
Streszczenie
Technologia Image-to-Video AI wykorzystuje technologię głębokiego uczenia się opartą na modelach dyfuzyjnych do przekształcania statycznych obrazów w dynamiczne filmy. W przeciwieństwie do generowania wyłącznie tekstu do wideo, wystarczy tylko przesłać zdjęcie, aby sztuczna inteligencja wygenerowała realistyczny ruch, ruchy kamery i spójny czasowo materiał filmowy wokół niego, zapewniając bardziej precyzyjną kontrolę nad końcowym rezultatem. W niniejszym przewodniku omówiono kompleksowo: zasady techniczne działania Image-to-Video AI; rodzaje obrazów zapewniające optymalne wyniki; pięciostopniowy samouczek tworzenia pierwszego filmu od podstaw; osiem praktycznych przykładów zastosowań wraz z przykładowymi poleceniami; zaawansowane techniki sterowania ruchem; oraz porównanie wiodących narzędzi z 2026 r. (w tym tych dostępnych bezpośrednio w Chinach). Wypróbuj Image-to-Video AI za darmo -->
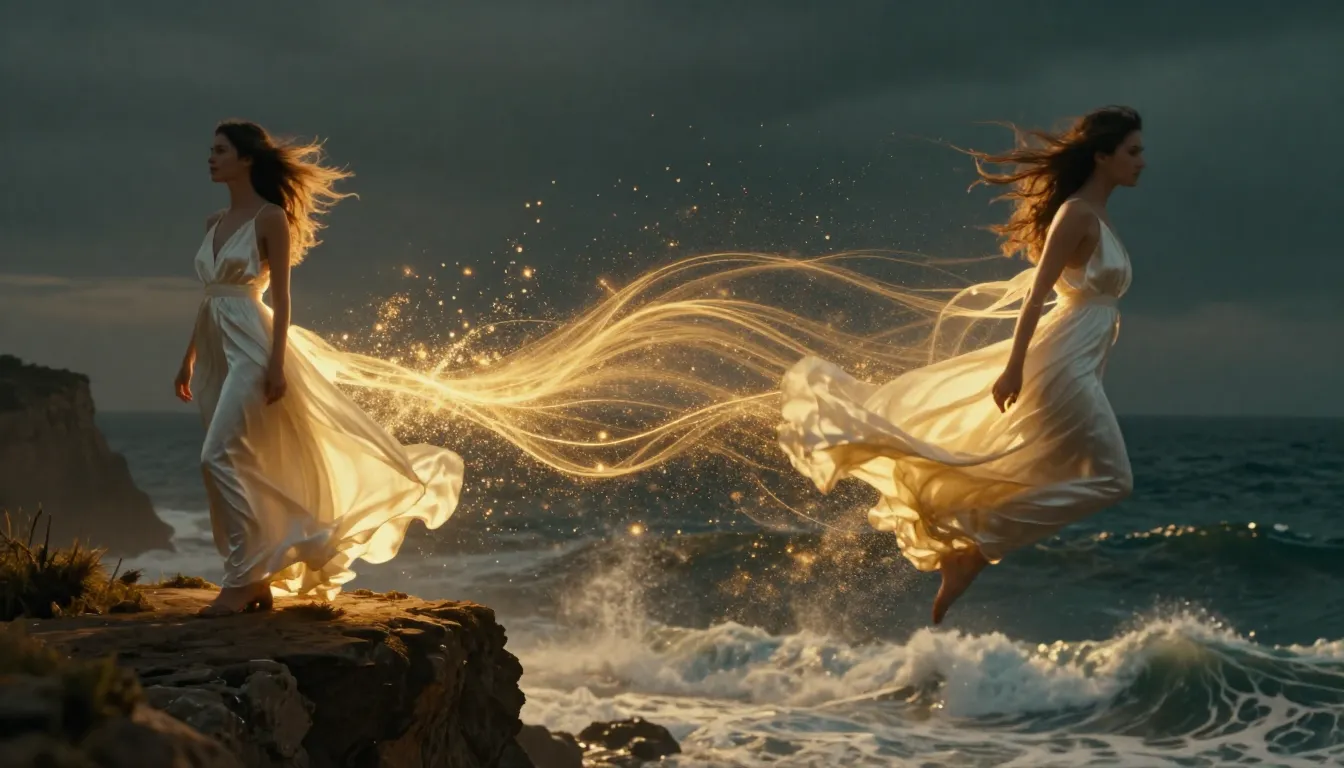
TuSheng Video AI wykorzystuje Twoje zdjęcia i generuje realistyczny ruch, kinowe ruchy kamery i ciągłość czasową — przekształcając pojedynczą klatkę w kinowy klip wideo.
Czym jest Tusheng Video AI?
Image-to-Video AI to technologia sztucznej inteligencji umożliwiająca generowanie filmów na podstawie statycznych obrazów. Użytkownik dostarcza zdjęcie – portret, zdjęcie produktu, krajobraz lub dzieło sztuki – a model AI tworzy krótki film, w którym elementy zaczynają się poruszać, kamera zmienia perspektywę, a cała scena ożywa.
W większości generatywnych systemów wideo wykorzystuje się modele dyfuzji wideo. Sieci neuronowe są trenowane na milionach par danych obrazów wideo, ucząc się statystycznych zależności między statycznymi klatkami a naturalnym ruchem. Po przedstawieniu nowego obrazu model przewiduje, jaki ruch będzie wyglądał najbardziej naturalnie, i generuje ciągłą sekwencję klatek, która płynnie przechodzi z oryginalnego zdjęcia.
Różnice w stosunku do tekstu do wideo
Text-to-Video generuje treści wyłącznie na podstawie tekstu. Sztuczna inteligencja jednocześnie tworzy zarówno treści wizualne, jak i ruch na podstawie podanego tekstu — jest to potężny, ale nieprzewidywalny proces, ponieważ sztuczna inteligencja samodzielnie określa wygląd obiektów, kompozycję scen i wszystkie wzorce ruchu.
Tusheng Video odwraca tę logikę do góry nogami: to Ty dostarczasz wizualną kotwicę. Sztuczna inteligencja już wie, jak wygląda scena, ponieważ pokazałeś ją bezpośrednio. Jej jedynym zadaniem jest wygenerowanie wiarygodnego ruchu. Oznacza to, że:
- Większa kontrola: Twoje obrazy określają temat, kompozycję, paletę kolorów i styl
- Mniej domysłów: Sztuczna inteligencja nie wymaga interpretacji niejasnych opisów tekstowych
- Większa spójność: Wyniki są bardzo zbliżone do obrazów źródłowych
- Szybsza iteracja: Dostosowanie podpowiedzi ruchu jest znacznie prostsze niż przepisywanie całego opisu sceny
Dlaczego film „TuSheng” ma tak duże znaczenie w 2026 roku?
TuSheng Video AI przekształciło się z eksperymentalnej zabawki w produktywne narzędzie. Marki e-commerce przekształcają zdjęcia produktów w animowane reklamy, twórcy treści ożywiają swoje najpopularniejsze posty, agenci nieruchomości tworzą wirtualne filmy z zdjęć nieruchomości, a nauczyciele ożywiają ilustracje z podręczników.
Technologia ta osiągnęła punkt zwrotny — filmy trwające od 5 do 15 sekund, generowane na podstawie wysokiej jakości obrazów źródłowych, są obecnie praktycznie nie do odróżnienia od tradycyjnych materiałów filmowych w większości scenariuszy. Właśnie dlatego konwersja obrazów na filmy stała się najszybciej rozwijającą się kategorią w ramach generowania filmów przez sztuczną inteligencję.
Tendencja ta jest szczególnie widoczna na rynku chińskim. Algorytmy platform takich jak Douyin, Xiaohongshu, Bilibili i Kuaishou zdecydowanie preferują treści wideo, co powoduje bezprecedensowy popyt wśród twórców na rozwiązania umożliwiające szybką konwersję zdjęć na filmy. Tusheng Video AI precyzyjnie wypełnia tę lukę na rynku.
Zasady techniczne działania sztucznej inteligencji Tusheng Video
Zrozumienie procesu technicznego pomaga osiągnąć lepsze wyniki. Wiedząc, dlaczego sztuczna inteligencja zachowuje się w określony sposób, można zapewnić lepsze dane wejściowe i tworzyć bardziej skuteczne polecenia. Oto czterostopniowy proces, który zachodzi za kulisami.

Cztery etapy przetwarzania wideo AI Tusheng: kodowanie obrazu, przewidywanie ruchu, generowanie klatek i wygładzanie czasowe.
Krok pierwszy: Kodowanie obrazu
Sztuczna inteligencja najpierw analizuje wprowadzony obraz za pomocą sieci kodera, kompresując go do postaci gęstej reprezentacji matematycznej znanej jako wektor utajniony. Można to rozumieć jako wyodrębnienie przez sztuczną inteligencję „odcisku palca” obrazu – uchwycenie jego struktury, koloru, głębi, położenia obiektu, kierunku oświetlenia i informacji semantycznych.
Ta ukryta reprezentacja jest znacznie bardziej zwarta niż oryginalne dane pikselowe, co umożliwia przeprowadzenie dalszych obliczeń. Jakość kodowania ma bezpośredni wpływ na wyniki wyjściowe. Obrazy wejściowe o wyższej rozdzielczości i większej ostrości generują bogatsze ukryte reprezentacje, co ostatecznie zapewnia lepszą jakość wyjściowego obrazu wideo.
Krok drugi: przewidywanie ruchu
Jest to kreatywny rdzeń całego procesu. Model dyfuzji przewiduje, jaki rodzaj ruchu będzie wyglądał naturalnie na podstawie oryginalnego obrazu, biorąc pod uwagę:
- Wskazówki kontekstowe: zdjęcie oceanu sugeruje, że fale powinny się wzburzać; portret sugeruje subtelne ruchy twarzy
- Informacje o głębi: obiekty znajdujące się bliżej aparatu mogą wykazywać inne wzorce ruchu niż obiekty odległe
- Fizyczna wiarygodność: Włosy powinny powiewać na wietrze, woda powinna spływać w dół, a tkanina powinna układać się naturalnie
- Twój tekst: Jeśli określisz „powolny ruch w lewo”, model odpowiednio dostosuje swoje przewidywania ruchu.
Model nie tylko zniekształca piksele. Generuje on całkowicie nową zawartość wizualną dla obszarów nowo odsłoniętych przez ruch kamery lub obiektu. Jeśli kamera przesunie się w prawo, model „wypełni” scenę poza prawą krawędzią oryginalnego obrazu.
Krok trzeci: Generowanie ramki
W oparciu o przewidywanie ruchu model generuje sekwencję klatek wideo. Każda klatka jest tworzona w procesie odwrotnej dyfuzji — zaczynając od szumu, stopniowo ulega ona udoskonaleniu, uzyskując wyraźny obraz, przy jednoczesnym zachowaniu spójności z poprzednią klatką i oryginalnym obrazem.
Seedance 2.0 i inne nowoczesne modele generują obrazy z dużą częstotliwością klatek (24–30 klatek na sekundę), zachowując spójność subpikselową między klatkami. Zapewnia to płynny obraz bez migotania i drgań, które były powszechnym problemem we wcześniejszych systemach.
Krok czwarty: Wygładzanie czasowe
Ostatni krok zapewnia płynne przejścia między wszystkimi wygenerowanymi klatkami. Mechanizm uwagi czasowej weryfikuje, czy jasność, kolor i ruch pozostają spójne w całym filmie, zapobiegając powstawaniu typowych artefaktów wizualnych:
- Nagłe zmiany kolorów między klatkami
- Nieoczekiwane pojawianie się lub znikanie obiektów
- Nienaturalne przyspieszenie lub spowolnienie ruchu
- Migotanie tekstury powierzchni
Efektem końcowym jest znakomity film, który płynnie wynika z oryginalnego materiału filmowego.
Dlaczego niektóre obrazy wyglądają lepiej?
Teraz można zrozumieć, dlaczego jakość obrazu wejściowego jest tak istotna. Niewyraźny obraz o niskiej rozdzielczości powoduje zakłócenia w kodowaniu w pierwszym etapie, dostarczając mniej informacji do modelu przewidywania ruchu (drugi etap). Skutkuje to mniej precyzyjnym ruchem i większą liczbą artefaktów wizualnych w końcowym wyniku. Natomiast ostry, dobrze skomponowany obraz z wyraźnymi wskazówkami głębi dostarcza modelowi bogatych informacji, co przekłada się na bardziej naturalny obraz wideo o wyższej jakości.
Jaki rodzaj obrazu daje najlepsze wyniki?
Nie wszystkie obrazy nadają się do wykorzystania w TuSheng Video AI. Różnica między dobrym a złym materiałem źródłowym może stanowić różnicę między oszałamiającym filmem a stosem bezużytecznych ujęć. Oto praktyczny przewodnik.

Po lewej stronie wyświetlane są odpowiednie obrazy źródłowe (o wysokiej rozdzielczości, dobrze skomponowane, sugerujące naturalny ruch), natomiast po prawej stronie wyświetlane są nieodpowiednie obrazy źródłowe (rozmyte, zagracone, zawierające elementy trudne do przetworzenia przez sztuczną inteligencję).
Odpowiednie typy obrazów
Wysoka rozdzielczość (1024x1024 lub wyższa). Większa liczba pikseli pozwala koderowi uzyskać większą szczegółowość. Zawsze należy korzystać z wersji o najwyższej dostępnej rozdzielczości. Minimalna zalecana rozdzielczość: 512x512 pikseli. Idealna rozdzielczość: 1024x1024 lub wyższa.
Obiekty są wyraźnie zdefiniowane, kontury ostro zaznaczone. Sztuczna inteligencja musi rozróżniać, co powinno się poruszać, a co pozostać statyczne. Portret, na którym obiekt jest wyraźnie oddzielony od tła, daje znacznie lepsze wyniki niż złożona, chaotyczna scena grupowa.
Dobrze oświetlone i prawidłowo naświetlone. Zdjęcia z dobrym oświetleniem zapewniają dokładne informacje o kolorze i głębi modelu. Należy unikać zdjęć, które są mocno prześwietlone lub niedoświetlone.
Naturalne nakładanie warstw i kompozycja. Obrazy z wyraźnie zdefiniowanym pierwszym planem, środkowym planem i tłem dostarczają sztucznej inteligencji wskazówek dotyczących głębi, zwiększając realizm efektów paralaksy i ruchów kamery.
Obrazy sugerujące ruch. Wizualne wskazówki dotyczące ruchu — włosy powiewające na wietrze, fale uderzające o brzeg, postać idąca przed siebie — stanowią dla modelu potężny punkt wyjścia do przewidywania ruchu. Sztuczna inteligencja potrafi rozpoznać „co będzie dalej” na podstawie tych wizualnych wskaźników.
Czyste tło. Proste lub naturalnie rozmyte tło zapewnia płynniejszy obraz wideo niż zagraconie tło wypełnione licznymi małymi obiektami.
Typy obrazów, które mogą powodować problemy
Rozmyte lub nieostre obrazy. Rozmycie na wejściu, rozmycie na wyjściu. Sztuczna inteligencja nie może dodać ostrości, której nie było w oryginalnym obrazie.
Nadmiernie złożone sceny. Obrazy zawierające wiele małych obiektów, skomplikowane wzory lub wizualny bałagan mogą przeciążać modele przewidywania ruchu, uniemożliwiając im określenie, co powinno się poruszać i w jaki sposób.
Obszerny tekst lub typografia. Modele wideo oparte na sztucznej inteligencji nadal mają trudności z zachowaniem czytelności tekstu w poszczególnych klatkach. Jeśli obrazy zawierają logo, znaki firmowe lub nakładki tekstowe, w wyjściowym materiale wideo wystąpią zniekształcenia.
Niska rozdzielczość (512x512 lub niższa). Małe obrazy zawierają niewystarczającą ilość informacji. Nawet powiększanie ich za pomocą sztucznej inteligencji przed wprowadzeniem okazuje się bezcelowe — dodaje pikseli, ale nie informacji.
Ciężkie filtry lub przetwarzanie końcowe. Ekstremalne korekty kolorów, przetwarzanie HDR lub rozległe modyfikacje w programie Photoshop mogą utrudniać modelowi zrozumienie oświetlenia i głębi.
Wiele twarzy o różnych rozmiarach. Sztuczna inteligencja skutecznie radzi sobie z pojedynczymi portretami. Zdjęcia grupowe z twarzami w różnych odległościach powodują niespójne animacje — niektóre twarze wyglądają naturalnie, a inne są zniekształcone.
Lista kontrolna do samodzielnej weryfikacji przed przesłaniem
Przed przesłaniem zdjęć należy szybko sprawdzić następujące kwestie:
- Minimalna rozdzielczość 1024x1024 pikseli
- Wyraźnie zdefiniowany obiekt, wyraźnie oddzielony od tła
- Prawidłowa ekspozycja (ani niedoświetlona, ani prześwietlona)
- Brak silnych filtrów, ekstremalnego HDR lub widocznej sztucznej obróbki
- Minimalna ilość tekstu, logo lub elementów typograficznych
- Kontrolowana złożoność sceny (1–3 główne obiekty)
- Format obrazu: JPG, PNG lub WebP
Po spełnieniu tych warunków można rozpocząć generowanie.
Przewodnik krok po kroku: Stwórz swój pierwszy obraz do wideo
Wykonaj pięć poniższych kroków, aby przekształcić dowolny statyczny obraz w animowany film AI. Jako platformę demonstracyjną wykorzystamy Seedance, ale zasady te mają zastosowanie do każdego narzędzia do przekształcania obrazów w filmy.
Krok pierwszy: Wybór odpowiednich obrazów źródłowych
Obraz źródłowy jest najważniejszym czynnikiem decydującym o jakości wydruku. Wybierz obraz zgodny z wytycznymi opisanymi wcześniej. Do pierwszej próby zalecamy wybór prostego portretu lub krajobrazu o wyraźnej głębi – te dwa rodzaje obrazów dają najbardziej spójne wyniki.
Zalecane zdjęcia dla początkujących: – wyraźne zdjęcie twarzy lub portret do połowy ciała w dobrym oświetleniu – krajobrazy z niebem, powierzchnią wody lub roślinnością (elementy te charakteryzują się naturalnym ruchem) – zdjęcia produktów na czystym tle – grafiki lub ilustracje z wyraźnie zarysowanymi elementami
Podczas generowania po raz pierwszy należy unikać stosowania złożonych kolaży, obrazów zawierających duże ilości tekstu lub zdjęć poddanych znacznej obróbce.
Krok drugi: Prześlij do Seedance
Otwórz Seedance Image-to-Video i prześlij wybrane zdjęcia. Seedance obsługuje formaty JPG, PNG i WebP. Platforma automatycznie przeanalizuje Twoje zdjęcia i przygotuje je do generowania.
Jeśli obraz jest wyjątkowo duży (którykolwiek z boków przekracza 4096 pikseli), system automatycznie go przeskaluje, zachowując proporcje, co eliminuje konieczność ręcznej regulacji.
Krok trzeci: Tworzenie polecenia zorientowanego na działanie
Na tym etapie informujesz sztuczną inteligencję o pożądanym ruchu. Twoja wskazówka powinna opisywać dynamikę, a nie zawartość obrazu (sztuczna inteligencja widziała już obraz). Skoncentruj się na następujących kwestiach:
- Ruch podmiotu: Co powinien zrobić podmiot?
- Ruch kamery: Jak powinna poruszać się kamera?
- Ruch otoczenia: Jakie dynamiczne elementy otoczenia powinny być obecne?
- Tempo i nastrój: Czy ogólne tempo powinno być szybkie czy wolne?
Przykłady podpowiedzi dotyczących portretów:
The woman slowly turns her head to the right and smiles softly.
A gentle breeze moves her hair. Background slightly out of focus
with subtle bokeh movement. Camera slowly pushes in from medium
shot to a close-up. Warm, natural lighting. Cinematic film quality.Przykładowy komunikat dotyczący krajobrazu:
Gentle waves roll toward the shore in slow motion. Clouds drift
slowly across the sky from left to right. Sunlight shimmers on
the water surface. Camera slowly pans right, revealing more of
the coastline. Peaceful, serene atmosphere. 4K cinematic quality.Przykład podpowiedzi produktu:
The camera slowly orbits around the product, rotating 45 degrees
clockwise. Soft studio lighting with subtle caustic reflections
on the surface. Clean white background with gentle gradient.
Premium commercial aesthetic. Smooth, steady camera movement.Podstawowa zasada: Opisuj ruch, a nie scenę. Scena już istnieje w Twoim obrazie.
Uwaga: Seedance obsługuje zarówno chińskie, jak i angielskie polecenia, chociaż polecenia w języku angielskim zazwyczaj zapewniają bardziej precyzyjną kontrolę ruchu kamery. Zaleca się używanie języka angielskiego do opisów związanych z ruchem i kamerą, natomiast język chiński może być stosowany do opisów atmosfery i stylu.
Krok czwarty: Wybierz parametry
Skonfiguruj ustawienia generowania:
| Parametr | Zalecana wartość | Opis |
|---|---|---|
| Model | Seedance 2.0 | Optymalna jakość obrazu do generowania obrazu do wideo |
| Czas trwania | 5 sekund (dla początkowych prób) | Zacznij od krótkiego, a następnie wydłuż; po uzyskaniu satysfakcjonującego wyniku wygeneruj wersje rozszerzone |
| Proporcje obrazu | Dopasuj do obrazu | 16:9 dla orientacji poziomej, 9:16 dla orientacji pionowej, 1:1 dla orientacji kwadratowej |
| Rozdzielczość | 1080p | Zawsze wybieraj najwyższą dostępną rozdzielczość |
Zaawansowana technika: Najpierw wygeneruj wersję trwającą 5 sekund. Jeśli ruch i styl są zadowalające, użyj tego samego polecenia, aby wygenerować dłuższą wersję (8–15 sekund). Takie podejście pozwala zaoszczędzić kredyty podczas fazy eksploracji.
Krok piąty: Generowanie, sprawdzanie, powtarzanie
Kliknij Generuj i poczekaj 1–3 minuty. Po wyświetleniu wyników oceń je według następujących kryteriów:
- Czy ruch jest płynny i naturalny?
- Czy obiekt zachowuje spójność wizualną przez cały czas?
- Czy ruch kamery jest zgodny z Twoimi oczekiwaniami?
- Czy występują jakieś niedoskonałości wizualne (migotanie, zniekształcenia, deformacje)?
- Czy jakość wideo odpowiada oryginalnemu materiałowi filmowemu?
Jeśli którykolwiek aspekt okaże się niezadowalający, dostosuj monit i wygeneruj ponownie. Typowe metody dostosowywania obejmują:
- Za szybko? Dodaj „powoli”, „delikatnie”, „stopniowo” do opisu ruchu
- Niewłaściwy kierunek kamery? ** Określ to jaśniej: „statyczna kamera, bez ruchu kamery” lub „powolne zbliżenie”
- Niedoskonałości twarzy? Uprość ruch: zmniejsz liczbę czynności wykonywanych jednocześnie
- **Brak dynamiki? ** Wprowadź dynamiczne czasowniki: „kołysanie się”, „płynąć”, „dryfować”, „przesuwać się”
Po dwóch lub trzech rundach iteracji uzyskasz wysokiej jakości film, który ożywi Twoje zdjęcia.
Zacznij tworzyć swój pierwszy klip wideo z obrazu już teraz -->
8 głównych zastosowań i przykładów konwersji obrazów do formatu wideo na dużą skalę
TuSheng Video AI nie jest narzędziem o jednym zastosowaniu. Służy do dziesiątek kreatywnych i komercyjnych celów. Poniżej znajduje się osiem scenariuszy zastosowań o wysokiej wartości, wraz z praktycznymi wskazówkami gotowymi do bezpośredniego skopiowania i modyfikacji.
- Animacja portretowa
Ożyw swoje zdjęcia. Animacja portretów to najpopularniejsza aplikacja do przekształcania zdjęć w filmy. Prześlij zdjęcie profilowe, selfie lub obraz postaci, a następnie dodaj subtelne, realistyczne animacje – oddychanie, mruganie, obracanie głowy, zmiana wyrazu twarzy i ruch włosów.
Nadaje się do filmów pamiątkowych, treści w mediach społecznościowych, tworzenia wirtualnych awatarów i kreatywnego opowiadania historii. W serwisach Douyin i Xiaohongshu treści typu „zdjęcia ożywione” pozostają niezmiennym magnesem przyciągającym ruch.

Statyczny portret przekształca się w realistyczny film — naturalne mrugnięcia, subtelne ruchy głowy i powiewające włosy, dając nieoczekiwanie realistyczne rezultaty.
Przykładowe polecenie:
The person looks directly at the camera with a calm, confident
expression. They slowly tilt their head slightly to the left and
give a subtle warm smile. Eyes blink naturally. A soft breeze gently
moves their hair. Shallow depth of field with softly blurred
background. Warm natural lighting. Cinematic portrait quality.- Prezentacja produktów
Zmień zdjęcia produktów w dynamiczne treści reklamowe. To rewolucyjne rozwiązanie dla marek e-commerce i influencerów – masz już setki, a nawet tysiące zdjęć produktów, a teraz każde z nich może stać się reklamą wideo, zdjęciem prezentowanym na stronach szczegółowych produktów lub krótkim filmem w mediach społecznościowych.
Na stronach szczegółów produktów w serwisach Taobao i JD.com, w prezentacjach produktów transmitowanych na żywo w serwisie Douyin oraz w postach z rekomendacjami produktów w serwisie Xiaohongshu dynamiczne wyświetlanie produktów konsekwentnie osiąga znacznie wyższe współczynniki konwersji niż statyczne obrazy.

Standardowy obraz produktu zostaje podniesiony do poziomu wyrafinowanej reklamy komercyjnej — z panoramowaniem kamery, efektownym oświetleniem i płynnymi ruchami — tradycyjnej produkcji, która może kosztować od kilkuset do kilku tysięcy funtów.
Przykładowe polecenie:
The camera slowly orbits 90 degrees around the product, revealing
its form from multiple angles. Soft directional studio lighting
with subtle caustic reflections on the surface. A gentle highlight
sweep moves across the product. Clean, premium commercial aesthetic.
Shallow depth of field. Ultra-smooth camera movement. 4K quality.3. Malowniczy film poklatkowy
Zmień zdjęcia krajobrazowe w klimatyczne filmy poklatkowe. Chmury przemykają po niebie, woda płynie, światło zmienia się ze złocistego na niebieskawe, a liście kołyszą się na wietrze. Idealne do treści podróżniczych, prezentacji nieruchomości z lotu ptaka i klimatycznych materiałów filmowych B-roll.
Fotografowie krajobrazów i vlogerzy podróżniczy na Bilibili mogą bezpośrednio przekształcać swoje wyselekcjonowane zdjęcia w fascynujące filmy poklatkowe, znacznie obniżając koszty produkcji.

Fotografia krajobrazu przekształcona w filmowy film poklatkowy — płynące chmury, falująca powierzchnia wody oraz zmieniające się światło i cień — tworzą dynamiczny, nastrojowy efekt z pojedynczego statycznego obrazu.
Przykładowe polecenie:
Time-lapse effect. Clouds move steadily across the sky from left
to right. Water in the foreground ripples and flows gently. Light
shifts subtly as if the sun is moving, creating slowly changing
shadows on the landscape. Trees and grass sway gently in the wind.
Camera remains static on a tripod. Serene, majestic atmosphere.
Cinematic landscape quality.4. Treści w mediach społecznościowych
Zmień swoje najpopularniejsze posty statyczne w treści wideo, które sprawią, że ludzie przestaną przewijać stronę. Algorytmy platform takich jak TikTok, Xiaohongshu, Bilibili i Kuaishou zdecydowanie faworyzują treści wideo — popularny post z obrazkiem prawie na pewno zyska większy ruch, jeśli zostanie przekształcony w film.
W przypadku twórców treści Xiaohongshu zestaw postów zawierających zdjęcia i tekst może zyskać od 3 do 5 razy większą widoczność, jeśli towarzyszy im wersja wideo. Natomiast Douyin i Kuaishou działają wyłącznie w oparciu o format wideo jako podstawową formę treści.
Przykładowy komunikat:
Dynamic, attention-grabbing motion. The subject moves confidently
toward the camera with energy and presence. Background elements
shift with parallax depth effect. Quick, punchy camera push-in
that creates impact. Vibrant colors, high contrast. Bold,
eye-catching aesthetic optimized for social media. Vertical 9:16.- Animacja sztuki i ilustracji
Ożyw dzieła sztuki, ilustracje, obrazy cyfrowe i projekty graficzne. Ten scenariusz zastosowania jest bardzo popularny wśród artystów, projektantów gier i zespołów kreatywnych, którzy chcą zaprezentować swoje prace w bardziej atrakcyjny sposób.
W społecznościach artystycznych i anime Bilibili i Xiaohongshu animowane ilustracje są bardzo popularną treścią. Przekształcanie statycznych grafik w filmy w stylu „żywych tapet” często skutkuje znacznie większą liczbą udostępnień i zapisów niż w przypadku oryginalnych obrazów.
Przykładowe polecenie:
The illustrated scene comes to life with gentle, painterly motion.
Characters move subtly within their positions -- breathing, shifting
weight, small gestures. Background elements like leaves, clouds,
or particles drift slowly. The artistic style is preserved exactly
as painted. Movement is smooth and dreamlike, like a living painting.
Gentle ambient lighting shifts. Fantasy illustration quality.6. Wirtualne oglądanie nieruchomości
Przekształć zdjęcia nieruchomości w wirtualne filmy prezentacyjne. Agenci nieruchomości mogą tworzyć wciągające podglądy przy użyciu istniejących zdjęć nieruchomości, eliminując potrzebę organizowania specjalnych zespołów fotograficznych do sesji zdjęciowych na miejscu.
W przypadku ofert nieruchomości wyświetlanych na platformach takich jak Ke.com i Anjuke, a także promocji nieruchomości w WeChat Moments i Xiaohongshu, dynamiczne filmy prezentacyjne wykazują znacznie wyższy współczynnik konwersji zapytań klientów.
Przykładowe polecenie:
Smooth virtual walkthrough. The camera glides forward slowly into
the room, revealing the space with a wide-angle perspective.
Natural daylight streams through the windows, casting soft shadows.
Subtle dust particles float in the sunbeams. The camera pans
gently to the left, showing the full room layout. Clean, bright,
aspirational real estate aesthetic. Steady, professional movement.- Prezentacja mody i stylizacji
Twórz dynamiczne treści modowe na podstawie zdjęć strojów wykonanych w studiu. Modelki poruszają się, tkaniny układają się naturalnie, a estetyczny styl redaktorski pozostaje nienaruszony.
Blogerzy modowi z Xiaohongshu i sprzedawcy odzieży z Taobao mogą przekształcić ogromne ilości istniejących zdjęć modelek i płaskich ujęć stylizacji w dynamiczne filmy prezentacyjne, tworząc bardziej efektowny wizualnie przekaz w kanałach informacyjnych.
Przykładowe polecenie:
The model strikes a confident pose and then slowly shifts their
weight, creating natural body movement. Fabric of the outfit
flows and catches the light with each subtle motion. Wind effect
gently moves the hair. Camera starts at full body and slowly drifts
upward to a waist-up shot. High-fashion editorial lighting with
strong directional shadows. Vogue magazine aesthetic. Cinematic
slow motion.- Treści edukacyjne i wyjaśniające
Zmień statyczne wykresy, infografiki i ilustracje edukacyjne w dynamiczne prezentacje. Złożone koncepcje stają się łatwiejsze do zrozumienia, gdy są przedstawione w formie ruchomej.
Twórcy w strefie wiedzy Bilibili i na różnych platformach edukacyjnych mogą przekształcać materiały szkoleniowe, diagramy i schematy blokowe w animowane materiały wideo, co znacznie zwiększa skuteczność nauczania i wskaźniki retencji widzów.
Przykładowe polecenie:
The diagram elements animate sequentially. Arrows begin to flow
in their indicated directions. Labels fade in one by one. Moving
parts of the system activate in logical order, showing the process
step by step. Smooth transitions between stages. Clean, clear
educational style. Elements highlight with subtle glow as they
become active. Professional presentation quality.Kompleksowy przewodnik po technikach podpowiedzi dla Tusheng Video
Dobrze skonstruowany prompt jest najskuteczniejszą umiejętnością w generowaniu obrazów na podstawie zdjęć. Ponieważ sztuczna inteligencja widziała już Twój obraz, prompt powinien skupiać się wyłącznie na ruchu i dynamice. Oto techniki, które zapewniają najlepsze wyniki.
Skrócony przewodnik po słowach kluczowych związanych ze sportem
Użyj tych konkretnych słów kluczowych, aby precyzyjnie kontrolować ruch wideo.
| Rodzaj ruchu | Słowa kluczowe | Efekt | |-------- -|-------|------| | Kamera: do przodu | przesunięcie do przodu, zbliżenie, zbliżenie, podejście | Kamera zbliża się do obiektu | | Kamera: do tyłu | przesunięcie do tyłu, oddalenie, cofnięcie, oddalenie | Kamera oddala się od obiektu | | Ujęcie: w lewo/w prawo | panoramowanie w lewo, panoramowanie w prawo, śledzenie w lewo, śledzenie w prawo | Kamera obraca się lub śledzi w poziomie | | Ujęcie: w górę/w dół | przechylanie w górę, przechylanie w dół, podnoszenie dźwigu, opuszczanie dźwigu | Kamera obraca się lub porusza w pionie | | Ujęcie: Orbita | orbita, obrót, obrót wokół, łuk | Kamera krąży wokół obiektu | | Kamera: Zoom | powiększanie, pomniejszanie, zmiana ogniskowej | Zoom obiektywu (bez przemieszczania) | | Obiekt: Mikro ruchy | oddychanie, mruganie, przenoszenie ciężaru ciała, mikro ruchy | Subtelne, realistyczne ruchy | | Obiekt: umiarkowany | obrót głowy, uśmiech, gest, powolny chód | Wyraźny, ale kontrolowany ruch | | Obiekt: dynamiczny | bieg, skok, taniec, obrót, machanie | Energiczny ruch całego ciała | | Otoczenie: Łagodne | powiew, dryfowanie, kołysanie, falowanie, migotanie | Delikatny ruch otoczenia | | Otoczenie: Intensywne | podmuch, pęd, uderzenie, wir, kaskada | Silna dynamika otoczenia | | Paralaksa | paralaksa, zmiana głębi, ruch warstw | Pierwszy plan/tło poruszające się z różnymi prędkościami |

Różne słowa kluczowe dotyczące ruchu kamery dają zupełnie różne efekty. Wybierz technikę ruchu kamery zgodnie z oczekiwanym rezultatem.
Kontrola prędkości i tempa
Tempo ruchu ma ogromny wpływ na emocjonalny wydźwięk filmu. Zastosuj następujące modyfikatory:
- Bardzo wolno: „ledwo zauważalne”, „ultra-slow motion”, „lodowate tempo” — dramatyczne, kontemplacyjne
- Wolno: „powoli”, „delikatnie”, „stopniowo”, „bez pośpiechu” — elegancja, kinowa jakość
- Umiarkowane: „stałe”, „naturalne tempo”, „w tempie spacerowym” — realizm, styl dokumentalny
- Szybkie: „ szybko”, „żwawo”, „energicznie”, „błyskawicznie” — dynamiczne, ekscytujące
- Bardzo szybkie: „szybkie”, „szybkie ujęcie”, „szybkie cięcie”, „wybuch ruchu” — napięte, pełne akcji
Zaawansowana technika: Używaj domyślnie zwolnionego tempa. W filmach generowanych przez sztuczną inteligencję zwolnione tempo prawie zawsze wygląda lepiej niż przyspieszone. Szybki ruch zwiększa ryzyko wystąpienia niedoskonałości i niespójności wizualnych.
Niezależna kontrola ruchu tła i obiektu
Możesz samodzielnie kontrolować, co się porusza, a co pozostaje nieruchome. Jest to potężna technika kierowania uwagi widzów.
Obiekt w ruchu, tło w spoczynku:
The person walks forward confidently while the background remains
perfectly still. Static camera, no camera movement. Focus entirely
on the subject's motion.Dynamiczne tło, statyczny obiekt:
The person stands completely still, like a statue. Behind them,
clouds drift across the sky, leaves blow in the wind, and city
lights flicker. Only the environment moves.Oddzielne ruchy obu stron:
The person slowly turns their head while the camera simultaneously
dollies in. Background clouds drift in the opposite direction,
creating a sense of depth and dimension.Różnica między ruchem kamery a ruchem obiektu
Zrozumienie różnicy między ruchem kamery a ruchem obiektu ma kluczowe znaczenie dla osiągnięcia pożądanego efektu.
Ruch kamery zmienia perspektywę i kompozycję. Scena pozostaje niezmienna, zmienia się natomiast punkt widzenia. Wykorzystywane w celu: ujawnienia sceny, ustalenia scenerii i podkreślenia dramaturgii.
Ruch obiektów odnosi się do przemieszczania się elementów w obrębie sceny przy nieruchomej kamerze. Jest on wykorzystywany w animacji postaci, prezentacjach produktów oraz dynamice środowiska naturalnego.
Ruchy łączone wykorzystują oba rodzaje ruchów jednocześnie. Jest to technika najbardziej kinowa, ale jednocześnie najtrudniejsza do wykonania dla sztucznej inteligencji. Zaleca się najpierw opanować jeden rodzaj ruchu, a dopiero gdy wynik będzie satysfakcjonujący, dodać drugi.
Zaawansowane struktury podpowiedzi
Aby uzyskać najbardziej przewidywalne wyniki, uporządkuj swoje podpowiedzi w następującej kolejności:
- Główne działanie — co robi główny bohater
- Ruch kamery — jak porusza się kamera
- Dynamika otoczenia — co robią elementy otoczenia
- Prędkość/Tempo — tempo wszystkich ruchów
- Atmosfera/nastrój — ton emocjonalny
- Poprawa jakości wizualnej — techniczny opis jakości wizualnej
Przykład wykorzystania tej struktury:
[Subject] A young woman in a flowing white dress slowly raises
her hand to brush hair from her face.
[Camera] The camera executes a slow, steady dolly in from a
medium shot to a close-up.
[Environment] Cherry blossom petals drift gently through the
air. Soft golden sunlight filters through the trees.
[Speed] All motion is slow and deliberate, almost dreamlike.
[Mood] Romantic, ethereal, peaceful atmosphere.
[Quality] Cinematic shallow depth of field, anamorphic bokeh,
film grain, 4K quality.Porównanie narzędzi AI do analizy filmów TuSheng 2026
Konkurencja w sektorze strumieniowego przesyłania wideo nasila się. Poniżej znajduje się analiza porównawcza głównych platform na dzień lutego 2026 r., ze szczególnym uwzględnieniem dostępności dla użytkowników w Chinach kontynentalnych.

Wyniki przetwarzania tego samego obrazu źródłowego na pięciu różnych platformach generowania wideo. Różnice w jakości ruchu, spójności czasowej i wierności wizualnej są natychmiast widoczne.
| Funkcja | Seedance 2.0 | Runway Gen-4 | Pika 2.0 | Kling 3.0 | Luma Dream Machine | |------|-------------|-------------|---------|------ ----------|-------------------| | Maksymalna rozdzielczość | 2K (2048x1080) | 4K (wyskalowane) | 1080p | 1080p | 1080p | | Maksymalny czas trwania | 15 sekund | 10 sekund | 5 sekund | 2 minuty | 5 sekund | | Opcje wejściowe | Obraz + tekst + wideo + audio | Obraz + tekst + wideo | Obraz + tekst | Obraz + tekst | Obraz + tekst | | Wejście wielu obrazów | Obsługiwane (do 9 obrazów) | Nieobsługiwane | Nieobsługiwane | Nieobsługiwane | Nieobsługiwane | | Natywny dźwięk | Obsługiwane (8 języków z synchronizacją ruchu warg) | Nieobsługiwane | Częściowo (efekty dźwiękowe) | Nieobsługiwane | Nieobsługiwane | | Sterowanie kamerą | Oparte na podpowiedziach | Pędzel ruchu + tryb reżysera | Podstawowe | Podstawowe | Oparte na podpowiedziach | | Bezpłatny limit | Dostępne (bonus rejestracyjny) | Dostępny (ograniczony) | Dostępny (ograniczony) | Dostępny (ograniczony) | Dostępny (ograniczony) | | Cena początkowa | ~9,90 USD/miesiąc | 15 USD/miesiąc | 10 USD/miesiąc | ~6,99 USD/miesiąc | 9,99 USD/miesiąc | | Dostęp z Chin kontynentalnych | Bezpośredni dostęp | Wymagana sieć VPN | Wymagana sieć VPN | Bezpośredni dostęp | Wymagana sieć VPN | | Najbardziej odpowiedni dla | Kontrola multimodalna, jakość obrazu | Profesjonalny proces edycji | Początkujący, zabawne efekty | Długie filmy, wysoka wartość | Kinowy efekt, sceny 3D |
Szczegółowe recenzje poszczególnych narzędzi
Seedance 2.0 nie ma sobie równych pod względem elastyczności wprowadzania danych. Jest to jedyna platforma obsługująca jednoczesne przesyłanie do dziewięciu obrazów referencyjnych, synchronizację ruchu warg z dźwiękiem oraz łączenie wszystkich trybów wprowadzania danych w ramach jednego generowania. Jeśli szukasz maksymalnej kontroli nad wyjściem obrazu do wideo, Seedance oferuje najbardziej kompleksowy zestaw narzędzi. Jego rozdzielczość wyjściowa 2K jest również najwyższa spośród wszystkich narzędzi (bez konieczności stosowania upsamplingu). Opracowany przez ByteDance (firmę macierzystą TikTok), Seedance jest bezpośrednio dostępny dla użytkowników w Chinach kontynentalnych bez konieczności korzystania z VPN lub zagranicznych metod płatności.
Runway Gen-4 wyróżnia się precyzyjną kontrolą. Funkcja Motion Brush pozwala dokładnie „namalować”, które części obrazu powinny się poruszać i w jakim kierunku. Jeśli potrzebujesz chirurgicznej precyzji w określonych obszarach, Runway jest najskuteczniejszym rozwiązaniem. Wadą jest wyższa cena i niższe limity generowania. Dostęp w Chinach wymaga VPN.
Pika 2.0 jest najbardziej dostępną opcją. Dla nowicjuszy, którzy chcą eksperymentować z generowaniem obrazów do filmów bez konieczności nauki inżynierii promptów, efekty Pika dostępne za jednym kliknięciem i uproszczony interfejs oferują najniższą barierę wejścia. Chociaż jakość obrazu nie dorównuje narzędziom premium, jest wystarczająca do tworzenia zwykłych treści społecznościowych. Wymaga VPN, aby uzyskać dostęp w Chinach kontynentalnych.
Kling 3.0 przewyższa konkurencję zarówno pod względem czasu działania, jak i stosunku jakości do ceny. Jeśli potrzebujesz generować dłuższe filmy — 30 sekund, 1 minutę, a nawet 2 minuty — z pojedynczego obrazu, Kling jest jedyną realną opcją. Stosunek ceny do jakości obrazu jest wyjątkowo korzystny. Jego ograniczeniem są ograniczone opcje wprowadzania danych (pojedynczy obraz + tekst). Jako produkt należący do Kuaishou, Kling jest bezpośrednio dostępny w Chinach kontynentalnych, oferując użytkownikom krajowym kolejną płynną opcję.
Luma Dream Machine wyróżnia się w zakresie rozumienia przestrzeni. W przypadku krajobrazów, architektury i scen, w których kluczowe znaczenie ma trójwymiarowa świadomość przestrzenna, Luma zapewnia najbardziej przekonujące ruchy paralaksy i kamery. Animacja postaci pozostaje w tyle w porównaniu z konkurencją. Dostęp z terytorium kraju wymaga VPN.
Zalecenia dla użytkowników z Chin kontynentalnych
Jeśli jesteś w Chinach kontynentalnych, istnieją przede wszystkim dwa narzędzia wideo, z których można korzystać bezpośrednio bez VPN:
- Seedance 2.0 — opracowany przez ByteDance, w pełni funkcjonalny i gotowy do użycia, wyposażony w wielomodalne wejście + rozdzielczość 2K + zintegrowany dźwięk
- Kling 3.0 — produkt firmy Kuaishou, wyróżniający się generowaniem długich filmów wideo o doskonałym stosunku jakości do ceny
Chociaż zagraniczne narzędzia, takie jak Runway, Pika i Luma, mają swoje własne, charakterystyczne cechy, wszystkie wymagają dostępu do VPN i zagranicznych metod płatności, co stanowi większą barierę wejścia na rynek.
Dla twórców treści na krajowych platformach, takich jak Douyin, Xiaohongshu, Bilibili i Kuaishou, wybór narzędzi dostępnych bezpośrednio w Chinach jest nie tylko wygodniejszy, ale także zapewnia większą stabilność sieci i łatwość płatności.
Aby uzyskać bardziej kompleksowe porównanie (obejmujące funkcje przekształcania tekstu na wideo), zapoznaj się z naszym kompletnym rankingiem generatorów wideo opartych na sztucznej inteligencji na rok 2026.
Typowe błędy i metody ich korygowania
Po przetestowaniu tysięcy konwersji wideo na obraz, oto pięć najczęstszych błędów, które zaobserwowaliśmy — wraz z konkretnymi rozwiązaniami.
- Używaj zdjęć stockowych o niskiej rozdzielczości.
Popełniony błąd: przesłanie małego, skompresowanego obrazu (np. miniatury o rozmiarze 400 x 300 zapisanej z WeChat lub mediów społecznościowych) przy oczekiwaniu na obraz wideo w wysokiej rozdzielczości.
Dlaczego to nie działa: Enkoder nie jest w stanie wydobyć wystarczającej ilości informacji wizualnych z obrazów o niskiej rozdzielczości. Wynik jest zamazany, a dodatkowo pojawiają się artefakty ruchu.
Jak to naprawić: Zawsze używaj obrazów w najwyższej rozdzielczości. Jeśli dostępne są tylko obrazy w niskiej rozdzielczości, przed przesłaniem użyj narzędzi do skalowania AI (takich jak Real-ESRGAN lub Topaz Gigapixel), aby poprawić rozdzielczość. Minimalny zalecany rozmiar to 1024 x 1024 pikseli.
- Opisuj sceny, a nie działania.
Popełniony błąd: Tworzenie podpowiedzi takich jak „Powierzchnia morza o zachodzie słońca, ze złotym blaskiem migoczącym na wodzie”. Opisuje to wygląd obrazu, który sztuczna inteligencja już zna.
Dlaczego się nie udało: Sztuczna inteligencja już zakodowała obraz. Opisywanie jej zawartości obrazu marnuje miejsce na zbędne informacje i nie daje żadnych wskazówek co do działania.
Jak poprawić: Skup się wyłącznie na ruchu. Przepisz jako: „Fale delikatnie rozbijają się o brzeg. Złote promienie słońca migoczą na powierzchni wody. Chmury powoli przemieszczają się z lewej strony na prawą. Kamera powoli przesuwa się w prawo, podążając za linią brzegową”.
- Wymaganie wykonania zbyt wielu czynności jednocześnie
Popełnione błędy: „Postać odwraca głowę, macha ręką, idzie do przodu, podnosi filiżankę, uśmiecha się i tańczy, podczas gdy kamera zbliża się, przesuwa w lewo i przechyla się”.
Dlaczego to nie działa: Obecne modele sztucznej inteligencji nie są w stanie niezawodnie koordynować więcej niż dwóch lub trzech równoczesnych działań. Przeciążone polecenia powodują, że model albo ignoruje większość instrukcji, albo generuje niejasne, pełne błędów wyniki.
Jak edytować: Ogranicz każdą generację do jednej głównej akcji podmiotu i jednego ruchu kamery. W przypadku złożonych sekwencji akcji, przed edycją i połączeniem ich w całość, wygeneruj osobno wiele krótkich klipów.
- Ignoruj niezgodności proporcji obrazu
Popełniony błąd: Przesłanie zdjęcia w formacie 16:9 (poziomym), ale ustawienie orientacji wyjściowej na 9:16 (pionowej) lub odwrotnie.
Dlaczego to nie działa: Sztuczna inteligencja albo drastycznie przycina obraz, albo wymaga wypełnienia dużych pustych obszarów. Żadne z tych podejść nie daje zadowalających rezultatów — przycinanie narusza starannie skomponowaną kompozycję, a wypełnianie nowych obszarów powoduje niespójności.
Jak to naprawić: Upewnij się, że proporcje obrazu wyjściowego są zgodne z proporcjami obrazu źródłowego. Użyj proporcji 16:9 dla obrazów poziomych i 9:16 dla obrazów pionowych. Jeśli wymagane są inne proporcje, przed przesłaniem przytnij obraz źródłowy do docelowych proporcji.
- Oczekiwanie realistycznego efektu od obrazów ilustracyjnych
Popełniony błąd: Przesłanie ilustracji kreskówkowej lub płaskiego obrazu, oczekując, że sztuczna inteligencja wygeneruje fotorealistyczny ruch wideo.
Dlaczego to nie działa: Model próbuje interpretować style artystyczne, wprowadzając czasami niepożądany realizm. Płaskie ilustracje nie mają głębi i wskazówek dotyczących oświetlenia, na których model opiera się w celu naturalnego przewidywania ruchu.
Jak to naprawić: Jeśli materiałem źródłowym jest ilustracja, wyraźnie określ styl w poleceniu: „Zachowaj dokładnie styl ilustracji. Animacja w stylu 2D, nie fotorealistyczna. Ruchy powinny wyglądać jak ręcznie rysowane i malarskie”. Dzięki temu model zachowa styl artystyczny, a nie wprowadzi fotorealizm.
Często zadawane pytania
Które narzędzie AI najlepiej nadaje się do generowania filmów na podstawie obrazów?
Seedance 2.0 to nasza najlepsza rekomendacja do generowania obrazów do filmów w 2026 roku. Obsługuje wiele wejść obrazu (do 9 obrazów referencyjnych), generuje obrazy w rozdzielczości 2K i oferuje najbardziej elastyczną kombinację obrazów, tekstu, wideo i audio. Ponadto, opracowany przez ByteDance, Seedance jest bezpośrednio dostępny w Chinach kontynentalnych. Dla użytkowników dbających o budżet, Kling 3.0 zapewnia wyjątkową jakość obrazu w niższej cenie, również bezpośrednio dostępny w Chinach kontynentalnych. Dla początkujących, Pika 2.0 oferuje najprostszy interfejs. Optymalny wybór zależy od konkretnych wymagań — zapoznaj się z naszą [tabelą porównawczą narzędzi](#2026-year image-to-video AI tool comparison).
Czy serwis TuSheng Video jest bezpłatny?
Oczywiście. Wiele platform oferuje bezpłatne limity. Seedance zapewnia bezpłatne kredyty każdemu nowemu użytkownikowi — nie jest wymagana karta kredytowa. Pika 2.0 i Luma Dream Machine również oferują ograniczoną bezpłatną generację. HaiLuo AI zapewnia 10 bezpłatnych generacji dziennie. Te bezpłatne limity wystarczają do przetestowania technologii i wyprodukowania kilku filmów. W przypadku ciągłego użytkowania bardziej opłacalne są płatne plany. Aby uzyskać więcej informacji na temat strategii bezpłatnego korzystania, zapoznaj się z naszym Przewodnikiem po bezpłatnym korzystaniu z Seedance.
Jaka jest maksymalna długość filmów generowanych przez sztuczną inteligencję?
Różne platformy mają różne ograniczenia. Kling 3.0 jest liderem w tej dziedzinie, generując filmy o długości do 2 minut na obraz. Seedance 2.0 ma limit 15 sekund. Runway Gen-4 ogranicza czas trwania do 10 sekund. Pika 2.0 i Luma Dream Machine ograniczają czas trwania filmów do 5 sekund. W przypadku większości mediów społecznościowych i scenariuszy marketingowych optymalny czas trwania wynosi 5–15 sekund. Jeśli potrzebny jest dłuższy materiał filmowy, można wygenerować wiele krótkich klipów do późniejszej edycji i łączenia lub wykorzystać Kling do generowania długich filmów z jednego ujęcia.
Który format obrazu najlepiej nadaje się do generowania filmów przez sztuczną inteligencję?
PNG jest optymalnym formatem, ponieważ jest bezstratny — wolny od artefaktów kompresji. WebP (tryb bezstratny) zapewnia równoważne wyniki przy mniejszych rozmiarach plików. JPG jest również odpowiedni w większości przypadków, ale silnie skompresowane pliki JPG z zauważalnymi artefaktami kompresji pogarszają jakość wyjściową. Należy unikać stosowania formatów GIF, BMP lub innych niestandardowych formatów. Wszystkie główne platformy obsługują formaty JPG, PNG i WebP. Minimalna rozdzielczość: 512x512 pikseli. Zalecana: 1024x1024 lub wyższa.
Czy sztuczna inteligencja może animować dowolny rodzaj obrazu?
Sztuczna inteligencja może animować większość rodzajów obrazów, choć wyniki różnią się w zależności od tematu. Najlepsze efekty uzyskuje się w przypadku portretów i zdjęć twarzy — obecne modele dokładnie interpretują naturalne ruchy twarzy i włosów. Doskonałe wyniki uzyskuje się również w przypadku krajobrazów i scen naturalnych, z przekonującym odwzorowaniem ruchu chmur, płynącej wody i kołyszącej się roślinności. Obrazy produktów z czystym tłem dają niezmiennie wiarygodne wyniki. Ilustracje i grafiki mogą być animowane, choć może być konieczne dostosowanie stylistyczne, aby uniknąć niepożądanego fotorealizmu. Złożone sceny grupowe, obrazy zawierające dużo tekstu i zdjęcia niskiej jakości dają najmniej stabilne wyniki.
Jaka jest różnica między filmem generowanym na podstawie obrazu a filmem generowanym na podstawie tekstu?
Tekst do wideo generuje jednocześnie treści wizualne i ruch na podstawie opisów tekstowych. Sztuczna inteligencja dyktuje cały wygląd wizualny, oferując mniejszą kontrolę nad konkretnymi szczegółami, ale większą swobodę twórczą. Obraz do wideo wykorzystuje istniejące obrazy jako punkt wyjścia, generując wyłącznie ruch. Użytkownik zachowuje precyzyjną kontrolę nad efektem wizualnym, ponieważ to on dostarcza odniesienie wizualne. Image-to-Video zazwyczaj zapewnia bardziej przewidywalne i spójne wyniki, ponieważ sztuczna inteligencja ma konkretny punkt odniesienia wizualnego. Text-to-Video lepiej nadaje się do tworzenia przez sztuczną inteligencję całkowicie nowych treści od podstaw.
Czy Tusheng Video może sterować ruchem kamery?
Oczywiście. Większość nowoczesnych narzędzi do generowania wideo obsługuje sterowanie ruchami kamery za pomocą poleceń tekstowych. Można określić takie ruchy, jak „dolly in”, „pan left”, „orbit around”, „crane up”, „zoom out” i „tracking shot”. Seedance 2.0 i Luma Dream Machine reagują szczególnie dokładnie na te słowa kluczowe związane z ruchem. Runway Gen-4 oferuje dodatkową precyzję dzięki Motion Brush i Director Mode, umożliwiającym wizualne rysowanie ścieżki dla trajektorii kamery. Zaleca się określenie tylko jednego typu ruchu na generację, uzupełnionego modyfikatorami prędkości, takimi jak „powoli” lub „stale”.
Czy jakość obrazu filmów generowanych przez sztuczną inteligencję jest wystarczająca do zastosowań profesjonalnych?
W przypadku krótkich filmów (5–15 sekund) jest to całkowicie wykonalne. Wyniki pracy najlepszych platform, takich jak Seedance 2.0 i Runway Gen-4, są już profesjonalnie wykorzystywane w marketingu społecznościowym, filmach dotyczących produktów e-commerce, prezentacjach nieruchomości i koncepcjach reklamowych. W kraju znaczna część treści komercyjnych na platformach Douyin i Xiaohongshu zawiera obecnie materiały wideo generowane przez sztuczną inteligencję. Istnieją jednak pewne ograniczenia: dłuższy czas trwania zwiększa ryzyko niedoskonałości, złożone sceny z wieloma obiektami pozostają niestabilne, a renderowanie tekstu w filmach nadal nie jest idealne. W przypadku produkcji telewizyjnych lub filmowych, które wymagają absolutnej perfekcji, tradycyjne filmowanie pozostaje bezpieczniejszą opcją. W przypadku marketingu cyfrowego i treści społecznościowych technologia przekształcania obrazów w wideo za pomocą sztucznej inteligencji osiągnęła profesjonalny poziom.
Podsumowanie
TuSheng Video AI ewoluowało z nowatorskiego gadżetu do niezbędnego narzędzia do tworzenia treści. Technologia ta osiągnęła dojrzałość, narzędzia stały się przyjazne dla użytkownika, a jakość wyników spełnia obecnie profesjonalne standardy w przypadku większości scenariuszy związanych z treściami cyfrowymi.
Oto najważniejsze punkty:
- Jakość obrazów źródłowych ma kluczowe znaczenie. Ostre, dobrze skomponowane zdjęcia o wysokiej rozdzielczości zapewniają znacznie lepsze wyniki w porównaniu z rozmytych lub o niskiej rozdzielczości.
- Opisuj ruch, a nie wygląd. Sztuczna inteligencja już widzi Twój obraz. Powiedz jej, jak powinny się poruszać obiekty, a nie jak wyglądają.
- **Zacznij od prostych zadań. ** Jedna akcja obiektu plus jeden ruch kamery. Opanuj podstawy, zanim dodasz złożoność.
- Powtarzaj szybko. Najpierw wygeneruj krótkie klipy testowe; pełną wersję stwórz dopiero wtedy, gdy będziesz zadowolony.
- **Dopasuj narzędzia do zadań. ** Seedance stawia na wierność wizualną i kontrolę multimodalną; KeLing wyróżnia się długimi filmami i przystępną ceną; Runway koncentruje się na precyzyjnej edycji; Pika kładzie nacisk na prostotę i łatwość obsługi.
- Wybierz narzędzie, które odpowiada Twoim potrzebom. Jeśli mieszkasz w Chinach kontynentalnych, Seedance i KeLing mogą być używane bezpośrednio, bez dodatkowych barier sieciowych lub płatniczych.
Różnica między markami i twórcami korzystającymi z Tusheng Video AI a ich konkurentami, którzy nadal polegają na statycznych obrazach, z każdym miesiącem się powiększa. Każde zdjęcie w bibliotece produktów ma potencjał, aby stać się reklamą wideo. Każdy portret może stać się dynamicznym awatarem. Każdy krajobraz może posłużyć jako materiał filmowy typu B-roll.
Stwórz swój pierwszy film z obrazu za darmo --> — Prześlij dowolny obraz i zobacz, jak ożywa w ciągu dwóch minut. Nie jest wymagana karta kredytowa, dostęp bezpośrednio w Chinach kontynentalnych.
Chcesz poznać więcej funkcji wideo opartych na sztucznej inteligencji? Wypróbuj Seedance na wszystkich platformach --> — Generowanie tekstu do wideo, wideo do wideo, generowanie multimodalne: wszystko w jednym miejscu.
Więcej informacji: Kompletny przewodnik użytkownika Seedance | Przewodnik po poleceniach Seedance z ponad 50 przykładami | Przykłady zastosowań kreatywnych wideo AI | Ranking najlepszych generatorów wideo AI na rok 2026 | Przewodnik po marketingu wideo AI i mediach społecznościowych | AI tekst-do-wideo: kompletny przewodnik*
