
Zusammenfassung
Die Image-to-Video-KI nutzt Deep-Learning-Technologie auf Basis von Diffusionsmodellen, um statische Bilder in dynamische Videos umzuwandeln. Im Gegensatz zur reinen Text-zu-Video-Generierung müssen Sie lediglich ein Foto hochladen, damit die KI realistische Bewegungen, Kamerabewegungen und zeitlich kohärentes Filmmaterial darum herum generieren kann, wodurch Sie eine präzisere Kontrolle über das Endergebnis erhalten. Dieser Leitfaden behandelt umfassend: die technischen Prinzipien hinter Image-to-Video AI; welche Arten von Bildern optimale Ergebnisse liefern; eine fünfstufige Anleitung, um Ihr erstes Video von Grund auf neu zu erstellen; acht praktische Anwendungsfälle mit Beispielen; fortgeschrittene Techniken zur Bewegungssteuerung; und einen Vergleich der führenden Tools von 2026 in der Praxis (einschließlich derjenigen, die direkt in China zugänglich sind).Probieren Sie Image-to-Video AI kostenlos aus -->
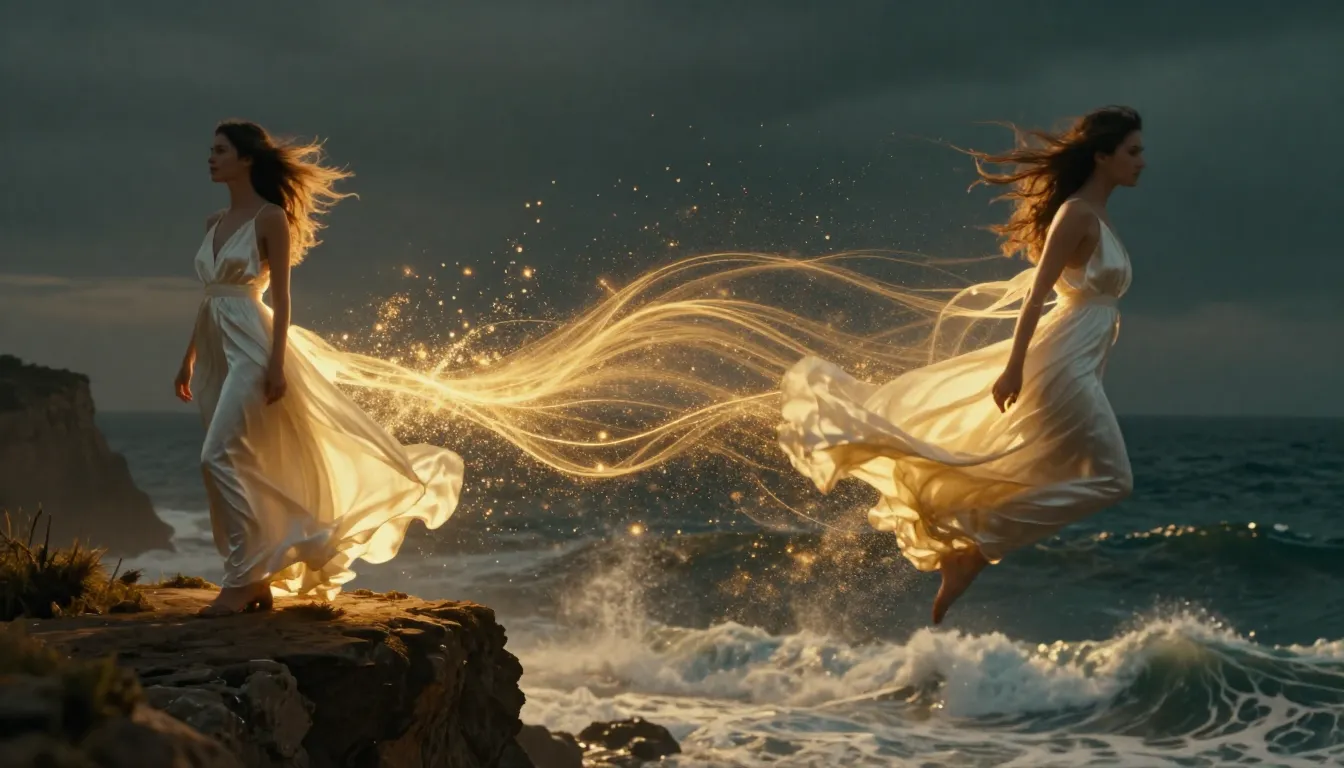
TuSheng Video AI nimmt Ihre Standbilder und erzeugt lebensechte Bewegungen, filmische Kamerabewegungen und zeitliche Kontinuität – und verwandelt so ein einzelnes Bild in einen filmischen Videoclip.
Was ist Tusheng Video AI?
Image-to-Video-KI ist eine Technologie der künstlichen Intelligenz, die in der Lage ist, aus statischen Bildern Videos zu generieren. Sie liefern ein Foto – sei es ein Porträt, ein Produktbild, eine Landschaft oder ein Kunstwerk – und das KI-Modell erstellt ein kurzes Video, in dem sich Elemente zu bewegen beginnen, die Kamera die Perspektive wechselt und die gesamte Szene zum Leben erwacht.
Im Kern verwenden die meisten generativen Videosysteme Videodiffusionsmodelle. Diese neuronalen Netze werden anhand von Millionen von Videobild-Datenpaaren trainiert und lernen dabei die statistische Beziehung zwischen statischen Bildern und nachfolgenden natürlichen Bewegungen. Wenn dem Modell ein neues Bild präsentiert wird, sagt es voraus, welche Bewegung am natürlichsten erscheint, und generiert eine kontinuierliche Bildsequenz, die nahtlos aus dem Originalfoto übergeht.
Unterschiede zu Text-zu-Video
Text-to-Video generiert Inhalte vollständig aus Text. Die KI erstellt gleichzeitig sowohl visuelle Inhalte als auch Bewegungen auf der Grundlage Ihrer Textvorgabe – ein leistungsstarker, aber unvorhersehbarer Prozess, da die KI unabhängig das Aussehen der Motive, die Komposition der Szenen und alle Arten von Bewegungen bestimmt.
Tusheng Video kehrt diese Logik um: Sie liefern den visuellen Anker. Die KI weiß bereits, wie die Szene aussieht, weil Sie sie ihr direkt gezeigt haben. Ihre einzige Aufgabe besteht darin, plausible Bewegungen zu generieren. Das bedeutet:
- Bessere Kontrolle: Ihre Bilder definieren das Motiv, die Komposition, die Farbpalette und den Stil
- Weniger Spekulationen: KI erfordert keine Interpretation vager Textbeschreibungen
- Verbesserte Konsistenz: Die Ergebnisse stimmen weitgehend mit dem Ausgangsbild überein
- Schnellere Iterationen: Das Anpassen der Bewegungsvorgabe ist viel einfacher als das Umschreiben der gesamten Szenenbeschreibung
Warum TuSheng Video im Jahr 2026 so wichtig ist
TuSheng Video AI hat sich von einem experimentellen Spielzeug zu einem produktiven Werkzeug entwickelt. E-Commerce-Marken verwandeln Produktbilder in animierte Werbeanzeigen, Content-Ersteller erwecken ihre beliebtesten Beiträge zum Leben, Immobilienmakler erstellen aus Fotos von Immobilien virtuelle Besichtigungsvideos und Pädagogen animieren Illustrationen aus Lehrbüchern.
Diese Technologie hat einen Wendepunkt erreicht: 5 bis 15 Sekunden lange Videos, die aus hochwertigen Quellbildern generiert werden, sind heute in den meisten Fällen von herkömmlichem Filmmaterial kaum noch zu unterscheiden. Genau aus diesem Grund ist die Bild-zu-Video-Konvertierung zur am schnellsten wachsenden Kategorie innerhalb der KI-Videogenerierung geworden.
Dieser Trend ist auf dem chinesischen Markt besonders ausgeprägt. Algorithmen auf Plattformen wie Douyin, Xiaohongshu, Bilibili und Kuaishou bevorzugen Videoinhalte, was bei den Erstellern zu einer beispiellosen Nachfrage nach Tools führt, mit denen Fotos schnell in Videos umgewandelt werden können. Tusheng Video AI schließt genau diese Lücke auf dem Markt.
Technische Grundlagen der Tusheng Video-KI
Wenn Sie den technischen Prozess verstehen, können Sie bessere Ergebnisse erzielen. Wenn Sie wissen, warum sich KI auf eine bestimmte Weise verhält, können Sie bessere Eingaben machen und effektivere Eingabeaufforderungen schreiben. Hier ist der vierstufige Prozess, der hinter den Kulissen abläuft.

Die vier Stufen der Tusheng Video AI-Verarbeitungs-Pipeline: Bildkodierung, Bewegungsvorhersage, Frame-Generierung und zeitliche Glättung.
Schritt 1: Bildkodierung
Die KI analysiert zunächst Ihr Eingabebild mithilfe eines Encoder-Netzwerks und komprimiert es zu einer dichten mathematischen Darstellung, die als latenter Vektor bezeichnet wird. Dies kann man sich so vorstellen, dass die KI einen „Fingerabdruck“ Ihres Bildes extrahiert – dabei erfasst sie dessen Struktur, Farbe, Tiefe, Positionierung des Motivs, Beleuchtungsrichtung und semantische Informationen.
Diese latente Darstellung ist wesentlich kompakter als die ursprünglichen Pixeldaten, wodurch nachfolgende Berechnungen möglich werden. Die Qualität der Kodierung wirkt sich direkt auf die Ausgabenergebnisse aus. Eingabebilder mit höherer Auflösung und Schärfe erzeugen reichhaltigere latente Darstellungen, was letztlich zu einer überlegenen Videoausgabe führt.
Schritt 2: Bewegungsvorhersage
Dies ist der kreative Kern des gesamten Prozesses. Das Diffusionsmodell sagt voraus, welche Art von Bewegung auf der Grundlage Ihres Originalbildes natürlich erscheinen würde, wobei Folgendes berücksichtigt wird:
- Szenischer Kontext: Ein Meeresfoto impliziert, dass Wellen schlagen sollten; ein Porträt suggeriert subtile Gesichtsdynamik
- Tiefeninformation: Objekte in der Nähe des Objektivs können andere Bewegungsmuster aufweisen als weit entfernte Motive
- Physikalischer Realismus: Haare sollten im Wind wehen, Wasser sollte nach unten fließen und Stoffe sollten natürlich fallen
- Ihre Textvorgabe: Wenn Sie „langsam nach links schwenken” angeben, passt das Modell seine Bewegungsvorhersage entsprechend an.
Das Modell verzerrt nicht nur Pixel. Es generiert völlig neue visuelle Inhalte für Bereiche, die durch Kamerabewegungen oder Objektbewegungen neu sichtbar werden. Wenn die Kamera nach rechts schwenkt, „füllt“ das Modell den Bereich jenseits des rechten Bildrandes des Originalbildes aus.
Schritt 3: Frame-Erzeugung
Basierend auf der Bewegungsvorhersage generiert das Modell eine Folge von Videobildern. Jedes Bild wird durch einen umgekehrten Diffusionsprozess erzeugt – ausgehend von Rauschen wird es schrittweise zu einem klaren Bild verfeinert, wobei die Konsistenz mit dem vorhergehenden Bild und dem Originalbild erhalten bleibt.
Seedance 2.0 und andere moderne Modelle generieren hohe Bildraten (24–30 fps) und gewährleisten dabei die Subpixel-Konsistenz zwischen den Bildern. Dies sorgt für eine flüssige, flimmerfreie Ausgabe ohne die bei früheren Systemen üblichen Ruckelprobleme.
Schritt 4: Zeitglättung
Der letzte Schritt sorgt für nahtlose Übergänge zwischen allen generierten Frames. Der zeitliche Aufmerksamkeitsmechanismus überprüft, ob Helligkeit, Farbe und Bewegung während des gesamten Videos konsistent bleiben, und verhindert so häufige visuelle Artefakte:
- Plötzliche Farbverschiebungen zwischen den Bildern
- Unerwartetes Erscheinen oder Verschwinden von Objekten
- Unnatürliche Beschleunigung oder Verlangsamung der Bewegung
- Flackern der Oberflächenstruktur
Das Endergebnis ist ein exquisites Video, das sich ganz natürlich aus dem Originalmaterial ergibt.
Warum sehen manche Bilder besser aus?
Jetzt können Sie verstehen, warum die Qualität des Eingangsbildes so entscheidend ist. Ein unscharfes Bild mit niedriger Auflösung erzeugt im ersten Schritt eine verrauschte potenzielle Codierung, wodurch dem Bewegungsvorhersagemodell (zweiter Schritt) weniger Informationen zur Verfügung stehen. Dies führt zu einer weniger präzisen Bewegung und mehr visuellen Artefakten in der endgültigen Ausgabe. Umgekehrt liefert ein scharfes, gut komponiertes Bild mit klaren Tiefenhinweisen dem Modell reichhaltige Informationen, was zu einem natürlicheren Video mit höherer Qualität führt.
Welche Art von Bild liefert die besten Ergebnisse?
Nicht alle Bilder sind für Tusheng Video AI geeignet. Der Unterschied zwischen gutem und schlechtem Ausgangsmaterial kann durchaus den Unterschied zwischen einem atemberaubenden Video und einem Haufen unbrauchbaren Filmmaterials ausmachen. Hier finden Sie einen praktischen Leitfaden.

Auf der linken Seite werden geeignete Stockbilder angezeigt (hohe Auflösung, gut komponiert, natürliche Bewegung suggerierend), während auf der rechten Seite ungeeignete Stockbilder zu sehen sind (unscharf, überladen, Elemente enthalten, die für KI schwer zu verarbeiten sind).
Geeignete Bildformate
Hohe Auflösung (1024x1024 oder höher). Mehr Pixel ermöglichen es dem Encoder, mehr Details zu extrahieren. Verwenden Sie immer die Version mit der höchsten verfügbaren Auflösung. Empfohlene Mindestauflösung: 512x512 Pixel. Ideal: 1024x1024 oder höher.
Die Motive sind klar definiert und haben deutliche Konturen. Die KI muss erkennen, was sich bewegen soll und was statisch bleiben soll. Ein Porträt, bei dem das Motiv scharf vom Hintergrund abgesetzt ist, liefert weitaus bessere Ergebnisse als eine komplexe, chaotische Gruppenszene.
Gut beleuchtet und korrekt belichtet. Bilder mit guter Beleuchtung liefern genaue Farb- und Tiefeninformationen für das Modell. Vermeiden Sie Bilder, die stark über- oder unterbelichtet sind.
Natürliche Schichtung und Komposition. Bilder mit klar definierten Vordergrund, Mittelgrund und Hintergrund liefern der KI Tiefenhinweise, wodurch der Realismus von Parallaxeneffekten und Kamerabewegungen verbessert wird.
Bilder, die Bewegung suggerieren. Bildliche Hinweise auf Bewegung – im Wind wehende Haare, Wellen, die sich über die Küste ergießen, eine voranschreitende Gestalt – bieten dem Modell aussagekräftige Ansatzpunkte für die Vorhersage von Bewegungen. KI kann anhand dieser visuellen Indikatoren erkennen, „was als Nächstes passiert“.
Saubere Hintergründe. Ein minimalistischer oder natürlich unscharfer Hintergrund sorgt für eine flüssigere Videoausgabe als unaufgeräumte Hintergründe, die mit zahlreichen kleinen Objekten gefüllt sind.
Bildtypen, die Probleme verursachen können
Unscharfe oder unscharfe Bilder. Unschärfe bei der Eingabe, Unschärfe bei der Ausgabe. KI kann keine Schärfe hinzufügen, die im Originalbild nicht vorhanden war.
Übermäßig komplexe Szenen. Bilder, die zahlreiche kleine Motive, komplizierte Muster oder visuelle Unordnung enthalten, können Bewegungsvorhersagemodelle überfordern, sodass diese nicht mehr in der Lage sind, zu bestimmen, was sich wie bewegen sollte.
Umfangreicher Text oder Typografie. KI-Videomodelle haben nach wie vor Schwierigkeiten, die Lesbarkeit von Text über mehrere Frames hinweg zu gewährleisten. Sollten Ihre Bilder Logos, Branding oder Textüberlagerungen enthalten, kommt es zu Verzerrungen in der Videoausgabe.
Niedrige Auflösung (512x512 oder weniger). Kleine Bilder enthalten unzureichende Informationen. Selbst eine Vergrößerung mit KI vor der Eingabe ist zwecklos – sie fügt Pixel hinzu, aber keine Informationen.
Starke Filter oder Nachbearbeitung. Extreme Farbanpassungen, HDR-Bearbeitung oder umfangreiche Photoshop-Modifikationen können das Verständnis des Modells für Beleuchtung und Tiefe verwirren.
Mehrere Gesichter unterschiedlicher Größe. KI verarbeitet einzelne Porträts effektiv. Gruppenaufnahmen mit Gesichtern in unterschiedlichen Entfernungen führen zu inkonsistenten Animationen – einige Gesichter wirken natürlich, während andere verzerrt erscheinen.
Checkliste zur Selbstkontrolle vor dem Hochladen
Bevor Sie Bilder hochladen, überprüfen Sie bitte kurz die folgenden Punkte:
- Mindestauflösung von 1024 x 1024 Pixel
- Motiv klar definiert und deutlich vom Hintergrund abgesetzt
- Korrekte Belichtung (weder unter- noch überbelichtet)
- Keine starken Filter, extremes HDR oder sichtbare künstliche Bearbeitung
- Minimale Text-, Logo- oder typografische Elemente
- Kontrollierte Komplexität der Szene (1–3 Hauptmotive)
- Bildformat: JPG, PNG oder WebP
Sobald diese Bedingungen erfüllt sind, kann mit der Erzeugung begonnen werden.
Schritt-für-Schritt-Anleitung: Erstellen Sie Ihr erstes Bild-zu-Video
Befolgen Sie diese fünf Schritte, um jedes statische Bild in ein animiertes KI-Video umzuwandeln. Wir verwenden Seedance als Demonstrationsplattform, aber diese Prinzipien gelten für jedes Bild-zu-Video-Tool.
Schritt 1: Auswahl geeigneter Quellbilder
Das Ausgangsbild ist der entscheidende Faktor für die Ausgabequalität. Wählen Sie ein Bild aus, das den zuvor genannten Richtlinien entspricht. Für Ihren ersten Versuch empfehlen wir Ihnen, ein einfaches Porträt oder eine Landschaft mit ausgeprägter Tiefe zu wählen – diese beiden Bildtypen liefern die konsistentesten Ergebnisse.
Empfohlene Bilder für erste Versuche: – Klare Porträtaufnahmen oder Halbfigurenporträts bei günstiger Beleuchtung – Landschaften mit Himmel, Wasserflächen oder Vegetation (diese Elemente besitzen eine inhärente Bewegung) – Produktbilder vor einfarbigem Hintergrund – Kunstwerke oder Illustrationen mit klar unterscheidbaren Elementen
Vermeiden Sie bei der ersten Generierung komplexe zusammengesetzte Bilder, Bilder mit großen Textmengen oder stark bearbeitete Fotos.
Schritt 2: Auf Seedance hochladen
Öffnen Sie Seedance Image-to-Video und laden Sie die ausgewählten Bilder hoch. Seedance unterstützt die Formate JPG, PNG und WebP. Die Plattform analysiert Ihre Bilder automatisch und bereitet sie für die Generierung vor.
Wenn ein Bild außergewöhnlich groß ist (mit einer Seite von mehr als 4096 Pixeln), skaliert das System es automatisch unter Beibehaltung der Proportionen, sodass keine manuelle Anpassung erforderlich ist.
Schritt 3: Erstellen einer handlungsorientierten Aufforderung
In dieser Phase teilen Sie der KI die gewünschte Bewegung mit. Ihre Eingabe sollte eher die Dynamik als den Bildinhalt beschreiben (die KI hat das Bild bereits gesehen). Konzentrieren Sie sich auf die folgenden Punkte:
- Bewegung des Motivs: Was soll das Motiv tun?
- Kamerabewegung: Wie soll sich die Kamera bewegen?
- Bewegung der Umgebung: Welche Umgebungsdynamik soll vorhanden sein?
- Tempo und Stimmung: Allgemeines Tempo – schnell oder langsam?
Beispiele für Porträt-Aufforderungen:
The woman slowly turns her head to the right and smiles softly.
A gentle breeze moves her hair. Background slightly out of focus
with subtle bokeh movement. Camera slowly pushes in from medium
shot to a close-up. Warm, natural lighting. Cinematic film quality.Beispiel für eine Landschaftsaufforderung:
Gentle waves roll toward the shore in slow motion. Clouds drift
slowly across the sky from left to right. Sunlight shimmers on
the water surface. Camera slowly pans right, revealing more of
the coastline. Peaceful, serene atmosphere. 4K cinematic quality.Beispiel für eine Produktanzeige:
The camera slowly orbits around the product, rotating 45 degrees
clockwise. Soft studio lighting with subtle caustic reflections
on the surface. Clean white background with gentle gradient.
Premium commercial aesthetic. Smooth, steady camera movement.Grundprinzip: Beschreiben Sie die Bewegung, nicht die Szene. Die Szene existiert bereits in Ihrem Bild.
Hinweis: Seedance unterstützt sowohl chinesische als auch englische Eingabeaufforderungen, wobei englische Eingabeaufforderungen in der Regel eine präzisere Steuerung der Kamerabewegungen ermöglichen. Es wird empfohlen, Englisch für Bewegungs- und kamerabezogene Beschreibungen zu verwenden, während Chinesisch für Beschreibungen der Atmosphäre und des Stils verwendet werden kann.
Schritt 4: Parameter auswählen
Einstellungen für die Konfigurationsgenerierung:
| Parameter | Empfohlener Wert | Beschreibung |
|---|---|---|
| Modell | Seedance 2.0 | Optimale Bildqualität für die Bild-zu-Video-Erzeugung |
| Dauer | 5 Sekunden (für erste Versuche) | Beginnen Sie mit einer kurzen Dauer und verlängern Sie diese dann; erstellen Sie erweiterte Versionen, wenn Sie zufrieden sind |
| Seitenverhältnis | Passt sich dem Bild an | 16:9 für Querformat, 9:16 für Hochformat, 1:1 für Quadrat |
| Auflösung | 1080p | Wählen Sie immer die höchste verfügbare Auflösung |
Fortgeschrittene Technik: Erstellen Sie zunächst eine 5-Sekunden-Version. Wenn die Bewegung und der Stil zufriedenstellend sind, verwenden Sie denselben Prompt, um eine längere Version (8–15 Sekunden) zu erstellen. Dieser Ansatz spart Credits während der Erkundungsphase.
Schritt 5: Generieren, überprüfen, wiederholen
Klicken Sie auf Generieren und warten Sie 1–3 Minuten. Sobald die Ergebnisse angezeigt werden, bewerten Sie diese anhand der folgenden Kriterien:
- Ist die Bewegung flüssig und natürlich?
- Behält das Motiv durchgehend seine visuelle Konsistenz bei?
- Entspricht die Kamerabewegung Ihren Erwartungen?
- Gibt es visuelle Mängel (Flackern, Verzerrungen, Verformungen)?
- Entspricht die Videoqualität dem Originalmaterial?
Sollte sich ein Aspekt als unbefriedigend erweisen, passen Sie die Eingabeaufforderung an und generieren Sie sie neu. Zu den gängigen Anpassungsmethoden gehören:
- Zu schnell? Fügen Sie „langsam“, „sanft“, „allmählich“ zur Bewegungsbeschreibung hinzu
- Falsche Kamerarichtung? ** Geben Sie genauere Angaben: „statische Kamera, keine Kamerabewegung“ oder „langsames Heranfahren“
- Unvollkommenheiten im Gesicht? Vereinfachen Sie die Bewegung: Reduzieren Sie die Anzahl der gleichzeitig ausgeführten Aktionen
- **Mangelnde Dynamik? ** Fügen Sie dynamische Verben ein: „schwanken“, „fließen“, „treiben“, „sich verschieben“
Nach zwei oder drei Iterationsrunden erhalten Sie ein hochwertiges Video, das Ihre Bilder zum Leben erweckt.
Beginnen Sie jetzt mit der Erstellung Ihres ersten Bild-zu-Video-Clips -->
8 wichtige Anwendungen und Beispiele für die Konvertierung großer Bilder in Videos
TuSheng Video AI ist kein Ein-Trick-Pony. Es dient Dutzenden von kreativen und kommerziellen Zwecken. Im Folgenden finden Sie acht hochwertige Anwendungsszenarien mit praktischen Anweisungen, die Sie direkt kopieren und anpassen können.
- Porträtanimation
Erwecken Sie Ihre Fotos zum Leben. Portrait Animation ist die beliebteste App zum Umwandeln von Fotos in Videos. Laden Sie ein Profilbild, ein Selfie oder ein Charakterbild hoch und fügen Sie dann subtile, lebensechte Animationen hinzu – Atmen, Blinzeln, Kopfdrehen, Ausdruckswechsel und Haarbewegungen.
Geeignet für Erinnerungsvideos, Social-Media-Inhalte, die Erstellung virtueller Avatare und kreatives Storytelling. Auf TikTok und Xiaohongshu sind Inhalte, bei denen „Fotos zum Leben erweckt werden“, nach wie vor ein ständiger Traffic-Magnet.

Ein statisches Porträt verwandelt sich in ein lebensechtes Video – natürliches Blinzeln, subtile Kopfbewegungen und fließendes Haar sorgen für einen überraschend realistischen Effekt.
Beispielaufforderung:
The person looks directly at the camera with a calm, confident
expression. They slowly tilt their head slightly to the left and
give a subtle warm smile. Eyes blink naturally. A soft breeze gently
moves their hair. Shallow depth of field with softly blurred
background. Warm natural lighting. Cinematic portrait quality.- Produktpräsentation
Verwandeln Sie Produktfotografien in dynamische kommerzielle Inhalte. Dies ist revolutionär für E-Commerce-Marken und Influencer – Sie verfügen bereits über Hunderte oder sogar Tausende von Produktbildern, und nun kann jedes einzelne davon zu einer Videowerbung, einem hervorgehobenen Bild für Produktdetailseiten oder einem Kurzfilm für soziale Medien werden.
Auf den Produktdetailseiten von Taobao und JD.com, in den Produktvorstellungen der Douyin-Livestreams und in den Produktempfehlungsbeiträgen von Xiaohongshu erzielen dynamische Produktanzeigen durchweg deutlich höhere Konversionsraten als statische Bilder.

Ein Standard-Produktbild wird auf das Niveau einer hochwertigen Werbeanzeige gehoben – mit Kameraschwenks, dramatischer Beleuchtung und fließenden Bewegungen –, deren traditionelle Produktion Hunderte bis Tausende von Pfund kosten könnte.
Beispielaufforderung:
The camera slowly orbits 90 degrees around the product, revealing
its form from multiple angles. Soft directional studio lighting
with subtle caustic reflections on the surface. A gentle highlight
sweep moves across the product. Clean, premium commercial aesthetic.
Shallow depth of field. Ultra-smooth camera movement. 4K quality.3. Malerischer Zeitraffer
Verwandeln Sie Landschaftsfotografie in stimmungsvolle Zeitraffer-Videos. Wolken ziehen über den Himmel, Wasser fließt, das Licht wechselt von goldenen zu blauen Farbtönen und Blätter wiegen sich im Wind. Ideal für Reiseberichte, Luftaufnahmen von Immobilien und stimmungsvolle B-Roll-Aufnahmen.
Landschaftsfotografen und Reise-Vlogger auf Bilibili können ihre kuratierten Fotos direkt in faszinierende Zeitraffer-Videos umwandeln und so die Produktionskosten erheblich senken.

Eine Landschaftsfotografie, die in einen filmischen Zeitraffer verwandelt wurde – fließende Wolken, plätscherndes Wasser und wechselnde Licht- und Schattenverhältnisse – und so aus einem einzigen statischen Bild eine dynamische, atmosphärische Qualität schafft.
Beispielaufforderung:
Time-lapse effect. Clouds move steadily across the sky from left
to right. Water in the foreground ripples and flows gently. Light
shifts subtly as if the sun is moving, creating slowly changing
shadows on the landscape. Trees and grass sway gently in the wind.
Camera remains static on a tripod. Serene, majestic atmosphere.
Cinematic landscape quality.4. Inhalte in sozialen Medien
Verwandeln Sie Ihre leistungsstärksten statischen Beiträge in Videoinhalte, die die Leute dazu bringen, beim Scrollen inne zu halten. Algorithmen auf Plattformen wie TikTok, Xiaohongshu, Bilibili und Kuaishou bevorzugen Videoinhalte stark – ein leistungsstarker Bildbeitrag wird mit ziemlicher Sicherheit mehr Traffic erzielen, wenn er in ein Video umgewandelt wird.
Für die Ersteller von Inhalten auf Xiaohongshu kann eine Reihe von Bild-Text-Beiträgen eine 3- bis 5-fache Steigerung der Reichweite erzielen, wenn sie von einer Videoversion begleitet werden. Douyin und Kuaishou hingegen basieren vollständig auf Videos als ihrem zentralen Inhaltsformat.
Beispielaufforderung:
Dynamic, attention-grabbing motion. The subject moves confidently
toward the camera with energy and presence. Background elements
shift with parallax depth effect. Quick, punchy camera push-in
that creates impact. Vibrant colors, high contrast. Bold,
eye-catching aesthetic optimized for social media. Vertical 9:16.- Kunst und Illustration Animation
Erwecken Sie Kunstwerke, Illustrationen, digitale Gemälde und Grafikdesigns zum Leben. Dieses Anwendungsszenario ist besonders beliebt bei Künstlern, Spieledesignern und Kreativteams, die ihre Arbeiten auf ansprechendere Weise präsentieren möchten.
In den Kunst- und Anime-Communities von Bilibili und Xiaohongshu zählen animierte Illustrationen zu den Inhalten mit der höchsten Interaktionsrate. Die Umwandlung statischer Kunstwerke in Videos im Stil von „lebenden Hintergrundbildern” führt oft zu deutlich höheren Shares und Speichervorgängen als die Originalbilder.
Beispielaufforderung:
The illustrated scene comes to life with gentle, painterly motion.
Characters move subtly within their positions -- breathing, shifting
weight, small gestures. Background elements like leaves, clouds,
or particles drift slowly. The artistic style is preserved exactly
as painted. Movement is smooth and dreamlike, like a living painting.
Gentle ambient lighting shifts. Fantasy illustration quality.6. Virtuelle Immobilienbesichtigungen
Verwandeln Sie Immobilienfotos in virtuelle Besichtigungsvideos. Immobilienmakler können anhand vorhandener Immobilienbilder immersive Vorschauen erstellen, sodass keine speziellen Fototeams für Aufnahmen vor Ort mehr organisiert werden müssen.
Bei Immobilienanzeigen, die auf Plattformen wie Beike und Anjuke angezeigt werden, sowie bei Immobilienwerbung in Social-Media-Feeds und auf Xiaohongshu weisen dynamische Besichtigungsvideos deutlich höhere Konversionsraten bei Kundenanfragen auf.
Beispielaufforderung:
Smooth virtual walkthrough. The camera glides forward slowly into
the room, revealing the space with a wide-angle perspective.
Natural daylight streams through the windows, casting soft shadows.
Subtle dust particles float in the sunbeams. The camera pans
gently to the left, showing the full room layout. Clean, bright,
aspirational real estate aesthetic. Steady, professional movement.- Mode- und Styling-Showcase
Erstellen Sie dynamische Modeinhalte aus Studio-Outfit-Fotos. Die Models bewegen sich, die Stoffe fallen natürlich, während der ästhetische Stil auf Redaktionsniveau erhalten bleibt.
Xiaohongshu-Modeblogger und Taobao-Bekleidungshändler können große Mengen bestehender Modelaufnahmen und Flat-Lay-Outfit-Bilder in dynamische Display-Videos umwandeln und so eine größere visuelle Wirkung innerhalb der Informationsfeeds erzielen.
Beispielaufforderung:
The model strikes a confident pose and then slowly shifts their
weight, creating natural body movement. Fabric of the outfit
flows and catches the light with each subtle motion. Wind effect
gently moves the hair. Camera starts at full body and slowly drifts
upward to a waist-up shot. High-fashion editorial lighting with
strong directional shadows. Vogue magazine aesthetic. Cinematic
slow motion.- Bildungs- und Erklärungsinhalte
Verwandeln Sie statische Diagramme, Infografiken und pädagogische Illustrationen in dynamische Präsentationen. Komplexe Konzepte lassen sich leichter verstehen, wenn sie in Bewegung gesetzt werden.
Die Entwickler der Wissenszone von Bilibili und verschiedener Bildungsplattformen können Kursunterlagen, Diagramme und Flussdiagramme in animierte Videoinhalte umwandeln, wodurch die Unterrichtseffektivität und die Zuschauerbindungsraten erheblich verbessert werden.
Beispielaufforderung:
The diagram elements animate sequentially. Arrows begin to flow
in their indicated directions. Labels fade in one by one. Moving
parts of the system activate in logical order, showing the process
step by step. Smooth transitions between stages. Clean, clear
educational style. Elements highlight with subtle glow as they
become active. Professional presentation quality.Ein umfassender Leitfaden zu Prompt-Techniken für Tusheng-Videos
Eine gut formulierte Eingabeaufforderung ist die wirkungsvollste Methode, um Bilder aus Fotos zu generieren. Da die KI Ihr Bild bereits gesehen hat, sollte sich Ihre Eingabeaufforderung ganz auf Bewegung und Dynamik konzentrieren. Hier sind einige Techniken, mit denen Sie die besten Ergebnisse erzielen.
Schnellreferenz für Sport-Schlüsselwörter
Verwenden Sie diese spezifischen Schlüsselwörter, um die Bewegung im Video präzise zu steuern.
| Bewegungsart | Stichworte | Wirkung | |-------- -|-------|------| | Aufnahme: Vorwärts | Dolly-Einstellung, Push-in, näher kommen, annähern | Kamera bewegt sich auf das Motiv zu | | Aufnahme: Rückwärts | Dolly-Ausstellung, Zurückziehen, zurückweichen, weitern | Kamera bewegt sich vom Motiv weg | | Aufnahme: Links/Rechts | Schwenk nach links, Schwenk nach rechts, Kamerafahrt nach links, Kamerafahrt nach rechts | Kamera dreht sich oder fährt horizontal | | Aufnahme: Auf/Ab | Neigung nach oben, Neigung nach unten, Kran nach oben, Kran nach unten | Kamera dreht sich oder bewegt sich vertikal | | Aufnahme: Orbit | umkreisen, drehen, rotieren, Bogen | Kamera umkreist Motiv | | Kamera: Zoom | heranzoomen, herauszoomen, Brennweitenverschiebung | Kamera zoomt (ohne Verschiebung) | | Motiv: Mikrobewegungen | atmen, blinzeln, Gewicht verlagern, Mikrobewegungen | Subtile, lebensechte Bewegungen | | Motiv: Moderat | Kopf drehen, lächeln, gestikulieren, langsam gehen | Klare, aber kontrollierte Bewegung | | Motiv: Dynamisch | rennen, springen, tanzen, sich drehen, winken | Energiegeladene Ganzkörperbewegung | | Umgebung: Sanft | Brise, Treiben, Schwanken, Wellen, Schimmern | Sanfte Umgebungsbewegungen | | Umgebung: Intensiv | Wehen, Rauschen, Krachen, Wirbeln, Stürzen | Kraftvolle Umgebungsdynamik | | Parallaxe | Parallaxe, Tiefenverschiebung, Bewegung von Ebenen | Vordergrund/Hintergrund bewegen sich mit unterschiedlichen Geschwindigkeiten |

Verschiedene Schlüsselwörter für Kamerabewegungen erzeugen völlig unterschiedliche Effekte. Wählen Sie Ihre Kamerabewegungstechnik bewusst entsprechend dem gewünschten Ergebnis aus.
Geschwindigkeits- und Tempokontrolle
Das Tempo der Bewegung hat einen großen Einfluss auf die emotionale Stimmung eines Videos. Verwenden Sie die folgenden Modifikatoren:
- Extrem langsam: „kaum wahrnehmbar“, „Ultra-Zeitlupe“, „schneebedecktes Tempo“ – dramatisch, kontemplativ
- Langsam: „langsam“, „sanft“, „allmählich“, „gemächlich“ – Eleganz, filmische Qualität
- Mäßig: „gleichmäßig“, „natürliches Tempo“, „in Gehgeschwindigkeit“ – Realismus, dokumentarischer Stil
- Schnell: „ schnell“, „lebhaft“, „energisch“, „flink“ – dynamisch, aufregend
- Extrem schnell: „rasant“, „Whip Pan“, „Quick Cut“, „Bewegungsschub“ – spannend, actionreich
Fortgeschrittene Technik: Verwenden Sie standardmäßig Zeitlupe. In KI-generierten Videos sieht Zeitlupe fast immer besser aus als Zeitraffer. Schnelle Bewegungen erhöhen das Risiko von Unvollkommenheiten und visuellen Unstimmigkeiten.
Unabhängige Bewegungssteuerung von Hintergrund und Motiv
Sie können selbstständig steuern, was sich bewegt und was still bleibt. Dies ist eine wirkungsvolle Technik, um die Aufmerksamkeit des Publikums zu lenken.
Objekt in Bewegung, Hintergrund unbewegt:
The person walks forward confidently while the background remains
perfectly still. Static camera, no camera movement. Focus entirely
on the subject's motion.Dynamischer Hintergrund, statisches Motiv:
The person stands completely still, like a statue. Behind them,
clouds drift across the sky, leaves blow in the wind, and city
lights flicker. Only the environment moves.Getrennte Bewegungen beider Seiten:
The person slowly turns their head while the camera simultaneously
dollies in. Background clouds drift in the opposite direction,
creating a sense of depth and dimension.Der Unterschied zwischen Kamerabewegung und Objektbewegung
Das Verständnis des Unterschieds zwischen Kamerabewegung und Objektbewegung ist entscheidend, um den gewünschten Effekt zu erzielen.
Die Kamerabewegung verändert die Perspektive und die Komposition. Die Szene selbst bleibt unverändert, während sich der Blickwinkel verschiebt. Verwendet für: die Enthüllung der Szene, die Darstellung der Kulisse und die dramatische Betonung.
Objektbewegung bezieht sich auf die Bewegung von Elementen innerhalb einer Szene, während die Kamera stationär bleibt. Sie wird für folgende Zwecke eingesetzt: Charakteranimation, Produktdemonstrationen und natürliche Umgebungsdynamik.
Kombinierte Bewegungen nutzen beide gleichzeitig. Dies ist die filmischste Technik, aber auch die für KI am schwierigsten auszuführende. Es ist ratsam, zunächst eine einzelne Bewegungsart zu beherrschen und die andere erst dann hinzuzufügen, wenn Sie mit dem Ergebnis zufrieden sind.
Erweiterte Eingabeaufforderungsstrukturen
Um möglichst vorhersehbare Ergebnisse zu erzielen, ordnen Sie Ihre Eingabeaufforderung in der folgenden Reihenfolge an:
- Primäre Handlung – Was das Hauptmotiv tut
- Kamerabewegung – Wie sich die Kamera bewegt
- Umgebungsdynamik – Was die Umgebungselemente tun
- Geschwindigkeit/Tempo – Das Tempo aller Bewegungen
- Atmosphäre/Stimmung – Emotionaler Ton
- Verbesserung der visuellen Qualität – Technische Beschreibung der visuellen Qualität
Beispiel für die Verwendung dieser Struktur:
[Subject] A young woman in a flowing white dress slowly raises
her hand to brush hair from her face.
[Camera] The camera executes a slow, steady dolly in from a
medium shot to a close-up.
[Environment] Cherry blossom petals drift gently through the
air. Soft golden sunlight filters through the trees.
[Speed] All motion is slow and deliberate, almost dreamlike.
[Mood] Romantic, ethereal, peaceful atmosphere.
[Quality] Cinematic shallow depth of field, anamorphic bokeh,
film grain, 4K quality.Vergleich der TuSheng Video-KI-Tools 2026
Der Wettbewerb im Bereich Video-Streaming verschärft sich. Nachfolgend finden Sie eine vergleichende Analyse der wichtigsten Plattformen im Februar 2026, wobei der Schwerpunkt auf der Zugänglichkeit für Nutzer auf dem chinesischen Festland liegt.

Die Verarbeitungsergebnisse desselben Quellbildes auf fünf verschiedenen Videogenerierungsplattformen. Unterschiede in der Bewegungsqualität, zeitlichen Konsistenz und visuellen Wiedergabetreue sind sofort erkennbar.
| Funktion | Seedance 2.0 | Runway Gen-4 | Pika 2.0 | Kling 3.0 | Luma Dream Machine | |------|-------------|-------------|---------|------ ----------|-------------------| | Maximale Auflösung | 2K (2048x1080) | 4K (hochskaliert) | 1080p | 1080p | 1080p | | Maximale Dauer | 15 Sekunden | 10 Sekunden | 5 Sekunden | 2 Minuten | 5 Sekunden | | Eingabeoptionen | Bild + Text + Video + Audio | Bild + Text + Video | Bild + Text | Bild + Text | Bild + Text | | Eingabe mehrerer Bilder | Unterstützt (bis zu 9 Bilder) | Nicht unterstützt | Nicht unterstützt | Nicht unterstützt | Nicht unterstützt | | Native Audio | Unterstützt (8 Sprachen mit Lippensynchronisation) | Nicht unterstützt | Teilweise (Soundeffekte) | Nicht unterstützt | Nicht unterstützt | | Kamerasteuerung | Auf Eingabeaufforderungen basierend | Motion Brush + Director-Modus | Grundlegend | Grundlegend | Auf Eingabeaufforderungen basierend | | Kostenloses Kontingent | Verfügbar (Registrierungsbonus) | Verfügbar (eingeschränkt) | Verfügbar (eingeschränkt) | Verfügbar (eingeschränkt) | Verfügbar (eingeschränkt) | | Startpreis | ~9,90 $/Monat | 15 $/Monat | 10 $/Monat | ~6,99 $/Monat | 9,99 $/Monat | | Zugang zum chinesischen Festland | Direkt zugänglich | VPN erforderlich | VPN erforderlich | Direkt zugänglich | VPN erforderlich | | Am besten geeignet für | Multimodale Steuerung, Bildqualität | Professioneller Bearbeitungsworkflow | Anfänger, lustige Effekte | Langform-Videos, hoher Wert | Kinoähnliches Gefühl, 3D-Szenen |
Detaillierte Bewertungen der einzelnen Tools
Seedance 2.0 ist unübertroffen in seiner Eingabeflexibilität. Es ist die einzige Plattform, die das gleichzeitige Hochladen von bis zu neun Referenzbildern, Audio-Eingabe-Lippensynchronisation und die Kombination aller Eingabemodi in einer einzigen Generation unterstützt. Für maximale Kontrolle über die Bild-zu-Video-Ausgabe bietet Seedance das umfassendste Toolkit. Seine 2K-Auflösung ist auch die höchste unter allen Tools (ohne auf Upsampling angewiesen zu sein). Seedance wurde von ByteDance (Muttergesellschaft von TikTok) entwickelt und ist für Nutzer in Festlandchina direkt zugänglich, ohne dass ein VPN oder Zahlungsmethoden aus dem Ausland erforderlich sind.
Runway Gen-4 zeichnet sich durch präzise Steuerung aus. Mit Motion Brush können Sie akribisch „malen”, welche Teile eines Bildes sich in welche Richtung bewegen sollen. Wenn Sie chirurgische Präzision für bestimmte Bereiche benötigen, ist Runway die beste Wahl. Die Nachteile sind der höhere Preis und die geringeren Generierungsquoten. Für den Zugriff innerhalb Chinas ist ein VPN erforderlich.
Pika 2.0 ist die am leichtesten zugängliche Option. Für Anfänger, die mit der Erstellung von Bildern zu Videos experimentieren möchten, ohne sich mit Prompt Engineering auseinandersetzen zu müssen, bieten die Ein-Klick-Effekte und die optimierte Benutzeroberfläche von Pika die niedrigste Einstiegshürde. Die Bildqualität bleibt zwar hinter der von Premium-Tools zurück, ist aber für gelegentliche Social-Media-Inhalte völlig ausreichend. Für den Zugriff innerhalb Chinas ist ein VPN erforderlich.
Kling 3.0 übertrifft seine Konkurrenten sowohl in Bezug auf die Dauer als auch auf das Preis-Leistungs-Verhältnis. Wenn Sie längere Videos – 30 Sekunden, 1 Minute oder sogar 2 Minuten – aus einem einzigen Bild erstellen möchten, ist Kling die einzige praktikable Option. Das Preis-Leistungs-Verhältnis in Bezug auf die Bildqualität ist außergewöhnlich günstig. Die einzige Einschränkung besteht in den begrenzten Eingabeoptionen (einzelnes Bild + Text). Als Produkt unter dem Dach von Kuaishou ist Kling direkt in Festlandchina zugänglich und bietet inländischen Nutzern eine weitere nahtlose Option.
Luma Dream Machine zeichnet sich durch sein räumliches Verständnis aus. Bei Landschaften, Architektur und Szenen, bei denen dreidimensionales räumliches Bewusstsein entscheidend ist, erzeugt Luma die überzeugendsten Parallax- und Kamerabewegungen. Die Charakteranimation bleibt im Vergleich zu Mitbewerbern zurück. Für den Zugriff aus dem Inland ist ein VPN erforderlich.
Empfehlungen für Nutzer aus Festlandchina
Wenn Sie sich auf dem chinesischen Festland befinden, gibt es im Wesentlichen zwei Videotools, die ohne VPN direkt verwendet werden können:
- Seedance 2.0 – Entwickelt von ByteDance, voll funktionsfähig und einsatzbereit, mit multimodaler Eingabe + 2K-Auflösung + integriertem Audio
- Kling 3.0 – Ein Produkt von Kuaishou, das sich durch die Erstellung langer Videos auszeichnet und ein hervorragendes Preis-Leistungs-Verhältnis bietet.
Während ausländische Tools wie Runway, Pika und Luma jeweils ihre eigenen Besonderheiten aufweisen, erfordern sie alle einen VPN-Zugang und ausländische Zahlungsmethoden, was eine höhere Einstiegshürde darstellt.
Für Content-Ersteller auf inländischen Plattformen wie Douyin, Xiaohongshu, Bilibili und Kuaishou ist die Entscheidung für Tools, die direkt in China zugänglich sind, nicht nur bequemer, sondern bietet auch mehr Sicherheit in Bezug auf Netzwerkstabilität und Zahlungsfreundlichkeit.
Für einen umfassenderen Vergleich (einschließlich Text-zu-Video-Funktionen) lesen Sie bitte unsere vollständige Rangliste der KI-Videogeneratoren für 2026.
Häufige Fehler und Korrekturmethoden
Nachdem wir Tausende von Videoclips getestet haben, sind hier die fünf häufigsten Fehler, die wir beobachtet haben – zusammen mit konkreten Korrekturmaßnahmen.
- Verwenden Sie Stockbilder mit niedriger Auflösung.
Der Fehler: Hochladen eines kleinen, komprimierten Bildes (z. B. eines aus WeChat oder sozialen Medien gespeicherten Miniaturbildes mit einer Größe von 400 x 300 Pixeln) bei gleichzeitiger Erwartung einer hochauflösenden Videoausgabe.
Warum es fehlschlägt: Der Encoder kann aus Bildern mit niedriger Auflösung nicht genügend visuelle Informationen extrahieren. Die Ausgabe übernimmt die Unschärfe und überlagert sie zusätzlich mit Bewegungsartefakten.
So beheben Sie das Problem: Verwenden Sie immer die Version des Bildes mit der höchsten Auflösung. Wenn nur Versionen mit niedriger Auflösung verfügbar sind, verwenden Sie ein KI-Upscaling-Tool (z. B. Real-ESRGAN oder Topaz Gigapixel), um die Auflösung vor dem Hochladen zu verbessern. Die empfohlene Mindestgröße beträgt 1024 x 1024 Pixel.
- Schreiben Sie Szenenbeschreibungen statt Handlungsbeschreibungen.
Der Fehler: Schreibanweisungen wie „Die Meeresoberfläche bei Sonnenuntergang, mit goldenem Licht, das auf dem Wasser glitzert“. Dies beschreibt das Aussehen des Bildes – etwas, das die KI bereits weiß.
Warum es fehlgeschlagen ist: Die KI hat das Bild bereits kodiert. Das Zurückbeschreiben des Bildinhalts verschwendet Platz für redundante Informationen und liefert keine Anweisungen für die Bewegung.
So überarbeiten Sie den Text: Konzentrieren Sie sich in der Aufgabenstellung ganz auf die Bewegung. Schreiben Sie den Text wie folgt um: „Wellen rollen sanft auf das Ufer zu. Goldenes Sonnenlicht glitzert auf der Wasseroberfläche. Wolken ziehen langsam von links nach rechts. Die Kamera schwenkt langsam nach rechts und folgt dabei der Küstenlinie.“
- Zu viele Aktionen müssen gleichzeitig ausgeführt werden.
Gemachte Fehler: „Die Figur dreht den Kopf, winkt, geht vorwärts, nimmt eine Tasse in die Hand, lächelt und tanzt, während die Kamera heranzoomt, nach links schwenkt und nach unten neigt.“
Warum es scheitert: Aktuelle KI-Modelle können nicht zuverlässig mehr als zwei oder drei gleichzeitige Aktionen koordinieren. Überladene Eingabeaufforderungen führen dazu, dass das Modell entweder die meisten Anweisungen ignoriert oder verwirrende, fehlerhafte Ergebnisse liefert.
Bearbeiten: Beschränken Sie jede Generation auf eine primäre Handlung und eine Kamerabewegung. Bei komplexen, fortlaufenden Handlungen erstellen Sie vor dem Bearbeiten mehrere kurze Clips separat und fügen Sie diese anschließend zusammen.
- Nicht übereinstimmende Seitenverhältnisse ignorieren
Häufiger Fehler: Hochladen eines Querformatfotos im Seitenverhältnis 16:9, aber Einstellen der Ausgabe auf Hochformat 9:16 oder umgekehrt.
Warum es nicht funktioniert: Die KI schneidet entweder Ihr Bild drastisch zu oder erfordert das Ausfüllen großer leerer Bereiche. Keiner der beiden Ansätze führt zu zufriedenstellenden Ergebnissen – das Zuschneiden beeinträchtigt die sorgfältig komponierte Bildgestaltung, während das Ausfüllen großer neuer Bereiche zu Unstimmigkeiten führt.
So beheben Sie das Problem: Stellen Sie sicher, dass das Seitenverhältnis der Ausgabe mit den Proportionen des Quellbildes übereinstimmt. Verwenden Sie 16:9 für Querformatbilder und 9:16 für Hochformatbilder. Wenn ein anderes Seitenverhältnis erforderlich ist, schneiden Sie das Quellbild vor dem Hochladen auf die gewünschten Proportionen zu.
- Realistische Wirkung von illustrativen Bildern erwarten
Der Fehler: Hochladen einer Cartoon-Illustration oder eines flachen Designs in der Erwartung, dass die KI ein fotorealistisches Video generiert.
Warum es nicht funktioniert: Das Modell versucht, künstlerische Stile zu interpretieren, was manchmal zu unerwünschtem Realismus führt. Flache Illustrationen lassen die Tiefe und Lichtverhältnisse vermissen, auf die sich das Modell für eine natürliche Bewegungsvorhersage stützt.
So beheben Sie das Problem: Wenn es sich bei dem Ausgangsmaterial um eine Illustration handelt, geben Sie den Stil in der Eingabeaufforderung ausdrücklich an: „Behalten Sie den illustrierten Kunststil genau bei. Animiert in einem 2D-Animationsstil, nicht fotorealistisch. Die Bewegung sollte sich handgezeichnet und malerisch anfühlen.“ Dadurch wird das Modell angewiesen, den künstlerischen Stil beizubehalten, anstatt Fotorealismus einzuführen.
Häufig gestellte Fragen
Welches KI-Tool eignet sich am besten für die Erstellung von Videos aus Bildern?
Seedance 2.0 ist unsere Top-Empfehlung für die Bild-zu-Video-Erstellung im Jahr 2026. Es unterstützt mehrere Bildeingaben (bis zu 9 Referenzbilder), Ausgabedaten mit einer Auflösung von 2K und bietet die flexibelste Kombination aus Bildern, Text, Video und Audio. Darüber hinaus wurde Seedance von ByteDance entwickelt und ist direkt innerhalb Chinas zugänglich. Für preisbewusste Nutzer bietet Kling 3.0 eine hervorragende Bildqualität zu einem günstigeren Preis und ist ebenfalls direkt in Festlandchina zugänglich. Für Anfänger bietet Pika 2.0 die einfachste Benutzeroberfläche. Die optimale Wahl hängt von Ihren spezifischen Anforderungen ab – bitte konsultieren Sie unsere [Tool-Vergleichstabelle](#2026-year image-to-video AI tool comparison).
Kann TuSheng Video kostenlos genutzt werden?
Selbstverständlich. Mehrere Plattformen bieten kostenlose Kontingente an. Seedance stellt jedem neuen Nutzer kostenlose Credits zur Verfügung – keine Kreditkarte erforderlich. Pika 2.0 und Luma Dream Machine bieten ebenfalls eine begrenzte kostenlose Generierung an. HaiLuo AI bietet täglich 10 kostenlose Generierungen. Diese kostenlosen Kontingente reichen aus, um die Technologie zu testen und mehrere Videos zu produzieren. Für die fortlaufende Nutzung sind kostenpflichtige Tarife kostengünstiger. Weitere Strategien zur kostenlosen Nutzung finden Sie in unserem Seedance-Leitfaden zur kostenlosen Nutzung.
Was ist die maximale Länge für KI-generierte Videos?
Verschiedene Plattformen haben unterschiedliche Beschränkungen. Kling 3.0 ist führend und generiert Videos von bis zu 2 Minuten pro Bild. Seedance 2.0 begrenzt die Länge auf 15 Sekunden. Runway Gen-4 begrenzt die Länge auf 10 Sekunden. Pika 2.0 und Luma Dream Machine begrenzen Videos auf 5 Sekunden. Für die meisten Social-Media- und Marketing-Szenarien erweisen sich 5 bis 15 Sekunden als optimale Dauer. Sollten längere Aufnahmen erforderlich sein, kann man mehrere kurze Clips für die anschließende Bearbeitung und Zusammenfügung erstellen oder Kling für die Erstellung von Langform-Videos aus einer einzigen Aufnahme verwenden.
Welches Bildformat eignet sich am besten für die KI-Videogenerierung?
PNG ist optimal, da es sich um ein verlustfreies Format handelt, das frei von Kompressionsartefakten ist. WebP (verlustfreier Modus) erzielt gleichwertige Ergebnisse mit geringeren Dateigrößen. JPG ist in den meisten Fällen ebenfalls geeignet, aber stark komprimierte JPGs mit sichtbaren Kompressionsartefakten beeinträchtigen die Ausgabequalität. Vermeiden Sie die Verwendung von GIF, BMP oder anderen nicht standardisierten Formaten. Alle gängigen Plattformen unterstützen JPG, PNG und WebP. Mindestauflösung: 512 x 512 Pixel. Empfohlen: 1024 x 1024 oder höher.
Kann KI jede Art von Bild animieren?
KI kann die meisten Arten von Bildern animieren, wobei die Ergebnisse je nach Motiv variieren. Porträts und Kopfaufnahmen liefern die besten Ergebnisse – aktuelle Modelle erfassen natürliche Gesichtsbewegungen und Haarbewegungen sehr gut. Landschaften und Naturszenen liefern ebenfalls hervorragende Ergebnisse mit überzeugenden Darstellungen von Wolkenbewegungen, fließendem Wasser und sich wiegender Vegetation. Produktbilder mit sauberem Hintergrund liefern durchweg zuverlässige Ergebnisse. Illustrationen und Kunstwerke können animiert werden, erfordern jedoch möglicherweise stilisierte Eingaben, um unbeabsichtigten Fotorealismus zu vermeiden. Komplexe Gruppenszenen, Bilder mit umfangreichem Text und Fotos von geringer Qualität liefern die unbeständigsten Ergebnisse.
Was ist der Unterschied zwischen bildgenerierten Videos und textgenerierten Videos?
Text-zu-Video generiert gleichzeitig visuelle Inhalte und Bewegungen aus textuellen Beschreibungen. Die KI bestimmt das gesamte visuelle Erscheinungsbild, bietet weniger Kontrolle über bestimmte Details, aber mehr kreative Freiheit. Bild-zu-Video verwendet Ihre vorhandenen Bilder als Ausgangspunkt und generiert nur die Bewegung. Sie behalten die präzise Kontrolle über die visuelle Ausgabe, da Sie die visuelle Referenz bereitstellen. Image-to-Video liefert in der Regel vorhersehbarere und konsistentere Ergebnisse, da die KI einen konkreten visuellen Ankerpunkt hat. Text-to-Video eignet sich besser, wenn die KI völlig neue Inhalte von Grund auf erstellen soll.
Kann Tusheng Video die Kamerabewegung steuern?
Selbstverständlich. Die meisten modernen generativen Videotools unterstützen die Steuerung von Kamerabewegungen über Textbefehle. Sie können Bewegungen wie „Dolly-in“, „Pan links“, „Orbit um“, „Kran hoch“, „Zoom out“ und „Tracking Shot“ festlegen. Seedance 2.0 und Luma Dream Machine reagieren besonders präzise auf diese Bewegungsbegriffe. Runway Gen-4 bietet zusätzliche Präzision durch seinen Motion Brush und Director Mode, der das visuelle Zeichnen von Pfaden für Kamerabewegungen ermöglicht. Es ist ratsam, nur einen Bewegungstyp pro Generation anzugeben und diesen durch Geschwindigkeitsmodifikatoren wie „langsam“ oder „gleichmäßig“ zu ergänzen.
Ist die Bildqualität von KI-generierten Videos für professionelle Anwendungen ausreichend?
Für kurze Videoinhalte (5–15 Sekunden) ist dies durchaus machbar. Die Ergebnisse von Spitzenplattformen wie Seedance 2.0 und Runway Gen-4 werden bereits professionell für Social-Media-Marketing, E-Commerce-Produktvideos, Immobilienpräsentationen und Werbekonzepte genutzt. Im Inland enthalten umfangreiche kommerzielle Inhalte auf Douyin und Xiaohongshu mittlerweile KI-generierte Video-Assets. Es bestehen jedoch weiterhin Einschränkungen: Längere Laufzeiten erhöhen das Risiko von Unvollkommenheiten, komplexe Szenen mit mehreren Motiven bleiben instabil und die Textwiedergabe in Videos ist noch nicht perfekt. Für Werke in Sendequalität oder Kinofilme, die absolute Perfektion erfordern, bleibt das traditionelle Filmen die sicherere Option. Für digitales Marketing und soziale Inhalte hat die KI-Bild-zu-Video-Technologie mittlerweile professionelle Standards erreicht.
Zusammenfassung
TuSheng Video KI hat sich von einer Neuheit zu einem unverzichtbaren Werkzeug für die Erstellung von Inhalten entwickelt. Die Technologie ist ausgereift, die Tools sind benutzerfreundlich geworden und die Ausgabequalität entspricht nun den professionellen Standards für die überwiegende Mehrheit der digitalen Inhaltsszenarien.
Die folgenden Punkte sind dabei besonders wichtig:
- Die Qualität der Ausgangsbilder ist von entscheidender Bedeutung. Scharfe, gut komponierte Bilder mit hoher Auflösung liefern deutlich bessere Ergebnisse als unscharfe oder Bilder mit niedriger Auflösung.
- Beschreiben Sie Bewegungen, nicht das Aussehen. Die KI hat Ihr Bild bereits gesehen. Sagen Sie ihr, wie sich die Dinge bewegen sollen, nicht wie sie aussehen.
- **Fangen Sie einfach an. ** Eine Aktion des Motivs plus eine Kamerabewegung. Beherrschen Sie die Grundlagen, bevor Sie die Komplexität erhöhen.
- Wiederholen Sie schnell. Erstellen Sie zunächst kurze Testclips; produzieren Sie die Vollversion erst, wenn Sie zufrieden sind.
- **Passen Sie die Tools an die Aufgaben an. ** Seedance legt Wert auf visuelle Genauigkeit und multimodale Steuerung, KeLing zeichnet sich durch lange Videos und Erschwinglichkeit aus, Runway konzentriert sich auf präzise Bearbeitung, während Pika Wert auf Einfachheit legt.
- Wählen Sie das Werkzeug, das zu Ihnen passt. Wenn Sie sich auf dem chinesischen Festland befinden, sind Seedance und KeLing ohne zusätzliche Netzwerk- oder Zahlungsbarrieren direkt zugänglich.
Die Kluft zwischen Marken und Kreativen, die Tusheng Video AI nutzen, und ihren Kollegen, die weiterhin auf statische Bilder setzen, vergrößert sich von Monat zu Monat. Jedes Foto in Ihrer Produktbibliothek birgt das Potenzial für eine Videowerbung. Jedes Porträt könnte zu einem dynamischen Avatar werden. Jede Landschaftsszene könnte als filmisches B-Roll-Material dienen.
Erstellen Sie kostenlos Ihr erstes Bild-zu-Video --> – Laden Sie ein beliebiges Bild hoch und sehen Sie zu, wie es innerhalb von zwei Minuten zum Leben erwacht. Keine Kreditkarte erforderlich, direkt in Festlandchina zugänglich.
Möchten Sie weitere KI-Videofunktionen entdecken? Erleben Sie Seedance auf allen Plattformen --> – Text-zu-Video, Video-zu-Video, multimodale Generierung: alles an einem Ort.
Weiterführende Literatur: Seedance Komplettanleitung | Seedance Prompt-Anleitung mit über 50 Beispielen | Anwendungsbeispiele für kreative KI-Videos | Ranking der besten KI-Videogeneratoren für 2026 | Leitfaden für KI-Videomarketing und soziale Medien | Text-zu-Video-KI: Komplettleitfaden*
