
Resumen
La IA de imagen a vídeo utiliza tecnología de aprendizaje profundo basada en modelos de difusión para transformar imágenes estáticas en vídeos dinámicos. A diferencia de la generación de texto a vídeo, solo es necesario subir una fotografía para que la IA genere movimientos realistas, movimientos de cámara y metraje temporalmente coherente a su alrededor, lo que le permite un control más preciso sobre el resultado final. Esta guía cubrirá de forma exhaustiva: los principios técnicos que hay detrás de la IA de imagen a vídeo; qué tipos de imágenes producen resultados óptimos; un tutorial de cinco pasos para crear su primer vídeo desde cero; ocho casos de uso prácticos con ejemplos concretos; técnicas avanzadas de control de movimiento; y una comparación realista de las 2026 herramientas líderes (incluidas las que son directamente accesibles en China). Pruebe Image-to-Video gratis -->
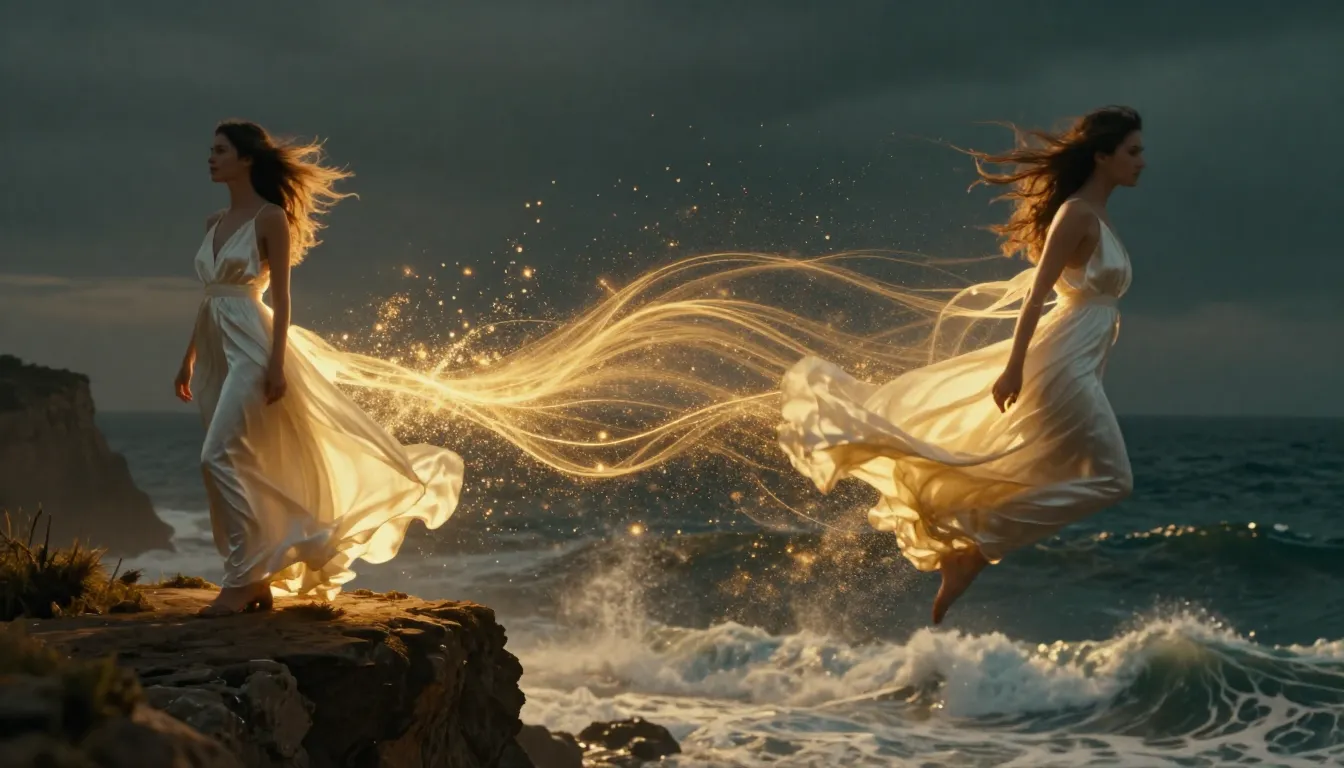
TuSheng Video AI toma tus fotografías fijas y genera movimientos realistas, movimientos de cámara cinematográficos y continuidad temporal, transformando un solo fotograma en un videoclip cinematográfico.
¿Qué es Tusheng Video AI?
La IA de imagen a vídeo es una tecnología de inteligencia artificial capaz de generar vídeos a partir de imágenes estáticas. Usted proporciona una fotografía, ya sea un retrato, una imagen de un producto, un paisaje o una obra de arte, y el modelo de IA produce un vídeo corto en el que los elementos comienzan a moverse, los ángulos de cámara cambian y toda la escena cobra vida.
En esencia, la mayoría de los sistemas de vídeo generativo emplean modelos de difusión de vídeo. Estas redes neuronales se entrenan con millones de pares de datos de imágenes de vídeo, aprendiendo la relación estadística entre fotogramas estáticos y el movimiento natural posterior. Cuando se le presenta una nueva imagen, el modelo predice qué movimiento parece más natural y genera una secuencia continua de fotogramas que transita suavemente desde la fotografía original.
Diferencias con respecto al texto a vídeo
Text-to-Video genera contenido a partir de texto. La IA crea simultáneamente contenido visual y movimiento basándose en tu indicación textual, un proceso potente pero impredecible, ya que la IA determina de forma independiente la apariencia de los sujetos, la composición de las escenas y todos los patrones de movimiento.
Tusheng Video da un giro completo a esta lógica: tú proporcionas el ancla visual. La IA ya sabe cómo es la escena, porque se la has mostrado directamente. Su única tarea es generar un movimiento plausible. Esto significa que:
- Mayor control: tus imágenes definen el tema, la composición, la paleta de colores y el estilo
- Menos conjeturas: la IA no requiere interpretar descripciones textuales vagas
- Mayor coherencia: los resultados se ajustan fielmente a las imágenes originales
- Iteraciones más rápidas: Ajustar la indicación de movimiento es mucho más sencillo que reescribir toda la descripción de la escena.
Por qué el vídeo TuSheng es tan importante en 2026
TuSheng Video AI ha pasado de ser un juguete experimental a convertirse en una herramienta de productividad. Las marcas de comercio electrónico transforman las imágenes de los productos en anuncios animados, los creadores de contenido dan vida a sus publicaciones más populares, los agentes inmobiliarios producen vídeos de visitas virtuales a partir de fotos de propiedades y los educadores animan las ilustraciones de los libros de texto.
Esta tecnología ha alcanzado un punto de inflexión: los vídeos de entre 5 y 15 segundos generados a partir de imágenes de alta calidad son ahora prácticamente indistinguibles de las grabaciones tradicionales en la mayoría de los casos. Precisamente por eso, la conversión de imágenes a vídeo se ha convertido en la categoría de más rápido crecimiento dentro de la generación de vídeo mediante IA.
Esta tendencia es especialmente pronunciada en el mercado chino. Los algoritmos de plataformas como Douyin, Xiaohongshu, Bilibili y Kuaishou favorecen en gran medida el contenido de vídeo, lo que genera una demanda sin precedentes entre los creadores de herramientas que permitan convertir rápidamente fotografías en vídeos. Tusheng Video AI aborda precisamente esta brecha en el mercado.
Principios técnicos de Tusheng Video AI
Comprender el proceso técnico te ayuda a obtener mejores resultados. Cuando sabes por qué la IA se comporta de una determinada manera, puedes proporcionar mejores datos y escribir indicaciones más eficaces. A continuación se describe el proceso de cuatro pasos que tiene lugar entre bastidores.

Las cuatro etapas del proceso de procesamiento de IA de Tusheng Video: codificación de imágenes, predicción de movimiento, generación de fotogramas y suavizado temporal.
Paso uno: Codificación de imágenes
La IA analiza primero la imagen introducida a través de una red codificadora, comprimiéndola en una representación matemática densa conocida como vector latente. Esto puede entenderse como que la IA extrae una «huella digital» de la imagen, capturando su estructura, color, profundidad, posición del sujeto, dirección de la iluminación e información semántica.
Esta representación latente es considerablemente más compacta que los datos de píxeles originales, lo que hace factibles los cálculos posteriores. La calidad de la codificación influye directamente en los resultados finales. Las imágenes de entrada con mayor resolución y nitidez generan representaciones latentes más ricas, lo que en última instancia da como resultado una salida de vídeo superior.
Paso dos: Predicción del movimiento
Este es el núcleo creativo de todo el proceso. El modelo de difusión predice qué tipo de movimiento parecería natural basándose en la imagen original, teniendo en cuenta:
- Contexto escénico: una fotografía del océano implica que las olas deben agitarse; un retrato sugiere un movimiento facial sutil
- Información de profundidad: los objetos cercanos al objetivo pueden mostrar patrones de movimiento distintos a los de los sujetos distantes
- Realismo físico: El cabello debe ondear con el viento, el agua debe fluir hacia abajo y la tela debe caer de forma natural
- Tu indicación de texto: Si especificas «desplazamiento lento hacia la izquierda», el modelo ajustará su predicción de movimiento en consecuencia.
El modelo no se limita a distorsionar los píxeles. Genera contenido visual completamente nuevo para las áreas recién expuestas por el movimiento de la cámara o el movimiento de los objetos. Si la cámara se desplaza hacia la derecha, el modelo «rellenará» la escena más allá del borde derecho de la imagen original.
Paso tres: Generación del marco
Basándose en la predicción de movimiento, el modelo genera una secuencia de fotogramas de vídeo. Cada fotograma se produce mediante un proceso de difusión inversa: partiendo del ruido, se va refinando progresivamente hasta obtener una imagen nítida, manteniendo la coherencia con el fotograma anterior y la imagen original.
Seedance 2.0 y otros modelos modernos generan a altas velocidades de fotogramas (24-30 fps) mientras mantienen la consistencia subpíxel entre fotogramas. Esto garantiza una salida fluida y sin parpadeos, sin los problemas de vibración habituales en los sistemas anteriores.
Paso cuatro: Suavizado temporal
El paso final garantiza transiciones fluidas entre todos los fotogramas generados. El mecanismo de atención temporal verifica que el brillo, el color y el movimiento se mantengan constantes a lo largo de todo el vídeo, evitando los artefactos visuales habituales:
- Cambios repentinos de color entre fotogramas
- Aparición o desaparición inesperada de objetos
- Aceleración o desaceleración antinatural del movimiento
- Parpadeo de la textura de la superficie
El resultado final es un vídeo exquisito que fluye con naturalidad a partir del metraje original.
¿Por qué algunas imágenes se ven mejor?
Ahora puede comprender por qué la calidad de la imagen de entrada es tan importante. Una imagen borrosa y de baja resolución produce una codificación potencial con ruido en el primer paso, lo que proporciona menos información al modelo de predicción de movimiento (el segundo paso). Esto da como resultado un movimiento menos preciso y más artefactos visuales en el resultado final. Por el contrario, una imagen nítida y bien compuesta con indicios de profundidad claros proporciona al modelo una gran cantidad de información, lo que se traduce en un vídeo más natural y de mayor calidad.
¿Qué tipo de imagen ofrece los mejores resultados?
No todas las imágenes son adecuadas para TuSheng Video AI. La diferencia entre un material de origen bueno y uno malo puede ser la diferencia entre un vídeo impresionante y un montón de material inutilizable. Aquí tienes una guía práctica.

El lado izquierdo muestra imágenes originales adecuadas (alta resolución, bien compuestas, que sugieren un movimiento natural), mientras que el lado derecho muestra imágenes originales inadecuadas (borrosas, desordenadas, que contienen elementos difíciles de procesar para la IA).
Tipos de imágenes adecuados
Alta resolución (1024 x 1024 o superior). Cuantos más píxeles, más detalles puede extraer el codificador. Utilice siempre la versión con la resolución más alta disponible. Mínimo recomendado: 512 x 512 píxeles. Ideal: 1024 x 1024 o superior.
Sujetos claramente definidos, contornos nítidamente delineados. La IA debe discernir qué debe moverse y qué debe permanecer estático. Un retrato en el que el sujeto está claramente separado del fondo ofrece resultados muy superiores a los de una escena grupal compleja y caótica.
Bien iluminadas y correctamente expuestas. Las imágenes con buena iluminación proporcionan información precisa sobre el color y la profundidad del modelo. Evite las imágenes muy sobreexpuestas o subexpuestas.
Capas y composición naturales. Las imágenes con un primer plano, un plano medio y un fondo claramente definidos proporcionan indicios de profundidad a la IA, lo que mejora el realismo de los efectos de paralaje y los movimientos de cámara.
Imágenes que sugieren movimiento. Las imágenes que insinúan movimiento —el cabello mecido por el viento, las olas a punto de romper contra la orilla, una persona dando un paso— proporcionan al modelo un poderoso punto de partida para predecir el movimiento. La IA puede comprender «lo que sucederá a continuación» a partir de estas señales visuales.
Fondos limpios. Un fondo sencillo o difuminado de forma natural produce un vídeo más fluido que uno recargado, lleno de numerosos objetos pequeños.
Tipos de imágenes que pueden causar problemas
Imágenes borrosas o desenfocadas. Desenfoque de entrada, desenfoque de salida. La IA no puede añadir nitidez que no estaba presente en la imagen original.
Escenas excesivamente complejas. Las imágenes que contienen numerosos objetos pequeños, patrones intrincados o elementos visuales que crean confusión pueden saturar los modelos de predicción de movimiento, impidiéndoles determinar qué debe moverse y cómo debe hacerlo.
Texto extenso o tipografía. Los modelos de vídeo con IA aún tienen dificultades para mantener la legibilidad del texto en todos los fotogramas. Si tus imágenes contienen logotipos, marcas o superposiciones de texto, se producirá una distorsión en el vídeo resultante.
Baja resolución (512 x 512 o inferior). Las imágenes pequeñas contienen información insuficiente. Incluso ampliarlas con IA antes de introducirlas resulta inútil, ya que añade píxeles, pero no información.
Filtros pesados o posprocesamiento. Los ajustes extremos de color, el procesamiento HDR o las modificaciones extensas con Photoshop pueden confundir la comprensión del modelo sobre la iluminación y la profundidad.
Múltiples rostros de diferentes tamaños. La IA gestiona eficazmente los retratos individuales. Las fotos de grupo con rostros a diferentes distancias producen animaciones inconsistentes: algunos rostros parecen naturales, mientras que otros se distorsionan.
Lista de verificación previa a la carga
Antes de subir imágenes, comprueba rápidamente los siguientes puntos:
- Resolución mínima de 1024 x 1024 píxeles
- Sujeto claramente definido con una separación nítida del fondo
- Exposición correcta (ni subexpuesta ni sobreexpuesta)
- Sin filtros pesados, HDR extremo ni procesamiento artificial visible
- Mínimo texto, logotipos o elementos tipográficos
- Complejidad de la escena controlada (1-3 sujetos principales)
- Formato de imagen: JPG, PNG o WebP
Una vez que se cumplan estas condiciones, podrá comenzar la generación.
Guía paso a paso: Genera tu primer vídeo a partir de una imagen
Siga estos cinco pasos para transformar cualquier imagen estática en un vídeo animado con IA. Utilizaremos Seedance como plataforma de demostración, aunque estos principios se aplican a cualquier herramienta de conversión de imágenes a vídeo.
Paso uno: selección de imágenes originales adecuadas
La imagen original es el factor más importante para la calidad del resultado. Elige una imagen que cumpla con las pautas que te dijimos antes. Para tu primer intento, te recomendamos elegir un retrato simple o un paisaje con bastante profundidad, ya que estos dos tipos de imágenes dan los resultados más consistentes.
Imágenes recomendadas para los primeros intentos:
- Retrato claro de la cabeza o de medio cuerpo con una iluminación favorable
- Paisajes con cielo, superficies de agua o vegetación (estos elementos poseen movimiento inherente)
- Imágenes de productos con fondos limpios
- Obras de arte o ilustraciones con elementos claramente definidos
Cuando genere por primera vez, evite utilizar imágenes compuestas complejas, imágenes que contengan grandes cantidades de texto o fotografías muy editadas.
Paso dos: Subir a Seedance
Abre Seedance Image-to-Video y sube las imágenes seleccionadas. Seedance admite los formatos JPG, PNG y WebP. La plataforma analizará automáticamente tus imágenes y las preparará para su generación.
Si una imagen es excepcionalmente grande (con cualquier lado que supere los 4096 píxeles), el sistema la escalará automáticamente manteniendo sus proporciones, lo que elimina la necesidad de realizar ajustes manuales.
Paso tres: Elaboración de una indicación orientada a la acción
En esta fase, le indicas a la IA el movimiento deseado. Tu indicación debe describir la dinámica en lugar del contenido de la imagen (la IA ya ha visto la imagen). Céntrate en los siguientes puntos:
- Movimiento del sujeto: ¿Qué debe hacer el sujeto?
- Movimiento de la cámara: ¿Cómo debe moverse la cámara?
- Movimiento del entorno: ¿Qué dinámica ambiental debe haber?
- Ritmo y ambiente: ¿Tempo general: rápido o lento?
Ejemplos de indicaciones para retratos:
The woman slowly turns her head to the right and smiles softly.
A gentle breeze moves her hair. Background slightly out of focus
with subtle bokeh movement. Camera slowly pushes in from medium
shot to a close-up. Warm, natural lighting. Cinematic film quality.Ejemplo de indicaciones para paisajes:
Gentle waves roll toward the shore in slow motion. Clouds drift
slowly across the sky from left to right. Sunlight shimmers on
the water surface. Camera slowly pans right, revealing more of
the coastline. Peaceful, serene atmosphere. 4K cinematic quality.Ejemplo de mensaje del producto:
The camera slowly orbits around the product, rotating 45 degrees
clockwise. Soft studio lighting with subtle caustic reflections
on the surface. Clean white background with gentle gradient.
Premium commercial aesthetic. Smooth, steady camera movement.Principio básico: Describe el movimiento, no la escena. La escena ya existe dentro de tu imagen.
Nota: Seedance admite indicaciones tanto en chino como en inglés, aunque las indicaciones en inglés suelen proporcionar un control más preciso del movimiento de la cámara. Se recomienda utilizar el inglés para las descripciones relacionadas con el movimiento y la cámara, mientras que el chino puede emplearse para las descripciones de la atmósfera y el estilo.
Paso cuatro: Seleccionar parámetros
Configurar los ajustes de generación:
| Parámetro | Valor recomendado | Descripción |
|---|---|---|
| Modelo | Seedance 2.0 | Calidad de imagen óptima para la generación de imágenes a vídeo |
| Duración | 5 segundos (para pruebas iniciales) | Empiece con vídeos cortos y luego más largos; genere versiones extendidas cuando esté satisfecho |
| Relación de aspecto | Coincide con la imagen | 16:9 para horizontal, 9:16 para vertical, 1:1 para cuadrado |
| Resolución | 1080p | Seleccione siempre la resolución más alta disponible |
Técnica avanzada: Primero genera una versión de 5 segundos. Si el movimiento y el estilo son satisfactorios, utiliza la misma indicación para generar una versión más larga (8-15 segundos). Este enfoque ahorra créditos durante la fase de exploración.
Paso cinco: Generar, verificar, iterar
Haga clic en Generar y espere entre 1 y 3 minutos. Una vez que aparezcan los resultados, evalúelos según los siguientes criterios:
- ¿El movimiento es fluido y natural?
- ¿El sujeto mantiene la coherencia visual en todo momento?
- ¿El movimiento de la cámara se ajusta a tus expectativas?
- ¿Hay alguna imperfección visual (parpadeo, distorsión, deformación)?
- ¿La calidad del vídeo coincide con la del metraje original?
Si algún aspecto resulta insatisfactorio, ajuste la indicación y vuelva a generar. Los métodos de ajuste habituales incluyen:
- ¿Demasiado rápido? Añade «lentamente», «suavemente», «gradualmente» a la descripción del movimiento
- ¿Dirección de cámara incorrecta? ** Especifica con mayor claridad: «cámara estática, sin movimiento de cámara» o «movimiento lento de la cámara»
- ¿Imperfecciones faciales? Simplifica el movimiento: reduce el número de acciones que se producen simultáneamente
- **¿Falta de dinamismo? ** Introduce verbos dinámicos: «balanceándose», «fluyendo», «derivando», «cambiando»
Después de dos o tres rondas de iteración, obtendrás un vídeo de alta calidad que dará vida a tus imágenes.
Empieza a crear tu primer clip de imagen a vídeo ahora -->
8 aplicaciones principales y ejemplos de conversión de imágenes a vídeo a gran escala
TuSheng Video AI no es un producto de un solo uso. Sirve para docenas de fines creativos y comerciales. A continuación se presentan ocho escenarios de aplicación de gran valor, con indicaciones prácticas listas para copiar y modificar directamente.
- Animación de retratos
Dale vida a tus fotos. Portrait Animation es la aplicación más popular para convertir fotos en vídeos. Sube tu foto de perfil, selfie o imagen de personaje y añádele animaciones sutiles y realistas: respiración, parpadeo, giro de cabeza, cambios de expresión y movimiento del cabello.
Adecuado para vídeos conmemorativos, contenido para redes sociales, creación de avatares virtuales y narración creativa. En TikTok y Xiaohongshu, el contenido que «da vida a las fotografías» sigue siendo un foco de tráfico constante.

Un retrato estático se transforma en un vídeo realista: parpadeos naturales, movimientos sutiles de la cabeza y cabello ondulado, el efecto es sorprendentemente realista.
Ejemplo de indicación:
The person looks directly at the camera with a calm, confident
expression. They slowly tilt their head slightly to the left and
give a subtle warm smile. Eyes blink naturally. A soft breeze gently
moves their hair. Shallow depth of field with softly blurred
background. Warm natural lighting. Cinematic portrait quality.- Presentación del producto
Transforma la fotografía de productos en contenido comercial dinámico. Esto supone una revolución para las marcas de comercio electrónico y los influencers: ya dispones de cientos o incluso miles de imágenes de productos, y ahora cada una de ellas puede convertirse en un anuncio de vídeo, una imagen destacada para las páginas de detalles del producto o un cortometraje para las redes sociales.
En las páginas de detalles de productos de Taobao y JD.com, en las presentaciones de productos en directo de Douyin y en las publicaciones de recomendaciones de productos de Xiaohongshu, las visualizaciones dinámicas de productos consiguen sistemáticamente tasas de conversión significativamente más altas que las imágenes estáticas.

Una imagen de producto estándar se eleva al nivel de sofisticación de un anuncio publicitario premium, con panorámicas de cámara, iluminación dramática y movimientos fluidos, una producción que podría costar entre cientos y miles de libras si se realizara con métodos convencionales.
Ejemplo de indicación:
The camera slowly orbits 90 degrees around the product, revealing
its form from multiple angles. Soft directional studio lighting
with subtle caustic reflections on the surface. A gentle highlight
sweep moves across the product. Clean, premium commercial aesthetic.
Shallow depth of field. Ultra-smooth camera movement. 4K quality.3. Lapso de tiempo panorámico
Transforma la fotografía paisajística en vídeos atmosféricos con estilo time-lapse. Las nubes se desplazan por el cielo, el agua fluye, la luz cambia de tonos dorados a azules y las hojas se mecen con la brisa. Ideal para contenidos de viajes, presentaciones aéreas de propiedades y metraje atmosférico de B-roll.
Los fotógrafos paisajistas y los vloggers de viajes de Bilibili pueden transformar directamente sus fotografías seleccionadas en cautivadores vídeos time-lapse, lo que reduce significativamente los costes de producción.

Una fotografía paisajística transformada en un time-lapse cinematográfico —nubes fluidas, agua ondulante y luces y sombras cambiantes— que crea una atmósfera dinámica a partir de una sola imagen estática.
Ejemplo de indicación:
Time-lapse effect. Clouds move steadily across the sky from left
to right. Water in the foreground ripples and flows gently. Light
shifts subtly as if the sun is moving, creating slowly changing
shadows on the landscape. Trees and grass sway gently in the wind.
Camera remains static on a tripod. Serene, majestic atmosphere.
Cinematic landscape quality.4. Contenido en redes sociales
Transforma tus publicaciones estáticas con mejor rendimiento en contenido de vídeo que haga que la gente deje de desplazarse. Los algoritmos de plataformas como TikTok, Xiaohongshu, Bilibili y Kuaishou favorecen en gran medida el contenido de vídeo: una publicación con imágenes de alto rendimiento casi con toda seguridad obtendrá mejor tráfico si se convierte en vídeo.
Para los creadores de contenido de Xiaohongshu, un conjunto de publicaciones con imágenes y texto puede ver un aumento de entre 3 y 5 veces en su exposición si se acompaña de una versión en vídeo. Sin embargo, Douyin y Kuaishou operan íntegramente con el vídeo como formato de contenido principal.
Ejemplo de indicación:
Dynamic, attention-grabbing motion. The subject moves confidently
toward the camera with energy and presence. Background elements
shift with parallax depth effect. Quick, punchy camera push-in
that creates impact. Vibrant colors, high contrast. Bold,
eye-catching aesthetic optimized for social media. Vertical 9:16.- Animación artística e ilustrativa
Da vida a obras de arte, ilustraciones, pinturas digitales y diseños gráficos. Este escenario de aplicación es muy apreciado por artistas, diseñadores de juegos y equipos creativos que buscan mostrar su trabajo de una manera más atractiva.
Dentro de las comunidades de arte y anime de Bilibili y Xiaohongshu, las ilustraciones animadas se consideran un contenido muy atractivo. La transformación de ilustraciones estáticas en vídeos con estilo de «fondos de pantalla animados» suele generar un número significativamente mayor de comparticiones y guardados que las imágenes originales.
Ejemplo de indicación:
The illustrated scene comes to life with gentle, painterly motion.
Characters move subtly within their positions -- breathing, shifting
weight, small gestures. Background elements like leaves, clouds,
or particles drift slowly. The artistic style is preserved exactly
as painted. Movement is smooth and dreamlike, like a living painting.
Gentle ambient lighting shifts. Fantasy illustration quality.6. Visitas virtuales a propiedades
Transforme las fotografías de propiedades en vídeos de visualización virtual. Las agencias inmobiliarias pueden crear vistas previas inmersivas utilizando imágenes existentes de las propiedades, lo que elimina la necesidad de contratar a equipos de fotografía especializados para visitar los inmuebles.
En los anuncios inmobiliarios que se muestran en plataformas como Beike y Anjuke, así como en las promociones inmobiliarias en WeChat Moments y Xiaohongshu, los vídeos dinámicos muestran una tasa de conversión significativamente mayor en cuanto a consultas de clientes.
Ejemplo de indicación:
Smooth virtual walkthrough. The camera glides forward slowly into
the room, revealing the space with a wide-angle perspective.
Natural daylight streams through the windows, casting soft shadows.
Subtle dust particles float in the sunbeams. The camera pans
gently to the left, showing the full room layout. Clean, bright,
aspirational real estate aesthetic. Steady, professional movement.- Muestra de moda y estilismo
Crea contenido de moda dinámico a partir de fotos de conjuntos de estudio. Las modelos se mueven, los tejidos fluyen con naturalidad y se conserva el estilo estético de nivel editorial.
Los blogueros de moda de Xiaohongshu y los vendedores de ropa de Taobao pueden convertir grandes cantidades de fotos de modelos y conjuntos planos existentes en vídeos dinámicos, creando un mayor impacto visual en los feeds de información.
Ejemplo de indicación:
The model strikes a confident pose and then slowly shifts their
weight, creating natural body movement. Fabric of the outfit
flows and catches the light with each subtle motion. Wind effect
gently moves the hair. Camera starts at full body and slowly drifts
upward to a waist-up shot. High-fashion editorial lighting with
strong directional shadows. Vogue magazine aesthetic. Cinematic
slow motion.- Contenido educativo y explicativo
Transforme gráficos estáticos, infografías e ilustraciones educativas en presentaciones dinámicas. Los conceptos complejos se vuelven más fáciles de comprender cuando se ponen en movimiento.
Los creadores de la Zona de Conocimiento de Bilibili y de diversas plataformas educativas pueden transformar material didáctico, diagramas y organigramas en recursos de vídeo dinámicos, lo que mejora significativamente la eficacia de la enseñanza y las tasas de retención de espectadores.
Ejemplo de indicación:
The diagram elements animate sequentially. Arrows begin to flow
in their indicated directions. Labels fade in one by one. Moving
parts of the system activate in logical order, showing the process
step by step. Smooth transitions between stages. Clean, clear
educational style. Elements highlight with subtle glow as they
become active. Professional presentation quality.Guía completa sobre técnicas de respuesta rápida para Tusheng Video
Una indicación bien redactada es la habilidad más útil para generar imágenes a partir de fotografías. Dado que la IA ya ha visto tu imagen, tu indicación debe centrarse exclusivamente en el movimiento y el dinamismo. A continuación te presentamos algunas técnicas que dan los mejores resultados.
Guía rápida de referencia de palabras clave deportivas
Utiliza estas palabras clave específicas para controlar con precisión el movimiento del vídeo.
| Tipo de movimiento | Palabras clave | Efecto | |-------- -|-------|------| | Cámara: hacia delante | acercamiento, empuje, acercamiento, aproximación | La cámara se mueve hacia el sujeto | | Cámara: hacia atrás | alejamiento, retroceso, retirada, ampliación | La cámara se aleja del sujeto | | Toma: Izquierda/Derecha | panorámica a la izquierda, panorámica a la derecha, seguimiento a la izquierda, seguimiento a la derecha | La cámara gira o sigue horizontalmente | | Toma: Arriba/Abajo | inclinación hacia arriba, inclinación hacia abajo, grúa hacia arriba, grúa hacia abajo | La cámara gira o se mueve verticalmente | | Toma: Órbita | orbitar, girar, rotar alrededor, arco | La cámara gira alrededor del sujeto | | Cámara: Zoom | acercar, alejar, cambio de distancia focal | La cámara ajusta el zoom (sin desplazamiento) | | Sujeto: Micromovimientos | respirar, parpadear, cambiar el peso, micromovimientos | Movimientos sutiles y realistas | | Sujeto: moderado | girar la cabeza, sonreír, gesticular, caminar lentamente | Movimiento claro pero controlado | | Sujeto: dinámico | correr, saltar, bailar, girar, saludar con la mano | Movimiento de todo el cuerpo con mucha energía | | Entorno: Suave | brisa, deriva, balanceo, ondulación, centelleo | Movimiento ambiental suave | | Entorno: Intenso | soplar, precipitarse, chocar, arremolinarse, caer en cascada | Dinámica ambiental vigorosa | | Paralaje | paralaje, cambio de profundidad, movimiento de capas | Primer plano/fondo moviéndose a diferentes velocidades |

Las diferentes palabras clave para el movimiento de la cámara producen efectos totalmente distintos. Seleccione deliberadamente la técnica de movimiento de la cámara en función del resultado deseado.
Control de velocidad y tempo
El ritmo del movimiento tiene un profundo efecto en el tono emocional de un vídeo. Emplea los siguientes modificadores:
- Extremadamente lento: «apenas perceptible», «cámara superlenta», «ritmo glacial» — Dramático, contemplativo
- Lento: «lentamente», «suavemente», «gradualmente», «sin prisas»: elegancia, calidad cinematográfica
- Moderado: «constante», «ritmo natural», «a velocidad de paseo»: realismo, estilo documental
- Rápido: « rápido», «enérgico», «vivo», «veloz»: dinámico, estimulante
- Extremadamente rápido: «rápido», «movimiento rápido de cámara», «corte rápido», «ráfaga de movimiento»: tenso, lleno de acción
Técnica avanzada: Utiliza la cámara lenta por defecto. En los vídeos generados por IA, la cámara lenta casi siempre se ve mejor que la cámara rápida. Los movimientos rápidos aumentan el riesgo de que aparezcan defectos e inconsistencias visuales.
Control independiente del movimiento del fondo y del sujeto
Puedes controlar de forma independiente qué se mueve y qué permanece inmóvil. Se trata de una técnica muy eficaz para dirigir la atención del público.
Sujeto en movimiento, fondo en reposo:
The person walks forward confidently while the background remains
perfectly still. Static camera, no camera movement. Focus entirely
on the subject's motion.Fondo dinámico, sujeto estático:
The person stands completely still, like a statue. Behind them,
clouds drift across the sky, leaves blow in the wind, and city
lights flicker. Only the environment moves.Movimientos separados por ambas partes:
The person slowly turns their head while the camera simultaneously
dollies in. Background clouds drift in the opposite direction,
creating a sense of depth and dimension.La distinción entre el movimiento de la cámara y el movimiento del objeto
Comprender la diferencia entre el movimiento de la cámara y el movimiento del objeto es fundamental para lograr el efecto deseado.
El movimiento de la cámara altera la perspectiva y la composición. La escena en sí permanece fija, mientras que el punto de vista cambia. Se utiliza para: revelar la escena, establecer el escenario y enfatizar el dramatismo.
El movimiento de objetos se refiere al movimiento de elementos dentro de una escena mientras la cámara permanece fija. Se emplea para: animación de personajes, demostraciones de productos y dinámicas de entornos naturales.
Los movimientos combinados utilizan ambos simultáneamente. Esta es la técnica más cinematográfica, pero también la más difícil de ejecutar correctamente para la IA. Es recomendable dominar primero un solo tipo de movimiento y añadir el otro solo cuando se esté satisfecho con el primero.
Estructuras avanzadas de indicaciones
Para obtener los resultados más predecibles, organice sus indicaciones en el siguiente orden:
- Acción principal: lo que hace el sujeto principal
- Movimiento de la cámara: cómo se mueve la cámara
- Dinámica ambiental: qué hacen los elementos ambientales
- Velocidad/ritmo: el tempo de todo el movimiento
- Atmósfera/Estado de ánimo: tono emocional
- Mejora de la calidad visual: descripción técnica de la calidad visual
Ejemplo de uso de esta estructura:
[Subject] A young woman in a flowing white dress slowly raises
her hand to brush hair from her face.
[Camera] The camera executes a slow, steady dolly in from a
medium shot to a close-up.
[Environment] Cherry blossom petals drift gently through the
air. Soft golden sunlight filters through the trees.
[Speed] All motion is slow and deliberate, almost dreamlike.
[Mood] Romantic, ethereal, peaceful atmosphere.
[Quality] Cinematic shallow depth of field, anamorphic bokeh,
film grain, 4K quality.Comparación de herramientas de IA para vídeo TuSheng 2026
La competencia en el sector del streaming de vídeo se está intensificando. A continuación se presenta un análisis comparativo de las principales plataformas a fecha de febrero de 2026, con especial énfasis en la accesibilidad para los usuarios de China continental.

Los efectos del procesamiento de la misma imagen original en cinco plataformas diferentes de generación de vídeo. Las diferencias en la calidad del movimiento, la consistencia temporal y la fidelidad visual son evidentes de inmediato.
| Característica | Seedance 2.0 | Runway Gen-4 | Pika 2.0 | Kling 3.0 | Luma Dream Machine | |------|-------------|-------------|---------|------ ----------|-------------------| | Resolución máxima | 2K (2048x1080) | 4K (mejorada) | 1080p | 1080p | 1080p | | Duración máxima | 15 segundos | 10 segundos | 5 segundos | 2 minutos | 5 segundos | | Opciones de entrada | Imagen + Texto + Vídeo + Audio | Imagen + Texto + Vídeo | Imagen + Texto | Imagen + Texto | Imagen + Texto | | Entrada de múltiples imágenes | Compatible (hasta 9 imágenes) | No compatible | No compatible | No compatible | No compatible | | Audio nativo | Compatible (8 idiomas con sincronización labial) | No compatible | Parcial (efectos de sonido) | No compatible | No compatible | | Control de la cámara | Basado en indicaciones | Pincel de movimiento + Modo director | Básico | Básico | Basado en indicaciones | | Cuota gratuita | Disponible (bonificación por registro) | Disponible (limitado) | Disponible (limitado) | Disponible (limitado) | Disponible (limitado) | | Precio inicial | ~9,90 $/mes | 15 $/mes | 10 $/mes | ~6,99 $/mes | 9,99 $/mes | | Acceso desde China continental | Acceso directo | Se requiere VPN | Se requiere VPN | Acceso directo | Se requiere VPN | | Ideal para | Control multimodal, calidad de imagen | Flujo de trabajo de edición profesional | Principiantes, efectos divertidos | Vídeos largos, alto valor | Sensación cinematográfica, escenas en 3D |
Reseñas detalladas de cada herramienta
Seedance 2.0 no tiene rival en cuanto a flexibilidad de entrada. Es la única plataforma que admite la carga simultánea de hasta nueve imágenes de referencia, la sincronización labial de la entrada de audio y la combinación de todos los modos de entrada en una sola generación. Si buscas el máximo control sobre la salida de imagen a vídeo, Seedance ofrece el conjunto de herramientas más completo. Su salida con resolución 2K también es la más alta de todas las herramientas (sin necesidad de recurrir al sobremuestreo). Desarrollado por ByteDance (empresa matriz de TikTok), los usuarios de China continental pueden acceder a él directamente sin necesidad de una VPN ni métodos de pago extranjeros.
Runway Gen-4 destaca por su control preciso. Motion Brush te permite «pintar» meticulosamente qué partes de una imagen deben moverse y en qué dirección. Si necesitas una precisión quirúrgica en áreas específicas, Runway es la opción más potente. Las desventajas son su precio más elevado y sus cuotas de generación más bajas. Para acceder desde China se necesita una VPN.
Pika 2.0 es la opción más accesible. Para los principiantes que deseen experimentar con la generación de imágenes a vídeo sin aprender ingeniería de comandos, los efectos con un solo clic y la interfaz optimizada de Pika ofrecen la barrera de entrada más baja. Aunque la calidad de la imagen no alcanza la de las herramientas premium, resulta perfectamente adecuada para contenidos sociales ocasionales. Requiere una VPN para acceder desde China continental.
Kling 3.0 supera a sus rivales tanto en tiempo de ejecución como en relación calidad-precio. Si necesitas generar vídeos prolongados (30 segundos, 1 minuto o incluso 2 minutos) a partir de una sola imagen, Kling es la única opción viable. Su relación calidad-precio es excepcionalmente favorable. Su limitación radica en las opciones de entrada restringidas (una sola imagen + texto). Como producto del grupo Kuaishou, Kling es directamente accesible en China continental, lo que ofrece a los usuarios nacionales otra opción sin complicaciones.
Luma Dream Machine destaca en la comprensión espacial. Para paisajes, arquitectura y escenas en las que es fundamental la percepción espacial tridimensional, Luma produce los movimientos de cámara y paralaje más convincentes. La animación de personajes se queda corta en comparación con la competencia. El acceso desde España requiere una VPN.
Recomendaciones para usuarios de China continental
Si te encuentras en China continental, existen principalmente dos herramientas de vídeo que se pueden utilizar directamente sin necesidad de una VPN:
- Seedance 2.0: desarrollado por ByteDance, totalmente funcional y listo para usar, con entrada multimodal + resolución 2K + audio integrado
- Kling 3.0: un producto de Kuaishou que destaca en la generación de vídeos de larga duración con una excelente relación calidad-precio.
Si bien las herramientas extranjeras como Runway, Pika y Luma poseen características propias, todas ellas requieren acceso a una VPN y métodos de pago extranjeros, lo que supone una barrera de entrada más elevada.
Para los creadores de contenido en plataformas nacionales como Douyin, Xiaohongshu, Bilibili y Kuaishou, optar por herramientas directamente accesibles dentro de China no solo ofrece una mayor comodidad, sino que también proporciona una estabilidad de red más fiable y facilidad de pago.
Para obtener una comparación más completa (incluidas las capacidades de conversión de texto a vídeo), consulte nuestra Clasificación completa de generadores de vídeo con IA para 2026.
Errores comunes y métodos de corrección
Después de analizar miles de videoclips, estos son los cinco errores más comunes que hemos observado, junto con las medidas correctivas específicas.
- Utiliza imágenes de archivo de baja resolución.
El error cometido: subir una imagen pequeña y comprimida (como una miniatura de 400 x 300 guardada desde WeChat o redes sociales) con la expectativa de producir un vídeo de alta definición.
Por qué falla: El codificador no puede extraer suficiente información visual de las imágenes de baja resolución. La salida hereda la borrosidad y, además, superpone artefactos de movimiento.
Cómo solucionarlo: Utiliza siempre la versión de mayor resolución de la imagen. Si solo dispones de versiones de baja resolución, utiliza herramientas de mejora de resolución basadas en IA (como Real-ESRGAN o Topaz Gigapixel) para mejorar la resolución antes de subirla. El tamaño mínimo recomendado es de 1024 x 1024 píxeles.
- Escribe descripciones de escenas en lugar de descripciones de acciones.
El error cometido: escribir indicaciones como «La superficie del mar al atardecer, con la luz dorada brillando sobre el agua». Esto describe el aspecto de la imagen, algo que la IA ya sabe.
Por qué falló: La IA ya ha codificado la imagen. Describirle el contenido de la imagen de nuevo supone malgastar espacio de prompt con información redundante y no aporta ninguna orientación para el movimiento.
Cómo revisar: Centra la descripción completamente en el movimiento. Reescribe como: «Las olas rompen suavemente contra la orilla. La luz dorada del sol brilla sobre la superficie del agua. Las nubes se desplazan lentamente de izquierda a derecha. La cámara se desplaza lentamente hacia la derecha, siguiendo la línea de la costa».
- Exigir que se realicen demasiadas acciones simultáneamente.
Errores cometidos: «El personaje se gira, saluda con la mano, camina hacia delante, coge una taza, sonríe y baila, mientras la cámara hace un zoom, se desplaza hacia la izquierda y se inclina».
Por qué falla: los modelos actuales de IA no pueden coordinar de forma fiable más de dos o tres acciones simultáneas. Las indicaciones sobrecargadas hacen que el modelo ignore la mayoría de las instrucciones o produzca resultados confusos y plagados de errores.
Cómo editar: Limita cada generación a una acción principal del sujeto más un movimiento de cámara. Para acciones continuas complejas, genera varios clips cortos por separado antes de editarlos y unirlos.
- Ignorar los desajustes en la relación de aspecto
El error cometido: subir una imagen apaisada en formato 16:9 pero configurar la salida en orientación vertical 9:16, o viceversa.
Por qué falla: la IA recorta drásticamente la imagen o requiere rellenar grandes áreas en blanco. Ninguno de los dos enfoques ofrece resultados satisfactorios: el recorte compromete el encuadre cuidadosamente compuesto, mientras que el relleno de nuevas regiones extensas introduce inconsistencias.
Cómo solucionarlo: Asegúrate de que la relación de aspecto de salida coincida con las proporciones de la imagen original. Usa 16:9 para imágenes horizontales y 9:16 para imágenes verticales. Si necesitas una relación de aspecto diferente, recorta la imagen original a las proporciones deseadas antes de subirla.
- Esperar un efecto realista de las imágenes ilustrativas.
El error cometido: subir una ilustración de dibujos animados o una imagen de diseño plano, esperando que la IA generara un vídeo con movimiento fotorrealista.
Por qué falla: El modelo intenta interpretar estilos artísticos, introduciendo en ocasiones un realismo no deseado. Las ilustraciones planas carecen de la profundidad y las señales de iluminación en las que se basa el modelo para predecir movimientos naturales.
Cómo solucionarlo: Si el material original es una ilustración, especifique explícitamente el estilo en la indicación: «Mantenga exactamente el estilo artístico ilustrado. Animado en un estilo de animación 2D, no fotorrealista. El movimiento debe parecer dibujado a mano y pictórico». Esto indica al modelo que conserve el estilo artístico en lugar de introducir fotorrealismo.
Preguntas frecuentes
¿Qué herramienta de IA es la más adecuada para generar vídeos a partir de imágenes?
Seedance 2.0 es nuestra principal recomendación para la generación de imágenes a vídeo en 2026. Admite múltiples entradas de imágenes (hasta 9 imágenes de referencia), ofrece una resolución de salida de 2K y proporciona la combinación más flexible de imágenes, texto, vídeo y audio. Además, desarrollado por ByteDance, Seedance es directamente accesible dentro de China continental. Para los usuarios que se preocupan por el presupuesto, Kling 3.0 ofrece una calidad de imagen excepcional a un precio más bajo, y también es accesible directamente desde China continental. Para los principiantes, Pika 2.0 cuenta con la interfaz más sencilla. La elección óptima depende de tus requisitos específicos; consulta nuestra [tabla comparativa de herramientas](#2026-year image-to-video AI tool comparison).
¿Se puede utilizar TuSheng Video de forma gratuita?
Por supuesto. Hay varias plataformas que ofrecen cuotas gratuitas. Seedance proporciona créditos gratuitos a todos los nuevos usuarios, sin necesidad de tarjeta de crédito. Pika 2.0 y Luma Dream Machine también ofrecen una generación gratuita limitada. HaiLuo AI proporciona 10 generaciones gratuitas al día. Estas cuotas gratuitas son suficientes para probar la tecnología y producir varios vídeos. Si necesita un uso continuado, los planes de pago resultan más rentables. Para obtener más estrategias de uso gratuito, consulte nuestra Guía de uso gratuito de Seedance.
¿Cuál es la duración máxima de los vídeos generados por IA?
Las diferentes plataformas tienen límites variables. Kling 3.0 lidera el sector, generando vídeos de hasta 2 minutos por imagen. Seedance 2.0 tiene un límite de 15 segundos. Runway Gen-4 tiene un límite de 10 segundos. Pika 2.0 y Luma Dream Machine limitan los vídeos a 5 segundos. Para la mayoría de los escenarios de redes sociales y marketing, entre 5 y 15 segundos es la duración óptima. Si se necesita un metraje más largo, se pueden generar varios clips cortos para su posterior edición y empalme, o utilizar Kling para generar vídeos largos de una sola toma.
¿Qué formato de imagen es el más adecuado para la generación de vídeos con IA?
PNG es óptimo, ya que es un formato sin pérdidas, libre de artefactos de compresión. WebP (modo sin pérdidas) logra resultados equivalentes con tamaños de archivo más pequeños. JPG también es adecuado en la mayoría de los casos, pero los archivos JPG muy comprimidos con artefactos de compresión visibles degradarán la calidad del resultado. Evite utilizar GIF, BMP u otros formatos no estándar. Todas las plataformas principales admiten JPG, PNG y WebP. Resolución mínima: 512 x 512 píxeles. Recomendada: 1024 x 1024 o superior.
¿Puede la IA animar cualquier tipo de imagen?
La IA puede animar la mayoría de los tipos de imágenes, aunque los resultados varían considerablemente. Los retratos y las fotos de rostro producen los resultados más convincentes: los modelos actuales capturan con destreza las expresiones faciales naturales y el movimiento del cabello. Los paisajes y las escenas naturales también funcionan excepcionalmente bien, con un movimiento de las nubes, el agua que fluye y el follaje que se mece representados con un realismo notable. Las imágenes de productos con fondos limpios producen resultados fiables de forma constante. Las ilustraciones y las obras de arte pueden animarse, aunque puede ser necesario adaptar las indicaciones estilísticas para evitar un fotorrealismo no deseado. Las escenas grupales complejas, las imágenes que contienen mucho texto y las fotografías de baja calidad producen los resultados menos estables.
¿Cuál es la diferencia entre un vídeo generado a partir de imágenes y un vídeo generado a partir de texto?
Texto a vídeo genera simultáneamente contenido visual y movimiento a partir de descripciones textuales. La IA determina toda la apariencia visual, lo que ofrece menos control sobre detalles específicos, pero mayor libertad creativa. Imagen a vídeo utiliza tus imágenes existentes como punto de partida y solo genera el movimiento. Mantienes un control preciso sobre la apariencia visual, ya que tú proporcionas la referencia visual. Image-to-Video suele ofrecer resultados más predecibles y consistentes, ya que la IA tiene un ancla visual concreta. Text-to-Video es más adecuado para que la IA cree contenido completamente nuevo desde cero.
¿Puede Tusheng Video controlar el movimiento de la cámara?
Por supuesto. La mayoría de las herramientas modernas de generación de vídeo admiten el control de los movimientos de la cámara mediante indicaciones de texto. Se pueden especificar movimientos como «dolly in», «pan left», «orbit around», «crane up», «zoom out» y «tracking shot». Seedance 2.0 y Luma Dream Machine responden con especial precisión a estas palabras clave de movimiento. Runway Gen-4 ofrece una precisión adicional gracias a su Motion Brush y Director Mode, que permiten dibujar visualmente la trayectoria de la cámara. Es recomendable especificar solo un tipo de movimiento por generación, complementado con modificadores de velocidad como «lentamente» o «de forma constante».
¿Es la calidad de imagen de los vídeos generados por IA suficiente para aplicaciones profesionales?
Para contenidos de vídeo de formato corto (5-15 segundos), es totalmente factible. Los resultados de plataformas de primer nivel como Seedance 2.0 y Runway Gen-4 ya se han utilizado de forma profesional para el marketing en redes sociales, vídeos de productos de comercio electrónico, presentaciones de propiedades y conceptos publicitarios. A nivel nacional, gran parte del contenido comercial de Douyin y Xiaohongshu incorpora ahora recursos de vídeo generados por IA. Sin embargo, siguen existiendo limitaciones: las duraciones prolongadas aumentan el riesgo de defectos, las escenas complejas con múltiples sujetos siguen siendo inestables y la representación del texto dentro de los vídeos sigue siendo imperfecta. Para las obras cinematográficas o de calidad televisiva que exigen una perfección absoluta, la filmación tradicional sigue siendo la opción más segura. Para el marketing digital y el contenido social, la tecnología de imagen a vídeo mediante IA ha alcanzado estándares profesionales.
Resumen
TuSheng Video AI ha pasado de ser un gadget novedoso a convertirse en una herramienta esencial para la creación de contenidos. La tecnología ha madurado, las herramientas se han vuelto fáciles de usar y la calidad del resultado cumple ahora con los estándares profesionales para la gran mayoría de los escenarios de contenido digital.
Los siguientes son los puntos clave:
- La calidad de las imágenes originales lo es todo. Las imágenes nítidas, bien compuestas y de alta resolución producen resultados muy superiores en comparación con las borrosas o de baja resolución.
- Escribe movimiento, no descripción. La IA ya ha visto tu imagen. Indícale cómo deben moverse las cosas, no cómo deben verse.
- **Empieza por lo sencillo. ** Una acción del sujeto más un movimiento de cámara. Domina los conceptos básicos antes de añadir complejidad.
- Repite rápidamente. Genera primero clips de prueba cortos; produce la versión completa solo cuando estés satisfecho.
- **Adapta las herramientas a las tareas. ** Seedance da prioridad a la fidelidad visual y al control multimodal; KeLing destaca por sus vídeos de larga duración y su asequibilidad; Runway se centra en la edición precisa; Pika hace hincapié en la simplicidad y la facilidad de uso.
- Seleccione la herramienta que se adapte a sus necesidades. Si se encuentra en China continental, Seedance y KeLing se pueden utilizar directamente sin barreras adicionales de red o de pago.
La brecha entre las marcas y los creadores que utilizan Tusheng Video AI y sus homólogos que siguen dependiendo de imágenes estáticas se amplía cada mes. Cada fotografía de su biblioteca de productos tiene potencial como anuncio de vídeo. Cada retrato podría convertirse en un avatar dinámico. Cada paisaje podría servir como metraje cinematográfico de segundo plano.
Crea tu primer vídeo a partir de una imagen de forma gratuita --> — Sube cualquier imagen y observa cómo cobra vida en dos minutos. No se requiere tarjeta de crédito, accesible directamente en China continental.
¿Te apetece explorar más funciones de vídeo con IA? Prueba Seedance en todas las plataformas -->: conversión de texto a vídeo, de vídeo a vídeo, generación multimodal: todo en un solo lugar.
Más información: Guía completa del usuario de Seedance | Guía de comandos de Seedance con más de 50 ejemplos | Casos de uso creativo de vídeos con IA | Clasificación de los mejores generadores de vídeo con IA para 2026 | Guía de marketing de vídeo con IA y redes sociales | IA de texto a vídeo: guía completa*
