
Sammendrag
Image-to-Video AI bruker dyp læringsteknologi basert på diffusjonsmodeller for å transformere statiske bilder til dynamiske videoer. I motsetning til ren tekst-til-video-generering, trenger du bare å laste opp et fotografi for at AI-en skal generere realistisk bevegelse, kamerabevegelser og tidsmessig sammenhengende opptak rundt det, noe som gir deg mer presis kontroll over det endelige resultatet. Denne guiden vil gi en omfattende gjennomgang av: de tekniske prinsippene bak Image-to-Video AI; hvilke typer bilder som gir optimale resultater; en femtrinns veiledning for å lage din første video fra bunnen av; åtte praktiske bruksområder med konkrete eksempler; avanserte teknikker for bevegelseskontroll; og en sammenligning av de ledende verktøyene i 2026 (inkludert de som er direkte tilgjengelige i Kina). Prøv Image-to-Video AI gratis -->
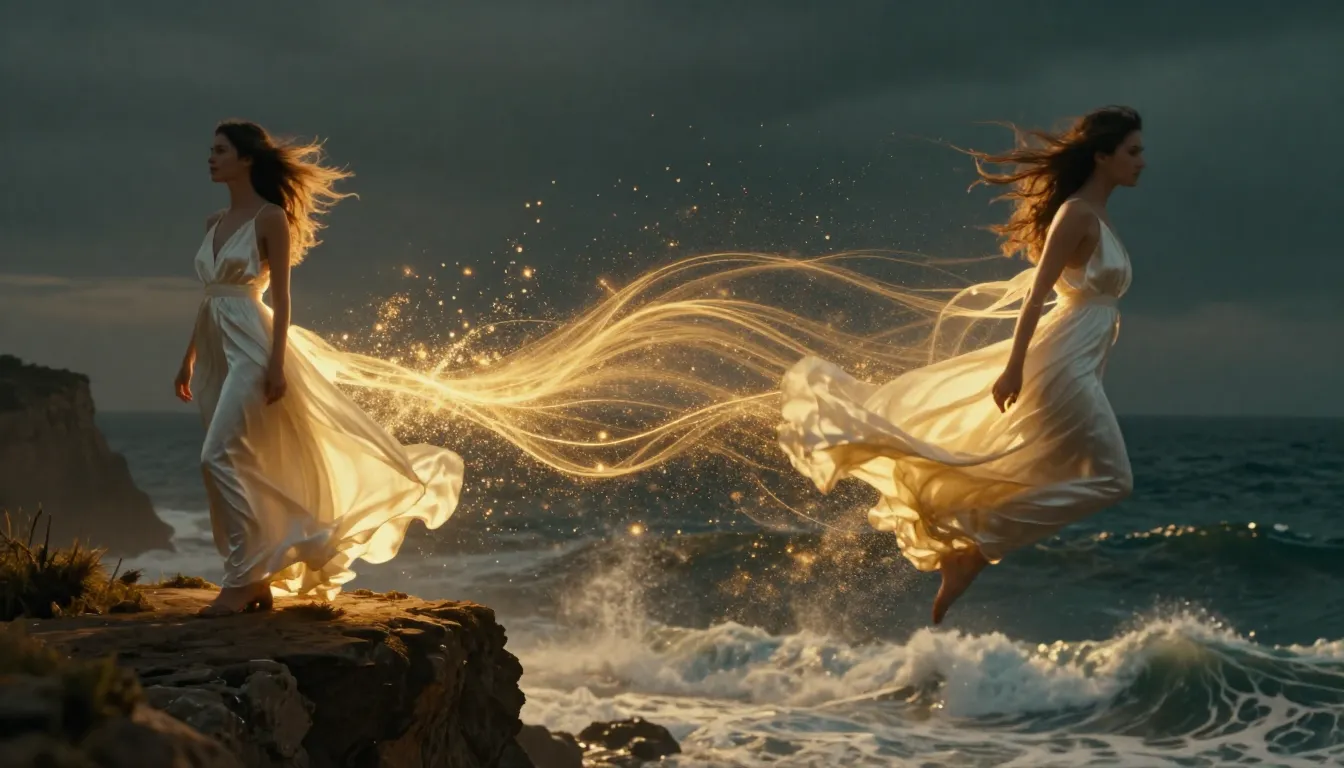
TuSheng Video AI tar stillbilder og genererer naturtro bevegelser, filmiske kamerabevegelser og tidsmessig kontinuitet – og forvandler et enkelt bilde til et filmisk videoklipp.
Hva er Tusheng Video AI?
Image-to-Video AI er en kunstig intelligens-teknologi som kan generere videoer fra statiske bilder. Du leverer et fotografi – det være seg et portrett, et produktbilde, et landskap eller et kunstverk – og AI-modellen produserer en kort video hvor elementene begynner å bevege seg, kameravinklene endres og hele scenen kommer til liv.
I sin kjerne bruker de fleste generative videosystemer videodiffusjonsmodeller. Disse nevrale nettverkene er trent på millioner av par med videobilder og data, og lærer seg det statistiske forholdet mellom statiske bilder og påfølgende naturlige bevegelser. Når modellen presenteres for et nytt bilde, forutsier den hvilken bevegelse som virker mest naturlig og genererer en kontinuerlig sekvens av bilder som glatt overgår fra det opprinnelige fotografiet.
Forskjeller fra tekst til video
Tekst-til-video genererer innhold utelukkende fra tekst. AI-en skaper samtidig både visuelt innhold og bevegelse basert på tekstprompten din – en kraftig, men uforutsigbar prosess, da AI-en uavhengig bestemmer utseendet til motivene, komposisjonen av scenene og alle bevegelsesmønstre.
Tusheng Video snur denne logikken på hodet: du gir det visuelle ankeret. AI-en vet allerede hvordan scenen ser ut, fordi du har vist den direkte. Dens eneste oppgave er å generere plausibel bevegelse. Dette betyr:
- Bedre kontroll: Bildene dine definerer motivet, komposisjonen, fargepaletten og stilen
- Mindre gjetning: AI krever ingen tolkning av vage tekstbeskrivelser
- Bedre konsistens: Resultatene samsvarer nøye med kildebildene
- Raskere iterasjon: Det er mye enklere å justere bevegelsesprompten enn å omskrive hele scenebeskrivelsen
Hvorfor TuSheng Video er så viktig i 2026
TuSheng Video AI har utviklet seg fra et eksperimentelt leketøy til et produktivitetsverktøy. E-handelsmerker forvandler produktbilder til animerte annonser, innholdsskapere gir liv til sine mest populære innlegg, eiendomsmeglere produserer virtuelle visningsvideoer fra eiendomsbilder, og lærere animerer illustrasjoner i lærebøker.
Denne teknologien har nådd et vendepunkt – 5 til 15 sekunders videoer generert fra høykvalitets kildebilder er nå praktisk talt umulige å skille fra tradisjonelle opptak i de fleste scenarier. Dette er nettopp grunnen til at bilde-til-video-konvertering har blitt den raskest voksende kategorien innen AI-videogenerering.
Denne trenden er spesielt uttalt i det kinesiske markedet. Algoritmer på plattformer som Douyin, Xiaohongshu, Bilibili og Kuaishou favoriserer i stor grad videoinnhold, noe som skaper en enestående etterspørsel blant innholdsskapere etter løsninger for å raskt konvertere fotografier til videoer. Tusheng Video AI fyller nettopp dette tomrommet i markedet.
Tekniske prinsipper for Tusheng Video AI
Å forstå den tekniske prosessen hjelper deg å oppnå bedre resultater. Når du vet hvorfor AI oppfører seg på en bestemt måte, kan du gi bedre innspill og skrive mer effektive instruksjoner. Her er den firetrinnsprosessen som foregår bak kulissene.

De fire trinnene i Tusheng Video AI-prosesseringsrørledningen: bildekoding, bevegelsesforutsigelse, rammeoppretting og tidsmessig utjevning.
Trinn 1: Bildekoding
AI analyserer først inngangsbildet ditt gjennom et kodernettverk og komprimerer det til en tett matematisk representasjon kjent som en latent vektor. Dette kan forstås som at AI trekker ut et «fingeravtrykk» av bildet ditt – og fanger opp dets struktur, farge, dybde, motivplassering, lysretning og semantisk informasjon.
Denne latente representasjonen er betydelig mer kompakt enn de opprinnelige pikseldataene, noe som gjør etterfølgende beregninger gjennomførbare. Kvaliteten på kodingen har direkte innvirkning på utdataene. Inngangsbilder med høyere oppløsning og skarpere bilde genererer rikere latente representasjoner, noe som til slutt gir overlegen videoutdata.
Trinn to: Bevegelsesforutsigelse
Dette er den kreative kjernen i hele prosessen. Diffusjonsmodellen forutsier hvilken type bevegelse som vil være naturlig basert på det originale bildet, og tar hensyn til:
- Scenisk kontekst: Et havfoto antyder at bølgene skal slå inn; et portrett antyder subtile ansiktsbevegelser
- Dybdeinformasjon: Objekter som er nærmere linsen kan vise andre bevegelsesmønstre enn objekter som er langt unna
- Fysisk realisme: Hår skal flyte med vinden, vann skal renne nedover, og stoff skal falle naturlig
- Din tekstprompt: Hvis du spesifiserer «panorer sakte mot venstre», vil modellen justere bevegelsesforutsigelsen sin deretter
Modellen forvrenger ikke bare piksler. Den genererer helt nytt visuelt innhold for områder som blir synlige ved kamerabevegelse eller objektbevegelse. Hvis kameraet panorerer til høyre, vil modellen «fylle ut» scenen utenfor den opprinnelige bildets høyre kant.
Trinn tre: Rammeoppretting
Basert på bevegelsesforutsigelse genererer modellen en sekvens av videobilder. Hvert bilde produseres gjennom en omvendt diffusjonsprosess – med utgangspunkt i støy blir det gradvis raffinert til et klart bilde, samtidig som det opprettholder konsistensen med det forrige bildet og det originale bildet.
Seedance 2.0 og andre moderne modeller genererer med høye bildefrekvenser (24–30 fps) samtidig som de opprettholder subpikselkonsistens mellom bildene. Dette sikrer jevn, flimmerfri utdata uten de rystelsesproblemene som var vanlige i tidligere systemer.
Trinn fire: Tidsutjevning
Det siste trinnet sikrer sømløse overganger mellom alle genererte rammer. Den tidsmessige oppmerksomhetsmekanismen verifiserer at lysstyrke, farge og bevegelse forblir konsistent gjennom hele videoen, og forhindrer vanlige visuelle artefakter:
- Plutselige fargeendringer mellom bildene
- Uventet opptreden eller forsvinning av objekter
- Unaturlig akselerasjon eller retardasjon av bevegelse
- Flimring i overflatestrukturen
Resultatet er en utsøkt video som flyter naturlig fra det originale opptaket.
Hvorfor ser noen bilder bedre ut?
Nå kan du forstå hvorfor kvaliteten på inngangsbildet er så viktig. Et uskarpt bilde med lav oppløsning gir en støyende potensiell koding i første trinn, noe som gir mindre informasjon til bevegelsesprediksjonsmodellen (andre trinn). Dette resulterer i mindre presis bevegelse og flere visuelle artefakter i det endelige resultatet. Omvendt gir et skarpt, godt komponert bilde med klare dybdeindikasjoner modellen rik informasjon, noe som gir en mer naturlig video av høyere kvalitet.
Hvilken type bilde gir best resultat?
Ikke alle bilder er egnet for TuSheng Video AI. Forskjellen mellom godt kildemateriale og dårlig kildemateriale kan være forskjellen mellom en fantastisk video og en haug med ubrukelig filmmateriale. Her er en praktisk guide.

Venstre side viser egnede kildebilder (høy oppløsning, godt komponert, som antyder naturlig bevegelse), mens høyre side viser uegnede kildebilder (uskarpe, rotete, inneholder elementer som er vanskelige for AI å behandle).
Egnede bildetyper
Høy oppløsning (1024x1024 eller høyere). Flere piksler gjør det mulig for koderen å hente ut flere detaljer. Bruk alltid den versjonen med høyest oppløsning som er tilgjengelig. Minste anbefalt oppløsning: 512x512 piksler. Ideell oppløsning: 1024x1024 eller høyere.
Motivene er klart definert med tydelige konturer. AI-en må skille mellom hva som skal bevege seg og hva som skal forbli statisk. Et portrett hvor motivet er skarpt skilt fra bakgrunnen gir langt bedre resultater enn komplekse, kaotiske gruppescenarier.
God belysning og riktig eksponering. Bilder med god belysning gir nøyaktig informasjon om farger og dybde for modellen. Unngå bilder som er sterkt overeksponerte eller undereksponerte.
Naturlig lagdeling og komposisjon. Bilder med tydelig definert forgrunn, mellomgrunn og bakgrunn gir AI dybdeinformasjon, noe som forbedrer realismen i parallakseffekter og kamerabevegelser.
Bilder som antyder bevegelse. Bilder som antyder bevegelse – hår som blåser i vinden, bølger som er i ferd med å slå mot kysten, en person som tar et skritt – gir modellen et kraftig utgangspunkt for å forutsi bevegelse. AI kan forstå «hva som skjer videre» ut fra disse visuelle signalene.
Rene bakgrunner. En minimalistisk eller naturlig uskarp bakgrunn gir jevnere videokvalitet enn en rotete bakgrunn fylt med mange små objekter.
Bildetyper som kan forårsake problemer
Uklare eller uskarpe bilder. Uklar inngang, uklar utgang. AI kan ikke legge til skarphet som ikke var til stede i det opprinnelige bildet.
Overdreven komplekse scener. Bilder som inneholder mange små motiver, intrikate mønstre eller visuelt rot kan overvelde bevegelsesprediksjonsmodeller, slik at de ikke klarer å bestemme hva som skal bevege seg og hvordan.
Omfattende tekst eller typografi. AI-videomodeller sliter fortsatt med å opprettholde tekstlesbarheten på tvers av bildene. Hvis bildene dine inneholder logoer, merkevarer eller tekstoverlegg, vil det oppstå forvrengning i videoutgangen.
Lav oppløsning (512x512 eller lavere). Små bilder inneholder utilstrekkelig informasjon. Selv å forstørre dem med AI før innlegging er nytteløst – det legger til piksler, men ikke informasjon.
Kraftige filtre eller etterbehandling. Ekstreme fargejusteringer, HDR-behandling eller omfattende Photoshop-modifikasjoner kan forvirre modellens forståelse av belysning og dybde.
Flere ansikter i forskjellige størrelser. AI håndterer enkeltportretter effektivt. Gruppebilder med ansikter i forskjellige avstander gir inkonsekvente animasjoner – noen ansikter ser naturlige ut, mens andre blir forvrengt.
Sjekkliste for selvkontroll før opplasting
Før du laster opp bilder, bør du raskt sjekke følgende punkter:
- Minimum oppløsning på 1024x1024 piksler
- Motivet er klart definert med tydelig avstand fra bakgrunnen
- Riktig eksponering (verken undereksponert eller overeksponert)
- Ingen kraftige filtre, ekstrem HDR eller synlig kunstig bearbeiding
- Minimalt med tekst, logoer eller typografiske elementer
- Kontrollert scenekompleksitet (1–3 primære motiver)
- Bildeformat: JPG, PNG eller WebP
Når disse betingelsene er oppfylt, kan produksjonen starte.
Trinnvis veiledning: Lag din første bilde-til-video
Følg disse fem trinnene for å forvandle et hvilket som helst statisk bilde til en animert AI-video. Vi bruker Seedance som demonstrasjonsplattform, men disse prinsippene gjelder for alle verktøy som konverterer bilder til video.
Trinn 1: Velge passende kildebilder
Kildebildet er den viktigste faktoren som bestemmer utskriftskvaliteten. Velg et bilde som oppfyller retningslinjene som er beskrevet tidligere. For ditt første forsøk anbefales det å velge et enkelt portrett eller et landskap med tydelig dybde – disse to bildetypene gir de mest konsistente resultatene.
Anbefalte bilder for første forsøk:
- Tydelig portrettfoto eller halvfigurportrett med god belysning
- Landskap med himmel, vannflater eller vegetasjon (disse elementene har en iboende bevegelse)
- Produktbilder mot ren bakgrunn
- Kunstverk eller illustrasjoner med tydelig definerte elementer
Når du genererer for første gang, bør du unngå å bruke komplekse collager, bilder med store mengder tekst eller sterkt redigerte fotografier.
Trinn to: Last opp til Seedance
Åpne Seedance Image-to-Video og last opp de valgte bildene dine. Seedance støtter JPG-, PNG- og WebP-formater. Plattformen analyserer automatisk bildene dine og gjør dem klare for generering.
Hvis et bilde er svært stort (med en side som overstiger 4096 piksler), vil systemet automatisk skalere det samtidig som proporsjonene beholdes, slik at manuell justering ikke er nødvendig.
Trinn tre: Utarbeide en handlingsorientert oppfordring
På dette stadiet informerer du AI-en om ønsket bevegelse. Din instruksjon bør beskrive dynamikken snarere enn bildeinnholdet (AI-en har allerede sett bildet). Fokuser på følgende punkter:
- Motivets bevegelse: Hva skal motivet gjøre?
- Kamerabevegelse: Hvordan skal kameraet bevege seg?
- Miljøets bevegelse: Hvilken dynamikk skal miljøet ha?
- Tempo og stemning: Skal det generelle tempoet være raskt eller langsomt?
Eksempler på portrettoppgaver:
The woman slowly turns her head to the right and smiles softly.
A gentle breeze moves her hair. Background slightly out of focus
with subtle bokeh movement. Camera slowly pushes in from medium
shot to a close-up. Warm, natural lighting. Cinematic film quality.Eksempel på landskapsmelding:
Gentle waves roll toward the shore in slow motion. Clouds drift
slowly across the sky from left to right. Sunlight shimmers on
the water surface. Camera slowly pans right, revealing more of
the coastline. Peaceful, serene atmosphere. 4K cinematic quality.Eksempel på produktmelding:
The camera slowly orbits around the product, rotating 45 degrees
clockwise. Soft studio lighting with subtle caustic reflections
on the surface. Clean white background with gentle gradient.
Premium commercial aesthetic. Smooth, steady camera movement.Kjerneprinsipp: Beskriv bevegelsen, ikke scenen. Scenen eksisterer allerede i bildet ditt.
Merk: Seedance støtter både kinesiske og engelske kommandoer, men engelske kommandoer gir vanligvis mer presis kontroll over kamerabevegelser. Det anbefales å bruke engelsk for bevegelses- og kamerarelaterte beskrivelser, mens kinesisk kan brukes for atmosfæriske og stilistiske beskrivelser.
Trinn fire: Velg parametere
Konfigurer genereringsinnstillinger:
| Parameter | Anbefalt verdi | Beskrivelse |
|---|---|---|
| Modell | Seedance 2.0 | Optimal bildekvalitet for generering av bilder til video |
| Varighet | 5 sekunder (for innledende forsøk) | Start kort, deretter lengre; generer utvidede versjoner når du er fornøyd |
| Bildeforhold | Tilpass bildedimensjoner | 16:9 for liggende, 9:16 for stående, 1:1 for kvadratisk |
| Oppløsning | 1080p | Velg alltid den høyeste tilgjengelige oppløsningen |
Avansert teknikk: Lag først en 5 sekunders versjon. Hvis bevegelsen og stilen er tilfredsstillende, bruk samme prompt for å lage en lengre versjon (8–15 sekunder). Denne tilnærmingen sparer kreditt i utforskningsfasen.
Trinn fem: Generer, sjekk, gjenta
Klikk på Generer og vent i 1–3 minutter. Når resultatene vises, vurderer du dem i henhold til følgende kriterier:
- Er bevegelsen naturlig og flytende?
- Opprettholder motivet visuell konsistens gjennom hele filmen?
- Stemmer kamerabevegelsen overens med dine forventninger?
- Er det noen visuelle feil (flimring, forvrengning, deformasjon)?
- Stemmer videokvaliteten overens med originalopptaket?
Hvis noe ikke er tilfredsstillende, justerer du spørsmålet og genererer på nytt. Vanlige justeringsmetoder:
- For raskt? Legg til «sakte», «forsiktig», «gradvis» i beskrivelsen av bevegelsen
- Feil kameraretning? ** Spesifiser tydeligere: «statisk kamera, ingen kamerabevegelse» eller «langsom dolly inn»
- Ansiktsfeil? Forenkle bevegelsen: reduser antall handlinger som utføres samtidig
- **Mangler dynamikk? ** Innfør dynamiske verb: «svingende», «flytende», «drivende», «skiftende»
Etter to eller tre iterasjonsrunder vil du få en video av høy kvalitet som gir bildene dine liv.
Begynn å lage ditt første bilde-til-videoklipp nå -->
8 viktige bruksområder og eksempler på konvertering av store bilder til video
TuSheng Video AI er ikke et en-triks-pony. Det tjener dusinvis av kreative og kommersielle formål. Nedenfor er åtte høykvalitets applikasjonsscenarier, komplett med praktiske instruksjoner som er klare for direkte kopiering og modifisering.
- Portrettanimasjon
Gi bildene dine liv. Portrettanimasjon er den mest populære appen for å gjøre bilder om til videoer. Last opp et profilbilde, selfie eller karakterbilde, og legg deretter til subtile, naturtro animasjoner – pusting, blinking, hodebevegelser, uttrykksendringer og hårbevegelser.
Egnet for minneverdige videoer, innhold på sosiale medier, oppretting av virtuelle avatarer og kreativ historiefortelling. På TikTok og Xiaohongshu er innhold som «gir bilder liv» fortsatt et populært trekkplaster.

Et statisk portrett forvandles til en naturtro video – naturlige blunk, subtile hodebevegelser og flytende hår, effekten er overraskende naturtro.
Eksempel på spørsmål:
The person looks directly at the camera with a calm, confident
expression. They slowly tilt their head slightly to the left and
give a subtle warm smile. Eyes blink naturally. A soft breeze gently
moves their hair. Shallow depth of field with softly blurred
background. Warm natural lighting. Cinematic portrait quality.- Produktpresentasjon
Forvandle produktfotografier til dynamisk kommersielt innhold. Dette er revolusjonerende for e-handelsmerker og influencere – du har allerede hundrevis eller til og med tusenvis av produktbilder, og nå kan hvert enkelt bilde bli en videoreklame, et nøkkelbilde for produktdetaljsider eller en kortfilm for sosiale medier.
På produktdetaljsidene til Taobao og JD.com, i produktpresentasjoner i Douyin-livestreamer og i produktanbefalinger på Xiaohongshu oppnår dynamiske produktvisninger gjennomgående betydelig høyere konverteringsfrekvenser enn statiske bilder.

Et standard produktbilde blir løftet til samme sofistikerte nivå som en premium reklamefilm – med kamerapanoreringer, dramatisk belysning og flytende bevegelser – en tradisjonell produksjon som kan koste hundrevis til tusenvis av pund.
Eksempel på spørsmål:
The camera slowly orbits 90 degrees around the product, revealing
its form from multiple angles. Soft directional studio lighting
with subtle caustic reflections on the surface. A gentle highlight
sweep moves across the product. Clean, premium commercial aesthetic.
Shallow depth of field. Ultra-smooth camera movement. 4K quality.3. Naturskjønn tidsforløp
Forvandle landskapsfotografier til stemningsfulle videoer i tidsforløpsstil. Skyer feier over himmelen, vann renner, lyset skifter fra gyldent til blått, og bladene svai i brisen. Ideelt for reiseinnhold, luftfoto av eiendommer og stemningsfulle B-roll-opptak.
Landskapsfotografer og reisevloggere på Bilibili kan direkte omdanne sine kuraterte fotografier til fengende tidsforløpsvideoer, noe som reduserer produksjonskostnadene betydelig.

Et landskapsfoto forvandlet til filmisk tidsforløp – flytende skyer, krusende vann og skiftende lys og skygge – skaper en dynamisk, atmosfærisk kvalitet fra et enkelt statisk bilde.
Eksempel på spørsmål:
Time-lapse effect. Clouds move steadily across the sky from left
to right. Water in the foreground ripples and flows gently. Light
shifts subtly as if the sun is moving, creating slowly changing
shadows on the landscape. Trees and grass sway gently in the wind.
Camera remains static on a tripod. Serene, majestic atmosphere.
Cinematic landscape quality.4. Innhold på sosiale medier
Forvandle dine mest populære statiske innlegg til videoinnhold som får folk til å slutte å bla videre. Algoritmer på plattformer som TikTok, Xiaohongshu, Bilibili og Kuaishou favoriserer alle videoinnhold – et populært bildeinnlegg får nesten garantert bedre trafikk når det konverteres til en video.
For innholdsprodusenter på Xiaohongshu kan et innlegg med tekst og bilder, ledsaget av en videoversjon, potensielt øke eksponeringen med tre til fem ganger. Douyin og Kuaishou opererer derimot utelukkende med video som sitt viktigste innholdsformat.
Eksempel på spørsmål:
Dynamic, attention-grabbing motion. The subject moves confidently
toward the camera with energy and presence. Background elements
shift with parallax depth effect. Quick, punchy camera push-in
that creates impact. Vibrant colors, high contrast. Bold,
eye-catching aesthetic optimized for social media. Vertical 9:16.- Kunst og illustrasjonsanimasjon
Gi kunstverk, illustrasjoner, digitale malerier og grafiske design liv. Dette bruksområdet er svært populært blant kunstnere, spilldesignere og kreative team som ønsker å vise frem arbeidet sitt på en mer engasjerende måte.
Innenfor Bilibili og Xiaohongshus kunst- og anime-miljøer er animerte illustrasjoner svært populært innhold. Å forvandle statiske kunstverk til videoer i «levende bakgrunn»-stil gir ofte betydelig flere delinger og lagringer enn de originale bildene.
Eksempel på spørsmål:
The illustrated scene comes to life with gentle, painterly motion.
Characters move subtly within their positions -- breathing, shifting
weight, small gestures. Background elements like leaves, clouds,
or particles drift slowly. The artistic style is preserved exactly
as painted. Movement is smooth and dreamlike, like a living painting.
Gentle ambient lighting shifts. Fantasy illustration quality.6. Virtuelle visninger av eiendommer
Forvandle eiendomsbilder til virtuelle visningsvideoer. Eiendomsmeglere kan lage immersive forhåndsvisninger ved hjelp av eksisterende eiendomsbilder, slik at det ikke lenger er nødvendig å arrangere dedikerte fotograferingsteam for fotografering på stedet.
For eiendomsannonser som vises på plattformer som Beike og Anjuke, samt eiendomsreklamer i WeChat Moments og Xiaohongshu, viser dynamiske visningsvideoer en betydelig høyere konverteringsrate for kundehenvendelser.
Eksempel på spørsmål:
Smooth virtual walkthrough. The camera glides forward slowly into
the room, revealing the space with a wide-angle perspective.
Natural daylight streams through the windows, casting soft shadows.
Subtle dust particles float in the sunbeams. The camera pans
gently to the left, showing the full room layout. Clean, bright,
aspirational real estate aesthetic. Steady, professional movement.- Mote- og stylingshow
Lag dynamisk moteinnhold fra studiobilder av antrekk. Modellene beveger seg, stoffene faller naturlig, mens den estetiske stilen på redaktørnivå forblir intakt.
Xiaohongshu-motebloggere og Taobao-klesforhandlere kan konvertere store mengder eksisterende modellbilder og flat-lay-antrekkbilder til dynamiske visningsvideoer, og dermed skape en mer visuelt slående tilstedeværelse i informasjonsfeeder.
Eksempel på spørsmål:
The model strikes a confident pose and then slowly shifts their
weight, creating natural body movement. Fabric of the outfit
flows and catches the light with each subtle motion. Wind effect
gently moves the hair. Camera starts at full body and slowly drifts
upward to a waist-up shot. High-fashion editorial lighting with
strong directional shadows. Vogue magazine aesthetic. Cinematic
slow motion.- Utdannings- og forklarende innhold
Forvandle statiske diagrammer, infografikk og pedagogiske illustrasjoner til dynamiske presentasjoner. Komplekse konsepter blir lettere å forstå når de settes i bevegelse.
Skaperne på Bilibili's Knowledge Zone og ulike utdanningsplattformer kan omforme kursmateriell, diagrammer og flytskjemaer til animerte videoer, noe som forbedrer undervisningseffektiviteten og seertallene betydelig.
Eksempel på spørsmål:
The diagram elements animate sequentially. Arrows begin to flow
in their indicated directions. Labels fade in one by one. Moving
parts of the system activate in logical order, showing the process
step by step. Smooth transitions between stages. Clean, clear
educational style. Elements highlight with subtle glow as they
become active. Professional presentation quality.En omfattende guide til teknikker for å få svar på Tusheng Video
En godt utformet prompt er den mest effektive ferdigheten når det gjelder å generere bilder fra fotografier. Siden AI-en allerede har sett bildet ditt, bør prompten din fokusere utelukkende på bevegelse og dynamikk. Her er noen teknikker som gir de beste resultatene.
Hurtigreferanse for sportsrelaterte nøkkelord
Bruk disse spesifikke nøkkelordene for å kontrollere videobevegelsen nøyaktig.
| Bevegelsestype | Nøkkelord | Effekt | |-------- -|-------|------| | Opptak: Fremover | dolly inn, skyv inn, beveg deg nærmere, nærme deg | Kameraet beveger seg mot motivet | | Opptak: Bakover | dolly ut, trekk tilbake, trekk deg tilbake, utvid | Kameraet beveger seg bort fra motivet | | Opptak: Venstre/høyre | panorering til venstre, panorering til høyre, sporing til venstre, sporing til høyre | Kameraet roterer eller sporer horisontalt | | Opptak: Opp/ned | vippe opp, vippe ned, kran opp, kran ned | Kameraet roterer eller beveger seg vertikalt | | Opptak: Orbit | orbit, revolve, rotate around, arc | Kameraet sirkler rundt motivet | | Kamera: Zoom | zoom in, zoom out, focal length shift | Kameraet zoomer (uten forflytning) | | Motiv: Mikrobevegelser | breathe, blink, shift weight, micro-movements | Subtile, naturtro bevegelser | | Motiv: Moderat | snu hodet, smile, gestikulere, gå sakte | Tydelig, men kontrollert bevegelse | | Motiv: Dynamisk | løpe, hoppe, danse, snurre, vinke | Energisk bevegelse av hele kroppen | | Omgivelser: Mild | bris, drive, svai, krusning, glitring | Myke bevegelser i omgivelsene | | Omgivelser: Intens | blåse, suse, krasje, virvle, foss | Kraftige bevegelser i omgivelsene | | Parallaks | parallaks, dybdeforskyvning, lagbevegelse | Forgrunn/bakgrunn beveger seg med ulik hastighet |

Ulike nøkkelord for kamerabevegelser gir helt forskjellige effekter. Velg kamerabevegelsesteknikk med omhu, i henhold til ønsket resultat.
Hastighet og tempokontroll
Bevegelsens tempo har stor innvirkning på den emosjonelle tonen i en video. Bruk følgende modifikatorer:
- Ekstremt langsom: «knapt merkbar», «ultra-slow motion», «isbre-tempo» — dramatisk, kontemplativ
- Langsom: «sakte», «forsiktig», «gradvis», «rolig» — eleganse, filmisk kvalitet
- Moderat: «jevnt», «naturlig tempo», «i ganghastighet» — realisme, dokumentarisk stil
- Rask: « raskt», «kvikt», «energisk», «hurtig» – dynamisk, spennende
- Ekstremt raskt: «raskt», «hurtig panorering», «rask klipping», «bevegelsesutbrudd» – spent, actionfylt
Avansert teknikk: Bruk sakte film som standard. I AI-genererte videoer ser sakte film nesten alltid bedre ut enn rask film. Raske bevegelser øker risikoen for feil og visuelle uoverensstemmelser.
Uavhengig bevegelseskontroll av bakgrunn og motiv
Du kan selv bestemme hva som skal bevege seg og hva som skal være stille. Dette er en effektiv teknikk for å styre publikums oppmerksomhet.
Motivet i bevegelse, bakgrunnen i ro:
The person walks forward confidently while the background remains
perfectly still. Static camera, no camera movement. Focus entirely
on the subject's motion.Dynamisk bakgrunn, statisk motiv:
The person stands completely still, like a statue. Behind them,
clouds drift across the sky, leaves blow in the wind, and city
lights flicker. Only the environment moves.Separate bevegelser fra begge sider:
The person slowly turns their head while the camera simultaneously
dollies in. Background clouds drift in the opposite direction,
creating a sense of depth and dimension.Forskjellen mellom kamerabevegelse og objektbevegelse
Det er avgjørende å forstå forskjellen mellom kamerabevegelse og objektbevegelse for å oppnå ønsket effekt.
Kamerabevegelse endrer perspektiv og komposisjon. Selve scenen forblir uendret, mens synsvinkelen endres. Brukes til: å avsløre scenen, etablere settingen og gi dramatisk vekt.
Objektbevegelse refererer til bevegelsen av elementer i en scene mens kameraet forblir stasjonært. Det brukes til: karakteranimasjon, produktdemonstrasjoner og naturlig miljødynamikk.
Kombinert bevegelse bruker begge teknikkene samtidig. Denne tilnærmingen gir de mest filmiske resultatene, men er samtidig den mest utfordrende for AI å utføre effektivt. Det anbefales å mestre én bevegelsestype først, og først legge til den andre når du er fornøyd med resultatet.
Avanserte promptstrukturer
For å oppnå mest mulig forutsigbare resultater, strukturer spørsmålet ditt i følgende rekkefølge:
- Primær handling — Hva hovedpersonen gjør
- Kamerabevegelse — Hvordan kameraet beveger seg
- Miljødynamikk — Hva miljøelementene gjør
- Hastighet/Tempo — Tempoet i all bevegelse
- Atmosfære/stemning — Den emosjonelle tonen
- Forbedring av visuell kvalitet — Teknisk beskrivelse av visuell kvalitet
Eksempel på bruk av denne strukturen:
[Subject] A young woman in a flowing white dress slowly raises
her hand to brush hair from her face.
[Camera] The camera executes a slow, steady dolly in from a
medium shot to a close-up.
[Environment] Cherry blossom petals drift gently through the
air. Soft golden sunlight filters through the trees.
[Speed] All motion is slow and deliberate, almost dreamlike.
[Mood] Romantic, ethereal, peaceful atmosphere.
[Quality] Cinematic shallow depth of field, anamorphic bokeh,
film grain, 4K quality.2026 TuSheng Video AI-verktøy sammenligning
Konkurransen i videostreamingsektoren blir stadig tøffere. Nedenfor følger en sammenlignende analyse av de største plattformene per februar 2026, med særlig vekt på tilgjengelighet for brukere på det kinesiske fastlandet.

Behandlingsresultatene av det samme kildebildet på fem forskjellige videoproduksjonsplattformer. Forskjeller i bevegelseskvalitet, tidsmessig konsistens og visuell trofasthet er umiddelbart synlige.
| Funksjon | Seedance 2.0 | Runway Gen-4 | Pika 2.0 | Kling 3.0 | Luma Dream Machine | |------|-------------|-------------|---------|------ ----------|-------------------| | Maksimal oppløsning | 2K (2048x1080) | 4K (oppskalert) | 1080p | 1080p | 1080p | | Maksimal varighet | 15 sekunder | 10 sekunder | 5 sekunder | 2 minutter | 5 sekunder | | Inndataalternativer | Bilde + tekst + video + lyd | Bilde + tekst + video | Bilde + tekst | Bilde + tekst | Bilde + tekst | | Inndata av flere bilder | Støttes (opptil 9 bilder) | Støttes ikke | Støttes ikke | Støttes ikke | Støttes ikke | | Innebygd lyd | Støttes (8 språk med leppesynkronisering) | Støttes ikke | Delvis (lydeffekter) | Støttes ikke | Støttes ikke | | Kamerakontroll | Promptbasert | Bevegelsesbørste + regissørmodus | Grunnleggende | Grunnleggende | Promptbasert | | Gratis kvote | Tilgjengelig (inkludert ved registrering) | Tilgjengelig (begrenset) | Tilgjengelig (begrenset) | Tilgjengelig (begrenset) | Tilgjengelig (begrenset) | | Startpris | ~9,90 $/måned | 15 $/måned | 10 $/måned | ~6,99 $/måned | 9,99 $/måned | | Tilgang fra Kina | Direkte tilgjengelig | VPN kreves | VPN kreves | Direkte tilgjengelig | VPN kreves | | Best egnet for | Multimodal kontroll, bildekvalitet | Profesjonell redigeringsarbeidsflyt | Nybegynnere, morsomme effekter | Langformvideo, høy verdi | Kinematisk følelse, 3D-scener |
Detaljerte anmeldelser av hvert verktøy
Seedance 2.0 er uovertruffen når det gjelder fleksibilitet i inndata. Det er den eneste plattformen som støtter samtidig opplasting av opptil ni referansebilder, lydinngang med leppesynkronisering og kombinasjon av alle inndatamoduser i én enkelt generasjon. Hvis du ønsker maksimal kontroll over bilde-til-video-utdata, tilbyr Seedance det mest omfattende verktøysettet. Dens 2K-oppløsning er også den høyeste blant alle verktøyene (uten å være avhengig av oppsampling). Utviklet av ByteDance (morselskapet til TikTok), kan brukere i Kina få direkte tilgang til det uten å trenge VPN eller utenlandske betalingsmetoder.
Runway Gen-4 utmerker seg med presis kontroll. Motion Brush lar deg nøye «male» hvilke deler av et bilde som skal bevege seg og i hvilken retning. Hvis du trenger kirurgisk presisjon over bestemte områder, er Runway det kraftigste alternativet. Ulempene er den høyere prisen og lavere generasjonskvoter. Tilgang fra Norge krever VPN.
Pika 2.0 er det mest tilgjengelige alternativet. For nybegynnere som ønsker å eksperimentere med å lage videoer fra bilder uten å lære seg prompt engineering, tilbyr Pikas effekter med ett klikk og strømlinjeformede grensesnitt den laveste inngangsbarrieren. Selv om bildekvaliteten ikke er på høyde med premiumverktøy, er den tilstrekkelig for uformelt sosialt innhold. Krever VPN for tilgang innenfor Kina.
Kling 3.0 overgår sine konkurrenter både når det gjelder kjøretid og pris/ytelse. Hvis du trenger å generere lengre videoer – 30 sekunder, 1 minutt eller til og med 2 minutter – fra et enkelt bilde, er Kling det eneste brukbare alternativet. Pris/bildekvalitet-forholdet er svært gunstig. Begrensningen ligger i de begrensede inndataalternativene (enkelt bilde + tekst). Som et produkt under Kuaishou-paraplyen er Kling direkte tilgjengelig i Kina, og tilbyr innenlandske brukere et annet sømløst alternativ.
Luma Dream Machine utmerker seg innen romlig forståelse. For landskap, arkitektur og scener hvor tredimensjonal romlig bevissthet er avgjørende, produserer Luma de mest overbevisende parallaks- og kamerabevegelsene. Karakteranimasjonen kommer til kort sammenlignet med konkurrentene. Tilgang fra hjemmet krever VPN.
Anbefalinger for brukere på fastlands-Kina
Hvis du befinner deg på fastlands-Kina, er det hovedsakelig to videoverktøy som kan brukes direkte uten VPN:
- Seedance 2.0 — Utviklet av ByteDance, fullt funksjonell og klar til bruk, med multimodal inndata + 2K-oppløsning + integrert lyd
- Kling 3.0 — Et produkt under Kuaishou, utmerker seg i generering av lange videoer med enestående valuta for pengene
Selv om utenlandske verktøy som Runway, Pika og Luma hver har sine egne særegne funksjoner, krever de alle VPN-tilgang og utenlandske betalingsmetoder, noe som utgjør en høyere inngangsbarriere.
For innholdsskapere på innenlandske plattformer som Douyin, Xiaohongshu, Bilibili og Kuaishou er det ikke bare mer praktisk å velge verktøy som er direkte tilgjengelige i Kina, men det gir også større sikkerhet når det gjelder nettverksstabilitet og betalingsenkelhet.
For en mer omfattende sammenligning (inkludert tekst-til-video-funksjoner), se vår Komplette rangering av AI-videogeneratorer for 2026.
Vanlige feil og korrigeringsmetoder
Etter å ha testet tusenvis av videoklipp, er dette de fem vanligste feilene vi har observert – sammen med konkrete tiltak for å rette dem opp.
- Bruk bilder med lav oppløsning
Feilen som ble gjort: Lastet opp et lite, komprimert bilde (for eksempel et miniatyrbilde på 400 x 300 lagret fra WeChat eller sosiale medier) mens man forventet video med høy oppløsning.
Hvorfor det mislykkes: Koderen kan ikke hente ut tilstrekkelig visuell informasjon fra bilder med lav oppløsning. Utdataene arver uskarpheten, samtidig som de overlagrer bevegelsesartefakter.
Slik løser du problemet: Bruk alltid bildet med høyest mulig oppløsning. Hvis det kun finnes versjoner med lav oppløsning, kan du bruke et AI-oppscaleringsverktøy (for eksempel Real-ESRGAN eller Topaz Gigapixel) for å forbedre oppløsningen før du laster opp bildet. Minste anbefalte størrelse er 1024 x 1024 piksler.
- Skriv scenebeskrivelser i stedet for handlingsbeskrivelser
Feilen som ble gjort: Skriveoppgaver som «Havoverflaten ved solnedgang, med gyldent lys som glitrer på vannet». Dette beskriver bildets utseende – noe AI-en allerede vet.
Hvorfor det mislyktes: AI-en har allerede kodet bildet. Å beskrive innholdet i bildet tilbake til den, er bortkastet plass på overflødig informasjon og gir ingen retning for handling.
Hvordan revidere: Fokuser hele oppgaven på bevegelsen. Omskriv til: «Bølgene ruller forsiktig mot kysten. Gyllent sollys glitrer på vannoverflaten. Skyene driver sakte fra venstre til høyre. Kameraet panorerer sakte mot høyre og følger kystlinjen.»
- Krever for mange handlinger som skal utføres samtidig
Feil som ble gjort: «Karakteren snur seg, vinker, går fremover, tar opp en kopp, smiler og danser, mens kameraet zoomer inn, panorerer til venstre og vipper.»
Hvorfor det mislykkes: Dagens AI-modeller kan ikke på en pålitelig måte koordinere mer enn to eller tre samtidige handlinger. Overbelastede kommandoer fører til at modellen enten ignorerer de fleste instruksjonene eller produserer forvirrende, feilfylte resultater.
Hvordan redigere: Begrens hver generasjon til én primær handling og én kamerabevegelse. For komplekse kontinuerlige handlinger, generer flere korte klipp separat før du redigerer og setter dem sammen.
- Ignorer feil i bildeformatet
Feilen som ble gjort: Lastet opp et landskapsbilde i 16:9-format, men satte utdataene til 9:16-portrettformat, eller omvendt.
Hvorfor det mislykkes: AI beskjærer bildet ditt drastisk eller krever at store tomme områder fylles ut. Ingen av metodene gir tilfredsstillende resultater – beskjæring ødelegger den nøye komponerte rammen, mens utfylling av store nye områder fører til inkonsekvenser.
Slik løser du problemet: Sørg for at utskriftsformatet samsvarer med kildebildets proporsjoner. Bruk 16:9 for liggende bilder og 9:16 for stående bilder. Hvis et annet format er nødvendig, beskjær kildebildet til målproposjonene før du laster det opp.
- Forventer en realistisk effekt fra illustrative bilder
Feilen som ble gjort: Å laste opp en tegneserieillustrasjon eller et flat designbilde, i forventning om at AI-en skulle generere fotorealistisk videobevegelse.
Hvorfor det mislykkes: Modellen forsøker å tolke kunstneriske stiler, og introduserer noen ganger uønsket realisme. Flate illustrasjoner mangler dybde og lyssignaler som modellen er avhengig av for å forutsi naturlige bevegelser.
Hvordan fikse det: Hvis kildematerialet er en illustrasjon, angir du stilen eksplisitt i instruksjonen: «Behold den illustrerte kunststilen nøyaktig. Animasjon i 2D-stil, ikke fotorealistisk. Bevegelsene skal føles håndtegnet og maleriske.» Dette instruerer modellen om å bevare den kunstneriske stilen i stedet for å innføre fotorealisme.
Ofte stilte spørsmål
Hvilket AI-verktøy er best egnet for å generere videoer fra bilder?
Seedance 2.0 er vår beste anbefaling for generering av bilder til video i 2026. Den støtter flere bildeinnganger (opptil 9 referansebilder), har en oppløsning på 2K og tilbyr den mest fleksible kombinasjonen av bilder, tekst, video og lyd. Videre er Seedance utviklet av ByteDance og er direkte tilgjengelig i Kina. For prisbevisste brukere leverer Kling 3.0 enestående bildekvalitet til en lavere pris, og er også direkte tilgjengelig i Kina. For nybegynnere har Pika 2.0 det mest oversiktlige grensesnittet. Det optimale valget avhenger av dine spesifikke behov – se vår [verktøysammenligningstabell](#2026-year image-to-video AI tool comparison).
Kan TuSheng Video brukes gratis?
Absolutt. Flere plattformer tilbyr gratis kvoter. Seedance gir gratis kreditt til alle nye brukere – uten krav om kredittkort. Pika 2.0 og Luma Dream Machine tilbyr også begrenset gratis generering. HaiLuo AI gir 10 gratis genereringer daglig. Disse gratis kvotene er tilstrekkelige for å teste teknologien og produsere flere videoer. Hvis du har behov for kontinuerlig bruk, er betalte abonnementer mer økonomisk. For flere strategier for gratis bruk, se vår Seedance Free Usage Guide.
Hva er maksimal lengde for AI-genererte videoer?
Ulike plattformer har forskjellige begrensninger. Kling 3.0 er ledende på området og genererer videoer på opptil 2 minutter fra ett enkelt bilde. Seedance 2.0 har en begrensning på 15 sekunder. Runway Gen-4 har en øvre grense på 10 sekunder. Pika 2.0 og Luma Dream Machine begrenser videoer til 5 sekunder. For de fleste sosiale medier og markedsføringsscenarier er 5–15 sekunder den optimale varigheten. Hvis det er behov for lengre opptak, kan man generere flere korte klipp for senere redigering og sammenkobling, eller bruke Kling til å generere lange videoer fra ett enkelt opptak.
Hvilket bildeformat er best egnet for AI-videogenerering?
PNG er optimalt, da det er et tapsfritt format uten komprimeringsartefakter. WebP (tapsfri modus) oppnår tilsvarende resultater med mindre filstørrelser. JPG er også egnet i de fleste tilfeller, men sterkt komprimerte JPG-filer med merkbare komprimeringsartefakter vil forringe utskriftskvaliteten. Unngå å bruke GIF, BMP eller andre ikke-standardiserte formater. Alle større plattformer støtter JPG, PNG og WebP. Minimum oppløsning: 512x512 piksler. Anbefalt: 1024x1024 eller høyere.
Kan AI animere alle typer bilder?
AI kan animere de fleste typer bilder, men resultatene varierer avhengig av motivet. Portretter og ansiktsbilder gir de mest overbevisende resultatene – dagens modeller fanger naturlige ansiktsuttrykk og hårbevegelser på en dyktig måte. Landskap og naturbilder gir også utmerkede resultater, med overbevisende gjengivelse av skybevegelser, rennende vann og svaiende løvverk. Produktbilder med ren bakgrunn gir gjennomgående pålitelige resultater. Illustrasjoner og kunstverk kan animeres, men det kan være nødvendig med skreddersydde stilprompter for å unngå utilsiktet fotorealisme. Komplekse gruppescener, bilder som inneholder mye tekst og fotografier av lav kvalitet gir de minst stabile resultatene.
Hva er forskjellen mellom bildegenerert video og tekstgenerert video?
Tekst-til-video genererer både visuelt innhold og bevegelse samtidig fra tekstbeskrivelser. AI-en dikterer hele det visuelle utseendet, noe som gir mindre kontroll over spesifikke detaljer, men større kreativ frihet. Bilde-til-video bruker dine eksisterende bilder som utgangspunkt og genererer bare bevegelsen. Du beholder presis kontroll over det visuelle resultatet, siden du gir den visuelle referansen. Image-to-Video gir vanligvis mer forutsigbare og konsistente resultater, siden AI-en har et konkret visuelt ankerpunkt. Text-to-Video er bedre egnet når AI-en skal lage helt nytt innhold fra bunnen av.
Kan Tusheng Video kontrollere kamerabevegelser?
Absolutt. De fleste moderne generative videoverktøy støtter kontroll av kamerabevegelser via tekstmeldinger. Du kan spesifisere bevegelser som «dolly in», «pan left», «orbit around», «crane up», «zoom out» og «tracking shot». Seedance 2.0 og Luma Dream Machine reagerer spesielt nøyaktig på disse bevegelsesnøkkelordene. Runway Gen-4 tilbyr ekstra presisjon gjennom Motion Brush og Director Mode, som muliggjør visuell banetegning for kamerabevegelser. Det anbefales å spesifisere bare én bevegelsestype per generasjon, supplert med hastighetsmodifikatorer som «sakte» eller «jevnt».
Er bildekvaliteten på AI-genererte videoer god nok til profesjonelle formål?
For kortformet videoinnhold (5–15 sekunder) er dette fullt mulig. Produkter fra toppplattformer som Seedance 2.0 og Runway Gen-4 har allerede blitt brukt profesjonelt til markedsføring på sosiale medier, produktvideoer for e-handel, eiendomspresentasjoner og reklamekonsepter. På hjemmemarkedet inneholder nå betydelig kommersielt innhold på Douyin og Xiaohongshu AI-genererte videoelementer. Det finnes imidlertid fortsatt begrensninger: lengre varighet øker risikoen for feil, komplekse scener med flere motiver er fortsatt ustabile, og tekstgjengivelse i videoer er fortsatt ufullkommen. For kringkastings- eller filmproduksjoner som krever absolutt perfeksjon, er tradisjonell filming fortsatt det sikreste alternativet. For digital markedsføring og sosialt innhold har AI-teknologi for bilde-til-video nådd profesjonelle standarder.
Sammendrag
TuSheng Video AI har utviklet seg fra å være en nyhet til å bli et uunnværlig verktøy for innholdsproduksjon. Teknologien har modnet, verktøyene har blitt brukervennlige, og kvaliteten på resultatet oppfyller nå profesjonelle standarder for de aller fleste scenarier innen digitalt innhold.
Følgende er de viktigste punktene:
- Kvaliteten på kildebildene er avgjørende. Skarpe, godt komponerte bilder med høy oppløsning gir langt bedre resultater enn uskarpe bilder eller bilder med lav oppløsning.
- Skriv bevegelse, ikke beskrivelse. AI-en har allerede sett bildet ditt. Fortell den hvordan ting skal bevege seg, ikke hvordan de ser ut.
- **Begynn enkelt. ** Én handling og én kamerabevegelse. Mestre det grunnleggende før du legger til kompleksitet.
- Gjenta raskt. Lag korte testklipp først; produser fullversjonen først når du er fornøyd.
- **Tilpass verktøyene til oppgavene. ** Seedance prioriterer visuell trofasthet og multimodal kontroll, KeLing utmerker seg med lange videoer og rimelige priser, Runway fokuserer på presis redigering, mens Pika legger vekt på enkelhet og brukervennlighet.
- Velg verktøyet som passer dine behov. Hvis du befinner deg på fastlandet i Kina, kan Seedance og KeLing brukes direkte uten ekstra nettverks- eller betalingsbarrierer.
Forskjellen mellom merkevarer og skapere som bruker Tusheng Video AI og deres kolleger som fortsatt er avhengige av statiske bilder, øker for hver måned. Hvert bilde i produktbiblioteket ditt er en potensiell videoreklame. Hvert portrett er en potensiell animert avatar. Hvert landskap er potensielt filmisk B-roll-opptak.
Lag din første bilde-til-video gratis --> — Last opp et hvilket som helst bilde og se det komme til live i løpet av to minutter. Ingen kredittkort kreves, direkte tilgjengelig i Kina.
Har du lyst til å utforske flere AI-videofunksjoner? Opplev Seedance på alle plattformer --> — Tekst til video, video til video, multimodal generering: alt håndteres på ett sted.
Videre lesning: Seedance komplett brukerveiledning | Seedance promptveiledning med over 50 eksempler | Eksempler på kreativ bruk av AI-video | Rangering av de beste AI-videogeneratorene for 2026 | AI-videomarkedsføring og sosial medieguide | Tekst-til-video AI: Komplett guide*
