
Résumé
L'IA Image-to-Video utilise une technologie d'apprentissage profond basée sur des modèles de diffusion pour transformer des images statiques en vidéos dynamiques. Contrairement à la génération purement texte-vidéo, il vous suffit de télécharger une photo pour que l'IA génère des mouvements réalistes, des mouvements de caméra et des séquences cohérentes dans le temps autour de celle-ci, vous permettant ainsi de contrôler plus précisément le résultat final. Ce guide couvre de manière exhaustive : les principes techniques derrière l'IA Image-to-Video ; les types d'images qui donnent des résultats optimaux ; un tutoriel pratique en cinq étapes pour créer votre première vidéo à partir de zéro ; huit cas d'utilisation pratiques avec des exemples concrets ; des techniques avancées de contrôle des mouvements ; et une comparaison réelle des outils courants en 2026 (y compris ceux directement accessibles en Chine). Essayez gratuitement l'IA Image-to-Video -->
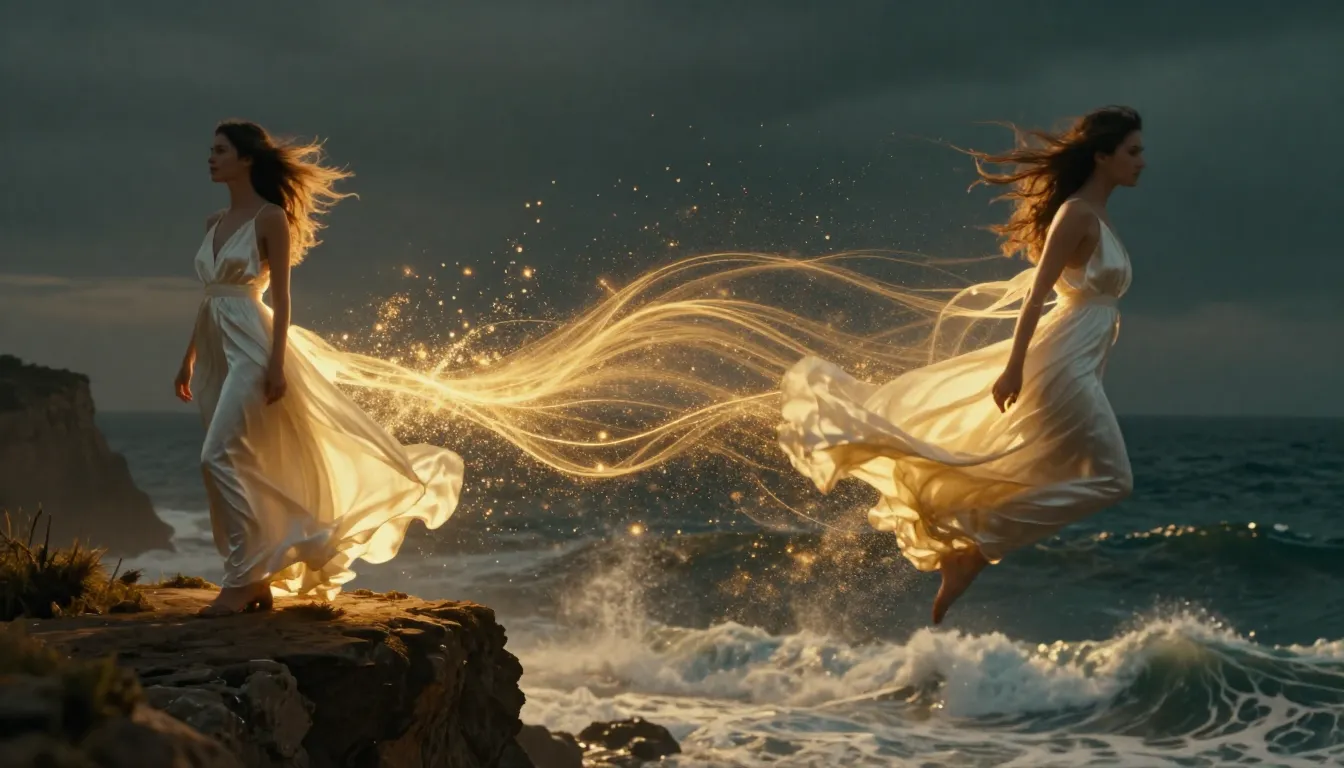
TuSheng Video AI prend vos photos et génère des mouvements réalistes, des mouvements de caméra cinématographiques et une continuité temporelle, transformant ainsi une simple image en un clip vidéo cinématographique.
Qu'est-ce que Tusheng Video AI ?
L'IA Image-to-Video est une technologie d'intelligence artificielle capable de générer des vidéos à partir d'images statiques. Vous fournissez une photographie (portrait, image de produit, paysage ou œuvre d'art) et le modèle d'IA produit une courte vidéo dans laquelle les éléments commencent à bouger, les angles de caméra changent et toute la scène prend vie.
À la base, la plupart des systèmes vidéo génératifs utilisent des modèles de diffusion vidéo. Ces réseaux neuronaux sont entraînés à partir de millions de paires de données vidéo-image, apprenant ainsi la relation statistique entre les images statiques et les mouvements naturels qui s'ensuivent. Lorsqu'une nouvelle image lui est présentée, le modèle prédit le mouvement qui semble le plus naturel et génère une séquence continue d'images qui s'enchaînent de manière fluide à partir de la photographie originale.
Différences par rapport à la conversion texte-vidéo
Text-to-Video crée entièrement à partir de texte. L'IA génère simultanément du contenu visuel et des mouvements à partir de votre invite textuelle. Puissante mais imprévisible, l'IA détermine de manière indépendante l'apparence du sujet, la composition de la scène et tous les schémas de mouvement.
Tusheng Video renverse cette logique : c'est vous qui fournissez l'ancrage visuel. L'IA sait déjà à quoi ressemble la scène, car vous la lui avez montrée directement. Sa seule tâche consiste à générer un mouvement plausible. Cela signifie que :
- Meilleur contrôle : vos images définissent le sujet, la composition, la palette de couleurs et le style
- Moins d'approximations : l'IA ne nécessite aucune interprétation de descriptions textuelles vagues
- Meilleure cohérence : les résultats correspondent étroitement aux images sources
- Itération plus rapide : Il est beaucoup plus simple d'ajuster la commande de mouvement que de réécrire toute la description de la scène
Pourquoi la vidéo TuSheng est-elle si importante en 2026 ?
TuSheng Video AI est passé d'un jouet expérimental à un outil de productivité. Les marques de commerce électronique transforment les images de leurs produits en publicités animées, les créateurs de contenu donnent vie à leurs publications les plus populaires, les agents immobiliers produisent des vidéos de visite virtuelle à partir de photos de propriétés, et les enseignants animent les illustrations des manuels scolaires.
Cette technologie a atteint un tournant décisif : les vidéos de 5 à 15 secondes générées à partir d'images sources de haute qualité sont désormais pratiquement impossibles à distinguer des séquences traditionnelles dans la plupart des cas. C'est précisément pour cette raison que la conversion d'images en vidéos est devenue la catégorie qui connaît la plus forte croissance dans le domaine de la génération de vidéos par IA.
Cette tendance est particulièrement marquée sur le marché chinois. Les algorithmes de plateformes telles que Douyin, Xiaohongshu, Bilibili et Kuaishou favorisent largement les contenus vidéo, créant ainsi une demande sans précédent parmi les créateurs pour des outils permettant de convertir rapidement des photos en vidéos. Tusheng Video AI comble précisément cette lacune sur le marché.
Principes techniques de l'IA vidéo Tusheng
Comprendre le processus technique vous aide à obtenir de meilleurs résultats. Lorsque vous savez pourquoi l'IA se comporte d'une certaine manière, vous pouvez fournir de meilleures données et rédiger des invites plus efficaces. Voici les quatre étapes du processus qui se déroule en coulisses.

Les quatre étapes du pipeline de traitement de l'IA vidéo Tusheng : encodage d'image, prédiction de mouvement, génération d'images et lissage temporel.
Première étape : encodage de l'image
L'IA analyse d'abord votre image d'entrée à l'aide d'un réseau d'encodeurs, puis la compresse en une représentation mathématique dense appelée vecteur latent. On peut considérer que l'IA extrait une « empreinte digitale » de votre image, en capturant sa structure, ses couleurs, sa profondeur, le positionnement du sujet, la direction de l'éclairage et les informations sémantiques.
Cette représentation latente est considérablement plus compacte que les données pixel originales, ce qui rend les calculs ultérieurs réalisables. La qualité de l'encodage a un impact direct sur les résultats obtenus. Des images d'entrée plus nettes et de plus haute résolution génèrent des représentations latentes plus riches, ce qui se traduit finalement par une sortie vidéo de qualité supérieure.
Deuxième étape : prédiction des mouvements
Il s'agit du cœur créatif de l'ensemble du processus. Le modèle de diffusion prédit quel type de mouvement semblerait naturel en fonction de votre image originale, en tenant compte des éléments suivants :
- Indices contextuels : une photographie d'océan implique que les vagues doivent déferler ; un portrait suggère des mouvements faciaux subtils
- Informations sur la profondeur : les objets plus proches de l'objectif peuvent présenter des schémas de mouvement différents de ceux des objets éloignés
- Plausibilité physique : les cheveux doivent flotter au vent, l'eau doit s'écouler vers le bas et les tissus doivent tomber naturellement.
- Votre invite de texte : si vous spécifiez « panoramique lent vers la gauche », le modèle ajustera sa prédiction de mouvement en conséquence.
Le modèle ne se contente pas de déformer les pixels. Il génère un contenu visuel entièrement nouveau pour les zones nouvellement exposées par le mouvement de la caméra ou celui des objets. Si la caméra effectue un panoramique vers la droite, le modèle « remplira » la scène au-delà du bord droit de l'image d'origine.
Troisième étape : génération du cadre
Sur la base de la prédiction de mouvement, le modèle génère une séquence d'images vidéo. Chaque image est produite par un processus de diffusion inverse : à partir du bruit, elle s'affine progressivement pour former une image claire tout en conservant sa cohérence avec l'image précédente et l'image originale.
Seedance 2.0 et d'autres modèles modernes génèrent des images à des fréquences élevées (24 à 30 images par seconde) tout en conservant la cohérence des sous-pixels entre les images. Cela garantit un rendu fluide et sans scintillement, sans les problèmes de saccades courants sur les systèmes antérieurs.
Étape 4 : Lissage temporel
La dernière étape garantit des transitions fluides entre toutes les images générées. Le mécanisme d'attention temporelle vérifie que la luminosité, la couleur et le mouvement restent cohérents tout au long de la vidéo, évitant ainsi les artefacts visuels courants :
- Changements soudains de couleur entre les images
- Apparition ou disparition inattendue d'objets
- Accélération ou décélération anormale du mouvement
- Scintillement de la texture de la surface
Le résultat final est une vidéo magnifique qui s'inscrit naturellement dans la continuité des images originales.
Pourquoi certaines images sont-elles plus belles que d'autres ?
Vous comprenez désormais pourquoi la qualité de l'image d'entrée est si importante. Une image floue et de faible résolution produit un encodage latent bruité lors de la première étape, fournissant moins d'informations au modèle de prédiction de mouvement (deuxième étape). Il en résulte un mouvement moins précis et davantage d'artefacts visuels dans le résultat final. À l'inverse, une image nette et bien composée, avec des repères de profondeur clairs, fournit au modèle des informations riches, ce qui se traduit par une vidéo plus naturelle et de meilleure qualité.
Quel type d'image donne les meilleurs résultats ?
Toutes les images ne sont pas adaptées à TuSheng Video AI. La différence entre un bon matériel source et un mauvais matériel source peut très bien être l'écart entre une vidéo époustouflante et une pile d'images inutilisables. Voici un guide pratique.

Le côté gauche affiche les images sources appropriées (haute résolution, bien composées, suggérant un mouvement naturel), tandis que le côté droit montre les images sources inappropriées (floues, encombrées, contenant des éléments difficiles à traiter par l'IA).
Types d'images adaptés
Haute résolution (1024x1024 ou plus). Un nombre plus élevé de pixels permet à l'encodeur d'extraire davantage de détails. Utilisez toujours la version avec la résolution la plus élevée disponible. Résolution minimale recommandée : 512x512 pixels. Résolution idéale : 1024x1024 ou plus.
Les sujets sont clairement définis avec des contours distincts. L'IA doit discerner ce qui doit bouger et ce qui doit rester statique. Un portrait où le sujet est nettement séparé de l'arrière-plan donne des résultats bien supérieurs à ceux obtenus avec une scène de groupe complexe et chaotique.
Bien éclairées et correctement exposées. Les images bien éclairées fournissent des informations précises sur les couleurs et la profondeur du modèle. Évitez les images fortement surexposées ou sous-exposées.
Superposition et composition naturelles. Les images avec un premier plan, un plan intermédiaire et un arrière-plan clairement définis fournissent à l'IA des repères de profondeur, améliorant ainsi le réalisme des effets de parallaxe et des mouvements de caméra.
Images suggérant le mouvement. Les indices picturaux du mouvement (cheveux fouettés par le vent, vagues sur le point de s'écraser sur le rivage, silhouette avançant à grands pas) fournissent au modèle des points de départ efficaces pour prédire le mouvement. L'IA peut discerner « ce qui va se passer ensuite » à partir de ces indicateurs visuels.
Arrière-plans épurés. Un arrière-plan simple ou naturellement flou produit une vidéo plus fluide qu'un arrière-plan encombré de nombreux petits objets.
Types d'images pouvant poser problème
Images floues ou mal mises au point. Flou à l'entrée, flou à la sortie. L'IA ne peut pas ajouter de netteté qui n'était pas présente dans l'image originale.
Scènes excessivement complexes. Les images contenant de nombreux petits sujets, des motifs complexes ou un encombrement visuel peuvent submerger les modèles de prédiction de mouvement, les rendant incapables de déterminer ce qui doit bouger et comment.
Texte ou typographie volumineux. Les modèles vidéo IA ont encore du mal à maintenir la lisibilité du texte d'une image à l'autre. Si vos images contiennent des logos, des marques ou des superpositions de texte, une distorsion apparaîtra dans la vidéo finale.
Basse résolution (512x512 ou moins). Les petites images contiennent trop peu d'informations. Même les agrandir à l'aide de l'IA avant de les saisir s'avère inutile, car cela ajoute des pixels, mais pas d'informations.
Filtres lourds ou post-traitement. Les réglages extrêmes des couleurs, le traitement HDR ou les modifications importantes apportées dans Photoshop peuvent perturber la compréhension du modèle en matière d'éclairage et de profondeur.
Visages multiples de tailles variables. L'IA gère efficacement les portraits individuels. Les photos de groupe où les visages sont à des distances différentes produisent des animations incohérentes : certains visages semblent naturels, tandis que d'autres sont déformés.
Liste de contrôle à effectuer avant le téléchargement
Avant de télécharger des images, vérifiez rapidement les points suivants :
- Résolution minimale de 1024x1024 pixels
- Sujet clairement défini et nettement séparé de l'arrière-plan
- Exposition correcte (ni sous-exposée ni surexposée)
- Pas de filtres lourds, de HDR extrême ou de traces de traitement artificiel
- Texte, logos ou éléments typographiques minimaux
- Complexité de la scène contrôlée (1 à 3 sujets principaux)
- Format d'image : JPG, PNG ou WebP
Une fois ces conditions remplies, la production peut commencer.
Guide étape par étape : générez votre première image-vidéo
Suivez ces cinq étapes pour transformer n'importe quelle image statique en une vidéo animée générée par IA. Nous utiliserons Seedance comme plateforme de démonstration, mais ces principes s'appliquent à n'importe quel outil de conversion d'images en vidéos.
Première étape : sélectionner des images sources appropriées
L'image source est le facteur le plus déterminant pour la qualité du résultat final. Choisissez une image qui respecte les directives énoncées précédemment. Pour votre première tentative, nous vous recommandons de choisir un portrait simple ou un paysage avec une profondeur prononcée. Ces deux types d'images donnent les résultats les plus cohérents.
Images recommandées pour les premières tentatives :
- Portrait net en gros plan ou en demi-longueur sous un bon éclairage
- Paysages comportant du ciel, des surfaces aquatiques ou de la végétation (ces éléments possèdent un mouvement inhérent)
- Images de produits sur fond uni
- Œuvres d'art ou illustrations comportant des éléments clairement définis
Lors de la première génération, évitez d'utiliser des images composites complexes, des images contenant de grandes quantités de texte ou des photographies fortement retouchées.
Deuxième étape : télécharger vers Seedance
Ouvrez Seedance Image-to-Video et téléchargez les images sélectionnées. Seedance prend en charge les formats JPG, PNG et WebP. La plateforme analysera automatiquement vos images et les préparera pour la génération.
Si une image est exceptionnellement grande (avec un côté dépassant 4096 pixels), le système la redimensionnera automatiquement tout en conservant son rapport hauteur/largeur, éliminant ainsi le besoin d'un ajustement manuel.
Troisième étape : élaborer une invite axée sur le mouvement
À ce stade, vous informez l'IA du mouvement souhaité. Votre invite doit décrire la dynamique plutôt que le contenu de l'image (l'IA a déjà vu l'image). Concentrez-vous sur les points suivants :
- Mouvement du sujet : que doit faire le sujet ?
- Mouvement de la caméra : comment la caméra doit-elle bouger ?
- Mouvement de l'environnement : quelle dynamique environnementale doit être présente ?
- Rythme et ambiance : tempo général – rapide ou lent ?
Exemples de suggestions pour les portraits :
The woman slowly turns her head to the right and smiles softly.
A gentle breeze moves her hair. Background slightly out of focus
with subtle bokeh movement. Camera slowly pushes in from medium
shot to a close-up. Warm, natural lighting. Cinematic film quality.Exemple d'invite paysage :
Gentle waves roll toward the shore in slow motion. Clouds drift
slowly across the sky from left to right. Sunlight shimmers on
the water surface. Camera slowly pans right, revealing more of
the coastline. Peaceful, serene atmosphere. 4K cinematic quality.Exemple d'invite produit :
The camera slowly orbits around the product, rotating 45 degrees
clockwise. Soft studio lighting with subtle caustic reflections
on the surface. Clean white background with gentle gradient.
Premium commercial aesthetic. Smooth, steady camera movement.Principe fondamental : Décrivez le mouvement, pas la scène. La scène existe déjà dans votre image.
Remarque : Seedance prend en charge les invites en chinois et en anglais, bien que les invites en anglais permettent généralement un contrôle plus précis des mouvements de la caméra. Il est recommandé d'utiliser l'anglais pour les descriptions liées au mouvement et à la caméra, tandis que le chinois peut être utilisé pour les descriptions d'ambiance et de style.
Étape 4 : Sélectionner les paramètres
Configurer les paramètres de génération :
| Paramètre | Valeur recommandée | Description |
|---|---|---|
| Modèle | Seedance 2.0 | Qualité d'image optimale pour la génération d'images en vidéo |
| Durée | 5 secondes (pour les essais initiaux) | Commencez par une durée courte, puis allongez-la ; générez des versions plus longues lorsque vous êtes satisfait |
| Format d'image | Correspond à l'image | 16:9 pour le format paysage, 9:16 pour le format portrait, 1:1 pour le format carré |
| Résolution | 1080p | Sélectionnez toujours la résolution la plus élevée disponible |
Technique avancée : générez d'abord une version de 5 secondes. Si le mouvement et le style vous satisfont, utilisez la même invite pour générer une version plus longue (8 à 15 secondes). Cette approche permet d'économiser des crédits pendant la phase d'exploration.
Étape 5 : Générer, vérifier, itérer
Cliquez sur Générer et attendez 1 à 3 minutes. Une fois les résultats affichés, évaluez-les selon les critères suivants :
- Le mouvement est-il fluide et naturel ?
- Le sujet conserve-t-il une cohérence visuelle tout au long de la vidéo ?
- Le mouvement de la caméra correspond-il à vos attentes ?
- Y a-t-il des imperfections visuelles (scintillement, distorsion, déformation) ?
- La qualité vidéo correspond-elle à celle du métrage original ?
Si un aspect s'avère insatisfaisant, ajustez l'invite et régénérez. Les méthodes d'ajustement courantes comprennent :
- Trop rapide ? Ajoutez « lentement », « doucement », « progressivement » à la description du mouvement
- Mauvaise direction de la caméra ? ** Précisez plus clairement : « caméra statique, pas de mouvement de caméra » ou « lent travelling avant »
- Des imperfections faciales ? Simplifiez le mouvement : réduisez le nombre d'actions simultanées
- **Manque de dynamisme ? ** Introduisez des verbes dynamiques : « se balancer », « couler », « dériver », « se déplacer »
Après deux ou trois cycles d'itération, vous obtiendrez une vidéo de haute qualité qui donnera vie à vos images.
Commencez dès maintenant à créer votre premier clip vidéo à partir d'une image -->
8 applications principales et exemples de conversion d'images volumineuses en vidéos
TuSheng Video AI n'est pas un outil à usage unique. Il sert à des dizaines d'applications créatives et commerciales. Vous trouverez ci-dessous huit scénarios d'application à forte valeur ajoutée, accompagnés d'instructions pratiques prêtes à être copiées et modifiées.
- Animation de portraits
Donnez vie à vos photos. Portrait Animation est l'application photo-vidéo la plus populaire. Téléchargez une photo de profil, un selfie ou une image de personnage, puis ajoutez des animations subtiles et réalistes : respiration, clignement des yeux, rotation de la tête, changements d'expression et mouvement des cheveux.
Convient aux vidéos commémoratives, aux contenus destinés aux réseaux sociaux, à la création d'avatars virtuels et à la narration créative. Sur Douyin et Xiaohongshu, les contenus « photos animées » restent un aimant à trafic constant.

Un portrait statique se transforme en une vidéo réaliste : clignements d'yeux naturels, mouvements subtils de la tête et cheveux flottants, l'effet est étonnamment réaliste.
Exemple d'invite :
The person looks directly at the camera with a calm, confident
expression. They slowly tilt their head slightly to the left and
give a subtle warm smile. Eyes blink naturally. A soft breeze gently
moves their hair. Shallow depth of field with softly blurred
background. Warm natural lighting. Cinematic portrait quality.- Présentation des produits
Transformez vos photos de produits en contenu commercial dynamique. C'est une véritable révolution pour les marques de commerce électronique et les influenceurs : vous possédez déjà des centaines, voire des milliers d'images de produits, et chacune d'entre elles peut désormais devenir une publicité vidéo, un visuel clé pour les pages détaillées des produits ou un court-métrage destiné aux réseaux sociaux.
Sur les pages détaillées des produits Taobao et JD.com, dans les présentations de produits en direct sur Douyin et dans les publications de recommandations de produits sur Xiaohongshu, les affichages dynamiques des produits obtiennent des taux de conversion nettement supérieurs à ceux des images statiques.

Une image de produit standard est rehaussée pour atteindre le niveau de sophistication d'une publicité commerciale haut de gamme, avec des rotations d'objectif, un éclairage spectaculaire et des mouvements fluides, une production traditionnelle qui pourrait coûter des centaines, voire des milliers de livres sterling.
Exemple d'invite :
The camera slowly orbits 90 degrees around the product, revealing
its form from multiple angles. Soft directional studio lighting
with subtle caustic reflections on the surface. A gentle highlight
sweep moves across the product. Clean, premium commercial aesthetic.
Shallow depth of field. Ultra-smooth camera movement. 4K quality.3. Time-lapse panoramique
Transformez vos photos de paysages en vidéos atmosphériques de type time-lapse. Les nuages défilent dans le ciel, l'eau coule, la lumière passe des teintes dorées aux tons bleus et les feuilles ondulent dans la brise. Idéal pour les contenus liés au voyage, les présentations aériennes de propriétés immobilières et les séquences d'ambiance.
Les photographes paysagistes et les vlogueurs de voyage sur Bilibili peuvent directement transformer leurs photos sélectionnées en vidéos captivantes en accéléré, ce qui réduit considérablement les coûts de production.

Une photographie de paysage transformée en time-lapse cinématographique — nuages fluides, eau ondulante, jeux d'ombres et de lumières — créant une atmosphère dynamique à partir d'une seule image statique.
Exemple d'invite :
Time-lapse effect. Clouds move steadily across the sky from left
to right. Water in the foreground ripples and flows gently. Light
shifts subtly as if the sun is moving, creating slowly changing
shadows on the landscape. Trees and grass sway gently in the wind.
Camera remains static on a tripod. Serene, majestic atmosphere.
Cinematic landscape quality.4. Contenu des réseaux sociaux
Transformez vos publications statiques les plus performantes en contenu vidéo qui incite les utilisateurs à s'arrêter de faire défiler leur fil d'actualité. Les algorithmes des plateformes telles que TikTok, Xiaohongshu, Bilibili et Kuaishou favorisent largement le contenu vidéo. Une publication image très performante obtiendra presque certainement un meilleur trafic lorsqu'elle sera convertie en vidéo.
Pour les créateurs de contenu Xiaohongshu, une série de publications image-texte peut voir son exposition multipliée par 3 à 5 si elle est accompagnée d'une version vidéo. Douyin et Kuaishou, quant à eux, fonctionnent entièrement sur la vidéo comme format de contenu principal.
Exemple d'invite :
Dynamic, attention-grabbing motion. The subject moves confidently
toward the camera with energy and presence. Background elements
shift with parallax depth effect. Quick, punchy camera push-in
that creates impact. Vibrant colors, high contrast. Bold,
eye-catching aesthetic optimized for social media. Vertical 9:16.- Animation artistique et illustration
Donnez vie à vos œuvres d'art, illustrations, peintures numériques et créations graphiques. Ce scénario d'application est très apprécié des artistes, concepteurs de jeux et équipes créatives qui cherchent à présenter leur travail de manière plus attrayante.
Au sein des communautés artistiques et anime de Bilibili et Xiaohongshu, les illustrations animées sont considérées comme un contenu très engageant. La transformation d'œuvres d'art statiques en vidéos de type « fond d'écran animé » génère souvent un nombre de partages et d'enregistrements nettement supérieur à celui des images originales.
Exemple d'invite :
The illustrated scene comes to life with gentle, painterly motion.
Characters move subtly within their positions -- breathing, shifting
weight, small gestures. Background elements like leaves, clouds,
or particles drift slowly. The artistic style is preserved exactly
as painted. Movement is smooth and dreamlike, like a living painting.
Gentle ambient lighting shifts. Fantasy illustration quality.6. Visites virtuelles de propriétés
Transformez les photos immobilières en vidéos de visite virtuelle. Les agents immobiliers peuvent créer des aperçus immersifs à partir des images existantes des biens immobiliers, ce qui leur évite de devoir faire appel à des équipes de photographes spécialisés pour réaliser des prises de vue sur place.
Pour les annonces immobilières affichées sur des plateformes telles que Beike et Anjuke, ainsi que pour les promotions immobilières dans WeChat Moments et Xiaohongshu, les vidéos de visite dynamique affichent un taux de conversion nettement plus élevé en termes de demandes de renseignements de la part des clients.
Exemple d'invite :
Smooth virtual walkthrough. The camera glides forward slowly into
the room, revealing the space with a wide-angle perspective.
Natural daylight streams through the windows, casting soft shadows.
Subtle dust particles float in the sunbeams. The camera pans
gently to the left, showing the full room layout. Clean, bright,
aspirational real estate aesthetic. Steady, professional movement.- Défilé de mode et stylisme
Créez du contenu mode dynamique à partir de photos de tenues prises en studio. Les mannequins bougent, les tissus tombent naturellement, tandis que le style esthétique digne d'un éditeur reste intact.
Les blogueurs mode Xiaohongshu et les vendeurs de vêtements Taobao peuvent convertir de grandes quantités de photos de mannequins et de tenues en vidéos dynamiques, créant ainsi un plus grand impact visuel dans les flux d'informations.
Exemple d'invite :
The model strikes a confident pose and then slowly shifts their
weight, creating natural body movement. Fabric of the outfit
flows and catches the light with each subtle motion. Wind effect
gently moves the hair. Camera starts at full body and slowly drifts
upward to a waist-up shot. High-fashion editorial lighting with
strong directional shadows. Vogue magazine aesthetic. Cinematic
slow motion.- Contenu éducatif et explicatif
Transformez des graphiques statiques, des infographies et des illustrations éducatives en présentations dynamiques. Les concepts complexes deviennent plus faciles à comprendre lorsqu'ils sont mis en mouvement.
Les créateurs de la zone de connaissances de Bilibili et de diverses plateformes éducatives peuvent transformer des supports de cours, des diagrammes et des organigrammes en ressources vidéo animées, améliorant ainsi considérablement l'efficacité de l'enseignement et les taux de rétention des spectateurs.
Exemple d'invite :
The diagram elements animate sequentially. Arrows begin to flow
in their indicated directions. Labels fade in one by one. Moving
parts of the system activate in logical order, showing the process
step by step. Smooth transitions between stages. Clean, clear
educational style. Elements highlight with subtle glow as they
become active. Professional presentation quality.Guide complet des techniques de prompt vidéo Tusheng
Une invite bien rédigée est la compétence la plus puissante pour générer des images à partir de photos. Étant donné que l'IA a déjà vu votre image, votre invite doit se concentrer entièrement sur le mouvement et le dynamisme. Voici les techniques qui donnent les meilleurs résultats.
Guide de référence rapide des mots-clés liés au sport
Utilisez ces mots-clés spécifiques pour contrôler avec précision le mouvement de la vidéo.
| Type de mouvement | Mots-clés | Effet | |-------- -|-------|------| | Caméra : avant | travelling avant, zoom avant, se rapprocher, s'approcher | La caméra se déplace vers le sujet | | Caméra : arrière | travelling arrière, zoom arrière, reculer, s'éloigner | La caméra s'éloigne du sujet | | Plan : gauche/droite | panoramique vers la gauche, panoramique vers la droite, suivi vers la gauche, suivi vers la droite | La caméra pivote ou suit horizontalement | | Plan : haut/bas | inclinaison vers le haut, inclinaison vers le bas, grue vers le haut, grue vers le bas | La caméra pivote ou se déplace verticalement | | Plan : Orbite | orbite, rotation, rotation autour, arc | La caméra tourne autour du sujet | | Caméra : Zoom | zoom avant, zoom arrière, changement de distance focale | La caméra effectue un zoom (sans déplacement) | | Sujet : Micro-mouvements | respiration, clignement des yeux, transfert de poids, micro-mouvements | Mouvements subtils et réalistes | | Sujet : modéré | tourner la tête, sourire, faire un geste, marcher lentement | Mouvements clairs mais contrôlés | | Sujet : dynamique | courir, sauter, danser, tourner, agiter la main | Mouvements énergiques de tout le corps | | Environnement : Doux | brise, dérive, balancement, ondulation, scintillement | Mouvements environnementaux doux | | Environnement : intense | souffle, précipitation, collision, tourbillon, cascade | Dynamique environnementale vigoureuse | | Parallaxe | parallaxe, changement de profondeur, mouvement des couches | Déplacement du premier plan/arrière-plan à des vitesses différentes |

Différents mots-clés de mouvement de caméra produisent des effets totalement distincts. Choisissez délibérément votre technique de mouvement de caméra en fonction du résultat souhaité.
Contrôle de la vitesse et du tempo
Le rythme du mouvement a un effet profond sur le ton émotionnel d'une vidéo. Utilisez les modificateurs suivants :
- Extrêmement lent : « à peine perceptible », « ultra-ralenti », « rythme glacial » — Dramatique, contemplatif
- Lent : « lentement », « doucement », « progressivement », « tranquillement » — élégance, qualité cinématographique
- Modéré : « régulier », « rythme naturel », « à vitesse de marche » — réalisme, style documentaire
- Rapide : « rapidement », « vivement », « énergiquement », « rapidement » — dynamique, exaltant
- Extrêmement rapide : « rapide », « panoramique rapide », « montage rapide », « explosion de mouvement » — tendu, plein d'action
Technique avancée : utilisez le ralenti par défaut. Dans les vidéos générées par IA, le ralenti est presque toujours plus esthétique que l'accéléré. Les mouvements rapides augmentent le risque d'imperfections et d'incohérences visuelles.
Contrôle indépendant du mouvement de l'arrière-plan et du sujet
Vous pouvez contrôler indépendamment ce qui bouge et ce qui reste immobile. Il s'agit d'une technique puissante pour diriger l'attention du public.
Sujet en mouvement, arrière-plan immobile :
The person walks forward confidently while the background remains
perfectly still. Static camera, no camera movement. Focus entirely
on the subject's motion.Arrière-plan dynamique, sujet statique :
The person stands completely still, like a statue. Behind them,
clouds drift across the sky, leaves blow in the wind, and city
lights flicker. Only the environment moves.Mouvements séparés des deux côtés :
The person slowly turns their head while the camera simultaneously
dollies in. Background clouds drift in the opposite direction,
creating a sense of depth and dimension.La distinction entre le mouvement de la caméra et le mouvement de l'objet
Il est essentiel de comprendre la distinction entre le mouvement de la caméra et le mouvement de l'objet pour obtenir l'effet souhaité.
Le mouvement de caméra modifie la perspective et la composition. La scène elle-même reste immobile, tandis que le point de vue change. Utilisé pour : révéler la scène, établir le décor et créer un effet dramatique.
Le mouvement d'objet désigne le déplacement d'éléments au sein d'une scène alors que la caméra reste immobile. Il est utilisé pour : l'animation de personnages, les démonstrations de produits et la dynamique des environnements naturels.
Les mouvements combinés utilisent les deux simultanément. Il s'agit de la technique la plus cinématographique, mais aussi la plus difficile à exécuter correctement pour l'IA. Il est conseillé de maîtriser d'abord un seul type de mouvement, puis d'ajouter l'autre une fois que vous êtes satisfait.
Structures d'invites avancées
Pour obtenir les résultats les plus prévisibles, organisez votre invite dans l'ordre suivant :
- Action principale — Ce que fait le sujet principal
- Mouvement de la caméra — Comment la caméra se déplace
- Dynamique environnementale — Ce que font les éléments environnementaux
- Vitesse/rythme — Le tempo de tous les mouvements
- Atmosphère/Ambiance — Ton émotionnel
- Amélioration de la qualité visuelle — Description technique de la qualité visuelle
Exemple d'utilisation de cette structure :
[Subject] A young woman in a flowing white dress slowly raises
her hand to brush hair from her face.
[Camera] The camera executes a slow, steady dolly in from a
medium shot to a close-up.
[Environment] Cherry blossom petals drift gently through the
air. Soft golden sunlight filters through the trees.
[Speed] All motion is slow and deliberate, almost dreamlike.
[Mood] Romantic, ethereal, peaceful atmosphere.
[Quality] Cinematic shallow depth of field, anamorphic bokeh,
film grain, 4K quality.Comparaison des outils vidéo IA TuSheng 2026
La concurrence dans le secteur du streaming vidéo s'intensifie. Vous trouverez ci-dessous une analyse comparative des principales plateformes en février 2026, mettant particulièrement l'accent sur l'accessibilité pour les utilisateurs en Chine continentale.

Résultats du traitement d'une même image source sur cinq plateformes de génération vidéo différentes. Les différences en termes de qualité du mouvement, de cohérence temporelle et de fidélité visuelle sont immédiatement perceptibles.
| Caractéristique | Seedance 2.0 | Runway Gen-4 | Pika 2.0 | Kling 3.0 | Luma Dream Machine | |------|-------------|-------------|---------|------ ----------|-------------------| | Résolution maximale | 2K (2048x1080) | 4K (upscalée) | 1080p | 1080p | 1080p | | Durée maximale | 15 secondes | 10 secondes | 5 secondes | 2 minutes | 5 secondes | | Options d'entrée | Image + texte + vidéo + audio | Image + texte + vidéo | Image + texte | Image + texte | Image + texte | | Entrée multi-images | Prise en charge (jusqu'à 9 images) | Non prise en charge | Non prise en charge | Non prise en charge | Non prise en charge | | Audio natif | Pris en charge (8 langues avec synchronisation labiale) | Non pris en charge | Partiel (effets sonores) | Non pris en charge | Non pris en charge | | Contrôle de la caméra | Basé sur des invites | Pinceau de mouvement + Mode réalisateur | Basique | Basique | Basé sur des invites | | Quota gratuit | Disponible (fourni lors de l'inscription) | Disponible (restreint) | Disponible (restreint) | Disponible (restreint) | Disponible (restreint) | | Prix de départ | ~9,90 $/mois | 15 $/mois | 10 $/mois | ~6,99 $/mois | 9,99 $/mois | | Accès depuis la Chine continentale | Accès direct | VPN requis | VPN requis | Accès direct | VPN requis | | Idéal pour | Contrôle multimodal, qualité d'image | Flux de travail d'édition professionnel | Débutants, effets amusants | Vidéos longues, grande valeur | Ambiance cinématographique, scènes en 3D |
Examens détaillés de chaque outil
Seedance 2.0 est sans égal en matière de flexibilité d'entrée. C'est la seule plateforme qui prend en charge le téléchargement simultané de neuf images de référence, la synchronisation labiale de l'entrée audio et la combinaison de tous les modes d'entrée en une seule génération. Pour un contrôle maximal de la sortie image-vidéo, Seedance offre la boîte à outils la plus complète. Sa sortie en résolution 2K est également la plus élevée de tous les outils (sans recourir au suréchantillonnage). Développé par ByteDance (société mère de TikTok), les utilisateurs de Chine continentale peuvent y accéder directement sans avoir besoin d'un VPN ou de moyens de paiement étrangers.
Runway Gen-4 excelle dans le contrôle précis. Motion Brush vous permet de « peindre » méticuleusement les parties d'une image qui doivent bouger et dans quelle direction. Si vous avez besoin d'une précision chirurgicale sur des zones spécifiques, Runway est le choix le plus judicieux. Ses inconvénients sont son prix plus élevé et ses quotas de génération plus faibles. Un accès depuis le territoire national nécessite un VPN.
Pika 2.0 est l'option la plus accessible. Pour les novices qui souhaitent s'essayer à la génération d'images à partir de vidéos sans avoir à apprendre l'ingénierie des invites, les effets en un clic et l'interface simplifiée de Pika offrent le seuil d'entrée le plus bas. Bien que la qualité d'image soit inférieure à celle des outils haut de gamme, elle est suffisante pour les contenus sociaux occasionnels. Nécessite un VPN pour y accéder depuis la Chine continentale.
Kling 3.0 surpasse ses concurrents tant en termes de durée que de rapport qualité-prix. Si vous avez besoin de générer des vidéos longues (30 secondes, 1 minute, voire 2 minutes) à partir d'une seule image, Kling est la seule option viable. Son rapport qualité-prix est exceptionnellement avantageux. Sa limitation réside dans ses options d'entrée restreintes (image unique + texte). En tant que produit de Kuaishou, Kling est directement accessible en Chine continentale, offrant ainsi aux utilisateurs nationaux une autre option transparente.
Luma Dream Machine excelle dans la compréhension spatiale. Pour les paysages, l'architecture et les scènes où la perception spatiale en trois dimensions est cruciale, Luma produit les mouvements de parallaxe et de caméra les plus convaincants. L'animation des personnages est toutefois moins performante que celle de ses concurrents. Un accès depuis le territoire national nécessite un VPN.
Recommandations pour les utilisateurs de Chine continentale
Si vous vous trouvez en Chine continentale, il existe principalement deux outils vidéo qui peuvent être utilisés directement sans VPN :
- Seedance 2.0 — Développé par ByteDance, entièrement fonctionnel et prêt à l'emploi, avec saisie multimodale + résolution 2K + audio intégré
- Kling 3.0 — Un produit de Kuaishou, excellent pour la création de vidéos longues, offrant un excellent rapport qualité-prix
Bien que les outils étrangers tels que Runway, Pika et Luma possèdent chacun leurs propres caractéristiques distinctives, ils nécessitent tous un accès VPN et des méthodes de paiement étrangères, ce qui représente un obstacle supplémentaire à leur utilisation.
Pour les créateurs de contenu sur les plateformes nationales telles que Douyin, Xiaohongshu, Bilibili et Kuaishou, opter pour des outils directement accessibles en Chine est non seulement plus pratique, mais offre également une plus grande garantie en termes de stabilité du réseau et de facilité de paiement.
Pour une comparaison plus complète (incluant les fonctionnalités de conversion texte-vidéo), veuillez consulter notre classement complet des générateurs de vidéos IA 2026.
Erreurs courantes et méthodes de correction
Après avoir testé des milliers de clips vidéo, voici les cinq erreurs les plus courantes que nous avons observées, ainsi que les mesures correctives spécifiques.
- Utilisez des images d'archives à basse résolution.
L'erreur commise : télécharger une petite image compressée (telle qu'une vignette de 400 x 300 pixels enregistrée à partir de WeChat ou des réseaux sociaux) tout en s'attendant à obtenir une vidéo haute définition.
Pourquoi cela échoue : l'encodeur ne peut pas extraire suffisamment d'informations visuelles à partir d'images à faible résolution. La sortie hérite du flou tout en introduisant des artefacts de mouvement.
Comment y remédier : utilisez toujours la version de l'image ayant la plus haute résolution. Si seules des versions à basse résolution sont disponibles, utilisez des outils d'amélioration par IA (tels que Real-ESRGAN ou Topaz Gigapixel) pour améliorer la résolution avant le téléchargement. La taille minimale recommandée est de 1024 x 1024 pixels.
- Écrivez des descriptions de scènes plutôt que des descriptions d'actions.
L'erreur commise : rédiger des consignes telles que « La surface de la mer au coucher du soleil, avec une lumière dorée scintillant sur l'eau ». Cela décrit l'apparence de l'image, que l'IA connaît déjà.
Pourquoi cela a échoué : l'IA a déjà encodé l'image. Lui décrire à nouveau le contenu de l'image gaspille de l'espace de prompt pour des informations redondantes et ne fournit aucune indication pour le mouvement.
Comment réviser : Concentrez-vous entièrement sur le mouvement. Réécrivez comme suit : « Les vagues roulent doucement vers le rivage. La lumière dorée du soleil scintille à la surface de l'eau. Les nuages dérivent lentement de gauche à droite. La caméra effectue un panoramique lent vers la droite, suivant la ligne côtière. »
- Exiger trop d'actions à effectuer simultanément
Erreurs commises : « Le personnage tourne la tête, fait un signe de la main, avance, prend une tasse, sourit et danse, tandis que la caméra avance, effectue un panoramique vers la gauche et s'incline. »
Pourquoi cela échoue : les modèles d'IA actuels ne peuvent pas coordonner de manière fiable plus de deux ou trois actions simultanées. Les invites surchargées conduisent le modèle soit à ignorer la plupart des instructions, soit à produire des résultats confus et truffés d'erreurs.
Comment monter : Limitez chaque génération à une action principale du sujet et à un mouvement de caméra. Pour les actions complexes et continues, générez plusieurs clips courts séparément avant de les monter et de les assembler.
- Ignorer les incompatibilités de format d'image
L'erreur commise : télécharger une image au format paysage 16:9 mais définir le format de sortie sur portrait 9:16, ou inversement.
Pourquoi cela échoue : l'IA recadre considérablement votre image ou nécessite de remplir de grandes zones vides. Aucune de ces deux approches ne donne de résultats satisfaisants : le recadrage compromet le cadrage soigneusement composé, tandis que le remplissage de nouvelles zones étendues introduit des incohérences.
Comment corriger : assurez-vous que le format d'image de sortie correspond aux proportions de l'image source. Utilisez le format 16:9 pour les images au format paysage et 9:16 pour les images au format portrait. Si un format différent est requis, recadrez l'image source aux proportions souhaitées avant de la télécharger.
- Attendre un effet photoréaliste d'une illustration
L'erreur commise : télécharger une illustration de bande dessinée ou une image au design plat, en espérant que l'IA génère une vidéo photoréaliste.
Pourquoi cela échoue : le modèle tente d'interpréter les styles artistiques, introduisant parfois un réalisme indésirable. Les illustrations plates manquent de profondeur et d'indications d'éclairage sur lesquelles le modèle s'appuie pour prédire les mouvements naturels.
Comment corriger : si le matériel source est une illustration, indiquez explicitement le style dans la consigne : « Conservez exactement le style artistique illustré. Animez dans un style d'animation 2D, et non photoréaliste. Les mouvements doivent donner l'impression d'être dessinés à la main et picturaux. » Cela indique au modèle de préserver le style artistique plutôt que d'introduire le photoréalisme.
Foire aux questions
Quel outil d'IA est le mieux adapté pour générer des vidéos à partir d'images ?
Seedance 2.0 est notre recommandation numéro un pour la génération d'images à partir de vidéos en 2026. Il prend en charge plusieurs entrées d'images (jusqu'à 9 images de référence), offre une résolution de sortie de 2K et propose la combinaison la plus flexible d'images, de texte, de vidéo et d'audio. De plus, développé par ByteDance, Seedance est directement accessible en Chine continentale. Pour les utilisateurs soucieux de leur budget, Kling 3.0 offre une qualité d'image exceptionnelle à un prix plus bas, et est également directement accessible en Chine continentale. Pour les débutants, Pika 2.0 dispose de l'interface la plus simple. Le choix optimal dépend de vos besoins spécifiques. Veuillez consulter notre [tableau comparatif des outils](#2026-year image-to-video AI tool comparison).
La vidéo TuSheng peut-elle être utilisée gratuitement ?
Bien sûr. Plusieurs plateformes offrent des quotas gratuits. Seedance offre des crédits gratuits à chaque nouvel utilisateur, sans carte de crédit requise. Pika 2.0 et Luma Dream Machine offrent également une génération gratuite limitée. HaiLuo AI offre 10 générations gratuites par jour. Ces quotas gratuits suffisent pour tester la technologie et produire plusieurs vidéos. Si vous avez besoin d'une utilisation continue, les forfaits payants s'avèrent plus économiques. Pour plus d'informations sur les stratégies d'utilisation gratuite, consultez notre Guide d'utilisation gratuite de Seedance.
Quelle est la durée maximale des vidéos générées par l'IA ?
Les différentes plateformes ont des limites variables. Kling 3.0 est en tête du classement, générant des vidéos pouvant atteindre 2 minutes par image. Seedance 2.0 plafonne à 15 secondes. Runway Gen-4 plafonne à 10 secondes. Pika 2.0 et Luma Dream Machine limitent les vidéos à 5 secondes. Pour la plupart des scénarios liés aux réseaux sociaux et au marketing, une durée optimale se situe entre 5 et 15 secondes. Si des séquences plus longues sont nécessaires, il est possible de générer plusieurs clips courts pour les éditer et les assembler ultérieurement, ou d'utiliser Kling pour générer une vidéo longue à partir d'une seule prise.
Quel format d'image est le plus adapté à la génération de vidéos par IA ?
Le format PNG est optimal car il s'agit d'un format sans perte, exempt d'artefacts de compression. Le format WebP (mode sans perte) offre des résultats équivalents avec des fichiers de taille réduite. Le format JPG convient également dans la plupart des cas, mais les fichiers JPG fortement compressés avec des artefacts visibles dégradent la qualité du résultat. Évitez d'utiliser les formats GIF, BMP ou autres formats non standard. Toutes les principales plateformes prennent en charge les formats JPG, PNG et WebP. Résolution minimale : 512 x 512 pixels. Recommandée : 1024 x 1024 ou supérieure.
L'IA peut-elle animer n'importe quel type d'image ?
L'IA peut animer la plupart des types d'images, mais les résultats varient en fonction du sujet. Les portraits et les photos de visage donnent les meilleurs résultats : les modèles actuels interprètent avec précision les mouvements naturels du visage et des cheveux. Les paysages et les scènes naturelles donnent également d'excellents résultats, avec des représentations convaincantes du mouvement des nuages, de l'écoulement de l'eau et du balancement de la végétation. Les images de produits avec un arrière-plan épuré donnent des résultats toujours fiables. Les illustrations et les œuvres d'art peuvent être animées, mais des indications stylistiques personnalisées peuvent être nécessaires pour éviter un photoréalisme involontaire. Les scènes de groupe complexes, les images contenant beaucoup de texte et les photographies de mauvaise qualité produisent les résultats les moins stables.
Quelle est la différence entre une vidéo générée à partir d'images et une vidéo générée à partir de texte ?
Text-to-Video génère simultanément du contenu visuel et du mouvement à partir de descriptions textuelles. L'IA dicte l'apparence visuelle dans son ensemble, offrant moins de contrôle sur les détails spécifiques, mais une plus grande liberté créative. Image-to-Video utilise vos images existantes comme point de départ, ne générant que le mouvement. Vous conservez un contrôle précis sur le résultat visuel, car vous fournissez la référence visuelle. Image-to-Video offre généralement des résultats plus prévisibles et cohérents, car l'IA dispose d'un ancrage visuel concret. Text-to-Video est plus adapté pour demander à l'IA de créer un contenu entièrement nouveau à partir de zéro.
Tusheng Video peut-il contrôler les mouvements de la caméra ?
Tout à fait. La plupart des outils vidéo génératifs modernes prennent en charge le contrôle des mouvements de caméra via des invites textuelles. Vous pouvez spécifier des mouvements tels que « dolly in », « pan left », « orbit around », « crane up », « zoom out » et « tracking shot ». Seedance 2.0 et Luma Dream Machine réagissent de manière particulièrement précise à ces mots-clés de mouvement. Runway Gen-4 offre une précision supplémentaire grâce aux modes Motion Brush et Director, qui permettent de tracer visuellement la trajectoire de la caméra. Il est conseillé de ne spécifier qu'un seul type de mouvement par génération, complété par des modificateurs de vitesse tels que « lentement » ou « régulièrement ».
La qualité d'image des vidéos générées par l'IA est-elle suffisante pour des applications professionnelles ?
Pour les contenus vidéo courts (5 à 15 secondes), c'est tout à fait faisable. Les résultats obtenus par des plateformes de premier plan telles que Seedance 2.0 et Runway Gen-4 ont déjà été utilisés de manière professionnelle pour le marketing sur les réseaux sociaux, les vidéos de produits de commerce électronique, les présentations immobilières et les concepts publicitaires. Au niveau national, une grande partie du contenu commercial sur Douyin et Xiaohongshu intègre désormais des ressources vidéo générées par l'IA. Cependant, certaines limites persistent : les durées prolongées augmentent le risque d'imperfections, les scènes complexes à plusieurs sujets restent instables et le rendu du texte dans les vidéos n'est toujours pas parfait. Pour les œuvres cinématographiques ou de qualité professionnelle exigeant une perfection absolue, le tournage traditionnel reste l'option la plus sûre. Pour le marketing numérique et le contenu social, la technologie d'image à vidéo par IA a désormais atteint des normes professionnelles.
Résumé
TuSheng Video AI est passé d'un gadget novateur à un outil indispensable pour la création de contenu. La technologie a mûri, les outils sont devenus conviviaux et la qualité du résultat répond désormais aux normes professionnelles pour la grande majorité des scénarios de contenu numérique.
Voici les points clés :
- La qualité des images sources est primordiale. Des images nettes, bien composées et en haute résolution donnent des résultats nettement supérieurs à celles qui sont floues ou en basse résolution.
- Écrivez le mouvement, pas la description. L'IA a déjà vu votre image. Dites-lui comment les choses doivent bouger, pas à quoi elles ressemblent.
- **Commencez par quelque chose de simple. ** Une action du sujet plus un mouvement de caméra. Maîtrisez les bases avant d'ajouter de la complexité.
- Répétez rapidement. Générez d'abord de courts clips de test ; ne produisez la version complète que lorsque vous êtes satisfait.
- **Adaptez les outils aux tâches. ** Seedance privilégie la fidélité visuelle et le contrôle multimodal, Ke Ling excelle dans les vidéos longues et abordables, Runway se concentre sur le montage précis, tandis que Pika met l'accent sur la simplicité et la facilité d'utilisation.
- Sélectionnez l'outil qui correspond à vos besoins. Si vous êtes en Chine continentale, Seedance et Ke Ling peuvent être utilisés directement sans barrières supplémentaires liées au réseau ou au paiement.
L'écart entre les marques et les créateurs qui utilisent Tusheng Video AI et leurs pairs qui continuent de s'appuyer sur des images statiques se creuse chaque mois. Chaque photographie de votre bibliothèque de produits est une publicité vidéo potentielle. Chaque portrait est un avatar animé potentiel. Chaque paysage est un plan de coupe cinématographique potentiel.
Créez gratuitement votre première image-vidéo --> — Téléchargez n'importe quelle image et regardez-la prendre vie en moins de deux minutes. Aucune carte de crédit requise, directement accessible en Chine continentale.
Envie d'explorer davantage les fonctionnalités vidéo de l'IA ? Découvrez Seedance sur toutes les plateformes --> — Conversion texte-vidéo, vidéo-vidéo, génération multimodale : tout est géré au même endroit.
Pour en savoir plus : Guide d'utilisation complet de Seedance | Guide des invites Seedance avec plus de 50 exemples | Cas d'utilisation créatifs de la vidéo IA | Classement des meilleurs générateurs de vidéos IA pour 2026 | Guide du marketing vidéo IA et des réseaux sociaux | IA texte-vidéo : guide complet*
