
Oversikt
Tekst-til-video-AI er en kunstig intelligens-teknologi som automatisk genererer videoer fra tekstbeskrivelser. Skriv inn en beskrivelse, så produserer AI-en et videoklipp med bevegelse, lyseffekter og kamerabevegelser. Innen 2026 har denne teknologien, ved hjelp av Diffusion Transformer (DiT)-arkitekturen, utviklet seg fra en uklar eksperimentell prototype til nesten kinokvalitet. Denne guiden dekker de tekniske prinsippene, en praktisk veiledning i fem trinn, ti replikerbare maler for kommandoer, en sammenlignende analyse av åtte verktøy, seks viktige bruksscenarier og de reelle begrensningene du må forstå.Opplev tekst-til-video-generering gratis →

Tekst-til-video-AI: Fra en enkel beskrivelse til filmopptak i kinokvalitet – AI gjør «tekst-til-video» til virkelighet.
Hva er tekst-til-video-AI?
Tekst-til-video-AI refererer til en kategori av kunstig intelligens-teknologi som automatisk genererer videoinnhold fra tekstbeskrivelser. Du beskriver en scene – en kvinne som spaserer gjennom regnet, et produkt som roterer på en utstillingsstand, en drone som svever over fjellkjeder – og AI-modellen produserer et svært realistisk videoklipp med naturlige bevegelser, belysning og fysiske effekter.
Kjernekonseptet er enkelt: tekstinngang, videoutgang. Men den underliggende teknologien er langt fra enkel. Moderne tekst-til-video-systemer bruker nevrale nettverk som er trent på milliarder av parvise datasett med «video-tekst», og lærer seg de statistiske sammenhengene mellom språklige beskrivelser og visuell bevegelse. Når du skriver «en katt hopper opp på et bord», trekker modellen på sin akkumulerte kunnskap om katter, fysikken ved å hoppe, bordplater og tyngdekraften for å generere en plausibel video.
2026: Fra eksperiment til produktivitetsverktøy
Tekst-til-video-AI krysset terskelen for «produksjonsklar» kapasitet i 2025–2026. De første systemene fra 2022–2023 kunne bare produsere korte, uskarpe og fysisk usannsynlige klipp. Dagens modeller genererer imidlertid videoer med 2K-oppløsning, fysisk nøyaktige, naturlig animerte bevegelser og kinokvalitet, med en varighet på 5–15 sekunder. Dette spranget forvandler tekst-til-video fra en forskningskuriositet til et praktisk verktøy:
- Innholdsprodusenter: Få tak i B-roll, introsekvenser og sosiale medieressurser uten kamera
- Markedsførere: Masseproduser reklamevarianter og produktdemonstrasjoner
- Lærere: Visualiser abstrakte konsepter
- Små og mellomstore bedrifter: Unngå de høye kostnadene ved profesjonell videoproduksjon
- Alle: Hvis du kan skrive, kan du lage videoer
Terskelen for å lage videoer har senket seg fra «å eie et kamera og kunne redigere» til «å lage en fengende beskrivelse».
Teknologisk utvikling: Fra GAN til DiT
Å forstå den underliggende teknologien kan hjelpe deg med å lage bedre instruksjoner og velge mer passende verktøy. Nedenfor ser du den teknologiske utviklingen gjennom tre generasjoner av tekst-til-video-AI.

Tre generasjoner av teknologisk utvikling: GAN-er (2020–2022) → Diffusjonsmodeller (2023–2024) → Diffusjonstransformatorer / DiT (2025–2026).
Første generasjon: GAN-æraen (2020–2022)
Generative Adversarial Networks (GAN) var den første arkitekturen som demonstrerte muligheten for å generere «tekst til video». To nevrale nettverk gjennomgår adversarial trening – generatoren lager videorammer, mens diskriminatoren vurderer deres autentisitet. Resultatene var imidlertid av lav oppløsning (256×256), korte i varighet (2–4 sekunder) og fysisk usannsynlige. Objekter gjennomgår uforutsigbare deformasjoner, ansiktsdrag blir forvrengt, og tidsmessig konsistens blir alvorlig kompromittert. Representative prestasjoner inkluderer CogVideo og NUWA.
Andre generasjon: Diffusjonsmodellens tidsalder (2023–2024)
Diffusjonsmodellen har fundamentalt endret landskapet. Den bruker ikke lenger adversarial training, men lærer i stedet en «revers denoising»-prosess – som starter med ren støy og gradvis fjerner støyen til det blir en sammenhengende video under tekstuell veiledning. Denne tilnærmingen gir et kvalitativt sprang: høyere oppløsning (opptil 1080p), lengre varighet (4–10 sekunder) og forbedret tekst-visuell tilpasning.
OpenAI's Sora (utgitt i februar 2024) demonstrerte at diffusjonsmodeller kan generere forbausende fotorealistiske videoer. Runway Gen-2/Gen-3, Pika og Stable Video Diffusion tilhører alle denne generasjonen.
Tredje generasjon: DiT — Diffusjonstransformator (2025–2026)
De mest avanserte arkitekturene kombinerer i dag diffusjonsprosesser med Transformer-arkitekturen (samme arkitektur som ligger bak GPT og BERT). DiT-modeller behandler video som en sekvens av rom-tidslige lapper, og oppnår dermed:
- Forbedret tidsmessig konsistens: Transformers er svært gode til å modellere langtrekkende avhengigheter på tvers av rammer
- Høyere oppløsning: Innebygd 2K-utdata (Seedance 2.0 oppnår 2048×1080)
- Større fysisk nøyaktighet: Mer realistisk bevegelse, tyngdekraft og væskedynamikk
- Forbedret tekstforståelse: Betydelig forbedret samsvar mellom promptbeskrivelser og visuelle utdata
- Multimodal inndata: Utvalgte DiT-modeller kan samtidig behandle bilde-, video- og lydinndata
Seedance 2.0, Google Veo 3 og Keeling 3.0 bruker alle DiT-arkitekturen. Dette er grunnen til at tekst-til-video-generering i 2026 viser en kvalitativ forskjell sammenlignet med 2024.
Tekst til video vs. bilde til video
Disse to tilnærmingene er komplementære snarere enn konkurrerende:
| Dimensjon | Tekst til video (T2V) | Bilde til video (I2V) | |------|------------------|----------------- -| | Inndata | Kun tekstbeskrivelse | Fotografi + bevegelsesbeskrivelse | | Kreativ frihet | Høyest — AI bestemmer alle visuelle elementer | Begrenset av kildebildet | | Kontrollerbarhet | Lavere — Avhengig av nøyaktigheten i prompten | Høyere — Visuelle ankerpunkter tilgjengelig | | Egnede scenarier | Konseptutforskning, originalt innhold | Produktvisning, fotoanimasjon, stilmatcheing | | Forutsigbarhet | Lav — Samme prompt gir forskjellige resultater hver gang | Høy — Utdata samsvarer konsekvent med kildebildet |
De fleste profesjonelle arbeidsflyter bruker begge tilnærmingene: først bruker man T2V til å utforske kreative konsepter, og deretter finpusser man resultatet med I2V. For en detaljert gjennomgang av generering av bilder til video, se vår Image-to-Video AI Complete Guide.
5-trinns veiledning: Lag din første AI-video
Følgende er en trinnvis veiledning for å generere tekst-til-video-innhold fra bunnen av, ved hjelp av Seedance 2.0 som demonstrasjonsplattform. De underliggende prinsippene gjelder for alle verktøy.

Fra rask opprettelse til endelig resultat: Fem trinn for å fullføre din første AI-video.
Trinn 1: Definer videoens mål
Før du skriver oppgaven, må du først bestemme:
- Type: B-roll-opptak, produktdemonstrasjoner, innhold for sosiale medier, kunstneriske kreasjoner eller fortelling?
- Varighet: 5 sekunder for testing, 10–15 sekunder for endelig utgave
- Bildeformat: 16:9 for YouTube/Bilibili, 9:16 for Douyin/Kuaishou/ Xiaohongshu, 1:1 for WeChat Moments
- Stil: Filmisk, dokumentarisk, animasjon, reklamefilm eller kunstnerisk
Å definere klare mål forhindrer sløsing med generasjonskvoter på tvetydige eksperimenter.
Trinn 2: Utarbeide tekstmeldinger av høy kvalitet
Prompt er selve essensen av tekst-til-video-generering. Bruk følgende formel:
[Emne] + [Handling/Bevegelse] + [Setting] + [Stil] + [Kamerabevegelse] + [Belysning]
Dårlig prompt: «En hund som løper»
God prompt: «En golden retriever løper gjennom en solfylt eng, med villblomster som vugger i brisen. Hundens pels bølger med hvert skritt. Kameraet følger med på bakkenivå. Varmt gyldent lys med lange skygger. Filmisk kort dybdeskarphet, 4K-kvalitet.
Viktige prinsipper:
- Bevegelsen må være spesifikk: «vender hodet sakte» i stedet for «vender»
- Beskriv kamerabevegelser: «kameraet zoomer inn» eller «drone-luftopptak»
- Skap atmosfæren: Belysning, fargegradering, atmosfære
- Unngå motsetninger: Ikke be om «rask handling» og «sakte film» samtidig
- Ikke be om tekst/brukergrensesnitt: Den nåværende modellen sliter med å gjengi lesbar tekst i videorammer
Merk: Det anbefales å skrive instruksjoner på engelsk, selv når du bruker innenlandske verktøy (som KeLing, TongYi WanXiang eller Hunyuan Video). Dette skyldes at de fleste modeller er trent på mer omfattende engelskspråklige datasett.
For et mer omfattende system for promptteknikker, se Veiledning for skriving av prompts og 10 virkelig effektive AI-videoprompts.
Trinn 3: Velg Verktøy og parametere
Velg en plattform (se sammenligningstabellen nedenfor), og konfigurer deretter:
- Modell: Bruk den nyeste tilgjengelige modellen (f.eks. Seedance 2.0, ikke 1.0)
- Oppløsning: Minimum 1080p; velg 2K hvis tilgjengelig
- Varighet: Test med 5 sekunder i utgangspunktet, forleng hvis resultatet er tilfredsstillende
- Bildeforhold: Tilpass distribusjonsplattformen din
- Seed-verdi (hvis tilgjengelig): Lås seed-verdien for konsistent iterasjon
Trinn 4: Generer og gjennomgå
Klikk på Generer og vent i 60–180 sekunder (avhengig av verktøyet). Når du gjennomgår resultatet, må du være oppmerksom på følgende:
- ✅ Stemmer bevegelsen med beskrivelsen?
- ✅ Er motivet konsistent gjennom hele filmen (ingen forvrengning)?
- ✅ Er fysikken plausibel (tyngdekraft, væsker, tekstiler)?
- ✅ Er kamerabevegelsen jevn?
- ❌ Er det noen artefakter, flimring eller forvrengning?
- ❌ Er det en uhyggelig dal-effekt på ansikter/hender?
Trinn 5: Iterativ optimalisering
Det første forsøket er sjelden perfekt. Optimeringsmetoder:
- Juster prompten: Legg til detaljer der AI-en har gjort feil
- Endre bare én variabel om gangen: Ikke skriv om hele prompten
- Eksperimenter med forskjellige frø: Den samme prompten kan gi helt forskjellige resultater
- Forleng varigheten: Når du er fornøyd med 5-sekundersversjonen, kan du prøve 10–15 sekunder
- Inkorporer lyd: Hvis verktøyet støtter det (Seedance, Veo 3), kan du legge til lydeffekter eller bakgrunnsmusikk

Eksempler på iterasjoner av prompt: V1 (grunnleggende prompt) → V2 (tillegg av beskrivelser av bevegelse og belysning) → V3 (fullstendige filmiske spesifikasjoner). Hver forbedringssyklus forbedrer bildekvaliteten betydelig.
10 maler for tekst-til-video-generering
Følgende maler kan kopieres og brukes direkte. De er testet på Seedance 2.0 og er kompatible med de fleste vanlige plattformer.
1. Filmisk portrett
A close-up of a young woman with flowing dark hair, her face illuminated by warm golden hour sunlight filtering through a window. She slowly turns her head toward the camera, a subtle smile forming. Soft bokeh background of a cozy interior. Camera holds steady with a slight push-in. Warm amber lighting, shallow depth of field, 4K cinematic quality.
Egnede scenarier: Sosiale medier, personlig merkevarebygging, kunstnerisk skapelse
- Produktpresentasjon
A sleek wireless headphone rotating slowly on a matte black pedestal. Soft studio lighting creates clean highlights on the brushed metal surface. Camera orbits 180 degrees at eye level. Minimalist white background, no shadows. Smooth continuous motion, commercial product photography quality.
Egnede scenarier: Produktdetaljsider for e-handel, produktmarkedsføring, hovedbildevideoer på Taobao/JD.com
- Naturfilm
An epic aerial drone shot over a misty mountain valley at sunrise. Golden light breaks through layered clouds, illuminating a winding river below. Camera pushes forward slowly, revealing the vast landscape. Volumetric fog drifts between peaks. IMAX cinematography quality, hyper-detailed.
Egnet for: YouTube/Bilibili-introfilmer, reiseinnhold, skjermsparere, meditasjonskanaler
4. Urban Street
A neon-lit Tokyo alley at night after rain. Wet cobblestones reflect vivid pink, teal, and amber neon signs. A lone figure walks away from camera, umbrella in hand. Steam rises from a street vent. Camera follows at a distance, tracking shot. Film noir atmosphere, anamorphic lens flare.
Egnede scenarier: Musikkvideoer, stemningsfulle B-roll-opptak, innhold i cyberpunk-stil
- Anime-stil
An anime warrior princess with flowing silver hair stands on a cliff edge overlooking a fantasy kingdom. Her cape billows dramatically in the wind. She raises a glowing sword that emits blue energy particles. Cherry blossom petals drift past. Camera slowly orbits. Studio Ghibli meets Ufotable quality animation.
Egnet for: Animasjonsinnhold, spillkanaler, fantasifortellinger
6. Mat og drikke
Extreme macro close-up of rich dark coffee being poured in slow motion into a pristine ceramic cup. Individual droplets and tiny splashes frozen mid-air. Wisps of steam curl elegantly upward. Warm side lighting reveals the liquid's amber transparency. Cinnamon stick and scattered beans visible in soft focus foreground.
Egnede scenarier: Markedsføring av mat og drikke, matbloggere, reklame for drikkevarer
- Mote og redaksjonelt
A model in a flowing white silk gown walks confidently down a dark runway. Multiple flash strobes create sharp geometric light patterns. The fabric billows with perfect physics. Camera at a low angle, slight slow motion. High fashion editorial aesthetic, Vogue magazine quality.
Egnede scenarier: Motemerker, skjønnhetsinnhold, redaksjonelle artikler
- Science fiction og fantasy
A massive spaceship emerges from hyperspace above a ringed planet. Blue energy dissipates around the hull as the vessel decelerates. Tiny fighter escorts flank its sides. Camera pulls back to reveal the scale against the planet. Volumetric space dust and distant star field. Hollywood VFX quality.
Gjeldende scenarier: Underholdningsinnhold, science fiction-kanaler, konseptvisualisering
- Sport og action
A basketball player at the peak of a slam dunk, frozen in mid-air. Time resumes in slow motion — sweat droplets fly, the ball compresses against the rim, arena spotlights create dramatic lens flare. Camera shoots from below looking up. ESPN broadcast quality, hyper-detailed.
Egnet for: Sportsinnhold, sportsmerker, høydepunkter
- Abstrakt kunst (abstrakt og kunstnerisk)
Liquid gold and deep indigo ink collide in slow motion inside a glass sphere. The fluids intertwine in mesmerizing fractal patterns. Tiny bubbles catch light. Camera slowly rotates around the sphere. Pure black background. Macro photography meets fluid dynamics simulation. Meditative, hypnotic pace.
Egnede scenarier: Bakgrunnsbilder, musikkvideoer, kunstinstallasjoner, skjermsparere

Den faktiske utdataen fra fire av de ti malene ovenfor – hver prompt genererer særegent stiliserte bilder i kinokvalitet fra ren tekst.
2026: En sammenlignende gjennomgang av åtte verktøy for generering av tekst til video
Vi testet åtte populære plattformer ved hjelp av samme oppgave («En golden retriever som løper gjennom en solfylt eng, med viltvoksende blomster som svaier i vinden, i kinokvalitet 4K»), og vurderte dem på fem forskjellige områder. Alle testene ble fullført i februar 2026.
| Verktøy | Maksimal oppløsning | Maksimal varighet | Gratis versjon | Lyd | Beste bruk | Bildekvalitetsvurdering | |------|----------|---------|--------|------|-------- -|---------| | Seedance 2.0 | 2K (2048×1080) | 15 sekunder | ✅ Daglig gratiskvote | ✅ Lydeffekter + musikk + leppesynkronisering | Multimodal oppretting | 9,2/10 | | Google Veo 3 | 4K (begrenset) | 8 sekunder | ✅ AI Studio-kvote | ✅ Innfødt lyd | Audiovisuell fusjon | 9,0/10 | | Sora 2 | 1080p | 20 sekunder | ❌ Krever ChatGPT Plus | ❌ | Langtekstdrevet video | 8,8/10 | | Keling 3.0 | 1080p | 20+ sekunder | ✅ Gratis registreringskreditter | ⚠️ Begrenset | Lange videoer, god valuta for pengene | 8,5/10 | | Runway Gen-4 | 1080p | 10 sekunder | ✅ 125 kreditt | ❌ | Profesjonell redigeringsarbeidsflyt | 8,5/10 | | Pika 2.0 | 1080p | 10 sekunder | ✅ Daglig gratis kvote | ⚠️ Kun lydeffekter | Nybegynnere, lekne effekter | 8,0/10 | | Luma Dream Machine | 1080p | 5 sekunder | ✅ Gratis generering | ❌ | 3D-scener, rask iterasjon | 7,8/10 | | Snail AI (MiniMax) | 1080p | 6 sekunder | ✅ Daglig gratis | ❌ | Raskeste genereringshastighet | 7,5/10 |
Viktig merknad for innenlandske brukere: Seedance 2.0, KeLing 3.0 og Hailuo AI er direkte tilgjengelige i Kina. Sora 2 krever et ChatGPT Plus-abonnement (VPN nødvendig). Google Veo 3 krever tilgang via Google AI Studio (VPN nødvendig). Runway, Pika og Luma krever alle en utenlandsk nettverkstilkobling.
Innenlandske alternativer: Tongyi Wanxiang (Alibaba), Hunyuan Video (Tencent) og Qingying (datterselskap av ByteDance) tilbyr også tekst-til-video-genereringsfunksjoner, med varierende gratis brukstilgang.
Viktige konklusjoner:
- Beste totale bildekvalitet: Seedance 2.0 (innfødt 2K + quad-modus inngang + lyd)
- Sterkeste lydfunksjoner: Seedance 2.0 og Google Veo 3
- Beste gratisversjon: Seedance 2.0 (gratis tilgang til 2K-oppløsning, ingen kredittkort kreves)
- Lengste gratis videolengde: Keeling 3.0 (20+ sekunder)
- Best egnet for nybegynnere: Pika 2.0 (enklest grensesnitt, morsomme effekter)
For en mer detaljert sammenligning, se Den komplette sammenligningen av de beste AI-videogeneratorene for 2026. For å fokusere utelukkende på gratisabonnementer, se En sammenlignende gjennomgang av gratis AI-videogeneratorer.
6 viktige bruksscenarier
- Innhold på sosiale medier
Lag iøynefallende korte videoer for TikTok, Kuaishou, Xiaohongshu, Bilibili og YouTube Shorts. AI eliminerer behovet for filming, redigering og etterproduksjon fullstendig.
Anbefalte spesifikasjoner: Bildeforhold 9:16, varighet 5–15 sekunder, med en sterk visuell effekt i åpningssekundet.
- Markedsføring og reklame
Masseproduser varianter av reklamemateriell. Test flere visuelle konsepter ved hjelp av ulike spørsmål før du forplikter deg til det formelle produksjonsbudsjettet. Generer A/B-testversjoner på få minutter.
Anbefalt konfigurasjon: Kompatibilitet med flere formater på tvers av flere plattformer. Kombiner med Seedances lydfunksjoner for å produsere komplette reklamefilmer.
3. Utdanning og opplæring
Visualisering av abstrakte konsepter som er vanskelige eller umulige å fange på film: molekylære strukturer, historiske hendelser, matematiske konsepter, vitenskapelige prosesser. AI-video gjør det usynlige synlig.
Anbefalt konfigurasjon: For optimale læringsresultater, kombiner en prompt som presist forklarer konseptet med en innspilt lydfil.
- Underholdning og fortelling
Uavhengige filmskapere og historiefortellere bruker tekst-til-video-teknologi til konseptvisualisering, storyboarding og til og med den endelige produksjonen av kortfilmer. Denne teknologien demokratiserer filmproduksjon.
Anbefalt konfigurasjon: Inkluder detaljerte spesifikasjoner for kameraretting og belysning i instruksjonen for å oppnå en kinematisk effekt.
- Produktvideoer for e-handel
Omdanne produktbeskrivelser til produktdemonstrasjonsvideoer. Dette er spesielt verdifullt for forhandlere med hundrevis av SKU-er som ikke kan filme individuelle videoer for hvert produkt. For detaljerte e-handelsarbeidsflyter, se AI E-commerce Video Guide.
Anbefalte spesifikasjoner: Produktfotografering med studiobelysning. Bildeformat 1:1 for produktdetaljsider, 16:9 for YouTube/Bilibili, 9:16 for TikTok/Xiaohongshu.
6. YouTube / Bilibili innholdsproduksjon
Lag B-roll-opptak, introsekvenser, visuelle kommentarer og komplette korte videoer. Skapere kan forbedre effektiviteten i innholdsproduksjonen med AI-video. For fullstendig informasjon om arbeidsflyten for YouTube-skapere, se AI Video YouTube Creator Guide.
Anbefalt konfigurasjon: Oppretthold visuell konsistens på tvers av kanaler innenfor hver prompt for å etablere merkevareerkjennelse.
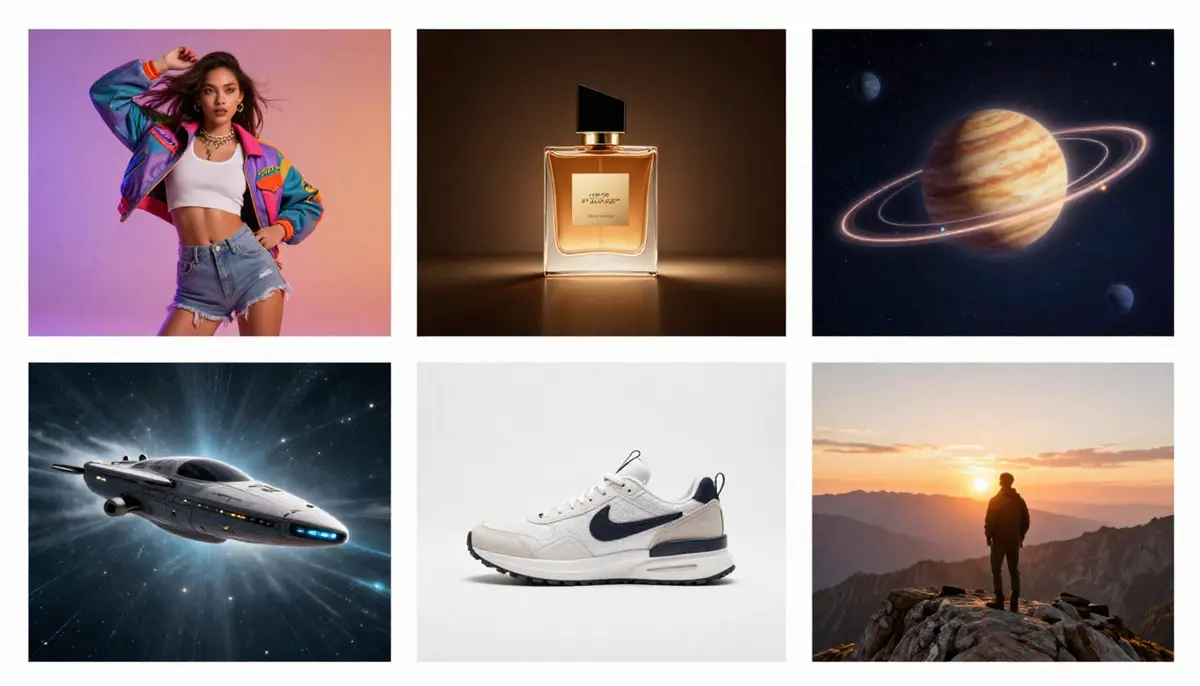
Seks praktiske anvendelser av tekst-til-video-AI – fra korte videoer på sosiale medier til produktdemonstrasjoner i e-handel og visualisering av pedagogiske konsepter.
Tekst til video vs. bilde til video: Når skal man bruke hva?
Dette er et av de mest stilte spørsmålene fra nye brukere. Svaret avhenger av hvilke materialer du har tilgjengelig og hva du trenger.

To veier til AI-video: Tekst-til-video-generering starter fra skriftlig tekst, mens bilde-til-video-generering starter med eksisterende fotografier.
Scenarier for tekst til video (T2V):
- Du lager helt nytt innhold (ingen referansebilder)
- Du ønsker maksimal kreativ frihet
- Du utfører konseptutforskning eller visuell brainstorming
- Du trenger abstrakte eller ufotograferbare scener (science fiction, fantasy, mikroskopisk/makroskopisk)
- Du ønsker å iterere raskt – å endre en prompt gir en helt annen scene
Scenarier for generering av videoer fra bilder (I2V):
- Du har et bestemt fotografi som krever dynamisk transformasjon
- Du trenger et resultat som samsvarer nøyaktig med eksisterende visuelle effekter
- Du konverterer produktbilder til produktvideoer
- Du trenger karakterkonsistens (samme person i alle scener)
- Du ønsker mer forutsigbare og kontrollerbare resultater
Beste praksis — Kombinere begge tilnærmingene:
- Bruk tekst-til-video-generering for å utforske kreative retninger
- Velg det optimale bildet som referansebilde
- Bruk bilde-til-video-generering for en raffinert, kontrollerbar sluttversjon
For en omfattende arbeidsflyt for generering av bilder til video, se Image-to-Video AI Complete Guide.
Nåværende begrensninger — En ærlig vurdering
Tekst-til-video-AI-en fra 2026 er imponerende, men langt fra feilfri. Nedenfor er områdene der den for tiden utmerker seg, og de som fortsatt er utfordrende.
Godt gjort
- Korte videoer (5–15 sekunder): Bildekvalitet som nærmer seg kinostandard
- Scener med ett motiv: Én person, ett dyr, ett objekt – utmerkede resultater
- Natur og landskap: Sterk ytelse i fluid dynamikk, vær og atmosfæriske effekter
- Stilisert innhold: Animasjon, film noir, sci-fi – svært pålitelig stilkonvertering
- Produktrotasjonsdemonstrasjoner: Enkel produktbevegelse med god konsistens
- Kamerabevegelser: Pan, zoom, dolly, sporingsopptak – godt kontrollert
Fortsatt vanskelig
- Hender og fingre: Overflødige fingre, usannsynlige bevegelser og fingerdeformiteter er fortsatt vanlig
- Tekstgjengivelse: Lesbar tekst i videoer er upålitelig – bokstavene vises forvrengt, tegnene er skjevt
- Komplekse interaksjoner mellom flere personer: Håndtrykk mellom to personer, dans eller slåssing resulterer ofte i uorganiserte lemmer
- Utvidet fortelling (>30 sekunder): Opprettholdelse av scenekonsistens over lengre perioder forringes
- Presis fysikk: Presis ballsprett, vann som helles i bestemte beholdere — fysikken er omtrentlig, ikke eksakt*⦁NLBR⦁* Langvarig ansiktskonsistens: Ansiktsdrag kan gjennomgå subtile endringer mellom bildene, spesielt over lengre perioder.
Utviklingen
Hver av disse begrensningene vil bli betydelig forbedret innen 2026 sammenlignet med 2024. Forbedringstakten er eksponentiell. Håndrendering vil utvikle seg fra «alltid feil» til «generelt nøyaktig». Ansiktskonsistensen vil endres fra «begynner å avvike etter 2 sekunder» til «forblir stabil i 10–15 sekunder». Tekstrendering vil utvikle seg fra «uleselig» til «av og til lesbar». Disse problemene forventes å fortsette å forbedres raskt i 2026–2027.
Ofte stilte spørsmål
Hvilken er den beste tekst-til-video-AI-en for 2026?
Seedance 2.0 er ledende når det gjelder total bildekvalitet med innfødt 2K-oppløsning, firmodulær inngang og integrert lydgenerering. Google Veo 3 utmerker seg innen audiovisuell fusjon og fysisk simulering. Sora 2 tilbyr den lengste varigheten for en enkelt generasjon (20 sekunder). Det «beste» valget avhenger av dine spesifikke krav – oppløsning, lyd, varighet eller pris. Hjemmebrukere kan også vurdere Keeling 3.0 (god valuta for pengene, lange videoer) og Tongyi Wanxiang (integrert med Alibaba-økosystemet).
Finnes det noen gratis tekst-til-video-AI?
Ja. Seedance 2.0 tilbyr en daglig gratis kvote uten å kreve kredittkort. Pika 2.0 tilbyr daglig gratis generering. Ke Ling 3.0 gir en registreringskvote. Google Veo 3 tilbyr gratis kvoter via AI Studio. Conch AI tilbyr også en daglig gratis kvote. For detaljer, se Sammenligning av gratis AI-videogeneratorer.
Hvor lange kan AI-videoer generert fra tekst være?
De fleste verktøy genererer innhold i intervaller på 5–15 sekunder. Sora 2 kan produsere opptil 20 sekunder. Keeling 3.0 støtter over 20 sekunder. For lengre innholdskrav kan flere segmenter genereres og settes sammen ved hjelp av redigeringsprogramvare som Kinevision, Premiere Pro eller DaVinci Resolve.
Kan tekst-til-video-AI oppnå profesjonell grafikk?
Innenfor en varighet på 5–15 sekunder er det gjennomførbart. Resultatet fra Seedance 2.0 og Veo 3 er ofte umulig å skille fra profesjonelt opptak i korte klipp. For lengre prosjekter er AI-video best å bruke som en del av materialet (B-roll, overgangsscener, visuelle effekter), snarere enn som hele produksjonen.
Hvordan lage effektive instruksjoner for generering av tekst til video?
Følg formelen: Emne + Handling + Setting + Stil + Opptak + Belysning. Beskrivelser av bevegelser bør være spesifikke, kamerabevegelser klart definert og atmosfæren tydelig etablert. Unngå motsetninger og avstå fra å be om tekst-/UI-elementer. Gå gradvis fra enkelt til komplekst. For mer informasjon, se Veiledning for å skrive prompter.
Hva er best: tekst-til-video eller bilde-til-video-generering?
Ulike bruksområder. Tekst-til-video gir maksimal kreativ frihet når det ikke finnes referansemateriale. Bilde-til-video gir større kontroll når det finnes et spesifikt visuelt utgangspunkt. De fleste profesjonelle bruker begge tilnærmingene – tekst-til-video for utforskende arbeid og bilde-til-video for finpussing.
Kan AI-tekstgenererte videoer brukes til kommersielle formål?
De fleste betalte abonnementer gir kommersielle rettigheter. Den betalte versjonen av Seedance 2.0 inkluderer fullstendige kommersielle rettigheter og er uten vannmerke. Vilkårene for bruk varierer mellom plattformene. Vennligst sjekk de spesifikke retningslinjene før bruk. I Kina er det foreløpig ingen eksplisitte regulatoriske begrensninger for kommersiell bruk av AI-generert innhold, men det anbefales å følge med på oppdateringer av de midlertidige tiltakene for administrasjon av generative kunstig intelligens-tjenester.
Vil tekst-til-video-AI erstatte redaktører?
Det vil ikke erstatte, men snarere transformere roller. AI håndterer innholdsgenerering – å skape originale visuelle ressurser fra beskrivelser. Menneskelige redaktører håndterer fortelling, tempo, emosjonell resonans, merkevarekonsistens og kreative beslutninger som krever menneskelig dømmekraft. Innen 2026 vil den mest effektive arbeidsflyten være AI-generering + menneskelig redigering.
Begynn å lage videoer med tekst
Innen 2026 vil tekst-til-video-AI være klar for profesjonelle applikasjoner. Denne teknologien har utviklet seg fra uklare GAN-eksperimenter til nesten kinolignende DiT-resultater på bare fire år, og er nå i stand til å håndtere innhold på sosiale medier, produktdemonstrasjoner, pedagogiske visualiseringer og kreativ utforskning.
Den beste måten å lære på er å begynne å generere. Skriv en prompt, se resultatene og gjenta.
Gjør første avsnitt til en video – prøv Seedance gratis →
Ønsker du større kontrollpresisjon? Prøv bilde-til-video-generering →
Vil du lære mer om teknikker for å skrive oppgaver? Les vår guide til å skrive oppgaver →
