
สรุปโดยย่อ
วิธีที่มีประสิทธิภาพที่สุดในการสร้างวิดีโอ AI ไม่ใช่แค่ป้อนคำอธิบายเข้าไปในเครื่องมือแปลงข้อความเป็นวิดีโอเท่านั้น แต่ควร เริ่มต้นด้วยภาพที่เตรียมไว้อย่างพิถีพิถัน
ขั้นตอนการสร้างภาพสามขั้นตอน — คำสั่ง → ภาพ → วิดีโอ — ให้ผลลัพธ์ที่เหนือกว่าการสร้างวิดีโอจากข้อความเพียงอย่างเดียวอย่างมาก ขั้นแรก สร้างคำสั่งที่มีระดับมืออาชีพ ใช้คำสั่งนี้เพื่อสร้างภาพที่มีการจัดองค์ประกอบอย่างแม่นยำ จากนั้นป้อนภาพนี้เป็นเฟรมแรกเข้าสู่ตัวสร้างวิดีโอ ผลลัพธ์: คุณจะได้ควบคุมเนื้อหาภาพ บรรยากาศแสง รายละเอียดการจัดองค์ประกอบ และจุดเริ่มต้นของการเคลื่อนไหวได้อย่างแม่นยำ
Seedance เป็นเครื่องมือเดียวที่ผสานรวมทั้งสามขั้นตอนไว้ในแพลตฟอร์มเดียว: ตัวสร้างข้อความสำหรับภาพ ช่วยให้คุณสร้างข้อความที่มืออาชีพต้องการ, ข้อความเป็นภาพ สร้างภาพอ้างอิงคุณภาพสูง, และ ภาพเป็นวิดีโอ เปลี่ยนภาพให้กลายเป็นคลิปวิดีโอแบบภาพยนตร์ ไม่จำเป็นต้องสลับเครื่องมือ ไม่จำเป็นต้องดาวน์โหลดและอัปโหลดใหม่ – จากแรงบันดาลใจถึงผลงานสำเร็จ ทุกขั้นตอนทำได้อย่างราบรื่นในขั้นตอนเดียว
ขั้นตอนที่ 1: สร้างข้อความกระตุ้น → | ขั้นตอนที่ 2: สร้างภาพ → | ขั้นตอนที่ 3: สร้างวิดีโอ →

ซ้าย: การสร้างวิดีโอจากข้อความล้วน — การประพันธ์แบบสุ่ม ภาพที่ควบคุมไม่ได้ ขวา: กระบวนการแบบภาพนำ — ปรับปรุงภาพก่อนแล้วค่อยเพิ่มการเคลื่อนไหว; การประพันธ์ที่แม่นยำ คุณภาพสม่ำเสมอ
ทำไม "ภาพนำ, วิดีโอเสริม" จึงมีประสิทธิภาพเหนือกว่าการแปลงข้อความเป็นวิดีโอ
ผู้ที่เคยใช้ Wensheng Video จะรู้ดีถึงประสบการณ์นี้: คุณเขียนคำอธิบายอย่างละเอียด—ครอบคลุมหัวข้อ แสง มุมกล้อง และองค์ประกอบ—แต่ฟุตเทจที่ AI สร้างขึ้นกลับไม่มีความคล้ายคลึงกับวิสัยทัศน์ของคุณเลย ตัวละครหันหน้าผิดทาง แสงสว่างแบนราบ องค์ประกอบดูเหมือนถูกสร้างขึ้นแบบสุ่ม และบทบาทไม่ตรงกับคำอธิบาย
นี่ไม่ใช่ข้อบกพร่องของเครื่องมือใดเครื่องมือหนึ่งโดยเฉพาะ แต่เป็นข้อจำกัดเชิงโครงสร้างที่มีอยู่ในวิธีการแปลงข้อความเป็นวิดีโอ
ข้อจำกัดโดยธรรมชาติของการสร้างเนื้อหาผ่านวิดีโอ
Wensheng Video ต้องการให้ AI บรรลุสองภารกิจที่ท้าทายอย่างยิ่ง พร้อมกัน: การสร้างภาพและการสร้างการเคลื่อนไหว โมเดลต้องตีความข้อความของคุณ กำหนดลักษณะของแต่ละพิกเซล ประกอบฉาก ตั้งค่าแสงและเงา กำหนดตำแหน่งกล้อง และจากนั้นสร้างการเคลื่อนไหวที่สอดคล้องกันจากทั้งหมดนี้—ทั้งหมดจากข้อความเพียงชิ้นเดียว
ผลลัพธ์คือทุกมิติอยู่เหนือการควบคุม:
- การจัดองค์ประกอบแบบสุ่ม คุณเขียนว่า "ผู้หญิงคนหนึ่งยืนอยู่กลางถนน" แต่สุดท้ายเธอกลับไปอยู่ด้านซ้ายของภาพหนึ่งในสาม โดยมีอาคารที่ไม่จำเป็นครึ่งหนึ่งของกรอบภาพ
- ตัวละครไม่สอดคล้องกัน ** โครงหน้า, เครื่องแต่งกาย, ทรงผม, และสัดส่วนของร่างกายมีการเปลี่ยนแปลงตามแต่ละรุ่น. AI ให้การตีความอย่างสร้างสรรค์ ไม่ใช่ตามข้อกำหนดของคุณ.
- **แสงสว่างไม่สามารถควบคุมได้. ** แม้แต่การระบุ "golden hour, แสงด้านขวาอบอุ่นจากซ้าย" ก็ยังให้ผลลัพธ์ที่ไม่สม่ำเสมออย่างมาก การตีความคำอธิบายแสงของ AI ยังคงคลุมเครืออย่างพื้นฐาน
- การจัดกรอบภาพไม่น่าเชื่อถือ ภาพระยะใกล้, ภาพระยะกลาง, ภาพเต็มตัว—เครื่องมือแปลงข้อความเป็นวิดีโอตีความคำเหล่านี้อย่างไม่เสถียรอย่างมาก ขอภาพระยะใกล้มาก มันจะให้ภาพเต็มตัว
สำหรับการทดลองสร้างสรรค์เชิงสำรวจ ความไม่แน่นอนนี้อาจเป็นส่วนหนึ่งของความสนุกได้ แต่หากคุณต้องการผลลัพธ์ที่ควบคุมได้ เชื่อถือได้ และเป็นมืออาชีพ มันจะกลายเป็นข้อบกพร่องร้ายแรง
ข้อได้เปรียบหลักของการให้ความสำคัญกับภาพ
TuSheng Video ได้พลิกโฉมสมการนี้อย่างสิ้นเชิง คุณไม่จำเป็นต้องให้ AI สร้างทั้งภาพและเคลื่อนไหวพร้อมกันอีกต่อไป แต่คุณสามารถ แยกสองงานนี้ออกจากกัน:
- เริ่มต้นด้วยภาพ หัวข้อ, องค์ประกอบ, แสง, สี, การจัดกรอบ—คุณควบคุมได้ทั้งหมด ปรับปรุงจนกว่าจะสมบูรณ์แบบ
- จากนั้นเพิ่มการเคลื่อนไหว งานเดียวของ AI คือการทำให้กรอบภาพที่สมบูรณ์แบบของคุณเคลื่อนไหว มันไม่จำเป็นต้องตีความคำอธิบายที่คลุมเครือหรือตัดสินใจเรื่ององค์ประกอบ แต่จะสร้างการเคลื่อนไหวจากจุดยึดภาพที่ชัดเจนของคุณ
การแยกจุดโฟกัสนี้ให้ผลลัพธ์ที่เหนือกว่าในทุกมิติ:
- การจัดวางถูกล็อกไว้ วัตถุหลักยังคงอยู่ในตำแหน่งที่คุณวางไว้อย่างแม่นยำ
- ความสม่ำเสมอของตัวละคร รายละเอียดใบหน้า เครื่องแต่งกาย และสัดส่วนยังคงเหมือนกับภาพต้นฉบับตลอดทั้งภาพ
- **แสงและเงาถูกคงไว้อย่างสมบูรณ์ **ทิศทางของแสง, พื้นผิว, และอุณหภูมิสีถูกสืบทอดมาจากภาพอย่างสมบูรณ์.
- กรอบภาพถูกปรับให้คงที่. ตำแหน่งของกล้องและมุมมองยังคงสอดคล้องกับการตั้งค่าต้นฉบับของภาพ.
เพื่ออธิบาย: การสร้างวิดีโอจากข้อความนั้นคล้ายกับการบรรยายฉากภาพยนตร์ให้ใครบางคนฟังทางโทรศัพท์และให้คำแนะนำให้เขาถ่ายทำฉากนั้น อย่างไรก็ตาม การสร้างวิดีโอจากภาพนั้นเหมือนกับการให้ใครบางคนดูภาพถ่ายและบอกเขาว่า "ทำให้ภาพนี้มีชีวิตชีวา" วิธีการหลังนี้ให้ผลลัพธ์ที่สามารถควบคุมได้มากขึ้นและมีคุณภาพสูงกว่า เนื่องจากระบบ AI ได้รับข้อมูลอ้างอิงทางภาพที่เป็นรูปธรรมแทนที่จะเป็นคำอธิบายที่เป็นนามธรรม
ผลกระทบแบบทวีคูณของคุณภาพ
ประโยชน์สะสมได้. กรอบเปิดที่ออกแบบมาอย่างดีช่วยเพิ่มทุกแง่มุมของวิดีโอ:
- ความสอดคล้องเชิงเวลาที่ดีขึ้น — โมเดลมีจุดยึดภาพคุณภาพสูงเพื่อรักษาความสอดคล้องตลอดทั้งลำดับ
- คุณภาพการเคลื่อนไหวที่ดีขึ้น — โมเดลสามารถดึงข้อมูลความลึก แสง และข้อมูลเชิงพื้นที่จากภาพต้นฉบับที่ชัดเจนได้อย่างแม่นยำ
- ความสอดคล้องทางสไตล์ที่เพิ่มมากขึ้น — ระบบสี, อารมณ์, และความสวยงามถูกฝังไว้โดยตรงในภาพ ไม่เหลือที่ว่างให้กับการตีความทางข้อความ
- อัตราการไม่สมบูรณ์ที่ลดลง — แบบจำลองเริ่มต้นด้วยข้อมูลภาพที่สะอาดและมีความละเอียดสูง แทนที่จะสังเคราะห์ทุกสิ่งจากเสียงรบกวน
วิดีโอที่สร้างจากเฟรมแรกคุณภาพสูงแสดงให้เห็นถึงความเหนือชั้นอย่างมีนัยสำคัญเหนือวิดีโอที่สร้างจากข้อความล้วน ๆ โดยมีคำสั่งที่เหมือนกันในแง่ของคุณภาพภาพ ความต่อเนื่องทางเวลา และความสวยงาม นี่ไม่ใช่ความแตกต่างที่เล็กน้อย—มันคือช่องว่างระหว่าง "การสาธิต AI ที่น่าบันเทิง" กับ "เนื้อหาที่สามารถนำไปใช้ได้ในระดับมืออาชีพ"
สำหรับการศึกษาอย่างละเอียดเกี่ยวกับวิธีการออกแบบภาพโดยเฉพาะสำหรับการสร้างวิดีโอ โปรดดูที่ คู่มือการออกแบบเฟรมแรกและเฟรมสุดท้าย
กระบวนการสร้างสรรค์ด้วย AI สามขั้นตอน
กระบวนการทำงานทั้งหมดแบ่งออกเป็นสามขั้นตอน โดยแต่ละขั้นตอนจะต่อยอดจากขั้นตอนก่อนหน้า หากดำเนินการในขั้นตอนใดอย่างไม่รอบคอบ จะส่งผลเสียต่อผลลัพธ์สุดท้ายในที่สุด การเข้าใจบทบาทของแต่ละขั้นตอน—และรู้ว่าควรทุ่มเทเวลาในส่วนใด—เป็นกุญแจสำคัญในการสร้างวิดีโอ AI คุณภาพสูงอย่างสม่ำเสมอ
ระยะที่หนึ่ง: การสร้างข้อความกระตุ้น
ทุกสิ่งเริ่มต้นจากคำสั่งเริ่มต้น คำสั่งเริ่มต้นที่ธรรมดา → ภาพธรรมดา → วิดีโอธรรมดา คำสั่งเริ่มต้นที่ยอดเยี่ยม → ภาพที่น่าทึ่ง → วิดีโอที่น่าทึ่ง คุณภาพของคำสั่งเริ่มต้นคือตัวแปรที่สำคัญที่สุดในการกำหนดคุณภาพของผลลัพธ์สุดท้าย และมันยังเป็นขั้นตอนที่ได้รับการลงทุนน้อยที่สุดในกระบวนการทำงานส่วนใหญ่
ปัญหาของการเขียนข้อความกระตุ้นด้วยตนเองคือ คนส่วนใหญ่มักเขียนข้อความกระตุ้นเหมือนกับการสร้างคำค้นหา: สั้น กระชับ ไม่ชัดเจน และมุ่งเน้นเฉพาะหัวข้อเท่านั้น "นาฬิกาหรู พื้นหลังสีเข้ม" สิ่งนี้บอก AI ว่าต้องวาดอะไร แต่ไม่ได้บอก วิธีการ วาดอย่างไร โมเดลจะเติมช่องว่างด้วยค่าเริ่มต้น—แสงเรียบ องค์ประกอบภาพอยู่ตรงกลาง ไม่มีรายละเอียดบรรยากาศ ไม่มีทิศทางด้านสไตล์
วิธีแก้ปัญหา: การสร้างข้อความกระตุ้นด้วย AI ตัวสร้างข้อความกระตุ้นจะขยายแนวคิดคร่าวๆ ของคุณให้เป็นข้อความกระตุ้นระดับมืออาชีพที่ครอบคลุมเนื้อหา หัวข้อ สภาพแวดล้อม แสง สี องค์ประกอบ สไตล์ และการปรับปรุงคุณภาพของภาพ ความแตกต่างของคุณภาพผลลัพธ์ระหว่างข้อความกระตุ้นที่เขียนด้วยมือ 10 คำกับข้อความกระตุ้นที่สร้างขึ้น 100 คำนั้นเป็นการก้าวกระโดดเชิงคุณภาพ
Seedance's ตัวสร้างคำกระตุ้นด้วยภาพ ทำได้ตรงตามนั้น เพียงป้อนคำอธิบายสั้นๆ เช่น "โฆษณาเรือนเวลาหรูหรา, มืดมนและดราม่า" เลือกสไตล์ (เหมือนจริง, ภาพยนตร์, ภาพประกอบ ฯลฯ) และ AI จะสร้างคำกระตุ้นที่สมบูรณ์และมืออาชีพทันที กระบวนการทั้งหมดใช้เวลาเพียงไม่กี่วินาที โดยมีค่าใช้จ่าย 2 เครดิตต่อคำกระตุ้น สำหรับคู่มือที่ครอบคลุมเกี่ยวกับการสร้างคำสั่งแบบครบถ้วน โปรดดูที่ คู่มือการสร้างคำสั่งสำหรับภาพ AI.
ทำไมขั้นตอนนี้จึงสำคัญมาก คำกระตุ้นเป็นเหมือนดีเอ็นเอของกระบวนการทั้งหมดของคุณ มันกำหนดสไตล์ อารมณ์ โครงสร้าง และขีดจำกัดคุณภาพของทุกสิ่งที่ตามมา การใช้เวลาห้านาทีในการปรับแต่งคำกระตุ้นของคุณก่อนที่จะสร้างภาพ สามารถช่วยประหยัดเวลาสามสิบนาทีในการปรับแก้ซ้ำๆ กับผลลัพธ์ที่ธรรมดาในภายหลังได้
ขั้นตอนที่สอง: การสร้างภาพ
เมื่อได้รับคำแนะนำจากผู้เชี่ยวชาญ ขั้นตอนต่อไปคือการสร้างภาพที่จะใช้เป็นเฟรมเปิดของวิดีโอ ในขั้นตอนนี้ คุณจะเปลี่ยนจากข้อความเป็นภาพ ซึ่งถือเป็นจุดที่ควร ใช้เวลาในการปรับปรุงมากที่สุด
จากข้อความสู่ภาพ วางข้อความที่ป้อนลงในเครื่องมือแปลงข้อความเป็นภาพ แล้วคลิกสร้าง ประเมินผลลัพธ์: องค์ประกอบเหมาะสมสำหรับวิดีโอหรือไม่? แสงมีการจัดชั้นอย่างเพียงพอหรือไม่? วัตถุหลักดูถูกต้องหรือไม่? ฉากสื่อถึงความลึกได้ดีหรือไม่?
หากคุณมีภาพอ้างอิงอยู่แล้วหรือต้องการปรับแต่งผลลัพธ์การสร้างที่มีอยู่ ภาพต่อภาพ คือเครื่องมือของคุณ อัปโหลดภาพที่คุณมีอยู่และอธิบายการแก้ไขที่ต้องการ—วิธีนี้มีประสิทธิภาพเป็นพิเศษสำหรับการปรับแต่งองค์ประกอบภาพ: ปรับแสง เพิ่มเอฟเฟกต์บรรยากาศ หรือเปลี่ยนแปลงเนื้อหาในฉากโดยไม่ต้องเริ่มต้นใหม่ทั้งหมด สำหรับคู่มือฉบับสมบูรณ์เกี่ยวกับกระบวนการ Image-to-Image กรุณาดูที่ คู่มือ AI Image-to-Image
ออกแบบภาพสำหรับใช้งานวิดีโอ ไม่ใช่ทุกภาพที่ดูสวยงามจะเหมาะสำหรับใช้เป็นภาพเปิดวิดีโอเสมอไป เมื่อสร้างภาพสำหรับใช้ในกระบวนการผลิต ควรคำนึงถึงหลักการจัดองค์ประกอบดังต่อไปนี้:
- เว้นพื้นที่ว่างในทิศทางของการเคลื่อนไหว หากตัวละครกำลังเคลื่อนที่จากซ้ายไปขวา ให้วางตำแหน่งตัวละครไปทางขวาของเฟรมเล็กน้อย
- รวมระดับความลึก ภาพที่มีองค์ประกอบเบื้องหน้า เบื้องกลาง และเบื้องหลังที่ชัดเจนจะสร้างเอฟเฟกต์ภาพลวงตาและการเคลื่อนไหวของกล้องที่ดูเป็นธรรมชาติมากขึ้นในวิดีโอ
- พิจารณาทิศทางการเคลื่อนไหวของกล้อง ** หากวางแผนที่จะใช้การเคลื่อนไหวแบบ "ผลัก" ให้ตรวจสอบให้แน่ใจว่าองค์ประกอบดูดีทั้งในกรอบปัจจุบันและในกรอบที่แคบลงซึ่งเน้นที่วัตถุเป็นหลัก
- หลีกเลี่ยงบล็อกข้อความขนาดใหญ่หรือรูปแบบที่สมมาตร องค์ประกอบเหล่านี้ยากต่อการสร้างแอนิเมชันให้ดูเป็นธรรมชาติและอาจทำให้เกิดสิ่งผิดปกติได้ง่าย
- **ใช้แสงที่มีทิศทางชัดเจน ** แสงสว่างที่มีทิศทางชัดเจนพร้อมเงาที่มองเห็นได้ จะสร้างเอฟเฟ็กต์วิดีโอที่ดูภาพยนตร์มากกว่าแสงสว่างที่ราบเรียบ.
หลักการสำคัญ: ลงทุนเวลาในการปรับแต่งภาพให้ถูกต้อง ทุกนาทีที่ทุ่มเทในการทำให้ภาพของคุณสมบูรณ์แบบ จะช่วยประหยัดเวลาหลายเท่าในขั้นตอนการสร้างวิดีโอ ภาพแรกที่ไร้ที่ติ หมายถึงวิดีโอของคุณสามารถใช้งานได้ตั้งแต่ครั้งแรกที่ลอง ในขณะที่ภาพแรกที่มีข้อบกพร่อง อาจต้องสร้างใหม่หลายครั้ง (แต่ละครั้งใช้เครดิตและเวลา) โดยไม่รับประกันผลลัพธ์ที่น่าพอใจ
ก่อนที่จะเริ่มสร้างวิดีโอ ให้วนซ้ำภาพเหล่านั้น 3–5 ครั้ง นี่ไม่ใช่ความสมบูรณ์แบบ—แต่เป็นความมีประสิทธิภาพ
สำหรับคู่มือที่ครอบคลุมเกี่ยวกับการสร้างภาพจากข้อความ (รวมถึงเทคนิคการป้อนข้อความและการเปรียบเทียบเครื่องมือ) โปรดดูที่ คู่มือฉบับสมบูรณ์เกี่ยวกับ AI สร้างภาพจากข้อความ สำหรับภาพรวมของเครื่องมือสร้างภาพที่ดีที่สุด โปรดดูที่ เครื่องมือสร้างภาพ AI ที่ดีที่สุดสำหรับปี 2026
สร้างภาพของคุณ → | ปรับแต่งภาพจากภาพ →
ขั้นตอนที่สาม: การสร้างวิดีโอ
นี่คือขั้นตอนที่คุณจะได้รับผลตอบแทน ภาพที่ขัดเกลาที่คุณได้ปรับปรุงแล้วจะเป็นจุดเริ่มต้นสำหรับคลิปวิดีโอแอนิเมชันของคุณ
อัปโหลดภาพเป็นเฟรมแรก อัปโหลดภาพที่คุณสร้างขึ้นลงในเครื่องมือ [Image-to-Video] ของ Seedance เครื่องมือนี้จะดึงภาพจากประวัติการสร้างของคุณโดยตรง—ไม่จำเป็นต้องดาวน์โหลดและอัปโหลดใหม่
ชี้นำการเคลื่อนไหวด้วยคำพูด เขียนคำแนะนำที่อธิบายการเคลื่อนไหวที่คุณต้องการ—อย่าอธิบายภาพ (ภาพได้ถูกประมวลผลแล้ว) ให้เน้นที่:
- การเคลื่อนไหวของกล้อง: "เคลื่อนกล้องแบบดอลลี่เข้าอย่างช้าๆ" 、ค่อยๆ เลื่อนกล้องไปทางซ้าย、เคลื่อนกล้องอย่างนุ่มนวลรอบๆ วัตถุ
- การกระทำของวัตถุ: "ผู้หญิงหันศีรษะช้าๆ"、กลีบดอกไม้ร่วงหล่นลงมา、ไอน้ำลอยขึ้นจากถ้วย
- การเคลื่อนไหวของสิ่งแวดล้อม: "เมฆเคลื่อนตัวช้าๆ", "น้ำเป็นระลอกคลื่นแผ่ขยายออกไป", "ใบไม้ไหวเบาๆ ตามสายลม"
- ** บรรยากาศ**: "บรรยากาศที่เต็มไปด้วยความดราม่า", "คุณภาพที่เหมือนฝันและเหนือจริง", "จังหวะที่เหมือนภาพยนตร์"
สร้างและตรวจสอบ. ระบบ AI จะรับคำสั่งภาพและคำสั่งการเคลื่อนไหวของคุณ แล้วผลิตวิดีโอเป็นส่วน ๆ ที่เริ่มต้นอย่างแม่นยำจากเฟรมแรกของคุณ และดำเนินไปตามคำสั่งการเคลื่อนไหวของคุณ. เนื่องจากคุณสามารถควบคุมจุดเริ่มต้นทางภาพได้ ผลลัพธ์จึงสามารถคาดการณ์ได้และคงที่. คุณภาพของวิดีโอจะสืบทอดมาจากคุณภาพของภาพ—เฟรมแรกที่ชัดเจน สว่างไสว และจัดวางอย่างถูกต้อง จะถูกถ่ายทอดไปสู่วิดีโอที่ชัดเจน สว่างไสว และจัดวางอย่างถูกต้องเช่นกัน.
สำหรับเทคนิคการควบคุมการเคลื่อนไหวขั้นสูงและการจับคู่เฟรมแรก/เฟรมสุดท้าย โปรดดูที่ คู่มือการออกแบบเฟรมแรกและเฟรมสุดท้าย สำหรับการแนะนำอย่างครอบคลุมเกี่ยวกับ AI จากภาพเป็นวิดีโอ โปรดดูที่ คู่มือ AI จากภาพเป็นวิดีโอ
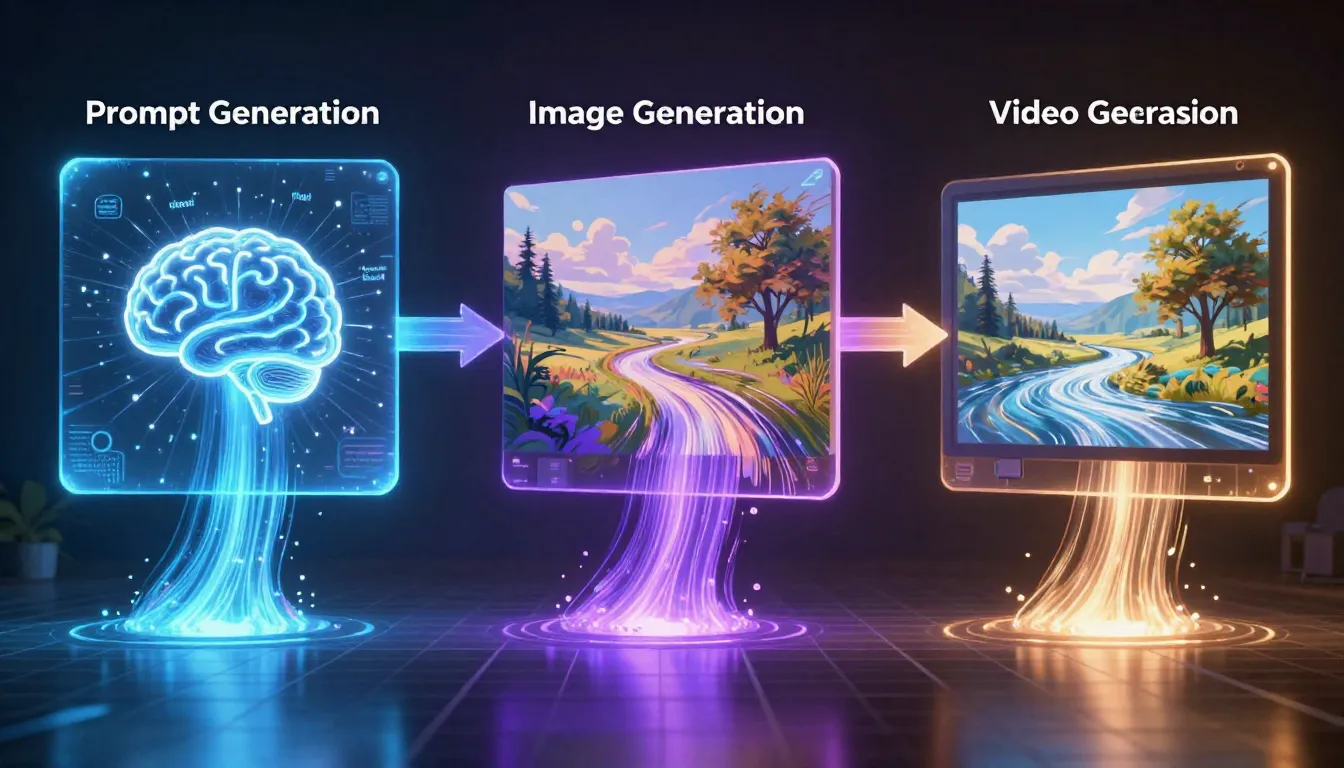
กระบวนการสามขั้นตอนในการทำงาน: เปลี่ยนคำอธิบายสั้น ๆ ให้เป็นคำแนะนำอย่างมืออาชีพ, เปลี่ยนคำแนะนำให้เป็นภาพคุณภาพสูง, และเปลี่ยนภาพให้กลายเป็นวิดีโอที่มีชีวิตชีวา. แต่ละขั้นตอนช่วยเพิ่มคุณภาพของขั้นตอนก่อนหน้า.
ข้อได้เปรียบของ Seedance: การดำเนินงานครบวงจรในสามขั้นตอน
ทุกวันนี้ ผู้สร้างผลงานส่วนใหญ่ที่พยายามเชื่อมต่อกระบวนการทำงานนี้เข้าด้วยกัน มักจะต้องนำเครื่องมือสามหรือสี่ตัวมาประกอบกัน พวกเขาใช้ ChatGPT หรือ Claude เพื่อเขียนข้อความแนะนำสำหรับสร้างภาพ จากนั้นเปลี่ยนไปใช้ Midjourney หรือ Tongyi Wansheng เพื่อสร้างภาพ ดาวน์โหลดภาพที่ได้ เปิด Ke Ling หรือ Runway แล้วอัปโหลดภาพนั้นอีกครั้งเพื่อสร้างวิดีโอ แต่ละขั้นตอนเหล่านี้หมายถึงการเปลี่ยนอินเทอร์เฟซใหม่ บัญชีใหม่ ระบบการชำระเงินใหม่ และข้อจำกัดที่แตกต่างกันไป
กระบวนการทำงานที่กระจัดกระจายนี้ไม่เพียงแต่สร้างความยุ่งยากเท่านั้น แต่ยังส่งผลเสียต่อคุณภาพโดยตรงอีกด้วย
การเปลี่ยนเครื่องมือส่งผลกระทบต่อคุณภาพอย่างไร
ทุกครั้งที่มีการถ่ายโอนภาพระหว่างเครื่องมือ จะเกิดการเสื่อมคุณภาพขึ้น วงจรการดาวน์โหลด-อัปโหลดทำให้เกิดข้อบกพร่องจากการบีบอัด การแปลงรูปแบบไฟล์ (เช่น PNG เป็น JPG หรือ WebP เป็น PNG) จะเปลี่ยนแปลงค่าสี ความละเอียดอาจถูกปรับใหม่ ข้อมูลเมตาดาตาที่เกี่ยวข้องกับวิธีการสร้างภาพ—ข้อมูลที่อาจช่วยให้โมเดลวิดีโอสร้างผลลัพธ์ที่ดีกว่า—จะถูกตัดออกไปทั้งหมด
นอกเหนือจากคุณภาพของข้อมูลแล้ว ยังมีภาระทางความคิดอีกด้วย เครื่องมือแต่ละชนิดมีไวยากรณ์คำสั่งที่แตกต่างกัน การตั้งค่าผลลัพธ์ที่ไม่เหมือนกัน และตัวเลือกอัตราส่วนภาพที่หลากหลาย คุณกำลังเสียเวลาไปกับการทำความคุ้นเคยกับอินเทอร์เฟซใหม่ แทนที่จะทุ่มเทเวลาให้กับการสร้างสรรค์ผลงาน
ระบบท่อแบบบูรณาการ
Seedance ขจัดความขัดแย้งทั้งหมดเหล่านี้ด้วยการนำเสนอทั้งสามขั้นตอนในแพลตฟอร์มเดียว:
1. เครื่องสร้างข้อความสำหรับภาพ (/image-prompt-generator). ป้อนแนวคิดสร้างสรรค์ของคุณ เลือกจาก 12 สไตล์ และรับข้อความที่สมบูรณ์และมืออาชีพ ข้อความที่สร้างขึ้นได้รับการปรับให้เหมาะสมกับโมเดลการสร้างภาพ Seedance แต่สามารถใช้ได้กับเครื่องมือวาดภาพ AI ใด ๆ อย่างเท่าเทียมกัน
2. ข้อความเป็นภาพและภาพเป็นภาพ (/text-to-image | /image-to-image). สร้างภาพจากข้อความหรือทำการปรับเปลี่ยนเฉพาะเจาะจงกับภาพที่มีอยู่ สร้างหลายรูปแบบได้อย่างรวดเร็ว เมื่อคุณพบองค์ประกอบที่เหมาะสมแล้ว ก็สามารถนำไปสู่ขั้นตอนถัดไปได้เลย
- ภาพเป็นวิดีโอ เลือกภาพที่สร้างไว้ล่วงหน้าจากคลังของคุณและส่งไปยังตัวสร้างวิดีโอโดยตรง ไม่มีการดาวน์โหลด ไม่มีการอัปโหลด ไม่มีการแปลงรูปแบบ ภาพความละเอียดเต็มจะถูกถ่ายโอนโดยไม่สูญเสียคุณภาพ
ทำไมการผสานรวมจึงให้ผลลัพธ์ที่เหนือกว่า?
นี่ไม่ใช่เพียงแค่คุณสมบัติเพื่อความสะดวกเท่านั้น; การผสานรวมให้ผลลัพธ์ที่เหนือกว่าอย่างแท้จริง:
- การสูญเสียการส่งผ่านเป็นศูนย์ ภาพถ่ายถูกส่งผ่านระหว่างขั้นตอนต่าง ๆ ด้วยความละเอียดเต็มที่ โดยไม่มีการบีบอัดหรือการสุ่มตัวอย่างใหม่
- ระบบนิเวศของแบบจำลองที่สอดคล้องกัน แบบจำลองการสร้างภาพและวิดีโอได้รับการปรับให้สอดคล้องกับความเข้ากันได้โดยธรรมชาติ ภาพที่สร้างโดยแบบจำลองข้อความเป็นภาพของ Seedance มีความเหมาะสมโดยธรรมชาติกับแบบจำลองวิดีโอของ Seedance
- ระบบเครดิตแบบรวม ** ไม่จำเป็นต้องรักษาการสมัครสมาชิกแยกกันสามรายการ เครดิตของคุณสามารถใช้ได้กับเครื่องมือทั้งสามอย่างทั่วถึง ทำให้การจัดสรรงบประมาณเป็นเรื่องง่ายและโปร่งใส
- วงจรการทำงานที่รวดเร็วขึ้น เวลาจาก "ฉันต้องการแก้ไขภาพนี้" ถึง "ฉันกำลังดูวิดีโอใหม่" ลดลงจากหลายนาทีที่ใช้ในการสลับเครื่องมือเหลือเพียงไม่กี่วินาทีของการผสานที่ราบรื่น
- รักษาการไหลของความคิดสร้างสรรค์ ** อยู่ในอินเทอร์เฟซเดียวเพื่อรักษาบริบทความคิดของคุณไว้ ให้ความสนใจกับแนวคิดสร้างสรรค์เอง ไม่ใช่การจัดการไฟล์หรือการนำทางเครื่องมือ
พูดตรงๆ: คุณสามารถใช้ ChatGPT เพื่อเขียนคำสั่ง, Midjourney หรือ Tongyi Wansheng สำหรับการสร้างภาพ, และ Keling หรือ Runway สำหรับการสร้างวิดีโอเพื่อสร้างกระบวนการที่มีคุณภาพสูงได้อย่างสมบูรณ์แบบ มืออาชีพหลายคนทำเช่นนั้นจริงๆ ข้อได้เปรียบของ Seedance ไม่ได้อยู่ที่ขั้นตอนใดขั้นตอนหนึ่งที่เหนือกว่าคู่แข่งอย่างมาก—แต่อยู่ที่การบูรณาการที่ทำให้กระบวนการราบรื่นซึ่งทำให้ผู้สร้างส่วนใหญ่ละทิ้งกระบวนการไปกลางทาง กระบวนการทำงานที่ดีที่สุดคือกระบวนการที่คุณจะเห็นจนจบจริงๆ
Seedance ผสานการสร้างสรรค์ข้อความ ภาพ และวิดีโอไว้ในแพลตฟอร์มเดียว ตั้งแต่แนวคิดจนถึงวิดีโอที่เสร็จสมบูรณ์ ไม่จำเป็นต้องสลับเครื่องมือ ดาวน์โหลดไฟล์ หรือจัดการหลายบัญชี
คู่มือปฏิบัติที่สมบูรณ์: 3 กรณีศึกษาจากโลกจริง
ทฤษฎีมีประโยชน์ แต่การปฏิบัติให้ผลลัพธ์ ด้านล่างนี้คือแบบฝึกหัดการสร้างงานแบบครบวงจรสามชุด—แต่ละชุดสอดคล้องกับวัตถุประสงค์เชิงสร้างสรรค์ที่แตกต่างกัน สไตล์ที่โดดเด่น และอัตราส่วนภาพที่หลากหลาย ทำตามเพื่อสร้างกระบวนการทำงานแบบครบวงจรของคุณเอง
กรณี 1: โฆษณาผลิตภัณฑ์ในรูปแบบภาพยนตร์
วัตถุประสงค์: ผลิตโฆษณาเรือนเวลาหรูหราความยาวห้าวินาทีสำหรับหน้าแสดงสินค้า
เฟสแรก — การสร้างข้อความกระตุ้น
เปิด เครื่องมือสร้างคำอธิบายภาพ และป้อนแนวคิดของคุณ
ข้อมูลนำเข้า: "โฆษณาเรือนเวลาหรู, บรรยากาศมืดและดราม่า"
เลือกสไตล์: สมจริง
ข้อความที่สร้างขึ้น:
A luxury men's wristwatch resting on a slab of dark emperador marble,
shot from a low three-quarter angle. Dramatic studio lighting: a single
hard key light from the upper left creates sharp reflections on the
polished steel case and sapphire crystal. The watch face shows 10:10
with luminous indices glowing faintly. Deep shadows pool around the
base, enhancing the sense of weight and prestige. Background is pure
black, fading to subtle charcoal gradient. Microscopic dust particles
float in the key light beam. Color palette: silver, deep charcoal,
amber highlights from the lume. Photorealistic product photography,
8K resolution, razor-sharp detail on every dial marking and link.การสร้างข้อความนี้ด้วยตนเองจะใช้เวลาอย่างน้อย 10–15 นาที เครื่องสร้างข้อความสามารถทำได้ภายในไม่กี่วินาที ครอบคลุมทั้งเจ็ดมิติของข้อความสำหรับมืออาชีพ: หัวข้อ, สภาพแวดล้อม, แสง, สี, องค์ประกอบ, สไตล์, และคุณภาพของภาพ
ขั้นตอนที่สอง — การสร้างภาพ
วางข้อความที่สร้างไว้ใน text-to-image. สร้างในอัตราส่วน 16:9 เพื่อให้เหมาะกับกรอบวิดีโอแนวนอน.
การเรนเดอร์ครั้งแรก: โครงสร้างโดยรวมมีความสมดุลดี แม้ว่าพื้นผิวหินอ่อนจะสะท้อนแสงมากเกินไปเล็กน้อย ทำให้ความสนใจเบี่ยงเบนไปจากตัวนาฬิกา
การทำซ้ำ: ปรับแต่งโดยใช้ Image-to-Image อัปโหลดภาพที่สร้างขึ้นในตอนแรกพร้อมกับคำแนะนำ: "ลดความเข้มของการสะท้อนบนพื้นผิวหินอ่อน เพิ่มความคมชัดของรายละเอียดบนหน้าปัดนาฬิกา ทำให้การไล่ระดับสีของพื้นหลังลึกขึ้นเล็กน้อย"
มุมมองที่สอง: นาฬิกาเป็นจุดเด่นอยู่ตรงกลาง ถูกอาบด้วยแสงและเงาที่ดราม่า พร้อมด้วยองค์ประกอบที่ซ้อนกันหลายชั้น พร้อมที่จะเข้าสู่ขั้นตอนการถ่ายทำวิดีโอ
ขั้นตอนที่สาม — การสร้างวิดีโอ
ส่งภาพที่ปรับแต่งแล้วไปยัง Image-to-Video
คำแนะนำในการออกกำลังกาย:
The camera executes a slow, smooth orbiting movement around the watch,
revealing different angles of the case and bracelet. The key light
shifts subtly as the camera moves, creating dynamic reflections across
the polished surfaces. Dust particles drift slowly through the light
beam. Cinematic, premium commercial pacing. Steady, professional
camera movement.(กล้องแพนช้าๆ และมั่นคงรอบๆ นาฬิกา เผยให้เห็นมุมมองต่างๆ ของตัวเรือนและสายนาฬิกา เมื่อกล้องเคลื่อนที่ แหล่งกำเนิดแสงหลักจะเปลี่ยนตำแหน่งอย่างละเอียด สร้างการสะท้อนที่เคลื่อนไหวบนพื้นผิวที่ขัดเงา ฝุ่นละอองลอยอย่างนุ่มนวลภายในลำแสง จังหวะการโฆษณาแบบภาพยนตร์ระดับไฮเอนด์ การเคลื่อนไหวของกล้องที่มั่นคงและเป็นมืออาชีพ)
สิ่งที่ต้องส่งมอบ: การนำเสนอผลิตภัณฑ์แบบสั้น 5 วินาทีที่สมบูรณ์แบบ—เริ่มต้นด้วยเฟรมที่จัดวางอย่างพิถีพิถันของคุณ หมุนกล้องอย่างราบรื่นรอบนาฬิกา แสงไฟที่โดดเด่น รายละเอียดคมชัด และพื้นผิวระดับพรีเมียมถูกถ่ายทอดอย่างไร้รอยต่อจากภาพต้นฉบับผ่านทุกเฟรมของวิดีโอ

กรณีศึกษาที่ 1: การโฆษณาเรือนเวลาหรู จากแนวคิดเพียงห้าคำสู่คลิปวิดีโอผลิตภัณฑ์ความยาวห้าวินาทีที่สมบูรณ์แบบ—กระบวนการสามขั้นตอนที่ส่งมอบผลงานระดับโฆษณาเชิงพาณิชย์
กรณี 2: เนื้อหาการเดินทางบนสื่อสังคมออนไลน์
วัตถุประสงค์: ผลิตวิดีโอแนวตั้งที่บันทึกภาพพระอาทิตย์ขึ้นที่ศาลเจ้าญี่ปุ่นสำหรับ TikTok/Instagram Reels
เฟสแรก — การสร้างข้อความกระตุ้น
เปิด ตัวสร้างข้อความแนะนำสำหรับภาพ
ข้อมูลนำเข้า: "พระอาทิตย์ขึ้นที่วัดญี่ปุ่น เช้าอันเงียบสงบ"
เลือกสไตล์: สมจริง
ข้อความที่สร้างขึ้น:
A traditional Japanese wooden temple (Kiyomizu-dera style) nestled
among ancient cedar trees, photographed at dawn. Golden sunrise light
filters through morning mist, casting long warm shadows across the
temple's wooden veranda. Cherry blossom branches frame the upper
portion of the composition, with delicate pink petals catching the
first light. A stone lantern stands in the foreground left, moss-
covered and weathered. The temple roof's curved eaves are silhouetted
against a sky transitioning from deep indigo to warm peach and gold.
Subtle mist hovers at ground level among the trees. Photorealistic
landscape photography, golden hour lighting, serene and contemplative
atmosphere, high dynamic range, rich natural color palette.ขั้นตอนที่สอง — การสร้างภาพ
วางลงใน แปลงข้อความเป็นภาพ. การตั้งค่าสำคัญ: สร้างในอัตราส่วนภาพแนวตั้ง 9:16 เหมาะสำหรับ TikTok และ Instagram Reels.
ร่างแรก: บรรยากาศสวยงามมาก แต่กิ่งซากุระอยู่สูงเกินไปในกรอบ ทำให้มีพื้นที่ว่างมากเกินไปในส่วนล่างของภาพ
การทำซ้ำ: หลังจากปรับแต่งข้อความกระตุ้นเล็กน้อยและเพิ่มคำอธิบาย "กิ่งซากุระแผ่ขยายจากมุมบนขวาและซ้าย เติมเต็มหนึ่งในสามส่วนบนของกรอบแนวตั้ง" รุ่นที่สองได้จัดวางดอกซากุระเป็นกรอบธรรมชาติสำหรับองค์ประกอบได้อย่างสมบูรณ์แบบ
องค์ประกอบนี้เหมาะอย่างยิ่งสำหรับวิดีโอแนวตั้ง: ศาลเจ้าดึงดูดสายตาไปยังจุดศูนย์กลางของเฟรม ในขณะที่ดอกซากุระที่ด้านบนสร้างความน่าสนใจทางสายตา โคมไฟหินและหมอกในเบื้องหน้าให้ความลึก ช็อตนี้เปิดโอกาสสำหรับการเคลื่อนไหวข้ามหลายชั้น
ขั้นตอนที่สาม — การสร้างวิดีโอ
ส่งไปที่ ภาพเป็นวิดีโอ
คำแนะนำในการออกกำลังกาย:
Gentle cherry blossom petals drift slowly downward through the frame.
Morning mist shifts and swirls at ground level among the trees. Two
birds fly across the sky in the background. The sunrise light gradually
intensifies, warming the scene. A subtle breeze moves the cherry
blossom branches slightly. Peaceful, meditative atmosphere. Slow,
contemplative pacing.กลีบดอกซากุระลอยละล่องอย่างแผ่วเบาผ่านกรอบภาพ หมอกยามเช้าไหลเอื่อยปกคลุมพื้นดินระหว่างต้นไม้ สองนกบินร่อนผ่านท้องฟ้าเป็นฉากหลัง แสงอาทิตย์ยามรุ่งอรุณค่อยๆ สว่างขึ้น อบอุ่นทั่วทั้งฉาก สายลมอ่อนโยนพัดกิ่งซากุระไหวเป็นระลอก บรรยากาศเงียบสงบ เหมาะแก่การทำสมาธิ จังหวะช้าๆ ที่ชวนให้ครุ่นคิด
สิ่งที่ได้รับ: วิดีโอแนวตั้งบรรยากาศความยาว 4 วินาที เหมาะสำหรับ TikTok และ Instagram Reels อย่างลงตัว ดอกซากุระลอยอย่างธรรมชาติ ท่ามกลางหมอกยามเช้าที่เพิ่มมิติและการเคลื่อนไหว นกในฉากหลังสร้างจุดสนใจที่ละเอียดอ่อน โทนสีอบอุ่นแบบทองคำของภาพต้นฉบับแทรกซึมในทุกเฟรมของวิดีโอ
กรณีศึกษา 3: เรื่องราวของแบรนด์ – การจับคู่กรอบแรกและกรอบสุดท้าย
วัตถุประสงค์: สร้างเรื่องราวแบรนด์ความยาวหกวินาทีที่ถ่ายทอดการเปลี่ยนแปลงของคาเฟ่จากความเงียบสงบในยามเช้าตรู่สู่บรรยากาศคึกคักและเต็มไปด้วยลูกค้า
กรณีนี้ใช้กระบวนการแบบท่อสองครั้ง โดยสร้าง คู่ของภาพที่ประกอบด้วยเฟรมแรกและเฟรมสุดท้าย เพื่อให้โมเดลวิดีโอมีจุดยึดภาพสองจุดสำหรับการกำหนดโครงเรื่อง สำหรับการวิเคราะห์เชิงลึกเกี่ยวกับเทคนิคนี้ โปรดดูที่ คู่มือการออกแบบเฟรมแรกและเฟรมสุดท้าย
เฟสแรก — สองคำแนะนำ
สร้างชุดคำสั่งสองชุดจาก เครื่องมือสร้างคำสั่งสำหรับภาพ
ข้อความป้อนเข้าเฟรมแรก: "ร้านกาแฟว่างเปล่า แสงสว่างจากยามเช้าส่องเข้ามา พร้อมโทนสีเหลืองอำพันอบอุ่น"
ข้อความเริ่มต้นสำหรับเฟรมแรก:
Interior of an artisanal coffee shop in the early morning, before
opening. Warm amber sunlight streams through large front windows,
casting long golden rectangles across worn hardwood floors. Exposed
brick walls, a polished wooden counter with a brass espresso machine,
and empty mismatched chairs around small tables. A chalkboard menu
hangs behind the counter. Dust motes float in the sunbeams. The space
feels warm, inviting, and full of potential. Shot at eye level from
just inside the entrance. Photorealistic interior photography, warm
color palette, golden hour tones, cozy atmosphere.ข้อความป้อนข้อมูลสำหรับเฟรมสุดท้าย: "ร้านกาแฟที่คึกคักในเช้าวันอบอุ่น มีลูกค้าเพลิดเพลินกับกาแฟของพวกเขา"
ข้อความคำสั่งสำหรับเฟรมสุดท้ายที่สร้างขึ้น:
The same artisanal coffee shop, now alive with morning activity.
Diverse customers sit at tables -- some reading, some talking, some
working on laptops. A barista behind the counter steams milk, creating
a plume of white steam. Coffee cups and pastries fill the tables. Warm
morning light still streams through the windows but is supplemented by
the warm glow of pendant lights. The atmosphere is bustling but cozy,
full of quiet energy and the warmth of community. Shot from the same
eye-level position just inside the entrance. Photorealistic interior
photography, warm tones, lively atmosphere.ขั้นตอนที่สอง — สองภาพ
สร้างเฟรมแรกใน text-to-image ด้วยอัตราส่วนภาพ 16:9 ทำซ้ำจนกว่าจะเห็นคาเฟ่ที่ว่างเปล่าดูอบอุ่นและน่าดึงดูด แสงเช้าสีทองส่องสว่างทั่วบริเวณ
เฟรมสุดท้ายใช้การสร้างภาพแบบ [image-to-image] อัปโหลดเฟรมเริ่มต้นเป็นภาพอ้างอิงและใช้คำสั่งสำหรับเฟรมสุดท้าย ขั้นตอนนี้มีความสำคัญ—การใช้เฟรมเริ่มต้นเป็นอ้างอิงจะช่วยให้เกิดความสอดคล้องทางสายตา สถาปัตยกรรม เฟอร์นิเจอร์ ทิศทางแสง และโทนสีจะคงความสม่ำเสมอระหว่างเฟรม โดยมีการเพิ่มเติมเพียงการใส่บุคคลและกิจกรรมเท่านั้น
วนซ้ำที่เฟรมสุดท้ายเพื่อให้แน่ใจว่าแขกดูเป็นธรรมชาติและบาริสต้ายืนอยู่หลังเคาน์เตอร์ สิ่งสำคัญคือ: ทั้งสองภาพควรดูเหมือนเป็นสถานที่เดียวกันที่ถ่ายในเวลาต่างกัน ไม่ใช่สองสถานที่แยกกัน
ขั้นตอนที่สาม — การสร้างวิดีโอ
อัปโหลดเฟรมแรกไปยัง Image-to-Video บนแพลตฟอร์มที่รองรับการอ้างอิงเฟรมสุดท้าย ให้อัปโหลดเฟรมสุดท้ายพร้อมกัน
คำแนะนำในการออกกำลังกาย:
Time-lapse style transition. The empty coffee shop gradually fills
with people arriving -- customers entering, sitting down, a barista
beginning to work. Morning light shifts slowly. The scene transitions
from quiet solitude to warm, bustling community. Smooth, cinematic
pacing. The camera position remains fixed.(การเปลี่ยนฉากแบบไทม์แลปส์ คาเฟ่ที่ว่างเปล่าค่อย ๆ เต็มไปด้วยลูกค้าที่ทยอยเข้ามา—ลูกค้าเดินเข้ามา นั่งที่โต๊ะ และบาริสตาก็เริ่มทำงาน แสงยามเช้าค่อย ๆ เปลี่ยนแปลงอย่างนุ่มนวล บรรยากาศค่อย ๆ เปลี่ยนจากความเงียบสงบเป็นชุมชนที่อบอุ่นและคึกคัก จังหวะการเล่าเรื่องลื่นไหลแบบภาพยนตร์ กล้องคงที่)
ผลลัพธ์: เรื่องราวแบรนด์ความยาวหกวินาทีที่ถ่ายทอดเรื่องราวอย่างสมบูรณ์—การตื่นขึ้นของร้านกาแฟ ภาพเปิดสร้างบรรยากาศที่เงียบสงบและอบอุ่นต้อนรับ ภาพปิดนำเสนอสภาพที่ต้องการให้เกิด การเปลี่ยนผ่านที่สร้างโดย AI เชื่อมโยงทั้งสองภาพ: ประตูเปิดออก ลูกค้าเข้ามาที่โต๊ะ บาริสตากดเครื่องชงกาแฟ และถ้วยกาแฟปรากฏบนโต๊ะ ข้อความของแบรนด์เรียบง่ายแต่ทรงพลัง—นี่คือสถานที่ที่รู้สึกเหมือนอยู่บ้าน

กรณีศึกษาที่ 3: การเล่าเรื่องแบรนด์ที่เชื่อมโยงกรอบเปิดและปิดเข้าด้วยกัน AI สร้างการเปลี่ยนผ่านแบบไทม์แลปส์ระหว่างจุดยึดภาพสองจุด—จากความเงียบสงบของรุ่งอรุณสู่ความอบอุ่นของชุมชน
เทคนิคการเพิ่มประสิทธิภาพท่อส่ง
หลังจากที่ได้ผลิตวิดีโอหลายร้อยรายการผ่านกระบวนการนี้ หลักการห้าข้อต่อไปนี้ได้ส่งผลกระทบมากที่สุดต่อคุณภาพของผลงาน
เคล็ดลับที่ 1: ใช้เวลา 80% ของคุณไปกับรูปภาพ
นี่คือการปรับปรุงประสิทธิภาพที่สำคัญที่สุด คุณภาพของภาพเป็นคอขวดตลอดทั้งกระบวนการทั้งหมด ภาพที่สมบูรณ์แบบจะให้วิดีโอที่ใช้งานได้ในรุ่นแรก ภาพที่ธรรมดา แม้ว่าจะมีการสร้างการเคลื่อนไหวที่ดีเพียงใด ก็จะให้วิดีโอที่ธรรมดาเท่านั้น
การจัดสรรเวลาควรเป็นไปตามนี้:
- การสร้างข้อความ: 5% (เครื่องมือสร้างใช้เวลาไม่กี่วินาที, การเขียนด้วยมือใช้เวลาหลายนาที)
- การสร้างภาพและการปรับปรุง: 80% (สร้าง, ประเมินผล, ปรับแต่ง, สร้างใหม่จนกว่าฉากจะสมบูรณ์แบบ)
- การสร้างวิดีโอ: 15% (อัปโหลด, เขียนคำแนะนำการเคลื่อนไหว, สร้าง)
มือใหม่ส่วนใหญ่มักทำลำดับขั้นตอนกลับด้าน—ใช้เวลาสิบวินาทีกับภาพหนึ่งภาพ แล้วสร้างวิดีโอออกมาทีละอัน หวังว่าจะได้วิดีโอที่ดีโดยบังเอิญ ผู้ใช้ที่มีประสบการณ์จะใช้เวลาสิบนาทีกับภาพเดียว และมักจะได้วิดีโอที่ดีภายในไม่กี่ครั้งแรก วิธีหลังนี้ให้ผลลัพธ์ที่เหนือกว่าด้วยเครดิตน้อยกว่าและใช้เวลาน้อยกว่า
ก่อนที่จะเริ่มสร้างวิดีโอ ให้วนซ้ำภาพเหล่านั้นสามถึงห้าครั้ง นี่ไม่ใช่ความสมบูรณ์แบบ แต่เป็นความมีประสิทธิภาพ
เคล็ดลับที่ 2: ออกแบบมาเพื่อการเคลื่อนไหว
ภาพถ่ายที่น่าพอใจและกรอบวิดีโอที่ดีไม่ใช่สิ่งเดียวกัน เมื่อสร้างภาพสำหรับกระบวนการผลิต ให้จินตนาการว่าฉากนั้นจะปรากฏอย่างไรเมื่อมันมีชีวิตขึ้นมา
เว้นพื้นที่ว่างในทิศทางของการเคลื่อนไหวหลัก หากตัวละครกำลังเคลื่อนที่จากซ้ายไปขวา หลีกเลี่ยงการจัดวางให้อยู่ตรงกลาง ให้จัดวางไปทางขวาเล็กน้อยเพื่อให้มีพื้นที่สำหรับการเคลื่อนไหว หากกล้องกำลังเคลื่อนที่ไปทางซ้าย ให้แน่ใจว่าด้านซ้ายของเฟรมมีเนื้อหาที่น่าสนใจดึงดูดสายตา
จัดองค์ประกอบภาพตามทิศทางของกล้อง การถ่ายภาพแบบดัน (Push shots) จะได้ผลดีที่สุดเมื่อรายละเอียดที่น่าสนใจที่สุดอยู่ตรงกลางเฟรม การถ่ายภาพแบบแพน (Pan shots) ต้องมีความน่าสนใจทางสายตาตลอดความกว้างของเฟรม การถ่ายภาพแบบหมุนตาม (Circular tracking shots) เหมาะกับวัตถุที่มีมิติและมีความลึก ไม่ใช่วัตถุที่แบนราบ
หลีกเลี่ยงการจัดองค์ประกอบแบบสมมาตรที่ซับซ้อน แม้ว่าความสมมาตรที่สมบูรณ์แบบอาจดูโดดเด่นในภาพถ่าย แต่กลับสร้างความท้าทายในการสร้างวิดีโอ ระบบ AI มักประสบปัญหาในการรักษาความสมมาตรอย่างแม่นยำระหว่างแต่ละเฟรม ส่งผลให้เกิดการสั่นไหวที่รบกวนสายตา การจัดองค์ประกอบที่ไม่สมมาตรซึ่งมีทิศทางการไหลของภาพอย่างเป็นธรรมชาติ จะช่วยให้วิดีโอมีความลื่นไหลและดูน่าดึงดูดยิ่งขึ้น
รวมข้อมูลเชิงลึกของความลึก ภาพที่มีองค์ประกอบซ้อนทับกันในระยะทางที่แตกต่างกัน—วัตถุในเบื้องหน้า วัตถุในระยะกลาง และสภาพแวดล้อมในเบื้องหลัง—ให้ข้อมูลเชิงลึกของความลึกแก่ AI ซึ่งส่งผลให้เกิดเอฟเฟกต์พารัลแลกซ์ที่ดีขึ้นและการเคลื่อนไหวของกล้องที่ดูเป็นธรรมชาติมากขึ้น
สำหรับคู่มือที่ครอบคลุมเกี่ยวกับการออกแบบภาพโดยเฉพาะสำหรับวิดีโอ โปรดดูที่ คู่มือการออกแบบเฟรมแรกและเฟรมสุดท้าย
เทคนิคที่ 3: รักษาอัตราส่วนภาพให้คงที่ตลอดทั้งกระบวนการ
อัตราส่วนภาพที่ไม่ตรงกันระหว่างภาพและเฟรมวิดีโอถือเป็นหนึ่งในข้อผิดพลาดที่พบบ่อยที่สุดในกระบวนการทำงาน ซึ่งส่งผลให้คุณภาพของผลลัพธ์ลดลงอย่างหลีกเลี่ยงไม่ได้
- 16:9 สำหรับวิดีโอแนวนอน (YouTube, การนำเสนอ, หน้าเว็บไซต์)
- 9:16 สำหรับวิดีโอแนวตั้ง (TikTok, Instagram Reels, YouTube Shorts)
- 1:1 สำหรับวิดีโอสี่เหลี่ยมจัตุรัส (Instagram Stories, โฆษณาบางประเภทในโซเชียลมีเดีย)
ตั้งค่าอัตราส่วนภาพในระหว่างการสร้างภาพ แทนที่จะปล่อยไว้จนถึงขั้นตอนการทำวิดีโอ หากคุณสร้างภาพสี่เหลี่ยมจัตุรัสขนาด 1:1 แล้วพยายามสร้างวิดีโอขนาด 16:9 โมเดลวิดีโอจะต้องเติมด้านข้างขึ้นมาใหม่ทั้งหมด – และคุณภาพของเนื้อหาที่สร้างขึ้นนี้จะด้อยกว่าส่วนที่เหลือของเฟรม ควรสร้างภาพในอัตราส่วนภาพสุดท้ายของวิดีโอตั้งแต่เริ่มต้น
เคล็ดลับที่ 4: รักษาสไตล์การให้คำแนะนำที่สม่ำเสมอในทุกขั้นตอน
คำสำคัญด้านสไตล์ในคำอธิบายภาพและคำบอกทิศทางการเคลื่อนไหวในคำอธิบายวิดีโอควรใช้ภาษาภาพเดียวกัน ความไม่สอดคล้องกันระหว่างทั้งสองจะส่งผลให้เกิดปัญหาคุณภาพที่ละเอียดอ่อนในผลลัพธ์สุดท้าย
หากคำอธิบายภาพของคุณมีคำว่า "ภาพยนตร์, แสงสว่างที่ดราม่า, บรรยากาศที่เศร้าหมอง" คำอธิบายการเคลื่อนไหวของวิดีโอควรใช้ภาษาที่สอดคล้องกัน: "การเคลื่อนไหวของกล้องแบบภาพยนตร์, บรรยากาศที่ดราม่า, จังหวะที่เศร้าหมอง" หลีกเลี่ยงการจับคู่ภาพที่ดราม่าและภาพยนตร์กับคำอธิบายการเคลื่อนไหวเช่น "สนุกสนาน, กระโดด, กระฉับกระเฉง" – ความขัดแย้งทางอารมณ์จะทำให้แบบจำลองสับสนและลดความสอดคล้อง
คู่มืออ้างอิงด่วน — ตารางการจับคู่สไตล์:
| สไตล์ภาพ | ภาษาของคำแนะนำการเคลื่อนไหวที่ตรงกัน |
|---|---|
| ภาพยนตร์, ดราม่า | "การเคลื่อนไหวของกล้องแบบภาพยนตร์, จังหวะที่ดราม่า, ช้าและตั้งใจ" |
| สว่าง, เชิงพาณิชย์, สะอาด | "การเคลื่อนไหวที่ราบรื่น, มืออาชีพ, จังหวะที่มั่นคง, การเปลี่ยนฉากที่สะอาด" |
| ฝัน, เฟื่องฟ้า, นุ่มนวล | "การเคลื่อนไหวที่อ่อนโยน ลอยละล่อง บรรยากาศที่ฝัน ไหลไปอย่างช้าๆ" |
| พลังสูง, ดินามิก | "การเคลื่อนไหวของกล้องที่พลุ่งพล่าน จังหวะที่กระฉับกระเฉง การตัดต่อที่รวดเร็ว" |
| สารคดี, ธรรมชาติ | "ความรู้สึกเหมือนถือกล้องในมือ การเคลื่อนไหวที่เป็นธรรมชาติ จังหวะที่สังเกตการณ์" |
เคล็ดลับที่ 5: บันทึกแม่แบบ pipeline ที่ดีที่สุดของคุณ
เมื่อกระบวนการ → ข้อความ → ภาพ → วิดีโอ ให้ผลลัพธ์ที่น่าพอใจ ให้บันทึกกระบวนการทั้งหมด:
- คำสั่งภาพ (ข้อความต้นฉบับ)
- การตั้งค่าสไตล์ที่เลือก
- การตั้งค่าการสร้างภาพ (อัตราส่วนภาพ, โมเดล, หมายเลขเมล็ด, ฯลฯ)
- คำสั่งการเคลื่อนไหวของวิดีโอ
- การตั้งค่าการสร้างวิดีโอ (ระยะเวลา, ความละเอียด)
ท่อส่งนี้ใช้เป็นแม่แบบ ต้องการสร้างวิดีโอที่คล้ายกันสำหรับผลิตภัณฑ์อื่น ๆ หรือไม่? เพียงเปลี่ยนหัวข้อในคำแนะนำของภาพแล้วสร้างใหม่ ต้องการฉากที่ต่างกันในสไตล์เดียวกันหรือไม่? รักษาคำสำคัญสไตล์ไว้แล้วเปลี่ยนคำอธิบายของหัวข้อ
เมื่อเวลาผ่านไป คุณจะสร้างคลังข้อมูลที่สมบูรณ์ของกระบวนการทำงานที่ปรับให้เหมาะกับความต้องการสร้างสรรค์ที่แตกต่างกัน: โฆษณาผลิตภัณฑ์, เนื้อหาสำหรับสื่อสังคมออนไลน์, เรื่องราวของแบรนด์, ภาพเคลื่อนไหว B-roll สำหรับภาพยนตร์, การ์ตูนตัวละคร. โครงการใหม่แต่ละโครงการจะเริ่มต้นจากฐานที่พิสูจน์แล้วแทนที่จะเริ่มต้นจากศูนย์.
การเปรียบเทียบเครื่องมือทางเลือกในแต่ละขั้นตอน
Seedance มอบกระบวนการทำงานแบบครบวงจร แม้ว่าคุณจะสามารถสร้างขั้นตอนการทำงานนี้โดยใช้เครื่องมือแยกต่างหากได้เช่นกัน ด้านล่างนี้คือการเปรียบเทียบอย่างตรงไปตรงมาของแต่ละขั้นตอน
ระยะที่หนึ่ง: การสร้างข้อความกระตุ้น
| เครื่องมือ | เหมาะสำหรับ | คำอธิบาย |
|---|---|---|
| เครื่องมือสร้างข้อความสำหรับภาพ Seedance | สายงานที่รวมเข้าด้วยกัน, 12 แบบสำเร็จรูป | 2 เครดิตต่อข้อความ. ส่งออกโดยตรงไปยังเครื่องมือสร้างภาพ Seedance. |
| ChatGPT / GPT-4 | วิศวกรรมคำสั่งที่กำหนดเอง | ต้องคัดลอกและวางด้วยตนเอง ไม่มีรูปแบบสำเร็จรูป ยืดหยุ่นมากขึ้นสำหรับคำสั่งที่ซับซ้อน |
| Claude | คำแนะนำที่ละเอียดและประณีต | เชี่ยวชาญในการดำเนินการตามบรีฟสร้างสรรค์ที่ซับซ้อน ไม่มีการผสานรวมการสร้างภาพ |
| Tongyi Qianwen | ปรับให้เหมาะสมกับบริบทภาษาจีน | เข้าใจคำอธิบายภาษาจีนอย่างเป็นธรรมชาติมากขึ้น เหมาะสำหรับผู้ใช้ในประเทศ ต้องผสานรวมด้วยเครื่องมือปลายน้ำด้วยตนเอง |
ขั้นตอนที่สอง: การสร้างภาพ
| เครื่องมือ | เหมาะสำหรับ | หมายเหตุ |
|---|---|---|
| Seedance Text-to-Image / Image-to-Image | การรวมเข้ากับสายงาน, กระบวนการทำงานที่เน้นวิดีโอเป็นหลัก | ภาพถ่ายถูกส่งไปยังขั้นตอนวิดีโอโดยตรงโดยไม่สูญเสียคุณภาพเลย |
| Midjourney | คุณภาพทางศิลปะ, การแสดงออกทางสุนทรียะ | สร้างผลงานที่โดดเด่น ต้องการการใช้งานผ่าน Discord หรือเว็บอินเตอร์เฟซ สามารถดาวน์โหลดด้วยตนเองภายในระบบได้ |
| Tongyi Wanshang | รองรับคำสั่งภาษาจีน, การเข้าถึงในประเทศที่เสถียร | พัฒนาโดย Alibaba มีความเชี่ยวชาญในการเข้าใจคำอธิบายภาษาจีน เหมาะสำหรับผู้ใช้ในประเทศที่ไม่มี VPN |
| DALL-E 3 | ความแม่นยำของคำสั่ง, การแสดงผลตามข้อความ | โดดเด่นในการดำเนินการตามคำสั่งที่ซับซ้อนอย่างตรงตัว การควบคุมสไตล์มีจำกัด |
| Stable Diffusion | ควบคุมได้เต็มที่, สร้างแบบเฉพาะที่ | ความยืดหยุ่นสูงสุด ต้องการการตั้งค่าสภาพแวดล้อมทางเทคนิค เหมาะสำหรับงานปริมาณมาก |
ขั้นตอนที่สาม: การสร้างวิดีโอ
| เครื่องมือ | เหมาะสำหรับ | คำอธิบาย |
|---|---|---|
| Seedance Image-to-Video | สายงานแบบบูรณาการ คุณภาพสม่ำเสมอ | การถ่ายโอนภาพที่ราบรื่น รองรับการป้อนข้อมูลจากเฟรมแรกโดยตรง |
| Kling 3.0 | ระยะเวลาใช้งานยาวนาน คุณภาพสูง | สร้างได้สูงสุด 2 นาทีต่อครั้ง คุณภาพการเคลื่อนไหวยอดเยี่ยม โดย Kuaishou สามารถใช้งานได้ภายในประเทศจีน |
| จี่เมิ่ง AI | ระบบนิเวศจีน ใช้งานง่าย | พัฒนาโดย ByteDance ผสานกับระบบนิเวศ TikTok อย่างลึกซึ้ง เหมาะสำหรับการสร้างวิดีโอสั้น |
| รันเวย์ Gen-4 | การควบคุมที่แม่นยำ, แปรงการเคลื่อนไหว | โหมดผู้กำกับรองรับเส้นทางกล้องที่กำหนดเองได้ อินเทอร์เฟซระดับมืออาชีพ ราคาสูงกว่า |
| Pika 2.0 | การเริ่มต้นใช้งานที่ง่าย, การทดลองอย่างรวดเร็ว | อินเทอร์เฟซที่เรียบง่ายที่สุด เหมาะสำหรับผู้เริ่มต้น การควบคุมรายละเอียดการเคลื่อนไหวที่จำกัด |
พูดตรงๆ: คุณสามารถสร้างกระบวนการที่มีคุณภาพสูงได้โดยใช้ ChatGPT สำหรับการเขียนคำสั่ง, Midjourney สำหรับการสร้างภาพ, และ Keeling สำหรับการผลิตวิดีโอ ผู้เชี่ยวชาญหลายคนทำเช่นนั้นอย่างแม่นยำ ข้อได้เปรียบของ Seedance ไม่ได้อยู่ที่การเอาชนะคู่แข่งในขั้นตอนใด ๆ อย่างเดียว แต่อยู่ที่การกำจัดความเสียดทานผ่านการผสานรวม การรักษาคุณภาพในทุกขั้นตอน และการรวมกระบวนการทำงานที่แยกกันสามอย่างให้กลายเป็นหนึ่งเดียว สำหรับผู้สร้างสรรค์ที่ผลิตวิดีโอ AI อย่างต่อเนื่อง เวลาที่ประหยัดได้จากการอยู่ในแพลตฟอร์มเดียวจะเพิ่มขึ้นเป็นหลายชั่วโมงต่อสัปดาห์
สำหรับการเปรียบเทียบเครื่องมือสร้างวิดีโออย่างละเอียด โปรดดูที่ การเปรียบเทียบเครื่องมือสร้างวิดีโอ AI ที่ดีที่สุดปี 2026
ข้อผิดพลาดทั่วไปของระบบท่อ
ด้านล่างนี้คือข้อผิดพลาดที่พบบ่อยที่สุดห้าประการเมื่อตั้งค่ากระบวนการ prompt → image → video แต่ละข้อมีวิธีแก้ไขที่ตรงไปตรงมา
ข้อผิดพลาด 1: ข้ามขั้นตอนการเพิ่มรูปภาพโดยสมบูรณ์
การแสดงออกเฉพาะ: แปลงข้อความเป็นวิดีโอโดยตรง โดยไม่ผ่านกระบวนการสร้างภาพ
ทำไมถึงเป็นปัญหา: คุณสูญเสียการควบคุมองค์ประกอบทั้งหมด โมเดลวิดีโอจะเป็นผู้กำหนดทุกอย่าง—เนื้อหาภาพ, การจัดกรอบฉาก, และจุดเริ่มต้นของกล้อง ผลลัพธ์ไม่สามารถคาดการณ์ได้ และมีโอกาสน้อยมากที่จะตรงกับความตั้งใจสร้างสรรค์ของคุณในครั้งแรก
วิธีแก้ไข: สร้างภาพเฟรมแรกเสมอ แม้ว่าคุณจะเชื่อว่าข้อความที่คุณป้อนมีรายละเอียดเพียงพอแล้วก็ตาม การใช้เวลา 30 วินาทีในการสร้างภาพสามารถช่วยประหยัดเวลาจากการสร้างวิดีโอที่ล้มเหลวหลายครั้งได้
ข้อผิดพลาด 2: การใช้ภาพสต็อกโดยไม่ผ่านการประเมิน
การแสดงออกที่เฉพาะเจาะจง: ดาวน์โหลดภาพจากอินเทอร์เน็ตหรือเลือกภาพจากคลังภาพสต็อกแบบสุ่ม แล้วแทรกภาพนั้นเข้าไปในกระบวนการสร้างวิดีโอโดยตรงโดยไม่ประเมินความเหมาะสมของภาพนั้นสำหรับใช้เป็นภาพเปิด
ทำไมถึงเป็นปัญหา: ภาพถ่ายหลายภาพถูกออกแบบมาสำหรับการดูแบบนิ่ง ไม่ใช่การเคลื่อนไหว การครอบภาพแน่นเกินไป ทำให้ไม่มีพื้นที่สำหรับการเคลื่อนไหวของกล้อง วัตถุถูกจัดให้อยู่ตรงกลาง ทำให้มีตัวเลือกการจัดกรอบภาพน้อย แสงสว่างแบนราบ ทำให้เอฟเฟ็กต์วิดีโอดูน่าเบื่อ JPEG ที่ถูกบีบอัดสูงทำให้เกิดอาร์ติแฟค
วิธีแก้ไข: ก่อนใช้ภาพใด ๆ ให้ประเมินภาพนั้นตามหลักการ "ออกแบบสำหรับการเคลื่อนไหว" ก่อนเสมอ วิธีที่ดีกว่าคือใช้กระบวนการทำงานแบบสายงาน (pipeline) โดยเฉพาะเพื่อสร้างคีย์เฟรม
ข้อผิดพลาด 3: ความไม่ตรงกันของอัตราส่วนภาพ
การแสดงออกเฉพาะ: สร้างภาพสี่เหลี่ยมจัตุรัสแล้วสร้างวิดีโอแบบ 16:9 หรือใช้ภาพแนวนอนเพื่อผลิตวิดีโอแนวตั้ง
เหตุใดจึงก่อให้เกิดความเสียหายอย่างมีนัยสำคัญ: โมเดลวิดีโอจะทำการครอบตัดภาพของคุณ (ส่งผลให้เนื้อหาที่คุณออกแบบอย่างพิถีพิถันสูญหายไป) หรือเติมอัตราส่วนภาพใหม่ด้วยเนื้อหาที่สร้างขึ้นใหม่ทั้งหมด (โดยขอบที่เพิ่มเข้ามามีคุณภาพต่ำกว่า)
วิธีแก้ไข: กำหนดอัตราส่วนภาพสุดท้ายของวิดีโอให้ชัดเจนก่อนสร้างภาพ จากนั้นสร้างภาพตามอัตราส่วนภาพที่กำหนดไว้
ข้อผิดพลาดที่ 4: คำแนะนำวิดีโอที่อธิบายมากเกินไป
การแสดงออกเฉพาะ: วิดีโอคำอธิบายภาพอธิบายทั้งฉากและการเคลื่อนไหวพร้อมกัน: "นาฬิกาหรูบนหินอ่อนสีเข้มพร้อมแสงไฟที่โดดเด่น กล้องหมุนช้าๆ และแสงสะท้อนเต้นระบำบนพื้นผิว"
ทำไมสิ่งนี้จึงเป็นปัญหา: คำอธิบายภาพอาจขัดแย้งกับเนื้อหาของภาพ หากนาฬิกาถูกแสดงบนหินอ่อนสีขาวแต่คำสั่งระบุว่าเป็นหินอ่อนสีเข้ม โมเดลจะได้รับสัญญาณที่ขัดแย้งกัน ในกรณีที่ดีที่สุด คำอธิบายภาพจะกลายเป็นส่วนเกิน แต่ในกรณีที่แย่ที่สุด มันอาจทำให้โมเดลพยายามปรับเปลี่ยนเฟรมแรกที่คุณออกแบบไว้อย่างพิถีพิถัน
วิธีการสร้าง: คำแนะนำสำหรับวิดีโอควรอธิบายเฉพาะการเคลื่อนไหว มุมกล้อง และบรรยากาศเท่านั้น ภาพที่ได้ถูกสร้างเป็นภาพนิ่งเรียบร้อยแล้ว โปรดจำหลักการนี้ไว้: ภาพนิ่งสื่อถึง "สิ่งที่เห็น" ในขณะที่คำแนะนำสำหรับวิดีโอจะกำหนด "วิธีการเคลื่อนไหว"
ข้อผิดพลาดที่ 5: เร่งสร้างวิดีโอโดยไม่ตรวจสอบภาพซ้ำ
การแสดงออกเฉพาะ: การสร้างภาพและป้อนภาพนั้นเข้าสู่การสร้างวิดีโอโดยตรง แม้ว่าจะแสดงข้อบกพร่องที่เห็นได้ชัด เช่น องค์ประกอบที่เอียงเล็กน้อย ความไม่สมบูรณ์เล็กน้อย หรือการให้แสงที่ไม่เหมาะสม
ทำไมผลกระทบจึงมากขึ้น: วิดีโอขยายทุกข้อบกพร่องในภาพต้นฉบับ ความไม่สมบูรณ์เล็กน้อยในภาพถ่ายนิ่งกลายเป็นข้อบกพร่องที่เคลื่อนไหวอย่างต่อเนื่องตลอด 120 เฟรมของการเคลื่อนไหว การจัดองค์ประกอบที่เบี่ยงเบนไปจากจุดศูนย์กลางเล็กน้อยจะกลายเป็นความผิดพลาดที่เห็นได้ชัดเมื่อการเคลื่อนไหวของกล้องดึงความสนใจไปที่กรอบภาพ ข้อบกพร่องทุกประการในภาพถ่ายจะยิ่งเห็นได้ชัดเจนขึ้น ไม่ใช่ลดลง ในวิดีโอ
วิธีแก้ไข: ให้ขั้นตอนการสร้างภาพเป็นจุดตรวจสอบคุณภาพ (quality control checkpoint) ห้ามดำเนินการไปยังขั้นตอนการสร้างวิดีโอจนกว่าภาพจะน่าพอใจอย่างแท้จริง ทำซ้ำ 3–5 ครั้ง ใช้การสร้างภาพจากภาพ (image-to-image generation) สำหรับการซ่อมแซมที่เฉพาะเจาะจง ผลลัพธ์วิดีโอไม่สามารถมีคุณภาพเกินกว่าภาพต้นฉบับได้
คำถามที่พบบ่อย
ทำไมต้องใช้การเป็นตัวกลางของภาพแทนการแปลงข้อความเป็นวิดีโอโดยตรง?
การสร้างวิดีโอจากข้อความต้องการให้ AI สร้างทั้งภาพและเคลื่อนไหวจากข้อความพร้อมกัน ซึ่งหมายความว่าคุณมีการควบคุมน้อยมากเกี่ยวกับองค์ประกอบ, ลักษณะของตัวละคร, แสงสว่าง, และการจัดกรอบ แนวทางที่เน้นภาพเป็นอันดับแรกจะแยกงานทั้งสองนี้ออกจากกัน: คุณจะปรับแต่งภาพในระหว่างขั้นตอนการสร้างภาพ จากนั้นจึงสั่งให้ AI เพิ่มการเคลื่อนไหวเท่านั้น วิธีนี้ช่วยให้ได้ผลลัพธ์ที่คาดการณ์ได้มากขึ้นและมีคุณภาพสูงกว่า เนื่องจาก AI ได้รับข้อมูลอ้างอิงทางภาพที่ชัดเจน แทนที่จะต้องตีความข้อความที่คลุมเครือ ความแตกต่างนี้เห็นได้ชัดเจนโดยเฉพาะในสถานการณ์ระดับมืออาชีพที่ต้องการองค์ประกอบเฉพาะ โทนสีของแบรนด์ หรือดีไซน์ตัวละครที่สม่ำเสมอ
กระบวนการสร้างวิดีโอ AI ตั้งแต่เริ่มต้นทั้งหมดมีอะไรบ้าง?
กระบวนการทั้งหมดประกอบด้วยสามขั้นตอน ขั้นตอนที่หนึ่ง: ใช้เครื่องมือสร้างข้อความสำหรับ AI (เช่น Image Prompt Generator ของ Seedance) เพื่อขยายแนวคิดของคุณให้กลายเป็นข้อความรายละเอียดสำหรับภาพ ขั้นตอนที่สอง: นำข้อความที่ได้ไปใช้ในเครื่องมือสร้างภาพจากข้อความ (เช่น Text-to-Image ของ Seedance) เพื่อสร้างภาพตัวอย่างคุณภาพสูง โดยทำซ้ำจนกว่าจะพอใจ ขั้นตอนที่สาม: อัปโหลดภาพไปยังเครื่องมือสร้างวิดีโอจากภาพ (เช่น Seedance's image-to-video) เขียนคำอธิบายที่อธิบายเฉพาะการเคลื่อนไหว (การเคลื่อนไหวของกล้องและการกระทำของวัตถุ) และสร้างวิดีโอ กระบวนการทั้งหมดใช้เวลา 5–15 นาที ขึ้นอยู่กับจำนวนครั้งที่ต้องทำซ้ำในขั้นตอนการสร้างภาพ
ระบบเต็มรูปแบบของ Seedance มีค่าใช้จ่ายเครดิตกี่เครดิต?
ค่าใช้จ่ายจะแตกต่างกันไปขึ้นอยู่กับรูปแบบการตั้งค่า แต่โดยทั่วไปแล้วการรันท่อส่งข้อมูลแบบมาตรฐานจะประกอบด้วย: การสร้างข้อความตอบกลับที่ 2 เครดิต, การสร้างภาพที่ 4–8 เครดิตต่อรอบ (คาดการณ์ไว้ที่ 3–5 รอบ รวมเป็น 12–40 เครดิต) และการสร้างวิดีโอที่ 10–30 เครดิต (ขึ้นอยู่กับระยะเวลาและความละเอียด) จากแนวคิดไปจนถึงวิดีโอที่เสร็จสมบูรณ์ ค่าใช้จ่ายทั้งหมดโดยทั่วไปจะอยู่ในช่วง 25 ถึง 70 เครดิต ซึ่งเป็นการประหยัดอย่างมากเมื่อเทียบกับการใช้เครื่องมือสามตัวแยกกันพร้อมกับการสมัครสมาชิกสามรายการแยกกัน
สามารถใช้ภาพที่สร้างโดยเครื่องมืออื่นเพื่อสร้างวิดีโอใน Seedance ได้หรือไม่?
แน่นอน เครื่องมือ [Image-to-Video] ของ Seedance รองรับภาพที่อัปโหลดได้ทุกประเภท—ไม่จำเป็นต้องสร้างโดย Seedance เอง คุณสามารถสร้างภาพโดยใช้ Midjourney, DALL-E, Tongyi Wanshang, Stable Diffusion หรือเครื่องมืออื่น ๆ และอัปโหลดเป็นเฟรมแรกได้ ข้อดีของกระบวนการแบบบูรณาการคือการกำจัดขั้นตอนการดาวน์โหลด-อัปโหลด แม้ว่าจะไม่จำเป็นก็ตาม เมื่อใช้ภาพภายนอก เราแนะนำให้ใช้รูปแบบ PNG ที่มีความละเอียด 1024x1024 หรือสูงกว่า เพื่อป้องกันปัญหาการบีบอัดที่อาจส่งผลต่อคุณภาพของวิดีโอ
อัตราส่วนภาพใดที่ควรใช้สำหรับรูปภาพ?
ตรวจสอบให้แน่ใจว่าอัตราส่วนภาพของคุณตรงกับรูปแบบวิดีโอสุดท้ายที่ต้องการเสมอ 16:9 สำหรับวิดีโอแนวนอน (YouTube, การนำเสนอ, การฝังในเว็บไซต์), 9:16 สำหรับวิดีโอแนวตั้ง (TikTok, Instagram Reels, YouTube Shorts), 1:1 สำหรับวิดีโอสี่เหลี่ยมจัตุรัส (Instagram ฟีด, โฆษณาบางประเภทในโซเชียล) สร้างภาพในอัตราส่วนที่ถูกต้องตั้งแต่เริ่มต้น อย่าสร้างภาพสี่เหลี่ยมจัตุรัสแล้วคาดหวังให้เครื่องมือวิดีโอแปลงเป็นอัตราส่วน 16:9 – วิธีนี้จะทำให้องค์ประกอบของคุณถูกตัดออกหรือเพิ่มเนื้อหาที่สร้างโดย AI ที่ขอบ ซึ่งทั้งสองอย่างนี้จะลดคุณภาพลง
วิธีสร้างคู่คีย์เฟรม?
สร้างสองเฟรมโดยใช้กระบวนการแยกกัน เฟรมแรกจะปฏิบัติตามขั้นตอนมาตรฐาน: สร้างคำสั่ง, สร้างภาพ, และทำซ้ำจนกว่าจะพอใจ เฟรมสุดท้ายจะใช้ image-to-image โดยอัปโหลดเฟรมแรกเป็นภาพอ้างอิงและอธิบายการเปลี่ยนแปลงในสถานะสุดท้าย สิ่งนี้ช่วยให้เกิดความสอดคล้องทางสายตา—สถานที่เดียวกัน ทิศทางแสงเดียวกัน โทนสีเดียวกัน—ในขณะที่สามารถสร้างการเปลี่ยนแปลงของเรื่องราวตามที่ต้องการ (ช่วงเวลา กิจกรรม หรืออารมณ์ที่แตกต่างกัน) เพียงอัปโหลดทั้งสองเฟรมเข้าสู่โปรแกรมสร้างวิดีโอ แล้วปล่อยให้ AI สร้างการเปลี่ยนฉากให้โดยอัตโนมัติ สำหรับคู่มือฉบับสมบูรณ์เกี่ยวกับเทคนิคนี้ กรุณาดูที่ คู่มือการออกแบบเฟรมแรกและเฟรมสุดท้าย
กระบวนการทำงานนี้เหมาะสำหรับเนื้อหาเชิงพาณิชย์หรือไม่?
เหมาะสม. ท่อส่งสามขั้นตอนได้รับการนำมาใช้โดยแบรนด์อีคอมเมิร์ซสำหรับวิดีโอสินค้า, ทีมการตลาดสำหรับสินทรัพย์โฆษณา, บริษัทอสังหาริมทรัพย์สำหรับการจัดแสดงทรัพย์สิน, และเอเจนซีคอนเทนต์สำหรับการผลิตสื่อสังคมออนไลน์. วิดีโอที่สร้างโดย AI ความยาว 5–15 วินาที พร้อมเฟรมเปิดคุณภาพสูง ขณะนี้ได้มาตรฐานระดับมืออาชีพสำหรับเนื้อหาดิจิทัลแล้ว กุญแจสู่ความสำเร็จทางการค้าก็คือการลงทุนเวลาในขั้นตอนการสร้างภาพ—เฟรมเปิดที่ผ่านการขัดเกลาจะส่งผลโดยตรงต่อคุณภาพของวิดีโอโดยรวม สำหรับเนื้อหาที่มีความยาวมากขึ้นหรือเนื้อหาเชิงพาณิชย์ระดับออกอากาศ AI ถูกนำมาใช้มากขึ้นในการสร้างสรรค์ไอเดียและสร้างภาพตัวอย่างล่วงหน้า โดยขั้นตอนการผลิตขั้นสุดท้ายยังคงดำเนินการด้วยวิธีดั้งเดิมเพื่อให้มั่นใจในการควบคุมสูงสุด
หากภาพที่สร้างขึ้นมีข้อบกพร่อง ควรทำอย่างไร?
โปรดอย่าดำเนินการสร้างวิดีโอ ความไม่สมบูรณ์ในภาพต้นฉบับจะถูกขยายในวิดีโอ—มือที่บิดเบี้ยวเล็กน้อยในภาพนิ่งจะกลายเป็นมือที่ผิดรูปอย่างเห็นได้ชัดในลำดับการเคลื่อนไหว 120 เฟรม ประมวลผลภาพล่วงหน้า ใช้ [image-to-image] เพื่อสร้างพื้นที่ที่มีปัญหาใหม่ในขณะที่รักษาองค์ประกอบที่เหลือไว้ สำหรับข้อบกพร่องที่รุนแรง (เช่น รูปร่างมนุษย์ที่ผิดรูปเรขาคณิตที่ไม่สมจริง) ให้สร้างภาพใหม่ทั้งหมดโดยใช้คำแนะนำที่ปรับเปลี่ยนเพื่อหลีกเลี่ยงปัญหา องค์ประกอบที่มักเกิดข้อบกพร่อง ได้แก่ มือ (ระบุให้ชัดเจนว่า "มือวางไว้ข้างลำตัว" หรือ "มืออยู่ในกระเป๋า" เพื่อหลีกเลี่ยงท่าทางนิ้วที่ซับซ้อน), ข้อความ (หลีกเลี่ยงการใส่ข้อความในภาพที่สร้างขึ้น) และเงาสะท้อน (ให้ลดความซับซ้อนของพื้นผิวที่สะท้อนแสงในคำแนะนำ) ให้ดำเนินการผลิตวิดีโอได้ก็ต่อเมื่อภาพนั้นสมบูรณ์แบบแล้วเท่านั้น
เริ่มสร้างกระบวนการสร้างสรรค์ของคุณ
กระบวนการสามขั้นตอน—คำสั่ง → ภาพ → วิดีโอ—ยังคงเป็นวิธีที่น่าเชื่อถือที่สุดในการผลิตวิดีโอ AI คุณภาพสูงในปี 2026 มันแยกการควบคุมสร้างสรรค์ที่คุณต้องการ (ฉากควรปรากฏอย่างไร) จากความสามารถในการสร้างที่คุณปรารถนา (ฉากควรเคลื่อนไหวอย่างไร) ทำให้ได้วิดีโอที่สอดคล้องกับวิสัยทัศน์ของคุณแทนที่จะเป็นการคาดเดาแบบสุ่มจาก AI
วิดีโอที่ดีทุกชิ้นเริ่มต้นด้วยภาพที่ดี ภาพที่ดีทุกภาพเริ่มต้นด้วยคำแนะนำที่ดี หากวางรากฐานไว้ดี ทุกอย่างจะดำเนินไปอย่างราบรื่นตามธรรมชาติ
ขั้นตอนที่หนึ่ง: สร้างข้อความแนะนำ → — เปลี่ยนแนวคิดให้กลายเป็นข้อความแนะนำสำหรับสร้างภาพระดับมืออาชีพด้วยเครื่องมือสร้างข้อความแนะนำ AI ของ Seedance
ขั้นตอนที่สอง: สร้างภาพ → — สร้างและปรับปรุงเฟรมเปิดที่สมบูรณ์แบบสำหรับวิดีโอของคุณอย่างต่อเนื่อง
ขั้นตอนที่สาม: สร้างวิดีโอ → — เปลี่ยนภาพนิ่งให้กลายเป็นวิดีโอที่มีชีวิตชีวา พร้อมการเคลื่อนไหว มุมกล้อง และบรรยากาศที่สมจริง
การควบคุมเทคนิคเฟรมแรก → — ควบคุมการสร้างวิดีโอ AI ของคุณด้วยการเรียนรู้วิธีการออกแบบเฟรมอ้างอิง
อ่านเพิ่มเติม: คู่มือ AI สร้างวิดีโอจากภาพ | คู่มือออกแบบเฟรมแรกและเฟรมสุดท้าย | คู่มือ AI สร้างภาพจากข้อความฉบับสมบูรณ์ | คู่มือ AI สร้างภาพจากภาพ | คู่มือสร้างข้อความคำสั่ง AI สำหรับภาพ | เครื่องมือสร้างภาพ AI ยอดเยี่ยมปี 2026 | เครื่องมือสร้างวิดีโอ AI ที่ดีที่สุดสำหรับปี 2026*
