
Resumé
Image-to-Video AI bruger deep learning-teknologi baseret på diffusionsmodeller til at omdanne statiske billeder til dynamiske videoer. I modsætning til ren tekst-til-video-generering behøver du kun at uploade et fotografi for at AI'en kan generere realistiske bevægelser, kamerabevægelser og tidsmæssigt sammenhængende optagelser omkring det, hvilket giver dig mere præcis kontrol over det endelige resultat. Denne guide dækker omfattende: de tekniske principper bag Image-to-Video AI; hvilke typer billeder der giver optimale resultater; en femtrinsvejledning til at oprette din første video fra bunden; otte praktiske anvendelsestilfælde med eksempler; avancerede teknikker til bevægelseskontrol; og en sammenligning af de førende værktøjer i 2026 (inklusive dem, der er direkte tilgængelige i Kina). Prøv Image-to-Video AI gratis -->
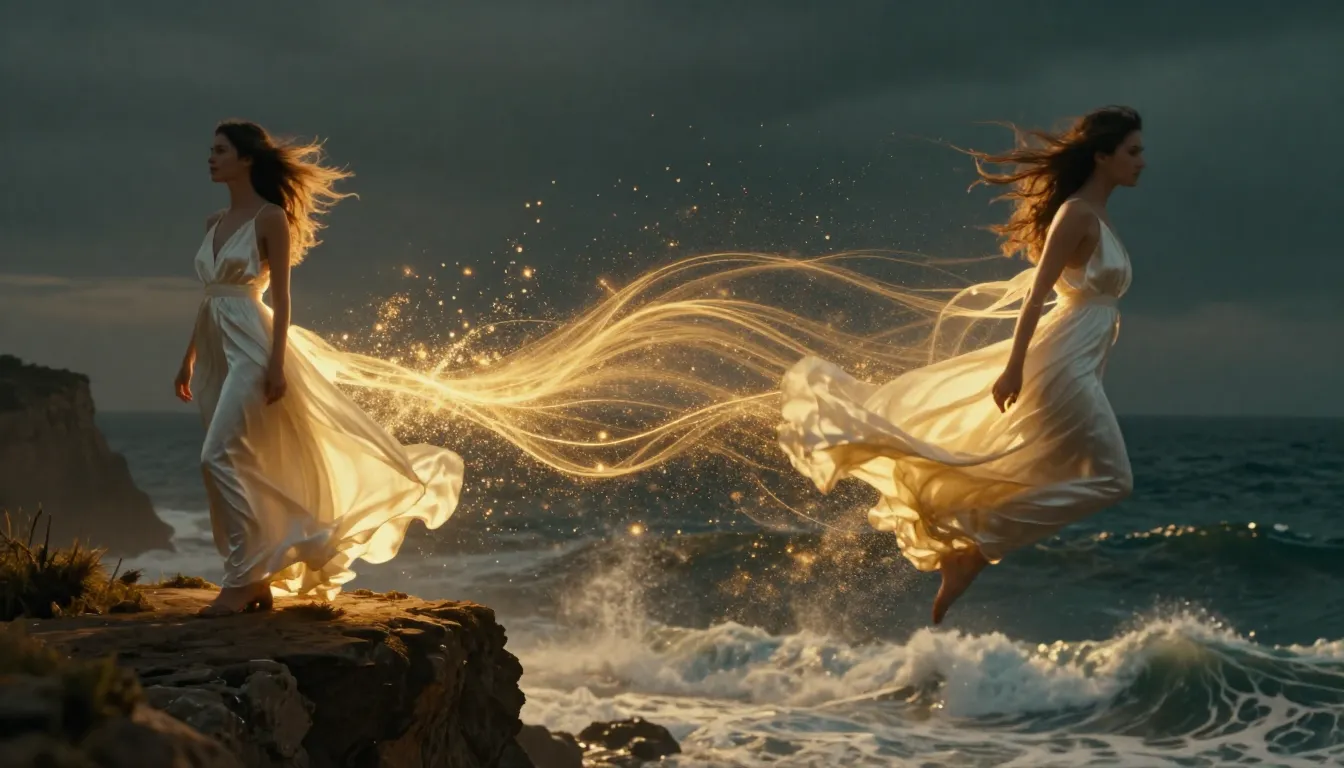
TuSheng Video AI tager dine stillbilleder og genererer naturtro bevægelser, filmiske kamerabevægelser og tidsmæssig kontinuitet – og forvandler et enkelt billede til et filmisk videoklip.
Hvad er Tusheng Video AI?
Image-to-Video AI er en kunstig intelligens-teknologi, der kan generere videoer ud fra statiske billeder. Du leverer et fotografi – det kan være et portræt, et produktbillede, et landskab eller et kunstværk – og AI-modellen producerer en kort video, hvor elementerne begynder at bevæge sig, kameraet skifter perspektiv, og hele scenen kommer til live.
I deres kerne anvender de fleste generative videosystemer videodiffusionsmodeller. Disse neurale netværk trænes på millioner af videobilleddatapar og lærer det statistiske forhold mellem statiske billeder og efterfølgende naturlige bevægelser. Når modellen præsenteres for et nyt billede, forudsiger den, hvilken bevægelse der virker mest naturlig, og genererer en kontinuerlig sekvens af billeder, der glidende overgår fra det oprindelige fotografi.
Forskelle fra tekst til video
Tekst-til-video genererer indhold udelukkende ud fra tekst. AI'en skaber samtidig både visuelt indhold og bevægelse baseret på din tekstuelle prompt – en kraftfuld, men uforudsigelig proces, da AI'en uafhængigt bestemmer motivernes udseende, scenernes komposition og alle former for bevægelse.
Tusheng Video vender denne logik på hovedet: du leverer det visuelle anker. AI'en ved allerede, hvordan scenen ser ud, fordi du har vist den direkte. Dens eneste opgave er at generere plausibel bevægelse. Det betyder:
- Større kontrol: Dine billeder definerer motivet, kompositionen, farvepaletten og stilen
- Mindre gætterier: AI kræver ingen fortolkning af vage tekstbeskrivelser
- Forbedret konsistens: Resultaterne stemmer nøje overens med kildebillederne
- Hurtigere iterationer: Det er langt nemmere at justere bevægelsesprompten end at omskrive hele scenebeskrivelsen
Hvorfor TuSheng Video er så vigtig i 2026
TuSheng Video AI har udviklet sig fra et eksperimentelt legetøj til et produktivitetsværktøj. E-handelsbrands omdanner produktbilleder til animerede reklamer, indholdsskabere giver deres mest populære indlæg liv, ejendomsmæglere producerer virtuelle fremvisningsvideoer ud fra ejendomsfotos, og undervisere animerer illustrationer i lærebøger.
Denne teknologi har nået et vendepunkt – 5 til 15 sekunders videoer genereret fra højkvalitets kildebilleder kan nu i de fleste tilfælde stort set ikke skelnes fra traditionelle optagelser. Det er netop derfor, at konvertering af billeder til video er blevet den hurtigst voksende kategori inden for AI-videogenerering.
Denne tendens er særlig udtalt på det kinesiske marked. Algoritmer på platforme som Douyin, Xiaohongshu, Bilibili og Kuaishou favoriserer alle i høj grad videoindhold, hvilket skaber en hidtil uset efterspørgsel blandt kreative efter værktøjer, der hurtigt kan konvertere fotografier til videoer. Tusheng Video AI adresserer netop dette hul i markedet.
Tekniske principper for Tusheng Video AI
At forstå den tekniske proces hjælper dig med at opnå bedre resultater. Når du ved, hvorfor AI opfører sig på en bestemt måde, kan du give bedre input og skrive mere effektive prompter. Her er den firetrinsproces, der foregår bag kulisserne.

De fire faser i Tusheng Videos AI-behandlingsproces: billedkodning, bevægelsesforudsigelse, billedgenerering og tidsmæssig udjævning.
Trin 1: Billedkodning
AI analyserer først dit inputbillede gennem et encoder-netværk og komprimerer det til en tæt matematisk repræsentation, der kaldes en latent vektor. Dette kan forstås som, at AI udtrækker et "fingeraftryk" af dit billede – og fanger dets struktur, farve, dybde, motivplacering, lysretning og semantiske information.
Denne latente repræsentation er betydeligt mere kompakt end de oprindelige pixeldata, hvilket gør efterfølgende beregninger mulige. Kvaliteten af kodningen har direkte indflydelse på outputresultaterne. Indgangsbilleder med højere opløsning og skarpere billeder genererer rigere latente repræsentationer, hvilket i sidste ende giver et bedre videooutput.
Trin to: Bevægelsesforudsigelse
Dette er den kreative kerne i hele processen. Diffusionsmodellen forudsiger, hvilken type bevægelse der vil virke naturlig baseret på dit originale billede, under hensyntagen til:
- Scenisk kontekst: Et havfoto antyder, at bølgerne skal bruse; et portræt antyder subtile ansigtsudtryk
- Dybdeinformation: Objekter tæt på linsen kan udvise andre bevægelsesmønstre end objekter i det fjerne
- Fysisk realisme: Hår skal blafre i vinden, vand skal løbe nedad, og stof skal falde naturligt
- Din tekstprompt: Hvis du angiver "panorer langsomt til venstre", vil modellen justere sin bevægelsesforudsigelse i overensstemmelse hermed.
Modellen forvrænger ikke blot pixels. Den genererer helt nyt visuelt indhold for områder, der bliver synlige ved kamerabevægelse eller objektbevægelse. Hvis kameraet panorerer til højre, vil modellen 'udfylde' scener uden for det oprindelige billedes højre kant.
Trin tre: Rammeopbygning
Baseret på bevægelsesforudsigelse genererer modellen en sekvens af videobilleder. Hvert billede produceres gennem en omvendt diffusionsproces – startende med støj, forfines det gradvist til et klart billede, samtidig med at det opretholder konsistensen med det foregående billede og det originale billede.
Seedance 2.0 og andre moderne modeller genererer med høje billedhastigheder (24–30 fps) og opretholder samtidig subpixelkonsistens mellem billederne. Dette sikrer en jævn, flimmerfri output uden de rystelser, der var almindelige i tidligere systemer.
Trin fire: Tidsudjævning
Det sidste trin sikrer sømløse overgange mellem alle genererede frames. Den tidsmæssige opmærksomhedsmekanisme verificerer, at lysstyrke, farve og bevægelse forbliver konsistente gennem hele videoen, hvilket forhindrer almindelige visuelle artefakter:
- Pludselige farveændringer mellem billeder
- Uventet fremkomst eller forsvinden af objekter
- Unaturlig acceleration eller deceleration af bevægelse
- Flimren i overfladestruktur
Det endelige resultat er en udsøgt video, der flyder naturligt fra det originale optagelser.
Hvorfor ser nogle billeder bedre ud?
Nu kan du forstå, hvorfor billedkvaliteten er så afgørende. Et sløret billede med lav opløsning giver en støjende potentiel kodning i første trin, hvilket giver færre oplysninger til bevægelsesforudsigelsesmodellen (andet trin). Dette resulterer i mindre præcise bevægelser og flere visuelle artefakter i det endelige resultat. Omvendt giver et skarpt, velkomponeret billede med klare dybdeindikationer modellen rige oplysninger, hvilket resulterer i en mere naturlig video af højere kvalitet.
Hvilken type billede giver de bedste resultater?
Ikke alle billeder er egnede til TuSheng Video AI. Forskellen mellem godt og dårligt kildemateriale kan meget vel være forskellen mellem en fantastisk video og en bunke ubrugeligt optagelsesmateriale. Her er en praktisk guide.

Den venstre side viser egnede stockbilleder (høj opløsning, velkomponerede, der antyder naturlige bevægelser), mens den højre side viser uegnede stockbilleder (slørede, rodede, indeholdende elementer, der er vanskelige for AI at behandle).
Egnede billedtyper
Høj opløsning (1024x1024 eller højere). Flere pixels gør det muligt for koderen at udtrække flere detaljer. Brug altid den version med den højeste opløsning, der er tilgængelig. Minimum anbefalet: 512x512 pixels. Ideelt: 1024x1024 eller højere.
Motiverne er klart definerede med tydelige konturer. AI'en skal skelne mellem, hvad der skal bevæges, og hvad der skal forblive statisk. Et portræt, hvor motivet er skarpt adskilt fra baggrunden, giver langt bedre resultater end en kompleks, kaotisk gruppescene.
God belysning og korrekt eksponering. Billeder med god belysning giver nøjagtige oplysninger om farver og dybde til modellen. Undgå billeder, der er stærkt overeksponerede eller undereksponerede.
Naturlig lagdeling og komposition. Billeder med klart defineret forgrund, mellemgrund og baggrund giver AI dybdeindikationer, hvilket forbedrer realismen i parallakseffekter og kamerabevægelser.
Billeder, der antyder bevægelse. Billedlige tegn på bevægelse – hår, der blæser i vinden, bølger, der er ved at slå ind mod kysten, en figur, der tager et skridt – giver modellen gode udgangspunkter for at forudsige bevægelse. AI kan ud fra disse visuelle indikatorer skelne, "hvad der sker næste gang".
Rene baggrunde. En enkel eller naturligt sløret baggrund giver en jævnere videoudgang end en rodet baggrund fyldt med mange små objekter.
Billedtyper, der kan forårsage problemer
Uklare eller uskarpe billeder. Uklar indgang, uklar udgang. AI kan ikke tilføje skarphed, der ikke var til stede i det originale billede.
Overdrevent komplekse scener. Billeder, der indeholder mange små motiver, indviklede mønstre eller visuel rod, kan overbelaste bevægelsesforudsigelsesmodellerne, så de ikke er i stand til at afgøre, hvad der skal bevæge sig, og hvordan.
Omfattende tekst eller typografi. AI-videomodeller har stadig svært ved at bevare tekstens læsbarhed på tværs af billeder. Hvis dine billeder indeholder logoer, varemærker eller tekstoverlejringer, vil der opstå forvrængning i videoudgangen.
Lav opløsning (512x512 eller derunder). Små billeder indeholder utilstrækkelig information. Selv forstørrelse med AI før indtastning er nytteløst – det tilføjer pixels, men ikke information.
Tunge filtre eller efterbehandling. Ekstreme farvejusteringer, HDR-behandling eller omfattende Photoshop-ændringer kan forvirre modellens forståelse af belysning og dybde.
Flere ansigter i forskellige størrelser. AI håndterer enkeltportrætter effektivt. Gruppebilleder med ansigter i forskellige afstande giver inkonsekvente animationer – nogle ansigter ser naturlige ud, mens andre bliver forvrængede.
Tjekliste til selvkontrol før upload
Før du uploader billeder, skal du hurtigt kontrollere følgende punkter:
- Minimum opløsning på 1024x1024 pixels
- Motivet er klart defineret med tydelig adskillelse fra baggrunden
- Korrekt eksponering (hverken undereksponeret eller overeksponeret)
- Ingen tunge filtre, ekstrem HDR eller synlig kunstig behandling
- Minimalt med tekst, logoer eller typografiske elementer
- Kontrolleret scenekompleksitet (1–3 primære motiver)
- Billedformat: JPG, PNG eller WebP
Når disse betingelser er opfyldt, kan produktionen påbegyndes.
Trin-for-trin guide: Generer dit første billede til video
Følg disse fem trin for at omdanne ethvert statisk billede til en animeret AI-video. Vi bruger Seedance som vores demonstrationsplatform, men disse principper gælder for alle værktøjer til konvertering af billeder til video.
Trin 1: Valg af egnede kildebilleder
Kildebilledet er den mest afgørende faktor for udskriftskvaliteten. Vælg et billede, der overholder de retningslinjer, der er beskrevet tidligere. Til dit første forsøg anbefaler vi, at du vælger et enkelt portræt eller et landskab med markant dybde – disse to typer billeder giver de mest ensartede resultater.
Anbefalede billeder til første forsøg:
- Tydeligt portrætbillede eller halvt portræt i gunstig belysning
- Landskaber med himmel, vandoverflader eller vegetation (disse elementer har en iboende bevægelse)
- Produktbilleder mod en ren baggrund
- Kunstværker eller illustrationer med klart definerede elementer
Når du genererer for første gang, skal du undgå at bruge komplekse sammensatte billeder, billeder med store mængder tekst eller stærkt redigerede fotografier.
Trin to: Upload til Seedance
Åbn Seedance Image-to-Video og upload de valgte billeder. Seedance understøtter JPG-, PNG- og WebP-formater. Platformen analyserer automatisk dine billeder og forbereder dem til generering.
Hvis et billede er usædvanligt stort (med en side på over 4096 pixels), ændrer systemet automatisk størrelsen på billedet, samtidig med at proportionerne bevares, så manuel justering ikke er nødvendig.
Trin tre: Udformning af en bevægelsesorienteret prompt
På dette trin informerer du AI'en om den ønskede bevægelse. Din prompt skal beskrive dynamikken snarere end billedets indhold (AI'en har allerede set billedet). Fokuser på følgende punkter:
- Motivets bevægelse: Hvad skal motivet gøre?
- Kamerabevægelse: Hvordan skal kameraet bevæge sig?
- Miljøets bevægelse: Hvilken dynamik skal der være i miljøet?
- Tempo og stemning: Skal det overordnede tempo være hurtigt eller langsomt?
Eksempler på portrætprompter:
The woman slowly turns her head to the right and smiles softly.
A gentle breeze moves her hair. Background slightly out of focus
with subtle bokeh movement. Camera slowly pushes in from medium
shot to a close-up. Warm, natural lighting. Cinematic film quality.Eksempel på landskabsprompt:
Gentle waves roll toward the shore in slow motion. Clouds drift
slowly across the sky from left to right. Sunlight shimmers on
the water surface. Camera slowly pans right, revealing more of
the coastline. Peaceful, serene atmosphere. 4K cinematic quality.Eksempel på produktprompt:
The camera slowly orbits around the product, rotating 45 degrees
clockwise. Soft studio lighting with subtle caustic reflections
on the surface. Clean white background with gentle gradient.
Premium commercial aesthetic. Smooth, steady camera movement.Grundlæggende princip: Beskriv bevægelsen, ikke scenen. Scenen findes allerede i dit billede.
Bemærk: Seedance understøtter både kinesiske og engelske kommandoer, men engelske kommandoer giver typisk større præcision i styringen af kamerabevægelser. Det anbefales at bruge engelsk til bevægelses- og kamerarelaterede beskrivelser, mens kinesisk kan bruges til atmosfæriske og stilistiske beskrivelser.
Trin fire: Vælg parametre
Konfigurer genereringsindstillinger:
| Parameter | Anbefalet værdi | Beskrivelse |
|---|---|---|
| Model | Seedance 2.0 | Optimal billedkvalitet til generering af billeder til video |
| Varighed | 5 sekunder (til indledende forsøg) | Start kort, derefter længere; generer udvidede versioner, når du er tilfreds |
| Billedformat | Match billeddimensioner | 16:9 for liggende, 9:16 for stående, 1:1 for kvadratisk |
| Opløsning | 1080p | Vælg altid den højeste tilgængelige opløsning |
Avanceret teknik: Generer først en 5-sekunders version. Hvis bevægelsen og stilen er tilfredsstillende, skal du bruge den samme prompt til at generere en længere version (8–15 sekunder). Denne fremgangsmåde sparer kreditter i udforskningsfasen.
Trin fem: Generer, kontroller, gentag
Klik på Generer og vent 1–3 minutter. Når resultaterne vises, skal du evaluere dem ud fra følgende kriterier:
- Er bevægelsen flydende og naturlig?
- Bevarer motivet visuel konsistens gennem hele videoen?
- Er kamerabevægelsen i overensstemmelse med dine forventninger?
- Er der visuelle uregelmæssigheder (flimmer, forvrængning, deformation)?
- Er videokvaliteten i overensstemmelse med det originale optagelse?
Hvis noget aspekt viser sig at være utilfredsstillende, skal du justere prompten og regenerere. Almindelige justeringsmetoder:
- For hurtigt? Tilføj "langsomt", "forsigtigt", "gradvist" til bevægelsesbeskrivelsen
- Forkert kameraretning? ** Angiv det mere tydeligt: "statisk kamera, ingen kamerabevægelse" eller "langsom dolly ind"
- Ufuldkommenheder i ansigtet? Forenkle bevægelsen: reducer antallet af handlinger, der udføres samtidigt
- **Mangler dynamik? ** Indfør dynamiske verber: "svingende", "flydende", "drivende", "skiftende"
Efter to eller tre iterationer får du en video i høj kvalitet, der giver dine billeder liv.
Begynd at oprette dit første billed-til-videoklip nu -->
8 vigtige anvendelser og eksempler på konvertering af store billeder til video
TuSheng Video AI er ikke et one-trick pony. Det tjener snesevis af kreative og kommercielle formål. Nedenfor er otte højværdige anvendelsesscenarier, komplet med praktiske prompter, der er klar til direkte kopiering og ændring.
- Portrætanimation
Giv dine fotos liv. Portrætanimation er den mest populære app til at omdanne fotos til videoer. Upload et profilbillede, et selfie eller et karakterbillede, og tilføj derefter subtile, naturtro animationer – vejrtrækning, blink, hovedbevægelser, skiftende udtryk og hårbevægelser.
Velegnet til mindeværdige videoer, indhold til sociale medier, oprettelse af virtuelle avatarer og kreativ storytelling. På TikTok og Xiaohongshu er indhold, hvor "fotos kommer til live", fortsat en konstant trafikmagnet.

Et statisk portræt forvandles til en naturtro video – naturlige blink, subtile hovedbevægelser og flydende hår, effekten er overraskende naturtro.
Eksempel på prompt:
The person looks directly at the camera with a calm, confident
expression. They slowly tilt their head slightly to the left and
give a subtle warm smile. Eyes blink naturally. A soft breeze gently
moves their hair. Shallow depth of field with softly blurred
background. Warm natural lighting. Cinematic portrait quality.- Produktfremvisning
Omdan produktfotografering til dynamisk kommercielt indhold. Dette er revolutionerende for e-handelsbrands og influencers – du har allerede hundredvis eller endda tusindvis af produktbilleder, og nu kan hvert enkelt af dem blive til en videoannonce, et nøglebillede til produktdetaljesider eller en kortfilm til sociale medier.
På Taobao og JD.coms produktdetaljesider, i Douyins livestream-produktintroduktioner og i Xiaohongshus produktanbefalingsindlæg opnår dynamiske produktvisninger konsekvent betydeligt højere konverteringsfrekvenser end statiske billeder.

Et standardproduktbillede løftes til samme niveau som en sofistikeret reklamefilm – med kamerapanoreringer, dramatisk belysning og flydende bevægelser – en produktion, der ved hjælp af konventionelle metoder kan koste hundredvis eller tusindvis af pund.
Eksempel på prompt:
The camera slowly orbits 90 degrees around the product, revealing
its form from multiple angles. Soft directional studio lighting
with subtle caustic reflections on the surface. A gentle highlight
sweep moves across the product. Clean, premium commercial aesthetic.
Shallow depth of field. Ultra-smooth camera movement. 4K quality.3. Scenisk tidsforkortelse
Forvandl landskabsfotografering til stemningsfulde time-lapse-videoer. Skyer fejer hen over himlen, vandet strømmer, lyset skifter fra gyldent til blåt, og bladene svajer i brisen. Ideel til rejseindhold, luftfotos af ejendomme og stemningsfulde B-roll-optagelser.
Landskabsfotografer og rejsevloggere på Bilibili kan direkte omdanne deres kuraterede fotografier til fængslende time-lapse-videoer, hvilket reducerer produktionsomkostningerne betydeligt.

Et landskabsfotografi omdannet til filmisk time-lapse – flydende skyer, krusende vand og skiftende lys og skygger – skaber en dynamisk, atmosfærisk kvalitet ud fra et enkelt statisk billede.
Eksempel på prompt:
Time-lapse effect. Clouds move steadily across the sky from left
to right. Water in the foreground ripples and flows gently. Light
shifts subtly as if the sun is moving, creating slowly changing
shadows on the landscape. Trees and grass sway gently in the wind.
Camera remains static on a tripod. Serene, majestic atmosphere.
Cinematic landscape quality.4. Indhold på sociale medier
Omdan dine bedst præsterende statiske indlæg til videoindhold, der får folk til at stoppe med at scrolle. Algoritmer på platforme som TikTok, Xiaohongshu, Bilibili og Kuaishou favoriserer alle i høj grad videoindhold – et højt præsterende billedindlæg vil næsten helt sikkert få bedre trafik, når det konverteres til en video.
For indholdsskabere på Xiaohongshu kan en række billed-tekst-indlæg få en 3-5 gange større eksponering, hvis de ledsages af en videoversion. Douyin og Kuaishou fungerer derimod udelukkende med video som deres primære indholdsformat.
Eksempel på prompt:
Dynamic, attention-grabbing motion. The subject moves confidently
toward the camera with energy and presence. Background elements
shift with parallax depth effect. Quick, punchy camera push-in
that creates impact. Vibrant colors, high contrast. Bold,
eye-catching aesthetic optimized for social media. Vertical 9:16.- Kunst og illustration Animation
Giv kunstværker, illustrationer, digitale malerier og grafiske designs liv. Dette anvendelsesscenarie er meget populært blandt kunstnere, spildesignere og kreative teams, der ønsker at fremvise deres arbejde på en mere engagerende måde.
Inden for Bilibili og Xiaohongshus kunst- og anime-fællesskaber er animerede illustrationer meget populært indhold. At omdanne statiske illustrationer til videoer i stil med "levende tapet" giver ofte betydeligt flere delinger og gemninger end de originale billeder.
Eksempel på prompt:
The illustrated scene comes to life with gentle, painterly motion.
Characters move subtly within their positions -- breathing, shifting
weight, small gestures. Background elements like leaves, clouds,
or particles drift slowly. The artistic style is preserved exactly
as painted. Movement is smooth and dreamlike, like a living painting.
Gentle ambient lighting shifts. Fantasy illustration quality.6. Virtuelle ejendomsbesigtigelser
Omdan ejendomsfotos til virtuelle rundvisningsvideoer. Ejendomsmæglere kan skabe immersive forhåndsvisninger ved hjælp af eksisterende ejendomsbilleder, hvilket eliminerer behovet for at arrangere fotografering på stedet med specialiserede teams.
For ejendomsannoncer, der vises på platforme som Beike og Anjuke, samt ejendomsreklamer i WeChat Moments og Xiaohongshu, viser dynamiske visningsvideoer en betydeligt højere konverteringsrate for kundehenvendelser.
Eksempel på prompt:
Smooth virtual walkthrough. The camera glides forward slowly into
the room, revealing the space with a wide-angle perspective.
Natural daylight streams through the windows, casting soft shadows.
Subtle dust particles float in the sunbeams. The camera pans
gently to the left, showing the full room layout. Clean, bright,
aspirational real estate aesthetic. Steady, professional movement.- Mode- og stylingudstilling
Skab dynamisk modeindhold ud fra fotos af tøj i studiet. Modellerne bevæger sig, stofferne falder naturligt, mens den æstetiske stil på redaktørniveau forbliver intakt.
Xiaohongshu-modebloggere og Taobao-tøjforhandlere kan konvertere store mængder eksisterende modelbilleder og flade billeder af tøj til dynamiske displayvideoer, hvilket skaber en mere visuelt slående effekt i informationsfeeds.
Eksempel på prompt:
The model strikes a confident pose and then slowly shifts their
weight, creating natural body movement. Fabric of the outfit
flows and catches the light with each subtle motion. Wind effect
gently moves the hair. Camera starts at full body and slowly drifts
upward to a waist-up shot. High-fashion editorial lighting with
strong directional shadows. Vogue magazine aesthetic. Cinematic
slow motion.- Uddannelsesmæssigt og forklarende indhold
Omdan statiske diagrammer, infografikker og pædagogiske illustrationer til dynamiske præsentationer. Komplekse begreber bliver lettere at forstå, når de sættes i bevægelse.
Skabere på Bilibili's Knowledge Zone og forskellige uddannelsesplatforme kan omdanne kursusmateriale, diagrammer og flowcharts til animerede videoer, hvilket forbedrer undervisningseffektiviteten og seertallene betydeligt.
Eksempel på prompt:
The diagram elements animate sequentially. Arrows begin to flow
in their indicated directions. Labels fade in one by one. Moving
parts of the system activate in logical order, showing the process
step by step. Smooth transitions between stages. Clean, clear
educational style. Elements highlight with subtle glow as they
become active. Professional presentation quality.En omfattende guide til hurtige teknikker til Tusheng Video
En velformuleret prompt er den mest effektive metode til at generere billeder ud fra fotos. Da AI'en allerede har set dit billede, bør din prompt udelukkende fokusere på bevægelse og dynamik. Her er nogle teknikker, der giver de bedste resultater.
Hurtig referenceguide til sportsrelaterede søgeord
Brug disse specifikke nøgleord til at styre videobevægelser præcist.
| Bevægelsestype | Nøgleord | Effekt | |-------- -|-------|------| | Kamera: Fremad | dolly ind, skub ind, kom tættere på, nærmer sig | Kameraet bevæger sig mod motivet | | Kamera: Bagud | dolly ud, træk tilbage, træk dig tilbage, udvid | Kameraet bevæger sig væk fra motivet | | Optagelse: Venstre/højre | panorering til venstre, panorering til højre, tracking til venstre, tracking til højre | Kameraet roterer eller tracker vandret | | Optagelse: Op/ned | tilt op, tilt ned, kran op, kran ned | Kameraet roterer eller bevæger sig lodret | | Optagelse: Orbit | kredse, dreje, rotere rundt, bue | Kameraet kredser om motivet | | Kamera: Zoom | zoom ind, zoom ud, skift brændvidde | Kameraet zoomer (uden forskydning) | | Motiv: Mikrobevægelser | trække vejret, blinke, flytte vægten, mikrobevægelser | Subtile, naturtro bevægelser | | Motiv: Moderat | dreje hovedet, smile, gestikulere, gå langsomt | Tydelig, men kontrolleret bevægelse | | Motiv: Dynamisk | løbe, springe, danse, dreje, vinke | Energisk bevægelse af hele kroppen | | Miljø: Blid | brise, drive, svaje, krusning, skimmer | Blid bevægelse i omgivelserne | | Miljø: Intens | blæse, suse, styrte, hvirvle, kaskade | Kraftig dynamik i omgivelserne | | Parallaks | parallaks, dybdeforskydning, lag bevæger sig | Forgrund/baggrund bevæger sig med forskellige hastigheder |

Forskellige nøgleord for kamerabevægelser giver helt forskellige effekter. Vælg din kamerabevægelsesteknik omhyggeligt i henhold til det ønskede resultat.
Hastighed og tempokontrol
Bevægelsens tempo har en stor indflydelse på den følelsesmæssige tone i en video. Brug følgende modifikatorer:
- Ekstremt langsom: "knap mærkbar", "ultra-langsom bevægelse", "gletscheragtig hastighed" — Dramatisk, kontemplativ
- Langsom: "langsomt", "blidt", "gradvist", "afslappet" — elegance, filmisk kvalitet
- Moderat: "stabilt", "naturligt tempo", "i ganghastighed" — realisme, dokumentarisk stil
- Hurtigt: " hurtigt", "raskt", "energisk", "hurtigt" — dynamisk, spændende
- Ekstremt hurtigt: "hurtigt", "hurtig panorering", "hurtigt klip", "bevægelsesudbrud" — spændt, actionfyldt
Avanceret teknik: Brug slow motion som standard. I AI-genererede videoer ser slow motion næsten altid bedre ud end fast motion. Hurtige bevægelser øger risikoen for fejl og visuelle uoverensstemmelser.
Uafhængig bevægelseskontrol af baggrund og motiv
Du kan selv bestemme, hvad der skal bevæge sig, og hvad der skal forblive stille. Dette er en effektiv teknik til at styre publikums opmærksomhed.
Motivet i bevægelse, baggrunden i ro:
The person walks forward confidently while the background remains
perfectly still. Static camera, no camera movement. Focus entirely
on the subject's motion.Dynamisk baggrund, statisk motiv:
The person stands completely still, like a statue. Behind them,
clouds drift across the sky, leaves blow in the wind, and city
lights flicker. Only the environment moves.Separate bevægelser fra begge sider:
The person slowly turns their head while the camera simultaneously
dollies in. Background clouds drift in the opposite direction,
creating a sense of depth and dimension.Forskellen mellem kamerabevægelse og objektbevægelse
Det er afgørende at forstå forskellen mellem kamerabevægelse og objektbevægelse for at opnå den ønskede effekt.
Kamerabevægelse ændrer perspektivet og kompositionen. Selve scenen forbliver uændret, mens synsvinklen skifter. Anvendes til: at afsløre scenen, etablere omgivelserne og skabe dramatisk effekt.
Objektbevægelse refererer til bevægelsen af elementer inden for en scene, mens kameraet forbliver stationært. Det anvendes til: karakteranimation, produktdemonstrationer og naturlige miljødynamikker.
Kombineret bevægelse anvender begge teknikker samtidigt. Denne tilgang giver de mest filmiske resultater, men er samtidig den mest udfordrende for AI at udføre effektivt. Det anbefales at mestre en enkelt bevægelsestype først og først lægge den anden ovenpå, når du er tilfreds med resultatet.
Avancerede promptstrukturer
For at opnå de mest forudsigelige resultater skal du organisere din prompt i følgende rækkefølge:
- Hovedhandling — Hvad hovedpersonen gør
- Kamerabevægelse — Hvordan kameraet bevæger sig
- Miljødynamik — Hvad miljøelementerne gør
- Hastighed/Tempo — Tempoet for alle bevægelser
- Atmosfære/stemning — Følelsesmæssig tone
- Forbedring af visuel kvalitet — Teknisk beskrivelse af visuel kvalitet
Eksempel på brug af denne struktur:
[Subject] A young woman in a flowing white dress slowly raises
her hand to brush hair from her face.
[Camera] The camera executes a slow, steady dolly in from a
medium shot to a close-up.
[Environment] Cherry blossom petals drift gently through the
air. Soft golden sunlight filters through the trees.
[Speed] All motion is slow and deliberate, almost dreamlike.
[Mood] Romantic, ethereal, peaceful atmosphere.
[Quality] Cinematic shallow depth of field, anamorphic bokeh,
film grain, 4K quality.2026 TuSheng Video AI-værktøjs sammenligning
Konkurrencen inden for videostreaming intensiveres. Nedenfor findes en sammenlignende analyse af de mest populære platforme pr. februar 2026, med særlig vægt på tilgængeligheden for brugere i Kina.

Behandlingseffekterne af det samme kildebillede på fem forskellige videogenereringsplatforme. Forskelle i bevægelseskvalitet, tidsmæssig konsistens og visuel troværdighed er umiddelbart synlige.
| Funktion | Seedance 2.0 | Runway Gen-4 | Pika 2.0 | Kling 3.0 | Luma Dream Machine | |------|-------------|-------------|---------|------ ----------|-------------------| | Maksimal opløsning | 2K (2048x1080) | 4K (opskaleret) | 1080p | 1080p | 1080p | | Maksimal varighed | 15 sekunder | 10 sekunder | 5 sekunder | 2 minutter | 5 sekunder | | Indtastningsmuligheder | Billede + tekst + video + lyd | Billede + tekst + video | Billede + tekst | Billede + tekst | Billede + tekst | | Indtastning af flere billeder | Understøttet (op til 9 billeder) | Ikke understøttet | Ikke understøttet | Ikke understøttet | Ikke understøttet | | Indbygget lyd | Understøttet (8 sprog med læbesynkronisering) | Ikke understøttet | Delvist (lydeffekter) | Ikke understøttet | Ikke understøttet | | Kamerastyring | Promptbaseret | Bevægelsesbørste + instruktørtilstand | Grundlæggende | Grundlæggende | Promptbaseret | | Gratis kvote | Tilgængelig (Registreringsbonus) | Tilgængelig (begrænset) | Tilgængelig (begrænset) | Tilgængelig (begrænset) | Tilgængelig (begrænset) | | Startpris | ~9,90 $/måned | 15 $/måned | 10 $/måned | ~6,99 $/måned | 9,99 $/måned | | Adgang fra Kina | Direkte adgang | VPN påkrævet | VPN påkrævet | Direkte adgang | VPN påkrævet | | Bedst egnet til | Multimodal kontrol, billedkvalitet | Professionel redigeringsworkflow | Begyndere, sjove effekter | Lange videoer, høj værdi | Filmisk fornemmelse, 3D-scener |
Detaljerede anmeldelser af hvert værktøj
Seedance 2.0 er uovertruffen, når det gælder inputfleksibilitet. Det er den eneste platform, der understøtter samtidig upload af op til ni referencebilleder, lydinput med læbesynkronisering og kombination af alle inputtilstande i en enkelt generation. Hvis du ønsker maksimal kontrol over billed-til-video-output, tilbyder Seedance det mest omfattende værktøjssæt. Dens 2K-opløsning er også den højeste blandt alle værktøjer (uden at være afhængig af opsampling). Udviklet af ByteDance (moderselskab til TikTok), kan brugere i Kina få direkte adgang til det uden behov for VPN eller udenlandske betalingsmetoder.
Runway Gen-4 udmærker sig ved sin præcise kontrol. Motion Brush giver dig mulighed for omhyggeligt at 'male' hvilke dele af et billede der skal bevæges, og i hvilken retning. Hvis du har brug for kirurgisk præcision over bestemte områder, er Runway det bedste valg. Ulemperne er den højere pris og lavere generationskvoter. Adgang inden for Kina kræver en VPN.
Pika 2.0 er den mest tilgængelige løsning. For begyndere, der ønsker at eksperimentere med generering af billeder til video uden at lære prompt engineering, tilbyder Pikas one-click-effekter og strømlinede interface den laveste adgangsbarriere. Selvom billedkvaliteten ikke er på højde med premium-værktøjer, er den tilstrækkelig til afslappet socialt indhold. Kræver VPN for adgang inden for Kina.
Kling 3.0 overgår sine konkurrenter både med hensyn til varighed og værdi for pengene. Hvis du har brug for at generere længere videoer – 30 sekunder, 1 minut eller endda 2 minutter – ud fra et enkelt billede, er Kling den eneste brugbare mulighed. Dens pris-til-billedkvalitet-forhold er usædvanligt gunstigt. Dens begrænsning ligger i de begrænsede inputmuligheder (enkelt billede + tekst). Som et produkt under Kuaishou-paraplyen er Kling direkte tilgængelig i Kina og tilbyder indenlandske brugere endnu en problemfri mulighed.
Luma Dream Machine udmærker sig i rumlig forståelse. Til landskaber, arkitektur og scener, hvor tredimensionel rumlig bevidsthed er afgørende, producerer Luma de mest overbevisende parallaks- og kamerabevægelser. Karakteranimationen halter bagefter i forhold til konkurrenterne. Adgang fra Danmark kræver VPN.
Anbefalinger til brugere i Kina
Hvis du befinder dig i Kina, er der primært to videoværktøjer, der kan bruges direkte uden VPN:
- Seedance 2.0 — Udviklet af ByteDance, fuldt funktionelt og klar til brug, med multimodal indgang + 2K-opløsning + indbygget lyd
- Kling 3.0 — Et produkt under Kuaishou, der udmærker sig i generering af lange videoer med enestående værdi for pengene
Selvom udenlandske værktøjer som Runway, Pika og Luma hver har deres egne særlige funktioner, kræver de alle VPN-adgang og udenlandske betalingsmetoder, hvilket udgør en større adgangsbarriere.
For indholdsskabere på indenlandske platforme som Douyin, Xiaohongshu, Bilibili og Kuaishou giver valget af værktøjer, der er direkte tilgængelige i Kina, ikke kun større bekvemmelighed, men også øget pålidelighed med hensyn til netværksstabilitet og betalingslethed.
For en mere omfattende sammenligning (inklusive tekst-til-video-funktioner) henvises til vores Komplette rangliste over AI-videogeneratorer for 2026.
Almindelige fejl og korrektioner
Efter at have testet tusindvis af videoklip er her de fem mest almindelige fejl, vi har observeret – sammen med specifikke korrigerende foranstaltninger.
- Brug stockbilleder i lav opløsning
Den begåede fejl: At uploade et lille, komprimeret billede (f.eks. et 400x300-miniaturebillede gemt fra WeChat eller sociale medier) og samtidig forvente at få en video i høj opløsning.
Hvorfor det mislykkes: Enkoderen kan ikke udtrække tilstrækkelig visuel information fra billeder med lav opløsning. Outputtet arver sløringen og overlejrer samtidig bevægelsesartefakter.
Sådan løses problemet: Brug altid billedet i den højeste opløsning. Hvis der kun findes versioner i lav opløsning, skal du bruge et AI-opskaleringsværktøj (f.eks. Real-ESRGAN eller Topaz Gigapixel) til at forbedre opløsningen, inden du uploader billedet. Den anbefalede minimumsstørrelse er 1024x1024 pixels.
- Skriv scenebeskrivelser frem for handlingsbeskrivelser
Den begåede fejl: Skriveopgaver som f.eks. "Havoverfladen ved solnedgang, med gyldent lys, der glitrer på vandet." Dette beskriver billedets udseende – noget, som AI'en allerede ved.
Hvorfor det mislykkedes: AI'en har allerede kodet billedet. At beskrive billedets indhold tilbage til den spilder plads på overflødig information og giver ingen retning for bevægelse.
Sådan redigerer du: Fokuser udelukkende på bevægelsen. Omskriv til: "Bølgerne ruller blidt mod kysten. Gyldent sollys glimter på vandoverfladen. Skyerne driver langsomt fra venstre mod højre. Kameraet panorerer langsomt mod højre og følger kystlinjen."
- At kræve for mange handlinger udført samtidigt
Fejl: "Karakteren drejer hovedet, vinker, går fremad, tager en kop, smiler og danser, mens kameraet zoomer ind, panorerer til venstre og vipper."
Hvorfor det ikke fungerer: Nuværende AI-modeller kan ikke pålideligt koordinere mere end to eller tre samtidige handlinger. Overbelastede prompter får modellen til enten at ignorere de fleste instruktioner eller producere forvirrede, fejlbehæftede resultater.
Sådan redigeres: Begræns hver generation til én primær handling plus én kamerabevægelse. Ved komplekse, sammenhængende handlinger skal du generere flere korte klip separat, inden du redigerer og samler dem.
- Ignorer uoverensstemmelser i billedformat
Den begåede fejl: At uploade et 16:9-landskabsfoto, men indstille output til 9:16-portrætformat eller omvendt.
Hvorfor det ikke fungerer: AI beskærer enten dit billede drastisk eller kræver, at store tomme områder udfyldes. Ingen af disse metoder giver tilfredsstillende resultater – beskæring ødelægger den omhyggeligt komponerede indramning, mens udfyldning af store nye områder skaber uoverensstemmelser.
Sådan løses problemet: Sørg for, at billedformatet svarer til kildebilledets proportioner. Brug 16:9 til liggende billeder og 9:16 til stående billeder. Hvis der kræves et andet billedformat, skal du beskære kildebilledet til de ønskede proportioner, inden du uploader det.
- Forvent en realistisk effekt af illustrative billeder
Den begåede fejl: At uploade en tegneserieillustration eller et fladt designbillede i forventning om, at AI'en ville generere fotorealistisk videobevægelse.
Hvorfor det mislykkes: Modellen forsøger at fortolke kunstneriske stilarter, hvilket undertiden medfører uønsket realisme. Flade illustrationer mangler den dybde og de lyssignaler, som modellen er afhængig af for at kunne forudsige naturlige bevægelser.
Sådan løses problemet: Hvis kildematerialet er en illustration, skal du angive stilen eksplicit i prompten: "Bevar den illustrerede kunststil nøjagtigt. Animeret i en 2D-animationsstil, ikke fotorealistisk. Bevægelsen skal føles håndtegnet og malerisk." Dette instruerer modellen om at bevare den kunstneriske stil i stedet for at indføre fotorealisme.
Ofte stillede spørgsmål
Hvilket AI-værktøj er bedst egnet til at generere videoer ud fra billeder?
Seedance 2.0 er vores bedste anbefaling til generativ video i 2026. Det understøtter flere billedindgange (op til 9 referencebilleder), output i 2K-opløsning og tilbyder de mest fleksible kombinationer af billeder, tekst, video og lyd. Desuden er Seedance, der er udviklet af ByteDance, direkte tilgængeligt i Kina. For budgetbevidste brugere leverer Kling 3.0 enestående billedkvalitet til en lavere pris og er også direkte tilgængelig i Kina. For begyndere har Pika 2.0 den mest brugervenlige grænseflade. Det optimale valg afhænger af dine specifikke krav – se vores [værktøjssammenligningstabel](#2026-year image-to-video AI tool comparison).
Kan TuSheng Video bruges gratis?
Bestemt. Flere platforme tilbyder gratis kvoter. Seedance giver gratis kreditter til alle nye brugere – ingen kreditkort kræves. Pika 2.0 og Luma Dream Machine tilbyder også begrænset gratis generering. HaiLuo AI giver 10 gratis genereringer dagligt. Disse gratis kvoter er tilstrækkelige til at teste teknologien og producere flere videoer. Til løbende brug er betalte abonnementer mere omkostningseffektive. For yderligere strategier til gratis brug kan du læse vores Seedance Free Usage Guide.
Hvad er den maksimale længde for AI-genererede videoer?
Forskellige platforme har forskellige begrænsninger. Kling 3.0 er førende på området og genererer videoer på op til 2 minutter ud fra et enkelt billede. Seedance 2.0 har en begrænsning på 15 sekunder. Runway Gen-4 har en begrænsning på 10 sekunder. Pika 2.0 og Luma Dream Machine begrænser videoer til 5 sekunder. For de fleste sociale medier og marketing scenarier er 5-15 sekunder den optimale varighed. Hvis der er behov for længere optagelser, kan man generere flere korte klip til efterfølgende redigering og sammenklipning, eller bruge Kling til at generere lange videoer fra et enkelt optagelse.
Hvilket billedformat er mest velegnet til generering af AI-videoer?
PNG er optimalt, da det er et tabsfrit format uden komprimeringsartefakter. WebP (tabsfrit format) opnår tilsvarende resultater med mindre filstørrelser. JPG er også velegnet i de fleste tilfælde, men stærkt komprimerede JPG-filer med mærkbare komprimeringsartefakter forringer outputkvaliteten. Undgå at bruge GIF, BMP eller andre ikke-standardformater. Alle større platforme understøtter JPG, PNG og WebP. Minimumopløsning: 512x512 pixels. Anbefalet: 1024x1024 eller højere.
Kan AI animere alle typer billeder?
AI kan animere de fleste billedtyper, men resultaterne varierer afhængigt af motivet. Portrætter og hovedbilleder giver de bedste resultater – de nuværende modeller er dygtige til at fange naturlige ansigtsudtryk og hårbevægelser. Landskaber og naturlige scener fungerer også exceptionelt godt med overbevisende gengivelser af skybevægelser, strømmende vand og svajende løv. Produktbilleder med ren baggrund giver konsekvent pålidelige resultater. Illustrationer og kunstværker kan animeres, men der kan være behov for skræddersyede stilistiske prompter for at undgå utilsigtet fotorealisme. Komplekse gruppescener, billeder med meget tekst og fotografier af lav kvalitet giver de mindst stabile resultater.
Hvad er forskellen mellem billedgenereret video og tekstgenereret video?
Tekst til video genererer både visuelt indhold og bevægelse samtidigt ud fra tekstbeskrivelser. AI'en dikterer det samlede visuelle udseende, hvilket giver mindre kontrol over specifikke detaljer, men større kreativ frihed. Billede til video bruger dine eksisterende billeder som udgangspunkt og genererer kun bevægelsen. Du bevarer præcis kontrol over det visuelle output, fordi du leverer den visuelle reference. Image-to-Video er typisk mere forudsigeligt og konsistent i resultatet, da AI'en har et konkret visuelt anker. Text-to-Video er bedre egnet til at få AI'en til at skabe helt nyt indhold fra bunden.
Kan Tusheng Video styre kamerabevægelser?
Bestemt. De fleste moderne generative videoværktøjer understøtter styring af kamerabevægelser via tekstprompter. Du kan angive bevægelser som "dolly ind", "panorer til venstre", "kredsløb omkring", "kran op", "zoom ud" og "tracking shot". Seedance 2.0 og Luma Dream Machine reagerer særligt præcist på disse bevægelsesnøgleord. Runway Gen-4 tilbyder yderligere præcision gennem Motion Brush og Director Mode, der muliggør visuel stregning af baner. Det tilrådes kun at angive én bevægelsestype pr. generation, suppleret med hastighedsmodifikatorer såsom "langsomt" eller "stadigt".
Er billedkvaliteten af AI-genererede videoer tilstrækkelig til professionelle anvendelser?
For kortformat videoindhold (5–15 sekunder) er det helt gennemførligt. Output fra førende platforme som Seedance 2.0 og Runway Gen-4 er allerede blevet brugt professionelt til marketing på sociale medier, e-handelsproduktvideoer, ejendomspræsentationer og reklamekoncepter. På det indenlandske marked indeholder væsentlige kommercielle indhold på Douyin og Xiaohongshu nu AI-genererede videoaktiver. Der er dog stadig begrænsninger: længere varigheder øger risikoen for ufuldkommenheder, komplekse scener med flere motiver er stadig ustabile, og tekstgengivelse i videoer er stadig ikke perfekt. Til tv- eller filmproduktioner, der kræver absolut fejlfrihed, er traditionel filmoptagelse stadig det sikreste valg. Til digital markedsføring og indhold på sociale medier har AI-teknologi til konvertering af billeder til video nu nået professionelle standarder.
Resumé
TuSheng Video AI har udviklet sig fra en nyhedsgadget til et uundværligt værktøj til indholdsproduktion. Teknologien er modnet, værktøjerne er blevet brugervenlige, og outputkvaliteten opfylder nu professionelle standarder for langt de fleste digitale indholdsscenarier.
Følgende er de vigtigste punkter:
- Kvaliteten af kildebillederne er afgørende. Skarpe, velkomponerede billeder i høj opløsning giver langt bedre resultater end slørede billeder eller billeder i lav opløsning.
- Skriv bevægelse, ikke beskrivelse. AI'en ser allerede dit billede. Fortæl den, hvordan tingene skal bevæge sig, ikke hvordan de ser ud.
- **Start enkelt. ** Én handling plus én kamerabevægelse. Lær det grundlæggende, før du tilføjer kompleksitet.
- Gentag hurtigt. Generer først korte testklip; producer kun den fulde version, når du er tilfreds.
- **Tilpas værktøjerne til opgaverne. ** Seedance prioriterer visuel troværdighed og multimodal kontrol; KeLing udmærker sig ved lange videoer og overkommelige priser; Runway fokuserer på præcis redigering; Pika lægger vægt på enkelhed og brugervenlighed.
- Vælg det værktøj, der passer til dine behov. Hvis du befinder dig i Kina, kan Seedance og KeLing bruges direkte uden yderligere netværks- eller betalingsbarrierer.
Kløften mellem brands og kreative, der bruger Tusheng Video AI, og deres kolleger, der stadig er afhængige af statiske billeder, bliver større for hver måned, der går. Hvert eneste fotografi i dit produktbibliotek har potentiale som en videoannonce. Hvert portræt kan blive en dynamisk avatar. Hvert landskab kan fungere som filmisk B-roll-optagelse.
Opret din første billed-til-video gratis --> — Upload et hvilket som helst billede og se det komme til live inden for to minutter. Intet kreditkort kræves, direkte tilgængeligt i Kina.
Har du lyst til at udforske flere AI-videofunktioner? Oplev Seedance på alle platforme --> — Tekst til video, video til video, multimodal generering: alt håndteres ét sted.
Yderligere læsning: Seedance Komplet brugervejledning | Seedance Prompt Guide med over 50 eksempler | AI Video Creative Application Cases | Rangliste over de bedste AI-videogeneratorer i 2026 | AI-videomarkedsføring og guide til sociale medier | Tekst-til-video-AI: Komplet guide*
