens flare. Camera shoots from below looking up. ESPN broadcast quality, hyper-detailed.
Adequado para: Conteúdo desportivo, marcas desportivas, compilações de destaques
- Arte Abstrata (Abstrato e Artístico)
Liquid gold and deep indigo ink collide in slow motion inside a glass sphere. The fluids intertwine in mesmerizing fractal patterns. Tiny bubbles catch light. Camera slowly rotates around the sphere. Pure black background. Macro photography meets fluid dynamics simulation. Meditative, hypnotic pace.
Cenários adequados: Imagens de fundo, videoclipes, instalações artísticas, protetores de ecrã

O resultado real de quatro dos dez modelos acima — cada prompt gera visuais com estilo distinto e qualidade cinematográfica a partir de texto simples.
Resumo de 2026: comparação entre 8 ferramentas de conversão de texto em vídeo
Testámos oito plataformas populares usando o mesmo prompt («Um golden retriever a correr por um prado ensolarado, flores silvestres a balançar, qualidade cinematográfica 4K»), classificando-as em cinco dimensões. Todos os testes foram concluídos em fevereiro de 2026.
| Ferramenta | Resolução máxima | Duração máxima | Versão gratuita | Áudio | Melhor uso | Classificação da qualidade da imagem | |------|----------|---------|--------|------|-------- -|---------| | Seedance 2.0 | 2K (2048×1080) | 15 segundos | ✅ Quota diária gratuita | ✅ Efeitos sonoros + música + sincronização labial | Criação multimodal | 9,2/10 | | Google Veo 3 | 4K (limitado) | 8 segundos | ✅ Quota do AI Studio | ✅ Áudio nativo | Fusão audiovisual | 9,0/10 | | Sora 2 | 1080p | 20 segundos | ❌ Requer ChatGPT Plus | ❌ | Vídeo orientado por texto longo | 8,8/10 | | Keling 3.0 | 1080p | Mais de 20 segundos | ✅ Créditos de inscrição gratuitos | ⚠️ Limitado | Vídeos longos, boa relação custo-benefício | 8,5/10 | | Runway Gen-4 | 1080p | 10 segundos | ✅ 125 créditos | ❌ | Fluxo de trabalho de edição profissional | 8,5/10 | | Pika 2.0 | 1080p | 10 segundos | ✅ Quota diária gratuita | ⚠️ Apenas efeitos sonoros | Iniciantes, efeitos divertidos | 8,0/10 | | Luma Dream Machine | 1080p | 5 segundos | ✅ Geração gratuita | ❌ | Cenas 3D, iteração rápida | 7,8/10 | | Snail AI (MiniMax) | 1080p | 6 segundos | ✅ Gratuito diariamente | ❌ | Velocidade de geração mais rápida | 7,5/10 |
Aviso importante para utilizadores domésticos: Seedance 2.0, KeLing 3.0 e Haier AI são diretamente acessíveis na China continental. O Sora 2 requer uma subscrição do ChatGPT Plus (VPN necessária). O Google Veo 3 requer acesso através do Google AI Studio (VPN necessária). Runway, Pika e Luma requerem uma ligação de rede internacional.
Alternativas nacionais: Tongyi Wanshang (Alibaba), Hunyuan Video (Tencent) e Qingying (subsidiária da ByteDance) também oferecem recursos de geração de texto para vídeo, com cotas de uso gratuito variáveis.
Conclusões principais:
- Melhor qualidade de imagem geral: Seedance 2.0 (2K nativo + entrada quad-mode + áudio)
- Recursos de áudio mais potentes: Seedance 2.0 e Google Veo 3
- Melhor versão gratuita: Seedance 2.0 (acesso gratuito à resolução 2K, sem necessidade de cartão de crédito)
- Vídeo gratuito mais longo: Keeling 3.0 (mais de 20 segundos)
- Mais adequado para iniciantes: Pika 2.0 (interface mais simples, efeitos divertidos)
Para uma comparação mais detalhada, consulte A comparação completa dos melhores geradores de vídeo com IA para 2026. Para se concentrar exclusivamente nos planos gratuitos, consulte Uma análise comparativa dos geradores de vídeo com IA gratuitos.
6 Cenários de aplicação principais
- Conteúdo das redes sociais
Crie vídeos curtos atraentes para o Douyin, Kuaishou, Xiaohongshu, Bilibili e YouTube Shorts. A IA elimina totalmente a necessidade de filmagem, edição e pós-produção.
Especificações recomendadas: proporção de 9:16, duração de 5 a 15 segundos, com uma abertura visualmente impactante no primeiro segundo.
- Marketing e publicidade
Produza em massa variantes de material publicitário. Teste vários conceitos visuais utilizando diferentes sugestões antes de se comprometer com o orçamento formal de produção. Gere versões de teste A/B em poucos minutos.
Configuração recomendada: Compatibilidade multiformato em várias plataformas. Combine com os recursos de áudio do Seedance para produzir filmes publicitários completos.
3. Educação e Formação
Visualizar conceitos abstratos que são difíceis ou impossíveis de capturar: estruturas moleculares, eventos históricos, conceitos matemáticos, processos científicos. O vídeo de IA torna o invisível visível.
Configuração recomendada: Para obter os melhores resultados no ensino, use instruções que descrevam os conceitos com precisão, juntamente com gravações de áudio narradas.
- Entretenimento e narrativa
Cineastas independentes e criadores de histórias utilizam a tecnologia de conversão de texto em vídeo para visualização de conceitos, storyboards e até mesmo a produção final de curtas-metragens. Essa tecnologia democratiza a produção cinematográfica.
Configuração recomendada: Inclua especificações detalhadas sobre a direção da câmara e a iluminação na instrução para obter qualidade cinematográfica.
- Vídeos de produtos de comércio eletrónico
Transforme descrições de produtos em vídeos de demonstração de produtos. Isso é particularmente valioso para retalhistas com centenas de SKUs que não podem filmar vídeos individuais para cada produto. Para fluxos de trabalho detalhados de comércio eletrónico, consulte o Guia de Vídeos de Comércio Eletrónico com IA.
Especificações recomendadas: Fotografia do produto com configuração de iluminação de estúdio. Proporção 1:1 para páginas de detalhes do produto, 16:9 para YouTube/Bilibili, 9:16 para TikTok/Xiaohongshu.
6. Criação de conteúdo para YouTube/Bilibili
Crie imagens B-roll, sequências introdutórias, comentários visuais e vídeos curtos completos. Os criadores podem melhorar a eficiência da produção de conteúdo com o vídeo AI. Para conhecer todo o fluxo de trabalho do criador do YouTube, consulte o Guia do criador do YouTube para vídeo AI.
Configuração recomendada: mantenha a consistência visual entre os canais em cada prompt para estabelecer o reconhecimento da marca.
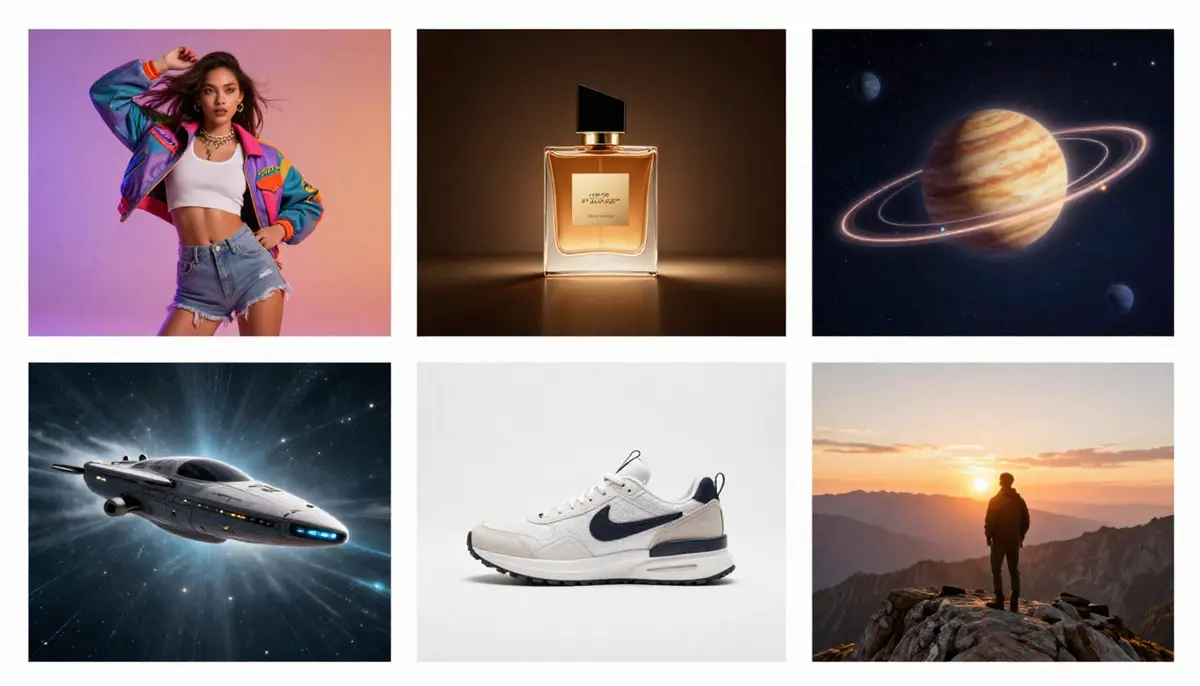
Seis aplicações práticas da IA de texto para vídeo: de vídeos curtos nas redes sociais a demonstrações de produtos de comércio eletrónico e visualização de conceitos educativos.
Texto para vídeo vs. imagem para vídeo: quando usar cada um?
Esta é uma das perguntas mais frequentes dos novos utilizadores. A resposta depende dos materiais que você tem disponíveis e do que você precisa.

Dois caminhos para o vídeo com IA: a geração de texto para vídeo começa a partir do texto, enquanto a geração de imagem para vídeo começa com fotografias existentes.
Cenários para Texto para Vídeo (T2V):
- Está a criar conteúdo totalmente novo (sem imagens de referência)
- Você deseja liberdade criativa máxima
- Você está a realizar uma exploração de conceitos ou um brainstorming visual
- Você precisa de cenas abstratas ou impossíveis de filmar (ficção científica, fantasia, microscópicas/macroscópicas)
- Você deseja iterar rapidamente — alterar um prompt gera uma cena completamente diferente
Cenários para gerar vídeos a partir de imagens (I2V):
- Possui uma fotografia específica que requer animação
- Necessita de um resultado que corresponda exatamente aos efeitos visuais existentes
- Está a converter imagens de produtos em vídeos de produtos
- Necessita de consistência nas personagens (a mesma pessoa em todas as cenas)
- Deseja resultados mais previsíveis e controláveis
Melhor prática — Combinar ambas as abordagens:
- Utilizar a geração de texto para vídeo para explorar direções criativas
- Selecionar o quadro ideal como imagem de referência
- Empregar a geração de imagem para vídeo para obter uma versão final refinada e controlável
Para um fluxo de trabalho abrangente de geração de imagem para vídeo, consulte o Guia completo para IA de imagem para vídeo.
Limitações atuais — Uma avaliação honesta
A IA de conversão de texto em vídeo de 2026 é impressionante, mas está longe de ser perfeita. Abaixo estão as áreas em que ela atualmente se destaca e aquelas que continuam sendo um desafio.
Muito bem!
- Vídeos curtos (5-15 segundos): Visuais com qualidade cinematográfica
- Cenas com um único tema: Uma pessoa, um animal, um objeto — resultados excelentes
- Natureza e paisagens: Renderização excecional de dinâmica de fluidos, clima e efeitos atmosféricos
- Conteúdo estilizado: Animação, filme noir, ficção científica — conversão de estilo altamente fiável
- Exibições de rotação de produtos: Movimento simples do produto com boa consistência
- Movimentos da câmara: Panorâmica, zoom, dolly, travellings — bem controlados
Ainda difícil
- Mãos e dedos: Dedos em excesso, gestos implausíveis e deformidades nos dedos continuam a ser comuns
- Renderização de texto: O texto legível nas imagens de vídeo revela-se pouco fiável — as letras aparecem distorcidas, os caracteres deformados
- Interações complexas entre várias pessoas: Aperto de mão entre duas pessoas, dança em conjunto ou combate frequentemente apresentam desorganização dos membros
- Narrativa prolongada (>30 segundos): A manutenção da consistência da cena durante períodos prolongados degrada-se
- Física precisa: Queda precisa de uma bola, água a ser despejada em recipientes específicos — a física é aproximada, não exata*⦁NLBR⦁* Consistência facial a longo prazo: As características faciais podem sofrer alterações subtis entre os fotogramas, especialmente em períodos prolongados.
Tendência de progresso
Cada uma dessas limitações será significativamente melhorada até 2026 em comparação com 2024. O ritmo de melhoria é exponencial. A renderização manual progredirá de «sempre incorreta» para «geralmente precisa». A consistência facial mudará de «começa a desviar-se após 2 segundos» para «permanece estável por 10 a 15 segundos». A renderização de texto avançará de «ilegível» para «ocasionalmente legível». Espera-se que estas questões continuem a melhorar rapidamente em 2026-2027.
Perguntas frequentes
Qual é a melhor IA de conversão de texto em vídeo para 2026?
O Seedance 2.0 lidera em qualidade geral de imagem com resolução nativa de 2K, entrada quad-modal e geração de áudio integrada. O Google Veo 3 se destaca na fusão audiovisual e simulação física. O Sora 2 oferece a maior duração de geração única (20 segundos). A escolha "melhor" depende dos seus requisitos específicos — resolução, áudio, duração ou preço. Os utilizadores domésticos também podem considerar o KeLing 3.0 (alta relação custo-benefício, vídeos longos) e o Tongyi Wanxiang (integrado ao ecossistema Alibaba).
Existe alguma IA gratuita para converter texto em vídeo?
Sim. O Seedance 2.0 oferece uma cota diária gratuita sem exigir cartão de crédito. O Pika 2.0 oferece geração diária gratuita. O Keiling 3.0 concede uma cota de inscrição. O Google Veo 3 oferece cotas gratuitas através do AI Studio. O Conch AI também oferece uma cota diária gratuita. Para mais detalhes, consulte Comparação de geradores de vídeo AI gratuitos.
Qual é a duração máxima dos vídeos de IA gerados a partir de texto?
A maioria das ferramentas gera 5 a 15 segundos por execução. O Sora 2 pode produzir até 20 segundos. O Keeling 3.0 suporta mais de 20 segundos. Para conteúdos mais longos, é possível gerar vários segmentos e juntá-los usando aplicações como Kinevision, Premiere Pro ou DaVinci Resolve.
A IA de conversão de texto em vídeo consegue produzir imagens com qualidade profissional?
Em um intervalo de 5 a 15 segundos, isso é viável. A saída do Seedance 2.0 e do Veo 3 muitas vezes é indistinguível de filmagens profissionais em clipes curtos. Para projetos mais longos, o vídeo com IA é melhor utilizado como um componente do material (B-roll, tomadas de transição, efeitos visuais), em vez de como a totalidade da produção.
Como criar prompts eficazes para a geração de texto para vídeo?
Siga a fórmula: Assunto + Ação + Cenário + Estilo + Tomada + Iluminação. As descrições dos movimentos devem ser específicas, os movimentos da câmara claramente definidos e a atmosfera distintamente estabelecida. Evite contradições e abstenha-se de solicitar elementos de texto/IU. Repita progressivamente, do simples ao complexo. Para mais detalhes, consulte o Guia de Redação de Prompts.
O que é superior: geração de texto para vídeo ou imagem para vídeo?
Diferentes aplicações. O texto para vídeo oferece máxima liberdade criativa quando não há material de referência disponível. A imagem para vídeo proporciona maior controlo quando existe um ponto de partida visual específico. A maioria dos profissionais utiliza ambas as abordagens — empregando o texto para vídeo para trabalhos exploratórios e a imagem para vídeo para refinamento.
Os vídeos gerados por IA podem ser usados comercialmente?
A maioria dos planos pagos concede direitos comerciais. A versão paga do Seedance 2.0 inclui direitos comerciais completos e não possui marca d'água. Os termos de serviço variam entre as plataformas; verifique as políticas específicas antes de usar. Na China, o uso comercial de conteúdo gerado por IA atualmente não enfrenta restrições regulatórias explícitas, embora seja aconselhável monitorar as atualizações das Medidas Provisórias para a Administração de Serviços de Inteligência Artificial Generativa.
A IA de conversão de texto em vídeo substituirá os editores?
Não substituirá, mas sim transformará funções. A IA lida com a geração de conteúdo, criando recursos visuais originais a partir de descrições. Os editores humanos gerem a narrativa, o ritmo, a ressonância emocional, a consistência da marca e as decisões criativas que exigem julgamento humano. Até 2026, o fluxo de trabalho mais eficaz será a geração por IA + edição humana.
Comece a criar vídeos com texto
Até 2026, a IA de texto para vídeo estará pronta para aplicações profissionais. Tendo evoluído de experiências GAN difusas para resultados DiT quase cinematográficos em apenas quatro anos, esta tecnologia agora é capaz de lidar com conteúdo de redes sociais, demonstrações de produtos, visualizações educacionais e exploração criativa.
A melhor maneira de aprender é começar a gerar. Escreva um prompt, veja os resultados e repita.
Transforme o seu primeiro parágrafo em vídeo – experimente o Seedance gratuitamente →
Procura maior precisão no controlo? Experimente a geração de imagem para vídeo →
Quer aprofundar os seus conhecimentos sobre técnicas de prompt? Leia o nosso Guia de Redação de Prompts →
