
Abstract
L'intelligenza artificiale Image-to-Video utilizza una tecnologia di deep learning basata su modelli di diffusione per trasformare immagini statiche in video dinamici. A differenza della generazione puramente da testo a video, è sufficiente caricare una fotografia affinché l'intelligenza artificiale generi movimenti realistici, movimenti di macchina e filmati temporalmente coerenti attorno ad essa, garantendo un controllo più preciso sul risultato finale. Questa guida tratterà in modo esaustivo: i principi tecnici alla base dell'IA Image-to-Video; quali tipi di immagini producono risultati ottimali; un tutorial in cinque passaggi per creare il tuo primo video da zero; otto casi d'uso pratici con esempi immediati; tecniche avanzate di controllo del movimento; e un confronto reale tra i principali strumenti del 2026 (compresi quelli direttamente accessibili in Cina). Prova gratuitamente l'IA Image-to-Video -->
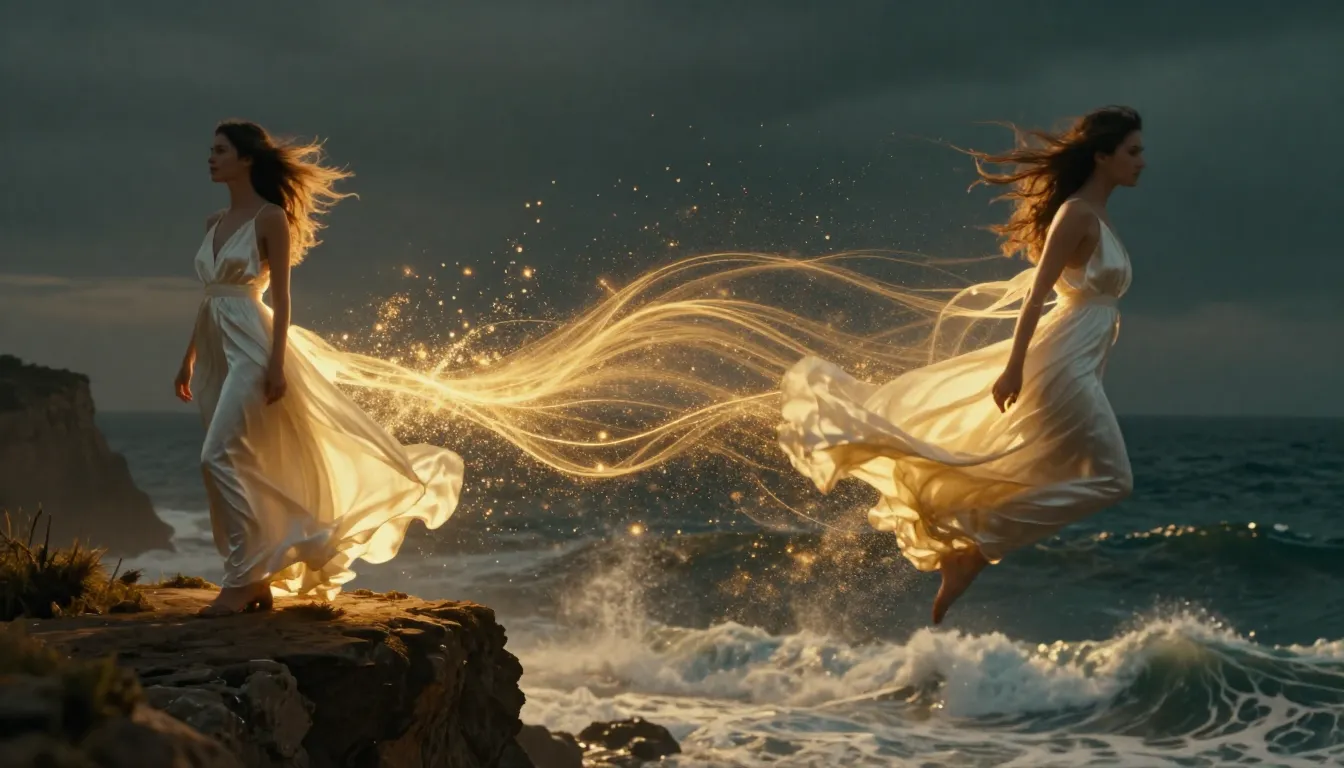
TuSheng Video AI prende le tue fotografie e genera movimenti realistici, movimenti di macchina cinematografici e continuità temporale, trasformando un singolo fotogramma in un videoclip cinematografico.
Che cos'è Tusheng Video AI?
L'intelligenza artificiale Image-to-Video è una tecnologia di intelligenza artificiale in grado di generare video da immagini statiche. È sufficiente fornire una fotografia, che sia un ritratto, l'immagine di un prodotto, un paesaggio o un'opera d'arte, e il modello di intelligenza artificiale produrrà un breve video in cui gli elementi iniziano a muoversi, la telecamera cambia prospettiva e l'intera scena prende vita.
Fondamentalmente, la maggior parte dei sistemi video generativi utilizza modelli di diffusione video. Queste reti neurali vengono addestrate su milioni di coppie di dati video-immagine, apprendendo le relazioni statistiche tra fotogrammi statici e movimenti naturali successivi. Quando viene presentata una nuova immagine, il modello prevede quale movimento appare più naturale e genera una sequenza continua di fotogrammi che passa fluidamente dalla fotografia originale.
Differenze rispetto al testo-video
Text-to-Video genera contenuti interamente dal testo. L'IA crea contemporaneamente sia contenuti visivi che movimenti basati sul testo fornito dall'utente: un processo potente ma imprevedibile, poiché l'IA determina in modo indipendente l'aspetto dei soggetti, la composizione delle scene e tutti i modelli di movimento.
Tusheng Video ribalta questa logica: sei tu a fornire l'ancora visiva. L'IA sa già come appare la scena, perché gliel'hai mostrata direttamente. Il suo unico compito è generare un movimento plausibile. Ciò significa che:
- Maggiore controllo: le immagini definiscono il soggetto, la composizione, la tavolozza dei colori e lo stile
- Meno congetture: l'IA non richiede l'interpretazione di descrizioni testuali vaghe
- Maggiore coerenza: i risultati corrispondono fedelmente all'immagine di partenza
- Iterazioni più rapide: regolare il prompt di movimento è molto più semplice che riscrivere l'intera descrizione della scena.
Perché il video TuSheng è così importante nel 2026
TuSheng Video AI si è evoluto da un giocattolo sperimentale a uno strumento produttivo. I marchi di e-commerce trasformano le immagini dei prodotti in pubblicità animate, i creatori di contenuti danno vita ai loro post più popolari, gli agenti immobiliari producono video di visita virtuale dalle foto degli immobili e gli educatori animano le illustrazioni dei libri di testo.
Questa tecnologia ha raggiunto un punto di svolta: i video da 5 a 15 secondi generati da immagini sorgente di alta qualità sono ormai praticamente indistinguibili dalle riprese tradizionali nella maggior parte dei casi. Questo è proprio il motivo per cui la conversione da immagine a video è diventata la categoria in più rapida crescita nell'ambito della generazione di video basata sull'intelligenza artificiale.
Questa tendenza è particolarmente marcata nel mercato cinese. Gli algoritmi su piattaforme come Douyin, Xiaohongshu, Bilibili e Kuaishou favoriscono fortemente i contenuti video, creando una domanda senza precedenti tra i creatori di contenuti per soluzioni che consentano di convertire rapidamente le fotografie in video. Tusheng Video AI risponde proprio a questa lacuna nel mercato.
Principi tecnici dell'intelligenza artificiale video Tusheng
Comprendere il processo tecnico ti aiuta a ottenere risultati migliori. Quando sai perché l'IA si comporta in un certo modo, puoi fornire input migliori e scrivere prompt più efficaci. Ecco il processo in quattro fasi che avviene dietro le quinte.

Le quattro fasi della pipeline di elaborazione AI di Tusheng Video: codifica delle immagini, previsione del movimento, generazione dei fotogrammi e livellamento temporale.
Fase uno: codifica delle immagini
L'IA analizza innanzitutto l'immagine inserita attraverso una rete di codificatori, comprimendola in una rappresentazione matematica densa nota come vettore latente. Questo processo può essere inteso come l'estrazione da parte dell'IA di una "impronta digitale" dell'immagine, che ne cattura la struttura, il colore, la profondità, il posizionamento del soggetto, la direzione dell'illuminazione e le informazioni semantiche.
Questa rappresentazione latente è notevolmente più compatta rispetto ai dati pixel originali, rendendo fattibili i calcoli successivi. La qualità della codifica influenza direttamente i risultati finali. Immagini di input con risoluzione più elevata e maggiore nitidezza generano rappresentazioni latenti più ricche, producendo in ultima analisi un output video di qualità superiore.
Fase due: previsione del movimento
Questo è il nucleo creativo dell'intero processo. Il modello di diffusione prevede quale tipo di movimento risulterebbe naturale in base all'immagine originale, tenendo conto di:
- Contesto scenico: una fotografia dell'oceano implica che le onde dovrebbero infrangersi; un ritratto suggerisce un movimento sottile del viso
- Informazioni sulla profondità: gli oggetti più vicini all'obiettivo possono mostrare modelli di movimento diversi rispetto agli oggetti distanti
- Realismo fisico: i capelli dovrebbero fluttuare al vento, l'acqua dovrebbe scorrere verso il basso e il tessuto dovrebbe drappeggiarsi in modo naturale
- Il tuo testo di prompt: se specifichi "panoramica lenta verso sinistra", il modello regolerà la sua previsione di movimento di conseguenza
Il modello non si limita a distorcere i pixel. Genera contenuti visivi completamente nuovi per le aree appena esposte dal movimento della telecamera o dell'oggetto. Se la telecamera effettua una panoramica verso destra, il modello "riempirà" la scena oltre il bordo destro dell'immagine originale.
Fase tre: generazione del frame
Basandosi sulla previsione del movimento, il modello genera una sequenza di fotogrammi video. Ogni fotogramma viene prodotto attraverso un processo di diffusione inversa: partendo dal rumore, si affina progressivamente fino a diventare un'immagine chiara, mantenendo la coerenza con il fotogramma precedente e l'immagine originale.
Seedance 2.0 e altri modelli moderni generano frame rate elevati (24-30 fps) mantenendo la coerenza sub-pixel tra i fotogrammi. Ciò garantisce un output fluido e privo di sfarfallio, senza i problemi di juddering comuni ai sistemi precedenti.
Fase quattro: livellamento temporale
Il passaggio finale garantisce transizioni fluide tra tutti i fotogrammi generati. Il meccanismo di attenzione temporale verifica che la luminosità, il colore e il movimento rimangano coerenti durante l'intero video, prevenendo comuni artefatti visivi:
- Improvvisi cambiamenti di colore tra i fotogrammi
- Apparizione o scomparsa inaspettata di oggetti
- Accelerazione o decelerazione innaturale del movimento
- Sfarfallio della texture della superficie
Il risultato finale è un video raffinato che scorre in modo naturale dalle riprese originali.
Perché alcune immagini hanno un aspetto migliore?
Ora puoi capire perché la qualità dell'immagine in ingresso è così importante. Un'immagine sfocata e a bassa risoluzione produce una codifica latente rumorosa nella prima fase, fornendo meno informazioni al modello di previsione del movimento (la seconda fase). Ciò si traduce in un movimento meno preciso e in un maggior numero di artefatti visivi nell'output finale. Al contrario, un'immagine nitida e ben composta con chiari indizi di profondità fornisce al modello informazioni ricche, che si traducono in un video più naturale e di qualità superiore.
Quale tipo di immagine offre i risultati migliori?
Non tutte le immagini sono adatte a Tusheng Video AI. La differenza tra materiale di partenza di buona qualità e materiale di scarsa qualità può essere il divario tra un video straordinario e una pila di filmati inutilizzabili. Ecco una guida pratica.

Il lato sinistro mostra immagini sorgente adeguate (ad alta risoluzione, ben composte, che suggeriscono un movimento naturale), mentre il lato destro mostra immagini sorgente inadeguate (sfocate, disordinate, contenenti elementi difficili da elaborare per l'IA).
Tipi di immagini adatti
Alta risoluzione (1024x1024 o superiore). Un numero maggiore di pixel consente all'encoder di estrarre maggiori dettagli. Utilizzare sempre la versione con la risoluzione più alta disponibile. Minimo consigliato: 512x512 pixel. Ideale: 1024x1024 o superiore.
Soggetti chiaramente definiti, contorni nettamente delineati. L'IA deve distinguere ciò che deve muoversi da ciò che deve rimanere statico. Un ritratto in cui il soggetto è nettamente separato dallo sfondo produce risultati di gran lunga superiori rispetto a una scena di gruppo complessa e caotica.
Ben illuminate e correttamente esposte. Le immagini con una buona illuminazione forniscono informazioni accurate sul colore e sulla profondità del modello. Evita immagini fortemente sovraesposte o sottoesposte.
Stratificazione e composizione naturali. Le immagini con primo piano, piano intermedio e sfondo ben distinti forniscono all'IA indicazioni di profondità, migliorando il realismo degli effetti di parallasse e dei movimenti della telecamera.
Immagini che suggeriscono il movimento. Gli indizi visivi del movimento (capelli mossi dal vento, onde che stanno per infrangersi sulla riva, una figura che avanza a grandi passi) forniscono al modello potenti punti di partenza per prevedere il movimento. L'intelligenza artificiale è in grado di discernere "cosa succederà dopo" da questi indicatori visivi.
Sfondi puliti. Uno sfondo minimalista o naturalmente sfocato produce un video più fluido rispetto a uno sfondo disordinato e pieno di numerosi piccoli oggetti.
Tipi di immagini che potrebbero causare problemi
Immagini sfocate o fuori fuoco. Sfocatura in ingresso, sfocatura in uscita. L'intelligenza artificiale non può aggiungere nitidezza che non era presente nell'immagine originale.
Scene eccessivamente complesse. Le immagini che contengono numerosi soggetti di piccole dimensioni, motivi intricati o elementi visivi disordinati possono sovraccaricare i modelli di previsione del movimento, rendendoli incapaci di determinare cosa dovrebbe muoversi e in che modo.
Testi o tipografia estesi. I modelli video basati sull'intelligenza artificiale hanno ancora difficoltà a mantenere la leggibilità del testo tra i fotogrammi. Se le immagini contengono loghi, marchi o sovrapposizioni di testo, potrebbero verificarsi distorsioni nell'output video.
Bassa risoluzione (512x512 o inferiore). Le immagini di piccole dimensioni contengono informazioni insufficienti. Anche ingrandirle con l'AI prima dell'inserimento si rivela inutile: aggiunge pixel ma non informazioni.
Filtri pesanti o post-elaborazione. Regolazioni estreme dei colori, elaborazione HDR o modifiche estese con Photoshop possono confondere la comprensione della modella dell'illuminazione e della profondità.
Volti multipli di dimensioni diverse. L'intelligenza artificiale gestisce efficacemente i ritratti singoli. Le foto di gruppo con volti a distanze diverse producono animazioni incoerenti: alcuni volti appaiono naturali, mentre altri risultano distorti.
Lista di controllo pre-caricamento
Prima di caricare le immagini, controlla rapidamente i seguenti punti:
- Risoluzione minima di 1024x1024 pixel
- Soggetto chiaramente definito con netta separazione dallo sfondo
- Esposizione corretta (né sottoesposta né sovraesposta)
- Nessun filtro pesante, HDR estremo o tracce di elaborazione artificiale
- Testo, loghi o elementi tipografici minimi
- Complessità della scena controllata (1-3 soggetti principali)
- Formato immagine: JPG, PNG o WebP
Una volta soddisfatte queste condizioni, è possibile avviare la generazione.
Guida passo passo: crea il tuo primo video da immagine
Segui questi cinque passaggi per trasformare qualsiasi immagine statica in un video animato con l'aiuto dell'intelligenza artificiale. Useremo Seedance come piattaforma dimostrativa, anche se questi principi si applicano a qualsiasi strumento di conversione da immagine a video.
Fase uno: selezione delle immagini sorgente adeguate
L'immagine sorgente è il fattore più importante per la qualità del risultato finale. Scegli un'immagine che rispetti le linee guida che abbiamo visto prima. Per il tuo primo tentativo, ti consiglio di scegliere un ritratto semplice o un paesaggio con una profondità evidente: questi due tipi di immagini danno i risultati più uniformi.
Immagini consigliate per i primi tentativi:
- Ritratto chiaro a mezzo busto o a figura intera con illuminazione favorevole
- Paesaggi con cielo, specchi d'acqua o vegetazione (questi elementi possiedono un movimento intrinseco)
- Immagini di prodotti su sfondi puliti
- Opere d'arte o illustrazioni con elementi chiaramente distinguibili
Quando si genera per la prima volta, evitare di utilizzare immagini composite complesse, immagini contenenti grandi quantità di testo o fotografie pesantemente modificate.
Fase due: Caricare su Seedance
Apri Seedance Image-to-Video e carica le immagini selezionate. Seedance supporta i formati JPG, PNG e WebP. La piattaforma analizzerà automaticamente le immagini e le preparerà per la generazione.
Se un'immagine è particolarmente grande (con uno dei lati superiore a 4096 pixel), il sistema ne ridimensionerà automaticamente le proporzioni, eliminando la necessità di una regolazione manuale.
Fase tre: Creazione di un prompt orientato al movimento
In questa fase, comunichi all'IA il movimento desiderato. Il tuo prompt dovrebbe descrivere la dinamica piuttosto che il contenuto dell'immagine (l'IA ha già visto l'immagine). Concentrati sui seguenti punti:
- Movimento del soggetto: cosa dovrebbe fare il soggetto?
- Movimento della telecamera: come dovrebbe muoversi la telecamera?
- Movimento dell'ambiente: quali dinamiche ambientali dovrebbero essere presenti?
- Ritmo e atmosfera: tempo generale – veloce o lento?
Esempi di suggerimenti per i ritratti:
The woman slowly turns her head to the right and smiles softly.
A gentle breeze moves her hair. Background slightly out of focus
with subtle bokeh movement. Camera slowly pushes in from medium
shot to a close-up. Warm, natural lighting. Cinematic film quality.Esempio di prompt paesaggistico:
Gentle waves roll toward the shore in slow motion. Clouds drift
slowly across the sky from left to right. Sunlight shimmers on
the water surface. Camera slowly pans right, revealing more of
the coastline. Peaceful, serene atmosphere. 4K cinematic quality.Esempio di suggerimento sul prodotto:
The camera slowly orbits around the product, rotating 45 degrees
clockwise. Soft studio lighting with subtle caustic reflections
on the surface. Clean white background with gentle gradient.
Premium commercial aesthetic. Smooth, steady camera movement.Principio fondamentale: Descrivi il movimento, non la scena. La scena esiste già all'interno della tua immagine.
Nota: Seedance supporta sia i comandi in cinese che in inglese, anche se quelli in inglese consentono in genere un controllo più preciso dei movimenti della telecamera. Si consiglia di utilizzare l'inglese per le descrizioni relative al movimento e alla telecamera, mentre il cinese può essere utilizzato per le descrizioni atmosferiche e stilistiche.
Fase quattro: selezionare i parametri
Configura le impostazioni di generazione:
| Parametro | Valore consigliato | Descrizione |
|---|---|---|
| Modello | Seedance 2.0 | Qualità dell'immagine ottimale per la generazione di immagini in video |
| Durata | 5 secondi (per le prove iniziali) | Inizia con una durata breve, poi allunga; genera versioni estese quando sei soddisfatto |
| Proporzioni | Corrispondenti all'immagine | 16:9 per orizzontale, 9:16 per verticale, 1:1 per quadrato |
| Risoluzione | 1080p | Seleziona sempre la risoluzione più alta disponibile |
Tecnica avanzata: generare innanzitutto una versione di 5 secondi. Se il movimento e lo stile sono soddisfacenti, utilizzare lo stesso prompt per generare una versione più lunga (8-15 secondi). Questo approccio consente di risparmiare crediti durante la fase di esplorazione.
Fase cinque: generare, controllare, iterare
Clicca su Genera e attendi 1-3 minuti. Una volta visualizzati i risultati, valutali in base ai seguenti criteri:
- Il movimento è fluido e naturale?
- Il soggetto mantiene una coerenza visiva per tutta la durata del video?
- Il movimento della telecamera è in linea con le tue aspettative?
- Ci sono imperfezioni visive (sfarfallio, distorsione, deformazione)?
- La qualità del video corrisponde a quella del filmato originale?
Se qualche aspetto risulta insoddisfacente, modificare il prompt e rigenerare. I metodi di regolazione più comuni includono:
- Troppo veloce? Aggiungi "lentamente", "delicatamente", "gradualmente" alla descrizione del movimento
- Direzione della telecamera sbagliata? ** Specifica più chiaramente: "telecamera statica, nessun movimento della telecamera" o "dolly lento"
- Imperfezioni facciali? Semplifica il movimento: riduci il numero di azioni eseguite contemporaneamente
- **Mancanza di dinamismo? ** Introduci verbi dinamici: "ondeggiare", "scorrere", "fluttuare", "spostarsi"
Dopo due o tre cicli di iterazione, otterrai un video di alta qualità che darà vita alle tue immagini.
Inizia subito a creare il tuo primo clip da immagine a video -->
8 principali applicazioni ed esempi di conversione su larga scala da immagine a video
TuSheng Video AI non è un prodotto monouso. È utile per decine di scopi creativi e commerciali. Di seguito sono riportati otto scenari applicativi di alto valore, completi di suggerimenti pratici pronti per essere copiati e modificati direttamente.
- Animazione ritratto
Dai vita alle tue foto. Portrait Animation è l'app più popolare per trasformare le foto in video. Carica una foto del profilo, un selfie o l'immagine di un personaggio, quindi aggiungi animazioni sottili e realistiche: respirazione, battito delle palpebre, rotazione della testa, cambiamento delle espressioni e movimento dei capelli.
Adatto per video commemorativi, contenuti sui social media, creazione di avatar virtuali e narrazione creativa. Su Douyin e Xiaohongshu, i contenuti "le foto prendono vita" rimangono un punto di riferimento costante per il traffico.

Un ritratto statico si trasforma in un video realistico: battiti di ciglia naturali, movimenti sottili della testa e capelli che fluttuano, l'effetto è sorprendentemente realistico.
Esempio di prompt:
The person looks directly at the camera with a calm, confident
expression. They slowly tilt their head slightly to the left and
give a subtle warm smile. Eyes blink naturally. A soft breeze gently
moves their hair. Shallow depth of field with softly blurred
background. Warm natural lighting. Cinematic portrait quality.- Vetrina dei prodotti
Trasforma le fotografie dei prodotti in contenuti commerciali dinamici. Si tratta di una rivoluzione per i marchi di e-commerce e gli influencer: possiedi già centinaia o addirittura migliaia di immagini dei prodotti e ora ognuna di esse può diventare un video pubblicitario, un'immagine chiave per le pagine di dettaglio dei prodotti o un cortometraggio per i social media.
Nelle pagine dei dettagli dei prodotti su Taobao e JD.com, nelle presentazioni dei prodotti in diretta streaming su Douyin e nei post di raccomandazione dei prodotti su Xiaohongshu, le visualizzazioni dinamiche dei prodotti ottengono costantemente tassi di conversione significativamente più elevati rispetto alle immagini statiche.

Un'immagine standard di prodotto viene elevata alla raffinatezza di una pubblicità commerciale di alta qualità, con panoramiche della telecamera, illuminazione drammatica e movimenti fluidi, una produzione tradizionale che potrebbe costare centinaia o migliaia di sterline.
Esempio di prompt:
The camera slowly orbits 90 degrees around the product, revealing
its form from multiple angles. Soft directional studio lighting
with subtle caustic reflections on the surface. A gentle highlight
sweep moves across the product. Clean, premium commercial aesthetic.
Shallow depth of field. Ultra-smooth camera movement. 4K quality.3. Time-lapse paesaggistico
Trasforma le fotografie paesaggistiche in suggestivi video in stile time-lapse. Le nuvole attraversano il cielo, l'acqua scorre, la luce passa dal dorato al blu e le foglie ondeggiano nella brezza. Ideale per contenuti di viaggio, presentazioni aeree di proprietà immobiliari e suggestive riprese B-roll.
I fotografi paesaggisti e i vlogger di viaggi su Bilibili possono trasformare direttamente le loro fotografie selezionate in affascinanti video time-lapse, riducendo significativamente i costi di produzione.

Una fotografia paesaggistica trasformata in un time-lapse cinematografico: nuvole che scorrono, acqua ondulata, luci e ombre mutevoli, creando un effetto dinamico e suggestivo da una singola immagine statica.
Esempio di prompt:
Time-lapse effect. Clouds move steadily across the sky from left
to right. Water in the foreground ripples and flows gently. Light
shifts subtly as if the sun is moving, creating slowly changing
shadows on the landscape. Trees and grass sway gently in the wind.
Camera remains static on a tripod. Serene, majestic atmosphere.
Cinematic landscape quality.4. Contenuti dei social media
Trasforma i tuoi post statici più performanti in contenuti video che inducono le persone a interrompere lo scorrimento. Gli algoritmi su piattaforme come TikTok, Xiaohongshu, Bilibili e Kuaishou favoriscono fortemente i contenuti video: un post con immagini altamente performante ottiene quasi sempre un traffico migliore quando viene convertito in video.
Per i creatori di contenuti Xiaohongshu, una serie di post con immagini e testo può vedere la propria visibilità aumentare da 3 a 5 volte se accompagnata da una versione video. Douyin e Kuaishou, tuttavia, operano interamente con i video come formato di contenuto principale.
Esempio di prompt:
Dynamic, attention-grabbing motion. The subject moves confidently
toward the camera with energy and presence. Background elements
shift with parallax depth effect. Quick, punchy camera push-in
that creates impact. Vibrant colors, high contrast. Bold,
eye-catching aesthetic optimized for social media. Vertical 9:16.- Animazione artistica e illustrativa
Dai vita a opere d'arte, illustrazioni, dipinti digitali e progetti grafici. Questo scenario applicativo è molto apprezzato da artisti, game designer e team creativi che desiderano mostrare il proprio lavoro in modo più coinvolgente.
All'interno delle comunità artistiche e anime di Bilibili e Xiaohongshu, le illustrazioni animate sono considerate contenuti altamente coinvolgenti. Trasformare le opere d'arte statiche in video in stile "sfondo animato" spesso produce un numero di condivisioni e salvataggi significativamente più elevato rispetto alle immagini originali.
Esempio di prompt:
The illustrated scene comes to life with gentle, painterly motion.
Characters move subtly within their positions -- breathing, shifting
weight, small gestures. Background elements like leaves, clouds,
or particles drift slowly. The artistic style is preserved exactly
as painted. Movement is smooth and dreamlike, like a living painting.
Gentle ambient lighting shifts. Fantasy illustration quality.6. Visite virtuali degli immobili
Trasforma le fotografie degli immobili in video di visualizzazione virtuale. Gli agenti immobiliari possono creare anteprime coinvolgenti utilizzando le immagini esistenti degli immobili, eliminando la necessità di organizzare visite da parte di team di fotografi specializzati.
Per gli annunci immobiliari visualizzati su piattaforme come Beike e Anjuke, così come per le promozioni immobiliari nei feed dei social media e su Xiaohongshu, i video di visualizzazione dinamica dimostrano un tasso di conversione significativamente più elevato per le richieste dei clienti.
Esempio di prompt:
Smooth virtual walkthrough. The camera glides forward slowly into
the room, revealing the space with a wide-angle perspective.
Natural daylight streams through the windows, casting soft shadows.
Subtle dust particles float in the sunbeams. The camera pans
gently to the left, showing the full room layout. Clean, bright,
aspirational real estate aesthetic. Steady, professional movement.- Sfilata di moda e styling
Crea contenuti di moda dinamici dalle foto degli outfit in studio. Le modelle si muovono, i tessuti cadono in modo naturale, mentre lo stile estetico di livello editoriale viene preservato.
I fashion blogger di Xiaohongshu e i venditori di abbigliamento su Taobao possono convertire grandi quantità di foto di modelli esistenti e immagini di outfit in formato flat lay in video dinamici, creando una presenza visivamente più accattivante all'interno dei feed informativi.
Esempio di prompt:
The model strikes a confident pose and then slowly shifts their
weight, creating natural body movement. Fabric of the outfit
flows and catches the light with each subtle motion. Wind effect
gently moves the hair. Camera starts at full body and slowly drifts
upward to a waist-up shot. High-fashion editorial lighting with
strong directional shadows. Vogue magazine aesthetic. Cinematic
slow motion.- Contenuti didattici e esplicativi
Trasforma grafici statici, infografiche e illustrazioni didattiche in presentazioni dinamiche. I concetti complessi diventano più facili da comprendere quando vengono messi in movimento.
I creatori della Knowledge Zone di Bilibili e di varie piattaforme educative possono trasformare materiale didattico, diagrammi e diagrammi di flusso in risorse video animate, migliorando significativamente l'efficacia dell'insegnamento e i tassi di fidelizzazione degli spettatori.
Esempio di prompt:
The diagram elements animate sequentially. Arrows begin to flow
in their indicated directions. Labels fade in one by one. Moving
parts of the system activate in logical order, showing the process
step by step. Smooth transitions between stages. Clean, clear
educational style. Elements highlight with subtle glow as they
become active. Professional presentation quality.Guida completa alle tecniche di prompt per Tusheng Video
Un prompt ben strutturato è la tecnica più efficace per generare immagini a partire da fotografie. Poiché l'IA ha già visto la tua immagine, il prompt dovrebbe concentrarsi interamente sul movimento e sul dinamismo. Ecco alcune tecniche che garantiscono i migliori risultati.
Guida rapida alle parole chiave sportive
Utilizza queste parole chiave specifiche per controllare con precisione il movimento del video.
| Tipo di movimento | Parole chiave | Effetto | |-------- -|-------|------| | Obiettivo: in avanti | carrellata in avanti, zoom avanti, avvicinamento, avvicinarsi | L'obiettivo si sposta verso il soggetto | | Obiettivo: indietro | carrellata indietro, zoom indietro, allontanamento, allargamento | L'obiettivo si allontana dal soggetto | | Ripresa: sinistra/destra | panoramica a sinistra, panoramica a destra, tracciamento a sinistra, tracciamento a destra | La telecamera ruota o traccia orizzontalmente | | Ripresa: su/giù | inclinazione verso l'alto, inclinazione verso il basso, gru verso l'alto, gru verso il basso | La telecamera ruota o si sposta verticalmente | | Ripresa: Orbita | orbita, rotazione, rotazione intorno, arco | La telecamera gira intorno al soggetto | | Telecamera: Zoom | zoom avanti, zoom indietro, spostamento della lunghezza focale | La telecamera esegue uno zoom (senza spostamento) | | Soggetto: Micro-movimenti | respirazione, battito di ciglia, spostamento del peso, micro-movimenti | Movimenti sottili e realistici | | Soggetto: moderato | girare la testa, sorridere, gesticolare, camminare lentamente | Movimenti chiari ma controllati | | Soggetto: dinamico | correre, saltare, ballare, girare, salutare con la mano | Movimenti energici di tutto il corpo | | Ambiente: Delicato | brezza, deriva, oscillazione, increspatura, luccichio | Movimento ambientale morbido | | Ambiente: Intenso | soffio, impeto, schianto, vortice, cascata | Dinamica ambientale vigorosa | | Parallasse | parallasse, spostamento di profondità, movimento degli strati | Primo piano/sfondo che si muovono a velocità diverse |

Diverse parole chiave relative al movimento della telecamera producono effetti completamente diversi. Scegliete con attenzione la tecnica di movimento della telecamera in base al risultato desiderato.
Controllo della velocità e del tempo
Il ritmo del movimento ha un effetto profondo sul tono emotivo di un video. Utilizza i seguenti modificatori:
- Estremamente lento: "appena percettibile", "ultra-slow motion", "ritmo glaciale" — drammatico, contemplativo
- Lento: "lentamente", "delicatamente", "gradualmente", "con calma" — eleganza, qualità cinematografica
- Velocità media: "costante", "ritmo naturale", "alla velocità di una passeggiata" — realismo, stile documentaristico
- Velocità elevata: " rapidamente", "bruscamente", "energicamente", "veloce" — dinamico, esaltante
- Estremamente veloce: "rapido", "panoramica veloce", "taglio rapido", "esplosione di movimento" — teso, ricco di azione
Tecnica avanzata: utilizzare il rallentatore come impostazione predefinita. Nei video generati dall'intelligenza artificiale, il rallentatore offre quasi sempre risultati migliori rispetto all'acceleratore. I movimenti rapidi aumentano il rischio di imperfezioni e incongruenze visive.
Controllo indipendente del movimento dello sfondo e del soggetto
È possibile controllare in modo indipendente ciò che si muove e ciò che rimane immobile. Si tratta di una tecnica potente per dirigere l'attenzione del pubblico.
Soggetto in movimento, sfondo fermo:
The person walks forward confidently while the background remains
perfectly still. Static camera, no camera movement. Focus entirely
on the subject's motion.Sfondo dinamico, soggetto statico:
The person stands completely still, like a statue. Behind them,
clouds drift across the sky, leaves blow in the wind, and city
lights flicker. Only the environment moves.Movimenti separati da entrambe le parti:
The person slowly turns their head while the camera simultaneously
dollies in. Background clouds drift in the opposite direction,
creating a sense of depth and dimension.La differenza tra movimento della telecamera e movimento dell'oggetto
Comprendere la differenza tra il movimento della telecamera e il movimento dell'oggetto è fondamentale per ottenere l'effetto desiderato.
Il movimento della telecamera altera la prospettiva e la composizione. La scena rimane fissa, mentre cambia il punto di vista. Utilizzato per: rivelare l'inquadratura, definire la scena e creare enfasi drammatica.
Il movimento degli oggetti si riferisce al movimento degli elementi all'interno di una scena mentre la telecamera rimane fissa. Viene utilizzato per: animazione dei personaggi, dimostrazioni di prodotti e dinamiche dell'ambiente naturale.
Il movimento combinato impiega entrambe le tecniche contemporaneamente. Questo approccio produce i risultati più cinematografici, ma risulta anche il più difficile da eseguire efficacemente per l'IA. È consigliabile padroneggiare prima un solo tipo di movimento e introdurre l'altro solo quando si è soddisfatti del risultato.
Strutture di prompt avanzate
Per ottenere risultati più prevedibili, organizza i tuoi suggerimenti nel seguente ordine:
- Azione primaria — Cosa fa il soggetto principale
- Movimento della telecamera — Come si muove la telecamera
- Dinamiche ambientali — Cosa fanno gli elementi ambientali
- Velocità/Ritmo — Il tempo di tutti i movimenti
- Atmosfera/Stato d'animo — Tono emotivo
- Miglioramento della qualità visiva — Descrizione tecnica della qualità visiva
Esempio di utilizzo di questa struttura:
[Subject] A young woman in a flowing white dress slowly raises
her hand to brush hair from her face.
[Camera] The camera executes a slow, steady dolly in from a
medium shot to a close-up.
[Environment] Cherry blossom petals drift gently through the
air. Soft golden sunlight filters through the trees.
[Speed] All motion is slow and deliberate, almost dreamlike.
[Mood] Romantic, ethereal, peaceful atmosphere.
[Quality] Cinematic shallow depth of field, anamorphic bokeh,
film grain, 4K quality.Confronto tra strumenti di intelligenza artificiale per video TuSheng 2026
La concorrenza nel settore dello streaming video si sta intensificando. Di seguito è riportata un'analisi comparativa delle principali piattaforme al febbraio 2026, con particolare attenzione all'accessibilità per gli utenti della Cina continentale.

I risultati dell'elaborazione della stessa immagine sorgente su cinque diverse piattaforme di generazione video. Le differenze in termini di qualità del movimento, coerenza temporale e fedeltà visiva sono immediatamente evidenti.
| Caratteristica | Seedance 2.0 | Runway Gen-4 | Pika 2.0 | Kling 3.0 | Luma Dream Machine | |------|-------------|-------------|---------|------ ----------|-------------------| | Risoluzione massima | 2K (2048x1080) | 4K (upscaled) | 1080p | 1080p | 1080p | | Durata massima | 15 secondi | 10 secondi | 5 secondi | 2 minuti | 5 secondi | | Opzioni di input | Immagine + Testo + Video + Audio | Immagine + Testo + Video | Immagine + Testo | Immagine + Testo | Immagine + Testo | | Input multi-immagine | Supportato (fino a 9 immagini) | Non supportato | Non supportato | Non supportato | Non supportato | | Audio nativo | Supportato (8 lingue con sincronizzazione labiale) | Non supportato | Parziale (effetti sonori) | Non supportato | Non supportato | | Controllo della fotocamera | Basato su prompt | Pennello di movimento + Modalità regista | Base | Base | Basato su prompt | | Quota gratuita | Disponibile (Bonus di registrazione) | Disponibile (limitato) | Disponibile (limitato) | Disponibile (limitato) | Disponibile (limitato) | | Prezzo di partenza | ~9,90 $/mese | 15 $/mese | 10 $/mese | ~6,99 $/mese | 9,99 $/mese | | Accesso dalla Cina continentale | Accesso diretto | VPN richiesta | VPN richiesta | Accesso diretto | VPN richiesta | | Ideale per | Controllo multimodale, qualità dell'immagine | Flusso di lavoro di editing professionale | Principianti, effetti divertenti | Video di lunga durata, alto valore | Effetto cinematografico, scene 3D |
Recensioni dettagliate di ogni strumento
Seedance 2.0 non ha rivali in termini di flessibilità di input. È l'unica piattaforma che supporta il caricamento simultaneo di un massimo di nove immagini di riferimento, la sincronizzazione labiale dell'input audio e la combinazione di tutte le modalità di input in un'unica generazione. Per il massimo controllo sull'output da immagine a video, Seedance offre il toolkit più completo. La sua risoluzione di output 2K è anche la più alta tra tutti gli strumenti (senza ricorrere all'upsampling). Sviluppato da ByteDance (società madre di TikTok), Seedance è direttamente accessibile agli utenti della Cina continentale senza richiedere una VPN o metodi di pagamento esteri.
Runway Gen-4 eccelle nel controllo di precisione. Motion Brush consente di "dipingere" meticolosamente quali parti di un'immagine devono muoversi e in quale direzione. Se avete bisogno di una precisione chirurgica su aree specifiche, Runway è l'opzione più potente. Gli svantaggi sono il prezzo più elevato e le quote di generazione inferiori. L'accesso richiede una VPN all'interno della Cina.
Pika 2.0 è l'opzione più accessibile. Per i principianti che desiderano sperimentare la generazione di immagini in video senza imparare l'ingegneria dei prompt, gli effetti con un solo clic e l'interfaccia semplificata di Pika rappresentano la barriera di ingresso più bassa. Sebbene la qualità dell'immagine non sia all'altezza degli strumenti premium, è sufficiente per i contenuti social occasionali. Richiede una VPN per l'accesso dalla Cina continentale.
Kling 3.0 supera nettamente i suoi concorrenti sia in termini di tempo di esecuzione che di rapporto qualità-prezzo. Se avete bisogno di generare video di lunghezza estesa (30 secondi, 1 minuto o anche 2 minuti) da una singola immagine, Kling è l'unica opzione praticabile. Il suo rapporto qualità-prezzo è eccezionalmente vantaggioso. Il suo limite risiede nelle opzioni di input limitate (singola immagine + testo). Essendo un prodotto del gruppo Kuaishou, Kling è direttamente accessibile nella Cina continentale, offrendo agli utenti nazionali un'altra opzione senza soluzione di continuità.
Luma Dream Machine eccelle nella comprensione spaziale. Per paesaggi, architettura e scene in cui la percezione spaziale tridimensionale è fondamentale, Luma produce i movimenti di parallasse e di telecamera più convincenti. La sua animazione dei personaggi è inferiore rispetto alla concorrenza. L'accesso dall'Italia richiede una VPN.
Raccomandazioni per gli utenti della Cina continentale
Se ti trovi nella Cina continentale, esistono principalmente due strumenti video che possono essere utilizzati direttamente senza una VPN:
- Seedance 2.0 — Sviluppato da ByteDance, completamente funzionante e pronto all'uso, con input multimodale + risoluzione 2K + audio integrato
- Kling 3.0 — Un prodotto di Kuaishou, eccelle nella generazione di video di lunga durata con un ottimo rapporto qualità-prezzo
Sebbene strumenti stranieri come Runway, Pika e Luma abbiano ciascuno le proprie caratteristiche distintive, tutti richiedono un accesso VPN e metodi di pagamento stranieri, il che rappresenta una barriera all'ingresso più elevata.
Per i creatori di contenuti su piattaforme nazionali come Douyin, Xiaohongshu, Bilibili e Kuaishou, optare per strumenti direttamente accessibili all'interno della Cina non solo è più conveniente, ma offre anche maggiori garanzie in termini di stabilità della rete e facilità di pagamento.
Per un confronto più completo (comprese le funzionalità di conversione da testo a video), consulta la nostra Classifica completa dei generatori di video AI per il 2026.
Errori comuni e metodi di correzione
Dopo aver testato migliaia di videoclip, ecco i cinque errori più comuni che abbiamo osservato, insieme alle misure correttive specifiche.
- Utilizza immagini stock a bassa risoluzione
L'errore commesso: caricare un'immagine piccola e compressa (come una miniatura 400x300 salvata da WeChat o dai social media) aspettandosi un video in alta definizione.
Perché non funziona: l'encoder non è in grado di estrarre informazioni visive sufficienti dalle immagini a bassa risoluzione. L'output eredita la sfocatura e sovrappone anche artefatti di movimento.
Come risolvere: utilizzare sempre la versione dell'immagine con la risoluzione più alta. Se sono disponibili solo versioni a bassa risoluzione, utilizzare uno strumento di upscaling AI (come Real-ESRGAN o Topaz Gigapixel) per migliorare la risoluzione prima del caricamento. La dimensione minima consigliata è 1024x1024 pixel.
- Scrivi descrizioni delle scene piuttosto che descrizioni delle azioni
L'errore commesso: scrivere suggerimenti come "La superficie del mare al tramonto, con la luce dorata che brilla sull'acqua". Questo descrive l'aspetto dell'immagine, che l'IA già conosce.
Perché non ha funzionato: l'IA ha già codificato l'immagine. Descrivere nuovamente il contenuto dell'immagine spreca spazio di prompt con informazioni ridondanti e non fornisce alcuna indicazione per il movimento.
Come rivedere: Concentra l'attenzione esclusivamente sul movimento. Riscrivi come segue: "Le onde si infrangono dolcemente sulla riva. La luce dorata del sole brilla sulla superficie dell'acqua. Le nuvole si spostano lentamente da sinistra a destra. La telecamera si sposta lentamente verso destra, seguendo la linea costiera."
- Richiedere troppe azioni da eseguire contemporaneamente
Errori commessi: "Il personaggio gira la testa, saluta con la mano, cammina in avanti, prende una tazza, sorride e balla, mentre la telecamera zoomma, fa una panoramica a sinistra e si inclina".
Perché non funziona: gli attuali modelli di IA non sono in grado di coordinare in modo affidabile più di due o tre azioni simultanee. I prompt sovraccarichi inducono il modello a ignorare la maggior parte delle istruzioni o a produrre risultati confusi e pieni di errori.
Come modificare: Limita ogni generazione a un'azione principale del soggetto più un movimento della telecamera. Per azioni complesse e continue, genera più clip brevi separatamente prima di modificarle e unirle insieme.
- Ignora le discrepanze nelle proporzioni
Errore comune: caricare una foto in formato orizzontale con proporzioni 16:9 ma impostare l'output su verticale 9:16, o viceversa.
Perché non funziona: l'intelligenza artificiale ritaglia drasticamente l'immagine o richiede il riempimento di ampie aree vuote. Nessuno dei due approcci produce risultati soddisfacenti: il ritaglio compromette l'inquadratura accuratamente composta, mentre il riempimento di nuove aree estese introduce incongruenze.
Come risolvere: assicurati che le proporzioni dell'output corrispondano a quelle dell'immagine originale. Usa 16:9 per le immagini orizzontali e 9:16 per quelle verticali. Se hai bisogno di proporzioni diverse, ritaglia l'immagine originale prima di caricarla.
- Aspettarsi un effetto realistico dalle immagini illustrative
L'errore commesso: caricare un'illustrazione cartoon o un'immagine flat design, aspettandosi che l'IA generi un video fotorealistico.
Perché non funziona: il modello cerca di interpretare gli stili artistici, introducendo talvolta un realismo indesiderato. Le illustrazioni piatte mancano della profondità e degli indizi di illuminazione su cui il modello si basa per prevedere i movimenti naturali.
Come risolvere: se il materiale di partenza è un'illustrazione, specifica chiaramente lo stile nel prompt: "Mantieni esattamente lo stile artistico dell'illustrazione. Animazione in stile 2D, non fotorealistica. Il movimento deve sembrare disegnato a mano e pittorico". In questo modo si indica al modello di preservare lo stile artistico piuttosto che introdurre il fotorealismo.
Domande frequenti
Qual è lo strumento di intelligenza artificiale più adatto per generare video dalle immagini?
Seedance 2.0 è la nostra raccomandazione principale per la generazione di immagini in video nel 2026. Supporta input multipli di immagini (fino a 9 immagini di riferimento), output con risoluzione 2K e offre la combinazione più flessibile di immagini, testo, video e audio. Inoltre, sviluppato da ByteDance, Seedance è direttamente accessibile dalla Cina continentale. Per gli utenti attenti al budget, Kling 3.0 offre una qualità dell'immagine eccezionale a un prezzo inferiore ed è anch'esso direttamente accessibile dalla Cina continentale. Per i principianti, Pika 2.0 presenta l'interfaccia più intuitiva. La scelta ottimale dipende dalle vostre esigenze specifiche: consultate la nostra [tabella di confronto degli strumenti](#2026-year image-to-video AI tool comparison).
TuSheng Video può essere utilizzato gratuitamente?
Certamente. Diverse piattaforme offrono quote gratuite. Seedance fornisce crediti gratuiti a ogni nuovo utente, senza richiedere carta di credito. Anche Pika 2.0 e Luma Dream Machine offrono una generazione gratuita limitata. HaiLuo AI fornisce 10 generazioni gratuite al giorno. Queste quote gratuite sono sufficienti per testare la tecnologia e produrre diversi video. Se avete bisogno di un utilizzo continuativo, i piani a pagamento risultano più economici. Per ulteriori strategie di utilizzo gratuito, consulta la nostra Guida all'utilizzo gratuito di Seedance.
Qual è la durata massima dei video generati dall'intelligenza artificiale?
Le diverse piattaforme hanno limiti diversi. Kling 3.0 è all'avanguardia, generando video fino a 2 minuti per immagine. Seedance 2.0 ha un limite massimo di 15 secondi. Runway Gen-4 ha un limite massimo di 10 secondi. Pika 2.0 e Luma Dream Machine limitano i video a 5 secondi. Per la maggior parte dei social media e degli scenari di marketing, 5-15 secondi rappresentano la durata ottimale. Se fosse necessario un filmato più lungo, è possibile generare più clip brevi per la successiva modifica e unione, oppure utilizzare Kling per la generazione di video lunghi con un'unica ripresa.
Qual è il formato immagine più adatto per la generazione di video con l'intelligenza artificiale?
Il formato PNG è ottimale in quanto è un formato senza perdita di dati, privo di artefatti di compressione. Il formato WebP (modalità senza perdita di dati) ottiene risultati equivalenti con dimensioni di file inferiori. Anche il formato JPG è adatto nella maggior parte dei casi, ma i file JPG fortemente compressi con artefatti di compressione evidenti degradano la qualità dell'output. Evita di utilizzare GIF, BMP o altri formati non standard. Tutte le principali piattaforme supportano JPG, PNG e WebP. Risoluzione minima: 512x512 pixel. Risoluzione consigliata: 1024x1024 o superiore.
L'intelligenza artificiale è in grado di animare qualsiasi tipo di immagine?
L'IA è in grado di animare la maggior parte dei tipi di immagini, anche se i risultati variano a seconda del soggetto. I ritratti e le foto del viso producono i risultati migliori: i modelli attuali interpretano con precisione i movimenti naturali del viso e il flusso dei capelli. Anche i paesaggi e le scene naturali offrono prestazioni eccezionali, con movimenti convincenti delle nuvole, del flusso dell'acqua e della vegetazione ondeggiante. Le immagini di prodotti con sfondi puliti producono risultati costantemente affidabili. Le illustrazioni e le opere d'arte possono essere animate, anche se potrebbero essere necessari suggerimenti stilistici personalizzati per evitare un fotorealismo indesiderato. Le scene di gruppo complesse, le immagini che contengono testo consistente e le fotografie di bassa qualità producono i risultati meno stabili.
Qual è la differenza tra un video generato da immagini e un video generato da testo?
Text-to-Video genera contemporaneamente contenuti visivi e movimento a partire da descrizioni testuali. L'IA determina l'intero aspetto visivo, offrendo un controllo minore sui dettagli specifici ma una maggiore libertà creativa. Image-to-Video utilizza le immagini esistenti come punto di partenza, generando solo il movimento. L'utente mantiene un controllo preciso sul risultato visivo, poiché fornisce il riferimento visivo. Image-to-Video è in genere più prevedibile e coerente nei risultati, poiché l'IA ha un punto di riferimento visivo concreto. Text-to-Video è più adatto per far creare all'IA contenuti completamente nuovi da zero.
Tusheng Video è in grado di controllare il movimento della telecamera?
Certamente. La maggior parte dei moderni strumenti di generazione video supporta il controllo dei movimenti della telecamera tramite comandi testuali. È possibile specificare movimenti quali "dolly in", "pan left", "orbit around", "crane up", "zoom out" e "tracking shot". Seedance 2.0 e Luma Dream Machine rispondono in modo particolarmente accurato a queste parole chiave di movimento. Runway Gen-4 offre una precisione aggiuntiva grazie al suo Motion Brush e alla modalità Director, che consentono di tracciare visivamente il percorso della telecamera. Si consiglia di specificare un solo tipo di movimento per generazione, integrato con modificatori di velocità come "lentamente" o "costantemente".
La qualità delle immagini dei video generati dall'intelligenza artificiale è sufficiente per applicazioni professionali?
Per i contenuti video di breve durata (5-15 secondi), è del tutto fattibile. I risultati ottenuti da piattaforme di alto livello come Seedance 2.0 e Runway Gen-4 sono già stati utilizzati in modo professionale per il social media marketing, i video di prodotti e-commerce, le presentazioni immobiliari e i concetti pubblicitari. A livello nazionale, i contenuti commerciali di rilievo su Douyin e Xiaohongshu ora incorporano risorse video generate dall'intelligenza artificiale. Tuttavia, permangono alcune limitazioni: le durate prolungate aumentano il rischio di imperfezioni; le scene complesse con più soggetti rimangono instabili; e il rendering del testo all'interno dei video non è ancora perfetto. Per le opere cinematografiche o di livello televisivo che richiedono una perfezione assoluta, le riprese tradizionali rimangono l'opzione più sicura. Per il marketing digitale e i contenuti social, la tecnologia di conversione da immagine a video basata sull'intelligenza artificiale ha ormai raggiunto standard professionali.
Riepilogo
TuSheng Video AI si è evoluto da gadget innovativo a strumento essenziale per la creazione di contenuti. La tecnologia è maturata, gli strumenti sono diventati facili da usare e la qualità dei risultati ora soddisfa gli standard professionali per la stragrande maggioranza degli scenari di contenuti digitali.
Di seguito sono riportati i punti chiave:
- La qualità delle immagini sorgente è fondamentale. Immagini nitide, ben composte e ad alta risoluzione producono risultati di gran lunga superiori rispetto a quelle sfocate o a bassa risoluzione.
- Scrivi il movimento, non la descrizione. L'IA ha già visto la tua immagine. Spiega come devono muoversi gli elementi, non come appaiono.
- **Inizia in modo semplice. ** Un'azione principale più un movimento della telecamera. Padroneggia le basi prima di aggiungere complessità.
- Ripeti rapidamente. Genera prima brevi clip di prova; produci la versione completa solo quando sei soddisfatto.
- **Abbina gli strumenti alle attività. ** Seedance dà la priorità alla fedeltà visiva e al controllo multimodale; KeLing eccelle nei video di lunga durata e nell'accessibilità economica; Runway si concentra sul montaggio preciso; Pika enfatizza la semplicità e la facilità d'uso.
- Scegli lo strumento più adatto alle tue esigenze. Se ti trovi nella Cina continentale, Seedance e KeLing possono essere utilizzati direttamente senza ulteriori barriere di rete o di pagamento.
Il divario tra i marchi e i creatori che utilizzano Tusheng Video AI e i loro colleghi che continuano ad affidarsi alle immagini statiche si allarga di mese in mese. Ogni fotografia nella tua libreria di prodotti ha il potenziale per diventare un video pubblicitario. Ogni ritratto potrebbe diventare un avatar dinamico. Ogni scena paesaggistica potrebbe fungere da filmato cinematografico B-roll.
Crea gratuitamente il tuo primo video da immagine --> — Carica qualsiasi immagine e guardala prendere vita in 2 minuti. Non è richiesta alcuna carta di credito, direttamente accessibile nella Cina continentale.
Ti interessa scoprire altre funzionalità video basate sull'intelligenza artificiale? Prova Seedance su tutte le piattaforme --> — Generazione da testo a video, da video a video, multimodale: tutto sotto lo stesso tetto.
Ulteriori letture: Guida completa per l'utente di Seedance | Guida ai prompt di Seedance con oltre 50 esempi | Casi di applicazione creativa dei video AI | Classifica dei migliori generatori di video AI per il 2026 | Guida al marketing video AI e ai social media | AI da testo a video: guida completa*
