
De un vistazo
La IA de texto a vídeo es una tecnología de inteligencia artificial que genera automáticamente vídeos a partir de descripciones textuales. Introduzca una descripción y la IA producirá un videoclip con movimiento, efectos de iluminación y movimientos de cámara. Para 2026, gracias a la arquitectura Diffusion Transformer (DiT), esta tecnología ha pasado de ser un prototipo experimental difuso a alcanzar una calidad casi cinematográfica. Esta guía abarca los principios técnicos, un tutorial práctico de cinco pasos, diez plantillas de comandos replicables, un análisis comparativo de ocho herramientas, seis escenarios de aplicación principales y las limitaciones reales que debes comprender.Prueba la generación de texto a vídeo de forma gratuita →

IA de texto a vídeo: desde una simple descripción hasta imágenes con calidad cinematográfica, la IA hace realidad la conversión de «texto a vídeo».
¿Qué es la IA de texto a vídeo?
La IA de texto a vídeo se refiere a una categoría de tecnología de inteligencia artificial que genera automáticamente contenido de vídeo a partir de descripciones textuales. Usted describe una escena (una mujer paseando bajo la lluvia, un producto girando en un expositor, un dron sobrevolando una cordillera) y el modelo de IA produce un videoclip muy realista con movimientos naturales, iluminación y efectos físicos.
El concepto básico es sencillo: entrada de texto, salida de vídeo. Sin embargo, la tecnología que hay detrás dista mucho de ser simple. Los sistemas modernos de conversión de texto a vídeo emplean redes neuronales entrenadas con miles de millones de conjuntos de datos emparejados de «vídeo-texto», que aprenden las relaciones estadísticas entre las descripciones lingüísticas y el movimiento visual. Cuando escribes «un gato salta sobre una mesa», el modelo recurre a su conocimiento acumulado sobre gatos, la física del salto, las superficies de las mesas y la gravedad para generar un vídeo plausible.
2026: Del experimento a la herramienta de productividad
La IA de texto a vídeo superó el umbral de la capacidad «lista para la producción» en 2025-2026. Los primeros sistemas de 2022-2023 solo podían producir clips breves, borrosos y físicamente inverosímiles. Sin embargo, los modelos actuales generan vídeos con resolución 2K, movimientos animados de forma natural y físicamente precisos, y calidad cinematográfica, con una duración de entre 5 y 15 segundos. Este salto transforma la conversión de texto a vídeo de una curiosidad de investigación a una herramienta práctica:
- Creadores de contenido: Obtenga material de archivo, secuencias introductorias y recursos para redes sociales sin necesidad de una cámara
- Profesionales del marketing: Produzcan en masa variantes publicitarias y demostraciones de productos
- Educadores: Visualicen conceptos abstractos
- Pequeñas y medianas empresas: Eviten los altos costes de la producción de vídeos profesionales
- Cualquiera: Si sabe escribir, puede hacer vídeos
El umbral para la creación de vídeos ha bajado de «tener una cámara y saber editar» a «redactar una descripción atractiva».
Evolución tecnológica: de GAN a DiT
Comprender la tecnología subyacente puede ayudarte a crear mejores indicaciones y seleccionar herramientas más adecuadas. A continuación se muestra la evolución tecnológica de tres generaciones de la IA de texto a vídeo.

Tres generaciones de evolución tecnológica: GAN (2020-2022) → Modelos de difusión (2023-2024) → Transformadores de difusión / DiT (2025-2026).
Primera generación: la era GAN (2020-2022)
Las redes generativas adversarias (GAN) fueron la primera arquitectura en demostrar la viabilidad de la conversión de «texto a vídeo». Dos redes neuronales se someten a un entrenamiento adversario: el generador crea fotogramas de vídeo, mientras que el discriminador juzga su autenticidad. Sin embargo, los resultados eran de baja resolución (256 × 256), corta duración (2-4 segundos) y físicamente inverosímiles. Los objetos sufren deformaciones impredecibles, los rasgos faciales se distorsionan y la coherencia temporal se ve gravemente comprometida. Entre los logros más representativos se encuentran CogVideo y NUWA.
Segunda generación: la era de los modelos de difusión (2023-2024)
El modelo de difusión ha transformado radicalmente el panorama. Ya no emplea el entrenamiento adversarial, sino que aprende un proceso de «desruido inverso», que parte del ruido puro y lo elimina progresivamente hasta obtener un vídeo coherente bajo la guía textual. Este enfoque supone un salto cualitativo: mayor resolución (hasta 1080p), mayor duración (4-10 segundos) y mejor alineación entre el texto y la imagen.
Sora, de OpenAI (lanzado en febrero de 2024), demostró que los modelos de difusión pueden generar vídeos sorprendentemente fotorrealistas. Runway Gen-2/Gen-3, Pika y Stable Video Diffusion pertenecen a esta generación.
Tercera generación: DiT — Transformador de difusión (2025-2026)
Las arquitecturas más avanzadas actualmente combinan procesos de difusión con la arquitectura Transformer (la misma arquitectura que hay detrás de GPT y BERT). Los modelos DiT procesan el vídeo como una secuencia de parches espacio-temporales, logrando:
- Mayor consistencia temporal: los transformadores destacan en el modelado de dependencias de largo alcance entre fotogramas
- Mayor resolución: Salida nativa 2K (Seedance 2.0 alcanza 2048×1080)
- Mayor precisión física: Movimiento, gravedad y dinámica de fluidos más realistas
- Mayor comprensión del texto: Alineación significativamente mejorada entre las descripciones de las indicaciones y los resultados visuales
- Entrada multimodal: Algunos modelos DiT pueden aceptar simultáneamente entradas de imagen, vídeo y audio.
Seedance 2.0, Google Veo 3 y Keeling 3.0 utilizan la arquitectura DiT. Por eso, la generación de texto a vídeo en 2026 presenta una diferencia cualitativa con respecto a la de 2024.
Texto a vídeo frente a imagen a vídeo
Estos dos enfoques son complementarios más que competitivos:
| Dimensión | Texto a vídeo (T2V) | Imagen a vídeo (I2V) | |------|------------------|----------------- -| | Entrada | Solo descripción de texto | Fotografía + descripción del movimiento | | Libertad creativa | Máxima: la IA determina todos los elementos visuales | Limitada por la imagen de origen | | Controlabilidad | Menor: depende de la precisión de la indicación | Mayor: hay anclajes visuales disponibles | | Escenarios adecuados | Exploración de conceptos, contenido original | Exhibición de productos, animación fotográfica, combinación de estilos | | Previsibilidad | Baja: la misma indicación produce resultados diferentes cada vez | Alta: el resultado coincide siempre con la imagen original |
La mayoría de los flujos de trabajo profesionales utilizan ambos enfoques: primero emplean T2V para explorar conceptos creativos y luego refinan el resultado con I2V. Para obtener información detallada sobre la generación de imágenes a vídeo, consulte nuestra Guía completa de IA de imagen a vídeo.
Tutorial en 5 pasos: cómo crear tu primer vídeo con IA
A continuación se ofrece una guía paso a paso para generar contenido de texto a vídeo desde cero, utilizando Seedance 2.0 como plataforma de demostración. Los principios subyacentes se aplican a cualquier herramienta.

Desde la creación rápida hasta el resultado final: cinco pasos para completar tu primer vídeo con IA.
Paso 1: Definir los objetivos del vídeo.
Antes de escribir la indicación, primero determine:
- Tipo: ¿Material de archivo, demostraciones de productos, contenido para redes sociales, creaciones artísticas o narración?
- Duración: 5 segundos para pruebas, 10-15 segundos para el resultado final
- Relación de aspecto: 16:9 para YouTube / Bilibili, 9:16 para Douyin / Kuaishou / Xiaohongshu, 1:1 para WeChat Moments
- Estilo: Cinematográfico, documental, animación, anuncio comercial o artístico
Definir objetivos claros evita el desperdicio de cuotas de generación en experimentos ambiguos.
Paso 2: Creación de indicaciones de texto de alta calidad
La sugerencia es la esencia de la generación de texto a vídeo. Emplea la siguiente fórmula:
[Tema] + [Acción/Movimiento] + [Escenario] + [Estilo] + [Movimiento de cámara] + [Iluminación]
Indicación deficiente: «Un perro corriendo».
Buena indicación: «Un golden retriever corriendo por un prado soleado, con flores silvestres meciéndose con la brisa. El pelaje del perro se ondula con cada zancada. La cámara lo sigue a ras de suelo. Iluminación cálida de la hora dorada con sombras alargadas. Profundidad de campo cinematográfica, calidad 4K».
Principios clave:
- El movimiento debe ser específico: «gira lentamente la cabeza» en lugar de «gira»
- Describe los movimientos de la cámara: «la cámara se acerca» o «toma aérea con dron»
- Crea la atmósfera: iluminación, gradación de color, ambiente
- Evitar contradicciones: no solicitar simultáneamente «acción rápida» y «cámara lenta»
- No solicitar texto/interfaz de usuario: el modelo actual tiene dificultades para renderizar texto legible dentro de los fotogramas de vídeo.
Nota: Es recomendable redactar las indicaciones en inglés, incluso cuando se utilicen herramientas nacionales (como KeLing, TongYi WanXiang o Hunyuan Video). Esto se debe a que la mayoría de los modelos se han entrenado con conjuntos de datos más amplios en inglés.
Para obtener un sistema de técnicas de indicaciones más completo, consulte la Guía para escribir indicaciones y 10 indicaciones de vídeo de IA realmente eficaces.
Paso 3: Seleccionar herramientas y parámetros
Seleccione una plataforma (consulte la tabla comparativa más abajo) y, a continuación, configure:
- Modelo: Utiliza el último modelo disponible (por ejemplo, Seedance 2.0, no 1.0)
- Resolución: Mínimo 1080p; opta por 2K cuando esté disponible
- Duración: Pruebe inicialmente con 5 segundos y amplíe si es satisfactorio
- Relación de aspecto: Adapte a su plataforma de distribución
- Valor inicial (si está disponible): Bloquee el valor inicial para una iteración coherente
Paso 4: Generar y revisar
Haga clic en Generar y espere entre 60 y 180 segundos (dependiendo de la herramienta). Al revisar el resultado, preste atención a:
- ✅ ¿El movimiento coincide con la descripción?
- ✅ ¿El sujeto es coherente en todo momento (sin distorsiones)?
- ✅ ¿La física es plausible (gravedad, fluidos, tejidos)?
- ✅ ¿El movimiento de la cámara es fluido?
- ❌ ¿Hay artefactos, parpadeos o distorsiones?
- ❌ ¿Hay un efecto de valle inquietante en las caras/manos?
Paso 5: Optimización iterativa
El primer intento rara vez es perfecto. Métodos de optimización:
- Ajusta la indicación: añade detalles donde la IA se haya equivocado
- Cambia solo una variable cada vez: no reescribas toda la indicación
- Experimente con diferentes semillas: la misma indicación puede dar resultados completamente diferentes
- Aumente la duración: una vez que esté satisfecho con la versión de 5 segundos, pruebe con 10-15 segundos
- Incorpore audio: si la herramienta lo admite (Seedance, Veo 3), añada efectos de sonido o música de fondo.

Ejemplos de iteración rápida: V1 (prompt base) → V2 (añadiendo descripciones de movimiento e iluminación) → V3 (especificaciones cinematográficas completas). Cada ciclo de refinamiento mejora significativamente la calidad de la imagen.
10 plantillas de comandos para la generación de texto a vídeo
Las siguientes plantillas están listas para su uso inmediato. Han sido probadas en Seedance 2.0 y son compatibles con la mayoría de las plataformas principales.
1. Retrato cinematográfico
A close-up of a young woman with flowing dark hair, her face illuminated by warm golden hour sunlight filtering through a window. She slowly turns her head toward the camera, a subtle smile forming. Soft bokeh background of a cozy interior. Camera holds steady with a slight push-in. Warm amber lighting, shallow depth of field, 4K cinematic quality.
Escenarios adecuados: redes sociales, marca personal, creación artística.
- Presentación de productos
A sleek wireless headphone rotating slowly on a matte black pedestal. Soft studio lighting creates clean highlights on the brushed metal surface. Camera orbits 180 degrees at eye level. Minimalist white background, no shadows. Smooth continuous motion, commercial product photography quality.
Escenarios adecuados: páginas de detalles de productos de comercio electrónico, marketing de productos, vídeos de imágenes principales de Taobao/JD.com.
- Naturaleza cinematográfica
An epic aerial drone shot over a misty mountain valley at sunrise. Golden light breaks through layered clouds, illuminating a winding river below. Camera pushes forward slowly, revealing the vast landscape. Volumetric fog drifts between peaks. IMAX cinematography quality, hyper-detailed.
Adecuado para: vídeos de introducción de YouTube/Bilibili, contenido de viajes, salvapantallas, canales de meditación.
4. Calle urbana
A neon-lit Tokyo alley at night after rain. Wet cobblestones reflect vivid pink, teal, and amber neon signs. A lone figure walks away from camera, umbrella in hand. Steam rises from a street vent. Camera follows at a distance, tracking shot. Film noir atmosphere, anamorphic lens flare.
Escenarios adecuados: vídeos musicales, metraje atmosférico de segundo plano, contenido de estilo cyberpunk.
- Estilo anime
An anime warrior princess with flowing silver hair stands on a cliff edge overlooking a fantasy kingdom. Her cape billows dramatically in the wind. She raises a glowing sword that emits blue energy particles. Cherry blossom petals drift past. Camera slowly orbits. Studio Ghibli meets Ufotable quality animation.
Adecuado para: Contenido animado, canales de videojuegos, narrativas fantásticas.
6. Comida y bebida
Extreme macro close-up of rich dark coffee being poured in slow motion into a pristine ceramic cup. Individual droplets and tiny splashes frozen mid-air. Wisps of steam curl elegantly upward. Warm side lighting reveals the liquid's amber transparency. Cinnamon stick and scattered beans visible in soft focus foreground.
Escenarios adecuados: Marketing de alimentos y bebidas, blogueros gastronómicos, publicidad de bebidas.
- Moda y editorial
A model in a flowing white silk gown walks confidently down a dark runway. Multiple flash strobes create sharp geometric light patterns. The fabric billows with perfect physics. Camera at a low angle, slight slow motion. High fashion editorial aesthetic, Vogue magazine quality.
Escenarios adecuados: marcas de moda, contenido de belleza, artículos editoriales.
- Ciencia ficción y fantasía
A massive spaceship emerges from hyperspace above a ringed planet. Blue energy dissipates around the hull as the vessel decelerates. Tiny fighter escorts flank its sides. Camera pulls back to reveal the scale against the planet. Volumetric space dust and distant star field. Hollywood VFX quality.
Escenarios adecuados: Contenido de entretenimiento, canales de ciencia ficción, visualización de conceptos.
- Deportes y acción
A basketball player at the peak of a slam dunk, frozen in mid-air. Time resumes in slow motion — sweat droplets fly, the ball compresses against the rim, arena spotlights create dramatic lens flare. Camera shoots from below looking up. ESPN broadcast quality, hyper-detailed.
Escenarios adecuados: Contenido deportivo, marcas deportivas, recopilaciones de momentos destacados.
- Arte abstracto (abstracto y artístico)
Liquid gold and deep indigo ink collide in slow motion inside a glass sphere. The fluids intertwine in mesmerizing fractal patterns. Tiny bubbles catch light. Camera slowly rotates around the sphere. Pure black background. Macro photography meets fluid dynamics simulation. Meditative, hypnotic pace.
Escenarios adecuados: Imágenes de fondo, vídeos musicales, instalaciones artísticas, salvapantallas.

El resultado real de cuatro de las diez plantillas anteriores: cada indicador genera imágenes distintas con calidad cinematográfica a partir de texto sin formato.
Resumen de 2026: comparación de 8 herramientas de conversión de texto a vídeo
Probamos ocho plataformas principales utilizando la misma indicación («Un golden retriever corriendo por un prado soleado, con flores silvestres meciéndose, calidad cinematográfica 4K») y las puntuamos en cinco dimensiones. Todas las pruebas se completaron en febrero de 2026.
| Herramienta | Resolución máxima | Duración máxima | Versión gratuita | Audio | Mejor uso | Calificación de calidad de imagen | |------|----------|---------|--------|------|-------- -|---------| | Seedance 2.0 | 2K (2048×1080) | 15 segundos | ✅ Cuota diaria gratuita | ✅ Efectos de sonido + música + sincronización labial | Creación multimodal | 9,2/10 | | Google Veo 3 | 4K (limitado) | 8 segundos | ✅ Cuota de AI Studio | ✅ Audio nativo | Fusión audiovisual | 9,0/10 | | Sora 2 | 1080p | 20 segundos | ❌ Requiere ChatGPT Plus | ❌ | Vídeo basado en texto largo | 8,8/10 | | Keling 3.0 | 1080p | Más de 20 segundos | ✅ Créditos de registro gratuitos | ⚠️ Limitado | Vídeos largos, buena relación calidad-precio | 8,5/10 | | Runway Gen-4 | 1080p | 10 segundos | ✅ 125 créditos | ❌ | Flujo de trabajo de edición profesional | 8,5/10 | | Pika 2.0 | 1080p | 10 segundos | ✅ Cuota diaria gratuita | ⚠️ Solo efectos de sonido | Principiantes, efectos divertidos | 8,0/10 | | Luma Dream Machine | 1080p | 5 segundos | ✅ Generación gratuita | ❌ | Escenas en 3D, iteración rápida | 7,8/10 | | Snail AI (MiniMax) | 1080p | 6 segundos | ✅ Gratis diario | ❌ | Velocidad de generación más rápida | 7,5/10 |
Aviso importante para usuarios nacionales: Se puede acceder directamente a Seedance 2.0, KeLing 3.0 y Haier AI desde China continental. Sora 2 requiere una suscripción a ChatGPT Plus (se necesita VPN). Google Veo 3 requiere acceso a través de Google AI Studio (se necesita VPN). Runway, Pika y Luma requieren una conexión de red internacional.
Alternativas nacionales: Tongyi Wanxiang (Alibaba), Hunyuan Video (Tencent) y Qingying (filial de ByteDance) también ofrecen funciones de generación de texto a vídeo, con diferentes cuotas de uso gratuito.
Conclusiones clave:
- Mejor calidad de imagen general: Seedance 2.0 (2K nativo + entrada cuádruple + audio)
- Mejores capacidades de audio: Seedance 2.0 y Google Veo 3
- Mejor versión gratuita: Seedance 2.0 (acceso gratuito a resolución 2K, sin necesidad de tarjeta de crédito)
- Mayor duración de vídeo gratuito: Keeling 3.0 (más de 20 segundos)
- Más fácil de usar para principiantes: Pika 2.0 (interfaz más sencilla, efectos divertidos)
Para obtener una comparación más detallada, consulte La comparación completa de los mejores generadores de vídeo con IA para 2026. Si desea centrarse únicamente en los planes gratuitos, consulte Una revisión comparativa de los generadores de vídeo con IA gratuitos.
6 escenarios de aplicación clave
- Contenido de redes sociales
Crea vídeos cortos llamativos para Douyin, Kuaishou, Xiaohongshu, Bilibili y YouTube Shorts. La IA elimina por completo la necesidad de grabar, editar y realizar la posproducción.
Especificaciones recomendadas: relación de aspecto 9:16, duración de 5 a 15 segundos, con una apertura visualmente impactante en el primer segundo.
- Marketing y publicidad
Produce en masa variantes de material publicitario. Prueba múltiples conceptos visuales utilizando diferentes indicaciones antes de comprometerte con el presupuesto de producción formal. Genera versiones de prueba A/B en cuestión de minutos.
Configuración recomendada: Compatibilidad multiformato en múltiples plataformas. Combínelo con las capacidades de audio de Seedance para producir películas publicitarias completas.
3. Educación y formación
Visualizar conceptos abstractos que son difíciles o imposibles de capturar en una película: estructuras moleculares, acontecimientos históricos, conceptos matemáticos, procesos científicos. El vídeo con IA hace visible lo invisible.
Configuración recomendada: Para obtener resultados óptimos en la enseñanza, combine una indicación que articule con precisión el concepto con audio narrado.
- Entretenimiento y narrativa
Los cineastas independientes y los creadores de historias utilizan la tecnología de conversión de texto a vídeo para la visualización de conceptos, la creación de guiones gráficos e incluso la producción final de cortometrajes. Esta tecnología democratiza la realización cinematográfica.
Configuración recomendada: Incluya especificaciones detalladas sobre la dirección de la cámara y la iluminación en las instrucciones para lograr un efecto cinematográfico.
- Vídeos de productos de comercio electrónico
Transforme las descripciones de los productos en vídeos de demostración de los mismos. Esto resulta especialmente útil para los minoristas con cientos de referencias que no pueden grabar vídeos individuales para cada producto. Para obtener información detallada sobre los flujos de trabajo del comercio electrónico, consulte la Guía de vídeos de comercio electrónico con IA.
Especificaciones recomendadas: Fotografía de productos con iluminación de estudio. Relación de aspecto 1:1 para páginas de detalles del producto, 16:9 para YouTube/Bilibili, 9:16 para TikTok/Xiaohongshu.
6. Creación de contenido para YouTube / Bilibili
Genera material de archivo B-roll, secuencias introductorias, comentarios visuales y vídeos cortos completos. Los creadores pueden mejorar la eficiencia en la producción de contenido con la tecnología de vídeo con IA. Para conocer el flujo de trabajo completo de los creadores de YouTube, consulta la Guía para creadores de YouTube sobre vídeo con IA.
Configuración recomendada: Mantenga la coherencia visual en todos los canales dentro de cada mensaje para establecer el reconocimiento de la marca.
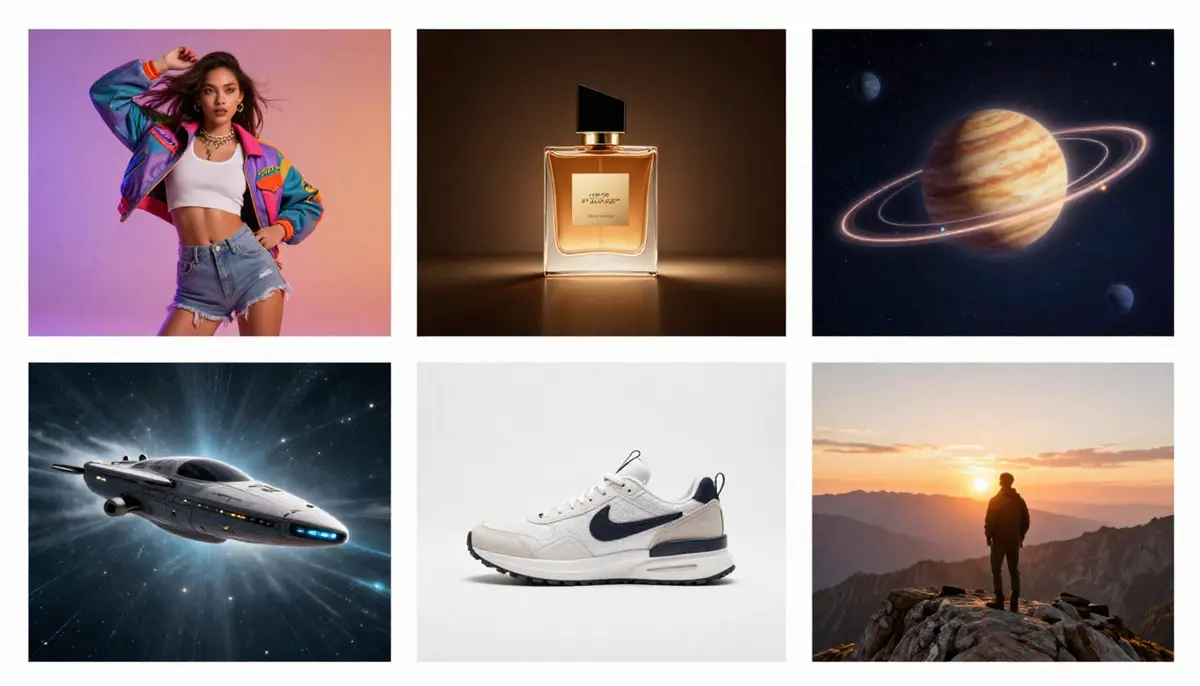
Seis aplicaciones prácticas de la IA de texto a vídeo: desde cortometrajes en redes sociales hasta demostraciones de productos de comercio electrónico y visualización de conceptos educativos.
Texto a vídeo frente a imagen a vídeo: ¿cuándo usar cada uno?
Esta es una de las preguntas más frecuentes de los nuevos usuarios. La respuesta depende de los materiales que tengas disponibles y de lo que necesites.

Dos vías hacia el vídeo con IA: la generación de texto a vídeo parte del texto escrito, mientras que la generación de imagen a vídeo comienza con fotografías existentes.
Escenarios para texto a vídeo (T2V):
- Desea crear contenido totalmente nuevo (sin imágenes de referencia).
- Desea la máxima libertad creativa.
- Está llevando a cabo una exploración conceptual o una lluvia de ideas visuales.
- Necesita escenas abstractas o imposibles de fotografiar (ciencia ficción, fantasía, microscópicas/macroscópicas).
- Desea iterar rápidamente: cambiar una indicación produce una escena completamente diferente.
Escenarios para generar vídeos a partir de imágenes (I2V):
- Tienes una fotografía específica que requiere una transformación dinámica
- Necesitas un resultado que coincida exactamente con los efectos visuales existentes
- Estás convirtiendo imágenes de productos en vídeos de productos
- Necesitas coherencia en los personajes (la misma persona en todas las escenas)
- Deseas resultados más predecibles y controlables
Mejores prácticas: combinación de ambos enfoques:
- Utilizar la generación de texto a vídeo para explorar direcciones creativas.
- Seleccionar el fotograma óptimo como imagen de referencia.
- Emplear la generación de imagen a vídeo para obtener una versión final refinada y controlable.
Para obtener información sobre un flujo de trabajo completo de generación de vídeo a partir de imágenes, consulte la Guía completa de IA para la conversión de imágenes a vídeo.
Limitaciones actuales: una evaluación honesta
La IA de conversión de texto a vídeo de 2026 es impresionante, pero aún está lejos de ser perfecta. A continuación se indican las áreas en las que actualmente destaca y aquellas que siguen siendo un reto.
Bien hecho
- Vídeos cortos (5-15 segundos): Calidad de imagen cercana a los estándares cinematográficos
- Escenas con un solo sujeto: Una persona, un animal, un objeto: resultados excelentes
- Naturaleza y paisajes: Representación excepcional de la dinámica de fluidos, el clima y los efectos atmosféricos
- Contenido estilizado: Animación, cine negro, ciencia ficción: conversión de estilo altamente fiable
- Visualizaciones de rotación de productos: movimiento sencillo del producto con buena consistencia
- Movimientos de cámara: panorámica, zoom, dolly, travellings: bien controlados
Sigue siendo difícil
- Manos y dedos: Los dedos supernumerarios, los gestos inverosímiles y las deformidades en los dedos siguen siendo habituales
- Representación del texto: El texto legible en los vídeos resulta poco fiable: las letras aparecen distorsionadas y los caracteres deformados
- Interacciones complejas entre varias personas: Los apretones de manos entre dos personas, los bailes en pareja o los combates suelen mostrar una desorganización de las extremidades . - Narrativa prolongada (>30 segundos): El mantenimiento de la coherencia de la escena durante períodos prolongados se degrada . - Física precisa: Rebote preciso de la pelota, agua que se vierte en recipientes específicos: la física es aproximada, no exacta
- Consistencia facial a largo plazo: Los rasgos faciales pueden sufrir cambios sutiles entre fotogramas, especialmente durante periodos prolongados.
Tendencia de progreso
Cada una de estas limitaciones mejorará significativamente para 2026 en comparación con 2024. El ritmo de mejora es exponencial. El renderizado manual pasará de «siempre incorrecto» a «generalmente preciso». La consistencia facial pasará de «comenzar a desviarse después de 2 segundos» a «permanecer estable durante 10-15 segundos». El renderizado de texto avanzará de «ilegible» a «ocasionalmente legible». Se espera que estos problemas sigan mejorando rápidamente entre 2026 y 2027.
Preguntas frecuentes
¿Cuál es la mejor IA de texto a vídeo para 2026?
Seedance 2.0 lidera la calidad de imagen general con una resolución nativa de 2K, entrada cuádruple y generación de audio integrada. Google Veo 3 destaca en la fusión audiovisual y la simulación física. Sora 2 ofrece la mayor duración de una sola generación (20 segundos). La «mejor» opción depende de tus requisitos específicos: resolución, audio, duración o precio. Los usuarios domésticos también pueden considerar KeLing 3.0 (alta relación calidad-precio, vídeos largos) y Tongyi Wanxiang (integrado con el ecosistema Alibaba).
¿Existe alguna IA gratuita para convertir texto en vídeo?
Sí. Seedance 2.0 ofrece una cuota diaria gratuita sin necesidad de tarjeta de crédito. Pika 2.0 ofrece generación diaria gratuita. Ke Ling 3.0 concede una cuota por registrarse. Google Veo 3 ofrece cuotas gratuitas a través de AI Studio. Conch AI también ofrece una cuota diaria gratuita. Para más detalles, consulte Comparación de generadores de vídeo con IA gratuitos.
¿Qué duración pueden tener los vídeos generados por IA a partir de texto?
La mayoría de las herramientas generan contenido en incrementos de 5 a 15 segundos. Sora 2 admite hasta 20 segundos. Keeling 3.0 admite más de 20 segundos. Para requisitos de contenido más largos, se pueden generar varios segmentos y unirlos mediante software de edición como Kinevision, Premiere Pro o DaVinci Resolve.
¿Puede la IA de texto a vídeo lograr imágenes de calidad profesional?
En un intervalo de tiempo de entre 5 y 15 segundos, es factible. El resultado de Seedance 2.0 y Veo 3 suele ser indistinguible del metraje profesional en clips cortos. Para proyectos más extensos, el vídeo generado por IA se utiliza mejor como un componente del material (rollos B, tomas de transición, efectos visuales), en lugar de como la totalidad de la producción.
¿Cómo crear indicaciones eficaces para la generación de texto a vídeo?
Sigue la fórmula: Sujeto + Acción + Escenario + Estilo + Toma + Iluminación. Las descripciones del movimiento deben ser específicas, los movimientos de la cámara deben estar claramente definidos y la atmósfera debe estar claramente establecida. Evita las contradicciones y abstente de solicitar elementos de texto/interfaz de usuario. Repite progresivamente de lo simple a lo complejo. Para más detalles, consulta la Guía de redacción de indicaciones.
¿Qué es mejor: la generación de vídeo a partir de texto o la generación de vídeo a partir de imágenes?
Diferentes aplicaciones. La conversión de texto a vídeo ofrece la máxima libertad creativa cuando no se dispone de material de referencia. La conversión de imagen a vídeo proporciona un mayor control cuando existe un punto de partida visual específico. La mayoría de los profesionales utilizan ambos enfoques: emplean la conversión de texto a vídeo para el trabajo exploratorio y la conversión de imagen a vídeo para el perfeccionamiento.
¿Se pueden utilizar comercialmente los vídeos generados por IA a partir de texto?
La mayoría de los planes de pago otorgan derechos comerciales. La versión de pago de Seedance 2.0 incluye derechos comerciales completos y no tiene marcas de agua. Las condiciones del servicio varían según la plataforma; comprueba las políticas específicas antes de utilizarlo. En China, el uso comercial de contenidos generados por IA no se enfrenta actualmente a restricciones normativas explícitas, aunque es aconsejable estar al tanto de las actualizaciones de las Medidas provisionales para la administración de los servicios de inteligencia artificial generativa.
¿La IA de texto a vídeo sustituirá a los editores?
No sustituirá, sino que modificará las funciones. La IA se encarga de la generación de contenidos, creando recursos visuales originales a partir de descripciones. Los editores humanos gestionan la narrativa, el ritmo, la resonancia emocional, la coherencia de la marca y las decisiones creativas que requieren el juicio humano. Para 2026, el flujo de trabajo más eficaz será la generación mediante IA + la edición humana.
Empieza a crear vídeos con texto
Para 2026, la IA de texto a vídeo estará lista para aplicaciones profesionales. Tras haber evolucionado desde experimentos GAN borrosos hasta resultados DiT casi cinematográficos en solo cuatro años, esta tecnología ahora es capaz de manejar contenido de redes sociales, demostraciones de productos, visualizaciones educativas y exploración creativa.
La mejor manera de aprender es empezar a generar. Escribe una indicación, observa los resultados y repite.
Convierte tu primer párrafo en vídeo: prueba Seedance gratis →
¿Buscas una mayor precisión en el control? Prueba la generación de vídeo a partir de imágenes →
¿Quieres profundizar en las técnicas de prompts? Lee nuestra Guía para escribir prompts →
