
لمحة عامة
تقنية Text-to-Video AI هي تقنية ذكاء اصطناعي تولد مقاطع فيديو تلقائيًا من الأوصاف النصية. أدخل وصفًا، وستنتج تقنية الذكاء الاصطناعي مقطع فيديو يتضمن حركة وتأثيرات إضاءة وحركات الكاميرا. بحلول عام 2026، وبالاستفادة من بنية Diffusion Transformer (DiT)، تطورت هذه التكنولوجيا من نموذج تجريبي غامض إلى جودة شبه سينمائية. يغطي هذا الدليل المبادئ التقنية، ودليلًا عمليًا من خمس خطوات، وعشرة قوالب موجهة قابلة للتكرار، وتحليلًا مقارنًا لثمانية أدوات، وستة سيناريوهات تطبيق رئيسية، والقيود الحقيقية التي يجب أن تفهمها.جرب إنشاء الفيديو من النص مجانًا →

تقنية تحويل النص إلى فيديو باستخدام الذكاء الاصطناعي: من وصف واحد إلى لقطات بجودة سينمائية، يجعل الذكاء الاصطناعي تقنية "تحويل النص إلى فيديو" حقيقة واقعة.
ما هو الذكاء الاصطناعي لتحويل النص إلى فيديو؟
يشير مصطلح "الذكاء الاصطناعي لتحويل النص إلى فيديو" إلى فئة من تقنيات الذكاء الاصطناعي التي تولد محتوى فيديو تلقائيًا من الأوصاف النصية. يمكنك وصف مشهد ما — امرأة تمشي تحت المطر، منتج يدور على منصة عرض، طائرة بدون طيار تحلق فوق سلاسل جبلية — ويقوم نموذج الذكاء الاصطناعي بإنتاج مقطع فيديو واقعي بشكل ملحوظ يتميز بحركة طبيعية وإضاءة وتأثيرات فيزيائية.
المفهوم الأساسي بسيط: إدخال نص، إخراج فيديو. لكن التكنولوجيا الأساسية بعيدة كل البعد عن البساطة. تستخدم أنظمة تحويل النص إلى فيديو الحديثة شبكات عصبية مدربة على مليارات من مجموعات البيانات المقترنة "الفيديو-النص"، لتتعلم العلاقات الإحصائية بين الأوصاف اللغوية والحركة البصرية. عندما تكتب "قطة تقفز على طاولة"، يستند النموذج إلى معرفته المتراكمة عن القطط، وفيزياء القفز، وأسطح الطاولات، والجاذبية لإنتاج فيديو معقول.
2026: من التجربة إلى أداة الإنتاجية
تجاوزت تقنية الذكاء الاصطناعي لتحويل النص إلى فيديو عتبة القدرة على "الجاهزية للإنتاج" في 2025-2026. لم تكن الأنظمة المبكرة من 2022-2023 قادرة إلا على إنتاج مقاطع قصيرة وغير واضحة وغير قابلة للتصديق من الناحية الفيزيائية. لكن النماذج الحالية تنتج مقاطع فيديو بدقة 2K مع حركة دقيقة من الناحية الفيزيائية ورسوم متحركة طبيعية وجودة سينمائية، وتستمر من 5 إلى 15 ثانية. هذا القفزة تحول تحويل النص إلى فيديو من مجرد فضول بحثي إلى أداة عملية:
- مبدعو المحتوى: الحصول على لقطات B-roll ومقاطع مقدمة ومواد وسائل التواصل الاجتماعي دون الحاجة إلى كاميرا
- المسوقون: إنتاج نسخ إعلانية متنوعة وعروض توضيحية للمنتجات بكميات كبيرة
- المعلمون: تصور المفاهيم المجردة
- الشركات الصغيرة والمتوسطة: تجنب التكاليف الباهظة لإنتاج الفيديوهات الاحترافية
- أي شخص: إذا كنت تستطيع الكتابة، يمكنك إنتاج الفيديوهات
انخفضت عتبة إنشاء الفيديو من "امتلاك كاميرا ومعرفة كيفية التحرير" إلى "صياغة وصف جذاب".
التطور التكنولوجي: من GAN إلى DiT
فهم التكنولوجيا الأساسية يمكن أن يساعدك في صياغة مطالبات أفضل واختيار أدوات أكثر ملاءمة. فيما يلي التطور التكنولوجي لثلاثة أجيال من الذكاء الاصطناعي لتحويل النص إلى فيديو.

ثلاثة أجيال من التطور التكنولوجي: GANs (2020-2022) → نماذج الانتشار (2023-2024) → محولات الانتشار / DiT (2025-2026).
الجيل الأول: عصر GAN (2020-2022)
كانت الشبكات التنافسية التوليدية (GANs) أول بنية تثبت جدوى تحويل "النص إلى فيديو". تخضع شبكتان عصبيتان لتدريب تنافسي — يقوم المولد بإنشاء إطارات فيديو بينما يقوم المميز بتقييم مدى صحتها. ومع ذلك، كانت النتائج منخفضة الدقة (256×256) وقصيرة المدة (2-4 ثوانٍ) وغير قابلة للتصديق من الناحية الفيزيائية. تخضع الكائنات لتشوهات غير متوقعة، وتصبح ملامح الوجه مشوهة، ويتأثر الاتساق الزمني بشكل كبير. تشمل الإنجازات التمثيلية CogVideo و NUWA.
الجيل الثاني: عصر نماذج الانتشار (2023-2024)
لقد أدى نموذج الانتشار إلى إعادة تشكيل المشهد بشكل جذري. فهو لم يعد يستخدم التدريب التنافسي، بل يتعلم عملية "إزالة الضوضاء العكسية" — بدءًا من الضوضاء النقية وإزالة الضوضاء تدريجيًا لتحويلها إلى فيديو متماسك موجه بالنص. يوفر هذا النهج قفزة نوعية: دقة أعلى (تصل إلى 1080p)، ومدة أطول (4-10 ثوانٍ)، وتحسين التوافق بين النص والصورة.
أثبتت Sora من OpenAI (التي تم إصدارها في فبراير 2024) أن نماذج الانتشار يمكنها إنتاج مقاطع فيديو واقعية بشكل مذهل. تنتمي Runway Gen-2/Gen-3 و Pika و Stable Video Diffusion إلى هذا الجيل.
الجيل الثالث: DiT — محول الانتشار (2025–2026)
تجمع أحدث البنى المعمارية حالياً بين عمليات الانتشار وبنية Transformer (نفس البنية المعمارية المستخدمة في GPT و BERT). تعالج نماذج DiT الفيديو كسلسلة من البقع المكانية والزمانية، مما يحقق:
- تحسين الاتساق الزمني: تتميز المحولات بتميزها في نمذجة التبعيات بعيدة المدى عبر الإطارات
- دقة أعلى: إخراج 2K أصلي (يحقق Seedance 2.0 2048×1080)
- دقة فيزيائية محسنة: حركة وجاذبية وديناميكيات سوائل أكثر واقعية
- فهم أقوى للنصوص: تحسين كبير في التوافق بين الأوصاف السريعة والمخرجات المرئية
- إدخال متعدد الوسائط: يمكن لنماذج DiT المحددة معالجة مدخلات الصور والفيديو والصوت في وقت واحد
تستخدم Seedance 2.0 و Google Veo 3 و Keeling 3.0 جميعها بنية DiT. ولهذا السبب، يظهر توليد النصوص إلى فيديو في عام 2026 اختلافًا نوعيًا مقارنةً بعام 2024.
تحويل النص إلى فيديو مقابل تحويل الصورة إلى فيديو
هذان النهجان متكاملان وليس متنافسان:
| البعد | تحويل النص إلى فيديو (T2V) | تحويل الصورة إلى فيديو (I2V) | |------|------------------|----------------- -| | الإدخال | وصف نصي فقط | صورة فوتوغرافية + وصف الحركة | | الحرية الإبداعية | أعلى — يحدد الذكاء الاصطناعي جميع العناصر المرئية | مقيد بالصورة المصدرية | | قابلية التحكم | أقل — يعتمد على دقة الموجه | أعلى — تتوفر نقاط ارتكاز مرئية | | السيناريوهات المناسبة | استكشاف المفاهيم، المحتوى الأصلي | عرض المنتج، الرسوم المتحركة للصور، مطابقة الأنماط | | القدرة على التنبؤ | منخفضة — نفس الموجهة تعطي نتائج مختلفة في كل مرة | عالية — الناتج يتطابق باستمرار مع الصورة المصدر |
تستخدم معظم سير العمل الاحترافية كلا النهجين: أولاً استخدام T2V لاستكشاف المفاهيم الإبداعية، ثم صقل النتائج باستخدام I2V. للاطلاع على استكشاف مفصل لتوليد الصور إلى فيديو، راجع الدليل الكامل للذكاء الاصطناعي لتحويل الصور إلى فيديو.
دليل تعليمي من 5 خطوات: إنشاء أول فيديو بالذكاء الاصطناعي
فيما يلي دليل تفصيلي لإنشاء محتوى نصي إلى فيديو من البداية، باستخدام Seedance 2.0 كمنصة عرض توضيحي. تنطبق المبادئ الأساسية على أي أداة.

من الإنشاء الفوري إلى الناتج النهائي: خمس خطوات لإكمال أول فيديو لك باستخدام الذكاء الاصطناعي.
الخطوة 1: تحديد أهداف الفيديو
قبل كتابة الموجه، حدد أولاً:
- النوع: لقطات B-roll، عروض منتجات، محتوى وسائل التواصل الاجتماعي، إبداعات فنية أو سرد؟
- المدة: 5 ثوانٍ للاختبار، 10-15 ثانية للناتج النهائي
- نسبة العرض إلى الارتفاع: 16:9 لـ YouTube / Bilibili، 9:16 لـ Douyin / Kuaishou / Xiaohongshu، 1:1 لـ WeChat Moments
- النمط: سينمائي، وثائقي، رسوم متحركة، إعلان تجاري، أو فني
تحديد أهداف واضحة يمنع إهدار حصص التوليد على تجارب غامضة.
الخطوة 2: صياغة نصوص عالية الجودة
الموجه هو جوهر إنشاء الفيديو من النص. استخدم الصيغة التالية:
[الموضوع] + [الحركة/التحرك] + [الإعداد] + [الأسلوب] + [حركة الكاميرا] + [الإضاءة]
موجه سيئ: "كلب يركض"
مشهد جيد: "كلب من فصيلة غولدن ريتريفر يركض في مرج مشمس، وأزهار برية تتمايل مع النسيم. يتماوج فراء الكلب مع كل خطوة. الكاميرا تتبعه على مستوى الأرض. إضاءة دافئة في الساعة الذهبية مع ظلال طويلة. عمق مجال سطحي سينمائي، جودة 4K."
المبادئ الأساسية:
- يجب أن تكون الحركة محددة: "يدير رأسه ببطء" بدلاً من "يدير"
- صف حركات الكاميرا: "تقترب الكاميرا" أو "لقطة جوية بطائرة بدون طيار"
- حدد الأجواء: الإضاءة، تدرج الألوان، الأجواء
- تجنب التناقضات: لا تطلب "حركة سريعة" و"حركة بطيئة" في نفس الوقت
- لا تطلب نصًا/واجهة مستخدم: يواجه النموذج الحالي صعوبة في عرض نص واضح داخل لقطات الفيديو
ملاحظة: يُنصح بكتابة المطالبات باللغة الإنجليزية، حتى عند استخدام الأدوات المحلية (KeLing، TongYi WanXiang، Hunyuan Video)، حيث أن معظم النماذج تم تدريبها على مجموعات بيانات إنجليزية أكثر شمولاً.
للحصول على نظام تقنيات موجهة أكثر شمولاً، يرجى الرجوع إلى دليل كتابة الموجهات و10 موجهات فيديو فعالة حقًا للذكاء الاصطناعي.
الخطوة 3: حدد الأدوات والمعلمات
حدد منصة (انظر جدول المقارنة أدناه)، ثم قم بالتكوين:
- النموذج: استخدم أحدث نموذج متاح (على سبيل المثال، Seedance 2.0، وليس 1.0)
- الدقة: 1080p كحد أدنى؛ اختر 2K إذا كان متاحًا
- المدة: اختبر بـ 5 ثوانٍ في البداية، وقم بتمديدها إذا كانت مرضية
- نسبة العرض إلى الارتفاع: طابقها مع منصة التوزيع الخاصة بك
- قيمة البذرة (إذا كانت متاحة): قم بتثبيت البذرة للحصول على تكرار متسق
الخطوة 4: إنشاء ومراجعة
انقر فوق "إنشاء" وانتظر لمدة 60-180 ثانية (حسب الأداة). عند مراجعة النتيجة، انتبه إلى:
- ✅ هل تتطابق الحركة مع الوصف؟
- ✅ هل الموضوع متسق طوال الوقت (بدون تشويه)؟
- ✅ هل الفيزياء معقولة (الجاذبية، السوائل، الأقمشة)؟
- ✅ هل حركة الكاميرا سلسة؟
- ❌ هل هناك أي عيوب أو وميض أو تشويه؟
- ❌ هل هناك تأثير غريب على الوجوه/الأيدي؟
الخطوة 5: التحسين التكراري
نادراً ما تكون المحاولة الأولى مثالية. طرق التحسين:
- اضبط الموجه: أضف التفاصيل التي أخطأت فيها الذكاء الاصطناعي
- قم بتغيير متغير واحد فقط في كل مرة: لا تعيد كتابة الموجه بالكامل
- جرب بذور مختلفة: قد يؤدي نفس الموجه إلى نتائج مختلفة تمامًا
- قم بتمديد المدة: بمجرد أن تصبح راضيًا عن النسخة التي مدتها 5 ثوانٍ، جرب 10-15 ثانية
- أضف صوتًا: إذا كانت الأداة تدعم ذلك (Seedance، Veo 3)، فقم بدمج مؤثرات صوتية أو موسيقى خلفية

أمثلة على التكرار السريع: V1 (الموجه الأساسي) → V2 (إضافة أوصاف الحركة والإضاءة) → V3 (المواصفات السينمائية الكاملة). كل دورة تحسين تعزز جودة الصورة بشكل كبير.
10 قوالب موجهة لتوليد الفيديو من النص
يمكن نسخ القوالب التالية واستخدامها مباشرة. وقد تم اختبارها على Seedance 2.0 وهي متوافقة مع معظم المنصات الشائعة.
1. صورة سينمائية
A close-up of a young woman with flowing dark hair, her face illuminated by warm golden hour sunlight filtering through a window. She slowly turns her head toward the camera, a subtle smile forming. Soft bokeh background of a cozy interior. Camera holds steady with a slight push-in. Warm amber lighting, shallow depth of field, 4K cinematic quality.
السيناريوهات المناسبة: وسائل التواصل الاجتماعي، العلامة التجارية الشخصية، الإبداع الفني
- عرض المنتجات
A sleek wireless headphone rotating slowly on a matte black pedestal. Soft studio lighting creates clean highlights on the brushed metal surface. Camera orbits 180 degrees at eye level. Minimalist white background, no shadows. Smooth continuous motion, commercial product photography quality.
السيناريوهات المناسبة: صفحات تفاصيل منتجات التجارة الإلكترونية، تسويق المنتجات، مقاطع الفيديو الرئيسية لصور Taobao/JD.com
- الطبيعة السينمائية
An epic aerial drone shot over a misty mountain valley at sunrise. Golden light breaks through layered clouds, illuminating a winding river below. Camera pushes forward slowly, revealing the vast landscape. Volumetric fog drifts between peaks. IMAX cinematography quality, hyper-detailed.
مناسب لـ: مقاطع فيديو مقدمة YouTube/Bilibili، محتوى السفر، شاشات التوقف، قنوات التأمل
4. شارع حضري
A neon-lit Tokyo alley at night after rain. Wet cobblestones reflect vivid pink, teal, and amber neon signs. A lone figure walks away from camera, umbrella in hand. Steam rises from a street vent. Camera follows at a distance, tracking shot. Film noir atmosphere, anamorphic lens flare.
السيناريوهات المناسبة: مقاطع الفيديو الموسيقية، لقطات B-roll ذات أجواء خاصة، محتوى على طراز السايبربانك
- أسلوب الأنيمي
An anime warrior princess with flowing silver hair stands on a cliff edge overlooking a fantasy kingdom. Her cape billows dramatically in the wind. She raises a glowing sword that emits blue energy particles. Cherry blossom petals drift past. Camera slowly orbits. Studio Ghibli meets Ufotable quality animation.
مناسب لـ: المحتوى المتحرك، قنوات الألعاب، القصص الخيالية
6. الأطعمة والمشروبات
Extreme macro close-up of rich dark coffee being poured in slow motion into a pristine ceramic cup. Individual droplets and tiny splashes frozen mid-air. Wisps of steam curl elegantly upward. Warm side lighting reveals the liquid's amber transparency. Cinnamon stick and scattered beans visible in soft focus foreground.
السيناريوهات المناسبة: تسويق الأغذية والمشروبات، مدونو الأغذية، إعلانات المشروبات
- الموضة والتحرير
A model in a flowing white silk gown walks confidently down a dark runway. Multiple flash strobes create sharp geometric light patterns. The fabric billows with perfect physics. Camera at a low angle, slight slow motion. High fashion editorial aesthetic, Vogue magazine quality.
السيناريوهات المناسبة: العلامات التجارية للأزياء، محتوى الجمال، المقالات التحريرية
- الخيال العلمي والفانتازيا
A massive spaceship emerges from hyperspace above a ringed planet. Blue energy dissipates around the hull as the vessel decelerates. Tiny fighter escorts flank its sides. Camera pulls back to reveal the scale against the planet. Volumetric space dust and distant star field. Hollywood VFX quality.
السيناريوهات القابلة للتطبيق: محتوى ترفيهي، قنوات خيال علمي، تصور المفاهيم
- الرياضة والحركة
A basketball player at the peak of a slam dunk, frozen in mid-air. Time resumes in slow motion — sweat droplets fly, the ball compresses against the rim, arena spotlights create dramatic lens flare. Camera shoots from below looking up. ESPN broadcast quality, hyper-detailed.
السيناريوهات المناسبة: المحتوى الرياضي، العلامات التجارية الرياضية، مجموعات أبرز اللقطات
- الفن التجريدي (تجريدي وفني)
Liquid gold and deep indigo ink collide in slow motion inside a glass sphere. The fluids intertwine in mesmerizing fractal patterns. Tiny bubbles catch light. Camera slowly rotates around the sphere. Pure black background. Macro photography meets fluid dynamics simulation. Meditative, hypnotic pace.
السيناريوهات المناسبة: صور خلفية، مقاطع فيديو موسيقية، تركيبات فنية، شاشات توقف

الناتج الفعلي من أربعة من القوالب العشرة المذكورة أعلاه — كل موجه يولد صورًا ذات أسلوب مميز وجودة سينمائية من نص عادي.
ملخص عام 2026: مقارنة بين 8 أدوات لتحويل النص إلى فيديو
قمنا باختبار ثماني منصات رئيسية باستخدام نفس الموجه ("كلب من فصيلة غولدن ريتريفر يركض في مرج مشمس، وأزهار برية تتمايل، وجودة سينمائية 4K")، وقمنا بتقييمها عبر خمسة أبعاد. تم الانتهاء من جميع الاختبارات في فبراير 2026.
| الأداة | الدقة القصوى | المدة القصوى | الإصدار المجاني | الصوت | أفضل استخدام | تقييم جودة الصورة | |------|----------|---------|--------|------|-------- -|---------| | Seedance 2.0 | 2K (2048×1080) | 15 ثانية | ✅ حصة يومية مجانية | ✅ مؤثرات صوتية + موسيقى + مزامنة شفاه | إنشاء متعدد الوسائط | 9.2/10 | | Google Veo 3 | 4K (محدود) | 8 ثوانٍ | ✅ حصة AI Studio | ✅ صوت أصلي | دمج صوتي ومرئي | 9.0/10 | | Sora 2 | 1080p | 20 ثانية | ❌ يتطلب ChatGPT Plus | ❌ | فيديو مدفوع بنص طويل | 8.8/10 | | Keling 3.0 | 1080p | 20+ ثانية | ✅ رصيد تسجيل مجاني | ⚠️ محدود | مقاطع فيديو طويلة، قيمة مقابل المال | 8.5/10 | | Runway Gen-4 | 1080p | 10 ثوانٍ | ✅ 125 رصيد | ❌ | سير عمل تحرير احترافي | 8.5/10 | | Pika 2.0 | 1080p | 10 ثوانٍ | ✅ حصة يومية مجانية | ⚠️ مؤثرات صوتية فقط | مبتدئون، مؤثرات مرحة | 8.0/10 | | Luma Dream Machine | 1080p | 5 ثوانٍ | ✅ إنشاء مجاني | ❌ | مشاهد ثلاثية الأبعاد، تكرار سريع | 7.8/10 | | Snail AI (MiniMax) | 1080p | 6 ثوانٍ | ✅ مجاني يوميًا | ❌ | أسرع سرعة إنشاء | 7.5/10 |
إشعار هام للمستخدمين المحليين: يمكن الوصول إلى Seedance 2.0 و KeLing 3.0 و Haier AI مباشرة من داخل الصين القارية. يتطلب Sora 2 اشتراكًا في ChatGPT Plus (يلزم استخدام VPN). يتطلب Google Veo 3 الوصول عبر Google AI Studio (يلزم استخدام VPN). تتطلب Runway و Pika و Luma اتصالاً بشبكة خارجية.
البدائل المحلية: توفر Tongyi Wanxiang (Alibaba) و Hunyuan Video (Tencent) و Qingying (شركة تابعة لـ ByteDance) أيضًا إمكانيات تحويل النص إلى فيديو، مع حصص استخدام مجانية متفاوتة.
الاستنتاجات الرئيسية:
- أفضل جودة صورة إجمالية: Seedance 2.0 (2K أصلي + إدخال رباعي الأوضاع + صوت)
- أقوى إمكانات صوتية: Seedance 2.0 و Google Veo 3
- أفضل إصدار مجاني: Seedance 2.0 (وصول مجاني إلى دقة 2K، لا حاجة لبطاقة ائتمان)
- أطول فيديو مجاني: Keeling 3.0 (20+ ثانية)
- الأكثر ملاءمة للمبتدئين: Pika 2.0 (واجهة أبسط، تأثيرات ممتعة)
لمقارنة أكثر تفصيلاً، يرجى الرجوع إلى المقارنة الكاملة لأفضل برامج إنشاء الفيديو بالذكاء الاصطناعي لعام 2026. للتركيز فقط على الباقات المجانية، يرجى الاطلاع على مراجعة مقارنة لبرامج إنشاء الفيديو بالذكاء الاصطناعي المجانية.
6 سيناريوهات تطبيق رئيسية
- محتوى وسائل التواصل الاجتماعي
أنشئ مقاطع فيديو قصيرة جذابة لـ TikTok و Kuaishou و Xiaohongshu و Bilibili و YouTube Shorts. تقنية الذكاء الاصطناعي تلغي الحاجة إلى التصوير والتحرير وما بعد الإنتاج تمامًا.
المواصفات الموصى بها: نسبة العرض إلى الارتفاع 9:16، مدة 5-15 ثانية، مع افتتاحية ملفتة للنظر في الثانية الأولى.
- التسويق والإعلان
إنتاج متنوع من المواد الإعلانية بكميات كبيرة. اختبار مفاهيم بصرية متعددة باستخدام مطالبات مختلفة قبل الالتزام بميزانية الإنتاج الرسمية. إنشاء إصدارات اختبار A/B في غضون دقائق.
التكوين الموصى به: توافق متعدد التنسيقات عبر منصات متعددة. قم بإقرانه بقدرات Seedance الصوتية لإنتاج أفلام إعلانية كاملة.
3. التعليم والتدريب
تصور المفاهيم المجردة التي يصعب أو يستحيل فهمها: الهياكل الجزيئية، الأحداث التاريخية، المفاهيم الرياضية، العمليات العلمية. فيديو الذكاء الاصطناعي يجعل غير المرئي مرئيًا.
التكوين الموصى به: للحصول على أفضل نتائج تعليمية، استخدم مطالبات تصف المفاهيم بدقة إلى جانب التسجيلات الصوتية المروية.
- الترفيه والسرد
يستخدم صانعو الأفلام المستقلون ومؤلفو القصص تقنية تحويل النص إلى فيديو لتصور المفاهيم، ووضع القصص المصورة، وحتى الإنتاج النهائي للأفلام القصيرة. هذه التقنية تجعل صناعة الأفلام متاحة للجميع.
التكوين الموصى به: قم بتضمين مواصفات تفصيلية لاتجاه الكاميرا والإضاءة في الموجه لتحقيق جودة سينمائية.
- مقاطع فيديو عن منتجات التجارة الإلكترونية
حوّل أوصاف المنتجات إلى مقاطع فيديو لعرض المنتجات. وهذا أمر مهم بشكل خاص للتجار الذين لديهم مئات من وحدات التخزين ولا يمكنهم تصوير مقاطع فيديو فردية لكل منتج. للحصول على تفاصيل حول سير عمل التجارة الإلكترونية، يرجى الرجوع إلى دليل الفيديو للتجارة الإلكترونية بالذكاء الاصطناعي.
المواصفات الموصى بها: تصوير المنتجات باستخدام إضاءة الاستوديو. نسبة العرض إلى الارتفاع 1:1 لصفحات تفاصيل المنتج، و16:9 لـ YouTube/Bilibili، و9:16 لـ TikTok/Xiaohongshu.
6. إنشاء محتوى على YouTube / Bilibili
أنشئ لقطات B-roll ومقاطع مقدمة وتعليقات مرئية ومقاطع فيديو قصيرة كاملة. يمكن للمبدعين تحسين كفاءة إنتاج المحتوى باستخدام الفيديو المدعوم بالذكاء الاصطناعي. للاطلاع على سير عمل المبدعين على YouTube بالكامل، يرجى الرجوع إلى دليل المبدعين على YouTube للفيديو المدعوم بالذكاء الاصطناعي.
التكوين الموصى به: حافظ على الاتساق البصري في جميع المطالبات لترسيخ الاعتراف بالعلامة التجارية.
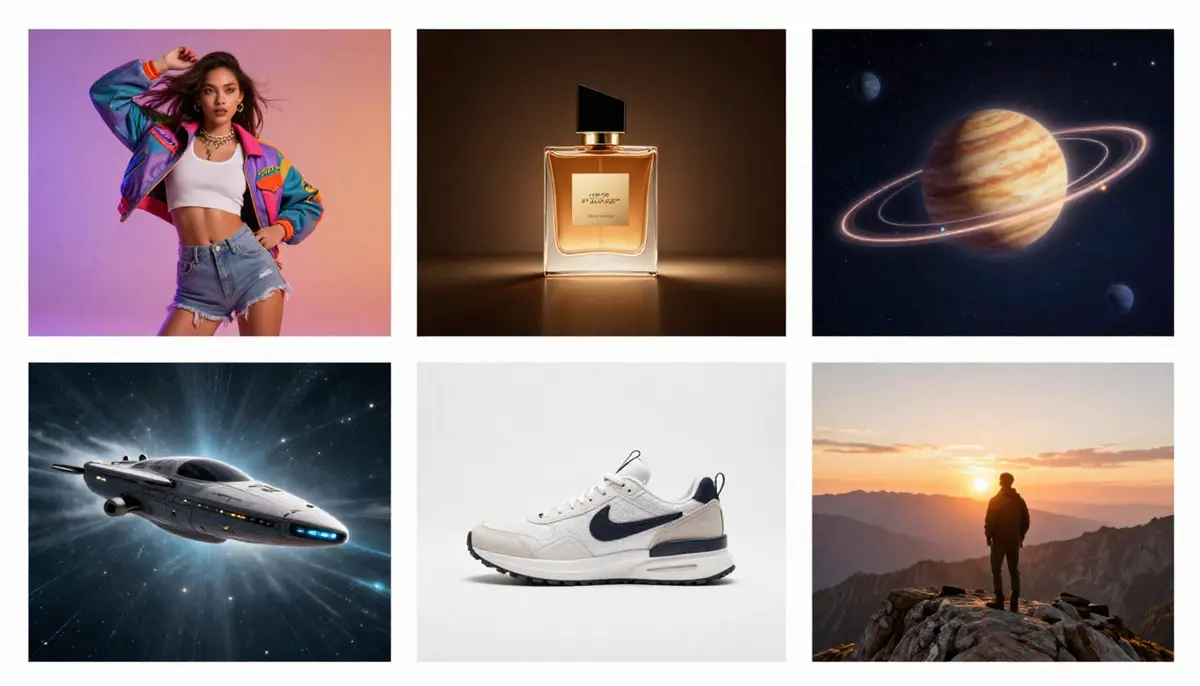
ستة تطبيقات عملية لتقنية الذكاء الاصطناعي لتحويل النص إلى فيديو — من مقاطع الفيديو القصيرة على وسائل التواصل الاجتماعي إلى عروض المنتجات في التجارة الإلكترونية، وتصور المفاهيم التعليمية.
تحويل النص إلى فيديو مقابل تحويل الصورة إلى فيديو: متى تستخدم أيهما؟
هذا هو أحد الأسئلة الأكثر شيوعًا التي يطرحها المستخدمون الجدد. تعتمد الإجابة على المواد المتوفرة لديك وما تحتاجه.

طريقتان للوصول إلى الفيديو بالذكاء الاصطناعي: يبدأ إنشاء الفيديو من النص المكتوب، بينما يبدأ إنشاء الفيديو من الصور الموجودة.
سيناريوهات لإنشاء نص إلى فيديو (T2V):
- ترغب في إنشاء محتوى جديد تمامًا (بدون صور مرجعية)
- ترغب في الحصول على أقصى قدر من الحرية الإبداعية
- تقوم باستكشاف المفاهيم أو العصف الذهني البصري
- تحتاج إلى مشاهد مجردة أو لا يمكن تصويرها (خيال علمي، خيال، مجهرية/ماكروسكوبية)
- ترغب في التكرار السريع — يؤدي تغيير واحد في الموجه إلى مشهد مختلف تمامًا
سيناريوهات لإنشاء مقاطع فيديو من الصور (I2V):
- لديك صورة فوتوغرافية معينة تتطلب تحويلًا ديناميكيًا
- تحتاج إلى مخرجات تتطابق تمامًا مع المؤثرات البصرية الحالية
- تقوم بتحويل صور المنتجات إلى مقاطع فيديو للمنتجات
- تحتاج إلى اتساق الشخصيات (نفس الشخص في جميع المشاهد)
- ترغب في الحصول على نتائج أكثر قابلية للتنبؤ والتحكم
أفضل الممارسات — الجمع بين النهجين:
- استخدام توليد النص إلى فيديو لاستكشاف الاتجاهات الإبداعية
- اختيار الإطار الأمثل كصورة مرجعية
- استخدام توليد الصورة إلى فيديو للحصول على نسخة نهائية محسنة وقابلة للتحكم
للحصول على سير عمل شامل لتحويل الصور إلى فيديو، يرجى الرجوع إلى الدليل الكامل لتحويل الصور إلى فيديو باستخدام الذكاء الاصطناعي.
القيود الحالية — تقييم صادق
تقنية تحويل النص إلى فيديو باستخدام الذكاء الاصطناعي لعام 2026 مثيرة للإعجاب، لكنها بعيدة عن الكمال. فيما يلي المجالات التي تتفوق فيها حاليًا وتلك التي لا تزال تمثل تحديًا.
أحسنت
- مقاطع فيديو قصيرة (5-15 ثانية): جودة صورة تقترب من المعايير السينمائية
- مشاهد ذات موضوع واحد: شخص واحد، حيوان واحد، كائن واحد — نتائج ممتازة
- الطبيعة والمناظر الطبيعية: عرض قوي للديناميكيات السائلة والطقس والتأثيرات الجوية
- محتوى منمق: الرسوم المتحركة، أفلام النوار، الخيال العلمي — تحويل أنماط موثوق للغاية
- عرض دوران المنتج: حركة بسيطة للمنتج مع اتساق جيد
- حركات الكاميرا: التحريك، التكبير، الدوران، اللقطات المتحركة — تحكم جيد
لا يزال صعباً
- اليدين والأصابع: لا تزال الأصابع الزائدة والإيماءات غير المعقولة وتشوهات الأصابع سائدة
- عرض النص: النص المقروء في مقاطع الفيديو غير موثوق به — تظهر الحروف مشوهة والأحرف منحرفة
- التفاعلات المعقدة بين عدة أشخاص: غالبًا ما تؤدي المصافحة بين شخصين أو الرقص معًا أو القتال إلى حدوث ارتباك في الأطراف
- السرد الطويل (>30 ثانية): يتدهور الحفاظ على اتساق المشهد على مدى فترات طويلة
- الفيزياء الدقيقة: الارتداد الدقيق للكرة، وسكب الماء في أوعية معينة — الفيزياء تقريبية وليست دقيقة
- اتساق الوجه على المدى الطويل: قد تخضع ملامح الوجه لتغييرات طفيفة بين الإطارات، خاصة على مدى فترات طويلة
اتجاه التقدم
سيتم تحسين كل من هذه القيود بشكل كبير بحلول عام 2026 مقارنة بعام 2024. وتيرة التحسن هي أسية. يتطور العرض اليدوي من "غير صحيح دائمًا" إلى "دقيق بشكل عام". يتحول اتساق الوجه من "يتغير بعد ثانيتين" إلى "مستقر لمدة 10-15 ثانية". يتطور عرض النص من "غير قابل للقراءة" إلى "قابل للقراءة في بعض الأحيان". من المتوقع أن تستمر هذه المشكلات في التحسن بسرعة بين عامي 2026 و2027.
الأسئلة المتكررة
ما هو أفضل برنامج تحويل النص إلى فيديو باستخدام الذكاء الاصطناعي لعام 2026؟
يتصدر Seedance 2.0 جودة الصورة الإجمالية بدقة 2K أصلية وإدخال رباعي الأوضاع وتوليد صوت مدمج. يتفوق Google Veo 3 في الدمج السمعي البصري والمحاكاة الفيزيائية. يوفر Sora 2 أطول مدة للجيل الواحد (20 ثانية). يعتمد الاختيار "الأفضل" على متطلباتك المحددة — الدقة أو الصوت أو المدة أو السعر. يمكن للمستخدمين المحليين أيضًا التفكير في Keeling 3.0 (قيمة عالية مقابل المال، مقاطع فيديو طويلة) و Tongyi Wanxiang (متكامل مع نظام Alibaba البيئي).
هل هناك أي برنامج مجاني لتحويل النص إلى فيديو باستخدام الذكاء الاصطناعي؟
نعم. يوفر Seedance 2.0 رصيدًا يوميًا مجانيًا دون الحاجة إلى بطاقة ائتمان. يوفر Pika 2.0 إنتاجًا يوميًا مجانيًا. يمنح Ke Ling 3.0 رصيدًا عند التسجيل. يوفر Google Veo 3 حصصًا مجانية عبر AI Studio. يوفر Conch AI أيضًا رصيدًا يوميًا مجانيًا. للحصول على التفاصيل، راجع مقارنة بين برامج إنشاء مقاطع الفيديو بالذكاء الاصطناعي المجانية.
ما هي المدة التي يمكن أن تستغرقها مقاطع الفيديو التي يتم إنشاؤها بواسطة الذكاء الاصطناعي استنادًا إلى النص؟
تقوم معظم الأدوات بإنشاء محتوى بزيادات تتراوح بين 5 و 15 ثانية. يمكن لـ Sora 2 إنتاج ما يصل إلى 20 ثانية. يدعم Keeling 3.0 أكثر من 20 ثانية. بالنسبة لمتطلبات المحتوى الأطول، يمكن إنشاء عدة مقاطع ودمجها معًا باستخدام برامج تحرير مثل Kinevision أو Premiere Pro أو DaVinci Resolve.
هل يمكن للذكاء الاصطناعي لتحويل النص إلى فيديو تحقيق صور بجودة احترافية؟
في غضون 5 إلى 15 ثانية، يمكن تحقيق ذلك. غالبًا ما لا يمكن تمييز الناتج من Seedance 2.0 و Veo 3 عن اللقطات الاحترافية في المقاطع القصيرة. بالنسبة للمشاريع الطويلة، من الأفضل استخدام الفيديو المدعوم بالذكاء الاصطناعي كعنصر من عناصر المادة (لقطات B-roll، لقطات انتقالية، مؤثرات بصرية)، بدلاً من استخدامه في الإنتاج بأكمله.
كيفية صياغة مطالبات فعالة لتوليد النص إلى فيديو؟
اتبع الصيغة التالية: الموضوع + الفعل + المكان + الأسلوب + اللقطة + الإضاءة. يجب أن تكون أوصاف الحركة محددة، وحركات الكاميرا واضحة، والأجواء محددة بوضوح. تجنب التناقضات وامتنع عن طلب عناصر النص/واجهة المستخدم. كرر بشكل تدريجي من البسيط إلى المعقد. لمزيد من التفاصيل، راجع دليل كتابة المطالبات.
أيهما أفضل: إنشاء فيديو من نص أم إنشاء فيديو من صورة؟
تطبيقات مختلفة. يوفر تحويل النص إلى فيديو أقصى قدر من الحرية الإبداعية عندما لا تتوفر مواد مرجعية. يوفر تحويل الصورة إلى فيديو تحكمًا أكبر عندما توجد نقطة انطلاق بصرية محددة. يستخدم معظم المحترفين كلا النهجين — باستخدام T2V للاستكشاف و I2V للتحسين.
هل يمكن استخدام مقاطع الفيديو التي تم إنشاؤها بواسطة الذكاء الاصطناعي لأغراض تجارية؟
تمنح معظم الخطط المدفوعة حقوقًا تجارية. تتضمن النسخة المدفوعة من Seedance 2.0 حقوقًا تجارية كاملة وخالية من العلامات المائية. تختلف شروط الخدمة باختلاف المنصات؛ يرجى التحقق من السياسات المحددة قبل الاستخدام. في الصين، لا يواجه الاستخدام التجاري للمحتوى الذي تم إنشاؤه بواسطة الذكاء الاصطناعي حاليًا أي قيود تنظيمية صريحة، على الرغم من أنه من المستحسن مراقبة التحديثات على التدابير المؤقتة لإدارة خدمات الذكاء الاصطناعي التوليدي.
هل ستحل تقنية تحويل النص إلى فيديو بالذكاء الاصطناعي محل المحررين؟
لن تحل محل الأدوار، بل ستحولها. تتولى الذكاء الاصطناعي إنشاء المحتوى — إنشاء أصول بصرية أصلية من الأوصاف. يتولى المحررون البشريون إدارة السرد، والإيقاع، والتأثير العاطفي، واتساق العلامة التجارية، والقرارات الإبداعية التي تتطلب الحكم البشري. بحلول عام 2026، سيكون سير العمل الأكثر فعالية هو إنشاء الذكاء الاصطناعي + التحرير البشري.
ابدأ في إنشاء مقاطع فيديو باستخدام النص
بحلول عام 2026، ستكون تقنية الذكاء الاصطناعي لتحويل النص إلى فيديو جاهزة للاستخدام في التطبيقات الاحترافية. بعد أن تطورت هذه التقنية من تجارب GAN غير واضحة إلى مخرجات DiT شبه سينمائية في غضون أربع سنوات فقط، أصبحت الآن قادرة على التعامل مع محتوى وسائل التواصل الاجتماعي وعروض المنتجات والتصورات التعليمية والاستكشاف الإبداعي.
أفضل طريقة للتعلم هي البدء في الإنشاء. اكتب موجهًا، وشاهد النتائج، وكرر العملية.
حوّل الفقرة الأولى إلى فيديو – جرّب Seedance مجانًا →
هل تبحث عن دقة تحكم أكبر؟ جرب إنشاء فيديو من صورة →
هل تريد التعمق أكثر في تقنيات كتابة المطالبات؟ اقرأ دليل كتابة المطالبات →
