
Resumo
A IA Image-to-Video utiliza tecnologia de aprendizagem profunda baseada em modelos de difusão para transformar imagens estáticas em vídeos dinâmicos. Ao contrário da geração puramente de texto para vídeo, basta carregar uma fotografia para que a IA gere movimentos realistas, movimentos de câmara e imagens temporalmente coerentes à sua volta, proporcionando-lhe um controlo mais preciso sobre o resultado final. Este guia abordará de forma abrangente: os princípios técnicos por trás da IA Image-to-Video; quais tipos de imagens produzem resultados ótimos; um tutorial de cinco etapas para criar o seu primeiro vídeo do zero; oito casos de uso práticos com exemplos imediatos; técnicas avançadas de controle de movimento; e uma comparação realista das principais ferramentas de 2026 (incluindo aquelas diretamente acessíveis na China). Experimente a IA Image-to-Video gratuitamente -->
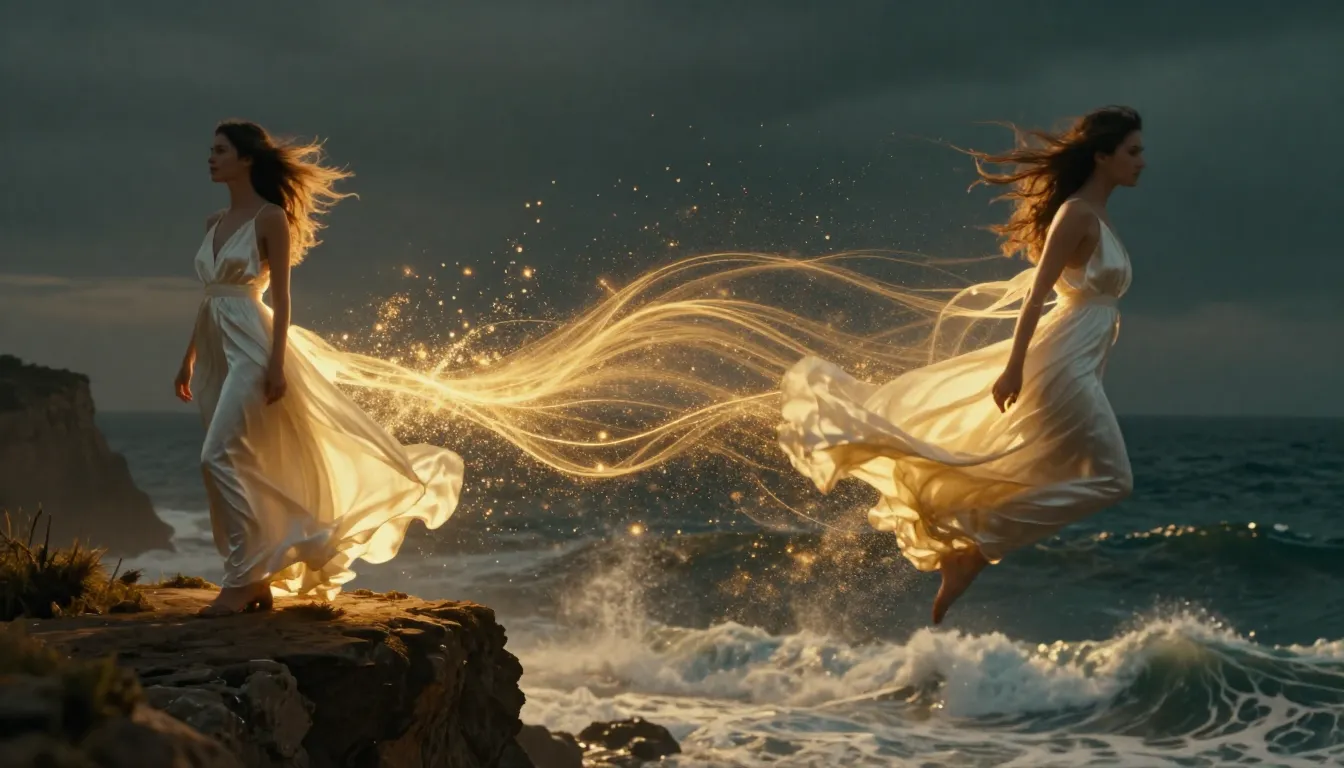
O TuSheng Video AI pega as suas fotografias estáticas e gera movimentos realistas, movimentos de câmara cinematográficos e continuidade temporal — transformando um único fotograma num videoclipe cinematográfico.
O que é o Tusheng Video AI?
A IA Image-to-Video é uma tecnologia de inteligência artificial capaz de gerar vídeos a partir de imagens estáticas. Você fornece uma fotografia — seja um retrato, imagem de produto, paisagem ou obra de arte — e o modelo de IA produz um pequeno vídeo em que os elementos começam a se mover, os ângulos da câmara mudam e toda a cena ganha vida.
Na sua essência, a maioria dos sistemas de vídeo generativo emprega modelos de difusão de vídeo. Estas redes neurais são treinadas com milhões de pares de dados de imagens de vídeo, aprendendo a relação estatística entre fotogramas estáticos e o movimento natural subsequente. Quando apresentado a uma nova imagem, o modelo prevê qual o movimento que parece mais natural e gera uma sequência contínua de fotogramas que faz uma transição suave a partir da fotografia original.
Diferenças entre texto e vídeo
O Text-to-Video gera conteúdo inteiramente a partir de texto. A IA cria simultaneamente conteúdo visual e movimento com base na sua solicitação textual – um processo poderoso, mas imprevisível, já que a IA determina de forma independente a aparência dos objetos, a composição das cenas e todos os padrões de movimento.
O Tusheng Video inverte essa lógica: você fornece a âncora visual. A IA já sabe como é a cena, porque você a mostrou diretamente. A sua única tarefa é gerar um movimento plausível. Isso significa que:
- Maior controlo: as suas imagens definem o tema, a composição, a paleta de cores e o estilo
- Menos suposições: a IA não requer a interpretação de descrições textuais vagas
- Maior consistência: os resultados correspondem fielmente às imagens de origem
- Iteração mais rápida: Ajustar o prompt de movimento é muito mais simples do que reescrever toda a descrição da cena
Por que o vídeo TuSheng é tão importante em 2026
O TuSheng Video AI evoluiu de um brinquedo experimental para uma ferramenta produtiva. Marcas de comércio eletrónico transformam imagens de produtos em anúncios animados, criadores de conteúdo dão vida às suas publicações mais populares, agentes imobiliários criam vídeos de visualização virtual a partir de fotos de imóveis e educadores animam ilustrações de livros didáticos.
Esta tecnologia atingiu um ponto de viragem: vídeos de 5 a 15 segundos gerados a partir de imagens de alta qualidade são agora praticamente indistinguíveis das filmagens tradicionais na maioria dos cenários. É precisamente por isso que a conversão de imagem em vídeo se tornou a categoria de mais rápido crescimento na geração de vídeo por IA.
Essa tendência é particularmente pronunciada no mercado chinês. Algoritmos em plataformas como Douyin, Xiaohongshu, Bilibili e Kuaishou favorecem fortemente o conteúdo de vídeo, criando uma demanda sem precedentes entre os criadores por ferramentas que convertem rapidamente fotografias em vídeos. O Tusheng Video AI atende precisamente a essa lacuna no mercado.
Princípios técnicos da IA de vídeo Tusheng
Compreender o processo técnico ajuda a obter melhores resultados. Quando se sabe por que razão a IA se comporta de determinada forma, é possível fornecer melhores contributos e escrever prompts mais eficazes. Aqui está o processo de quatro etapas que ocorre nos bastidores.

As quatro etapas do pipeline de processamento de IA do Tusheng Video: codificação de imagem, previsão de movimento, geração de quadros e suavização temporal.
Primeiro passo: Codificação da imagem
A IA analisa primeiro a sua imagem de entrada através de uma rede codificadora, comprimindo-a numa representação matemática densa conhecida como vetor latente. Isto pode ser entendido como a IA extraindo uma «impressão digital» da sua imagem — capturando a sua estrutura, cor, profundidade, posicionamento do objeto, direção da iluminação e informações semânticas.
Essa representação latente é consideravelmente mais compacta do que os dados de pixel originais, tornando viáveis os cálculos subsequentes. A qualidade da codificação influencia diretamente os resultados finais. Imagens de entrada com resolução mais alta e mais nítidas geram representações latentes mais ricas, resultando em uma saída de vídeo superior.
Passo dois: previsão de movimento
Este é o núcleo criativo de todo o processo. O modelo de difusão prevê que tipo de movimento pareceria natural com base na sua imagem original, levando em consideração:
- Contexto cénico: Uma fotografia do oceano implica que as ondas devem agitar-se; um retrato sugere uma dinâmica facial subtil
- Informação de profundidade: Os objetos próximos da lente podem apresentar padrões de movimento distintos dos objetos distantes
- Realismo físico: O cabelo deve ondular com o vento, a água deve escorrer para baixo e o tecido deve cair naturalmente
- Sua solicitação de texto: Se especificar "panorâmica lenta para a esquerda", o modelo ajustará sua previsão de movimento de acordo
O modelo não distorce apenas os pixels. Ele gera conteúdo visual totalmente novo para áreas recém-expostas pelo movimento da câmara ou do objeto. Se a câmara fizer uma panorâmica para a direita, o modelo irá «preencher» a cena além da borda direita da imagem original.
Passo três: Geração do quadro
Com base na previsão de movimento, o modelo gera uma sequência de fotogramas de vídeo. Cada fotograma é produzido através de um processo de difusão inversa — começando com ruído, ele é progressivamente refinado até se tornar uma imagem nítida, mantendo a consistência com o fotograma anterior e a imagem original.
O Seedance 2.0 e outros modelos modernos geram a altas taxas de fotogramas (24–30 fps), mantendo a consistência subpixel entre os fotogramas. Isto garante uma saída suave e sem cintilação, sem os problemas de tremulação comuns nos sistemas anteriores.
Passo quatro: Suavização temporal
A etapa final garante transições perfeitas entre todos os fotogramas gerados. O mecanismo de atenção temporal verifica se o brilho, a cor e o movimento permanecem consistentes ao longo de todo o vídeo, evitando artefactos visuais comuns:
- Mudanças repentinas de cor entre os fotogramas
- Aparecimento ou desaparecimento inesperado de objetos
- Aceleração ou desaceleração não natural do movimento
- Tremulação da textura da superfície
O resultado final é um vídeo requintado que flui naturalmente a partir das imagens originais.
Por que algumas imagens têm melhor aparência?
Agora pode compreender por que a qualidade da imagem de entrada é tão crucial. Uma imagem desfocada e de baixa resolução produz uma codificação potencial ruidosa na primeira etapa, fornecendo menos informações ao modelo de previsão de movimento (a segunda etapa). Isso resulta em movimentos menos precisos e mais artefactos visuais na saída final. Por outro lado, uma imagem nítida e bem composta, com pistas de profundidade claras, fornece ao modelo informações ricas, traduzindo-se num vídeo mais natural e de maior qualidade.
Que tipo de imagem produz os melhores resultados?
Nem todas as imagens são adequadas para o TuSheng Video AI. A diferença entre um bom material de origem e um material de origem de baixa qualidade pode muito bem ser a diferença entre um vídeo impressionante e uma pilha de filmagens inutilizáveis. Aqui está um guia prático.

O lado esquerdo exibe imagens de arquivo adequadas (alta resolução, bem compostas, sugerindo movimento natural), enquanto o lado direito mostra imagens de arquivo inadequadas (borradas, desorganizadas, contendo elementos difíceis de processar pela IA).
Tipos de imagens adequados
Alta resolução (1024x1024 ou superior). Mais pixels permitem que o codificador extraia mais detalhes. Utilize sempre a versão com a resolução mais alta disponível. Mínimo recomendado: 512x512 pixels. Ideal: 1024x1024 ou superior.
Os objetos são claramente definidos com contornos distintos. A IA deve discernir o que deve se mover e o que deve permanecer estático. Um retrato em que o objeto está nitidamente separado do fundo produz resultados muito superiores aos de uma cena complexa e caótica com vários objetos.
Bem iluminadas e corretamente expostas. Imagens com boa iluminação fornecem informações precisas sobre cor e profundidade para o modelo. Evite imagens que estejam muito superexpostas ou subexpostas.
Camadas naturais e composição. Imagens com primeiro plano, plano médio e fundo claramente definidos fornecem à IA pistas de profundidade, aumentando o realismo dos efeitos de paralaxe e dos movimentos da câmara.
Imagens que sugerem movimento. Pistas pictóricas de movimento — cabelos esvoaçando ao vento, ondas prestes a quebrar na costa, uma figura caminhando — fornecem ao modelo pontos de partida potentes para prever o movimento. A IA pode discernir "o que acontece a seguir" a partir desses indicadores visuais.
Fundos limpos. Um fundo simples ou naturalmente desfocado produz uma saída de vídeo mais suave do que um fundo desorganizado, cheio de vários objetos pequenos.
Tipos de imagens que podem causar problemas
Imagens desfocadas ou fora de foco. Desfoque na entrada, desfoque na saída. A IA não pode adicionar nitidez que não estava presente na imagem original.
Cenas excessivamente complexas. Imagens que contêm numerosos objetos pequenos, padrões intricados ou confusão visual podem sobrecarregar os modelos de previsão de movimento, tornando-os incapazes de determinar o que deve se mover e como.
Texto extenso ou tipografia. Os modelos de vídeo com IA ainda têm dificuldade em manter a legibilidade do texto entre os fotogramas. Se as suas imagens contiverem logótipos, marcas comerciais ou sobreposições de texto, ocorrerá distorção na saída de vídeo.
Baixa resolução (512x512 ou inferior). Imagens pequenas contêm informações insuficientes. Mesmo ampliá-las com IA antes da inserção é inútil, pois adiciona pixels, mas não informações.
Filtros pesados ou pós-processamento. Ajustes extremos de cor, processamento HDR ou modificações extensas no Photoshop podem confundir a compreensão do modelo sobre iluminação e profundidade.
Vários rostos de tamanhos diferentes. A IA lida com retratos individuais de forma eficaz. Fotos de grupo com rostos a distâncias diferentes produzem animações inconsistentes — alguns rostos parecem naturais, enquanto outros ficam distorcidos.
Lista de verificação pré-upload
Antes de carregar imagens, verifique rapidamente os seguintes pontos:
- Resolução mínima de 1024x1024 pixels
- Assunto claramente definido com separação distinta do fundo
- Exposição correta (nem subexposta nem superexposta)
- Sem filtros pesados, HDR extremo ou processamento artificial visível
- Mínimo de texto, logótipos ou elementos tipográficos
- Complexidade da cena controlada (1–3 objetos principais)
- Formato da imagem: JPG, PNG ou WebP
Assim que essas condições forem atendidas, a geração poderá começar.
Guia passo a passo: crie a sua primeira imagem para vídeo
Siga estes cinco passos para transformar qualquer imagem estática num vídeo animado com IA. Usaremos o Seedance como nossa plataforma de demonstração, embora esses princípios se apliquem a qualquer ferramenta de conversão de imagem em vídeo.
Primeiro passo: selecionar imagens de origem adequadas
A imagem original é o fator mais importante para determinar a qualidade do resultado final. Selecione uma imagem que esteja de acordo com as diretrizes descritas anteriormente. Para a sua primeira tentativa, é aconselhável escolher um retrato simples ou uma paisagem com profundidade acentuada – esses dois tipos de imagens produzem os resultados mais consistentes.
Imagens recomendadas para primeiras tentativas:
- Fotos nítidas do rosto ou retratos de meio corpo com iluminação favorável
- Paisagens com céu, superfícies aquáticas ou vegetação (esses elementos possuem movimento inerente)
- Imagens de produtos contra fundos limpos
- Obras de arte ou ilustrações com elementos claramente definidos
Ao gerar pela primeira vez, evite usar imagens compostas complexas, imagens que contenham grandes quantidades de texto ou fotografias altamente editadas.
Passo dois: Carregar para o Seedance
Abra o Seedance Image-to-Video e carregue as imagens selecionadas. O Seedance suporta os formatos JPG, PNG e WebP. A plataforma analisará automaticamente as suas imagens e prepará-las-á para geração.
Se uma imagem for excepcionalmente grande (com qualquer lado a exceder 4096 píxeis), o sistema irá redimensioná-la automaticamente, mantendo as suas proporções, eliminando a necessidade de ajuste manual.
Passo três: Criar um prompt orientado para a ação
Nesta fase, você informa à IA o movimento desejado. A sua indicação deve descrever a dinâmica, em vez do conteúdo da imagem (a IA já viu a imagem). Concentre-se nos seguintes pontos:
- Movimento do sujeito: O que o sujeito deve fazer?
- Movimento da câmara: Como a câmara deve se mover?
- Movimento ambiental: Que dinâmicas ambientais devem estar presentes?
- Ritmo e clima: Ritmo geral – rápido ou lento?
Exemplos de sugestões para retratos:
The woman slowly turns her head to the right and smiles softly.
A gentle breeze moves her hair. Background slightly out of focus
with subtle bokeh movement. Camera slowly pushes in from medium
shot to a close-up. Warm, natural lighting. Cinematic film quality.Exemplo de prompt paisagem:
Gentle waves roll toward the shore in slow motion. Clouds drift
slowly across the sky from left to right. Sunlight shimmers on
the water surface. Camera slowly pans right, revealing more of
the coastline. Peaceful, serene atmosphere. 4K cinematic quality.Exemplo de sugestão de produto:
The camera slowly orbits around the product, rotating 45 degrees
clockwise. Soft studio lighting with subtle caustic reflections
on the surface. Clean white background with gentle gradient.
Premium commercial aesthetic. Smooth, steady camera movement.Princípio fundamental: Descreva o movimento, não a cena. A cena já existe na sua imagem.
Observação: O Seedance suporta comandos em chinês e inglês, embora os comandos em inglês normalmente proporcionem um controlo mais preciso dos movimentos da câmara. Recomenda-se usar o inglês para descrições relacionadas com movimentos e câmara, enquanto o chinês pode ser usado para descrições de atmosfera e estilo.
Passo quatro: Selecione os parâmetros
Definições de geração de configuração:
| Parâmetro | Valor recomendado | Descrição |
|---|---|---|
| Modelo | Seedance 2.0 | Qualidade de imagem ideal para geração de imagem para vídeo |
| Duração | 5 segundos (para testes iniciais) | Comece com vídeos curtos e, depois, mais longos; crie versões estendidas quando estiver satisfeito |
| Proporção da imagem | Corresponda à imagem | 16:9 para paisagem, 9:16 para retrato, 1:1 para quadrado |
| Resolução | 1080p | Selecione sempre a resolução mais alta disponível |
Técnica avançada: primeiro, gere uma versão de 5 segundos. Se o movimento e o estilo forem satisfatórios, use o mesmo prompt para gerar uma versão mais longa (8 a 15 segundos). Essa abordagem economiza créditos durante a fase de exploração.
Passo cinco: Gerar, verificar, iterar
Clique em Gerar e aguarde de 1 a 3 minutos. Quando os resultados aparecerem, avalie-os de acordo com os seguintes critérios:
- O movimento é fluido e natural?
- O objeto mantém a consistência visual ao longo do vídeo?
- O movimento da câmara está de acordo com as suas expectativas?
- Existem imperfeições visuais (cintilação, distorção, deformação)?
- A qualidade do vídeo corresponde à filmagem original?
Se algum aspeto não estiver satisfatório, ajuste o prompt e regenere. Os métodos de ajuste comuns incluem:
- Muito rápido? Adicione «lentamente», «suavemente», «gradualmente» à descrição do movimento
- Direção errada da câmara? Especifique com mais clareza: «câmara estática, sem movimento da câmara» ou «dolly lento»
- Imperfeições faciais? Simplifique o movimento: reduza o número de ações realizadas simultaneamente
- **Falta de dinamismo? ** Introduza verbos dinâmicos: «balançar», «fluir», «derivar», «mudar»
Após duas ou três rodadas de iteração, obterá um vídeo de alta qualidade que dá vida às suas imagens.
Comece agora mesmo a criar o seu primeiro clipe de imagem para vídeo -->
8 Principais aplicações e exemplos de conversão de imagens grandes em vídeo
O TuSheng Video AI não é um produto com uma única função. Ele serve a dezenas de propósitos criativos e comerciais. Abaixo estão oito cenários de aplicação de alto valor, completos com instruções práticas prontas para serem copiadas e modificadas diretamente.
- Animação de retratos
Dê vida às suas fotos. A animação de retratos é a aplicação mais popular para transformar fotos em vídeos. Carregue uma foto de perfil, selfie ou imagem de personagem e adicione animações sutis e realistas – respirar, piscar, virar a cabeça, mudar de expressão e mover o cabelo.
Adequado para vídeos comemorativos, conteúdo de redes sociais, criação de avatares virtuais e narrativas criativas. No Douyin e no Xiaohongshu, o conteúdo de «fotos que ganham vida» continua a ser um ponto de acesso consistente.

Um retrato estático transforma-se num vídeo vivo — piscadelas naturais, movimentos subtis da cabeça e cabelo esvoaçante, o efeito é surpreendentemente realista.
Exemplo de prompt:
The person looks directly at the camera with a calm, confident
expression. They slowly tilt their head slightly to the left and
give a subtle warm smile. Eyes blink naturally. A soft breeze gently
moves their hair. Shallow depth of field with softly blurred
background. Warm natural lighting. Cinematic portrait quality.- Vitrine de produtos
Transforme fotografias de produtos em conteúdo comercial dinâmico. Isso é revolucionário para marcas de comércio eletrónico e influenciadores – você já possui centenas ou até milhares de imagens de produtos, e agora cada uma delas pode se tornar um anúncio em vídeo, uma imagem em destaque para páginas de detalhes do produto ou um curta-metragem para redes sociais.
Nas páginas de detalhes dos produtos do Taobao e JD.com, nas apresentações de produtos ao vivo do Douyin e nas publicações de recomendações de produtos do Xiaohongshu, as exibições dinâmicas de produtos alcançam consistentemente taxas de conversão significativamente mais altas do que as imagens estáticas.

Uma imagem padrão de produto é elevada ao nível de sofisticação de um anúncio comercial premium — com movimentos de câmara, iluminação dramática e movimentos fluidos —, cuja produção tradicional poderia custar centenas ou milhares de libras.
Exemplo de prompt:
The camera slowly orbits 90 degrees around the product, revealing
its form from multiple angles. Soft directional studio lighting
with subtle caustic reflections on the surface. A gentle highlight
sweep moves across the product. Clean, premium commercial aesthetic.
Shallow depth of field. Ultra-smooth camera movement. 4K quality.3. Time-lapse da paisagem
Transforme fotografias de paisagens em vídeos atmosféricos no estilo time-lapse. Nuvens cruzam o céu, água corre, a luz muda de tons dourados para tons azuis e folhas balançam com a brisa. Ideal para conteúdos de viagens, apresentações aéreas de propriedades e filmagens atmosféricas de B-roll.
Os fotógrafos de paisagens e vloggers de viagens no Bilibili podem transformar diretamente as suas fotografias selecionadas em vídeos time-lapse cativantes, reduzindo significativamente os custos de produção.

Uma fotografia paisagística transformada em um time-lapse cinematográfico — nuvens fluidas, água ondulante e luz e sombra em movimento — criando uma qualidade dinâmica e atmosférica a partir de uma única imagem estática.
Exemplo de prompt:
Time-lapse effect. Clouds move steadily across the sky from left
to right. Water in the foreground ripples and flows gently. Light
shifts subtly as if the sun is moving, creating slowly changing
shadows on the landscape. Trees and grass sway gently in the wind.
Camera remains static on a tripod. Serene, majestic atmosphere.
Cinematic landscape quality.4. Conteúdo das redes sociais
Transforme as suas publicações estáticas com melhor desempenho em conteúdo de vídeo que faça as pessoas pararem de rolar a tela. Os algoritmos de plataformas como TikTok, Xiaohongshu, Bilibili e Kuaishou favorecem fortemente o conteúdo de vídeo — uma publicação de imagem com alto desempenho quase certamente obterá melhor tráfego quando convertida em vídeo.
Para os criadores de conteúdo do Xiaohongshu, um conjunto de publicações com imagens e texto pode ter sua exposição aumentada em 3 a 5 vezes se acompanhado por uma versão em vídeo. O Douyin e o Kuaishou, no entanto, operam inteiramente com vídeo como seu formato de conteúdo principal.
Exemplo de prompt:
Dynamic, attention-grabbing motion. The subject moves confidently
toward the camera with energy and presence. Background elements
shift with parallax depth effect. Quick, punchy camera push-in
that creates impact. Vibrant colors, high contrast. Bold,
eye-catching aesthetic optimized for social media. Vertical 9:16.- Arte e Ilustração Animação
Dê vida a obras de arte, ilustrações, pinturas digitais e designs gráficos. Este cenário de aplicação é muito apreciado por artistas, designers de jogos e equipas criativas que procuram apresentar o seu trabalho de uma forma mais envolvente.
Nas comunidades de arte e anime do Bilibili e do Xiaohongshu, as ilustrações animadas são consideradas conteúdos altamente envolventes. Transformar obras de arte estáticas em vídeos do tipo «papel de parede animado» costuma gerar um número significativamente maior de partilhas e guardas do que as imagens originais.
Exemplo de prompt:
The illustrated scene comes to life with gentle, painterly motion.
Characters move subtly within their positions -- breathing, shifting
weight, small gestures. Background elements like leaves, clouds,
or particles drift slowly. The artistic style is preserved exactly
as painted. Movement is smooth and dreamlike, like a living painting.
Gentle ambient lighting shifts. Fantasy illustration quality.6. Visitas virtuais a imóveis
Transforme fotografias de imóveis em vídeos de visitas virtuais. Os agentes imobiliários podem criar pré-visualizações imersivas utilizando imagens existentes dos imóveis, eliminando a necessidade de contratar equipas de fotografia dedicadas para sessões fotográficas no local.
Para anúncios de imóveis exibidos em plataformas como Beike e Anjuke, bem como promoções de imóveis no WeChat Moments e Xiaohongshu, os vídeos dinâmicos apresentam taxas de conversão de consultas de clientes significativamente mais altas.
Exemplo de prompt:
Smooth virtual walkthrough. The camera glides forward slowly into
the room, revealing the space with a wide-angle perspective.
Natural daylight streams through the windows, casting soft shadows.
Subtle dust particles float in the sunbeams. The camera pans
gently to the left, showing the full room layout. Clean, bright,
aspirational real estate aesthetic. Steady, professional movement.- Mostra de Moda e Estilo
Crie conteúdo de moda dinâmico a partir de fotos de roupas em estúdio. As modelos se movem, os tecidos fluem naturalmente, enquanto o estilo estético de nível editorial é preservado.
Os blogueiros de moda do Xiaohongshu e os vendedores de roupas do Taobao podem converter grandes quantidades de fotos de modelos e imagens de roupas em vídeos dinâmicos, criando uma presença visualmente mais marcante nos feeds de informação.
Exemplo de prompt:
The model strikes a confident pose and then slowly shifts their
weight, creating natural body movement. Fabric of the outfit
flows and catches the light with each subtle motion. Wind effect
gently moves the hair. Camera starts at full body and slowly drifts
upward to a waist-up shot. High-fashion editorial lighting with
strong directional shadows. Vogue magazine aesthetic. Cinematic
slow motion.- Conteúdo educativo e explicativo
Transforme gráficos estáticos, infográficos e ilustrações educativas em apresentações dinâmicas. Conceitos complexos tornam-se mais fáceis de compreender quando colocados em movimento.
Os criadores da Zona de Conhecimento da Bilibili e de várias plataformas educacionais podem transformar materiais didáticos, diagramas e fluxogramas em recursos de vídeo animados, aumentando significativamente a eficácia do ensino e as taxas de retenção dos espectadores.
Exemplo de prompt:
The diagram elements animate sequentially. Arrows begin to flow
in their indicated directions. Labels fade in one by one. Moving
parts of the system activate in logical order, showing the process
step by step. Smooth transitions between stages. Clean, clear
educational style. Elements highlight with subtle glow as they
become active. Professional presentation quality.Um guia completo sobre técnicas de prompt para o vídeo Tusheng
Um prompt bem elaborado é a habilidade mais poderosa para gerar imagens a partir de fotografias. Como a IA já viu a sua imagem, o seu prompt deve concentrar-se inteiramente no movimento e no dinamismo. Aqui estão algumas técnicas que produzem os melhores resultados.
Guia rápido de referência de palavras-chave relacionadas com desporto
Use estas palavras-chave específicas para controlar com precisão o movimento do vídeo.
| Tipo de movimento | Palavras-chave | Efeito | |-------- -|-------|------| | Filmagem: para a frente | aproximação, avanço, aproximação, aproximação | A câmara move-se em direção ao objeto | | Filmagem: para trás | afastamento, recuo, afastamento, afastamento | A câmara afasta-se do objeto | | Toma: Esquerda/Direita | panorâmica para a esquerda, panorâmica para a direita, rastreamento para a esquerda, rastreamento para a direita | A câmara gira ou rastreia horizontalmente | | Toma: Para cima/Para baixo | inclinação para cima, inclinação para baixo, grua para cima, grua para baixo | A câmara gira ou move-se verticalmente | | Toma: Órbita | orbitar, girar, rodar em torno, arco | A câmara gira em torno do objeto | | Câmara: Zoom | ampliar, reduzir, mudança da distância focal | A câmara faz zoom (sem deslocamento) | | Objeto: Micromovimentos | respirar, piscar, mudar o peso, micromovimentos | Movimentos sutis e realistas | | Objeto: Moderado | virar a cabeça, sorrir, gesticular, andar lentamente | Movimento claro, mas controlado | | Objeto: Dinâmico | correr, saltar, dançar, girar, acenar | Movimento de alta energia com todo o corpo | | Ambiente: Suave | brisa, flutuação, oscilação, ondulação, cintilação | Movimento ambiental suave | | Ambiente: Intenso | sopro, rajada, colisão, redemoinho, cascata | Dinâmica ambiental forte | | Paralaxe | paralaxe, mudança de profundidade, movimento de camadas | Primeiro plano/fundo movendo-se em velocidades diferentes |

Diferentes palavras-chave para o movimento da câmara produzem efeitos totalmente distintos. Selecione a sua técnica de movimento da câmara deliberadamente, de acordo com o resultado desejado.
Controlo de velocidade e ritmo
O ritmo do movimento tem um efeito profundo no tom emocional de um vídeo. Utilize os seguintes modificadores:
- Extremamente lento: «quase impercetível», «câmera super lenta», «ritmo glacial» — dramático, contemplativo
- Lento: «lentamente», «suavemente», «gradualmente», «sem pressa» — elegância, qualidade cinematográfica
- Moderado: «constante», «ritmo natural», «à velocidade de caminhada» — realismo, estilo documental
- Rápido: « rapidamente», «vigorosamente», «energicamente», «rápido» — dinâmico, emocionante
- Extremamente rápido: «rápido», «panorâmica rápida», «corte rápido», «explosão de movimento» — tenso, cheio de ação
Técnica avançada: Use a câmera lenta por padrão. Em vídeos gerados por IA, a câmera lenta quase sempre fica melhor do que a câmera rápida. Movimentos rápidos aumentam o risco de imperfeições e inconsistências visuais.
Controlo de movimento independente do fundo e do objeto
Você pode controlar independentemente o que se move e o que permanece imóvel. Essa é uma técnica poderosa para direcionar a atenção do público.
Objeto em movimento, fundo em repouso:
The person walks forward confidently while the background remains
perfectly still. Static camera, no camera movement. Focus entirely
on the subject's motion.Fundo dinâmico, objeto estático:
The person stands completely still, like a statue. Behind them,
clouds drift across the sky, leaves blow in the wind, and city
lights flicker. Only the environment moves.Movimentos separados por ambos os lados:
The person slowly turns their head while the camera simultaneously
dollies in. Background clouds drift in the opposite direction,
creating a sense of depth and dimension.A diferença entre o movimento da câmara e o movimento do objeto
Compreender a diferença entre o movimento da câmara e o movimento do objeto é fundamental para alcançar o efeito desejado.
O movimento da câmara altera a perspetiva e a composição. A cena em si permanece estacionária, enquanto o ponto de vista muda. Utilizado para: revelar o enquadramento, estabelecer a cena e criar ênfase dramática.
O movimento de objetos refere-se ao movimento de elementos dentro de uma cena enquanto a câmara permanece estacionária. É utilizado para: animação de personagens, demonstrações de produtos e dinâmicas do ambiente natural.
Os movimentos combinados utilizam ambos simultaneamente. Esta é a técnica mais cinematográfica, mas também a mais desafiante para a IA executar bem. É aconselhável dominar primeiro um único tipo de movimento e só adicionar o outro quando estiver satisfeito.
Estruturas avançadas de prompt
Para obter os resultados mais previsíveis, organize o seu prompt na seguinte ordem:
- Ação principal — O que o sujeito principal faz
- Movimento da câmara — Como a câmara se move
- Dinâmica ambiental — O que os elementos ambientais fazem
- Velocidade/Ritmo — O tempo de todos os movimentos
- Atmosfera/Clima — Tom emocional
- Melhoria da qualidade visual — Descrição técnica da qualidade visual
Exemplo de utilização desta estrutura:
[Subject] A young woman in a flowing white dress slowly raises
her hand to brush hair from her face.
[Camera] The camera executes a slow, steady dolly in from a
medium shot to a close-up.
[Environment] Cherry blossom petals drift gently through the
air. Soft golden sunlight filters through the trees.
[Speed] All motion is slow and deliberate, almost dreamlike.
[Mood] Romantic, ethereal, peaceful atmosphere.
[Quality] Cinematic shallow depth of field, anamorphic bokeh,
film grain, 4K quality.Comparação das ferramentas de IA de vídeo TuSheng 2026
A concorrência no setor de streaming de vídeo está a intensificar-se. Abaixo está uma análise comparativa das principais plataformas em fevereiro de 2026, com ênfase especial na acessibilidade para utilizadores na China continental.

Os efeitos de processamento da mesma imagem de origem em cinco plataformas diferentes de geração de vídeo. As diferenças na qualidade do movimento, consistência temporal e fidelidade visual são imediatamente evidentes.
| Característica | Seedance 2.0 | Runway Gen-4 | Pika 2.0 | Kling 3.0 | Luma Dream Machine | |------|-------------|-------------|---------|------ ----------|-------------------| | Resolução máxima | 2K (2048x1080) | 4K (upscaled) | 1080p | 1080p | 1080p | | Duração máxima | 15 segundos | 10 segundos | 5 segundos | 2 minutos | 5 segundos | | Opções de entrada | Imagem + Texto + Vídeo + Áudio | Imagem + Texto + Vídeo | Imagem + Texto | Imagem + Texto | Imagem + Texto | | Entrada de múltiplas imagens | Suportado (até 9 imagens) | Não suportado | Não suportado | Não suportado | Não suportado | | Áudio nativo | Suportado (8 idiomas com sincronização labial) | Não suportado | Parcial (efeitos sonoros) | Não suportado | Não suportado | | Controlo da câmara | Baseado em prompts | Pincel de movimento + Modo diretor | Básico | Básico | Baseado em prompts | | Quota gratuita | Disponível (incluída no registo) | Disponível (restrita) | Disponível (restrita) | Disponível (restrita) | Disponível (restrita) | | Preço inicial | ~$9,90/mês | $15/mês | $10/mês | ~$6,99/mês | $9,99/mês | | Acesso à China continental | Acesso direto | VPN necessária | VPN necessária | Acesso direto | VPN necessária | | Mais adequado para | Controlo multimodal, qualidade de imagem | Fluxo de trabalho de edição profissional | Iniciantes, efeitos divertidos | Vídeos longos, alto valor | Sensação cinematográfica, cenas 3D |
Análises detalhadas de cada ferramenta
O Seedance 2.0 é incomparável em termos de flexibilidade de entrada. É a única plataforma que suporta uploads simultâneos de até nove imagens de referência, sincronização labial de entrada de áudio e combinação de todos os modos de entrada numa única geração. Para um controlo máximo sobre a saída de imagem para vídeo, o Seedance oferece o kit de ferramentas mais abrangente. A sua saída com resolução 2K também representa a mais alta entre todas as ferramentas (sem depender de upsampling). Desenvolvido pela ByteDance (empresa-mãe do TikTok), o Seedance é diretamente acessível aos utilizadores na China continental, sem necessidade de VPN ou métodos de pagamento internacionais.
O Runway Gen-4 destaca-se pelo controlo preciso. O Motion Brush permite-lhe «pintar» meticulosamente quais partes de uma imagem devem mover-se e em que direção. Se precisar de precisão cirúrgica em áreas específicas, o Runway é a opção mais poderosa. As desvantagens são o preço mais elevado e as quotas de geração mais baixas. O acesso doméstico requer uma VPN.
O Pika 2.0 é a opção mais acessível. Para novatos que desejam experimentar a geração de imagens para vídeo sem aprender engenharia de prompt, os efeitos com um clique e a interface simplificada do Pika oferecem a menor barreira de entrada. Embora a qualidade da imagem fique aquém das ferramentas premium, ela se mostra perfeitamente adequada para conteúdo social casual. Requer uma VPN para acesso na China continental.
O Kling 3.0 supera completamente os seus concorrentes tanto em tempo de execução como em relação custo-benefício. Se precisar de gerar vídeos longos — 30 segundos, 1 minuto ou até 2 minutos — a partir de uma única imagem, o Kling é a única opção viável. A sua relação preço-qualidade de imagem é excepcionalmente favorável. A sua limitação reside nas opções de entrada restritas (imagem única + texto). Como um produto sob a égide da Kuaishou, o Kling é diretamente acessível na China continental, oferecendo aos utilizadores domésticos outra opção perfeita.
O Luma Dream Machine destaca-se na compreensão espacial. Para paisagens, arquitetura e cenas em que a percepção espacial tridimensional é crucial, o Luma produz os movimentos de câmera e paralaxe mais convincentes. A animação de personagens fica aquém em comparação com os concorrentes. O acesso doméstico requer uma VPN.
Recomendações para utilizadores da China continental
Se estiver na China continental, existem basicamente duas ferramentas de vídeo que podem ser usadas diretamente sem uma VPN:
- Seedance 2.0 — Desenvolvido pela ByteDance, totalmente funcional e pronto a usar, com entrada multimodal + resolução 2K + áudio integrado
- Kling 3.0 — Um produto da Kuaishou, destaca-se na geração de vídeos longos, oferecendo uma excelente relação qualidade/preço
Embora ferramentas estrangeiras como Runway, Pika e Luma possuam características próprias, todas elas exigem acesso a VPN e métodos de pagamento internacionais, o que representa uma barreira maior à sua utilização.
Para criadores de conteúdo em plataformas nacionais como Douyin, Xiaohongshu, Bilibili e Kuaishou, optar por ferramentas diretamente acessíveis na China não só é mais conveniente, como também oferece maior garantia em termos de estabilidade de rede e facilidade de pagamento.
Para uma comparação mais abrangente (incluindo recursos de conversão de texto em vídeo), consulte o nosso Ranking completo dos geradores de vídeo com IA de 2026.
Erros comuns e métodos de correção
Depois de testar milhares de videoclipes, aqui estão os cinco erros mais comuns que observámos, juntamente com medidas corretivas específicas.
- Use imagens de baixa resolução como espaços reservados
O erro cometido: carregar uma imagem pequena e comprimida (como uma miniatura de 400x300 salva do WeChat ou das redes sociais) e esperar uma saída de vídeo em alta definição.
Por que falha: O codificador não consegue extrair informações visuais suficientes de imagens de baixa resolução. A saída herda a desfocagem e, ao mesmo tempo, sobrepõe artefactos de movimento.
Como corrigir: Utilize sempre a versão da imagem com a resolução mais alta. Se apenas estiverem disponíveis imagens com baixa resolução, utilize uma ferramenta de aumento de resolução com IA (como Real-ESRGAN ou Topaz Gigapixel) para melhorar a resolução antes de fazer o upload. O tamanho mínimo recomendado é 1024x1024 pixels.
- Escreva descrições de cenas em vez de descrições de ações
O erro cometido: Escrever sugestões como «A superfície do mar ao pôr do sol, com a luz dourada a brilhar na água». Isto descreve a aparência da imagem — algo que a IA já sabe.
Por que falhou: A IA já codificou a imagem. Descrever o conteúdo da imagem de volta para ela desperdiça espaço de prompt com informações redundantes e não fornece nenhuma orientação para o movimento.
Como revisar: Concentre-se inteiramente no movimento. Reescreva como: «As ondas rolam suavemente em direção à costa. A luz dourada do sol brilha na superfície da água. As nuvens flutuam lentamente da esquerda para a direita. A câmara se move lentamente para a direita, seguindo a linha costeira.»
- Exigir demasiadas ações a serem realizadas simultaneamente
Erro cometido: «A personagem vira a cabeça, acena, caminha para a frente, pega num copo, sorri e dança, enquanto a câmara avança, faz uma panorâmica para a esquerda e inclina-se.»
Por que falha: os modelos atuais de IA não conseguem coordenar de forma fiável mais do que duas ou três ações simultâneas. Prompts sobrecarregados fazem com que o modelo ignore a maioria das instruções ou produza resultados confusos e repletos de erros.
Como editar: Limite cada geração a uma ação principal do sujeito mais um movimento de câmara. Para ações sequenciais complexas, gere vários clipes curtos separadamente antes de editar e juntá-los.
- Ignorar incompatibilidades de proporção de imagem
O erro cometido: carregar uma foto na orientação paisagem 16:9, mas definir a saída para a orientação retrato 9:16, ou vice-versa.
Por que não funciona: a IA recorta drasticamente a sua imagem ou exige o preenchimento de grandes áreas em branco. Nenhuma das duas abordagens produz resultados satisfatórios — o recorte compromete o enquadramento cuidadosamente composto, enquanto o preenchimento de novas regiões extensas introduz inconsistências.
Como corrigir: Certifique-se de que a proporção da imagem de saída corresponde às proporções da imagem original. Use 16:9 para imagens na horizontal e 9:16 para imagens na vertical. Se for necessária uma proporção diferente, recorte a imagem original para as proporções desejadas antes de fazer o upload.
- Esperar um efeito realista de imagens ilustrativas
O erro cometido: carregar uma ilustração de desenho animado ou uma imagem de design plano, esperando que a IA gerasse um vídeo com movimento fotorrealista.
Por que falha: O modelo tenta interpretar estilos artísticos, por vezes introduzindo um realismo indesejado. As ilustrações planas carecem da profundidade e das pistas de iluminação nas quais o modelo se baseia para prever movimentos naturais.
Como corrigir: Se o material original for uma ilustração, indique explicitamente o estilo na instrução: «Mantenha exatamente o estilo artístico ilustrado. Animado num estilo de animação 2D, não fotorrealista. O movimento deve parecer desenhado à mão e pictórico.» Isso instrui o modelo a preservar o estilo artístico em vez de introduzir fotorrealismo.
Perguntas frequentes
Qual ferramenta de IA é mais adequada para gerar vídeos a partir de imagens?
O Seedance 2.0 é a nossa principal recomendação para a geração de imagens para vídeo em 2026. Ele suporta várias entradas de imagem (até 9 imagens de referência), saídas com resolução 2K e oferece a combinação mais flexível de imagens, texto, vídeo e áudio. Além disso, desenvolvido pela ByteDance, o Seedance é diretamente acessível na China continental. Para utilizadores preocupados com o orçamento, o Kling 3.0 oferece excelente qualidade de imagem a um preço mais baixo, também diretamente acessível na China continental. Para iniciantes, o Pika 2.0 possui a interface mais simples. A escolha ideal depende dos seus requisitos específicos — consulte a nossa [tabela de comparação de ferramentas](#2026-year image-to-video AI tool comparison).
O TuSheng Video pode ser usado gratuitamente?
Certamente. Várias plataformas oferecem quotas gratuitas. A Seedance oferece créditos gratuitos a todos os novos utilizadores, sem necessidade de cartão de crédito. A Pika 2.0 e a Luma Dream Machine também oferecem geração gratuita limitada. A HaiLuo AI oferece 10 gerações gratuitas por dia. Estas quotas gratuitas são suficientes para testar a tecnologia e produzir vários vídeos. Se precisar de uso contínuo, os planos pagos são mais económicos. Para mais estratégias de utilização gratuita, consulte o nosso Guia de Utilização Gratuita do Seedance.
Qual é a duração máxima dos vídeos gerados por IA?
Diferentes plataformas têm limites variados. O Kling 3.0 lidera o campo, gerando vídeos de até 2 minutos por imagem. O Seedance 2.0 tem um limite de 15 segundos. O Runway Gen-4 limita-se a 10 segundos. O Pika 2.0 e o Luma Dream Machine limitam os vídeos a 5 segundos. Para a maioria dos cenários de redes sociais e marketing, 5 a 15 segundos representam a duração ideal. Caso seja necessária uma filmagem mais longa, é possível gerar vários clipes curtos para edição e montagem posteriores, ou utilizar o Kling para a geração de vídeos longos com uma única filmagem.
Qual formato de imagem é mais adequado para a geração de vídeos por IA?
O PNG é ideal, pois é um formato sem perdas, livre de artefactos de compressão. O WebP (modo sem perdas) alcança resultados equivalentes com tamanhos de ficheiro menores. O JPG também é adequado na maioria dos casos, mas JPGs altamente comprimidos com artefactos visíveis degradam a qualidade da saída. Evite usar GIF, BMP ou outros formatos não padrão. Todas as principais plataformas suportam JPG, PNG e WebP. Resolução mínima: 512x512 pixels. Recomendado: 1024x1024 ou superior.
A IA pode animar qualquer tipo de imagem?
A IA pode animar a maioria dos tipos de imagens, embora os resultados variem dependendo do assunto. Retratos e fotos de rosto produzem os melhores resultados — os modelos atuais interpretam com precisão os movimentos faciais naturais e o movimento do cabelo. Paisagens e cenas naturais também têm um desempenho excepcionalmente bom, com movimento convincente das nuvens, água corrente e vegetação balançando. Imagens de produtos com fundos limpos produzem resultados consistentemente fiáveis. Ilustrações e obras de arte podem ser animadas, embora possam ser necessárias sugestões de estilo personalizadas para evitar um fotorrealismo indesejado. Cenas de grupo complexas, imagens que contêm texto substancial e fotografias de baixa qualidade produzem os resultados menos estáveis.
Qual é a diferença entre um vídeo gerado a partir de imagens e um vídeo gerado a partir de texto?
Texto para vídeo gera conteúdo visual e movimento simultaneamente a partir de descrições textuais. A IA dita toda a aparência visual, oferecendo menos controlo sobre detalhes específicos, mas maior liberdade criativa. Imagem para vídeo usa as suas imagens existentes como ponto de partida, gerando apenas o movimento. Mantém um controlo preciso sobre o resultado visual, pois fornece a referência visual. O Image-to-Video é normalmente mais previsível e consistente nos resultados, uma vez que a IA tem uma âncora visual concreta. O Text-to-Video é mais adequado para que a IA crie conteúdo totalmente novo a partir do zero.
A Tusheng Video consegue controlar o movimento da câmara?
Certamente. A maioria das ferramentas modernas de vídeo generativo suporta o controlo dos movimentos da câmara através de comandos de texto. É possível especificar movimentos como «dolly in», «pan left», «orbit around», «crane up», «zoom out» e «tracking shot». O Seedance 2.0 e o Luma Dream Machine respondem com particular precisão a estas palavras-chave de movimento. O Runway Gen-4 oferece precisão adicional através do seu Motion Brush e Director Mode, permitindo o desenho visual do percurso para as trajetórias da câmara. É aconselhável especificar apenas um tipo de movimento por geração, complementado com modificadores de velocidade, como «lentamente» ou «de forma constante».
A qualidade de imagem dos vídeos gerados por IA é suficiente para aplicações profissionais?
Para conteúdos de vídeo curtos (5 a 15 segundos), isso é totalmente viável. Os resultados de plataformas de ponta, como Seedance 2.0 e Runway Gen-4, já têm sido utilizados profissionalmente para marketing nas redes sociais, vídeos de produtos de comércio eletrónico, apresentações de imóveis e conceitos publicitários. No mercado interno, conteúdos comerciais substanciais no Douyin e no Xiaohongshu agora incorporam recursos de vídeo gerados por IA. No entanto, as limitações persistem: durações prolongadas aumentam o risco de imperfeições, cenas complexas com vários assuntos permanecem instáveis e a renderização de texto nos vídeos ainda está aquém da perfeição. Para trabalhos de nível cinematográfico ou de transmissão que exigem perfeição absoluta, a filmagem tradicional continua sendo a escolha mais segura. Para marketing digital e conteúdo social, a tecnologia de imagem para vídeo com IA agora atingiu padrões profissionais.
Resumo
O TuSheng Video AI evoluiu de um gadget inovador para uma ferramenta essencial para a criação de conteúdo. A tecnologia amadureceu, as ferramentas tornaram-se fáceis de usar e a qualidade do resultado agora atende aos padrões profissionais para a grande maioria dos cenários de conteúdo digital.
A seguir estão os pontos principais:
- A qualidade da imagem original determina tudo. Imagens nítidas, bem compostas e de alta resolução produzem resultados muito superiores em comparação com alternativas desfocadas ou de baixa resolução.
- Sugira o movimento, não a descrição. A IA já viu a sua imagem. Dê instruções sobre como os objetos devem se mover, não sobre como devem ser.
- **Comece de forma simples. ** Uma ação principal mais um movimento de câmara. Domine o básico antes de adicionar complexidade.
- Itere rapidamente. Gere primeiro clipes de teste curtos; produza a versão completa apenas quando estiver satisfeito.
- **Combine as ferramentas com as tarefas. ** O Seedance prioriza a fidelidade visual e o controlo multimodal, o KeLing se destaca em vídeos longos e acessibilidade, o Runway se concentra na edição precisa, enquanto o Pika enfatiza a simplicidade.
- Selecione a ferramenta que melhor atende às suas necessidades. Se você estiver na China continental, o Seedance e o KeLing são diretamente acessíveis, sem barreiras adicionais de rede ou pagamento.
A diferença entre as marcas e os criadores que utilizam o Tusheng Video AI e os seus pares que ainda dependem de imagens estáticas aumenta a cada mês. Cada fotografia na sua biblioteca de produtos tem potencial para se tornar um anúncio em vídeo. Cada retrato pode se tornar um avatar dinâmico. Cada paisagem pode servir como filmagem cinematográfica de B-roll.
Crie a sua primeira imagem em vídeo gratuitamente --> — Carregue qualquer imagem e veja-a ganhar vida em dois minutos. Não é necessário cartão de crédito, acessível diretamente na China continental.
Quer explorar mais recursos de vídeo com IA? Experimente o Seedance em todas as plataformas --> — Texto para vídeo, vídeo para vídeo, geração multimodal: tudo em um só lugar.
Leitura adicional: Guia completo do utilizador do Seedance | Guia de comandos do Seedance com mais de 50 exemplos | Casos de aplicação criativa de vídeo com IA | Ranking dos melhores geradores de vídeo com IA para 2026 | Guia de marketing de vídeo com IA e redes sociais | IA de texto para vídeo: guia completo*
